Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tento článek popisuje, jak vyvíjet trénovací skript pomocí poznámkového bloku na cloudové pracovní stanici Azure Machine Learning. Tento kurz popisuje základní kroky, které potřebujete, abyste mohli začít:
- Nastavte a nakonfigurujte cloudovou pracovní stanici. Vaše cloudová pracovní stanice využívá výpočetní instanci služby Azure Machine Learning, která je předem nakonfigurovaná s prostředími pro podporu potřeb vývoje modelů.
- Používejte cloudová vývojová prostředí.
- Pomocí MLflow můžete sledovat metriky modelu.
Požadavky
Pokud chcete používat Azure Machine Learning, potřebujete pracovní prostor. Pokud ho nemáte, dokončete vytváření prostředků, které potřebujete, abyste mohli začít vytvářet pracovní prostor a získat další informace o jeho používání.
Důležité
Pokud je váš pracovní prostor Azure Machine Learning nakonfigurovaný se spravovanou virtuální sítí, možná budete muset přidat odchozí pravidla, která povolí přístup k veřejným úložištím balíčků Pythonu. Další informace najdete v tématu Scénář: Přístup k veřejným balíčkům strojového učení.
Vytvořit nebo spustit výpočetní jednotku
Výpočetní prostředky můžete vytvořit v části Výpočty ve vašem pracovním prostoru. Výpočetní instance je cloudová pracovní stanice, která je plně spravovaná službou Azure Machine Learning. Tato série kurzů používá výpočetní instanci. Můžete ho také použít ke spuštění vlastního kódu a k vývoji a testování modelů.
- Přihlaste se k studio Azure Machine Learning.
- Vyberte pracovní prostor, pokud ještě není otevřený.
- V levém podokně vyberte Výpočty.
- Pokud nemáte výpočetní instanci, uprostřed stránky se zobrazí Nová . Vyberte Nový a vyplňte formulář. Můžete použít všechny výchozí hodnoty.
- Pokud máte výpočetní instanci, vyberte ji ze seznamu. Pokud je zastavený, vyberte Spustit.
Otevření editoru Visual Studio Code (VS Code)
Jakmile máte spuštěnou výpočetní instanci, můžete k ní přistupovat různými způsoby. Tento kurz popisuje, jak používat výpočetní instanci z editoru Visual Studio Code. Visual Studio Code poskytuje úplné integrované vývojové prostředí (IDE) pro vytváření výpočetních instancí.
V seznamu výpočetních instancí vyberte odkaz VS Code (Web) nebo VS Code (Desktop) pro výpočetní instanci, kterou chcete použít. Pokud zvolíte VS Code (Desktop), může se zobrazit zpráva s dotazem, jestli chcete aplikaci otevřít.

Tato instance editoru Visual Studio Code je připojená k vaší výpočetní instanci a k souborovému systému vašeho pracovního prostoru. I když ho otevřete na ploše, soubory, které vidíte, jsou soubory ve vašem pracovním prostoru.
Nastavení nového prostředí pro vytváření prototypů
Abyste mohli skript spustit, musíte pracovat v prostředí, které je nakonfigurované se závislostmi a knihovnami, které kód očekává. Tato část vám pomůže vytvořit prostředí, které je přizpůsobené vašemu kódu. Pokud chcete vytvořit nové jádro Jupyter, ke kterému se váš poznámkový blok připojí, použijte soubor YAML, který definuje závislosti.
Nahrajte soubor.
Soubory, které nahrajete, se ukládají do sdílené složky Azure a tyto soubory se připojují ke každé výpočetní instanci a sdílí se v rámci pracovního prostoru.
Přejděte na azureml-examples/tutorials/get-started-notebooks/workstation_env.yml.
Stáhněte si soubor prostředí Conda workstation_env.yml do počítače tak, že v pravém horním rohu stránky vyberete tlačítko se třemi tečkou (...) a pak vyberete Stáhnout.
Přetáhněte soubor z počítače do okna editoru Visual Studio Code. Soubor se nahraje do vašeho pracovního prostoru.
Přesuňte soubor do složky uživatelského jména.

Výběrem souboru ho zobrazíte jako náhled. Zkontrolujte závislosti, které určuje. Měli byste vidět přibližně toto:
name: workstation_env # This file serves as an example - you can update packages or versions to fit your use case dependencies: - python=3.8 - pip=21.2.4 - scikit-learn=0.24.2 - scipy=1.7.1 - pandas>=1.1,<1.2 - pip: - mlflow-skinny - azureml-mlflow - psutil>=5.8,<5.9 - ipykernel~=6.0 - matplotlibVytvořte jádro.
Teď pomocí terminálu vytvořte nové jádro Jupyter založené na souboru workstation_env.yml .
- V nabídce v horní části editoru Visual Studio Code vyberte Terminál > nový terminál.
Zobrazte si aktuální prostředí Conda. Aktivní prostředí je označené hvězdičkou (*).
conda env listSlouží
cdk přechodu do složky, kam jste nahráli soubor workstation_env.yml . Pokud jste ho například nahráli do složky uživatele, použijte tento příkaz:cd Users/myusernameUjistěte se, že je ve složce workstation_env.yml.
lsVytvořte prostředí na základě zadaného souboru Conda. Sestavení prostředí trvá několik minut.
conda env create -f workstation_env.ymlAktivujte nové prostředí.
conda activate workstation_envPoznámka:
Pokud se zobrazí CommandNotFoundError, postupujte podle pokynů ke spuštění
conda init bash, zavřete terminál a otevřete nový. Zkuste znovu příkazconda activate workstation_env.Ověřte, že je správné prostředí aktivní, a znovu vyhledejte prostředí označené znakem *.
conda env listVytvořte nové jádro Jupyter založené na aktivním prostředí.
python -m ipykernel install --user --name workstation_env --display-name "Tutorial Workstation Env"Zavřete okno terminálu.
Teď máte nové jádro. Dále otevřete poznámkový blok a použijete toto jádro.
Vytvoření poznámkového bloku
- V nabídce v horní části editoru Visual Studio Code vyberte Soubor > nový soubor.
- Pojmenujte nový soubor develop-tutorial.ipynb (nebo použijte jiný název). Nezapomeňte použít příponu .ipynb .
Nastavení jádra
- V pravém horním rohu nového souboru vyberte Vybrat jádro.
- Vyberte výpočetní instanci Azure ML (computeinstance-name).
- Vyberte jádro, které jste vytvořili: Tutorial Workstation Env. Pokud se jádro nezobrazuje, vyberte tlačítko aktualizovat nad seznamem.
Vývoj trénovacího skriptu
V této části vytvoříte trénovací skript Pythonu, který předpovídá výchozí platby platební kartou pomocí připravených testovacích a trénovacích datových sad z datové sady UCI.
Tento kód používá sklearn pro trénování a MLflow pro protokolování metrik.
Začněte kódem, který importuje balíčky a knihovny, které použijete v trénovacím skriptu.
import os import argparse import pandas as pd import mlflow import mlflow.sklearn from sklearn.ensemble import GradientBoostingClassifier from sklearn.metrics import classification_report from sklearn.model_selection import train_test_splitDále načtěte a zpracujte data experimentu. V tomto kurzu si přečtete data ze souboru na internetu.
# load the data credit_df = pd.read_csv( "https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv", header=1, index_col=0, ) train_df, test_df = train_test_split( credit_df, test_size=0.25, )Připravte data pro školení.
# Extracting the label column y_train = train_df.pop("default payment next month") # convert the dataframe values to array X_train = train_df.values # Extracting the label column y_test = test_df.pop("default payment next month") # convert the dataframe values to array X_test = test_df.valuesPřidejte kód pro zahájení automatickéhologování pomocí MLflow, abyste mohli sledovat metriky a výsledky. S iterativní povahou vývoje modelů pomáhá MLflow protokolovat parametry a výsledky modelu. Projděte si různá spuštění a porovnejte a zjistěte, jak model funguje. Protokoly také poskytují kontext, kdy jste připraveni přejít z fáze vývoje do fáze trénování pracovních postupů v rámci služby Azure Machine Learning.
# set name for logging mlflow.set_experiment("Develop on cloud tutorial") # enable autologging with MLflow mlflow.sklearn.autolog()Trénování modelu
# Train Gradient Boosting Classifier print(f"Training with data of shape {X_train.shape}") mlflow.start_run() clf = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1) clf.fit(X_train, y_train) y_pred = clf.predict(X_test) print(classification_report(y_test, y_pred)) # Stop logging for this model mlflow.end_run()Poznámka:
Upozornění MLflow můžete ignorovat. Výsledky, které potřebujete, budou stále sledovány.
Vyberte Spustit vše nad kódem.
Iterovat
Teď, když máte výsledky modelu, změňte něco a spusťte model znovu. Zkuste například použít jinou techniku klasifikace:
# Train AdaBoost Classifier
from sklearn.ensemble import AdaBoostClassifier
print(f"Training with data of shape {X_train.shape}")
mlflow.start_run()
ada = AdaBoostClassifier()
ada.fit(X_train, y_train)
y_pred = ada.predict(X_test)
print(classification_report(y_test, y_pred))
# Stop logging for this model
mlflow.end_run()Poznámka:
Upozornění MLflow můžete ignorovat. Výsledky, které potřebujete, budou stále sledovány.
Výběrem možnosti Spustit vše model spusťte.
Prozkoumání výsledků
Teď, když jste vyzkoušeli dva různé modely, použijte výsledky sledované nástrojem MLFfow a rozhodněte se, který model je lepší. Můžete odkazovat na metriky, jako je přesnost nebo jiné indikátory, které jsou pro vaše scénáře nejdůležitější. Tyto výsledky si můžete prohlédnout podrobněji tak, že se podíváte na úlohy vytvořené MLflow.
Vraťte se do pracovního prostoru v studio Azure Machine Learning.
V levém podokně vyberte Úlohy.
Vyberte Kurz Vývoj v cloudu.
Zobrazí se dvě úlohy, jedna pro každý z modelů, které jste vyzkoušeli. Názvy se automaticky vygenerují. Pokud chcete úlohu přejmenovat, najeďte myší na název a vyberte tlačítko tužky vedle ní.
Vyberte odkaz pro první úlohu. Název se zobrazí v horní části stránky. Můžete ho tady přejmenovat také pomocí tlačítka tužky.
Na stránce se zobrazují podrobnosti úlohy, jako jsou vlastnosti, výstupy, značky a parametry. V části Značky se zobrazí estimator_name, který popisuje typ modelu.
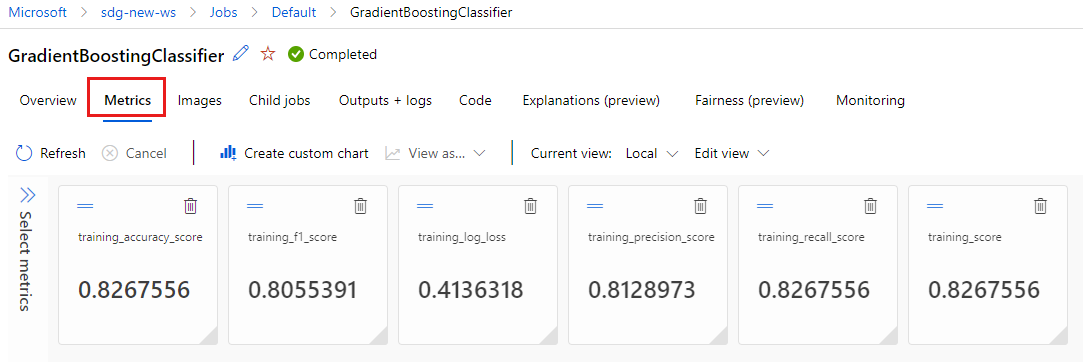
Výběrem karty Metriky zobrazíte metriky , které protokoloval MLflow. (Vaše výsledky se budou lišit, protože máte jinou trénovací sadu.)
Výběrem karty Obrázky zobrazíte obrázky vygenerované MLflow.
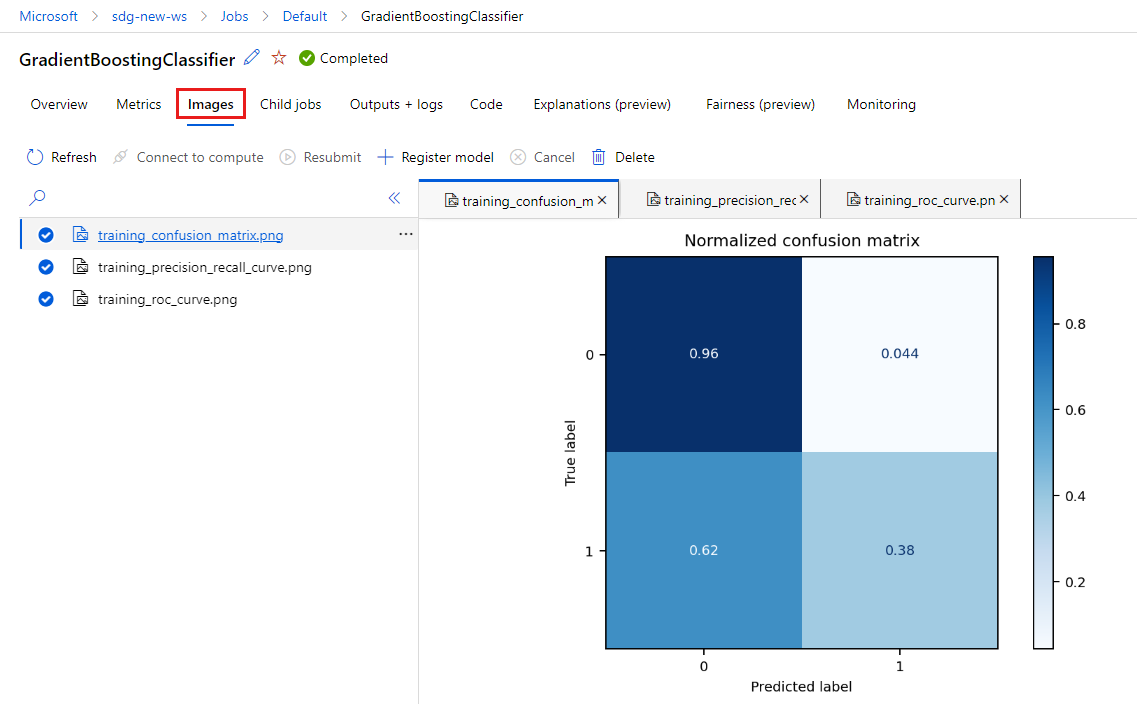
Vraťte se zpět a prohlédněte si metriky a obrázky pro druhý model.

Vytvoření skriptu Pythonu
Teď vytvoříte skript Pythonu z poznámkového bloku pro trénování modelu.
V editoru Visual Studio Code klikněte pravým tlačítkem na název souboru poznámkového bloku a vyberte Importovat poznámkový blok do skriptu.
Vyberte Soubor > Uložit pro uložení nového souboru skriptu. Zavolejte train.py.
Prohlédněte si soubor a odstraňte kód, který v trénovacím skriptu nechcete. Například ponechte kód pro model, který chcete použít, a odstraňte kód pro model, který nechcete použít.
- Nezapomeňte zachovat kód, který spouští automatickélogování (
mlflow.sklearn.autolog()). - Když skript Pythonu spustíte interaktivně (jak tady děláte), můžete ponechat řádek, který definuje název experimentu (
mlflow.set_experiment("Develop on cloud tutorial")). Nebo ho můžete pojmenovat jinak, abyste ho viděli jako jinou položku v části Úlohy . Když ale připravíte skript pro trénovací úlohu, tento řádek se nepoužije a měl by být vynechán: Definice úlohy obsahuje název experimentu. - Při trénování jednoho modelu nejsou čáry pro spuštění a ukončení běhu (
mlflow.start_run()amlflow.end_run()) nezbytné (nemají žádný vliv), ale můžete je ponechat.
- Nezapomeňte zachovat kód, který spouští automatickélogování (
Až budete s úpravami hotovi, soubor uložte.
Teď máte skript Pythonu, který můžete použít k trénování preferovaného modelu.
Spuštění skriptu Pythonu
Prozatím tento kód spouštíte ve výpočetní instanci, což je vývojové prostředí služby Azure Machine Learning. Kurz: Trénování modelu ukazuje, jak spustit trénovací skript škálovatelným způsobem pro výkonnější výpočetní prostředky.
Jako verzi Pythonu (workstations_env) vyberte prostředí, které jste vytvořili dříve v tomto kurzu. V pravém dolním rohu poznámkového bloku uvidíte název prostředí. Vyberte ho a pak vyberte prostředí v horní části editoru Visual Studio Code.

Spusťte skript Pythonu výběrem tlačítka Spustit vše nad kódem.



Poznámka:
Upozornění MLflow můžete ignorovat. Stále budete dostávat všechny metriky a obrázky z automatickéhologování.
Prozkoumání výsledků skriptu
Vraťte se do úloh v pracovním prostoru v studio Azure Machine Learning a podívejte se na výsledky trénovacího skriptu. Mějte na paměti, že se tréninková data mění s jednotlivými rozděleními, takže se výsledky mezi běhy liší.
Vyčištění prostředků
Pokud chcete pokračovat v dalších kurzech, přejděte na Další kroky.
Zastavení výpočetní instance
Pokud ji teď nebudete používat, zastavte výpočetní instanci:
- V levém podokně studia vyberte Výpočty.
- V horní části stránky vyberte Výpočetní instance.
- V seznamu vyberte výpočetní instanci.
- V horní části stránky vyberte Zastavit.
Odstranění všech prostředků
Důležité
Prostředky, které jste vytvořili, se dají použít jako předpoklady pro další kurzy a články s postupy pro Azure Machine Learning.
Pokud nemáte v úmyslu používat žádné prostředky, které jste vytvořili, odstraňte je, abyste za ně neúčtovaly žádné poplatky:
Na webu Azure Portal do vyhledávacího pole zadejte skupiny prostředků a vyberte je z výsledků.
V seznamu vyberte skupinu prostředků, kterou jste vytvořili.
Na stránce Přehled vyberte Odstranit skupinu prostředků.
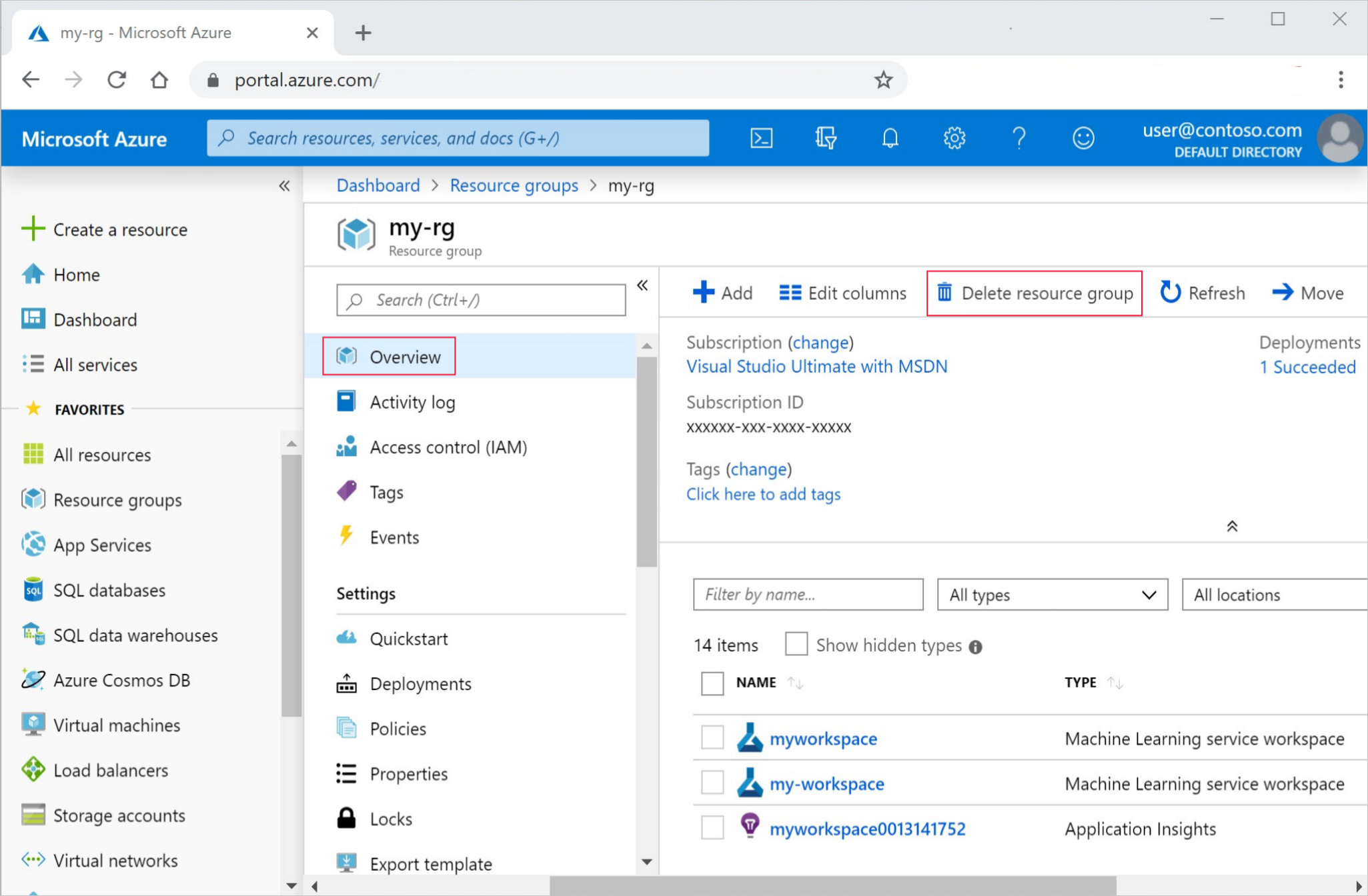
Zadejte název skupiny prostředků. Poté vyberte Odstranit.
Další kroky
Další informace najdete v těchto zdrojích informací:
- Artefakty a modely v MLflow
- Použití Gitu se službou Azure Machine Learning
- Spouštění poznámkových bloků Jupyter ve vašem pracovním prostoru
- Práce s terminálem výpočetní instance v pracovním prostoru
- Správa poznámkových bloků a terminálových relací
Tento kurz ukazuje počáteční kroky vytvoření modelu, vytváření prototypů na stejném počítači, ve kterém se nachází kód. V případě produkčního trénování se naučíte používat tento trénovací skript pro výkonnější vzdálené výpočetní prostředky: