Publikování kanálů strojového učení
PLATÍ PRO: Python SDK azureml v1
Python SDK azureml v1
V tomto článku se dozvíte, jak sdílet kanál strojového učení s kolegy nebo zákazníky.
Kanály strojového učení jsou opakovaně použitelné pracovní postupy pro úlohy strojového učení. Jednou z výhod kanálů je zvýšená spolupráce. Kanály verzí můžete také povolit zákazníkům používat aktuální model při práci na nové verzi.
Požadavky
Vytvoření pracovního prostoru Azure Machine Learning pro uložení všech prostředků kanálu
Konfigurace vývojového prostředí pro instalaci sady Azure Machine Learning SDK nebo použití výpočetní instance služby Azure Machine Learning s již nainstalovanou sadou SDK
Vytvořte a spusťte kanál strojového učení, například pomocí následujícího kurzu: Vytvoření kanálu Služby Azure Machine Learning pro dávkové vyhodnocování. Další možnosti najdete v tématu Vytváření a spouštění kanálů strojového učení pomocí sady Azure Machine Learning SDK.
Publikování kanálu
Jakmile máte kanál spuštěný a spuštěný, můžete kanál publikovat tak, aby běžel s různými vstupy. Aby koncový bod REST již publikovaného kanálu přijímal parametry, musíte nakonfigurovat kanál tak, aby používal PipelineParameter objekty pro argumenty, které se budou lišit.
K vytvoření parametru kanálu použijte objekt PipelineParameter s výchozí hodnotou.
from azureml.pipeline.core.graph import PipelineParameter pipeline_param = PipelineParameter( name="pipeline_arg", default_value=10)Přidejte tento
PipelineParameterobjekt jako parametr do některého z kroků v kanálu následujícím způsobem:compareStep = PythonScriptStep( script_name="compare.py", arguments=["--comp_data1", comp_data1, "--comp_data2", comp_data2, "--output_data", out_data3, "--param1", pipeline_param], inputs=[ comp_data1, comp_data2], outputs=[out_data3], compute_target=compute_target, source_directory=project_folder)Publikujte tento kanál, který při vyvolání přijme parametr.
published_pipeline1 = pipeline_run1.publish_pipeline( name="My_Published_Pipeline", description="My Published Pipeline Description", version="1.0")Po publikování kanálu ho můžete zkontrolovat v uživatelském rozhraní. ID kanálu je jedinečný identifikátor publikovaného kanálu.
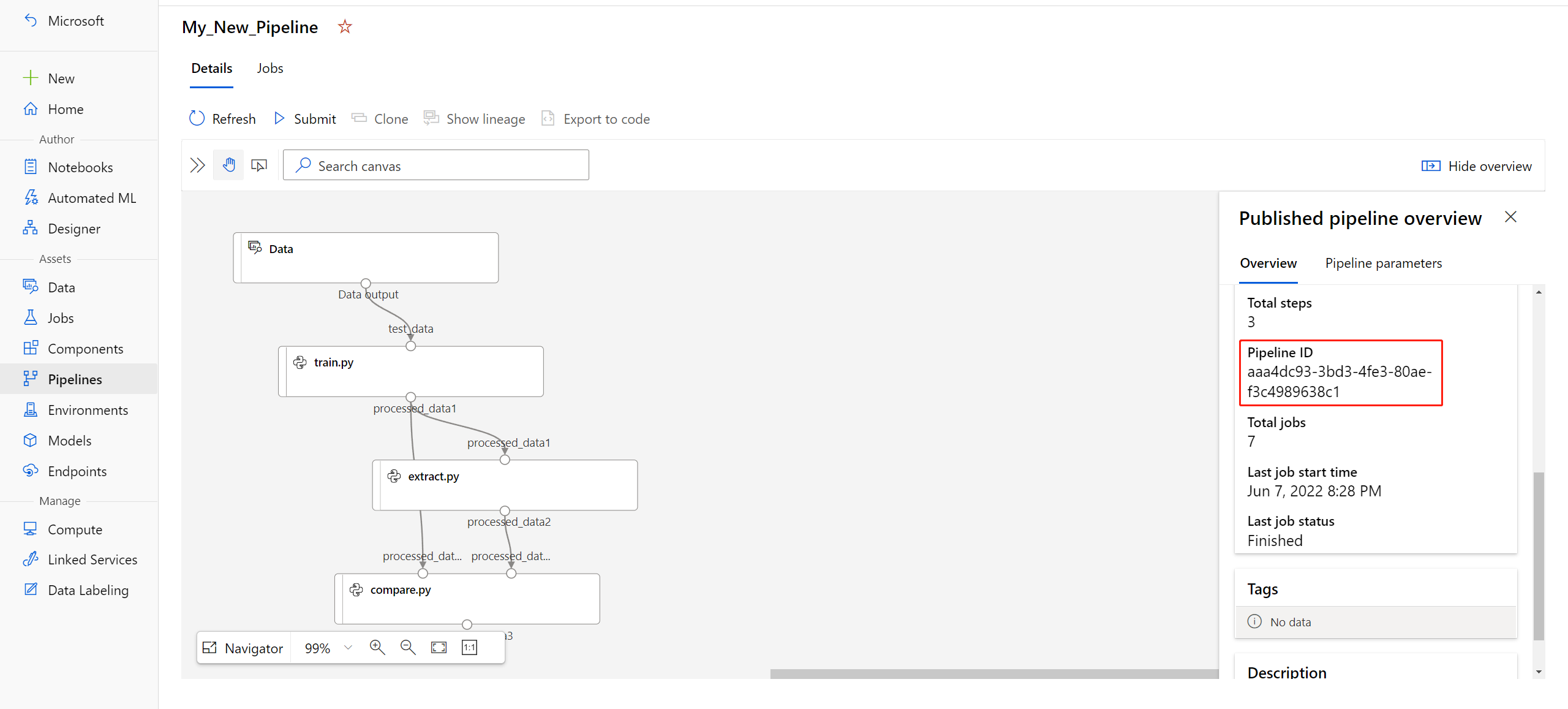

Spuštění publikovaného kanálu
Všechny publikované kanály mají koncový bod REST. Pomocí koncového bodu kanálu můžete spustit spuštění kanálu z libovolného externího systému, včetně klientů mimo Python. Tento koncový bod umožňuje "spravovanou opakovatelnost" ve scénářích dávkového bodování a opětovném natrénování.
Důležité
Pokud ke správě přístupu ke svému kanálu používáte řízení přístupu na základě role v Azure (Azure RBAC), nastavte oprávnění pro váš scénář kanálu (trénování nebo bodování).
K vyvolání spuštění předchozího kanálu potřebujete token hlavičky ověřování Microsoft Entra. Získání takového tokenu je popsáno v referenčních informacích ke třídě AzureCliAuthentication a v poznámkovém bloku Azure Machine Learning v ověřování.
from azureml.pipeline.core import PublishedPipeline
import requests
response = requests.post(published_pipeline1.endpoint,
headers=aad_token,
json={"ExperimentName": "My_Pipeline",
"ParameterAssignments": {"pipeline_arg": 20}})
Argument json požadavku POST musí obsahovat slovník obsahující ParameterAssignments parametry kanálu a jejich hodnoty. Kromě toho může json argument obsahovat následující klíče:
| Key | Popis |
|---|---|
ExperimentName |
Název experimentu přidruženého k tomuto koncovému bodu |
Description |
Volný text popisující koncový bod |
Tags |
Páry volných klíč-hodnota, které se dají použít k označení a přidávání poznámek k žádostem |
DataSetDefinitionValueAssignments |
Slovník používaný ke změně datových sad bez opětovného natrénování (viz následující diskuze) |
DataPathAssignments |
Slovník používaný ke změně cest k datům bez opětovného natrénování (viz následující diskuze) |
Spuštění publikovaného kanálu pomocí jazyka C#
Následující kód ukazuje, jak volat kanál asynchronně z jazyka C#. Částečný fragment kódu jenom zobrazuje strukturu volání a není součástí ukázky Microsoftu. Nezobrazuje se v ní kompletní třídy ani zpracování chyb.
[DataContract]
public class SubmitPipelineRunRequest
{
[DataMember]
public string ExperimentName { get; set; }
[DataMember]
public string Description { get; set; }
[DataMember(IsRequired = false)]
public IDictionary<string, string> ParameterAssignments { get; set; }
}
// ... in its own class and method ...
const string RestEndpoint = "your-pipeline-endpoint";
using (HttpClient client = new HttpClient())
{
var submitPipelineRunRequest = new SubmitPipelineRunRequest()
{
ExperimentName = "YourExperimentName",
Description = "Asynchronous C# REST api call",
ParameterAssignments = new Dictionary<string, string>
{
{
// Replace with your pipeline parameter keys and values
"your-pipeline-parameter", "default-value"
}
}
};
string auth_key = "your-auth-key";
client.DefaultRequestHeaders.Authorization = new AuthenticationHeaderValue("Bearer", auth_key);
// submit the job
var requestPayload = JsonConvert.SerializeObject(submitPipelineRunRequest);
var httpContent = new StringContent(requestPayload, Encoding.UTF8, "application/json");
var submitResponse = await client.PostAsync(RestEndpoint, httpContent).ConfigureAwait(false);
if (!submitResponse.IsSuccessStatusCode)
{
await WriteFailedResponse(submitResponse); // ... method not shown ...
return;
}
var result = await submitResponse.Content.ReadAsStringAsync().ConfigureAwait(false);
var obj = JObject.Parse(result);
// ... use `obj` dictionary to access results
}
Spuštění publikovaného kanálu pomocí Javy
Následující kód ukazuje volání kanálu, který vyžaduje ověření (viz Nastavení ověřování pro prostředky a pracovní postupy služby Azure Machine Learning). Pokud je váš kanál nasazen veřejně, nepotřebujete volání, která vytvářejí authKey. Částečný fragment kódu nezobrazuje často používané třídy Java a zpracování výjimek. Kód používá Optional.flatMap ke zřetězení funkcí, které mohou vrátit prázdnou Optional. Použití flatMap zkracuje a objasňuje kód, ale všimněte si, že getRequestBody() spolkne výjimky.
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.util.Optional;
// JSON library
import com.google.gson.Gson;
String scoringUri = "scoring-endpoint";
String tenantId = "your-tenant-id";
String clientId = "your-client-id";
String clientSecret = "your-client-secret";
String resourceManagerUrl = "https://management.azure.com";
String dataToBeScored = "{ \"ExperimentName\" : \"My_Pipeline\", \"ParameterAssignments\" : { \"pipeline_arg\" : \"20\" }}";
HttpClient client = HttpClient.newBuilder().build();
Gson gson = new Gson();
HttpRequest tokenAuthenticationRequest = tokenAuthenticationRequest(tenantId, clientId, clientSecret, resourceManagerUrl);
Optional<String> authBody = getRequestBody(client, tokenAuthenticationRequest);
Optional<String> authKey = authBody.flatMap(body -> Optional.of(gson.fromJson(body, AuthenticationBody.class).access_token);;
Optional<HttpRequest> scoringRequest = authKey.flatMap(key -> Optional.of(scoringRequest(key, scoringUri, dataToBeScored)));
Optional<String> scoringResult = scoringRequest.flatMap(req -> getRequestBody(client, req));
// ... etc (`scoringResult.orElse()`) ...
static HttpRequest tokenAuthenticationRequest(String tenantId, String clientId, String clientSecret, String resourceManagerUrl)
{
String authUrl = String.format("https://login.microsoftonline.com/%s/oauth2/token", tenantId);
String clientIdParam = String.format("client_id=%s", clientId);
String resourceParam = String.format("resource=%s", resourceManagerUrl);
String clientSecretParam = String.format("client_secret=%s", clientSecret);
String bodyString = String.format("grant_type=client_credentials&%s&%s&%s", clientIdParam, resourceParam, clientSecretParam);
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(authUrl))
.POST(HttpRequest.BodyPublishers.ofString(bodyString))
.build();
return request;
}
static HttpRequest scoringRequest(String authKey, String scoringUri, String dataToBeScored)
{
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(scoringUri))
.header("Authorization", String.format("Token %s", authKey))
.POST(HttpRequest.BodyPublishers.ofString(dataToBeScored))
.build();
return request;
}
static Optional<String> getRequestBody(HttpClient client, HttpRequest request) {
try {
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
if (response.statusCode() != 200) {
System.out.println(String.format("Unexpected server response %d", response.statusCode()));
return Optional.empty();
}
return Optional.of(response.body());
}catch(Exception x)
{
System.out.println(x.toString());
return Optional.empty();
}
}
class AuthenticationBody {
String access_token;
String token_type;
int expires_in;
String scope;
String refresh_token;
String id_token;
AuthenticationBody() {}
}
Změna datových sad a cest k datům bez opětovného natrénování
Možná budete chtít trénovat a odvozovat různé datové sady a cesty k datům. Můžete například chtít trénovat na menší datové sadě, ale odvozovat kompletní datovou sadu. Datové sady můžete přepnout pomocí DataSetDefinitionValueAssignments klíče v argumentu json požadavku. Přepnete datové cesty pomocí DataPathAssignments. Postup pro oba je podobný:
Ve skriptu definice kanálu vytvořte pro datovou
PipelineParametersadu.DatasetConsumptionConfigVytvořte neboDataPathz:PipelineParametertabular_dataset = Dataset.Tabular.from_delimited_files('https://dprepdata.blob.core.windows.net/demo/Titanic.csv') tabular_pipeline_param = PipelineParameter(name="tabular_ds_param", default_value=tabular_dataset) tabular_ds_consumption = DatasetConsumptionConfig("tabular_dataset", tabular_pipeline_param)Ve skriptu ML přistupovat k dynamicky zadané datové sadě pomocí
Run.get_context().input_datasets:from azureml.core import Run input_tabular_ds = Run.get_context().input_datasets['tabular_dataset'] dataframe = input_tabular_ds.to_pandas_dataframe() # ... etc ...Všimněte si, že skript ML přistupuje k hodnotě zadané pro
DatasetConsumptionConfig(tabular_dataset) a ne k hodnotěPipelineParameter(tabular_ds_param).V definičním
DatasetConsumptionConfigskriptu kanálu nastavte parametr naPipelineScriptStep:train_step = PythonScriptStep( name="train_step", script_name="train_with_dataset.py", arguments=["--param1", tabular_ds_consumption], inputs=[tabular_ds_consumption], compute_target=compute_target, source_directory=source_directory) pipeline = Pipeline(workspace=ws, steps=[train_step])Pokud chcete v odvozovacím volání REST dynamicky přepínat datové sady, použijte
DataSetDefinitionValueAssignments:tabular_ds1 = Dataset.Tabular.from_delimited_files('path_to_training_dataset') tabular_ds2 = Dataset.Tabular.from_delimited_files('path_to_inference_dataset') ds1_id = tabular_ds1.id d22_id = tabular_ds2.id response = requests.post(rest_endpoint, headers=aad_token, json={ "ExperimentName": "MyRestPipeline", "DataSetDefinitionValueAssignments": { "tabular_ds_param": { "SavedDataSetReference": {"Id": ds1_id #or ds2_id }}}})
Poznámkové bloky Showcasing Dataset and PipelineParameter a Showcasing DataPath a PipelineParameter mají kompletní příklady této techniky.
Vytvoření koncového bodu kanálu s verzí
Koncový bod kanálu můžete vytvořit s několika publikovanými kanály za ním. Tato technika poskytuje pevný koncový bod REST při iteraci a aktualizaci kanálů ML.
from azureml.pipeline.core import PipelineEndpoint
published_pipeline = PublishedPipeline.get(workspace=ws, id="My_Published_Pipeline_id")
pipeline_endpoint = PipelineEndpoint.publish(workspace=ws, name="PipelineEndpointTest",
pipeline=published_pipeline, description="Test description Notebook")
Odeslání úlohy do koncového bodu kanálu
Úlohu můžete odeslat do výchozí verze koncového bodu kanálu:
pipeline_endpoint_by_name = PipelineEndpoint.get(workspace=ws, name="PipelineEndpointTest")
run_id = pipeline_endpoint_by_name.submit("PipelineEndpointExperiment")
print(run_id)
Úlohu můžete odeslat také do konkrétní verze:
run_id = pipeline_endpoint_by_name.submit("PipelineEndpointExperiment", pipeline_version="0")
print(run_id)
Totéž lze provést pomocí rozhraní REST API:
rest_endpoint = pipeline_endpoint_by_name.endpoint
response = requests.post(rest_endpoint,
headers=aad_token,
json={"ExperimentName": "PipelineEndpointExperiment",
"RunSource": "API",
"ParameterAssignments": {"1": "united", "2":"city"}})
Použití publikovaných kanálů v sadě Studio
Publikovaný kanál můžete spustit také ze studia:
Přihlaste se k studio Azure Machine Learning.
Vlevo vyberte Koncové body.
Nahoře vyberte koncové body kanálu.
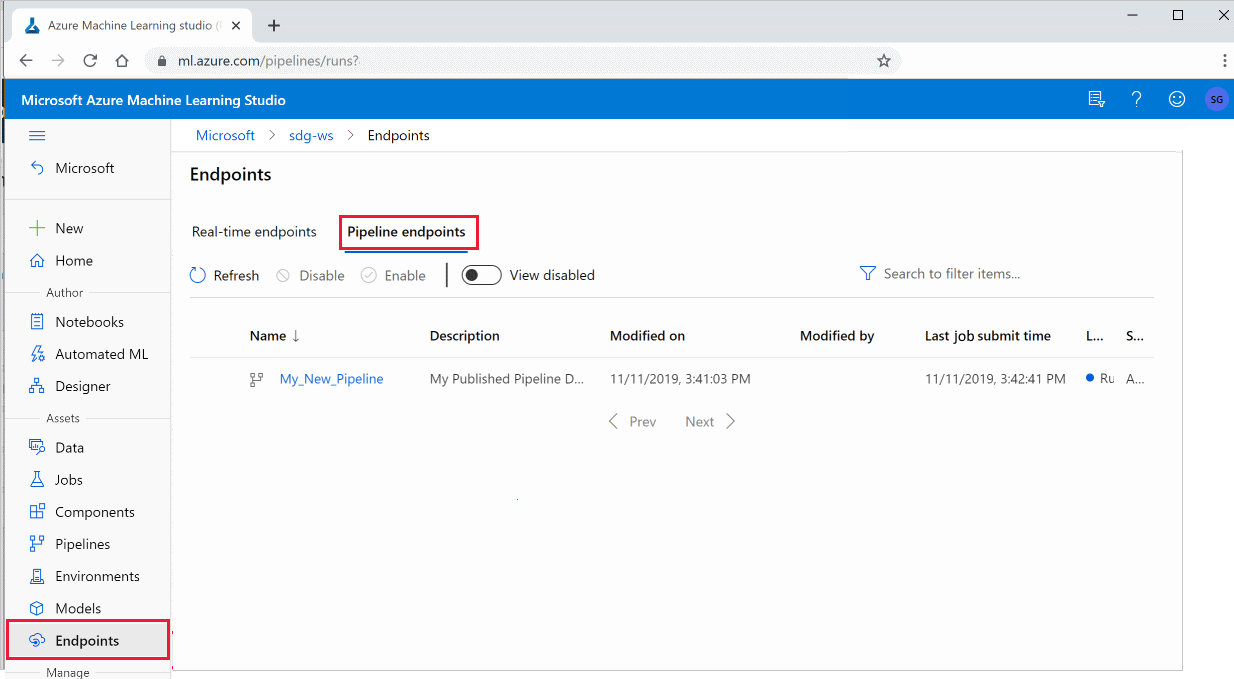
Vyberte konkrétní kanál, který se má spustit, využívat nebo zkontrolovat výsledky předchozích spuštění koncového bodu kanálu.
Zakázání publikovaného kanálu
Pokud chcete kanál skrýt ze seznamu publikovaných kanálů, zakažte ho v sadě Studio nebo v sadě SDK:
# Get the pipeline by using its ID from Azure Machine Learning studio
p = PublishedPipeline.get(ws, id="068f4885-7088-424b-8ce2-eeb9ba5381a6")
p.disable()
Můžete ho znovu povolit pomocí p.enable(). Další informace naleznete v tématu PublishedPipeline třídy reference.
Další kroky
- Pomocí těchto poznámkových bloků Jupyter na GitHubu můžete podrobněji prozkoumat kanály strojového učení.
- Prohlédnou si referenční nápovědu k sadě SDK pro balíček azureml-pipelines-core a balíček azureml-pipelines-steps .
- Tipy k ladění a řešení potíží s kanály najdete v návodech .