Spolehlivost v Azure Traffic Manageru
Tento článek obsahuje podporu zotavení po havárii napříč oblastmi a podporu provozní kontinuity pro Azure Traffic Manager.
Zotavení po havárii napříč oblastmi a provozní kontinuita
Zotavení po havárii (DR) se týká zotavení z událostí s vysokým dopadem, jako jsou přírodní katastrofy nebo neúspěšná nasazení, která vedou k výpadkům a ztrátě dat. Bez ohledu na příčinu je nejlepším řešením havárie dobře definovaný a otestovaný plán zotavení po havárii a návrh aplikace, který aktivně podporuje zotavení po havárii. Než začnete přemýšlet o vytvoření plánu zotavení po havárii, přečtěte si doporučení pro návrh strategie zotavení po havárii.
Pokud jde o zotavení po havárii, Microsoft používá model sdílené odpovědnosti. V modelu sdílené odpovědnosti Microsoft zajišťuje, aby byly dostupné základní služby infrastruktury a platformy. Současně mnoho služeb Azure automaticky nereplikuje data nebo se vrátí z oblasti, která selhala, aby se křížově replikovala do jiné povolené oblasti. Za tyto služby zodpovídáte za nastavení plánu zotavení po havárii, který funguje pro vaši úlohu. Většina služeb, které běží na nabídkách PaaS (Platforma jako služba) Azure, poskytuje funkce a pokyny pro podporu zotavení po havárii a pomocí funkcí specifických pro služby můžete podporovat rychlé obnovení , které vám pomůže s vývojem plánu zotavení po havárii.
Azure Traffic Manager je nástroj pro vyrovnávání zatížení provozu založený na DNS, který umožňuje distribuovat provoz do veřejných aplikací napříč globálními oblastmi Azure. Traffic Manager také poskytuje veřejné koncové body s vysokou dostupností a rychlou odezvou.
Traffic Manager pomocí DNS směruje požadavky klientů na příslušný koncový bod služby na základě metody směrování provozu. Traffic Manager také poskytuje monitorování stavu pro každý koncový bod. Koncový bod může být libovolná internetová služba hostovaná uvnitř Nebo mimo Azure. Traffic Manager poskytuje celou řadu metod směrování provozu a možností monitorování koncových bodů, takže vyhovuje různým požadavkům aplikací a modelům automatického převzetí služeb při selhání. Služba Traffic Manager je odolná vůči selhání, a to i selhání celé oblasti Azure.
Zotavení po havárii v geografické oblasti s více oblastmi
DNS je jedním z nejúčinnějších mechanismů pro přesměrování síťového provozu. DNS je efektivní, protože DNS je často globální a externí pro datové centrum. DNS je také izolovaný od jakýchkoli selhání na úrovni oblastí nebo zón dostupnosti (AZ).
K nastavení architektury zotavení po havárii existují dva technické aspekty:
Použití mechanismu nasazení k replikaci instancí, dat a konfigurací mezi primárním a pohotovostním prostředím. Tento typ zotavení po havárii je možné provést nativně prostřednictvím SlužbyAzure Site Recovery, viz dokumentace ke službě Azure Site Recovery prostřednictvím partnerských zařízení nebo služeb Microsoft Azure, jako jsou Veritas nebo NetApp.
Vývoj řešení pro přesměrování síťového nebo webového provozu z primární lokality do pohotovostní lokality Tento typ zotavení po havárii je možné dosáhnout prostřednictvím Azure DNS, Azure Traffic Manageru (DNS) nebo globálních nástrojů pro vyrovnávání zatížení třetích stran.
Tento článek se zaměřuje konkrétně na plánování zotavení po havárii Azure Traffic Manageru.
Detekce výpadků, oznámení a správa
Během havárie se primární koncový bod vyhodnocuje a stav se změní na snížený výkon a lokalita zotavení po havárii zůstane online. Ve výchozím nastavení Traffic Manager odesílá veškerý provoz na primární koncový bod (s nejvyšší prioritou). Pokud se primární koncový bod zobrazí se sníženým výkonem, Traffic Manager směruje provoz do druhého koncového bodu, dokud zůstane v pořádku. Můžete nakonfigurovat více koncových bodů v Traffic Manageru, které můžou sloužit jako další koncové body převzetí služeb při selhání, nebo jako nástroje pro vyrovnávání zatížení sdílející zatížení mezi koncovými body.
Nastavení detekce zotavení po havárii a výpadku
Pokud máte složité architektury a několik sad prostředků schopných provést stejnou funkci, můžete nakonfigurovat Azure Traffic Manager (na základě DNS) tak, aby kontrolovaly stav vašich prostředků a směrovaly provoz z prostředku, který není v pořádku, do prostředku, který je v pořádku.
V následujícím příkladu mají primární i sekundární oblast úplné nasazení. Toto nasazení zahrnuje cloudové služby a synchronizovanou databázi.
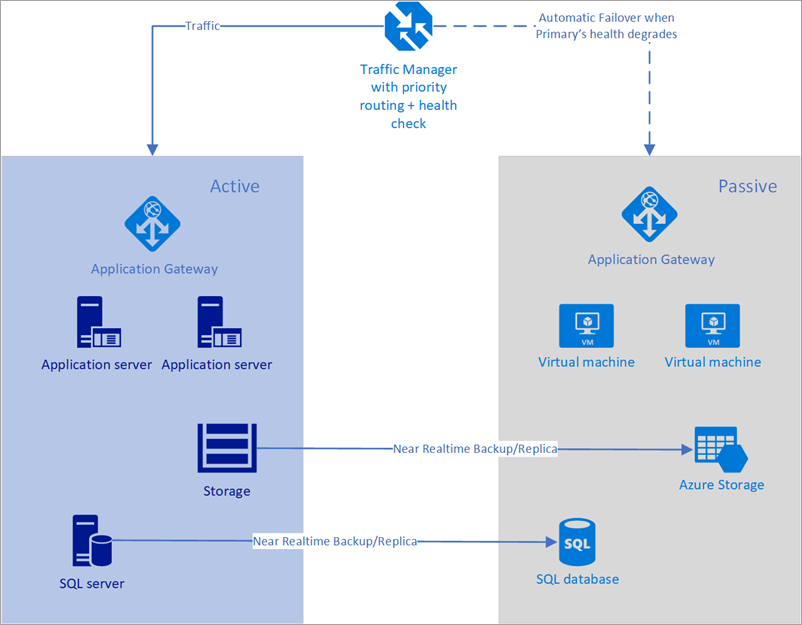
Obrázek – Automatické převzetí služeb při selhání pomocí Azure Traffic Manageru
Pouze primární oblast ale aktivně zpracovává síťové požadavky od uživatelů. Sekundární oblast se aktivuje jenom v případech, kdy dojde k přerušení služby v primární oblasti. V takovém případě všechny nové síťové požadavky směrují do sekundární oblasti. Vzhledem k tomu, že zálohování databáze je téměř okamžité, oba nástroje pro vyrovnávání zatížení mají IP adresy, které je možné zkontrolovat stav, a instance jsou vždy v provozu, tato topologie poskytuje možnost přejít za nízkou plánovanou dobu obnovení a převzetí služeb při selhání bez jakéhokoli ručního zásahu. Sekundární oblast převzetí služeb při selhání musí být připravená na aktivní okamžitě po selhání primární oblasti.
Tento scénář je ideální pro použití Azure Traffic Manageru, který má předem připravené sondy pro různé typy kontrol stavu, včetně http / https a TCP. Azure Traffic Manager má také modul pravidel, který je možné nakonfigurovat tak, aby při selhání převzal služby při selhání, jak je popsáno níže. Pojďme se podívat na následující řešení s využitím Traffic Manageru:
- Zákazník má koncový bod Region č. 1 známý jako prod.contoso.com se statickou IP adresou 100.168.124.44 a koncovým bodem Oblasti č. 2 označovaným jako dr.contoso.com se statickou IP adresou 100.168.124.43.
- Každé z těchto prostředí se předepisuje prostřednictvím veřejné vlastnosti, jako je nástroj pro vyrovnávání zatížení. Nástroj pro vyrovnávání zatížení je možné nakonfigurovat tak, aby měl koncový bod založený na DNS nebo plně kvalifikovaný název domény (FQDN), jak je znázorněno výše.
- Všechny instance v oblasti 2 jsou v téměř reálném čase replikace s oblastí 1. Image počítačů jsou navíc aktuální a všechna softwarová a konfigurační data jsou opravená a jsou v souladu s oblastí 1.
- Automatické škálování je předem předem nakonfigurované.
Konfigurace převzetí služeb při selhání pomocí Azure Traffic Manageru:
Vytvořte nový profil Azure Traffic Manageru Vytvořte nový profil Azure Traffic Manageru s názvem contoso123 a jako prioritu vyberte metodu Směrování. Pokud máte již existující skupinu prostředků, ke které chcete přidružit, můžete vybrat existující skupinu prostředků, jinak vytvořit novou skupinu prostředků.
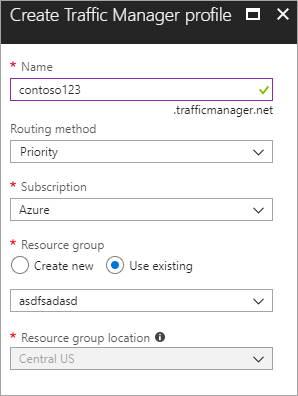
Obrázek – Vytvoření profilu Traffic Manageru
Vytvoření koncových bodů v profilu Traffic Manageru
V tomto kroku vytvoříte koncové body, které odkazují na produkční lokality a lokality zotavení po havárii. Tady zvolte Typ jako externí koncový bod, ale pokud je prostředek hostovaný v Azure, můžete také zvolit koncový bod Azure. Pokud zvolíte koncový bod Azure, vyberte cílový prostředek , který je službou App Service nebo veřejnou IP adresou přidělenou Azure. Priorita je nastavená jako 1 , protože se jedná o primární službu pro oblast 1. Podobně vytvořte také koncový bod zotavení po havárii v Traffic Manageru.
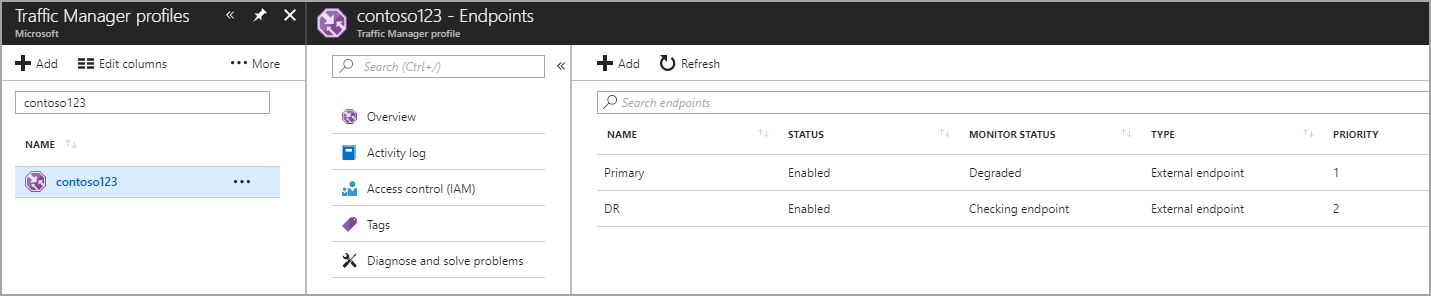
Obrázek – Vytvoření koncových bodů zotavení po havárii
Nastavení kontroly stavu a konfigurace převzetí služeb při selhání
V tomto kroku nastavíte hodnotu TTL DNS na 10 sekund, která je respektována většinou rekurzivních překladačů směřujících k internetu. Tato konfigurace znamená, že žádný překladač DNS nebude ukládat informace do mezipaměti po dobu delší než 10 sekund.
U nastavení monitorování koncových bodů je cesta aktuálně nastavená na / nebo kořen, ale můžete přizpůsobit nastavení koncového bodu tak, aby vyhodnocovala cestu, například prod.contoso.com/index.
Následující příklad ukazuje https jako protokol sondy. Můžete ale také zvolit protokol HTTP nebo tcp . Volba protokolu závisí na koncové aplikaci. Interval sondy je nastavený na 10 sekund, což umožňuje rychlé sondování a opakování je nastaveno na hodnotu 3. V důsledku toho Traffic Manager převezme služby při selhání druhému koncovému bodu, pokud tři po sobě jdoucí intervaly zaregistrují selhání.
Následující vzorec definuje celkovou dobu automatického převzetí služeb při selhání:
Time for failover = TTL + Retry * Probing intervalA v tomto případě je hodnota 10 + 3 * 10 = 40 sekund (Max).
Pokud je opakování nastaveno na hodnotu 1 a hodnota TTL je nastavená na 10 sekund, je čas převzetí služeb při selhání 10 + 1 * 10 = 20 sekund.
Nastavte opakování na hodnotu větší než 1 , aby se eliminovala šance na převzetí služeb při selhání z důvodu falešně pozitivních výsledků nebo jakýchkoli menších tří teček sítě.
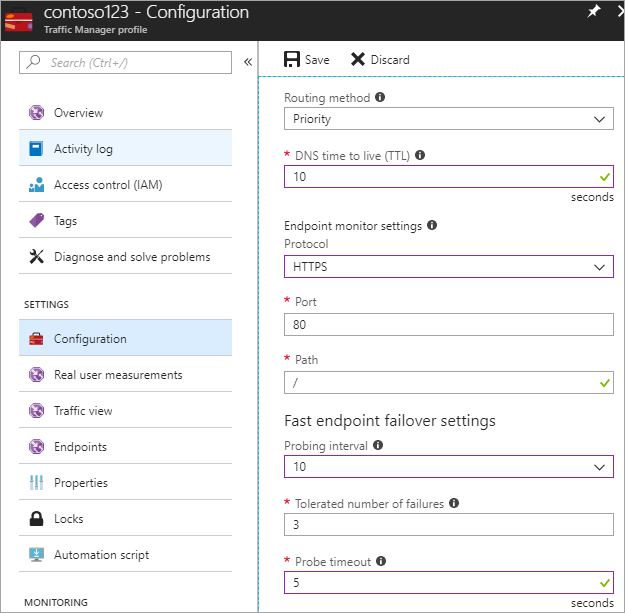
Obrázek – Nastavení kontroly stavu a konfigurace převzetí služeb při selhání
Další kroky
Přečtěte si další informace o Azure Traffic Manageru.
Přečtěte si další informace o Azure DNS.