Sledování experimentů Azure Databricks ML s využitím MLflow a Azure Machine Learning
MLflow je opensourcová knihovna pro správu životního cyklu experimentů strojového učení. Pomocí MLflow můžete integrovat Azure Databricks se službou Azure Machine Learning, abyste měli jistotu, že z obou produktů získáte to nejlepší.
V tomto článku se dozvíte:
- Požadované knihovny potřebné k používání MLflow s Azure Databricks a Azure Machine Learning.
- Sledování spuštění Azure Databricks pomocí MLflow ve službě Azure Machine Learning
- Jak protokolovat modely pomocí MLflow , abyste je zaregistrovali ve službě Azure Machine Learning.
- Nasazení a využívání modelů registrovaných ve službě Azure Machine Learning
Požadavky
azureml-mlflowNainstalujte balíček, který zpracovává připojení ke službě Azure Machine Learning, včetně ověřování.- Pracovní prostor a cluster Azure Databricks
- Vytvořte pracovní prostor Azure Machine Learning.
Příklady poznámkových bloků
Modely trénování v Azure Databricks a jejich nasazení ve službě Azure Machine Learning ukazují, jak trénovat modely v Azure Databricks a nasazovat je ve službě Azure Machine Learning. Zahrnuje také způsob zpracování případů, kdy chcete také sledovat experimenty a modely s instancí MLflow v Azure Databricks a využívat Azure Machine Learning k nasazení.
Instalace knihoven
Pokud chcete do clusteru nainstalovat knihovny, přejděte na kartu Knihovny a vyberte Nainstalovat nový.
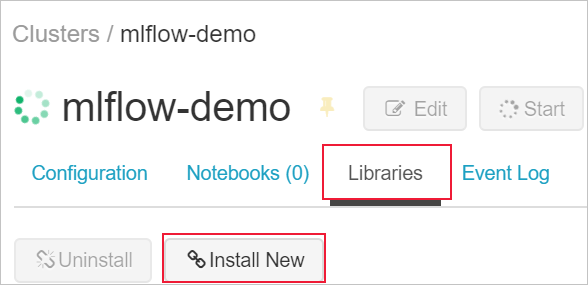
Do pole Balíček zadejte azureml-mlflow a pak vyberte nainstalovat. Tento krok podle potřeby opakujte, pokud chcete do clusteru pro experiment nainstalovat další balíčky.
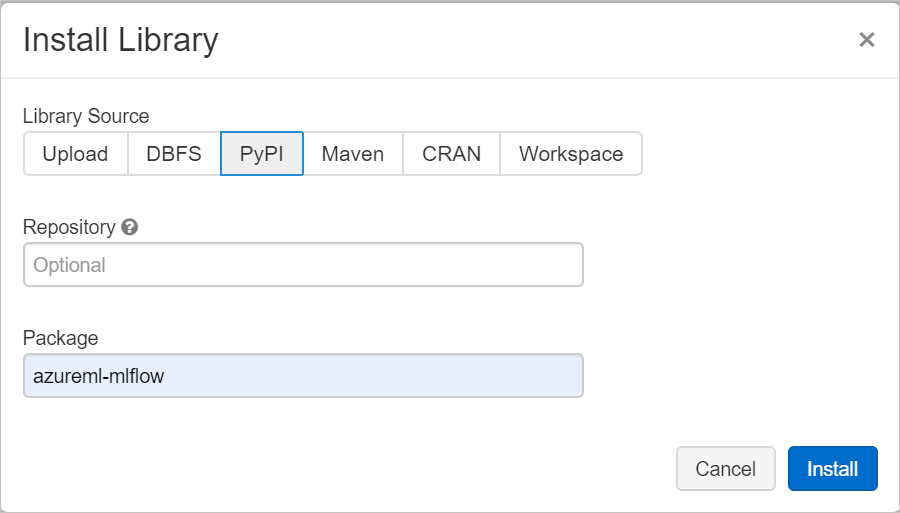
Sledování spuštění Azure Databricks s využitím MLflow
Azure Databricks je možné nakonfigurovat tak, aby sledoval experimenty pomocí MLflow dvěma způsoby:
- Sledování v pracovním prostoru Azure Databricks i v pracovním prostoru Azure Machine Learning (duální sledování)
- Sledování výhradně ve službě Azure Machine Learning
Ve výchozím nastavení je pro vás při propojení pracovního prostoru Azure Databricks nakonfigurované duální sledování.
Duální sledování ve službě Azure Databricks a Azure Machine Learning
Propojení pracovního prostoru ADB s pracovním prostorem Azure Machine Learning umožňuje současně sledovat data experimentu v pracovním prostoru Azure Machine Learning a pracovním prostoru Azure Databricks. Označuje se jako duální sledování.
Upozorňující
V tuto chvíli se nepodporuje duální sledování v pracovním prostoru Azure Machine Learning s povoleným privátním propojením. Místo toho nakonfigurujte výhradní sledování s pracovním prostorem Azure Machine Learning.
Upozorňující
Duální sledování v Microsoft Azure provozovaném společností 21Vianet v tuto chvíli nepodporuje. Místo toho nakonfigurujte výhradní sledování s pracovním prostorem Azure Machine Learning.
Pokud chcete pracovní prostor ADB propojit s novým nebo existujícím pracovním prostorem služby Azure Machine Learning,
- Přihlaste se na portál Azure.
- Přejděte na stránku Přehled pracovního prostoru ADB.
- V pravém dolním rohu vyberte tlačítko Propojit pracovní prostor Azure Machine Learning.
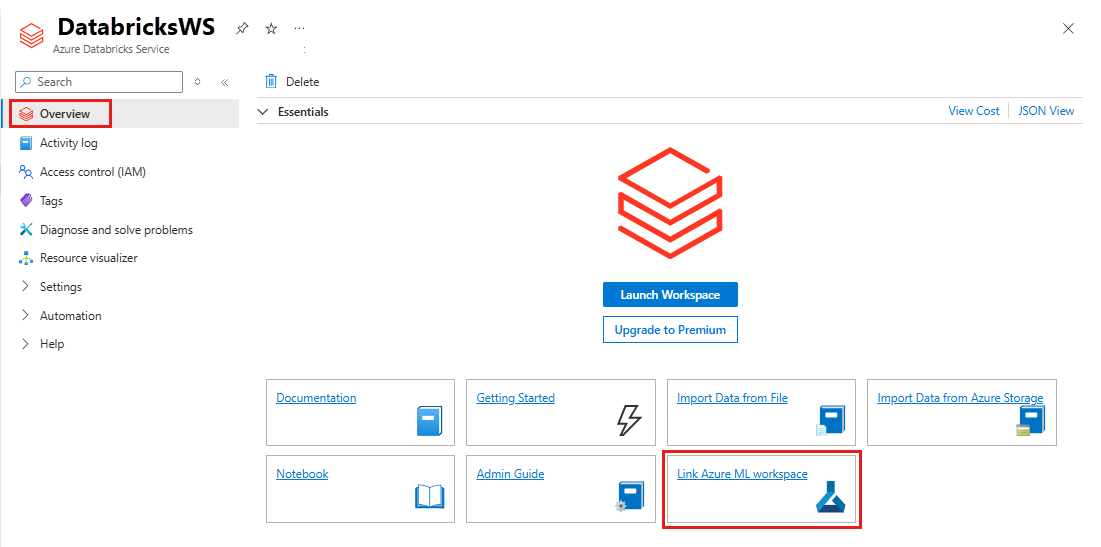
Po propojení pracovního prostoru Azure Databricks s pracovním prostorem Azure Machine Learning se sledování MLflow automaticky nastaví tak, aby se sledovalo na všech následujících místech:
- Propojený pracovní prostor Azure Machine Learning.
- Váš původní pracovní prostor ADB
Tok ML můžete v Azure Databricks použít stejným způsobem jako vy. Následující příklad nastaví název experimentu, protože se obvykle provádí v Azure Databricks a začne protokolovat některé parametry:
import mlflow
experimentName = "/Users/{user_name}/{experiment_folder}/{experiment_name}"
mlflow.set_experiment(experimentName)
with mlflow.start_run():
mlflow.log_param('epochs', 20)
pass
Poznámka:
Stejně jako u sledování nepodporují registry modelů registraci modelů současně ve službě Azure Machine Learning i Azure Databricks. Jeden nebo druhý se musí použít. Další podrobnosti najdete v části Registrace modelů v registru pomocí MLflow .
Sledování výhradně v pracovním prostoru Azure Machine Learning
Pokud dáváte přednost správě sledovaných experimentů v centralizované lokalitě, můžete nastavit sledování MLflow tak, aby se sledovalo jenom v pracovním prostoru Azure Machine Learning. Tato konfigurace má výhodu, že umožňuje snadnější cestu k nasazení pomocí možností nasazení služby Azure Machine Learning.
Upozorňující
V případě pracovního prostoru Azure Machine Learning s povoleným privátním propojením musíte nasadit Azure Databricks ve vlastní síti (injektáž virtuální sítě), abyste zajistili správné připojení.
Musíte nakonfigurovat identifikátor URI pro sledování MLflow tak, aby odkazoval výhradně na Azure Machine Learning, jak je znázorněno v následujícím příkladu:
Konfigurace identifikátoru URI sledování
Získejte identifikátor URI sledování pro váš pracovní prostor:
PLATÍ PRO:
 Rozšíření Azure CLI ml v2 (aktuální)
Rozšíření Azure CLI ml v2 (aktuální)Přihlaste se a nakonfigurujte pracovní prostor:
az account set --subscription <subscription> az configure --defaults workspace=<workspace> group=<resource-group> location=<location>Identifikátor URI sledování můžete získat pomocí
az ml workspacepříkazu:az ml workspace show --query mlflow_tracking_uri
Konfigurace identifikátoru URI sledování:
Pak metoda
set_tracking_uri()odkazuje identifikátor URI sledování MLflow na tento identifikátor URI.import mlflow mlflow.set_tracking_uri(mlflow_tracking_uri)Tip
Při práci na sdílených prostředích, jako je cluster Azure Databricks, cluster Azure Synapse Analytics nebo podobný, je užitečné nastavit proměnnou
MLFLOW_TRACKING_URIprostředí na úrovni clusteru, aby automaticky nakonfiguroval identifikátor URI pro sledování MLflow tak, aby odkazoval na Azure Machine Learning pro všechny relace spuštěné v clusteru, a ne na základě jednotlivých relací.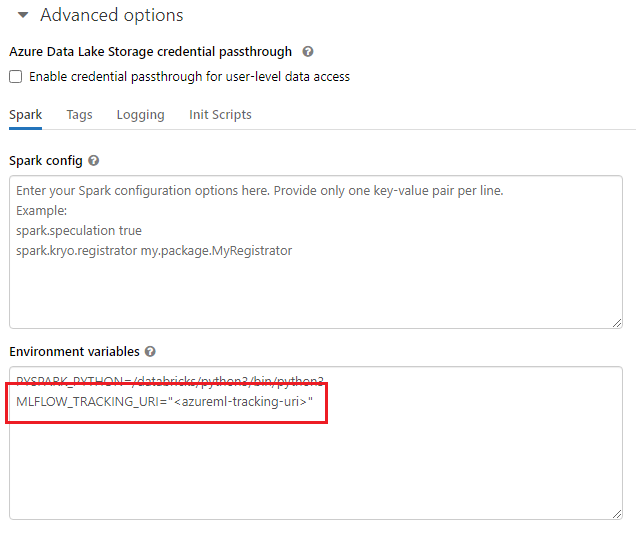
Jakmile je proměnná prostředí nakonfigurovaná, všechny experimenty spuštěné v tomto clusteru se budou sledovat ve službě Azure Machine Learning.
Konfigurace ověřování
Jakmile je sledování nakonfigurované, budete také muset nakonfigurovat, jak se ověřování musí stát s přidruženým pracovním prostorem. Modul plug-in Azure Machine Learning pro MLflow ve výchozím nastavení provede interaktivní ověřování otevřením výchozího prohlížeče a zobrazí výzvu k zadání přihlašovacích údajů. Informace o konfiguraci MLflow pro Azure Machine Learning: Konfigurace ověřování pro další způsoby konfigurace ověřování pro MLflow v pracovních prostorech Azure Machine Learning
U interaktivních úloh, kde je uživatel připojený k relaci, můžete spoléhat na interaktivní ověřování, a proto není potřeba provádět žádnou další akci.
Upozorňující
Interaktivní ověřování prohlížeče zablokuje provádění kódu při zobrazení výzvy k zadání přihlašovacích údajů. Není to vhodná možnost pro ověřování v bezobslužných prostředích, jako jsou trénovací úlohy. Doporučujeme nakonfigurovat jiný režim ověřování.
V těchto scénářích, ve kterých se vyžaduje bezobslužné spuštění, budete muset nakonfigurovat instanční objekt pro komunikaci se službou Azure Machine Learning.
import os
os.environ["AZURE_TENANT_ID"] = "<AZURE_TENANT_ID>"
os.environ["AZURE_CLIENT_ID"] = "<AZURE_CLIENT_ID>"
os.environ["AZURE_CLIENT_SECRET"] = "<AZURE_CLIENT_SECRET>"
Tip
Při práci na sdílených prostředích je vhodné nakonfigurovat tyto proměnné prostředí na výpočetních prostředcích. Osvědčeným postupem je spravovat jako tajné kódy v instanci služby Azure Key Vault, kdykoli je to možné. V Azure Databricks můžete například použít tajné kódy v proměnných prostředí následujícím způsobem v konfiguraci clusteru: AZURE_CLIENT_SECRET={{secrets/<scope-name>/<secret-name>}} Informace o tom, jak to udělat v Azure Databricks, najdete v tématu Referenční informace o tajném kódu v proměnné prostředí nebo se podívejte na podobnou dokumentaci ve vaší platformě.
Názvy experimentů ve službě Azure Machine Learning
Pokud je MLflow nakonfigurovaný tak, aby experimenty sledovaly výhradně v pracovním prostoru Azure Machine Learning, musí zásady vytváření názvů experimentu dodržovat zásady vytváření názvů, které používá Azure Machine Learning. V Azure Databricks jsou experimenty pojmenovány cestou k umístění, kde je experiment uložen, například /Users/alice@contoso.com/iris-classifier. Ve službě Azure Machine Learning ale musíte zadat název experimentu přímo. Stejně jako v předchozím příkladu by stejný experiment byl pojmenován iris-classifier přímo:
mlflow.set_experiment(experiment_name="experiment-name")
Sledování parametrů, metrik a artefaktů
Tok ML můžete v Azure Databricks použít stejným způsobem jako vy. Podrobnosti najdete v tématu Protokol a zobrazení metrik a souborů protokolů.
Protokolování modelů pomocí MLflow
Po vytrénování modelu ho můžete pomocí metody protokolovat na sledovací server mlflow.<model_flavor>.log_model() . <model_flavor>, odkazuje na architekturu přidruženou k modelu. Zjistěte, jaké typy modelů jsou podporované. V následujícím příkladu je zaregistrovaný model vytvořený pomocí knihovny Spark MLLib:
mlflow.spark.log_model(model, artifact_path = "model")
Stojí za zmínku, že příchuť spark neodpovídá skutečnosti, že trénujeme model v clusteru Spark, ale kvůli použité trénovací platformě (model můžete dokonale vytrénovat pomocí TensorFlow se Sparkem, a proto by se použila příchuť k použití tensorflow).
Modely se protokolují uvnitř sledovaného spuštění. To znamená, že modely jsou dostupné v Azure Databricks i Azure Machine Learning (výchozí) nebo výhradně ve službě Azure Machine Learning, pokud jste nakonfigurovali identifikátor URI sledování tak, aby na něj odkazoval.
Důležité
Všimněte si, že parametr zde registered_model_name nebyl zadán. Další podrobnosti o dopadech tohoto parametru a fungování registru najdete v části Registrace modelů v registru pomocí MLflow .
Registrace modelů v registru pomocí MLflow
Stejně jako u sledování nemůžou registry modelů fungovat současně ve službě Azure Databricks a Azure Machine Learning. Jeden nebo druhý se musí použít. Ve výchozím nastavení se pracovní prostor Azure Databricks používá pro registry modelů; pokud jste se rozhodli nastavit sledování MLflow tak, aby se sledovalo jenom v pracovním prostoru Služby Azure Machine Learning, registr modelů je pracovní prostor Azure Machine Learning.
Při zvažování, že používáte výchozí konfiguraci, následující řádek protokoluje model uvnitř odpovídajících spuštění Azure Databricks i Azure Machine Learning, ale zaregistruje ho jenom v Azure Databricks:
mlflow.spark.log_model(model, artifact_path = "model",
registered_model_name = 'model_name')
Pokud zaregistrovaný model s názvem neexistuje, metoda zaregistruje nový model, vytvoří verzi 1 a vrátí objekt ModelVersion MLflow.
Pokud zaregistrovaný model s názvem již existuje, metoda vytvoří novou verzi modelu a vrátí objekt verze.
Použití registru služby Azure Machine Learning s MLflow
Pokud chcete místo Azure Databricks používat registr modelů Služby Azure Machine Learning, doporučujeme nastavit sledování MLflow tak, aby se sledovalo jenom v pracovním prostoru Azure Machine Learning. Tím se odstraní nejednoznačnost míst, kde se modely registrují, a zjednoduší se tím složitost.
Pokud ale chcete dál používat možnosti duálního sledování, ale zaregistrovat modely ve službě Azure Machine Learning, můžete MLflow instruovat, aby pro registry modelů používal Azure Machine Learning a konfiguroval identifikátor URI registru modelů MLflow. Tento identifikátor URI má stejný formát a hodnotu jako identifikátor URI sledování MLflow.
mlflow.set_registry_uri(azureml_mlflow_uri)
Poznámka:
Hodnota azureml_mlflow_uri byla získána stejným způsobem, jakým byla degradovaná v nastavení sledování MLflow, aby se sledovala pouze v pracovním prostoru Azure Machine Learning.
Úplný příklad tohoto scénáře najdete v ukázkových modelech trénování v Azure Databricks a jejich nasazení ve službě Azure Machine Learning.
Nasazení a využívání modelů zaregistrovaných ve službě Azure Machine Learning
Modely zaregistrované ve službě Azure Machine Learning Service pomocí MLflow je možné využívat jako:
Koncový bod služby Azure Machine Learning (v reálném čase a dávka): Toto nasazení umožňuje využívat možnosti nasazení služby Azure Machine Learning pro odvozování v reálném čase i dávkové odvozování ve službě Azure Container Instances (ACI), Azure Kubernetes (AKS) nebo našich spravovaných koncových bodů odvozování.
Objekty modelu MLFlow nebo uživatelem definované funkce Pandas, které je možné použít v poznámkových blocích Azure Databricks ve streamovaných nebo dávkových kanálech.
Nasazení modelů do koncových bodů služby Azure Machine Learning
Modul plug-in můžete využít azureml-mlflow k nasazení modelu do pracovního prostoru Azure Machine Learning. Podívejte se , jak nasadit stránku modelů MLflow, kde najdete podrobné informace o tom, jak nasadit modely do různých cílů.
Důležité
Aby bylo možné je nasadit, musí být modely zaregistrované v registru služby Azure Machine Learning. Pokud se vaše modely zaregistrují v instanci MLflow v Azure Databricks, budete je muset znovu zaregistrovat ve službě Azure Machine Learning. V takovém případě si projděte ukázkové modely trénování v Azure Databricks a nasaďte je ve službě Azure Machine Learning.
Nasazení modelů do ADB pro dávkové vyhodnocování s využitím uživatelem definovaných funkcí
Pro dávkové vyhodnocování můžete zvolit clustery Azure Databricks. Pomocí mlflow můžete přeložit libovolný model z registru, ke kterému jste připojení. Obvykle použijete jednu z následujících dvou metod:
- Pokud jste model natrénovali a vytvořili pomocí knihoven Sparku (například
MLLib), použijtemlflow.pyfunc.spark_udfho k načtení modelu a jeho použití jako uživatelem definovaného uživatelem Spark Pandas k určení skóre nových dat. - Pokud váš model nebyl vytrénovaný nebo sestavený pomocí knihoven Sparku, použijte
mlflow.pyfunc.load_modelnebomlflow.<flavor>.load_modelnačtěte model v ovladači clusteru. Všimnětesich Všimněte si také, že MLflow neinstaluje žádnou knihovnu, kterou model vyžaduje ke spuštění. Tyto knihovny musí být před spuštěním nainstalované v clusteru.
Následující příklad ukazuje, jak načíst model z registru s názvem uci-heart-classifier a použít ho jako uživatelem definovaného uživatelem Spark Pandas k určení skóre nových dat.
from pyspark.sql.types import ArrayType, FloatType
model_name = "uci-heart-classifier"
model_uri = "models:/"+model_name+"/latest"
#Create a Spark UDF for the MLFlow model
pyfunc_udf = mlflow.pyfunc.spark_udf(spark, model_uri)
Po načtení modelu můžete použít k určení skóre nových dat:
#Load Scoring Data into Spark Dataframe
scoreDf = spark.table({table_name}).where({required_conditions})
#Make Prediction
preds = (scoreDf
.withColumn('target_column_name', pyfunc_udf('Input_column1', 'Input_column2', ' Input_column3', …))
)
display(preds)
Vyčištění prostředků
Pokud chcete zachovat pracovní prostor Azure Databricks, ale už ho nepotřebujete, můžete pracovní prostor Azure Machine Learning odstranit. Výsledkem této akce je zrušení propojení pracovního prostoru Azure Databricks a pracovního prostoru Azure Machine Learning.
Pokud nemáte v úmyslu používat protokolované metriky a artefakty ve vašem pracovním prostoru, možnost je odstranit jednotlivě, není v tuto chvíli dostupná. Místo toho odstraňte skupinu prostředků, která obsahuje účet úložiště a pracovní prostor, takže vám nebudou účtovány žádné poplatky:
Úplně nalevo na webu Azure Portal vyberte Skupiny prostředků.
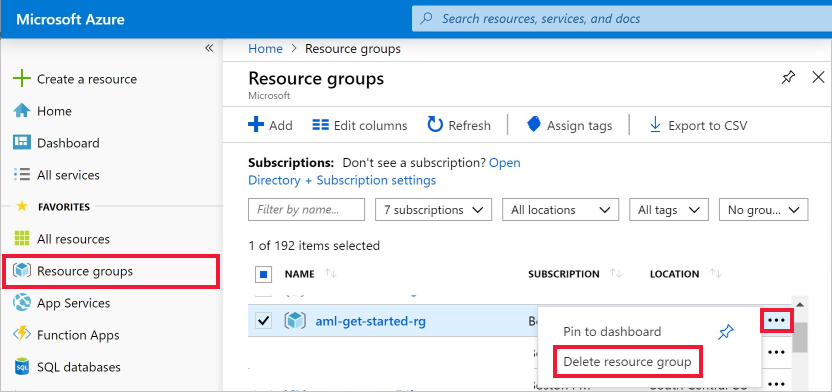
V seznamu vyberte skupinu prostředků, kterou jste vytvořili.
Vyberte Odstranit skupinu prostředků.
Zadejte název skupiny prostředků. Poté vyberte Odstranit.
Další kroky
- Nasaďte modely MLflow jako webovou službu Azure.
- Spravujte své modely.
- Sledování úloh experimentů pomocí MLflow a Azure Machine Learning
- Přečtěte si další informace o Azure Databricks a MLflow.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro