Sledování experimentů Azure Synapse Analytics ML pomocí MLflow a Azure Machine Learning
V tomto článku se dozvíte, jak povolit MLflow připojení ke službě Azure Machine Learning při práci v pracovním prostoru Azure Synapse Analytics. Tuto konfiguraci můžete využít ke sledování, správě modelů a nasazení modelu.
MLflow je opensourcová knihovna pro správu životního cyklu experimentů strojového učení. MLFlow Tracking je komponenta MLflow, která protokoluje a sleduje metriky trénování a artefakty modelu. Přečtěte si další informace o MLflow.
Pokud máte projekt MLflow pro trénování pomocí Azure Machine Learning, přečtěte si téma Trénování modelů ML pomocí projektů MLflow a Azure Machine Learning (Preview)
Požadavky
- Pracovní prostor a cluster Azure Synapse Analytics
- Pracovní prostor služby Azure Machine Learning
Instalace knihoven
Instalace knihoven ve vyhrazeném clusteru ve službě Azure Synapse Analytics:
Vytvořte
requirements.txtsoubor s balíčky, které experimenty vyžadují, ale ujistěte se, že obsahuje i následující balíčky:requirements.txt
mlflow azureml-mlflow azure-ai-mlPřejděte na portál pracovního prostoru Azure Analytics.
Přejděte na kartu Spravovat a vyberte Fondy Apache Sparku.
Klikněte na tři tečky vedle názvu clusteru a vyberte Balíčky.
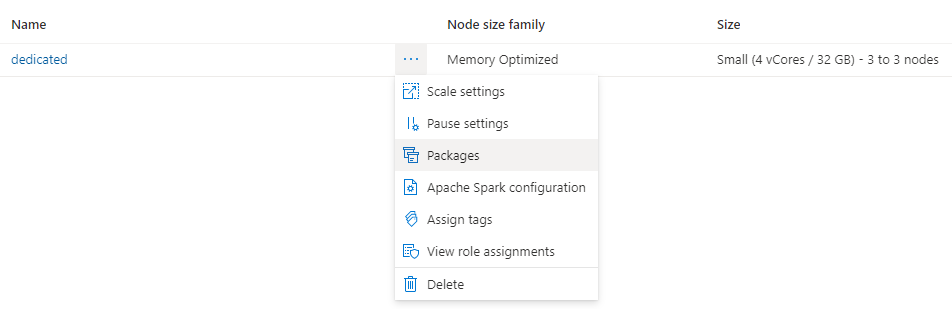
V části Soubory požadavků klikněte na Nahrát.
Nahrajte soubor
requirements.txt.Počkejte, než se cluster restartuje.
Sledování experimentů s využitím MLflow
Azure Synapse Analytics je možné nakonfigurovat tak, aby sledoval experimenty pomocí MLflow do pracovního prostoru Azure Machine Learning. Azure Machine Learning poskytuje centralizované úložiště pro správu celého životního cyklu experimentů, modelů a nasazení. Má také výhodu, že umožňuje snadnější cestu k nasazení pomocí možností nasazení služby Azure Machine Learning.
Konfigurace poznámkových bloků pro použití MLflow připojeného ke službě Azure Machine Learning
Pokud chcete azure Machine Learning použít jako centralizované úložiště pro experimenty, můžete využít MLflow. V každém poznámkovém bloku, na kterém pracujete, musíte nakonfigurovat identifikátor URI sledování tak, aby odkazoval na pracovní prostor, který budete používat. Následující příklad ukazuje, jak se dá provést:
Konfigurace identifikátoru URI sledování
Získejte identifikátor URI sledování pro váš pracovní prostor:
PLATÍ PRO:
 Rozšíření Azure CLI ml v2 (aktuální)
Rozšíření Azure CLI ml v2 (aktuální)Přihlaste se a nakonfigurujte pracovní prostor:
az account set --subscription <subscription> az configure --defaults workspace=<workspace> group=<resource-group> location=<location>Identifikátor URI sledování můžete získat pomocí
az ml workspacepříkazu:az ml workspace show --query mlflow_tracking_uri
Konfigurace identifikátoru URI sledování:
Pak metoda
set_tracking_uri()odkazuje identifikátor URI sledování MLflow na tento identifikátor URI.import mlflow mlflow.set_tracking_uri(mlflow_tracking_uri)Tip
Při práci na sdílených prostředích, jako je cluster Azure Databricks, cluster Azure Synapse Analytics nebo podobný, je užitečné nastavit proměnnou
MLFLOW_TRACKING_URIprostředí na úrovni clusteru, aby automaticky nakonfiguroval identifikátor URI pro sledování MLflow tak, aby odkazoval na Azure Machine Learning pro všechny relace spuštěné v clusteru, a ne na základě jednotlivých relací.
Konfigurace ověřování
Jakmile je sledování nakonfigurované, budete také muset nakonfigurovat, jak se ověřování musí stát s přidruženým pracovním prostorem. Modul plug-in Azure Machine Learning pro MLflow ve výchozím nastavení provede interaktivní ověřování otevřením výchozího prohlížeče a zobrazí výzvu k zadání přihlašovacích údajů. Informace o konfiguraci MLflow pro Azure Machine Learning: Konfigurace ověřování pro další způsoby konfigurace ověřování pro MLflow v pracovních prostorech Azure Machine Learning
U interaktivních úloh, kde je uživatel připojený k relaci, můžete spoléhat na interaktivní ověřování, a proto není potřeba provádět žádnou další akci.
Upozorňující
Interaktivní ověřování v prohlížeči blokuje provádění kódu při zobrazení výzvy k zadání přihlašovacích údajů. Tento přístup není vhodný pro ověřování v bezobslužných prostředích, jako jsou trénovací úlohy. Doporučujeme nakonfigurovat jiný režim ověřování.
V těchto scénářích, ve kterých se vyžaduje bezobslužné spuštění, musíte nakonfigurovat instanční objekt pro komunikaci se službou Azure Machine Learning.
import os
os.environ["AZURE_TENANT_ID"] = "<AZURE_TENANT_ID>"
os.environ["AZURE_CLIENT_ID"] = "<AZURE_CLIENT_ID>"
os.environ["AZURE_CLIENT_SECRET"] = "<AZURE_CLIENT_SECRET>"
Tip
Při práci na sdílených prostředích doporučujeme nakonfigurovat tyto proměnné prostředí ve výpočetním prostředí. Osvědčeným postupem je spravovat jako tajné kódy v instanci služby Azure Key Vault.
V Azure Databricks můžete například použít tajné kódy v proměnných prostředí následujícím způsobem v konfiguraci clusteru: AZURE_CLIENT_SECRET={{secrets/<scope-name>/<secret-name>}} Další informace o implementaci tohoto přístupu v Azure Databricks najdete v tématu Odkazování na tajný kód v proměnné prostředí nebo v dokumentaci pro vaši platformu.
Názvy experimentů ve službě Azure Machine Learning
Azure Machine Learning ve výchozím nastavení sleduje spuštění ve výchozím experimentu s názvem Default. Obvykle je vhodné nastavit experiment, na který budete pracovat. K nastavení názvu experimentu použijte následující syntaxi:
mlflow.set_experiment(experiment_name="experiment-name")
Sledování parametrů, metrik a artefaktů
Pak můžete MLflow použít ve službě Azure Synapse Analytics stejným způsobem, jako jste zvyklí. Podrobnosti najdete v tématu Protokol a zobrazení metrik a souborů protokolů.
Registrace modelů v registru pomocí MLflow
Modely je možné zaregistrovat v pracovním prostoru Azure Machine Learning, který nabízí centralizované úložiště pro správu jejich životního cyklu. Následující příklad zaznamená model natrénovaný pomocí knihovny Spark MLLib a zaregistruje ho také v registru.
mlflow.spark.log_model(model,
artifact_path = "model",
registered_model_name = "model_name")
Pokud zaregistrovaný model s názvem neexistuje, metoda zaregistruje nový model, vytvoří verzi 1 a vrátí objekt ModelVersion MLflow.
Pokud zaregistrovaný model s názvem již existuje, metoda vytvoří novou verzi modelu a vrátí objekt verze.
Modely zaregistrované ve službě Azure Machine Learning můžete spravovat pomocí MLflow. Další podrobnosti najdete v článku Správa registrů modelů ve službě Azure Machine Learning pomocí MLflow .
Nasazení a využívání modelů zaregistrovaných ve službě Azure Machine Learning
Modely zaregistrované ve službě Azure Machine Learning Service pomocí MLflow je možné využívat jako:
Koncový bod služby Azure Machine Learning (v reálném čase a dávka): Toto nasazení umožňuje využívat možnosti nasazení služby Azure Machine Learning pro odvozování v reálném čase i dávkové odvozování ve službě Azure Container Instances (ACI), Azure Kubernetes (AKS) nebo našich spravovaných koncových bodů.
Objekty modelu MLFlow nebo uživatelem definované soubory Pandas, které je možné použít v poznámkových blocích Azure Synapse Analytics ve streamovaných nebo dávkových kanálech.
Nasazení modelů do koncových bodů služby Azure Machine Learning
Modul plug-in můžete využít azureml-mlflow k nasazení modelu do pracovního prostoru Azure Machine Learning. Podívejte se , jak nasadit stránku modelů MLflow, kde najdete podrobné informace o tom, jak nasadit modely do různých cílů.
Důležité
Aby bylo možné je nasadit, musí být modely zaregistrované v registru služby Azure Machine Learning. Azure Machine Learning nepodporuje nasazení neregistrovaných modelů.
Nasazení modelů pro dávkové bodování pomocí funkcí definovaných uživatelem
Pro dávkové vyhodnocování můžete zvolit clustery Azure Synapse Analytics. Model MLFlow se načte a použije se jako UDF Spark Pandas k určení skóre nových dat.
from pyspark.sql.types import ArrayType, FloatType
model_uri = "runs:/"+last_run_id+ {model_path}
#Create a Spark UDF for the MLFlow model
pyfunc_udf = mlflow.pyfunc.spark_udf(spark, model_uri)
#Load Scoring Data into Spark Dataframe
scoreDf = spark.table({table_name}).where({required_conditions})
#Make Prediction
preds = (scoreDf
.withColumn('target_column_name', pyfunc_udf('Input_column1', 'Input_column2', ' Input_column3', …))
)
display(preds)
Vyčištění prostředků
Pokud chcete zachovat pracovní prostor Azure Synapse Analytics, ale už ho nepotřebujete, můžete pracovní prostor Azure Machine Learning odstranit. Pokud nemáte v úmyslu používat protokolované metriky a artefakty ve vašem pracovním prostoru, možnost je odstranit jednotlivě, není v tuto chvíli dostupná. Místo toho odstraňte skupinu prostředků, která obsahuje účet úložiště a pracovní prostor, takže vám nebudou účtovány žádné poplatky:
Úplně nalevo na webu Azure Portal vyberte Skupiny prostředků.
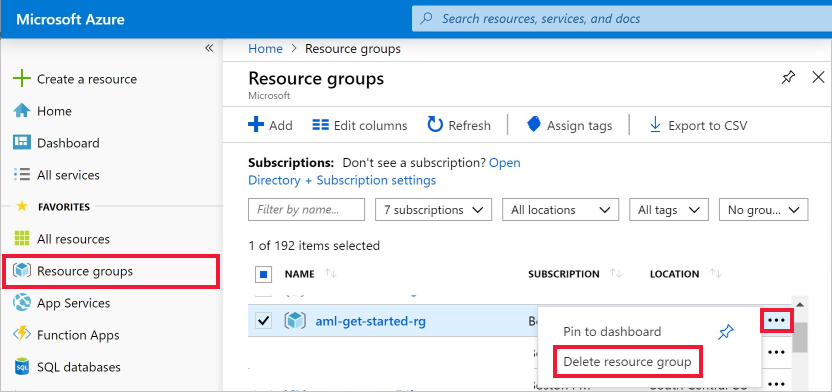
V seznamu vyberte skupinu prostředků, kterou jste vytvořili.
Vyberte Odstranit skupinu prostředků.
Zadejte název skupiny prostředků. Poté vyberte Odstranit.