Hledání obsahu služby Azure Blob Storage
Hledání v různých typech obsahu uložených ve službě Azure Blob Storage může být obtížné vyřešit, ale Azure AI Search poskytuje hlubokou integraci ve vrstvě obsahu, extrahování a odvozování textových informací, které se pak dají dotazovat v indexu vyhledávání.
V tomto článku si projděte základní pracovní postup pro extrakci obsahu a metadata z objektů blob a jeho odeslání do indexu vyhledávání ve službě Azure AI Search. Výsledný index se dá dotazovat pomocí fulltextového vyhledávání. Volitelně můžete zpracovaný obsah objektu blob odeslat do úložiště znalostí pro scénáře, které neprohledají.
Poznámka:
Už znáte pracovní postup a složení? Dalším krokem je konfigurace indexeru objektů blob.
Co znamená přidat fulltextové vyhledávání do dat objektů blob
Azure AI Search je samostatná vyhledávací služba, která podporuje indexování a dotazování úloh nad uživatelsky definovanými indexy, které obsahují váš privátní prohledávatelný obsah hostovaný v cloudu. Společné vyhledání prohledávatelného obsahu s dotazovacím strojem v cloudu je nezbytné pro výkon a vracení výsledků s rychlostí, kterou uživatelé očekávají od vyhledávacích dotazů.
Azure AI Search se integruje se službou Azure Blob Storage ve vrstvě indexování a importuje obsah objektů blob jako vyhledávací dokumenty indexované do invertovaných indexů a dalších struktur dotazů, které podporují textové dotazy volného formátu a výrazy filtru. Vzhledem k tomu, že se obsah objektu blob indexuje do indexu vyhledávání, můžete k vyhledání informací v obsahu objektu blob použít celou řadu funkcí dotazů ve službě Azure AI Search.
Vstupy jsou objekty blob v jednom kontejneru ve službě Azure Blob Storage. Objekty blob můžou být téměř jakýkoli druh textových dat. Pokud objekty blob obsahují obrázky, můžete přidat obohacení AI, abyste z obrázků vytvořili a extrahovali text a funkce.
Výstup je vždy index azure AI Search, který se používá k rychlému vyhledávání, načítání a zkoumání textu v klientských aplikacích. Mezi tím je samotná architektura kanálu indexování. Kanál je založený na funkci indexeru, která je podrobněji popsána v tomto článku.
Po vytvoření a naplnění indexu existuje nezávisle na kontejneru objektů blob, ale můžete znovu spustit operace indexování a aktualizovat index na základě změněných dokumentů. Informace o časovém razítku jednotlivých objektů blob se používají k detekci změn. Jako mechanismus aktualizace můžete zvolit plánované spuštění nebo indexování na vyžádání.
Prostředky používané v řešení vyhledávání objektů blob
Potřebujete Azure AI Search, Azure Blob Storage a klienta. Azure AI Search je obvykle jednou z několika komponent řešení, kde váš kód aplikace vydává dotazy na požadavky rozhraní API a zpracovává odpověď. Můžete také napsat kód aplikace pro zpracování indexování, i když pro testování konceptu a improvizované úlohy je běžné používat Azure Portal jako vyhledávacího klienta.
Ve službě Blob Storage budete potřebovat kontejner, který poskytuje zdrojový obsah. Můžete nastavit kritéria zahrnutí a vyloučení souborů a určit, které části objektu blob se indexují ve službě Azure AI Search.
Můžete začít přímo na stránce portálu účtu úložiště.
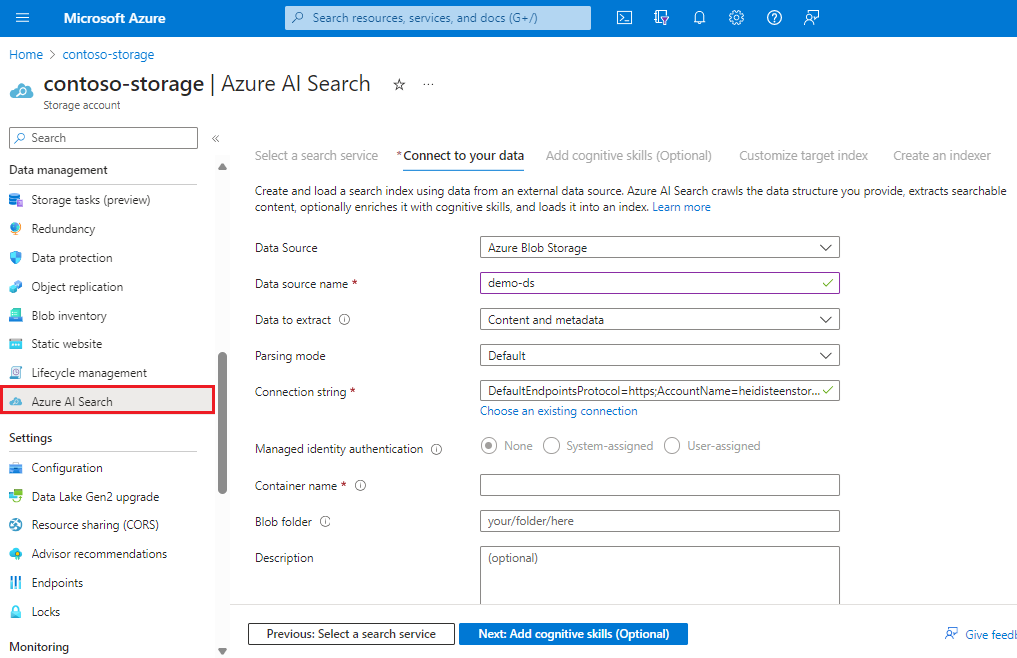
Na levé navigační stránce v části Správa dat vyberte Azure AI Search a vyberte nebo vytvořte vyhledávací službu.
Podle kroků v průvodci extrahujte a volitelně vytvořte prohledávatelný obsah z objektů blob. Pracovní postup je Průvodce importem dat. Pracovní postup vytvoří indexer, zdroj dat, index a sadu dovedností možností na vašem Search Azure AI.
Pomocí Průzkumníka služby Search na stránce vyhledávacího portálu můžete dotazovat obsah.
Průvodce je nejlepším místem, kde začít, ale při vlastní konfiguraci indexeru objektů blob zjistíte flexibilnější možnosti. Můžete použít klienta REST. Kurz: Indexování a vyhledávání částečně strukturovaných dat (objektů blob JSON) vás provede postupem volání rozhraní REST API.
Jak se objekty blob indexují
Ve výchozím nastavení se většina objektů blob indexuje jako jeden vyhledávací dokument v indexu, včetně objektů blob se strukturovaným obsahem, jako je JSON nebo CSV, které se indexují jako jeden blok textu. U dokumentů JSON nebo CSV s interní strukturou (oddělovači) ale můžete přiřadit režimy analýzy, které generují jednotlivé dokumenty hledání pro každý řádek nebo prvek:
Složený nebo vložený dokument (například archiv ZIP, wordový dokument s vloženým outlookovým e-mailem obsahujícím přílohy nebo přílohy. Soubor MSG s přílohami) je také indexován jako jeden dokument. Například všechny obrázky extrahované z přílohy objektu . Soubor MSG bude vrácen v poli normalized_images. Pokud máte obrázky, zvažte přidání rozšíření AI, abyste z tohoto obsahu získali další vyhledávací nástroj.
Textový obsah dokumentu se extrahuje do textového pole s názvem "content". Můžete také extrahovat standardní a uživatelsky definovaná metadata.
Poznámka:
Azure AI Search omezuje množství textu, které extrahuje v závislosti na cenové úrovni. Pokud jsou dokumenty zkráceny, zobrazí se v odpovědi na stav indexeru upozornění.
Použití indexeru objektů blob k extrakci obsahu
Indexer je podslužba podporující zdroj dat ve službě Azure AI Search, která je vybavena interní logikou pro vzorkování dat, čtení a načítání dat a metadat a serializaci dat z nativních formátů do dokumentů JSON pro následný import.
Objekty blob ve službě Azure Storage se indexují pomocí indexeru objektů blob. Tento indexer můžete vyvolat pomocí příkazu Azure AI Search ve službě Azure Storage, průvodce importem dat , rozhraním REST API nebo sadou .NET SDK. V kódu použijete tento indexer nastavením typu a poskytnutím informací o připojení, které zahrnují účet služby Azure Storage spolu s kontejnerem objektů blob. Objekty blob můžete podmnožinou vytvořením virtuálního adresáře, který pak můžete předat jako parametr, nebo filtrováním přípony typu souboru.
