Příprava dat pro úlohy počítačového zpracování obrazu pomocí automatizovaného strojového učení
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)Python SDK azure-ai-ml v2 (aktuální)
Rozšíření Azure CLI ml v2 (aktuální)Python SDK azure-ai-ml v2 (aktuální)
Důležité
Podpora trénování modelů počítačového zpracování obrazu pomocí automatizovaného strojového učení ve službě Azure Machine Learning je experimentální funkce ve verzi Public Preview. Některé funkce se nemusí podporovat nebo mohou mít omezené možnosti. Další informace najdete v dodatečných podmínkách použití pro verze Preview v Microsoft Azure.
V tomto článku se dozvíte, jak připravit image dat pro trénování modelů počítačového zpracování obrazu pomocí automatizovaného strojového učení ve službě Azure Machine Learning.
Pokud chcete vygenerovat modely pro úlohy počítačového zpracování obrazu pomocí automatizovaného strojového MLTableučení, musíte jako vstup pro trénování modelu použít označení obrazová data ve formě .
Můžete vytvořit z MLTable označených trénovacích dat ve formátu JSONL.
Pokud jsou vaše trénovací data označená v jiném formátu (například pascal VOC nebo COCO), můžete ho nejprve převést na JSONL a pak vytvořit MLTable. Alternativně můžete pomocí nástroje pro popisování dat služby Azure Machine Learning ručně označovat obrázky a exportovat označená data k trénování modelu AutoML.
Požadavky
- Seznamte se s akceptovanými schématy pro soubory JSONL pro experimenty s počítačovým zpracování obrazu AutoML.
Získání dat s popiskem
Abyste mohli trénovat modely počítačového zpracování obrazu pomocí AutoML, musíte nejprve získat trénovací data s popisky. Obrázky je potřeba nahrát do cloudu a popisky popisků musí být ve formátu JSONL. K označení dat můžete použít nástroj Popisování dat služby Azure Machine Learning nebo můžete začít s předem označenými daty obrázků.
Použití nástroje pro popisování dat ve službě Azure Machine Learning k označení trénovacích dat
Pokud nemáte předem označená data, můžete k ručnímu popisování obrázků použít nástroj pro popisování dat služby Azure Machine Learning. Tento nástroj automaticky vygeneruje data potřebná pro trénování v přijatém formátu.
Pomáhá vytvářet, spravovat a monitorovat úlohy popisování dat pro
- Klasifikace obrázků (více tříd a více popisků)
- Detekce objektů (ohraničující rámeček)
- Segmentace instancí (mnohoúhelník)
Pokud už máte označená data, která chcete použít, můžete exportovat označená data jako datovou sadu Azure Machine Learning a pak přistupovat k datové sadě na kartě Datové sady v studio Azure Machine Learning. Tato exportovaná datová sada se pak dá předat jako vstup ve azureml:<tabulardataset_name>:<version> formátu. Tady je příklad předání existující datové sady jako vstupu pro trénování modelů počítačového zpracování obrazu.
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)
training_data:
path: azureml:odFridgeObjectsTrainingDataset:1
type: mltable
mode: direct
Použití předem označených trénovacích dat z místního počítače
Pokud jste označili data, která chcete použít k trénování modelu, musíte nahrát obrázky do Azure. Image můžete nahrát do výchozí služby Azure Blob Storage pracovního prostoru Služby Azure Machine Learning a zaregistrovat je jako datový prostředek.
Následující skript nahraje data obrázků na místním počítači v cestě ./data/odFridgeObjects do úložiště dat ve službě Azure Blob Storage. Potom vytvoří nový datový prostředek s názvem "lednice-items-images-object-detection" v pracovním prostoru Služby Azure Machine Learning.
Pokud v pracovním prostoru Služby Azure Machine Learning již existuje datový prostředek s názvem "lednice-items-images-object-detection", aktualizuje číslo verze datového prostředku a odkazuje ho na nové místo, kam se data obrázku nahrála.
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)
Vytvořte soubor .yml s následující konfigurací.
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
name: fridge-items-images-object-detection
description: Fridge-items images Object detection
path: ./data/odFridgeObjects
type: uri_folder
Pokud chcete nahrát obrázky jako datový prostředek, spusťte následující příkaz CLI v2 s cestou k souboru .yml, názvu pracovního prostoru, skupině prostředků a ID předplatného.
az ml data create -f [PATH_TO_YML_FILE] --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Pokud už máte data v existujícím úložišti dat a chcete z něj vytvořit datový asset, můžete to udělat tak, že zadáte cestu k datům v úložišti dat místo toho, abyste poskytli cestu k místnímu počítači. Aktualizujte výše uvedený kód následujícím fragmentem kódu.
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)
Vytvořte soubor .yml s následující konfigurací.
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
name: fridge-items-images-object-detection
description: Fridge-items images Object detection
path: azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/<path_to_image_data_folder>
type: uri_folder
V dalším kroku potřebujete získat poznámky popisků ve formátu JSONL. Schéma označených dat závisí na úloze počítačového zpracování obrazu. Další informace o požadovaném schématu schématu JSONL pro jednotlivé typy úloh najdete v souborech JSONL pro experimenty s počítačovým zpracování obrazu AutoML.
Pokud jsou trénovací data v jiném formátu (například pascal VOC nebo COCO), jsou pomocné skripty pro převod dat na JSONL k dispozici v příkladech poznámkového bloku.
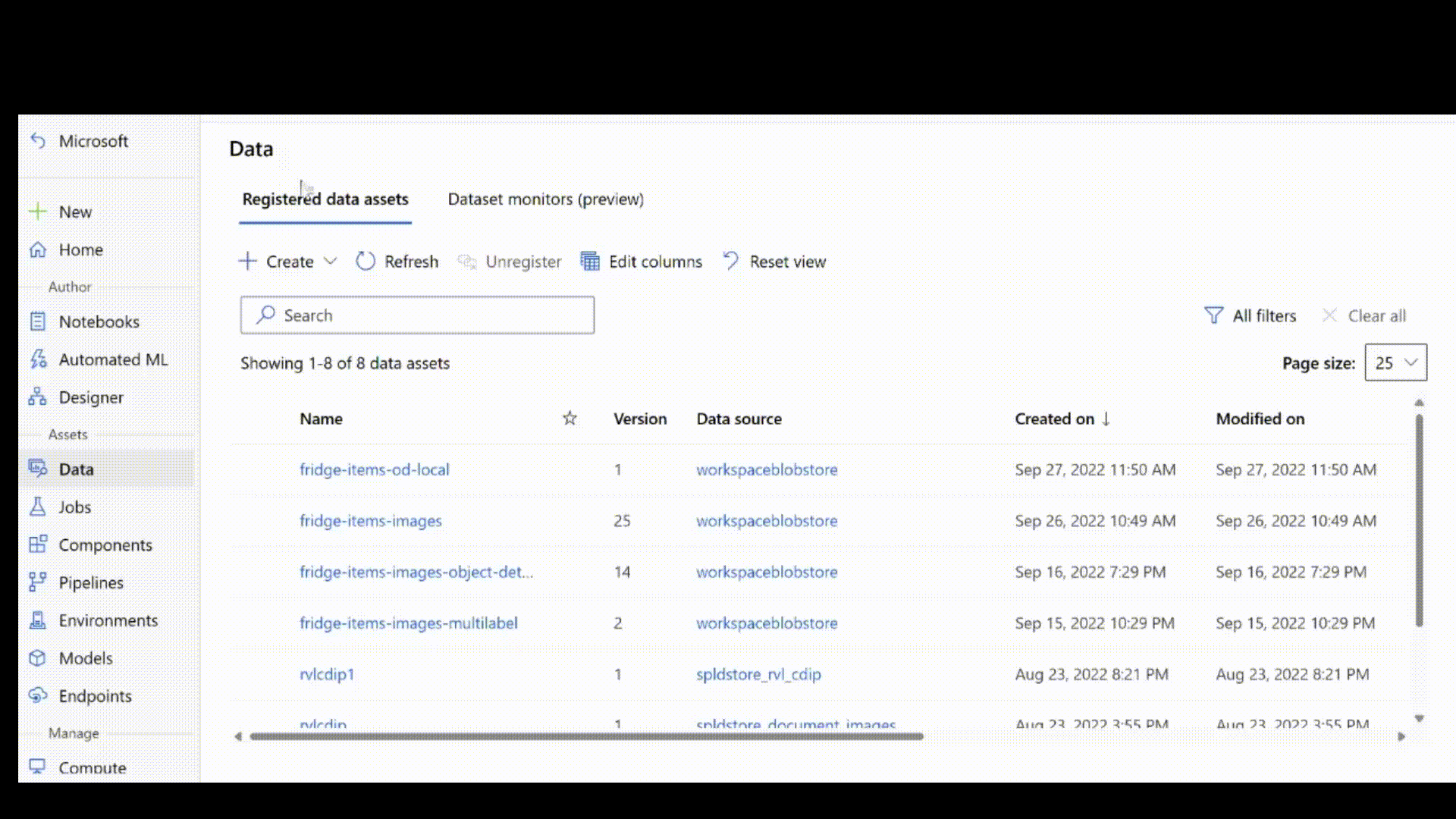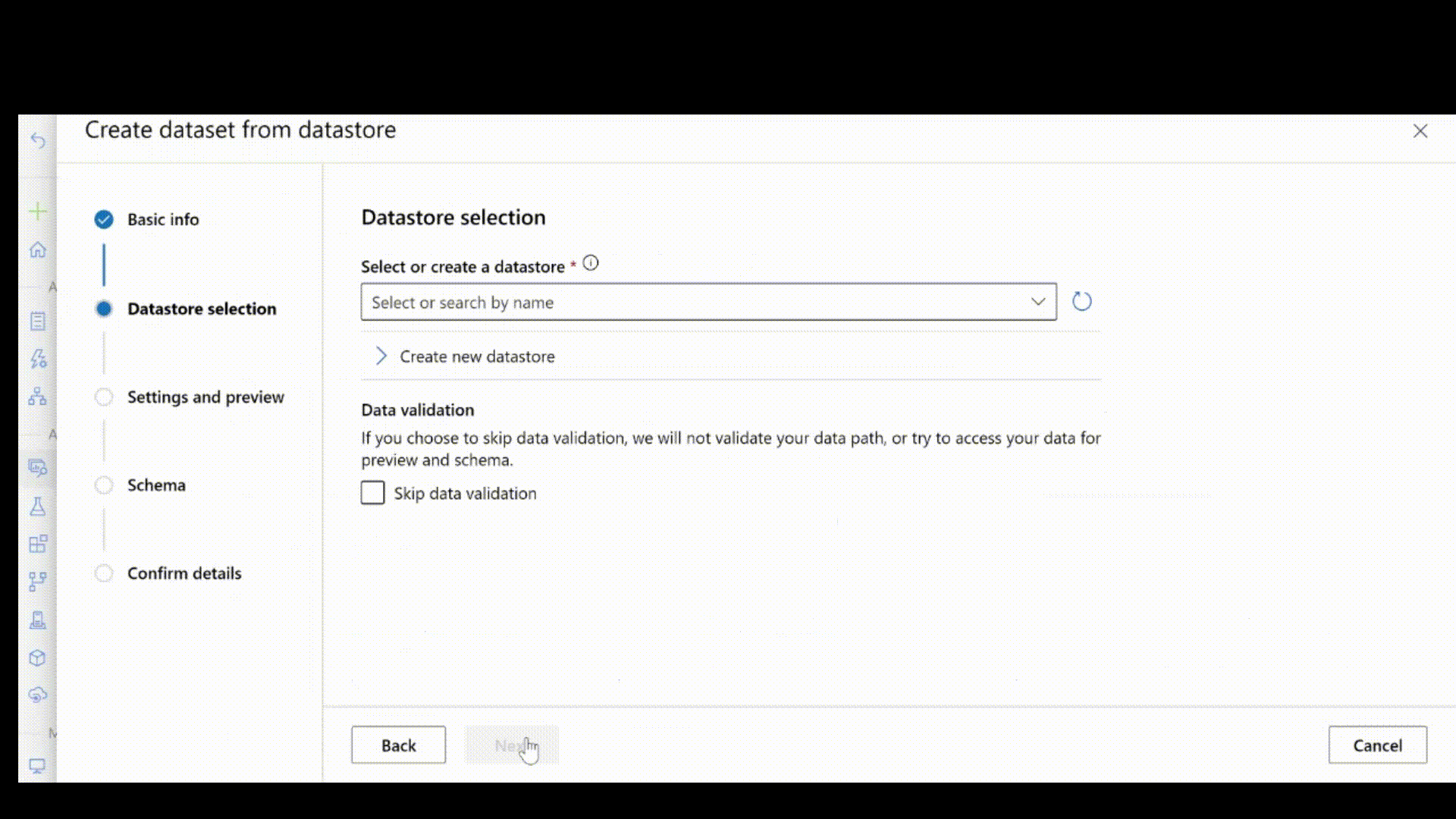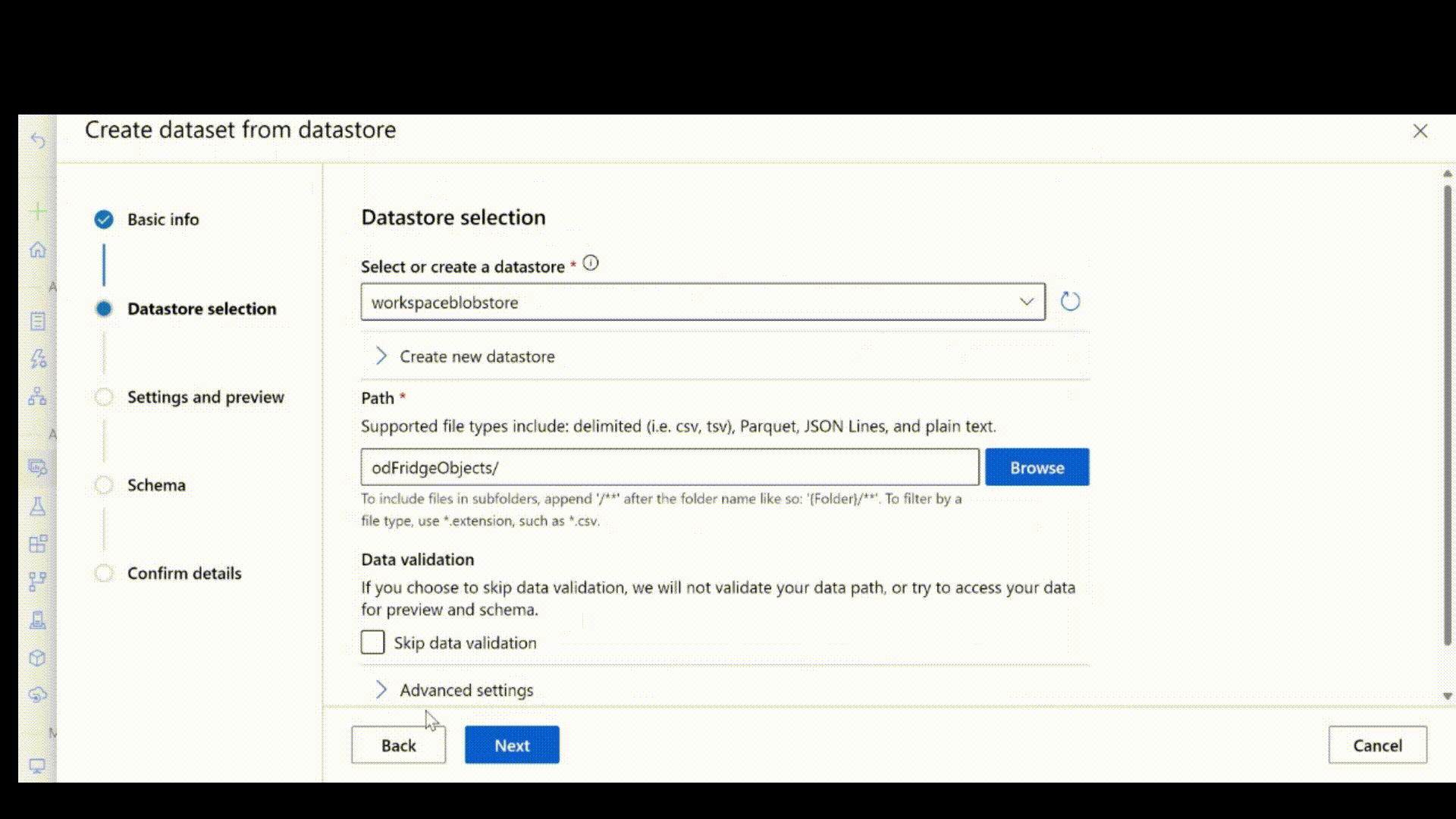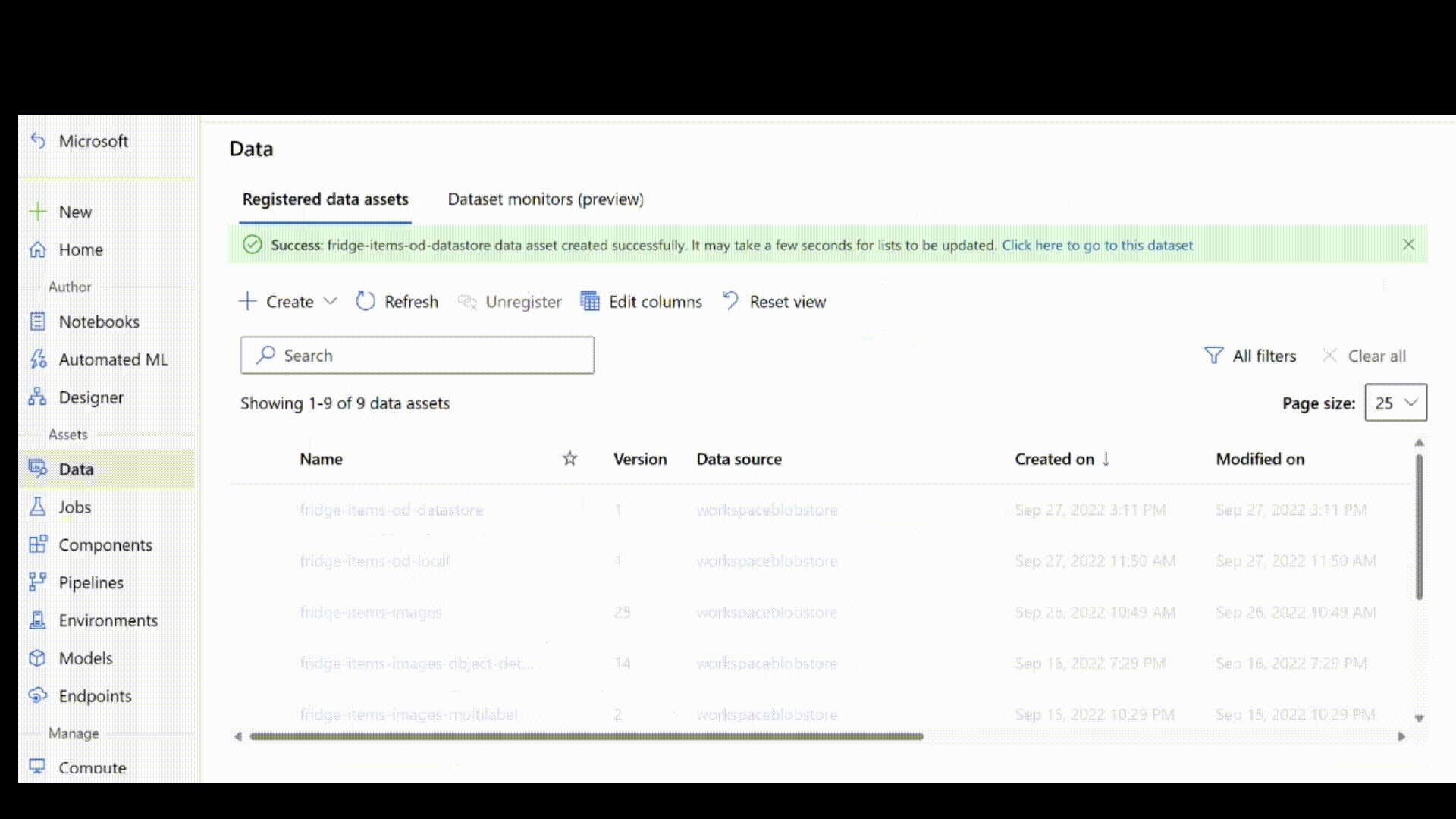
Jakmile vytvoříte soubor jsonl podle výše uvedených kroků, můžete ho zaregistrovat jako datový asset pomocí uživatelského rozhraní. Ujistěte se, že jste vybrali stream typ v části schématu, jak je znázorněno v této animaci.
Použití předem označených trénovacích dat ze služby Azure Blob Storage
Pokud máte v kontejneru v úložišti objektů blob v Kontejneru svoji trénovací data, můžete k němu přistupovat přímo tak , že vytvoříte úložiště dat odkazující na tento kontejner.
Vytvoření tabulky MLTable
Jakmile budete mít označená data ve formátu JSONL, můžete je použít k vytvoření MLTable , jak je znázorněno v tomto fragmentu kódu yaml. MLtable zabalí vaše data do spotřebního objektu pro trénování.
paths:
- file: ./train_annotations.jsonl
transformations:
- read_json_lines:
encoding: utf8
invalid_lines: error
include_path_column: false
- convert_column_types:
- columns: image_url
column_type: stream_info
Potom můžete předat MLTable jako datový vstup pro trénovací úlohu AutoML.
Další kroky
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro