Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Pokud je to možné, doporučujeme pomocí nativní replikace Apache Cassandra migrovat data z existujícího clusteru do služby Azure Managed Instance for Apache Cassandra konfigurací hybridního clusteru. Tento přístup použije protokol Gossip apache Cassandra k replikaci dat ze zdrojového datacentra do nového datacentra spravované instance. V některých scénářích ale může dojít k tomu, že vaše verze zdrojové databáze není kompatibilní nebo není možné nastavit hybridní cluster.
Tento kurz popisuje, jak migrovat data do služby Azure Managed Instance for Apache Cassandra offline pomocí konektoru Cassandra Spark a Azure Databricks pro Apache Spark.
Požadavky
Zřízení clusteru Azure Managed Instance pro Apache Cassandra pomocí webu Azure Portal nebo Azure CLI a ujistěte se, že se ke clusteru můžete připojit pomocí CQLSH.
Zřízení účtu Azure Databricks ve vaší virtuální síti Managed Cassandra Ujistěte se, že má také síťový přístup ke zdrojovému clusteru Cassandra.
Ujistěte se, že jste již migrovali schéma prostoru klíčů nebo tabulky ze zdrojové databáze Cassandra do cílové databáze spravované instance Cassandra.
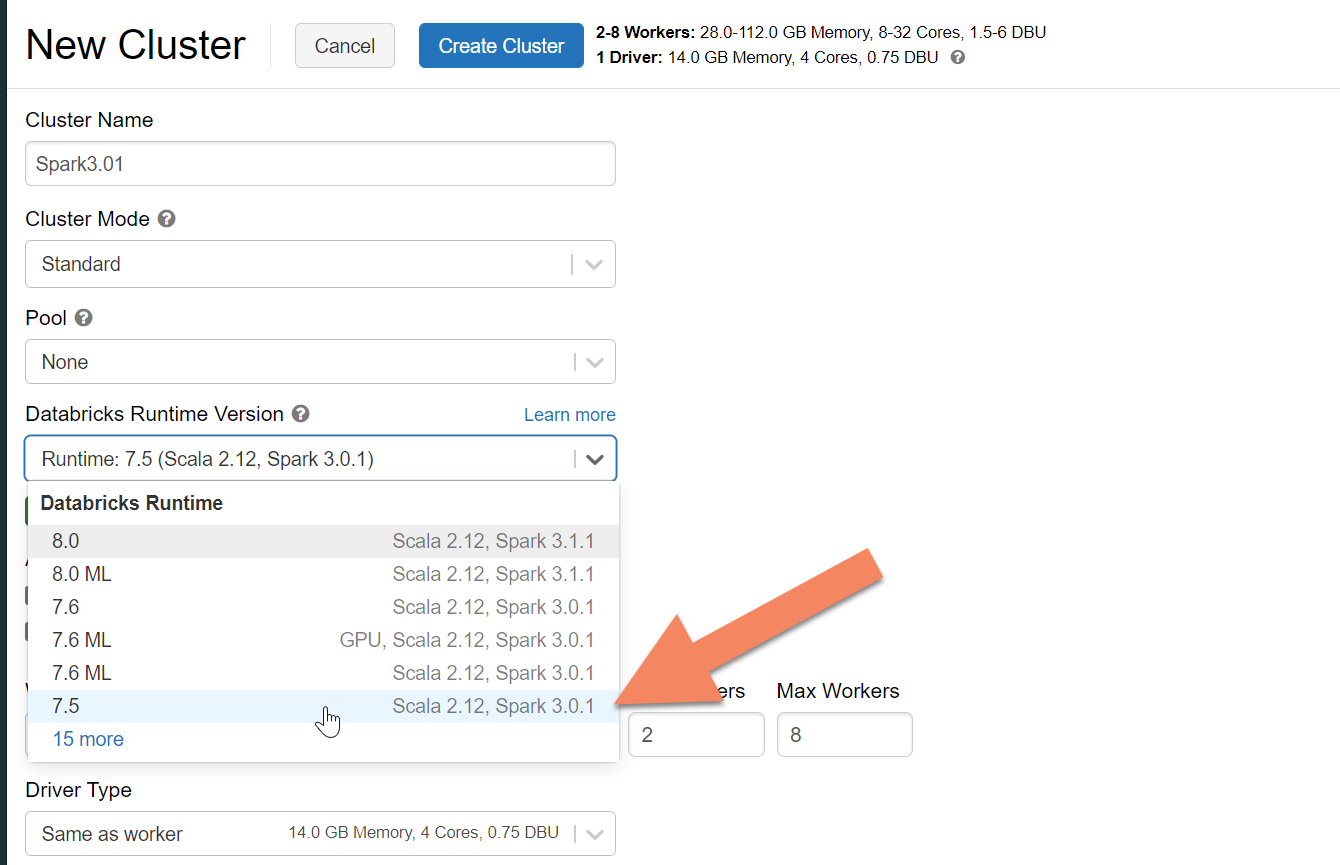
Zřízení clusteru Azure Databricks
Doporučujeme vybrat modul runtime Databricks verze 7.5, který podporuje Spark 3.0.
Přidání závislostí
Přidejte do clusteru knihovnu konektoru Apache Spark Cassandra pro připojení k nativním i koncovým bodům Cassandra služby Azure Cosmos DB. V clusteru vyberte Knihovny>Nainstalovat nový>Maven a pak přidejte com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0 souřadnice Mavenu.

Vyberte Nainstalovat a po dokončení instalace restartujte cluster.
Poznámka:
Po instalaci knihovny konektoru Cassandra se ujistěte, že restartujete cluster Databricks.
Vytvoření poznámkového bloku Scala pro migraci
Vytvoření poznámkového bloku Scala v Databricks Nahraďte konfiguraci zdrojové a cílové Cassandra odpovídajícími přihlašovacími údaji a zdrojovými a cílovými prostory klíčů a tabulkami. Pak spusťte následující kód:
import com.datastax.spark.connector._
import com.datastax.spark.connector.cql._
import org.apache.spark.SparkContext
// source cassandra configs
val sourceCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "false",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>"
)
//target cassandra configs
val targetCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>",
//throughput related settings below - tweak these depending on data volumes.
"spark.cassandra.output.batch.size.rows"-> "1",
"spark.cassandra.output.concurrent.writes" -> "1000",
"spark.cassandra.connection.remoteConnectionsPerExecutor" -> "10",
"spark.cassandra.concurrent.reads" -> "512",
"spark.cassandra.output.batch.grouping.buffer.size" -> "1000",
"spark.cassandra.connection.keep_alive_ms" -> "600000000"
)
//Read from source Cassandra
val DFfromSourceCassandra = sqlContext
.read
.format("org.apache.spark.sql.cassandra")
.options(sourceCassandra)
.load
//Write to target Cassandra
DFfromSourceCassandra
.write
.format("org.apache.spark.sql.cassandra")
.options(targetCassandra)
.mode(SaveMode.Append) // only required for Spark 3.x
.save
Poznámka:
Pokud potřebujete zachovat originál writetime každého řádku, projděte si ukázku migrace cassandra.