Správa provozní kontinuity v Azure
Azure udržuje jeden z nejvyspělejších a respektovaných programů řízení kontinuity podnikových procesů v oboru. Cílem kontinuity podnikových procesů v Azure je vytvořit a posunout obnovitelnost a odolnost všech nezávisle obnovitelných služeb, ať už jde o službu určenou pro zákazníky (součást nabídky Azure) nebo interní podpůrnou službu platformy.
Při pochopení kontinuity podnikových procesů je důležité si uvědomit, že řada nabídek se skládá z několika služeb. V Azure se každá služba staticky identifikuje pomocí nástrojů a je měrnou jednotkou používanou pro ochranu osobních údajů, zabezpečení, inventář, řízení provozní kontinuity rizik a další funkce. Pro správné měření schopností služby jsou pro každou službu zahrnuté tři prvky lidí, procesů a technologií bez ohledu na typ služby.
Příklad:
- Pokud existuje obchodní proces založený na lidech, jako je helpdesk nebo tým, doručování služeb je to, co dělají. Uživatelé k provádění služby používají procesy a technologie.
- Pokud existuje technologie jako služba, jako je Azure Virtual Machines, je doručováním služeb technologie spolu s lidmi a procesy, které podporují její provoz.
Model sdílené odpovědnosti
Řada nabídek Azure vyžaduje, abyste nastavili zotavení po havárii ve více oblastech a nejste zodpovědní za Microsoft. Ne všechny služby Azure automaticky replikují data nebo automaticky přejdou z oblasti, která selhala, aby se mezi replikovala do jiné povolené oblasti. V těchto případech zodpovídáte za konfiguraci obnovení a replikace.
Microsoft zajišťuje, aby byly dostupné základní služby infrastruktury a platformy. V některých scénářích ale využití vyžaduje duplikování nasazení a úložiště v kapacitě s více oblastmi, pokud se rozhodnete. Tyto příklady ilustrují model sdílené odpovědnosti. Jedná se o základní pilíř strategie provozní kontinuity a zotavení po havárii.
Rozdělení odpovědnosti
V jakémkoli místním datacentru vlastníte celý zásobník. Při přesunu prostředků do cloudu se některé zodpovědnosti přenesou do Microsoftu. Následující diagram znázorňuje oblasti a rozdělení odpovědnosti mezi vás a Microsoftem podle typu nasazení.
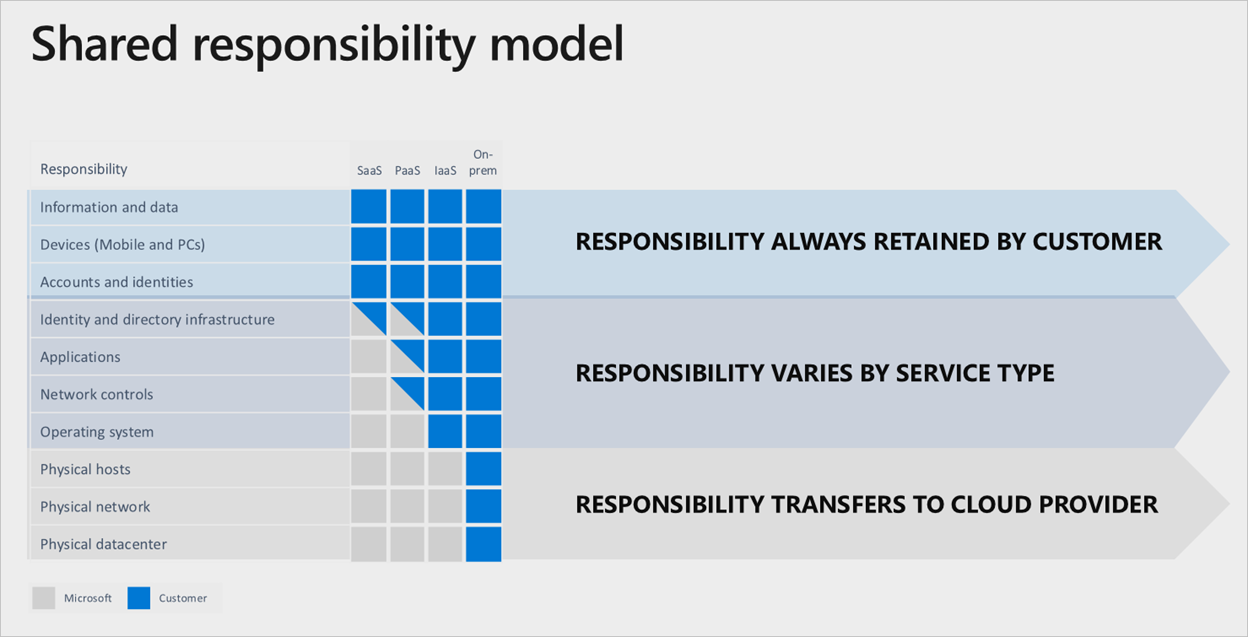
Dobrým příkladem modelu sdílené odpovědnosti je nasazení virtuálních počítačů. Pokud chcete nastavit replikaci mezi oblastmi pro zajištění odolnosti, pokud dojde k selhání oblasti, musíte nasadit duplicitní sadu virtuálních počítačů v alternativní povolené oblasti. Azure tyto služby automaticky nereplikuje, pokud dojde k selhání. Je vaší zodpovědností nasadit nezbytné prostředky. Pokud chcete ručně změnit primární oblasti, musíte mít proces nebo ho musíte použít ke zjištění a automatickému převzetí služeb při selhání pomocí Traffic Manageru.
Služby zotavení po havárii s podporou zákazníka mají veřejnou dokumentaci, která vás provede. Příklad veřejné dokumentace pro zotavení po havárii s podporou zákazníků najdete v Tématu Azure Data Lake Analytics.
Další informace o modelu sdílené odpovědnosti najdete v Centru zabezpečení Microsoftu.
Dodržování předpisů provozní kontinuity: Odpovědnost na úrovni služeb
Každá služba je nutná k dokončení záznamů zotavení po havárii provozní kontinuity v nástroji Azure Business Continuity Manager. Vlastníci služeb můžou pomocí nástroje pracovat v rámci federovaného modelu, aby mohli dokončit a začlenit požadavky, které zahrnují:
Vlastnosti služby: Definuje službu a způsob, jakým se dosahuje zotavení po havárii a odolnost proti havárii, a identifikuje zodpovědnou stranu pro zotavení po havárii (pro technologie). Podrobnosti o vlastnictví obnovení najdete v diskuzi o modelu sdílené odpovědnosti v předchozí části a diagramu.
Analýza obchodních dopadů: Tato analýza pomáhá vlastníkovi služby definovat cíl doby obnovení (RTO) a cíl bodu obnovení (RPO) na základě závažnosti služby v tabulce dopadů. Provozní, právní, regulační, brand image a finanční dopady se používají jako cílové cíle pro obnovení.
Poznámka:
Microsoft nepublikuje rto ani rpos pro služby, protože tato data jsou určená pouze pro interní míry. Všechny přísliby a míry zákazníků jsou založené na sla, protože pokrývají širší rozsah oproti RTO nebo RPO, které platí pouze v katastrofické ztrátě.
Závislosti: Každá služba mapuje závislosti (jiné služby), které vyžaduje, aby fungovala bez ohledu na to, jak je kritická, a mapuje se na modul runtime, potřebný pouze pro obnovení nebo obojí. Pokud existují závislosti úložiště, namapují se další data, která definují, co je uloženo, a pokud například vyžadují snímky k určitému bodu v čase.
Pracovníci: Jak je uvedeno v definici služby, je důležité znát umístění a množství pracovníků schopných podporovat službu, zajistit, aby nedošlo k selhání, a pokud jsou kritické zaměstnance rozptýleny, aby se zabránilo selháním v jednom umístění.
Externí dodavatelé: Společnost Microsoft uchovává komplexní seznam externích dodavatelů a dodavatelé, kteří se považují za kritické, měří možnosti. Pokud je služba identifikovaná jako závislost, možnosti dodavatelů se porovnávají s potřebami služby, aby se zajistilo, že výpadek třetí strany nenaruší služby Azure.
Hodnocení obnovení: Toto hodnocení je jedinečné pro program Azure Business Continuity Management. Toto hodnocení měří několik klíčových prvků k vytvoření skóre odolnosti:
- Ochota převzít služby při selhání: I když může existovat nějaký proces, nemusí to být první volba pro krátkodobé výpadky.
- Automatizace převzetí služeb při selhání
- Automatizace rozhodnutí o převzetí služeb při selhání
Nejspolehlivější a nejkratší doba převzetí služeb při selhání je služba, která je automatizovaná a nevyžaduje žádné lidské rozhodnutí. Automatizovaná služba používá monitorování prezenčních signálů nebo syntetické transakce k určení, že služba je v provozu a spouští okamžitou nápravu.
Plán obnovení a testování: Azure vyžaduje, aby každá služba měla podrobný plán obnovení a testovala tento plán, jako kdyby služba selhala kvůli závažnému výpadku. Plány obnovení musí být napsané tak, aby někdo s podobnými dovednostmi a přístupem mohl dokončit úkoly. Napsaný plán se vyhne tomu, že se spoléhá na dostupné odborníky na danou problematiku.
Testování se provádí několika způsoby, včetně sebetestování v produkčním nebo téměř produkčním prostředí, a jako součást podrobností o úplné oblasti Azure v kanárských sadách oblastí. Tyto povolené oblasti jsou shodné s produkčními oblastmi, ale je možné je zakázat, aniž by to mělo vliv na vaše služby. Testování se považuje za integrované, protože všechny služby jsou ovlivněny současně.
Povolení zákazníka: Pokud zodpovídáte za nastavení zotavení po havárii, musí mít Azure pokyny k veřejné dokumentaci. Pro všechny tyto služby jsou k dispozici odkazy na dokumentaci a podrobnosti o procesu.
Ověření dodržování předpisů provozní kontinuity
Jakmile služba dokončí záznam správy provozní kontinuity, musíte ho odeslat ke schválení. Je přiřazený managementu kontinuity podnikových procesů, který prošel celým záznamem o úplnosti a kvalitě. Pokud záznam splňuje všechny požadavky, je schválen. Pokud tomu tak není, žádost o přepracování se odmítne. Tento proces zajišťuje, že obě strany souhlasí, že bylo splněno dodržování předpisů provozní kontinuity a že práce je potvrzena pouze vlastníkem služby. Týmy interního auditu a dodržování předpisů Azure také pravidelně provádí náhodné vzorkování, aby se zajistilo, že se odesílají nejlepší data.
Testování služeb
Microsoft a Azure pro zotavení po havárii i připravenost zón dostupnosti do značného rozsahu testují. Služby se testují v produkčním nebo předprodukčním prostředí, aby ukázaly nezávislou obnovitelnost služeb, které nejsou závislé na převzetí služeb při selhání hlavní platformy.
Aby se zajistilo, že služby se můžou podobně obnovit ve scénáři skutečného výpadku oblasti, provádí se testování typu pull-the-plug v kanárských prostředích, která jsou plně nasazená v produkčních oblastech. Například clustery, racky a napájecí jednotky jsou doslova vypnuté pro simulaci celkového selhání oblasti.
Během těchto testů Azure používá stejný produkční proces pro detekci, oznámení, odpověď a obnovení. Žádní jednotlivci očekávají přechod k podrobnostem a technici, na které se spoléhají při obnovení, jsou normální prostředky obměně volání. Toto načasování se vyhne v závislosti na odborníkůch na danou problematiku, kteří nemusí být během skutečné události k dispozici.
Součástí těchto testů jsou služby, za které zodpovídáte za nastavení zotavení po havárii podle veřejné dokumentace Microsoftu. Týmy služeb vytvářejí instance podobné zákazníkům, aby ukázaly, že zotavení po havárii s podporou zákazníka funguje podle očekávání a že uvedené pokyny jsou přesné.
Další informace o certifikacích najdete v Centru zabezpečení Microsoftu a v části věnované dodržování předpisů.
Další kroky
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro