Nasazení modelů pro bodování v dávkových koncových bodech
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)Python SDK azure-ai-ml v2 (aktuální)
Rozšíření Azure CLI ml v2 (aktuální)Python SDK azure-ai-ml v2 (aktuální)
Koncové body služby Batch poskytují pohodlný způsob, jak nasadit modely, které spouští odvozování nad velkými objemy dat. Tyto koncové body zjednodušují proces hostování modelů pro dávkové vyhodnocování, takže se zaměřujete na strojové učení, nikoli na infrastrukturu.
K nasazení modelu použijte dávkové koncové body, když:
- Máte drahé modely, které vyžadují delší dobu, než se spustí odvozování.
- Musíte provést odvozování nad velkým množstvím dat distribuovaných ve více souborech.
- Nemáte požadavky na nízkou latenci.
- Můžete využít paralelizaci.
V tomto článku použijete dávkový koncový bod k nasazení modelu strojového učení, který řeší klasický problém rozpoznávání číslic MNIST (Modified National Institute of Standards and Technology). Nasazený model pak provádí dávkové odvozování nad velkým množstvím dat – v tomto případě soubory obrázků. Začnete vytvořením dávkového nasazení modelu vytvořeného pomocí Torch. Toto nasazení se stane výchozím v koncovém bodu. Později vytvoříte druhé nasazení režimu vytvořeného pomocí TensorFlow (Keras), otestujete druhé nasazení a pak ho nastavíte jako výchozí nasazení koncového bodu.
Pokud chcete postupovat podle ukázek kódu a souborů potřebných ke spuštění příkazů v tomto článku místně, projděte si část Klonování úložiště příkladů. Ukázky kódu a soubory jsou obsaženy v úložišti azureml-examples .
Požadavky
Než budete postupovat podle kroků v tomto článku, ujistěte se, že máte následující požadavky:
Předplatné Azure. Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet. Vyzkoušejte bezplatnou nebo placenou verzi služby Azure Machine Learning.
Pracovní prostor služby Azure Machine Learning. Pokud ho nemáte, vytvořte si ho pomocí kroků v článku Správa pracovních prostorů .
Pokud chcete provést následující úlohy, ujistěte se, že máte tato oprávnění v pracovním prostoru:
Vytváření a správa dávkových koncových bodů a nasazení: Použijte roli vlastníka, roli přispěvatele nebo vlastní roli, která povoluje
Microsoft.MachineLearningServices/workspaces/batchEndpoints/*.Vytvoření nasazení ARM ve skupině prostředků pracovního prostoru: Použijte roli vlastníka, roli přispěvatele nebo vlastní roli, která umožňuje ve
Microsoft.Resources/deployments/writeskupině prostředků, ve které je pracovní prostor nasazený.
Abyste mohli pracovat se službou Azure Machine Learning, musíte nainstalovat následující software:
PLATÍ PRO:
Rozšíření Azure CLI ml v2 (aktuální)Azure CLI a
mlrozšíření pro Azure Machine Learning.az extension add -n ml
Klonování úložiště příkladů
Příklad v tomto článku vychází z ukázek kódu obsažených v úložišti azureml-examples . Pokud chcete příkazy spustit místně, aniž byste museli kopírovat nebo vkládat YAML a další soubory, nejprve naklonujte úložiště a pak změňte adresáře do složky:
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli/endpoints/batch/deploy-models/mnist-classifier
Příprava systému
Připojení k pracovnímu prostoru
Nejprve se připojte k pracovnímu prostoru Azure Machine Learning, kde budete pracovat.
Pokud jste ještě nenastavili výchozí hodnoty pro Azure CLI, uložte výchozí nastavení. Pokud se chcete vyhnout předávání hodnot pro vaše předplatné, pracovní prostor, skupinu prostředků a umístění několikrát, spusťte tento kód:
az account set --subscription <subscription>
az configure --defaults workspace=<workspace> group=<resource-group> location=<location>
Vytvoření výpočetních prostředků
Koncové body služby Batch běží na výpočetních clusterech a podporují výpočetní clustery Azure Machine Learning (AmlCompute) i clustery Kubernetes. Clustery jsou sdíleným prostředkem, takže jeden cluster může v případě potřeby hostovat jedno nebo mnoho dávkových nasazení (společně s jinými úlohami).
Vytvořte výpočetní prostředky s názvem batch-cluster, jak je znázorněno v následujícím kódu. Podle potřeby můžete upravit a odkazovat na výpočetní prostředky pomocí azureml:<your-compute-name>.
az ml compute create -n batch-cluster --type amlcompute --min-instances 0 --max-instances 5
Poznámka:
Za výpočetní prostředky se v tomto okamžiku neúčtují poplatky, protože cluster zůstane na 0 uzlech, dokud se nevyvolá koncový bod dávky a neodesílají se úloha dávkového vyhodnocování. Další informace o nákladech na výpočetní prostředky najdete v tématu Správa a optimalizace nákladů na AmlCompute.
Vytvoření dávkového koncového bodu
Dávkový koncový bod je koncový bod HTTPS, který klienti můžou volat za účelem aktivace dávkové úlohy bodování. Dávková úloha bodování je úloha , která skóre více vstupů. Dávkové nasazení je sada výpočetních prostředků hostující model, který provádí skutečné dávkové vyhodnocování (nebo dávkové odvozování). Jeden dávkový koncový bod může mít několik dávkových nasazení. Další informace o dávkových koncových bodech najdete v tématu Co jsou dávkové koncové body?
Tip
Jedno z dávkových nasazení slouží jako výchozí nasazení koncového bodu. Při vyvolání koncového bodu provede výchozí nasazení skutečné dávkové vyhodnocování. Další informace o dávkových koncových bodech a nasazeních najdete v tématu Dávkové koncové body a dávkové nasazení.
Pojmenujte koncový bod. Název koncového bodu musí být jedinečný v rámci oblasti Azure, protože tento název je součástí identifikátoru URI koncového bodu. Například může existovat pouze jeden dávkový koncový bod s názvem
mybatchendpointvwestus2.Konfigurace dávkového koncového bodu
Následující soubor YAML definuje dávkový koncový bod. Tento soubor můžete použít s příkazem rozhraní příkazového řádku pro vytvoření dávkového koncového bodu.
endpoint.yml
$schema: https://azuremlschemas.azureedge.net/latest/batchEndpoint.schema.json name: mnist-batch description: A batch endpoint for scoring images from the MNIST dataset. tags: type: deep-learningNásledující tabulka popisuje klíčové vlastnosti koncového bodu. Úplné schéma YAML koncového bodu dávky najdete ve schématu YAML dávkového koncového bodu CLI (v2).
Key Popis nameNázev dávkového koncového bodu. Musí být jedinečný na úrovni oblasti Azure. descriptionPopis dávkového koncového bodu Tato vlastnost je nepovinná. tagsZnačky, které se mají zahrnout do koncového bodu. Tato vlastnost je nepovinná. Vytvořte koncový bod:
Vytvoření dávkového nasazení
Nasazení modelu je sada prostředků vyžadovaných pro hostování modelu, který provádí skutečné odvozování. K vytvoření nasazení dávkového modelu potřebujete následující položky:
- Registrovaný model v pracovním prostoru
- Kód pro určení skóre modelu
- Prostředí s nainstalovanými závislostmi modelu
- Předem vytvořené nastavení výpočetních prostředků a prostředků
Začněte registrací modelu, který se má nasadit – model Torch pro populární problém s rozpoznáváním číslic (MNIST). Nasazení služby Batch můžou nasazovat pouze modely, které jsou zaregistrované v pracovním prostoru. Tento krok můžete přeskočit, pokud už je model, který chcete nasadit, zaregistrovaný.
Tip
Modely se přidruží k nasazení, nikoli ke koncovému bodu. To znamená, že jeden koncový bod může obsluhovat různé modely (nebo verze modelu) ve stejném koncovém bodu za předpokladu, že různé modely (nebo verze modelů) se nasazují v různých nasazeních.
Teď je čas vytvořit bodovací skript. Nasazení služby Batch vyžadují bodovací skript, který indikuje, jak se má daný model spustit a jak se musí zpracovávat vstupní data. Koncové body služby Batch podporují skripty vytvořené v Pythonu. V tomto případě nasadíte model, který čte soubory obrázků představující číslice a vypíše odpovídající číslici. Bodovací skript je následující:
Poznámka:
V případě modelů MLflow azure Machine Learning automaticky vygeneruje bodovací skript, takže ho nemusíte zadávat. Pokud je vaším modelem MLflow, můžete tento krok přeskočit. Další informace o tom, jak dávkové koncové body fungují s modely MLflow, najdete v článku Použití modelů MLflow v dávkových nasazeních.
Upozorňující
Pokud nasazujete model automatizovaného strojového učení (AutoML) do dávkového koncového bodu, mějte na paměti, že bodovací skript, který AutoML poskytuje, funguje jenom pro online koncové body a není určený pro dávkové spouštění. Informace o tom, jak vytvořit bodovací skript pro dávkové nasazení, najdete v tématu Vytváření hodnoticích skriptů pro dávkové nasazení.
deployment-torch/code/batch_driver.py
import os import pandas as pd import torch import torchvision import glob from os.path import basename from mnist_classifier import MnistClassifier from typing import List def init(): global model global device # AZUREML_MODEL_DIR is an environment variable created during deployment # It is the path to the model folder model_path = os.environ["AZUREML_MODEL_DIR"] model_file = glob.glob(f"{model_path}/*/*.pt")[-1] model = MnistClassifier() model.load_state_dict(torch.load(model_file)) model.eval() device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] with torch.no_grad(): for image_path in mini_batch: image_data = torchvision.io.read_image(image_path).float() batch_data = image_data.expand(1, -1, -1, -1) input = batch_data.to(device) # perform inference predict_logits = model(input) # Compute probabilities, classes and labels predictions = torch.nn.Softmax(dim=-1)(predict_logits) predicted_prob, predicted_class = torch.max(predictions, axis=-1) results.append( { "file": basename(image_path), "class": predicted_class.numpy()[0], "probability": predicted_prob.numpy()[0], } ) return pd.DataFrame(results)Vytvořte prostředí, ve kterém se bude spouštět dávkové nasazení. Prostředí by mělo obsahovat balíčky
azureml-coreaazureml-dataset-runtime[fuse], které jsou vyžadovány koncovými body dávky a každou závislost, kterou váš kód vyžaduje ke spuštění. V tomto případě byly závislosti zachyceny vconda.yamlsouboru:deployment-torch/environment/conda.yaml
name: mnist-env channels: - conda-forge dependencies: - python=3.8.5 - pip<22.0 - pip: - torch==1.13.0 - torchvision==0.14.0 - pytorch-lightning - pandas - azureml-core - azureml-dataset-runtime[fuse]Důležité
Balíčky a
azureml-dataset-runtime[fuse]jsou vyžadoványazureml-coredávkovými nasazeními a měly by být zahrnuty do závislostí prostředí.Zadejte prostředí následujícím způsobem:
Definice prostředí bude zahrnuta do samotné definice nasazení jako anonymní prostředí. V nasazení se zobrazí následující řádky:
environment: name: batch-torch-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yamlUpozorňující
Kurátorovaná prostředí se v dávkových nasazeních nepodporují. Musíte zadat vlastní prostředí. Ke zjednodušení procesu můžete vždy použít základní image kurátorovaného prostředí.
Vytvoření definice nasazení
torch/deployment.yml nasazení
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-torch-dpl description: A deployment using Torch to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-torch path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-torch-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csv retry_settings: max_retries: 3 timeout: 30 error_threshold: -1 logging_level: infoNásledující tabulka popisuje klíčové vlastnosti dávkového nasazení. Úplné schéma YAML dávkového nasazení najdete ve schématu YAML dávkového nasazení CLI (v2).
Key Popis nameNázev nasazení. endpoint_nameNázev koncového bodu pro vytvoření nasazení v části. modelModel, který se má použít pro dávkové vyhodnocování. Příklad definuje model vložený pomocí path. Tato definice umožňuje, aby se soubory modelu automaticky nahrály a zaregistrovaly s automaticky vygenerovaným názvem a verzí. Další možnosti najdete ve schématu modelu. Osvědčeným postupem pro produkční scénáře je vytvořit model samostatně a odkazovat na něj zde. Pokud chcete odkazovat na existující model, použijteazureml:<model-name>:<model-version>syntaxi.code_configuration.codeMístní adresář, který obsahuje veškerý zdrojový kód Pythonu pro určení skóre modelu. code_configuration.scoring_scriptSoubor Pythonu code_configuration.codev adresáři. Tento soubor musí mítinit()funkci arun()funkci.init()Funkci použijte pro jakoukoli nákladnou nebo běžnou přípravu (například k načtení modelu do paměti).init()bude volána pouze jednou na začátku procesu. Sloužírun(mini_batch)k určení skóre každé položky. Hodnotamini_batchje seznam cest k souborům. Funkcerun()by měla vrátit datový rámec pandas nebo pole. Každý vrácený prvek označuje jeden úspěšný spuštění vstupní prvek v objektumini_batch. Další informace o tom, jak vytvořit bodovací skript, najdete v tématu Vysvětlení hodnoticího skriptu.environmentProstředí pro určení skóre modelu. Příklad definuje prostředí vložené pomocí conda_fileaimage.conda_fileZávislosti budou nainstalovány nad rozhranímimage. Prostředí se automaticky zaregistruje s automaticky vygenerovaným názvem a verzí. Další možnosti najdete ve schématu prostředí. Osvědčeným postupem pro produkční scénáře je vytvořit prostředí samostatně a odkazovat na něj zde. Pokud chcete odkazovat na existující prostředí, použijteazureml:<environment-name>:<environment-version>syntaxi.computeVýpočetní prostředky pro spuštění dávkového vyhodnocování. Příklad používá batch-clustervytvořený na začátku a odkazuje na něj pomocíazureml:<compute-name>syntaxe.resources.instance_countPočetinstancíchch settings.max_concurrency_per_instanceMaximální počet paralelních scoring_scriptspuštění na instanci.settings.mini_batch_sizePočet souborů, které scoring_scriptmůže zpracovat v jednomrun()volání.settings.output_actionJak se má výstup uspořádat do výstupního souboru. append_rowsloučí všechnyrun()vrácené výstupní výsledky do jednoho souboru s názvemoutput_file_name.summary_onlynebude sloučit výsledky výstupu a vypočítáerror_thresholdpouze .settings.output_file_nameNázev výstupního souboru dávkového bodování pro append_rowoutput_action.settings.retry_settings.max_retriesPočet maximálních pokusů o neúspěšný scoring_scriptrun()pokus .settings.retry_settings.timeoutČasový limit v sekundách pro scoring_scriptrun()bodování mini dávky.settings.error_thresholdPočet chyb vyhodnocování vstupního souboru, které by se měly ignorovat. Pokud počet chyb pro celý vstup překročí tuto hodnotu, úloha dávkového vyhodnocování se ukončí. Příklad používá -1, který označuje, že jakýkoli počet selhání je povolen bez ukončení dávkové bodovací úlohy.settings.logging_levelProtokolování podrobností Hodnoty při zvýšení úrovně podrobností jsou: UPOZORNĚNÍ, INFORMACE a LADĚNÍ. settings.environment_variablesSlovník párů název-hodnota proměnné prostředí, které se nastaví pro každou dávkovou úlohu vyhodnocování. Vytvořte nasazení:
Spuštěním následujícího kódu vytvořte dávkové nasazení v rámci koncového bodu dávky a nastavte ho jako výchozí nasazení.
az ml batch-deployment create --file deployment-torch/deployment.yml --endpoint-name $ENDPOINT_NAME --set-defaultTip
Parametr
--set-defaultnastaví nově vytvořené nasazení jako výchozí nasazení koncového bodu. Je to pohodlný způsob, jak vytvořit nové výchozí nasazení koncového bodu, zejména při prvním vytvoření nasazení. Osvědčeným postupem pro produkční scénáře je vytvoření nového nasazení, aniž byste ho nastavili jako výchozí. Ověřte, že nasazení funguje podle očekávání, a pak aktualizujte výchozí nasazení později. Další informace o implementaci tohoto procesu najdete v části Nasazení nového modelu .Zkontrolujte podrobnosti o dávkovém koncovém bodu a nasazení.

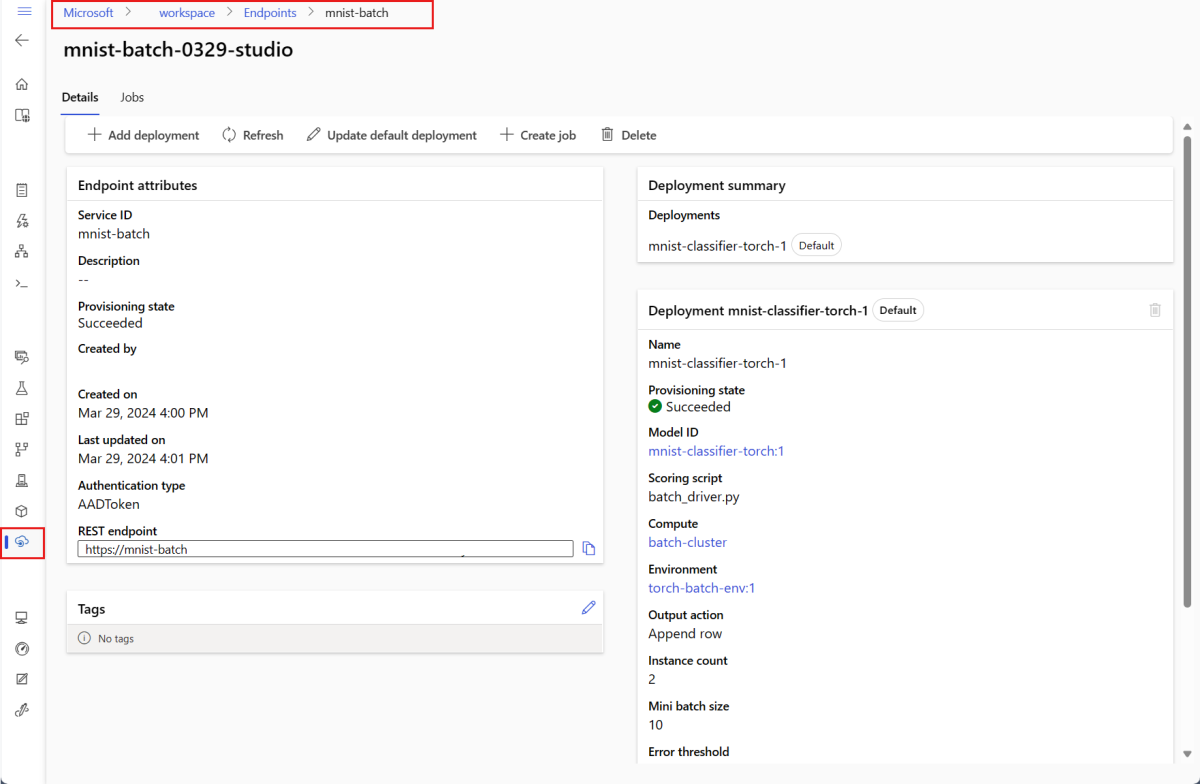
Spuštění dávkových koncových bodů a získání přístupu k výsledkům
Vyvolání dávkového koncového bodu aktivuje dávkovou úlohu bodování. name Úloha se vrátí z odpovědi vyvolání a dá se použít ke sledování průběhu dávkového vyhodnocování. Při spouštění modelů pro bodování v dávkových koncových bodech je potřeba zadat cestu ke vstupním datům, aby koncové body mohly najít data, která chcete určit. Následující příklad ukazuje, jak spustit novou úlohu pomocí ukázkových dat datové sady MNIST uložené v účtu služby Azure Storage.
Ke spuštění a vyvolání dávkového koncového bodu můžete použít Azure CLI, sadu Azure Machine Learning SDK nebo koncové body REST. Další podrobnosti o těchto možnostech najdete v tématu Vytváření úloh a vstupních dat pro dávkové koncové body.
Poznámka:
Jak funguje paralelizace?
Dávkové nasazení distribuují práci na úrovni souboru, což znamená, že složka obsahující 100 souborů s mini dávkami 10 souborů vygeneruje 10 dávek 10 souborů. Všimněte si, že k tomu dochází bez ohledu na velikost zahrnutých souborů. Pokud jsou vaše soubory příliš velké na zpracování ve velkých minidávkách, doporučujeme, abyste soubory rozdělili na menší soubory, abyste dosáhli vyšší úrovně paralelismu, nebo snížili počet souborů na minidávku. V současné době dávkové nasazení nemůžou počítat s nerovnoměrnou distribucí velikosti souboru.
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --input-type uri_folder --query name -o tsv)



Koncové body služby Batch podporují čtení souborů nebo složek umístěných v různých umístěních. Další informace o podporovanýchtypech
Monitorování průběhu provádění dávkových úloh
Dávkové úlohy vyhodnocování obvykle nějakou dobu trvá, než zpracuje celou sadu vstupů.
Následující kód zkontroluje stav úlohy a vypíše odkaz na studio Azure Machine Learning, kde najdete další podrobnosti.
az ml job show -n $JOB_NAME --web

Kontrola výsledků dávkového vyhodnocování
Výstupy úloh se ukládají v cloudovém úložišti, buď ve výchozím úložišti objektů blob pracovního prostoru, nebo v zadaném úložišti. Informace o tom, jak změnit výchozí hodnoty, najdete v tématu Konfigurace výstupního umístění. Následující kroky umožňují zobrazit výsledky vyhodnocování Průzkumník služby Azure Storage po dokončení úlohy:
Spuštěním následujícího kódu otevřete úlohu dávkového bodování v studio Azure Machine Learning. Odkaz job studio je také zahrnut v odpovědi
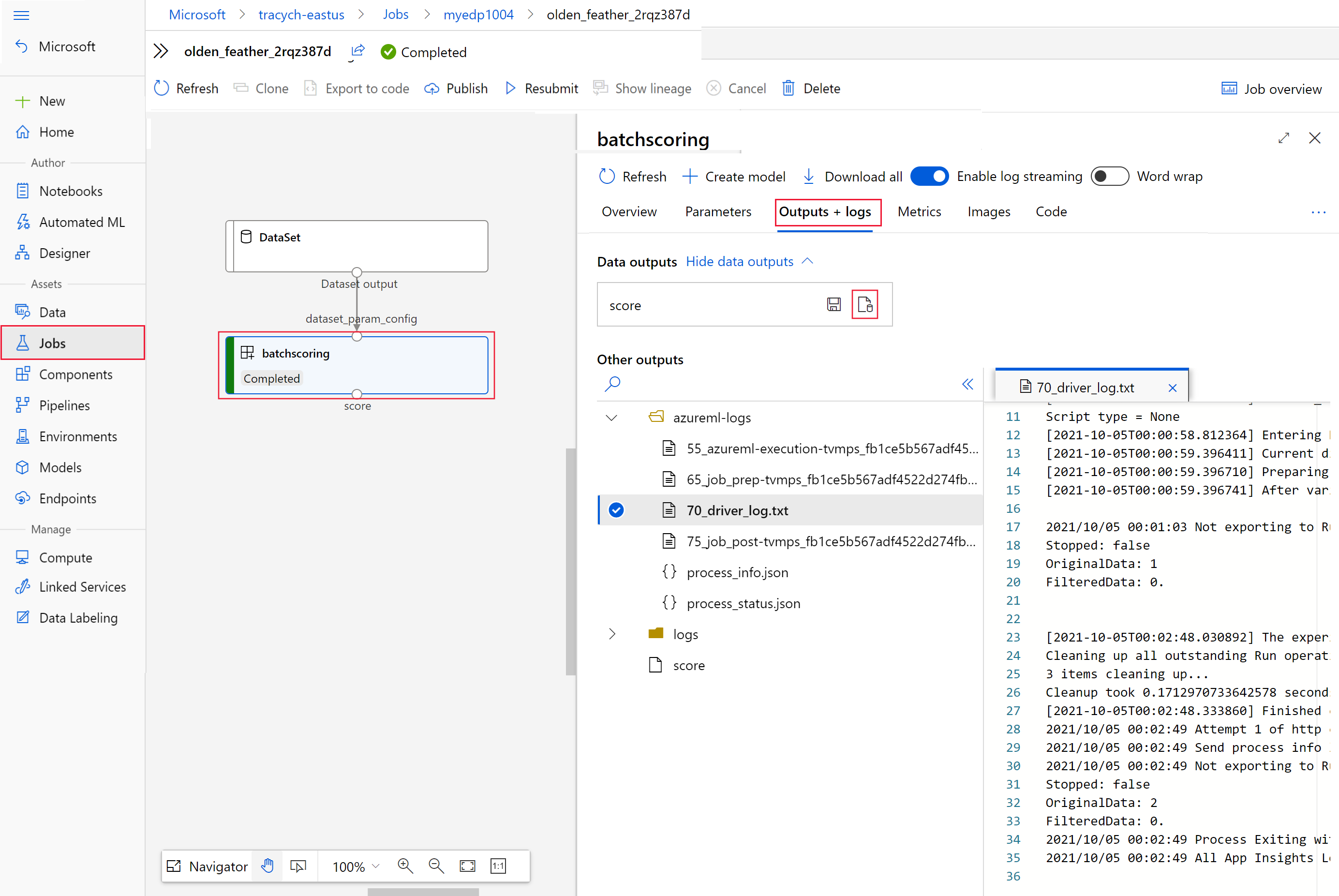
invoke, jako hodnotainteractionEndpoints.Studio.endpoint.az ml job show -n $JOB_NAME --webV grafu úlohy vyberte
batchscoringkrok.Vyberte kartu Výstupy a protokoly a pak vyberte Zobrazit výstupy dat.
Ve výstupech dat vyberte ikonu a otevřete Průzkumník služby Storage.
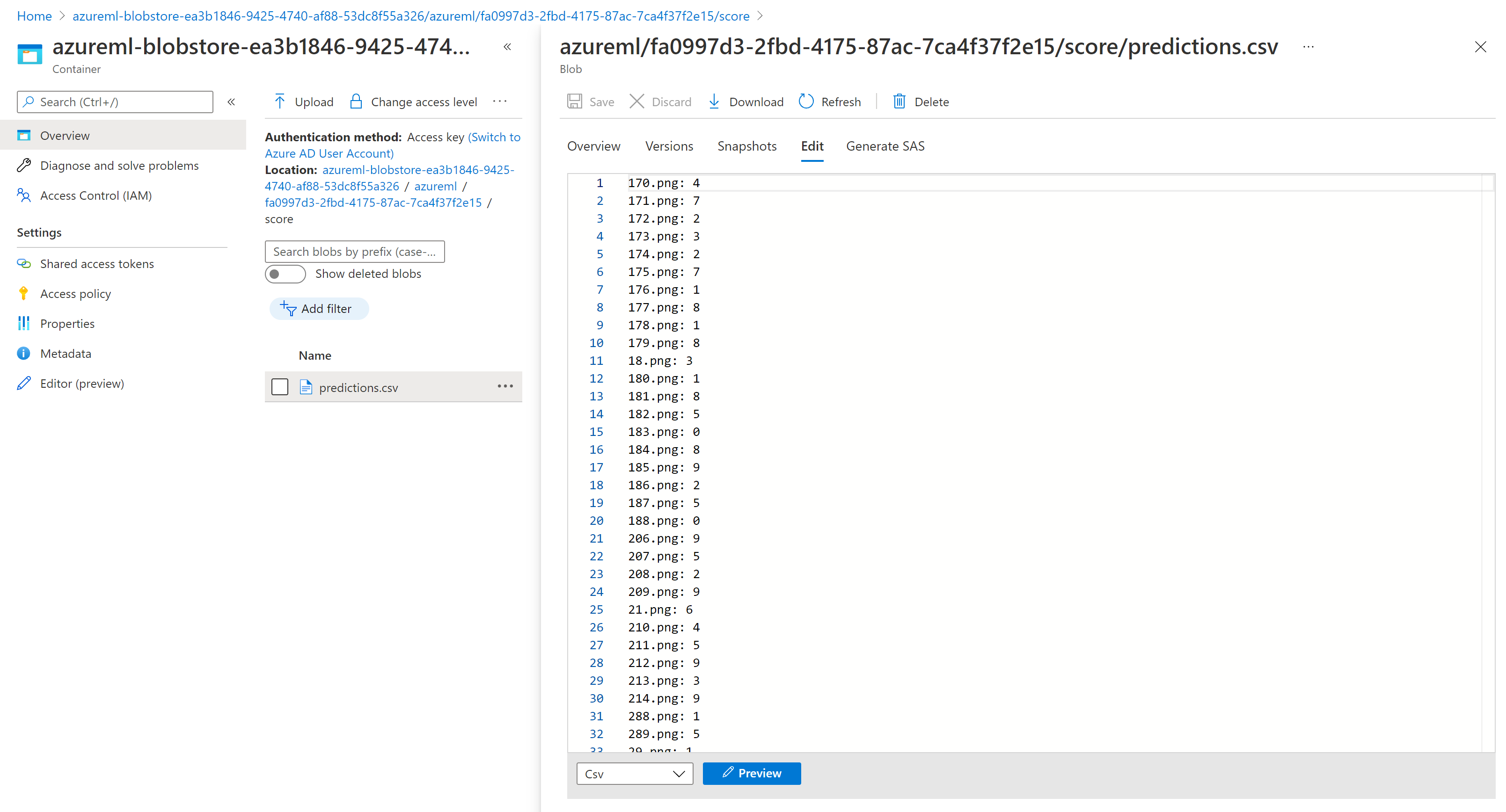
Výsledky vyhodnocování Průzkumník služby Storage se podobají následující ukázkové stránce:


Konfigurace výstupního umístění
Ve výchozím nastavení se výsledky dávkového vyhodnocování ukládají do výchozího úložiště objektů blob pracovního prostoru ve složce s názvem úlohy (identifikátor GUID vygenerovaný systémem). Při vyvolání dávkového koncového bodu můžete nakonfigurovat, kam se mají ukládat výstupy vyhodnocování.
Slouží output-path ke konfiguraci libovolné složky v registrovaném úložišti dat služby Azure Machine Learning. Syntaxe je --output-path stejná jako --input při zadávání složky, azureml://datastores/<datastore-name>/paths/<path-on-datastore>/tedy . Slouží --set output_file_name=<your-file-name> ke konfiguraci nového názvu výstupního souboru.
OUTPUT_FILE_NAME=predictions_`echo $RANDOM`.csv
OUTPUT_PATH="azureml://datastores/workspaceblobstore/paths/$ENDPOINT_NAME"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --output-path $OUTPUT_PATH --set output_file_name=$OUTPUT_FILE_NAME --query name -o tsv)

Upozorňující
Musíte použít jedinečné výstupní umístění. Pokud výstupní soubor existuje, úloha dávkového vyhodnocování selže.
Důležité
Na rozdíl od vstupů je možné výstupy ukládat jenom v úložištích dat Azure Machine Learning, která běží v účtech úložiště objektů blob.
Přepsání konfigurace nasazení pro každou úlohu
Při vyvolání dávkového koncového bodu je možné některá nastavení přepsat, aby se co nejlépe využily výpočetní prostředky a zlepšily výkon. Pro každou úlohu je možné nakonfigurovat následující nastavení:
- Počet instancí: Toto nastavení použijte k přepsání počtu instancí, které se mají vyžádat z výpočetního clusteru. Například pro větší objem datových vstupů můžete chtít použít více instancí, abyste urychlili koncové dávkové vyhodnocování.
- Velikost minidávkové dávky: Toto nastavení použijte k přepsání počtu souborů, které se mají zahrnout do každé minidávkové dávky. O počtu mini dávek se rozhoduje celkový počet vstupních souborů a velikost mini dávky. Menší velikost minidávkové dávky generuje více mini dávek. Mini dávky se dají spustit paralelně, ale můžou existovat další režijní náklady na plánování a vyvolání.
- Další nastavení, například maximální počet opakování, vypršení časového limitu a prahová hodnota chyby, se dají přepsat. Tato nastavení můžou mít vliv na dobu komplexního dávkového vyhodnocování pro různé úlohy.
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --mini-batch-size 20 --instance-count 5 --query name -o tsv)
Přidání nasazení do koncového bodu
Jakmile budete mít dávkový koncový bod s nasazením, můžete model dál upřesnit a přidat nová nasazení. Koncové body služby Batch budou dál obsluhovat výchozí nasazení při vývoji a nasazování nových modelů ve stejném koncovém bodu. Nasazení nemají vliv na sebe navzájem.
V tomto příkladu přidáte druhé nasazení, které používá model vytvořený pomocí Kerasu a TensorFlow k vyřešení stejného problému MNIST.
Přidání druhého nasazení
Vytvořte prostředí, ve kterém se bude spouštět dávkové nasazení. Zahrňte do prostředí jakoukoli závislost, která váš kód vyžaduje ke spuštění. Musíte také přidat knihovnu
azureml-core, protože je potřeba, aby dávkové nasazení fungovalo. Následující definice prostředí obsahuje požadované knihovny pro spuštění modelu s TensorFlow.Definice prostředí je součástí samotné definice nasazení jako anonymní prostředí.
environment: name: batch-tensorflow-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yamlPoužitý soubor conda vypadá takto:
deployment-keras/environment/conda.yaml
name: tensorflow-env channels: - conda-forge dependencies: - python=3.8.5 - pip - pip: - pandas - tensorflow - pillow - azureml-core - azureml-dataset-runtime[fuse]Vytvořte bodovací skript pro model:
deployment-keras/code/batch_driver.py
import os import numpy as np import pandas as pd import tensorflow as tf from typing import List from os.path import basename from PIL import Image from tensorflow.keras.models import load_model def init(): global model # AZUREML_MODEL_DIR is an environment variable created during deployment model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model") # load the model model = load_model(model_path) def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] for image_path in mini_batch: data = Image.open(image_path) data = np.array(data) data_batch = tf.expand_dims(data, axis=0) # perform inference pred = model.predict(data_batch) # Compute probabilities, classes and labels pred_prob = tf.math.reduce_max(tf.math.softmax(pred, axis=-1)).numpy() pred_class = tf.math.argmax(pred, axis=-1).numpy() results.append( { "file": basename(image_path), "class": pred_class[0], "probability": pred_prob, } ) return pd.DataFrame(results)Vytvoření definice nasazení
deployment-keras/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-keras-dpl description: A deployment using Keras with TensorFlow to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-keras path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-tensorflow-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csvVytvořte nasazení:
Spuštěním následujícího kódu vytvořte dávkové nasazení v rámci koncového bodu dávky a nastavte ho jako výchozí nasazení.
az ml batch-deployment create --file deployment-keras/deployment.yml --endpoint-name $ENDPOINT_NAMETip
V
--set-defaulttomto případě chybí parametr. Osvědčeným postupem pro produkční scénáře je vytvořit nové nasazení, aniž byste ho nastavili jako výchozí. Potom ho ověřte a aktualizujte výchozí nasazení později.
Testování jiného než výchozího dávkového nasazení
Pokud chcete otestovat nové jiné než výchozí nasazení, musíte znát název nasazení, které chcete spustit.
DEPLOYMENT_NAME="mnist-keras-dpl"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --deployment-name $DEPLOYMENT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --input-type uri_folder --query name -o tsv)
Oznámení --deployment-name se používá k určení nasazení, které se má provést. Tento parametr umožňuje invoke nevýkonné nasazení bez aktualizace výchozího nasazení dávkového koncového bodu.
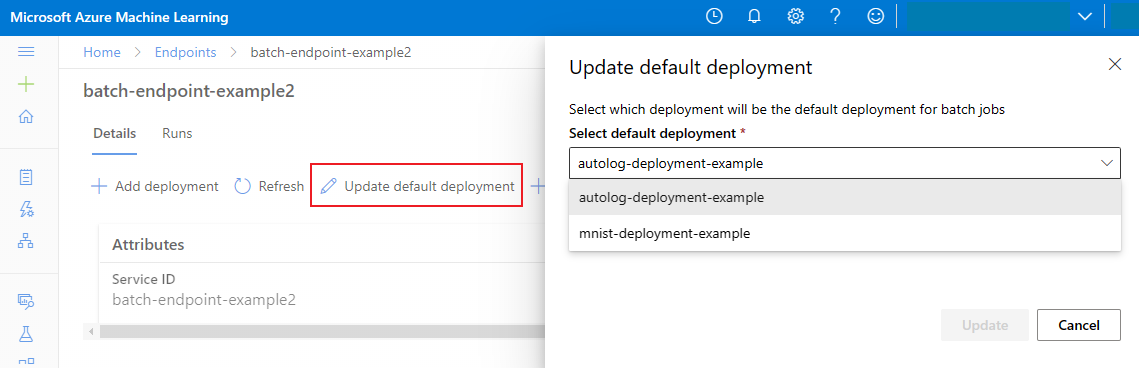
Aktualizace výchozího dávkového nasazení
I když můžete vyvolat konkrétní nasazení uvnitř koncového bodu, obvykle budete chtít vyvolat samotný koncový bod a nechat koncový bod rozhodnout, které nasazení použít – výchozí nasazení. Můžete změnit výchozí nasazení (a v důsledku toho změnit model obsluhující nasazení) beze změny smlouvy s uživatelem, který vyvolá koncový bod. K aktualizaci výchozího nasazení použijte následující kód:
az ml batch-endpoint update --name $ENDPOINT_NAME --set defaults.deployment_name=$DEPLOYMENT_NAME
Odstranění dávkového koncového bodu a nasazení
Pokud nebudete používat staré dávkové nasazení, odstraňte ho spuštěním následujícího kódu. --yes slouží k potvrzení odstranění.
az ml batch-deployment delete --name mnist-torch-dpl --endpoint-name $ENDPOINT_NAME --yes
Spuštěním následujícího kódu odstraňte koncový bod dávky a všechna jeho základní nasazení. Úlohy dávkového vyhodnocování se neodstraní.
az ml batch-endpoint delete --name $ENDPOINT_NAME --yes