Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)Python SDK azure-ai-ml v2 (aktuální)
Rozšíření Azure CLI ml v2 (aktuální)Python SDK azure-ai-ml v2 (aktuální)
Ve službě Azure Machine Learning můžete pomocí monitorování modelů průběžně sledovat výkon modelů strojového učení v produkčním prostředí. Monitorování modelů poskytuje široký pohled na monitorovací signály. Upozorní vás také na potenciální problémy. Když monitorujete signály a metriky výkonu modelů v produkčním prostředí, můžete kriticky vyhodnotit základní rizika vašich modelů. Můžete také identifikovat slepé skvrny, které by mohly nepříznivě ovlivnit vaši firmu.
V tomto článku se dozvíte, jak provádět následující úlohy:
- Nastavení předkonfigurovaného a pokročilého monitorování pro modely nasazené do online koncových bodů platform služby Azure Machine Learning
- Monitorování metrik výkonu pro modely v produkčním prostředí
- Monitorování modelů nasazených mimo Azure Machine Learning nebo nasazených do dávkových koncových bodů služby Azure Machine Learning
- Nastavení vlastních signálů a metrik pro použití při monitorování modelů
- Interpretace výsledků monitorování
- Integrace monitorování modelu Azure Machine Learning s Azure Event Gridem
Požadavky
Azure CLI a
mlrozšíření na Azure CLI, nainstalované a nakonfigurované. Další informace najdete v tématu Instalace a nastavení rozhraní příkazového řádku (v2).Prostředí Bash nebo kompatibilní prostředí, například prostředí v systému Linux nebo subsystému Windows pro Linux. Příklady Azure CLI v tomto článku předpokládají, že používáte tento typ shellu.
Pracovní prostor služby Azure Machine Learning. Pokyny k vytvoření pracovního prostoru najdete v tématu Nastavení.
Uživatelský účet, který má alespoň jednu z následujících rolí řízení přístupu na základě role v Azure (Azure RBAC):
- Role Vlastník pro pracovní prostor Azure Machine Learning
- Role Přispěvatel pro pracovní prostor Azure Machine Learning
- Vlastní role s
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*oprávněními
Další informace najdete v tématu Správa přístupu k pracovním prostorům Azure Machine Learning.
Monitorování online koncového bodu spravovaného službou Azure Machine Learning nebo online koncového bodu Kubernetes:
Model, který je nasazený do online koncového bodu služby Azure Machine Learning Podporují se spravované online koncové body a online koncové body Kubernetes. Pokyny k nasazení modelu do online koncového bodu služby Azure Machine Learning najdete v tématu Nasazení a hodnocení modelu strojového učení pomocí online koncového bodu.
Bylo povoleno shromažďování dat pro nasazení modelu. Shromažďování dat můžete povolit během kroku nasazení pro online koncové body služby Azure Machine Learning. Další informace najdete v tématu Shromažďování produkčních dat z modelů nasazených pro odvozování v reálném čase.
Monitorování modelu nasazeného do dávkového koncového bodu služby Azure Machine Learning nebo nasazeného mimo Azure Machine Learning:
- Prostředek pro shromažďování produkčních dat a jejich registraci jako datového assetu služby Azure Machine Learning
- Prostředek pro průběžné aktualizace registrovaného datového prostředku pro monitorování modelů
- (Doporučeno) Registrace modelu v pracovním prostoru Azure Machine Learning pro sledování rodokmenu
Konfigurace bezserverového výpočetního fondu Sparku
Úlohy monitorování modelů se plánují tak, aby běžely na bezserverových výpočetních fondech Sparku. Podporují se následující typy instancí virtuálních počítačů Azure:
- Standard_E4s_v3
- Standard_E8s_v3
- Standard_E16s_v3
- Standard_E32s_v3
- Standard_E64s_v3
Pokud chcete zadat typ instance virtuálního počítače, když budete postupovat podle postupů v tomto článku, postupujte takto:
Když k vytvoření monitorování použijete Azure CLI, použijete konfigurační soubor YAML. V daném souboru nastavte create_monitor.compute.instance_type hodnotu na typ, který chcete použít.
Nastavení připraveného monitorování modelů
Představte si scénář, ve kterém nasadíte model do produkčního prostředí v online koncovém bodu služby Azure Machine Learning a povolíte shromažďování dat v době nasazení. V tomto případě Azure Machine Learning shromažďuje produkční data odvozování a automaticky je ukládá do služby Azure Blob Storage. Monitorování modelu Azure Machine Learning můžete použít k nepřetržitému monitorování těchto produkčních dat odvozování.
K předběžnému nastavení monitorování modelů můžete použít Azure CLI, Sadu Python SDK nebo studio. Předefinovaná konfigurace monitorování modelu poskytuje následující možnosti monitorování:
- Azure Machine Learning automaticky rozpozná produkční datový prostředek odvozování, který je přidružený k online nasazení služby Azure Machine Learning, a použije datový asset pro monitorování modelu.
- Referenční datový asset porovnání je nastaven jako nedávný, minulý produkční odvozovací datový prostředek.
- Nastavení monitorování automaticky zahrnuje a sleduje následující integrované monitorovací signály: posun dat, posun předpovědi a kvalitu dat. Pro každý signál monitorování azure Machine Learning používá:
- Nedávný, minulý produkční odvozování datového assetu jako referenční referenční datový prostředek porovnání.
- Inteligentní výchozí hodnoty pro metriky a prahové hodnoty
- Úloha monitorování je nakonfigurovaná tak, aby běžela podle běžného plánu. Tato úloha získává monitorovací signály a vyhodnocuje každý výsledek metriky s odpovídající prahovou hodnotou. Když dojde k překročení jakékoli prahové hodnoty, Azure Machine Learning ve výchozím nastavení pošle uživateli, který monitor nastavil, e-mail s upozorněním.
Pokud chcete nastavit připravené monitorování modelu, proveďte následující kroky.
V Azure CLI použijete az ml schedule, abyste naplánovali úlohu monitorování.
Vytvořte definici monitorování v souboru YAML. Ukázkovou předem připravenou definici najdete v následujícím kódu YAML, který je k dispozici také v úložišti azureml-examples.
Před použitím této definice upravte hodnoty tak, aby vyhovovaly vašemu prostředí. Pro
endpoint_deployment_id, použít hodnotu ve formátuazureml:<endpoint-name>:<deployment-name>.# out-of-box-monitoring.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: credit_default_model_monitoring display_name: Credit default model monitoring description: Credit default model monitoring setup with minimal configurations trigger: # perform model monitoring activity daily at 3:15am type: recurrence frequency: day #can be minute, hour, day, week, month interval: 1 # #every day schedule: hours: 3 # at 3am minutes: 15 # at 15 mins after 3am create_monitor: compute: # specify a spark compute for monitoring job instance_type: standard_e4s_v3 runtime_version: "3.4" monitoring_target: ml_task: classification # model task type: [classification, regression, question_answering] endpoint_deployment_id: azureml:credit-default:main # azureml endpoint deployment id alert_notification: # emails to get alerts emails: - abc@example.com - def@example.comSpuštěním následujícího příkazu vytvořte model:
az ml schedule create -f ./out-of-box-monitoring.yaml


Nastavení rozšířeného monitorování modelů
Azure Machine Learning poskytuje mnoho funkcí pro průběžné monitorování modelů. Úplný seznam těchto funkcí najdete v tématu Možnosti monitorování modelů. V mnoha případech je potřeba nastavit monitorování modelu, které podporuje pokročilé úlohy monitorování. Následující část obsahuje několik příkladů pokročilého monitorování:
- Použití více monitorovacích signálů pro široké zobrazení
- Použití historických trénovacích dat modelu nebo ověřovacích dat jako referenčního datového prostředku porovnání
- Monitorování nejdůležitějších funkcí N a jednotlivých funkcí
Konfigurace důležitosti funkcí
Důležitost funkce představuje relativní důležitost jednotlivých vstupních funkcí pro výstup modelu. Například teplota může být pro předpověď modelu důležitější než zvýšení. Když zapnete důležitost funkcí, můžete získat přehled o funkcích, které nechcete v produkčním prostředí používat nebo které mají problémy s kvalitou dat.
Pokud chcete zapnout důležitost funkce u jakéhokoli signálu, jako je posun dat nebo kvalita dat, musíte zadat:
- Váš tréninkový datový prostředek jako
reference_datadatový prostředek. - Vlastnost
reference_data.data_column_names.target_column, což je název výstupního sloupce modelu nebo prediktivního sloupce.
Po zapnutí důležitosti funkcí uvidíte důležitost funkcí pro každou funkci, kterou monitorujete v nástroji Azure Machine Learning Studio.
Upozornění můžete zapnout nebo vypnout pro každý signál nastavením alert_enabled vlastnosti při použití sady Python SDK nebo Azure CLI.
K nastavení pokročilého monitorování modelů můžete použít Azure CLI, Sadu Python SDK nebo studio.
Vytvořte definici monitorování v souboru YAML. Ukázkovou pokročilou definici najdete v následujícím kódu YAML, který je k dispozici také v úložišti azureml-examples.
Před použitím této definice upravte následující nastavení a všechny ostatní tak, aby vyhovovaly potřebám vašeho prostředí:
- Pro
endpoint_deployment_id, použít hodnotu ve formátuazureml:<endpoint-name>:<deployment-name>. - Pro
pathv referenčních vstupních datových oddílech použijte hodnotu ve formátuazureml:<reference-data-asset-name>:<version>. - Použijte
target_columnnázev výstupního sloupce, který obsahuje hodnoty, které model predikuje, napříkladDEFAULT_NEXT_MONTH. - Seznamte si funkce, jako je
features,SEXaEDUCATION, které chcete použít v rozšířeném signálu kvality dat proAGE. - V části
emailsUveďte e-mailové adresy, které chcete použít pro oznámení.
# advanced-model-monitoring.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: fraud_detection_model_monitoring display_name: Fraud detection model monitoring description: Fraud detection model monitoring with advanced configurations trigger: # perform model monitoring activity daily at 3:15am type: recurrence frequency: day #can be minute, hour, day, week, month interval: 1 # #every day schedule: hours: 3 # at 3am minutes: 15 # at 15 mins after 3am create_monitor: compute: instance_type: standard_e4s_v3 runtime_version: "3.4" monitoring_target: ml_task: classification endpoint_deployment_id: azureml:credit-default:main monitoring_signals: advanced_data_drift: # monitoring signal name, any user defined name works type: data_drift # reference_dataset is optional. By default referece_dataset is the production inference data associated with Azure Machine Learning online endpoint reference_data: input_data: path: azureml:credit-reference:1 # use training data as comparison reference dataset type: mltable data_context: training data_column_names: target_column: DEFAULT_NEXT_MONTH features: top_n_feature_importance: 10 # monitor drift for top 10 features alert_enabled: true metric_thresholds: numerical: jensen_shannon_distance: 0.01 categorical: pearsons_chi_squared_test: 0.02 advanced_data_quality: type: data_quality # reference_dataset is optional. By default reference_dataset is the production inference data associated with Azure Machine Learning online endpoint reference_data: input_data: path: azureml:credit-reference:1 type: mltable data_context: training features: # monitor data quality for 3 individual features only - SEX - EDUCATION alert_enabled: true metric_thresholds: numerical: null_value_rate: 0.05 categorical: out_of_bounds_rate: 0.03 feature_attribution_drift_signal: type: feature_attribution_drift # production_data: is not required input here # Please ensure Azure Machine Learning online endpoint is enabled to collected both model_inputs and model_outputs data # Azure Machine Learning model monitoring will automatically join both model_inputs and model_outputs data and used it for computation reference_data: input_data: path: azureml:credit-reference:1 type: mltable data_context: training data_column_names: target_column: DEFAULT_NEXT_MONTH alert_enabled: true metric_thresholds: normalized_discounted_cumulative_gain: 0.9 alert_notification: emails: - abc@example.com - def@example.com- Pro
Spuštěním následujícího příkazu vytvořte model:
az ml schedule create -f ./advanced-model-monitoring.yaml






Nastavení monitorování výkonu modelu
Při použití monitorování modelů Azure Machine Learning můžete sledovat výkon modelů v produkčním prostředí pomocí výpočtu jejich metrik výkonu. Aktuálně se podporují následující metriky výkonu modelu:
- Klasifikační modely:
- Počet deset. míst
- Přesnost
- Odvolat
- Pro regresní modely:
- Střední absolutní chyba (MAE)
- Střední kvadratická chyba (MSE)
- Odmocněná střední kvadratická chyba (RMSE)
Požadavky pro monitorování výkonu modelu
Výstupní data pro produkční model (předpovědi modelu) s jedinečným ID pro každý řádek. Pokud ke shromažďování produkčních dat použijete kolektor dat Azure Machine Learning, je pro každý požadavek na odvozování poskytováno ID korelace. Kolektor dat také nabízí možnost protokolování vlastního jedinečného ID z vaší aplikace.
Poznámka:
Pro monitorování výkonu modelu Azure Machine Learning doporučujeme použít kolektor dat Azure Machine Learning k logování jedinečného ID ve vlastním sloupci.
Základní pravdivá data (skutečné hodnoty) s jedinečným ID pro každý řádek. Jedinečné ID pro daný řádek by se mělo shodovat s jedinečným ID pro výstupní data modelu pro konkrétní požadavek odvození. Toto jedinečné ID slouží ke spojení referenčních dat s výstupními daty modelu.
Pokud nemáte základní pravdivá data, nemůžete provádět monitorování výkonu modelu. Základní pravdivá data jsou zjištěna na úrovni aplikace, takže je vaší zodpovědností je shromáždit, jakmile budou k dispozici. Měli byste také udržovat datový prostředek ve službě Azure Machine Learning, který obsahuje tato základní pravdivá data.
(Volitelné) Předem sloučený tabulkový datový soubor s výstupními daty modelu a skutečnými daty, která jsou už spojena.
Požadavky na monitorování výkonu modelu při použití kolektoru dat
Azure Machine Learning pro vás vygeneruje ID korelace, když splňujete následující kritéria:
- Azure Machine Learning datový nástroj použijete ke sběru produkčních dat pro analýzu.
- Neposkytujete pro každý řádek jedinečné ID jako samostatný sloupec.
Vygenerované ID korelace je součástí zaprotokolovaného objektu JSON. Kolekce dat však shromažďuje řádky, které jsou odesílány v krátkých časových intervalech mezi sebou. Dávkové řádky spadají do stejného objektu JSON. V každém objektu mají všechny řádky stejné ID korelace.
K rozlišení řádků v objektu JSON používá monitorování výkonu modelu Azure Machine Learning indexování k určení pořadí řádků v objektu. Pokud například dávka obsahuje tři řádky a ID korelace je test, první řádek má ID test_0, druhý řádek má ID test_1a třetí řádek má ID test_2. Pokud chcete spárovat jedinečné ID datového prostředku základní pravdy s ID vašich výstupních dat modelu odvozování v produkčním prostředí, odpovídajícím způsobem použijte index na každé ID korelace. Pokud má protokolovaný objekt JSON jenom jeden řádek, použijte correlationid_0 jako correlationid hodnotu.
Pokud se chcete vyhnout použití tohoto indexování, doporučujeme zaznamenat jedinečné ID do vlastního sloupce. Vložte tento sloupec do datového rámce pandas, který protokoly kolektoru dat služby Azure Machine Learning . V konfiguraci monitorování modelu pak můžete zadat název tohoto sloupce, který spojí výstupní data modelu s vašimi základními pravdivými daty. Pokud jsou ID každého řádku v obou datových prostředcích stejná, může monitorování modelu Azure Machine Learning provádět monitorování výkonu modelu.
Příklad pracovního postupu monitorování výkonu modelu
Abyste porozuměli konceptům přidruženým k monitorování výkonu modelu, zvažte následující ukázkový pracovní postup. Platí pro scénář, ve kterém nasadíte model, abyste mohli předpovědět, jestli jsou transakce platební karty podvodné:
- Nakonfigurujte nasazení tak, aby používalo kolektor dat ke shromažďování produkčních dat odvozování modelu (vstupní a výstupní data). Uložte výstupní data do sloupce s názvem
is_fraud. - Pro každý řádek shromážděných dat odvozování zapište jedinečné ID. Jedinečné ID může pocházet z vaší aplikace nebo můžete použít
correlationidhodnotu, kterou Azure Machine Learning jedinečně vygeneruje pro každý protokolovaný objekt JSON. - Pokud jsou k dispozici základní pravdivá (nebo skutečná)
is_frauddata, zaznamenejte a přiřaďte každý řádek ke stejnému jedinečnému ID, které je zaznamenáno pro odpovídající řádek ve výstupních datech modelu. - Zaregistrujte datový prostředek ve službě Azure Machine Learning a použijte ho ke shromažďování a správě základních pravdivých
is_frauddat. - Vytvořte signál monitorování výkonu modelu, který pomocí jedinečných sloupců ID spojí produkční odvozování modelu a podkladové datové prostředky pravdivých informací.
- Vypočítá metriky výkonu modelu.
Jakmile splníte požadavky na monitorování výkonu modelu, nastavte monitorování modelu následujícím postupem:
Vytvořte definici monitorování v souboru YAML. Následující ukázková specifikace definuje monitorování modelu s daty odvozování produkčního prostředí. Před použitím této definice upravte následující nastavení a všechny ostatní tak, aby vyhovovaly potřebám vašeho prostředí:
- Pro
endpoint_deployment_id, použít hodnotu ve formátuazureml:<endpoint-name>:<deployment-name>. - Pro každou
pathhodnotu v oddílu vstupních dat použijte hodnotu ve formátuazureml:<data-asset-name>:<version>. -
predictionJako hodnotu použijte název výstupního sloupce, který obsahuje hodnoty, které model predikuje. -
actualPro tuto hodnotu použijte název základního sloupce pravdy, který obsahuje skutečné hodnoty, které se model snaží předpovědět. -
correlation_idPro hodnoty použijte názvy sloupců, které se používají ke spojení výstupních dat a podkladových pravdivých dat. - V části
emailsUveďte e-mailové adresy, které chcete použít pro oznámení.
# model-performance-monitoring.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: model_performance_monitoring display_name: Credit card fraud model performance description: Credit card fraud model performance trigger: type: recurrence frequency: day interval: 7 schedule: hours: 10 minutes: 15 create_monitor: compute: instance_type: standard_e8s_v3 runtime_version: "3.3" monitoring_target: ml_task: classification endpoint_deployment_id: azureml:loan-approval-endpoint:loan-approval-deployment monitoring_signals: fraud_detection_model_performance: type: model_performance production_data: input_data: path: azureml:credit-default-main-model_outputs:1 type: mltable data_column_names: prediction: is_fraud correlation_id: correlation_id reference_data: input_data: path: azureml:my_model_ground_truth_data:1 type: mltable data_column_names: actual: is_fraud correlation_id: correlation_id data_context: ground_truth alert_enabled: true metric_thresholds: tabular_classification: accuracy: 0.95 precision: 0.8 alert_notification: emails: - abc@example.com- Pro
Spuštěním následujícího příkazu vytvořte model:
az ml schedule create -f ./model-performance-monitoring.yaml





Nastavení monitorování modelů produkčních dat
Můžete také monitorovat modely, které nasadíte do dávkových koncových bodů služby Azure Machine Learning nebo které nasadíte mimo Azure Machine Learning. Pokud nemáte nasazení, ale máte produkční data, můžete je použít k provádění průběžného monitorování modelu. Abyste mohli monitorovat tyto modely, musíte být schopni:
- Shromážděte produkční data odvozování z modelů nasazených v produkčním prostředí.
- Zaregistrujte produkční data odvozování jako datový prostředek služby Azure Machine Learning a zajistěte průběžné aktualizace dat.
- Pokud ke shromažďování dat nepoužíváte kolektor dat , zadejte vlastní komponentu předběžného zpracování dat a zaregistrujte ji jako komponentu Azure Machine Learning. Bez této vlastní komponenty předběžného zpracování dat nemůže systém monitorování modelů Azure Machine Learning zpracovávat data do tabulkového formuláře, který podporuje časové intervaly.
Vlastní komponenta předběžného zpracování musí obsahovat následující vstupní a výstupní podpisy:
| Vstup nebo výstup | Název podpisu | Typ | Popis | Příklad hodnoty |
|---|---|---|---|---|
| vstup | data_window_start |
literál, řetězec | Čas spuštění okna dat ve formátu ISO8601 | 2023-05-01T04:31:57.012Z |
| vstup | data_window_end |
literál, řetězec | Koncový čas okna dat ve formátu ISO8601 | 2023-05-01T04:31:57.012Z |
| vstup | input_data |
uri_folder | Shromážděná produkční data odvozování, která jsou zaregistrovaná jako datový prostředek služby Azure Machine Learning | azureml:myproduction_inference_data:1 |
| výstup | preprocessed_data |
mltable | Tabulkový datový prostředek, který odpovídá podmnožině schématu referenčních dat |
Příklad vlastní komponenty předběžného zpracování dat najdete v custom_preprocessing v úložišti Azuremml-examples Na GitHubu.
Pokyny k registraci komponenty Azure Machine Learning najdete v tématu Registrace komponenty v pracovním prostoru.
Po registraci produkčních dat a součásti předběžného zpracování můžete nastavit monitorování modelu.
Vytvořte soubor YAML definice monitorování, který je podobný následujícímu souboru. Před použitím této definice upravte následující nastavení a všechny ostatní tak, aby vyhovovaly potřebám vašeho prostředí:
- Pro
endpoint_deployment_id, použít hodnotu ve formátuazureml:<endpoint-name>:<deployment-name>. - Pro
pre_processing_component, použít hodnotu ve formátuazureml:<component-name>:<component-version>. Zadejte přesnou verzi, například1.0.0, nikoli1. - Pro každou
pathz nich použijte hodnotu ve formátuazureml:<data-asset-name>:<version>. -
target_columnJako hodnotu použijte název výstupního sloupce, který obsahuje hodnoty, které model predikuje. - V části
emailsUveďte e-mailové adresy, které chcete použít pro oznámení.
# model-monitoring-with-collected-data.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: fraud_detection_model_monitoring display_name: Fraud detection model monitoring description: Fraud detection model monitoring with your own production data trigger: # perform model monitoring activity daily at 3:15am type: recurrence frequency: day #can be minute, hour, day, week, month interval: 1 # #every day schedule: hours: 3 # at 3am minutes: 15 # at 15 mins after 3am create_monitor: compute: instance_type: standard_e4s_v3 runtime_version: "3.4" monitoring_target: ml_task: classification endpoint_deployment_id: azureml:fraud-detection-endpoint:fraud-detection-deployment monitoring_signals: advanced_data_drift: # monitoring signal name, any user defined name works type: data_drift # define production dataset with your collected data production_data: input_data: path: azureml:my_production_inference_data_model_inputs:1 # your collected data is registered as Azure Machine Learning asset type: uri_folder data_context: model_inputs pre_processing_component: azureml:production_data_preprocessing:1.0.0 reference_data: input_data: path: azureml:my_model_training_data:1 # use training data as comparison baseline type: mltable data_context: training data_column_names: target_column: is_fraud features: top_n_feature_importance: 20 # monitor drift for top 20 features alert_enabled: true metric_thresholds: numerical: jensen_shannon_distance: 0.01 categorical: pearsons_chi_squared_test: 0.02 advanced_prediction_drift: # monitoring signal name, any user defined name works type: prediction_drift # define production dataset with your collected data production_data: input_data: path: azureml:my_production_inference_data_model_outputs:1 # your collected data is registered as Azure Machine Learning asset type: uri_folder data_context: model_outputs pre_processing_component: azureml:production_data_preprocessing:1.0.0 reference_data: input_data: path: azureml:my_model_validation_data:1 # use training data as comparison reference dataset type: mltable data_context: validation alert_enabled: true metric_thresholds: categorical: pearsons_chi_squared_test: 0.02 alert_notification: emails: - abc@example.com - def@example.com- Pro
Spuštěním následujícího příkazu vytvořte model.
az ml schedule create -f ./model-monitoring-with-collected-data.yaml
Nastavení monitorování modelů s využitím vlastních signálů a metrik
Když používáte monitorování modelu Azure Machine Learning, můžete definovat vlastní signál a implementovat libovolnou metriku podle vašeho výběru pro monitorování modelu. Vlastní signál můžete zaregistrovat jako součást služby Azure Machine Learning. Když úloha monitorování modelu běží podle zadaného plánu, vypočítá metriky definované v rámci vašeho vlastního signálu stejně jako u předem připravených signálů posunu dat, posunu předpovědí a kvality dat.
Pokud chcete nastavit vlastní signál pro monitorování modelů, musíte nejprve definovat vlastní signál a zaregistrovat ho jako komponentu Azure Machine Learning. Komponenta Azure Machine Learning musí obsahovat následující vstupní a výstupní podpisy.
Podpis vstupu komponenty
Vstupní datový rámec komponenty by měl obsahovat následující položky:
- Struktura
mltable, která obsahuje zpracovaná data z komponenty předběžného zpracování. - Libovolný počet literálů, z nichž každý představuje implementovanou metriku jako součást vlastní komponenty signálu. Pokud například implementujete metriku
std_deviation, potřebujete vstup prostd_deviation_threshold. Obecně platí, že pro každou metriku by měl být jeden vstup s názvem<metric-name>_threshold.
| Název podpisu | Typ | Popis | Příklad hodnoty |
|---|---|---|---|
production_data |
mltable | Tabulkový datový prostředek, který odpovídá podmnožině schématu referenčních dat | |
std_deviation_threshold |
literál, řetězec | Odpovídající prahová hodnota implementované metriky | 2 |
Podpis výstupu komponenty
Výstupní port komponenty by měl mít následující podpis:
| Název podpisu | Typ | Popis |
|---|---|---|
signal_metrics |
mltable | Struktura mltable, která obsahuje vypočítané metriky. Schéma tohoto podpisu najdete v další části, schématu signal_metrics. |
schéma signal_metrics
Výstupní datový rámec komponenty by měl obsahovat čtyři sloupce: group, metric_name, metric_valuea threshold_value.
| Název podpisu | Typ | Popis | Příklad hodnoty |
|---|---|---|---|
group |
literál, řetězec | Logické seskupení nejvyšší úrovně, které se použije na vlastní metriku | ČÁSTKA TRANSAKCE |
metric_name |
literál, řetězec | Název vlastní metriky | std_deviation |
metric_value |
číselný | Hodnota vlastní metriky | 44,896.082 |
threshold_value |
číselný | Prahová hodnota pro vlastní metriku | 2 |
Následující tabulka ukazuje příklad výstupu z vlastní komponenty signálu, která vypočítá metriku std_deviation :
| seskupit | hodnota metriky | název metriky | prahová_hodnota |
|---|---|---|---|
| ČÁSTKA TRANSAKCE | 44,896.082 | std_deviation | 2 |
| Místní hodina | 3.983 | std_deviation | 2 |
| Částka transakce (USD) | 54 004,902 | std_deviation | 2 |
| DIGITALITEMCOUNT | 7.238 | std_deviation | 2 |
| Fyzický počet položek | 5.509 | std_deviation | 2 |
Pokud chcete zobrazit příklad vlastní definice komponenty signálu a výpočetního kódu metrik, podívejte se na custom_signal v úložišti azureml-examples.
Pokyny k registraci komponenty Azure Machine Learning najdete v tématu Registrace komponenty v pracovním prostoru.
Po vytvoření a registraci vlastní komponenty signálu ve službě Azure Machine Learning proveďte následující kroky a nastavte monitorování modelu:
Vytvořte definici monitorování v souboru YAML, který je podobný následujícímu. Před použitím této definice upravte následující nastavení a všechny ostatní tak, aby vyhovovaly potřebám vašeho prostředí:
- Pro
component_id, použít hodnotu ve formátuazureml:<custom-signal-name>:1.0.0. - V
pathčásti vstupních dat použijte hodnotu ve formátuazureml:<production-data-asset-name>:<version>. - Pro
pre_processing_component:- Pokud ke shromažďování dat použijete kolektor dat , můžete vlastnost vynechat
pre_processing_component. - Pokud kolekci dat nepoužíváte a chcete použít komponentu k předběžnému zpracování produkčních dat, použijte hodnotu ve formátu
azureml:<custom-preprocessor-name>:<custom-preprocessor-version>.
- Pokud ke shromažďování dat použijete kolektor dat , můžete vlastnost vynechat
- V části
emailsUveďte e-mailové adresy, které chcete použít pro oznámení.
# custom-monitoring.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: my-custom-signal trigger: type: recurrence frequency: day # Possible frequency values include "minute," "hour," "day," "week," and "month." interval: 7 # Monitoring runs every day when you use the value 1. create_monitor: compute: instance_type: "standard_e4s_v3" runtime_version: "3.3" monitoring_signals: customSignal: type: custom component_id: azureml:my_custom_signal:1.0.0 input_data: production_data: input_data: type: uri_folder path: azureml:my_production_data:1 data_context: test data_window: lookback_window_size: P30D lookback_window_offset: P7D pre_processing_component: azureml:custom_preprocessor:1.0.0 metric_thresholds: - metric_name: std_deviation threshold: 2 alert_notification: emails: - abc@example.com- Pro
Spuštěním následujícího příkazu vytvořte model:
az ml schedule create -f ./custom-monitoring.yaml
Interpretace výsledků monitorování
Jakmile nakonfigurujete monitorování modelu a dokončí se první spuštění, můžete zobrazit výsledky v nástroji Azure Machine Learning Studio.
V sadě Studio v části Spravovat vyberte Monitorování. Na stránce Monitorování vyberte název monitoru vašeho modelu a zobrazíte stránku přehledu. Tato stránka zobrazuje model monitorování, koncový bod a nasazení. Poskytuje také podrobné informace o nakonfigurovaných signálech. Následující obrázek ukazuje stránku přehledu monitorování, která zahrnuje signály pro posun dat a kvalitu dat.
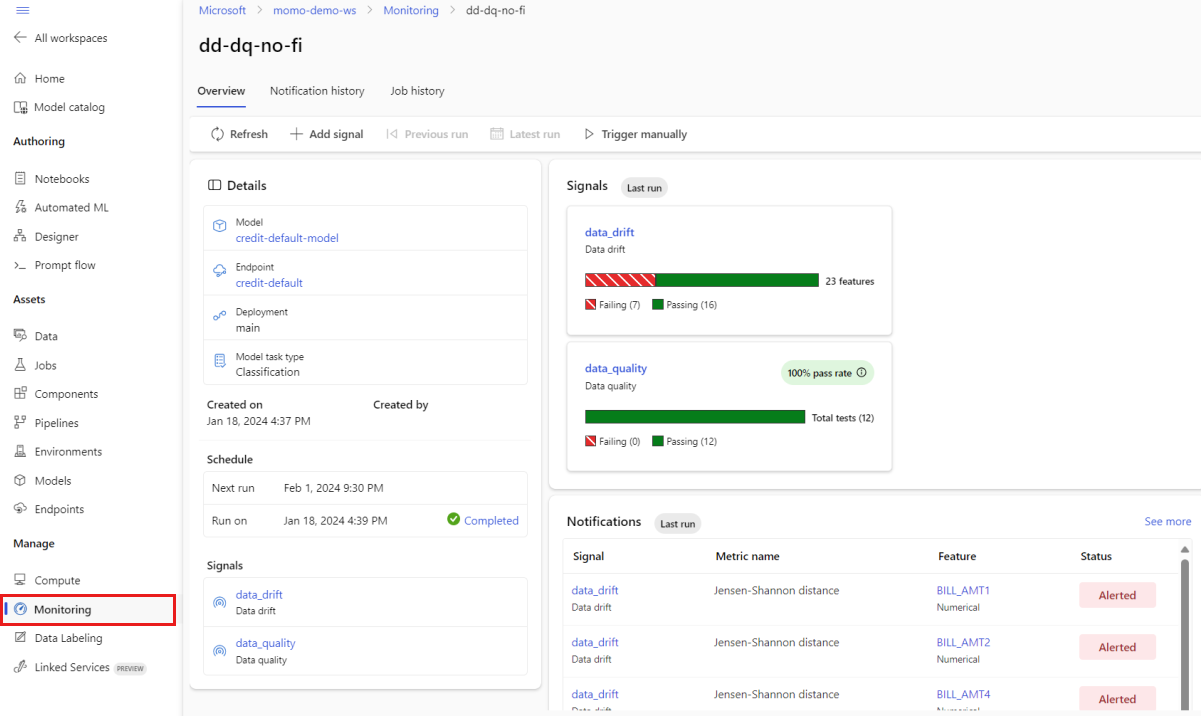
Podívejte se do části Oznámení na stránce přehledu. V této části uvidíte funkci pro každý signál, který porušuje nakonfigurovanou prahovou hodnotu pro příslušnou metriku.
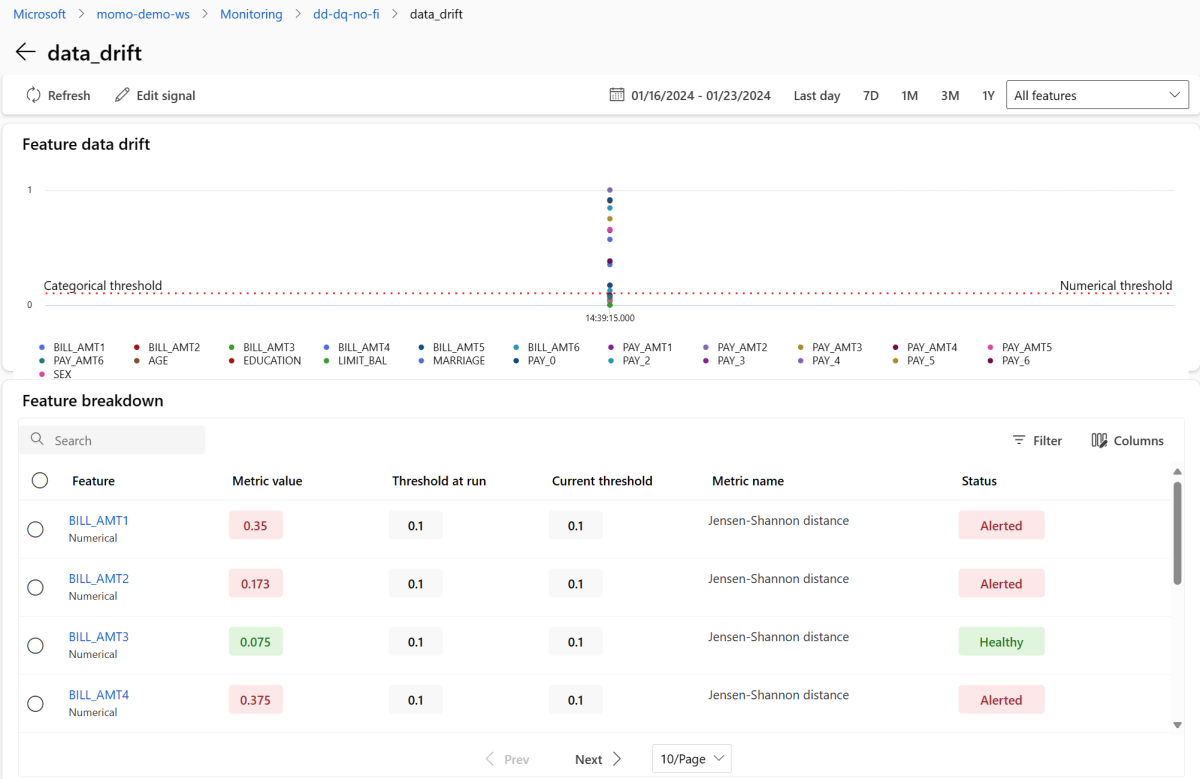
V části Signály vyberte data_drift , abyste zobrazili podrobné informace o signálu posunu dat. Na stránce podrobností uvidíte hodnotu metrik posunu dat pro každou číselnou a kategorickou funkci, kterou zahrnuje konfigurace monitorování. Pokud má monitor více spuštění, objeví se trendová čára pro každou vlastnost.
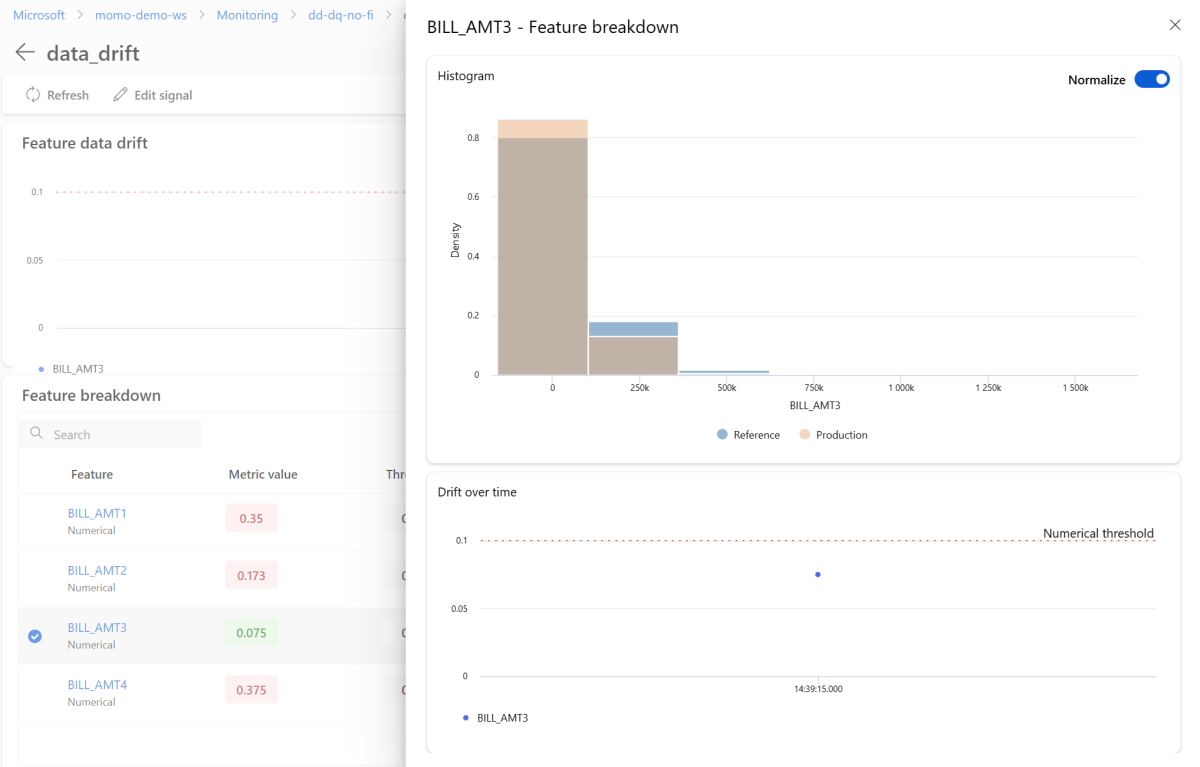
Na stránce podrobností vyberte název jednotlivé funkce. Otevře se podrobné zobrazení, které zobrazuje produkční distribuci v porovnání s referenční distribucí. Toto zobrazení můžete také použít ke sledování posunu v průběhu času pro tuto funkci.
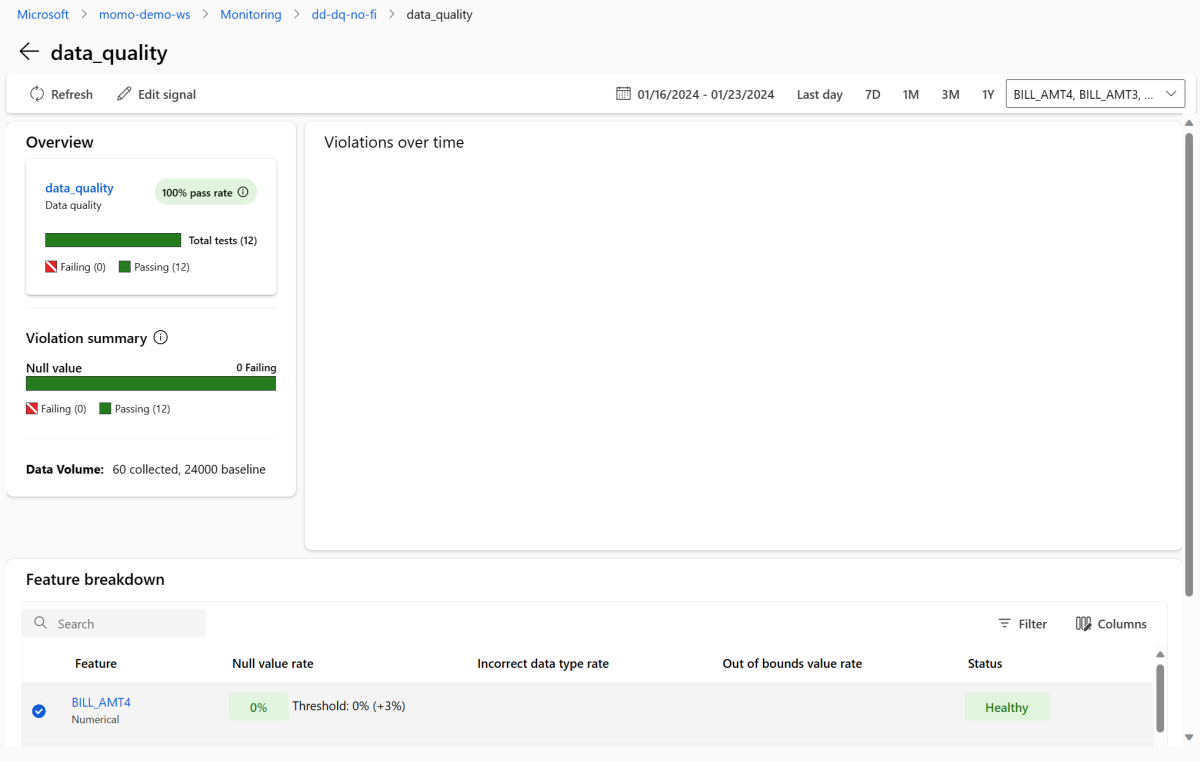
Vraťte se na stránku přehledu monitorování. V části Signály vyberte data_quality , abyste zobrazili podrobné informace o tomto signálu. Na této stránce uvidíte míry hodnot null, míry chyb mimo hranice a chybovost datových typů pro každou funkci, kterou monitorujete.




Monitorování modelů je průběžný proces. Když používáte monitorování modelů Azure Machine Learning, můžete nakonfigurovat několik monitorovacích signálů, abyste získali široký přehled o výkonu modelů v produkčním prostředí.
Integrace monitorování modelu Azure Machine Learning s Event Gridem
Když používáte Event Grid, můžete nakonfigurovat události, které jsou generovány monitorováním modelu Azure Machine Learning, aby aktivovaly aplikace, procesy a pracovní postupy CI/CD. Události můžete využívat prostřednictvím různých obslužných rutin událostí, jako jsou Azure Event Hubs, Azure Functions a Azure Logic Apps. Když monitory detekují posun, můžete provádět akce prostřednictvím kódu programu, například spuštěním kanálu strojového učení, který model přetrénuje a znovu ho nasadí.
Pokud chcete integrovat monitorování modelu Azure Machine Learning s Event Gridem, postupujte podle kroků v následujících částech.
Vytvoření systémového tématu
Pokud nemáte systémové téma Event Gridu, které se má použít k monitorování, vytvořte ho. Pokyny najdete v tématu Vytvoření, zobrazení a správa systémových témat Event Gridu na webu Azure Portal.
Vytvoření odběru událostí
Na webu Azure Portal přejděte do svého pracovního prostoru Azure Machine Learning.
Vyberte Události a potom vyberte Předplatné události.

Vedle názvu zadejte název odběru událostí, například MonitoringEvent.
V části Typy událostí vyberte pouze Změna stavu spuštění.
Upozorňující
Pro typ události vyberte pouze změna stavu spuštění. Nevybírejte zjištěnou odchylku datové sady, která se vztahuje na posun dat v1, nikoli na monitorování modelu Azure Machine Learning.
Vyberte kartu Filtry . V části Rozšířené filtry vyberte Přidat nový filtr a zadejte následující hodnoty:
- Do pole Klíč zadejte data.RunTags.azureml_modelmonitor_threshold_breached.
- V části Operátor vyberte Řetězec obsahuje.
- V části Hodnota se zadání nezdařilo kvůli jedné nebo více funkcím, které porušují prahové hodnoty metriky.

Když použijete tento filtr, události se vygenerují, když se změní stav spuštění jakéhokoli monitoru v pracovním prostoru Azure Machine Learning. Stav spuštění se může změnit z dokončeného na neúspěšný nebo se nepodařilo dokončit.
Pokud chcete filtrovat na úrovni monitorování, znovu vyberte Přidat nový filtr a zadejte následující hodnoty:
- Do pole Klíč zadejte data.RunTags.azureml_modelmonitor_threshold_breached.
- V části Operátor vyberte Řetězec obsahuje.
- V části Hodnota zadejte název signálu monitoru, pro který chcete filtrovat události, například credit_card_fraud_monitor_data_drift. Zadaný název se musí shodovat s názvem vašeho monitorovacího signálu. Každý signál, který používáte při filtrování, by měl mít název ve formátu
<monitor-name>_<signal-description>, který obsahuje název monitoru a popis signálu.
Vyberte kartu Základy . Nakonfigurujte koncový bod, který chcete použít jako obslužnou rutinu události, jako je event Hubs.
Výběrem možnosti Vytvořit vytvořte odběr události.

Zobrazit události
Po zachycení událostí je můžete zobrazit na stránce rozhraní obslužné rutiny události.

Události můžete zobrazit také na kartě Metriky služby Azure Monitor:
