Kurz: Prognóza poptávky s automatizovaným strojovým učením bez kódu v studio Azure Machine Learning
Naučte se vytvářet model prognózování časových řad bez psaní jednoho řádku kódu pomocí automatizovaného strojového učení v studio Azure Machine Learning. Tento model předpovídá poptávku po pronájmu služby sdílení kol.
V tomto kurzu nepíšete žádný kód, k trénování použijete rozhraní studia. Naučíte se provádět následující úlohy:
- Vytvoření a načtení datové sady
- Nakonfigurujte a spusťte experiment automatizovaného strojového učení.
- Zadejte nastavení prognózy.
- Prozkoumejte výsledky experimentu.
- Nasaďte nejlepší model.
Vyzkoušejte také automatizované strojové učení pro tyto další typy modelů:
- Příklad klasifikačního modelu bez kódu najdete v tématu Kurz: Vytvoření klasifikačního modelu pomocí automatizovaného strojového učení v Azure Machine Učení.
- První příklad kódu modelu rozpoznávání objektů najdete v kurzu: Trénování modelu rozpoznávání objektů pomocí AutoML a Pythonu.
Požadavky
Pracovní prostor služby Azure Machine Learning. Viz Vytvoření prostředků pracovního prostoru.
Stažení datového souboru bike-no.csv
Přihlášení do studia
V tomto kurzu vytvoříte experiment automatizovaného strojového učení spuštěný v studio Azure Machine Learning, konsolidované webové rozhraní, které zahrnuje nástroje strojového učení pro provádění scénářů datových věd pro odborníky na datové vědy na všech úrovních dovedností. Studio není podporované v prohlížečích Internet Explorer.
Přihlaste se k studio Azure Machine Learning.
Vyberte své předplatné a pracovní prostor, který jste vytvořili.
Vyberte Začínáme.
V levém podokně v části Autor vyberte Automatizované strojové učení.
Vyberte +Nová automatizovaná úloha ML.
Vytvoření a načtení datové sady
Než experiment nakonfigurujete, nahrajte datový soubor do pracovního prostoru ve formě datové sady Azure Machine Učení. To vám umožní zajistit, aby se data správně naformátovala pro váš experiment.
Ve formuláři Vybrat datovou sadu vyberte z rozevíracího seznamu +Vytvořit datovou sadu z místních souborů.
Ve formuláři Základní informace zadejte název datové sady a zadejte volitelný popis. Typ datové sady by měl být ve výchozím nastavení tabulkový, protože automatizované strojové učení v studio Azure Machine Learning aktuálně podporuje pouze tabulkové datové sady.
Výběr možnosti Další v levém dolním rohu
Ve formuláři úložiště dat a výběru souboru vyberte výchozí úložiště dat, které se automaticky nastavilo při vytváření pracovního prostoru, workspaceblobstore (Azure Blob Storage). Toto je umístění úložiště, kam nahrajete datový soubor.
V rozevíracím seznamu Nahrát soubory vyberte Nahrát soubory.
Zvolte soubor bike-no.csv na místním počítači. Toto je soubor, který jste stáhli jako předpoklad.
Vyberte Další.
Po dokončení nahrávání se na základě typu souboru předem vyplní formulář Nastavení a náhledu.
Ověřte, že je formulář Nastavení a náhledu vyplněný následujícím způsobem, a vyberte Další.
Pole Popis Hodnota pro kurz File format Definuje rozložení a typ dat uložených v souboru. Oddělené Delimiter Jeden nebo více znaků pro určení hranice mezi samostatnými, nezávislými oblastmi v prostém textu nebo jinými datovými proudy. Comma Kódování Určuje, jaký bit tabulky schématu znaků se má použít ke čtení datové sady. UTF-8 Záhlaví sloupců Určuje, jak se budou zacházet s hlavičkami datové sady( pokud existuje). Pouze první soubor obsahuje hlavičky. Přeskočit řádky Určuje, kolik řádků se v datové sadě přeskočí( pokud existuje). Nic Formulář schématu umožňuje další konfiguraci dat pro tento experiment.
V tomto příkladu zvolte ignorování neformálních a registrovaných sloupců. Tyto sloupce představují rozpis sloupce cnt , takže je nezahrneme.
V tomto příkladu ponechte výchozí hodnoty vlastností a typu.
Vyberte Další.
Ve formuláři Potvrdit podrobnosti ověřte, že informace odpovídají dříve vyplněným informacím o základních informacích a Nastavení a náhledu formulářů.
Výběrem možnosti Vytvořit dokončíte vytvoření datové sady.
Jakmile se zobrazí v seznamu, vyberte datovou sadu.
Vyberte Další.
Konfigurace úlohy
Po načtení a konfiguraci dat nastavte vzdálený cílový výpočetní objekt a vyberte sloupec v datech, která chcete předpovědět.
- Vyplňte formulář Konfigurovat úlohu následujícím způsobem:
Zadejte název experimentu:
automl-bikeshareJako cílový sloupec vyberte cnt , co chcete předpovědět. Tento sloupec označuje počet celkových zapůjčení kol.
Jako typ výpočetních prostředků vyberte výpočetní cluster .
Vyberte +Nový a nakonfigurujte cílový výpočetní objekt. Automatizované strojové učení podporuje pouze výpočetní Učení Azure Machine.
Vyplňte formulář Vybrat virtuální počítač a nastavte výpočetní prostředky.
Pole Popis Hodnota pro kurz Úroveň virtuálního počítače Vyberte, jakou prioritu má experiment mít. Vyhrazené Typ virtuálního počítače Vyberte typ virtuálního počítače pro výpočetní prostředky. CPU (jednotka centrálního zpracování) Velikost virtuálního počítače Vyberte velikost virtuálního počítače pro výpočetní prostředky. Seznam doporučených velikostí se poskytuje na základě vašich dat a typu experimentu. Standard_DS12_V2 Výběrem možnosti Další naplníte formulář Konfigurovat nastavení.
Pole Popis Hodnota pro kurz Název výpočetních prostředků Jedinečný název, který identifikuje výpočetní kontext. bike-compute Minimální a maximální počet uzlů Pokud chcete profilovat data, musíte zadat jeden nebo více uzlů. Minimální počet uzlů: 1
Maximální počet uzlů: 6Nečinné sekundy před vertikálním snížením kapacity Doba nečinnosti před automatickým vertikálním snížením kapacity clusteru na minimální počet uzlů. 120 (výchozí) Rozšířené nastavení Nastavení nakonfigurovat a autorizovat virtuální síť pro experiment. Nic Výběrem možnosti Vytvořit získáte cílový výpočetní objekt.
Dokončení této akce trvá několik minut.
Po vytvoření vyberte nový cílový výpočetní objekt z rozevíracího seznamu.
Vyberte Další.
Výběr nastavení prognózy
Dokončete nastavení pro experiment automatizovaného strojového učení zadáním typu úlohy a nastavení konfigurace strojového učení.
Ve formuláři Typ úlohy a nastavení vyberte jako typ úlohy strojového učení prognózování časových řad.
Jako sloupec Čas vyberte datuma ponechte identifikátory časových řad prázdné.
Frekvence určuje, jak často se shromažďují historická data. Ponechte vybranou možnost Automatické rozpoznávání .
Horizont prognózy je doba do budoucnosti, kterou chcete předpovědět. Zrušte výběr automatického rozpoznávání a do pole zadejte 14.
Vyberte Zobrazit další nastavení konfigurace a vyplňte pole následujícím způsobem. Tato nastavení slouží k lepšímu řízení úlohy trénování a určení nastavení pro prognózu. V opačném případě se výchozí hodnoty použijí na základě výběru experimentu a dat.
Další konfigurace Popis Hodnota pro kurz Primární metrika Metrika vyhodnocení, podle které se bude algoritmus strojového učení měřit. Normalizovaná střední kvadratická chyba odmocniny Vysvětlit nejlepší model Automaticky zobrazuje vysvětlitelnost nejlepšího modelu vytvořeného automatizovaným strojovém učení. Povolit Blokované algoritmy Algoritmy, které chcete vyloučit z trénovací úlohy Extrémní náhodné stromy Další nastavení prognózy Tato nastavení pomáhají zlepšit přesnost modelu.
Prognóza prodlevy cíle: jak daleko zpět chcete vytvořit prodlevy cílové proměnné
Cílové posuvné okno: Určuje velikost posuvného okna, ve kterém se generují funkce, jako je maximální, minimální a součet.
Prognóza prodlevy cíle: Žádná
Cílová velikost posuvné okno: ŽádnáKritérium ukončení Pokud jsou splněna kritéria, úloha trénování se zastaví. Doba trénování (hodiny): 3
Prahová hodnota skóre metriky: ŽádnáSouběžnost Maximální počet spuštěných paralelních iterací na iteraci Maximální počet souběžných iterací: 6 Zvolte Uložit.
Vyberte Další.
Ve formuláři [Volitelné] Ověření a testování ,
- Jako typ ověření vyberte křížové ověření k-fold.
- Jako počet křížových ověření vyberte 5.
Spuštění experimentu
Pokud chcete experiment spustit, vyberte Dokončit. Otevře se obrazovka s podrobnostmi o úloze se stavem úlohy v horní části vedle čísla úlohy. Tento stav se aktualizuje při pokroku experimentu. Oznámení se také zobrazí v pravém horním rohu studia, aby vás informovala o stavu experimentu.
Důležité
Příprava trvá 10 až 15 minut , než se připraví úloha experimentu.
Po spuštění trvá pro každou iteraci dalších 2 až 3 minuty.
V produkčním prostředí byste asi trochu odešel, protože tento proces nějakou dobu trvá. Během čekání doporučujeme začít zkoumat testované algoritmy na kartě Modely , jakmile budou dokončeny.
Prozkoumání modelů
Přejděte na kartu Modely a prohlédněte si testované algoritmy (modely). Ve výchozím nastavení jsou modely seřazené podle skóre metrik při jejich dokončení. Pro účely tohoto kurzu je v horní části seznamu model, který vyhodnotí nejvyšší skóre na základě zvolené metriky normalizované střední kvadratická chyba .
Během čekání na dokončení všech modelů experimentů vyberte název algoritmu dokončeného modelu a prozkoumejte jeho podrobnosti o výkonu.
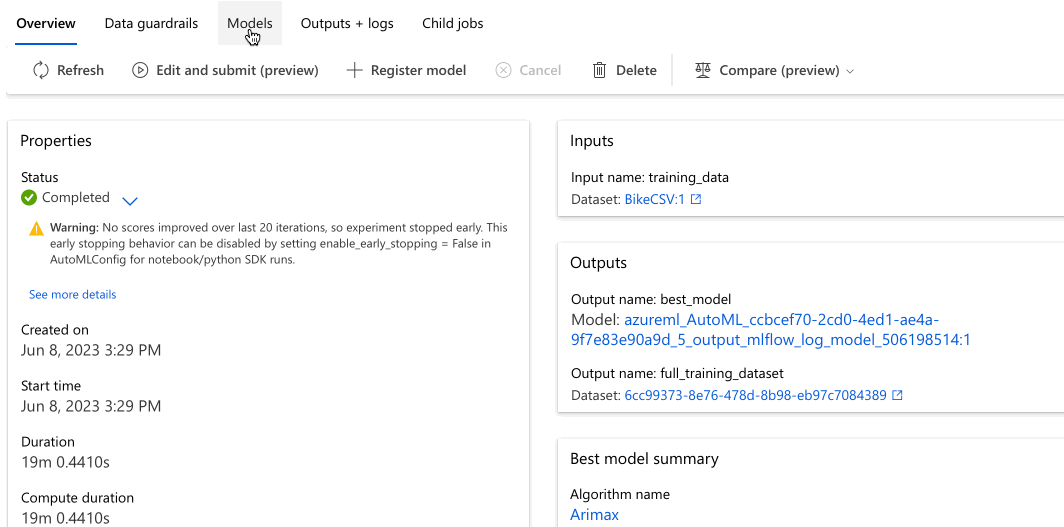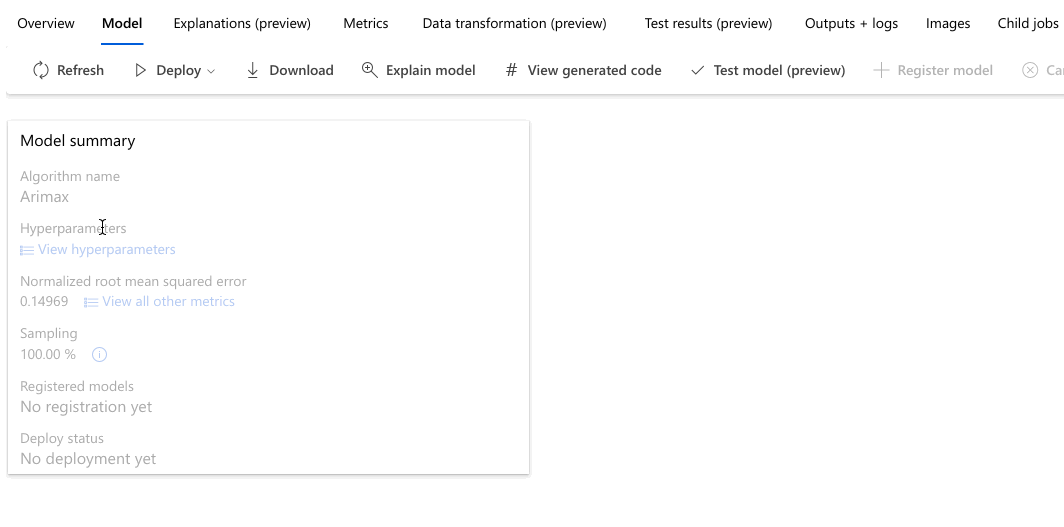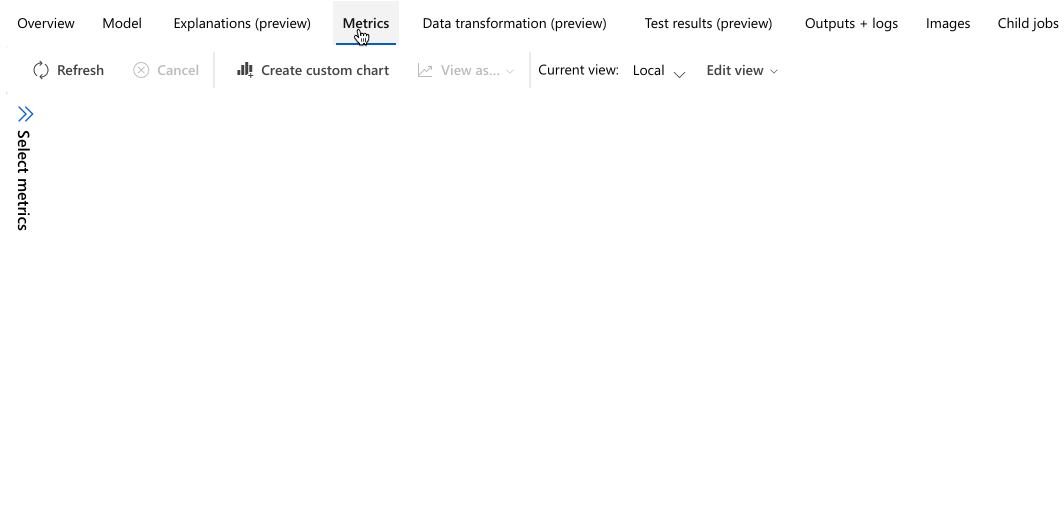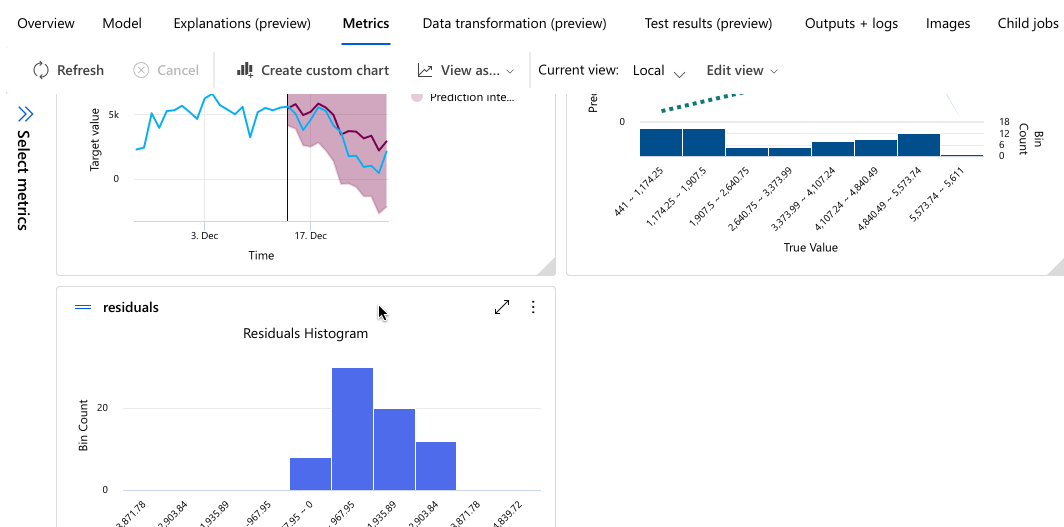
Následující příklad přejde k výběru modelu ze seznamu modelů, které úloha vytvořila. Pak vyberete kartu Přehled a Metriky , abyste zobrazili vlastnosti, metriky a grafy výkonu vybraného modelu.
Nasazení modelu
Automatizované strojové učení v studio Azure Machine Learning umožňuje nasadit nejlepší model jako webovou službu v několika krocích. Nasazení je integrace modelu, takže dokáže předpovědět nová data a identifikovat potenciální oblasti příležitostí.
Pro účely tohoto experimentu nasazení do webové služby znamená, že společnost sdílení kol má nyní iterativní a škálovatelné webové řešení pro prognózování poptávky po půjčování sdílených kol.
Po dokončení úlohy přejděte zpět na stránku nadřazené úlohy tak , že v horní části obrazovky vyberete 1 . Úlohu.
V části Nejlepší souhrn modelu je nejlepší model v kontextu tohoto experimentu vybrán na základě metriky normalizované střední střední kvadratická chyba.
Tento model nasadíme, ale doporučujeme, aby nasazení trvá přibližně 20 minut. Proces nasazení zahrnuje několik kroků, včetně registrace modelu, generování prostředků a jejich konfigurace pro webovou službu.
Výběrem nejlepšího modelu otevřete stránku specifickou pro daný model .
Vyberte tlačítko Nasadit umístěné v levé horní části obrazovky.
Naplňte podokno Nasazení modelu následujícím způsobem:
Pole Hodnota Název nasazení bikeshare-deploy Popis nasazení nasazení požadavků na sdílení kol Typ výpočetních prostředků Výběr výpočetní instance Azure (ACI) Povolit ověřování Zakázat. Použití vlastních prostředků nasazení Zakázat. Zakázání umožňuje automatické vygenerování výchozího souboru ovladače (hodnoticí skript) a souboru prostředí. V tomto příkladu používáme výchozí hodnoty uvedené v nabídce Upřesnit .
Vyberte Nasadit.
V horní části obrazovky úlohy se zobrazí zelená zpráva o úspěšném spuštění nasazení. Průběh nasazení najdete v podokně Souhrn modelu v části Stav nasazení.
Po úspěšném nasazení máte provozní webovou službu pro generování předpovědí.
Přejděte k dalším krokům, kde se dozvíte více o tom, jak využívat novou webovou službu, a otestujte predikce pomocí power BI integrované podpory azure machine Učení.
Vyčištění prostředků
Soubory nasazení jsou větší než data a soubory experimentů, takže jejich ukládání je nákladnější. Odstraňte jenom soubory nasazení, abyste minimalizovali náklady na váš účet, nebo pokud chcete zachovat pracovní prostor a soubory experimentů. Jinak odstraňte celou skupinu prostředků, pokud neplánujete používat žádné soubory.
Odstranění instance nasazení
Odstraňte pouze instanci nasazení z studio Azure Machine Learning, pokud chcete zachovat skupinu prostředků a pracovní prostor pro další kurzy a zkoumání.
Přejděte na studio Azure Machine Learning. V podokně Prostředky přejděte do svého pracovního prostoru a vlevo pod podoknem Prostředky vyberte Koncové body.
Vyberte nasazení, které chcete odstranit, a vyberte Odstranit.
Vyberte Pokračovat.
Odstranění skupiny prostředků
Důležité
Prostředky, které jste vytvořili, se dají použít jako předpoklady pro další kurzy a postupy pro azure machine Učení články.
Pokud nemáte v úmyslu používat žádné prostředky, které jste vytvořili, odstraňte je, abyste za ně neúčtovaly žádné poplatky:
Úplně nalevo na webu Azure Portal vyberte Skupiny prostředků.
V seznamu vyberte skupinu prostředků, kterou jste vytvořili.
Vyberte Odstranit skupinu prostředků.
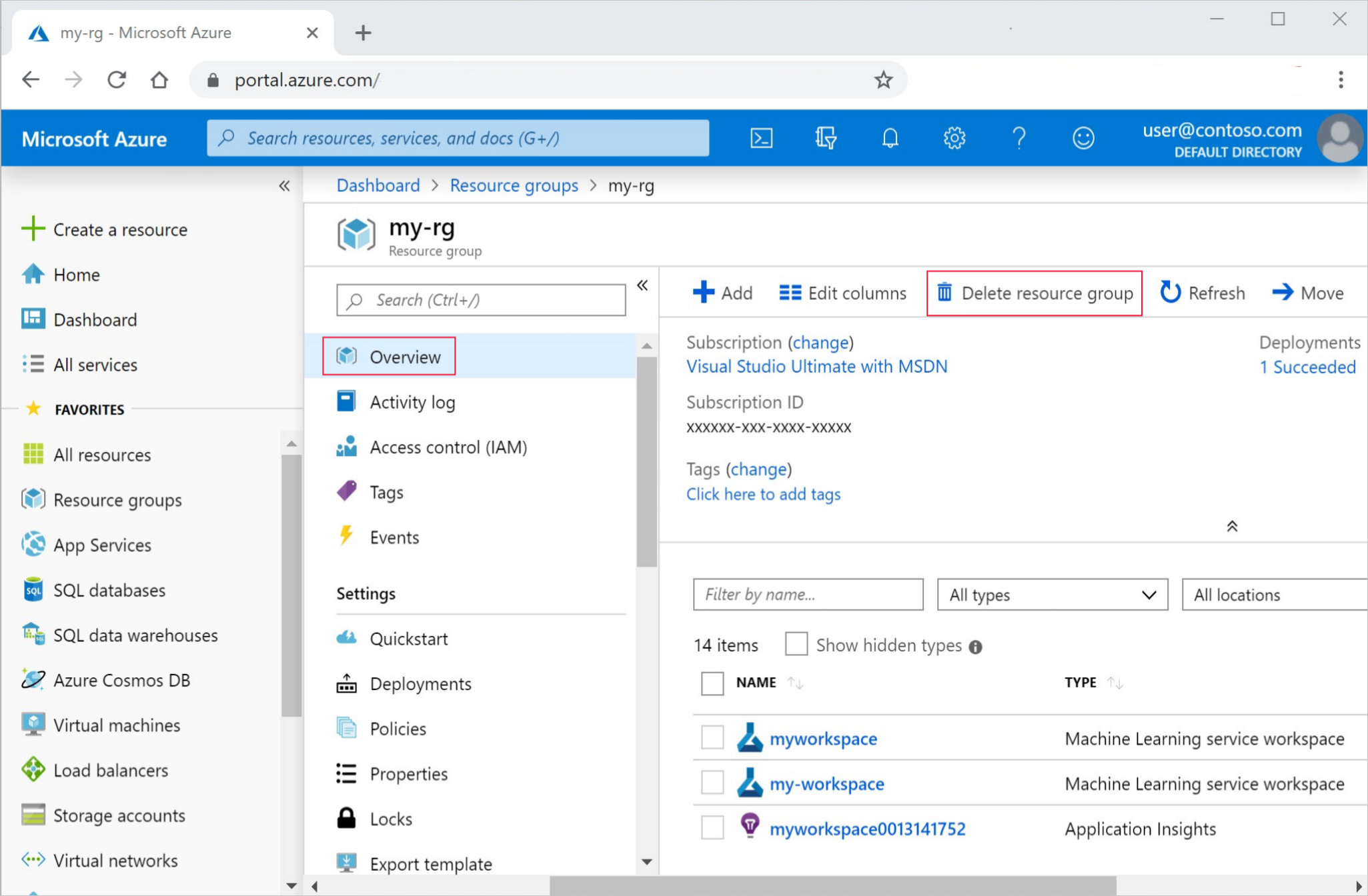
Zadejte název skupiny prostředků. Poté vyberte Odstranit.
Další kroky
V tomto kurzu jste pomocí automatizovaného strojového učení v studio Azure Machine Learning vytvořili a nasadíte model prognózování časových řad, který predikuje poptávku po půjčování kol.
Postup vytvoření podporovaného schématu Power BI pro usnadnění spotřeby nově nasazené webové služby najdete v tomto článku:
- Přečtěte si další informace o automatizovaném strojovém učení.
- Další informace o metrikách klasifikace a grafech najdete v článku Vysvětlení výsledků automatizovaného strojového učení.
Poznámka:
Tato datová sada sdílení kol byla v tomto kurzu upravena. Tato datová sada byla zpřístupněna jako součást soutěže Kaggle a původně byla k dispozici prostřednictvím Capital Bikeshare. Najdete ho také v databázi Učení počítače UCI.
Zdroj: Fanaee-T, Hadi a Gama, Joao, Event labeling combining ensemble detectors and background knowledge, Progress in Artificial Intelligence (2013): pp. 1-15, Springer Berlin Heidelberg.