Posun dat (Preview) se vyřadí a nahradí ho monitorováním modelů.
Posun dat (Preview) se vyřadí do 1. 9. 2025 a můžete začít používat monitorování modelů pro úkoly posunu dat. Projděte si následující obsah a seznamte se s nahrazením, mezerami funkcí a ručními kroky změn.
PLATÍ PRO: Python SDK azureml v1
Python SDK azureml v1
Zjistěte, jak monitorovat odchylky dat a nastavit upozornění, když je posun vysoký.
Poznámka:
Monitorování modelů Azure Machine Learning (v2) poskytuje vylepšené funkce pro posun dat spolu s dalšími funkcemi pro monitorování signálů a metrik. Další informace o možnostech monitorování modelů ve službě Azure Machine Learning (v2) najdete v tématu Monitorování modelů pomocí služby Azure Machine Learning.
Pomocí monitorování datových sad Azure Machine Learning (Preview) můžete:
- Analyzujte posun dat , abyste pochopili, jak se mění v průběhu času.
- Monitorování dat modelu pro rozdíly mezi trénováním a obsluhou datových sad Začněte shromažďováním dat modelu z nasazených modelů.
- Monitorujte nová data pro rozdíly mezi všemi směrnými a cílovými datovými sadami.
- Funkce profilu v datech umožňují sledovat, jak se statistické vlastnosti v průběhu času mění.
- Nastavte upozornění na odchylky dat pro časná upozornění na potenciální problémy.
- Vytvořte novou verzi datové sady, když zjistíte, že se data příliš posunují.
K vytvoření monitorování se používá datová sada Azure Machine Learning. Datová sada musí obsahovat sloupec časového razítka.
Metriky posunu dat můžete zobrazit pomocí sady Python SDK nebo v studio Azure Machine Learning. Další metriky a přehledy jsou k dispozici prostřednictvím prostředku Aplikace Azure lication Insights přidruženého k pracovnímu prostoru Azure Machine Learning.
Důležité
Detekce odchylek dat pro datové sady je aktuálně ve verzi Public Preview. Verze Preview je poskytována bez smlouvy o úrovni služeb a nedoporučuje se pro produkční úlohy. Některé funkce se nemusí podporovat nebo mohou mít omezené možnosti. Další informace najdete v dodatečných podmínkách použití pro verze Preview v Microsoft Azure.
Požadavky
K vytváření a práci s monitorováním datových sad potřebujete:
- Předplatné Azure. Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet. Vyzkoušejte si bezplatnou nebo placenou verzi služby Azure Machine Learning ještě dnes.
- Pracovní prostor Azure Machine Learning.
- Nainstalovaná sada Azure Machine Learning SDK pro Python, která zahrnuje balíček azureml-datasets.
- Strukturovaná (tabulková) data s časovým razítkem zadaným v cestě k souboru, názvu souboru nebo sloupci v datech.
Požadavky (migrace na monitorování modelů)
Při migraci na Monitorování modelů zkontrolujte požadavky uvedené v tomto článku Požadavky monitorování modelů služby Azure Machine Learning.
Co je posun dat?
Přesnost modelu se v průběhu času z velké části snižuje kvůli posunu dat. U modelů strojového učení je posun dat změnou vstupních dat modelu, která vede ke snížení výkonu modelu. Monitorování posunu dat pomáhá rozpoznat tyto problémy s výkonem modelu.
Mezi příčiny posunu dat patří:
- Upstreamové změny procesu, jako je například výměna senzoru, který mění měrné jednotky z palců na centimetry.
- Problémy s kvalitou dat, například poškozený senzor, vždy čte 0.
- Přirozený posun dat, jako je změna průměrné teploty s ročními obdobími.
- Změna vztahu mezi funkcemi nebo kovariantní posun.
Azure Machine Learning zjednodušuje detekci odchylek tím, že počítá jednu metriku, která abstrahuje složitost datových sad, které se porovnávají. Tyto datové sady můžou mít stovky funkcí a desítky tisíc řádků. Po zjištění posunu přejdete k podrobnostem o tom, které funkce způsobují posun. Potom zkontrolujete metriky na úrovni funkcí, abyste mohli ladit a izolovat původní příčinu posunu.
Tento přístup shora dolů usnadňuje monitorování dat místo tradičních technik založených na pravidlech. Techniky založené na pravidlech, jako je povolený rozsah dat nebo povolené jedinečné hodnoty, můžou být časově náročné a náchylné k chybám.
Ve službě Azure Machine Learning používáte monitorování datových sad k detekci a upozorňování na posun dat.
Monitorování datových sad
Pomocí monitorování datové sady můžete:
- Detekce a upozorňování na posun dat u nových dat v datové sadě
- Analýza historických dat za účelem posunu
- Profilování nových dat v průběhu času
Algoritmus posunu dat poskytuje celkovou míru změny dat a indikaci toho, které funkce jsou zodpovědné za další šetření. Monitorování datových sad vytváří mnoho dalších metrik profilací nových dat v timeseries datové sadě.
Vlastní upozorňování je možné nastavit pro všechny metriky vygenerované monitorováním prostřednictvím Aplikace Azure lication Insights. Monitorování datových sad je možné použít k rychlému zachycení problémů s daty a zkrácení doby ladění problému tím, že identifikuje pravděpodobné příčiny.
Koncepčně existují tři hlavní scénáře pro nastavení monitorování datových sad ve službě Azure Machine Learning.
| Scénář | Popis |
|---|---|
| Monitorování dat obsluhující model kvůli posunu od trénovacích dat | Výsledky z tohoto scénáře lze interpretovat jako monitorování proxy serveru pro přesnost modelu, protože přesnost modelu se snižuje při poskytování odchylek dat od trénovacích dat. |
| Monitorujte datovou sadu časových řad pro posun z předchozího časového období. | Tento scénář je obecnější a lze ho použít k monitorování datových sad, které zahrnovaly upstreamové nebo podřízené sestavení modelu. Cílová datová sada musí mít sloupec časového razítka. Základní datová sada může být libovolná tabulková datová sada, která má společné funkce s cílovou datovou sadou. |
| Proveďte analýzu minulých dat. | Tento scénář se dá použít k pochopení historických dat a informování rozhodnutí v nastavení monitorování datových sad. |
Monitorování datových sad závisí na následujících službách Azure.
| Služba Azure | Popis |
|---|---|
| Dataset | Drift používá datové sady Machine Learning k načtení trénovacích dat a porovnání dat pro trénování modelu. Generování profilu dat se používá k vygenerování některých hlášených metrik, jako je minimum, maximum, jedinečné hodnoty, počet jedinečných hodnot. |
| Kanál a výpočetní prostředky služby Azure Machine Learning | Úloha výpočtu posunu je hostovaná v kanálu služby Azure Machine Learning. Úloha se aktivuje na vyžádání nebo podle plánu tak, aby běžela na výpočetním výkonu nakonfigurované v době vytváření sledování odchylek. |
| Application Insights | Posun generuje metriky do Application Insights patřící do pracovního prostoru strojového učení. |
| Azure Blob Storage | Posun generuje metriky ve formátu JSON do služby Azure Blob Storage. |
Standardní a cílové datové sady
Datové sady Azure Machine Learning monitorujete pro posun dat. Při vytváření monitorování datové sady odkazujete na:
- Základní datová sada – obvykle trénovací datová sada pro model.
- Cílová datová sada – obvykle vstupní data modelu – se porovnává v průběhu času s datovou sadou podle směrného plánu. Toto porovnání znamená, že cílová datová sada musí mít zadaný sloupec časového razítka.
Monitorování porovnává základní a cílové datové sady.
Migrace na monitorování modelů
Ve službě Monitorování modelů najdete odpovídající koncepty, jak je znázorněno níže, a další podrobnosti najdete v tomto článku Nastavení monitorování modelů přenesením produkčních dat do služby Azure Machine Learning:
- Referenční datová sada: podobně jako u základní datové sady pro detekci posunů dat je nastavená jako datová sada pro odvozování z poslední doby v minulém produkčním prostředí.
- Produkční data odvozování: podobně jako cílová datová sada při detekci posunu dat je možné automaticky shromažďovat produkční data odvozování z modelů nasazených v produkčním prostředí. Může to být také odvozování dat, která ukládáte.
Vytvoření cílové datové sady
Cílová datová sada potřebuje timeseries vlastnost nastavenou na ni zadáním sloupce časového razítka buď ze sloupce v datech, nebo virtuálního sloupce odvozeného ze vzoru cesty souborů. Vytvořte datovou sadu s časovým razítkem prostřednictvím sady Python SDK nebo studio Azure Machine Learning. Aby bylo možné do datové sady přidat timeseries vlastnost, musí být zadán sloupec představující časové razítko. Pokud jsou vaše data rozdělená do struktury složek s časovými informacemi, například {yyyy/MM/dd}, vytvořte virtuální sloupec pomocí nastavení vzoru cesty a nastavte ho jako časové razítko oddílu, aby bylo možné povolit funkce rozhraní API časových řad.
PLATÍ PRO: Python SDK azureml v1
Metoda Dataset třídy with_timestamp_columns() definuje sloupec časového razítka pro datovou sadu.
from azureml.core import Workspace, Dataset, Datastore
# get workspace object
ws = Workspace.from_config()
# get datastore object
dstore = Datastore.get(ws, 'your datastore name')
# specify datastore paths
dstore_paths = [(dstore, 'weather/*/*/*/*/data.parquet')]
# specify partition format
partition_format = 'weather/{state}/{date:yyyy/MM/dd}/data.parquet'
# create the Tabular dataset with 'state' and 'date' as virtual columns
dset = Dataset.Tabular.from_parquet_files(path=dstore_paths, partition_format=partition_format)
# assign the timestamp attribute to a real or virtual column in the dataset
dset = dset.with_timestamp_columns('date')
# register the dataset as the target dataset
dset = dset.register(ws, 'target')
Tip
Úplný příklad použití timeseries vlastností datových sad najdete v ukázkovém poznámkovém bloku nebo dokumentaci k sadě SDK datových sad.

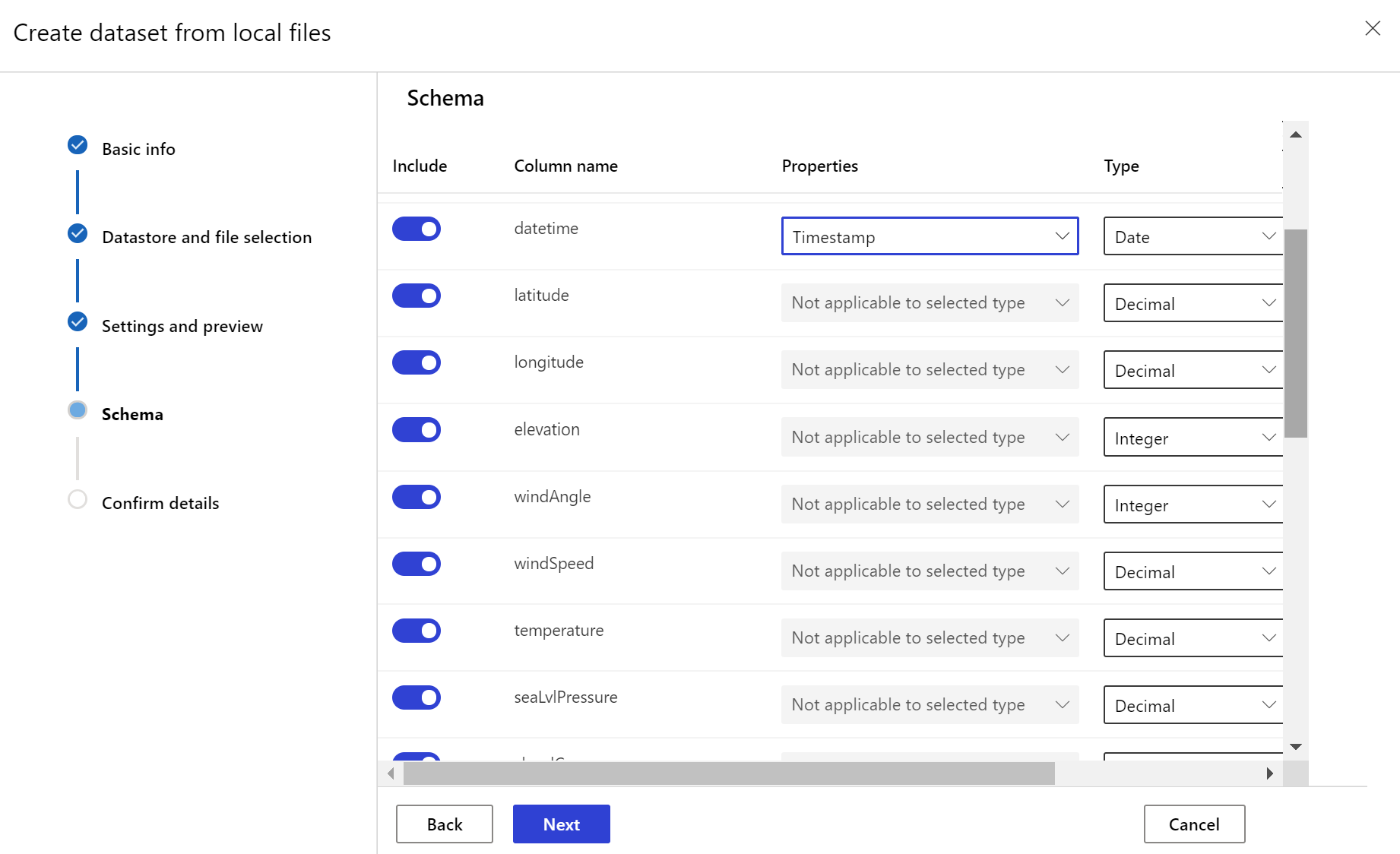
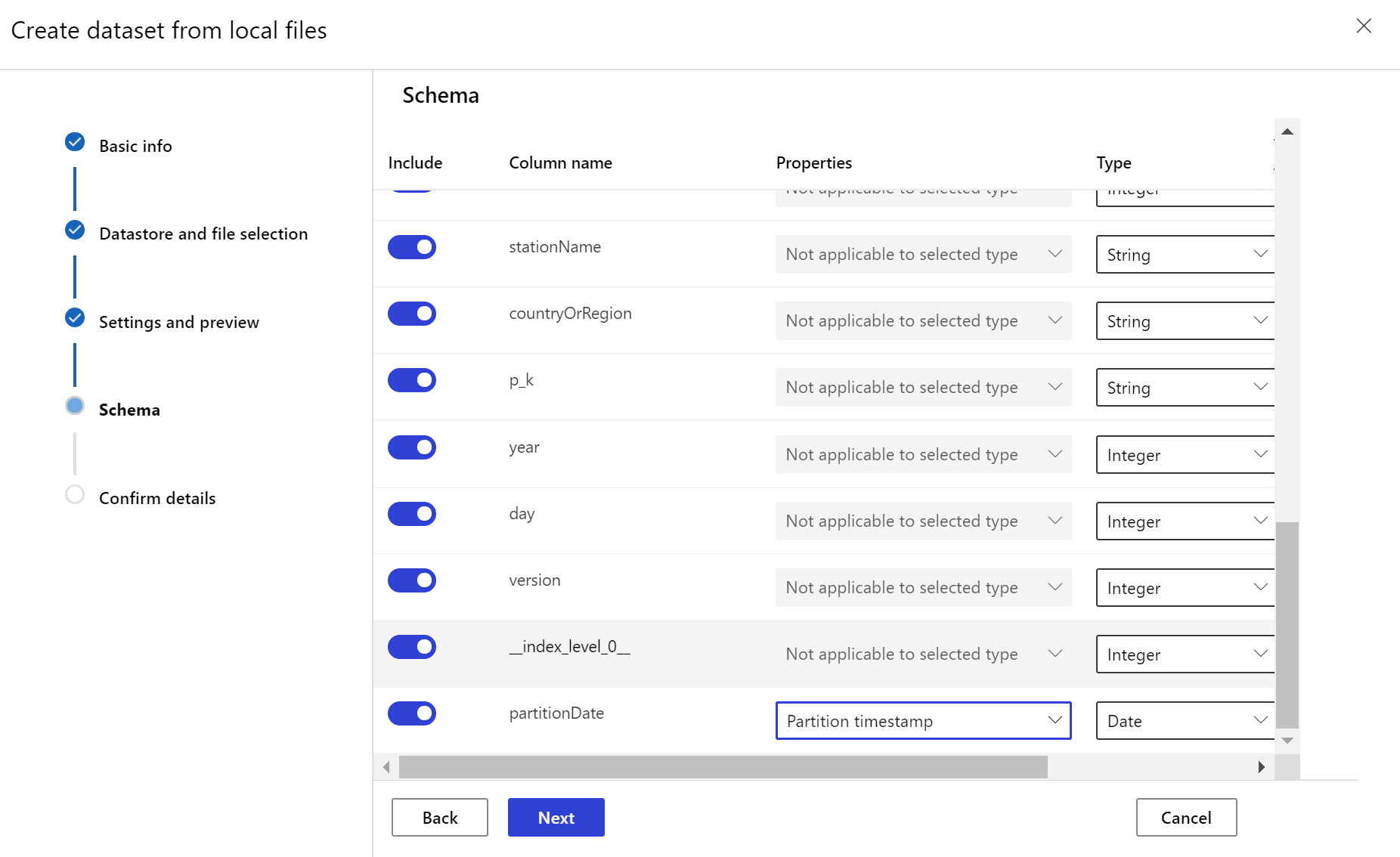
Vytvoření monitorování datové sady
Vytvořte monitorování datové sady pro detekci a upozorňování na posun dat v nové datové sadě. Použijte sadu Python SDK nebo studio Azure Machine Learning.
Jak je popsáno později, monitorování datové sady se spouští v nastavených intervalech (denní, týdenní, měsíční). Analyzuje nová data dostupná v cílové datové sadě od svého posledního spuštění. V některých případech nemusí taková analýza nejnovějších dat stačit:
- Nová data z nadřazeného zdroje se zpozdila kvůli poškozenému datovému kanálu a tato nová data nebyla při spuštění monitorování datové sady dostupná.
- Datová sada časových řad obsahovala pouze historická data a vy chcete analyzovat vzorce posunu v datové sadě v průběhu času. Příklad: Porovnání provozu na webu, jak v zimních a letních sezónách, tak k identifikaci sezónních vzorů.
- S monitorováním datových sad začínáte. Před nastavením funkce pro monitorování budoucích dnů chcete vyhodnotit, jak tato funkce funguje s vašimi stávajícími daty. V takových scénářích můžete odeslat spuštění na vyžádání s konkrétním cílovým rozsahem dat nastaveným na datovou sadu, abyste je mohli porovnat se základní datovou sadou.
Funkce backfill spustí úlohu obnovení pro zadaný rozsah počátečního a koncového data. Úloha obnovení vyplňuje očekávané chybějící datové body v sadě dat jako způsob, jak zajistit přesnost a úplnost dat.
Poznámka:
Monitorování modelů Azure Machine Learning nepodporuje funkci ručního obnovení , pokud chcete znovu provést monitorování modelu pro konkrétní časový rozsah, můžete pro tento konkrétní časový rozsah vytvořit další monitorování modelu.
PLATÍ PRO: Python SDK azureml v1
Úplné podrobnosti najdete v referenční dokumentaci k sadě Python SDK.
Následující příklad ukazuje, jak vytvořit monitorování datové sady pomocí sady Python SDK:
from azureml.core import Workspace, Dataset
from azureml.datadrift import DataDriftDetector
from datetime import datetime
# get the workspace object
ws = Workspace.from_config()
# get the target dataset
target = Dataset.get_by_name(ws, 'target')
# set the baseline dataset
baseline = target.time_before(datetime(2019, 2, 1))
# set up feature list
features = ['latitude', 'longitude', 'elevation', 'windAngle', 'windSpeed', 'temperature', 'snowDepth', 'stationName', 'countryOrRegion']
# set up data drift detector
monitor = DataDriftDetector.create_from_datasets(ws, 'drift-monitor', baseline, target,
compute_target='cpu-cluster',
frequency='Week',
feature_list=None,
drift_threshold=.6,
latency=24)
# get data drift detector by name
monitor = DataDriftDetector.get_by_name(ws, 'drift-monitor')
# update data drift detector
monitor = monitor.update(feature_list=features)
# run a backfill for January through May
backfill1 = monitor.backfill(datetime(2019, 1, 1), datetime(2019, 5, 1))
# run a backfill for May through today
backfill1 = monitor.backfill(datetime(2019, 5, 1), datetime.today())
# disable the pipeline schedule for the data drift detector
monitor = monitor.disable_schedule()
# enable the pipeline schedule for the data drift detector
monitor = monitor.enable_schedule()
Tip
Úplný příklad nastavení detektoru timeseries datových sad a posunů dat najdete v našem ukázkovém poznámkovém bloku.
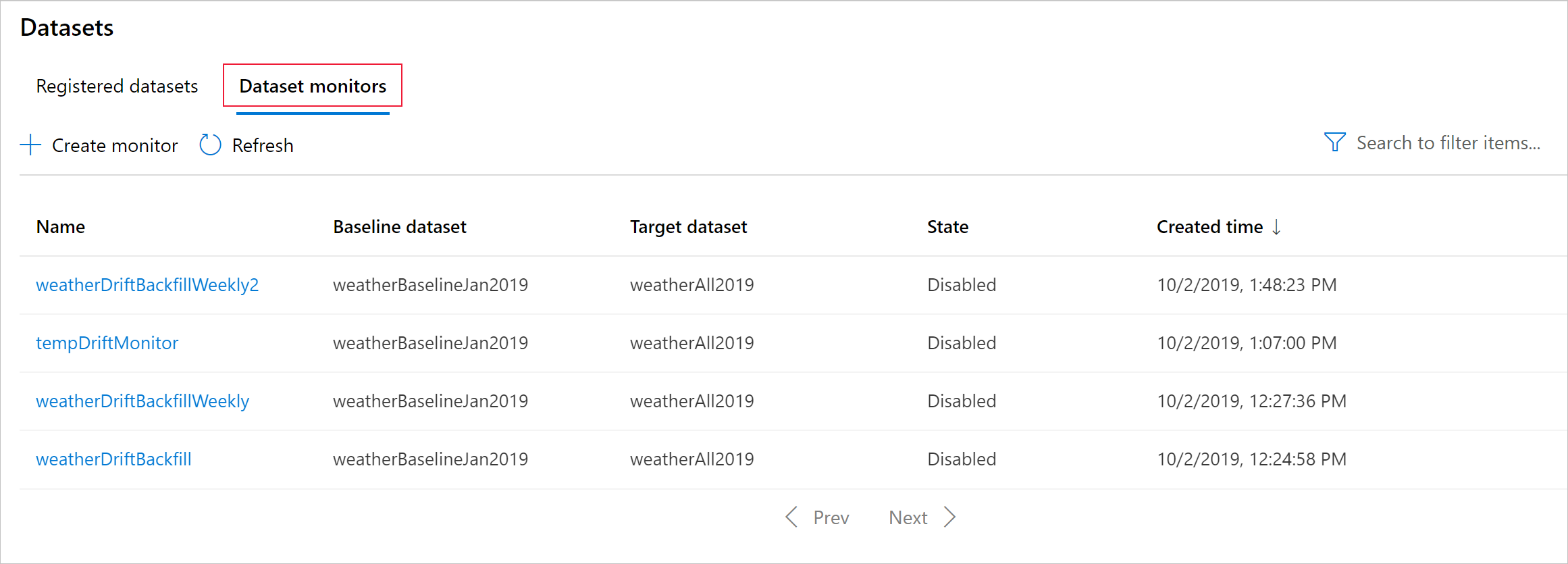
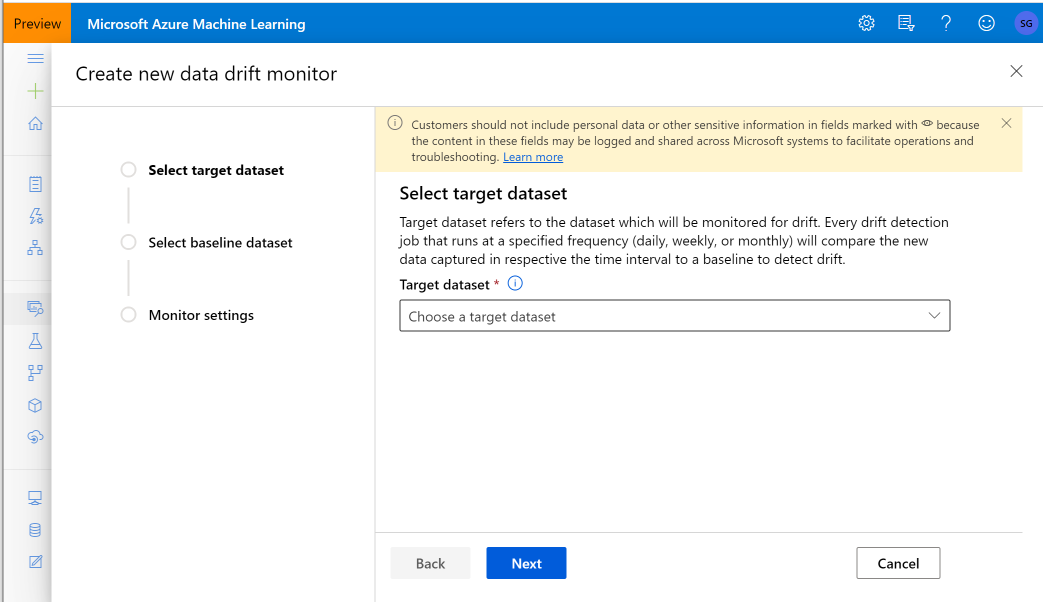
Vytvoření monitorování modelů (migrace na monitorování modelů)
Pokud jste model nasadili do produkčního prostředí v online koncovém bodu služby Azure Machine Learning a povolili shromažďování dat v době nasazení, Azure Machine Learning shromažďuje produkční data odvozování a automaticky je ukládá do služby Microsoft Azure Blob Storage. Pak můžete pomocí monitorování modelu Azure Machine Learning průběžně monitorovat tato produkční data odvozování a můžete přímo zvolit model, který vytvoří cílovou datovou sadu (produkční data odvozování ve službě Monitorování modelů).
Když migrujete na Monitorování modelů, pokud jste model nenasazovali do produkčního prostředí v online koncovém bodu služby Azure Machine Learning nebo nechcete používat shromažďování dat, můžete také nastavit monitorování modelu s využitím vlastních signálů a metrik.
Následující části obsahují další podrobnosti o tom, jak migrovat na Monitorování modelů.
Vytvoření monitorování modelů prostřednictvím automaticky shromážděných produkčních dat (migrace na monitorování modelů)
Pokud jste model nasadili do produkčního prostředí v online koncovém bodu služby Azure Machine Learning a povolili shromažďování dat v době nasazení.
K nastavení připraveného monitorování modelu můžete použít následující kód:
from azure.identity import DefaultAzureCredential
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
AlertNotification,
MonitoringTarget,
MonitorDefinition,
MonitorSchedule,
RecurrencePattern,
RecurrenceTrigger,
ServerlessSparkCompute
)
# get a handle to the workspace
ml_client = MLClient(
DefaultAzureCredential(),
subscription_id="subscription_id",
resource_group_name="resource_group_name",
workspace_name="workspace_name",
)
# create the compute
spark_compute = ServerlessSparkCompute(
instance_type="standard_e4s_v3",
runtime_version="3.3"
)
# specify your online endpoint deployment
monitoring_target = MonitoringTarget(
ml_task="classification",
endpoint_deployment_id="azureml:credit-default:main"
)
# create alert notification object
alert_notification = AlertNotification(
emails=['abc@example.com', 'def@example.com']
)
# create the monitor definition
monitor_definition = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
alert_notification=alert_notification
)
# specify the schedule frequency
recurrence_trigger = RecurrenceTrigger(
frequency="day",
interval=1,
schedule=RecurrencePattern(hours=3, minutes=15)
)
# create the monitor
model_monitor = MonitorSchedule(
name="credit_default_monitor_basic",
trigger=recurrence_trigger,
create_monitor=monitor_definition
)
poller = ml_client.schedules.begin_create_or_update(model_monitor)
created_monitor = poller.result()


Vytvoření monitorování modelu prostřednictvím komponenty předběžného zpracování vlastních dat (migrace na monitorování modelů)
Když migrujete na Monitorování modelů, pokud jste model nenasazovali do produkčního prostředí v online koncovém bodu služby Azure Machine Learning nebo nechcete používat shromažďování dat, můžete také nastavit monitorování modelu s využitím vlastních signálů a metrik.
Pokud nemáte nasazení, ale máte produkční data, můžete je použít k provádění průběžného monitorování modelu. Abyste mohli monitorovat tyto modely, musíte být schopni:
- Shromážděte produkční data odvozování z modelů nasazených v produkčním prostředí.
- Zaregistrujte produkční data odvozování jako datový prostředek služby Azure Machine Learning a zajistěte průběžné aktualizace dat.
- Zadejte vlastní komponentu předběžného zpracování dat a zaregistrujte ji jako komponentu Azure Machine Learning.
Pokud se data neshromažďují s kolektorem dat, musíte zadat vlastní komponentu předběžného zpracování dat. Bez této vlastní komponenty předběžného zpracování dat systém monitorování modelů Azure Machine Learning neví, jak zpracovávat data do tabulkového formuláře s podporou časových intervalů.
Vaše vlastní komponenta předběžného zpracování musí obsahovat tyto vstupní a výstupní podpisy:
| Vstup a výstup | Název podpisu | Typ | Popis | Příklad hodnoty |
|---|---|---|---|---|
| input | data_window_start |
literál, řetězec | data window start-time in ISO8601 format. | 2023-05-01T04:31:57.012Z |
| input | data_window_end |
literál, řetězec | data window end-time in ISO8601 format. | 2023-05-01T04:31:57.012Z |
| input | input_data |
uri_folder | Shromážděná produkční data odvozování, která jsou zaregistrovaná jako datový prostředek služby Azure Machine Learning. | azureml:myproduction_inference_data:1 |
| output | preprocessed_data |
mltable | Tabulková datová sada, která odpovídá podmnožině schématu referenčních dat. |
Příklad vlastní komponenty předběžného zpracování dat najdete v custom_preprocessing v úložišti Azuremml-examples Na GitHubu.
Vysvětlení výsledků posunu dat
Tato část ukazuje výsledky monitorování datové sady, které najdete na stránce Monitorování datových sad datových / sad v Nástroji Azure Studio. Nastavení můžete aktualizovat a analyzovat existující data pro určité časové období na této stránce.
Začněte přehledy nejvyšší úrovně o rozsahu posunu dat a zvýrazněním funkcí, které je potřeba dále prozkoumat.
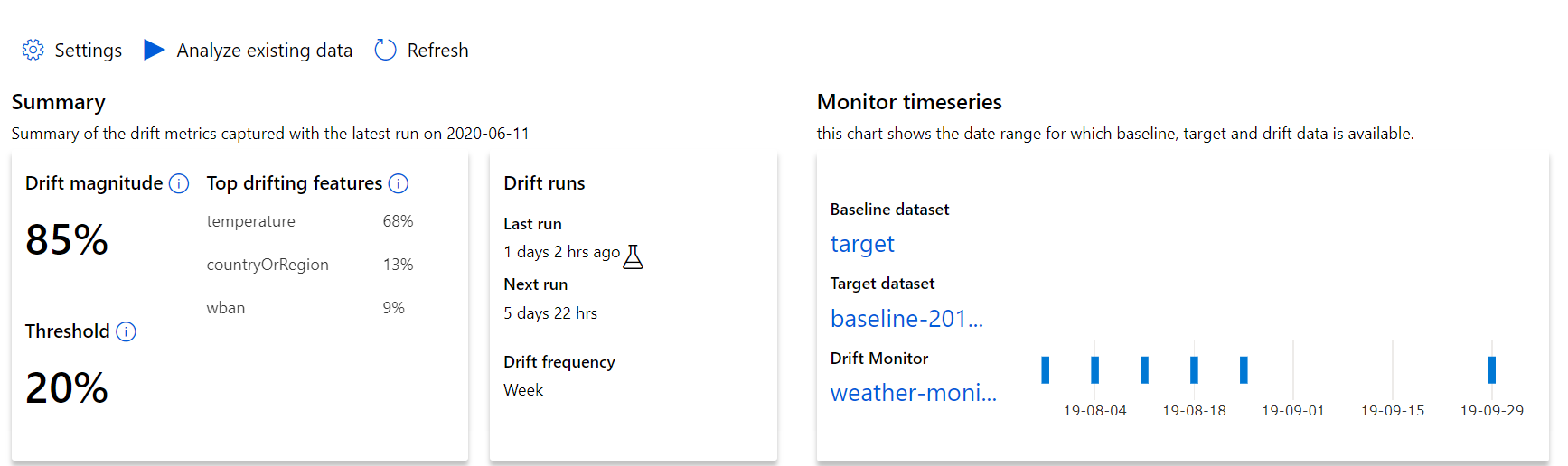
| Metrický | Popis |
|---|---|
| Velikost posunu dat | Procento posunu mezi směrnými hodnotami a cílovou datovou sadou v průběhu času. Toto procento se pohybuje od 0 do 100, 0 označuje identické datové sady a 100 indikuje, že model posunu dat Ve službě Azure Machine Learning dokáže tyto dvě datové sady úplně od sebe oddělit. Vzhledem k tomu, že se k vygenerování této velikosti používá techniky strojového učení, se očekává šum v přesném procentu. |
| Hlavní funkce posunu | Zobrazuje funkce z datové sady, u kterých došlo k posunu nejvíce, a proto přispívají nejvíce k metrice Drift Magnitude. Z důvodu kovariantního posunu nemusí základní distribuce funkce nutně měnit, aby měla relativně vysokou důležitost funkce. |
| Prahová hodnota | Velikost posunu dat nad rámec nastavené prahové hodnoty aktivuje upozornění. Nakonfigurujte prahovou hodnotu v nastavení monitorování. |
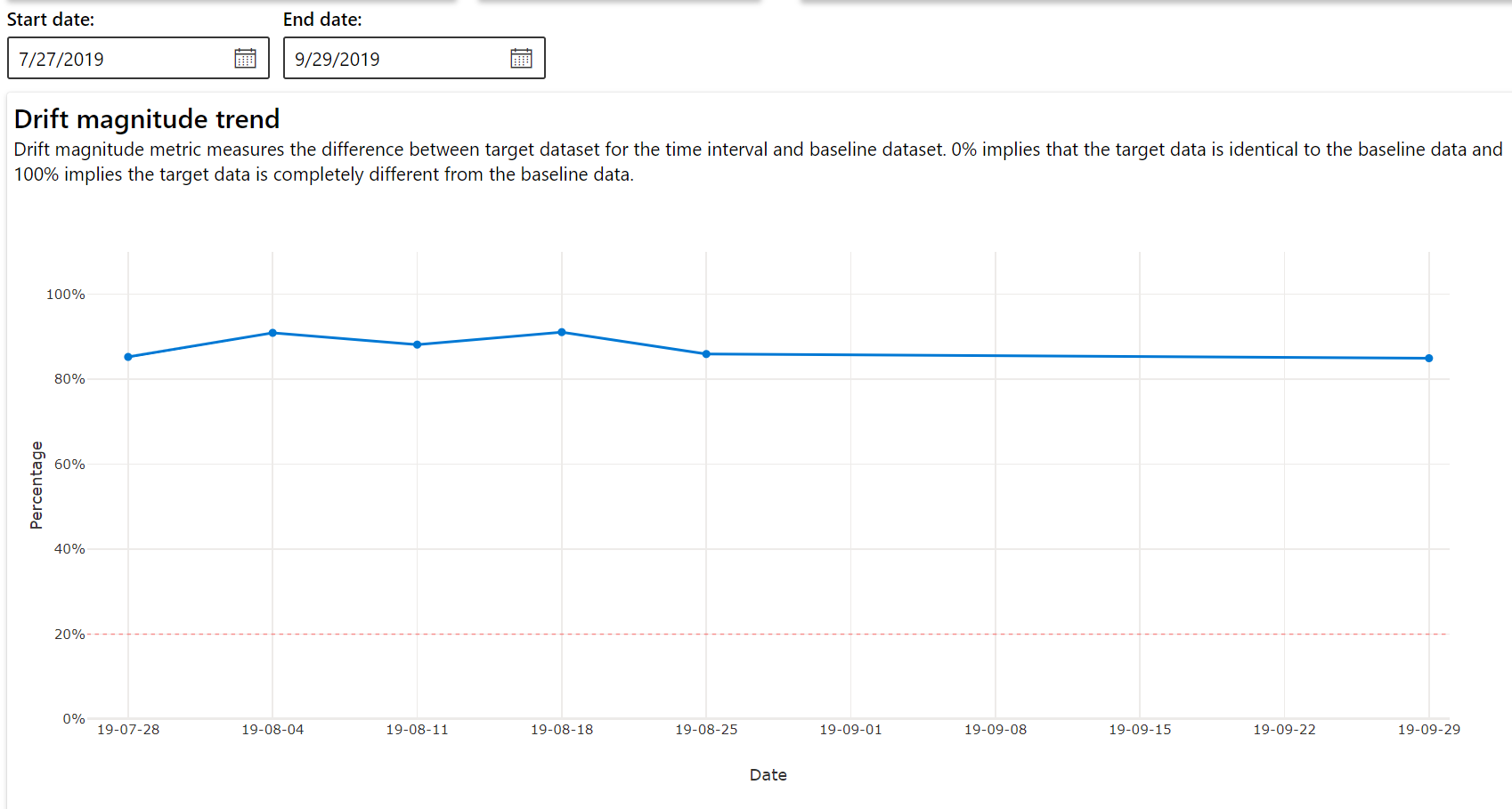
Trend posunu velikosti
Podívejte se, jak se datová sada liší od cílové datové sady v zadaném časovém období. Čím blíž k 100 %, tím více se obě datové sady liší.
Velikost posunu podle funkcí
Tato část obsahuje přehledy na úrovni funkcí o změně v distribuci vybrané funkce a dalších statistikách v průběhu času.
Cílová datová sada se také profiluje v průběhu času. Statistická vzdálenost mezi rozdělením jednotlivých funkcí podle směrného plánu se porovnává s cílovou datovou sadou v průběhu času. Koncepčně se to podobá velikosti posunu dat. Tato statistická vzdálenost je ale určená pro jednotlivé funkce, nikoli pro všechny funkce. K dispozici jsou také minimální, maximální a střední hodnoty.
V studio Azure Machine Learning vyberte pruh v grafu, abyste zobrazili podrobnosti na úrovni funkcí pro dané datum. Ve výchozím nastavení uvidíte distribuci základní datové sady a distribuci poslední úlohy stejné funkce.
Tyto metriky je také možné načíst v sadě Python SDK prostřednictvím get_metrics() metody objektu DataDriftDetector .
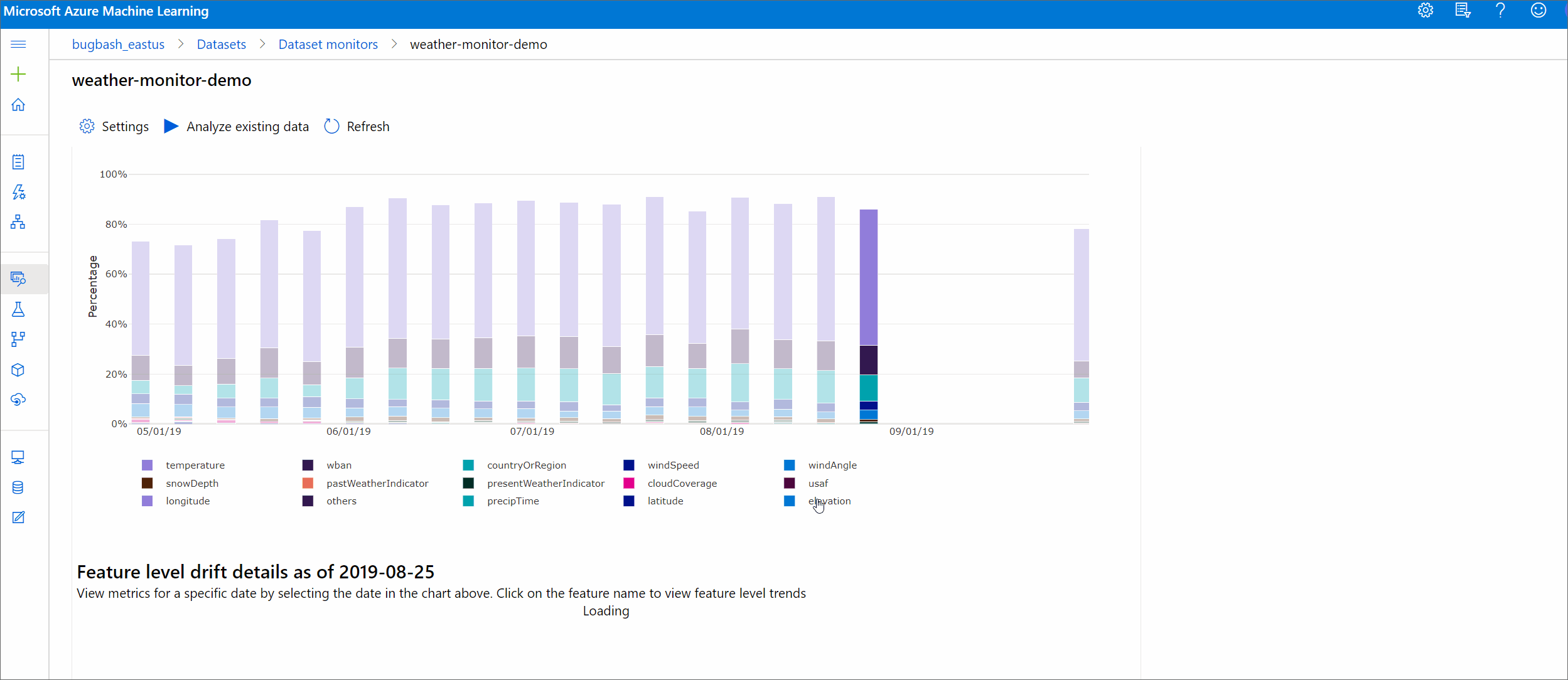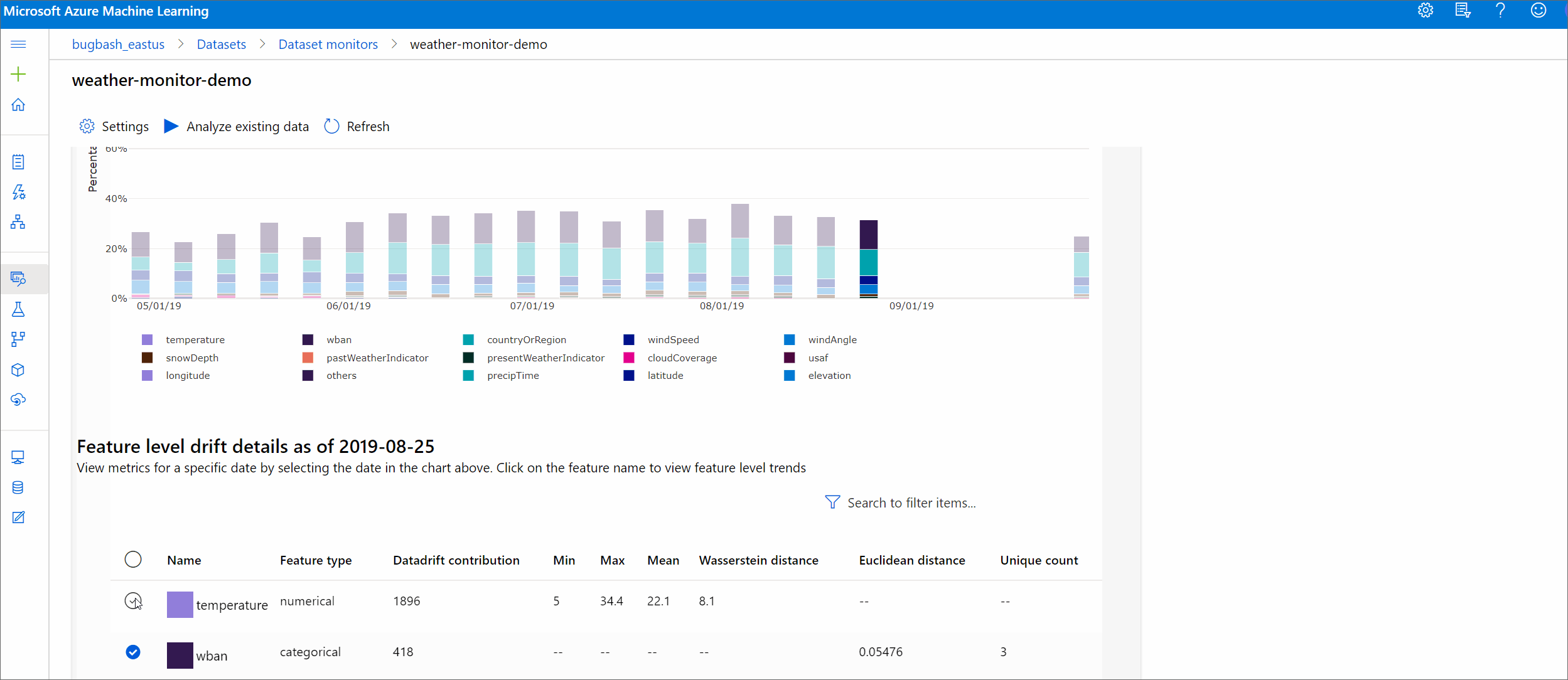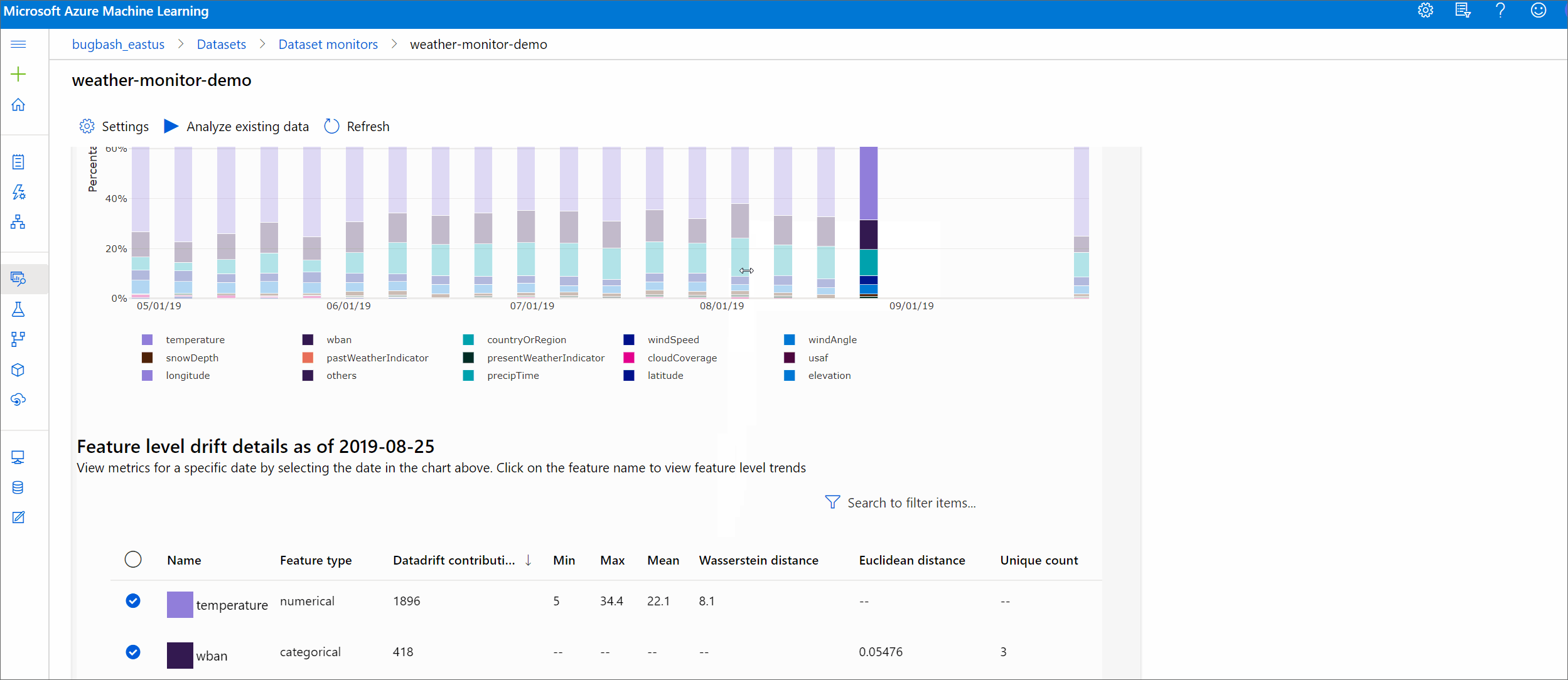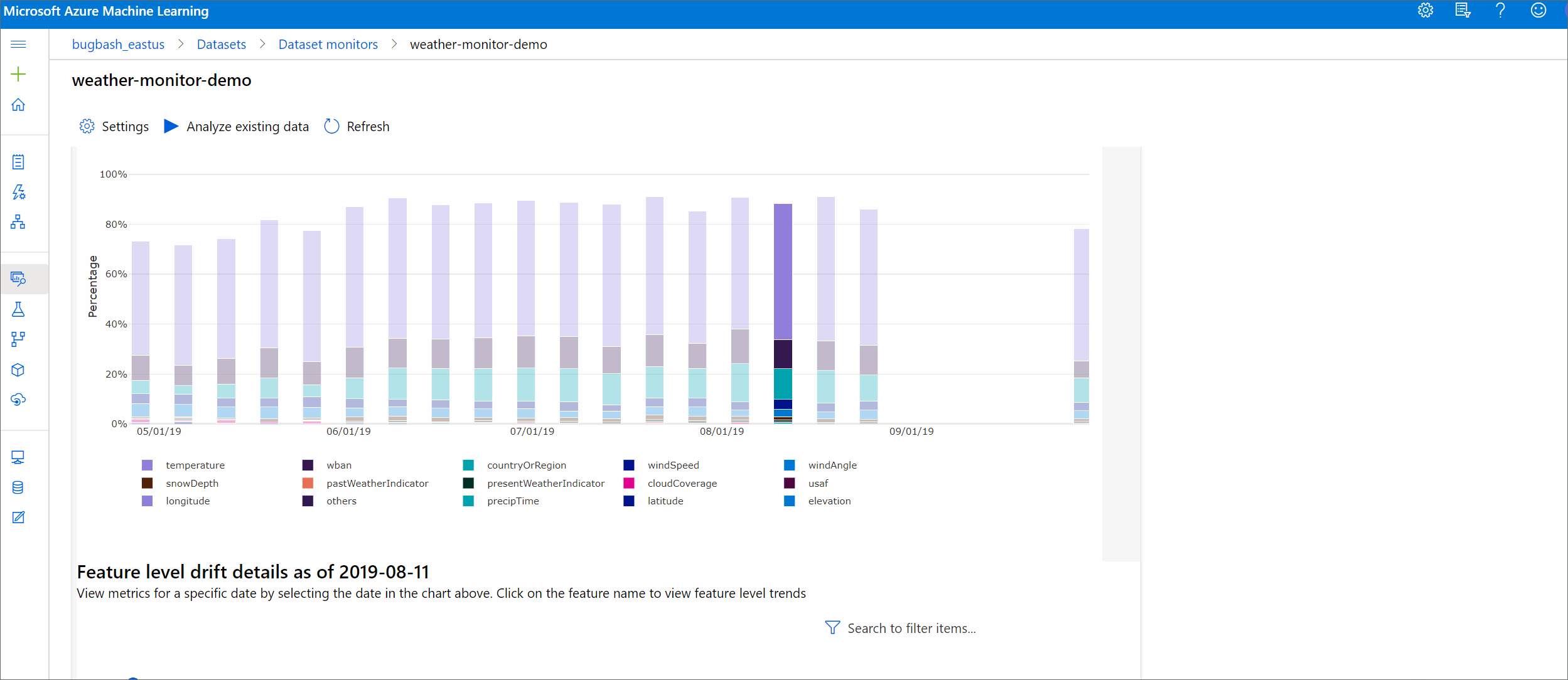
Podrobnosti funkce
Nakonec se posuňte dolů, abyste zobrazili podrobnosti o jednotlivých funkcích. Pomocí rozevíracích polí nad grafem tuto funkci vyberte a dále vyberte metriku, kterou chcete zobrazit.
Metriky v grafu závisí na typu funkce.
Číselné funkce
Metrický Popis Wasserstein vzdálenost Minimální množství práce pro transformaci směrného rozdělení na cílovou distribuci Střední hodnota Průměrná hodnota funkce Min. hodnota Minimální hodnota funkce. Max. hodnota Maximální hodnota funkce Kategorické funkce
Metrický Popis Euklidská vzdálenost Vypočítá se pro sloupce kategorií. Euklidská vzdálenost se vypočítá na dvou vektorech vygenerovaných z empirického rozdělení stejného sloupce kategorií ze dvou datových sad. 0 značí žádný rozdíl v empirických rozděleních. Čím více se liší od hodnoty 0, tím více se tento sloupec posune. Trendy se dají pozorovat z časového řady grafu této metriky a můžou být užitečné při odhalení funkce posunu. Jedinečné hodnoty Počet jedinečných hodnot (kardinality) funkce
V tomto grafu vyberte jedno datum a porovnejte rozdělení funkcí mezi cílem a tímto datem pro zobrazenou funkci. U číselných funkcí se zobrazí dvě rozdělení pravděpodobnosti. Pokud je tato funkce číselná, zobrazí se pruhový graf.
Metriky, výstrahy a události
Metriky se dají dotazovat v prostředku Aplikace Azure lication Insights přidruženém k vašemu pracovnímu prostoru strojového učení. Máte přístup ke všem funkcím Application Insights, včetně nastavení vlastních pravidel upozornění a skupin akcí pro aktivaci akce, jako je e-mail, SMS, nabízení nebo hlas nebo funkce Azure Functions. Podrobnosti najdete v kompletní dokumentaci k Application Insights.
Začněte tím, že přejdete na web Azure Portal a vyberete stránku Přehled pracovního prostoru. Přidružený prostředek Application Insights je úplně vpravo:

V levém podokně vyberte Protokoly (Analytics):
Metriky monitorování datové sady se ukládají jako customMetrics. Po nastavení monitorování datové sady můžete napsat a spustit dotaz, abyste je mohli zobrazit:

Po identifikaci metrik pro nastavení pravidel upozornění vytvořte nové pravidlo upozornění:
Můžete použít existující skupinu akcí nebo vytvořit novou k definování akce, která se má provést při splnění nastavených podmínek:
Řešení problému
Omezení a známé problémy monitorování odchylek dat:
Časový rozsah při analýze historických dat je omezen na 31 intervalů nastavení frekvence monitorování.
Omezení 200 funkcí, pokud není zadaný seznam funkcí (všechny použité funkce).
Velikost výpočetních prostředků musí být dostatečně velká pro zpracování dat.
Ujistěte se, že vaše datová sada obsahuje data v počátečním a koncovém datu dané úlohy monitorování.
Monitorování datových sad funguje jenom na datových sadách, které obsahují 50 řádků nebo více.
Sloupce nebo funkce v datové sadě jsou klasifikovány jako kategorické nebo číselné na základě podmínek v následující tabulce. Pokud funkce tyto podmínky nesplňuje – například sloupec řetězce typu s 100 jedinečnými >hodnotami – funkce se zahodí z našeho algoritmu posunu dat, ale přesto je profilovaná.
Typ funkce Datový typ Podmínka Omezení Kategorické string Počet jedinečných hodnot ve funkci je menší než 100 a menší než 5 % počtu řádků. Hodnota Null je považována za svou vlastní kategorii. Číselný int, float Hodnoty v této funkci jsou číselného datového typu a nesplňují podmínku pro kategorickou funkci. Funkce se zahodila, pokud >má 15 % hodnot hodnotu null. Když jste vytvořili monitorování odchylek dat, ale na stránce Monitorování datových sad v studio Azure Machine Learning nevidíte data, zkuste následující postup.
- Zkontrolujte, jestli jste v horní části stránky vybrali správný rozsah kalendářních dat.
- Na kartě Monitorování datových sad vyberte odkaz experimentu a zkontrolujte stav úlohy. Tento odkaz je na pravé straně tabulky.
- Pokud se úloha úspěšně dokončila, zkontrolujte protokoly ovladačů a zjistěte, kolik metrik se vygenerovalo nebo jestli se zobrazily nějaké zprávy s upozorněním. Po výběru experimentu vyhledejte protokoly ovladačů na kartě Výstup a protokoly .
Pokud funkce SADY SDK
backfill()negeneruje očekávaný výstup, může to být kvůli problému s ověřováním. Při vytváření výpočetních prostředků, které se mají předat této funkci, nepoužívejteRun.get_context().experiment.workspace.compute_targets. Místo toho pomocí servicePrincipalAuthentication , jako je například následující, vytvořte výpočetní prostředky, které předáváte do tétobackfill()funkce:
Poznámka:
Nezakódujte v kódu heslo instančního objektu. Místo toho ho načtěte z prostředí Pythonu, úložiště klíčů nebo jiné zabezpečené metody přístupu k tajným kódům.
auth = ServicePrincipalAuthentication(
tenant_id=tenant_id,
service_principal_id=app_id,
service_principal_password=client_secret
)
ws = Workspace.get("xxx", auth=auth, subscription_id="xxx", resource_group="xxx")
compute = ws.compute_targets.get("xxx")
V kolekci dat modelu může trvat až 10 minut, než data dorazí do vašeho účtu úložiště objektů blob. Obvykle ale trvá kratší dobu. Ve skriptu nebo poznámkovém bloku počkejte 10 minut, abyste zajistili úspěšné spuštění následujících buněk.
import time time.sleep(600)
Další kroky
- Přejděte do studio Azure Machine Learning nebo poznámkového bloku Pythonu a nastavte monitorování datové sady.
- Podívejte se, jak nastavit posun dat u modelů nasazených ve službě Azure Kubernetes Service.
- Nastavení monitorování posunu datových sad pomocí služby Azure Event Grid