Indexer "prolomí dokument", otevře objekt blob pro kontrolu obsahu. Po připojení ke zdroji dat se jedná o první krok v kanálu. V případě dat objektů blob se zjistí pdf, dokumenty Office a další typy obsahu. Zalomení dokumentu s extrakcí textu není zpoplatněno. Pokud objekty blob obsahují obsah obrázku, obrázky se ignorují, pokud nepřidáte rozšiřování AI. Standardní indexování se vztahuje pouze na textový obsah.
Indexer objektů blob Azure obsahuje konfigurační parametry a podporuje sledování změn, pokud podkladová data poskytují dostatečné informace. Další informace o základních funkcích v indexových datech z Azure Blob Storage.
Podporované úrovně přístupu
Mezi úrovně přístupu k úložišti objektů blob patří horká, studená a archivní úroveň. Indexery můžou přistupovat pouze k horké a studené.
Podporované typy obsahu
Spuštěním indexeru objektů blob v kontejneru můžete extrahovat text a metadata z následujících typů obsahu pomocí jednoho dotazu:
- CSV (viz indexování objektů blob CSV)
- EML
- EPUB
- GZ
- HTML
- JSON (viz indexování objektů blob JSON)
- KML (XML pro geografické reprezentace)
- formáty systém Microsoft Office: DOCX/DOC/DOCM, XLSX/XLS/XLSM, PPTX/PPTM, MSG (e-maily Outlooku), XML (2003 i 2006 WORD XML)
- Formáty otevřených dokumentů: ODT, ODS, ODP
- Soubory ve formátu prostého textu (viz také indexování prostého textu)
- RTF
- XML
- ZIP
Řízení indexovaných objektů blob
Můžete určit, které objekty blob se indexují a které se přeskočí, podle typu souboru objektu blob nebo nastavením vlastností samotného objektu blob, což způsobí, že indexer je přeskočí.
Zahrňte konkrétní přípony souborů nastavením "indexedFileNameExtensions" na čárkami oddělený seznam přípon souborů (s úvodní tečkou). Vylučte konkrétní přípony souborů nastavením "excludedFileNameExtensions" na přípony, které by se měly přeskočit. Pokud je stejné rozšíření v obou seznamech, bude vyloučeno z indexování.
PUT /indexers/[indexer name]?api-version=2023-11-01
{
"parameters" : {
"configuration" : {
"indexedFileNameExtensions" : ".pdf, .docx",
"excludedFileNameExtensions" : ".png, .jpeg"
}
}
}
Přidání metadat "skip" objektu blob
Parametry konfigurace indexeru se vztahují na všechny objekty blob v kontejneru nebo složce. Někdy chcete řídit, jak se jednotlivé objekty blob indexují.
Do objektů blob ve službě Blob Storage přidejte následující vlastnosti a hodnoty metadat. Když indexer na tuto vlastnost narazí, přeskočí objekt blob nebo jeho obsah při spuštění indexování.
| Název vlastnosti | Hodnota vlastnosti | Vysvětlení |
|---|---|---|
| "AzureSearch_Skip" | "true" |
Dává indexeru objektů blob pokyn, aby objekt blob úplně přeskočil. Metadata ani extrakce obsahu se nepokoušnou. To je užitečné, když se konkrétní objekt blob opakovaně nezdaří a přeruší proces indexování. |
| "AzureSearch_SkipContent" | "true" |
To odpovídá "dataToExtract" : "allMetadata" nastavení popsanému výše vymezenému konkrétnímu objektu blob. |
Indexování metadat objektů blob
Běžným scénářem, který usnadňuje řazení objektů blob libovolného typu obsahu, je indexování vlastních metadat i systémových vlastností pro každý objekt blob. Tímto způsobem se informace pro všechny objekty blob indexují bez ohledu na typ dokumentu uloženého v indexu ve vyhledávací službě. Pomocí nového indexu pak můžete pokračovat v řazení, filtrování a fazetě napříč veškerým obsahem úložiště objektů blob.
Poznámka:
Značky indexu objektů blob jsou nativně indexovány službou Blob Storage a vystavené pro dotazování. Pokud atributy klíče a hodnoty objektů blob vyžadují funkce indexování a filtrování, měly by se místo metadat využívat značky indexu objektů blob.
Další informace o indexu objektů blob najdete v tématu Správa a vyhledání dat ve službě Azure Blob Storage pomocí indexu objektů blob.
Vyhledávání obsahu objektu blob v indexu vyhledávání
Výstupem indexeru je vyhledávací index, který se používá k interaktivnímu zkoumání pomocí volného textu a filtrovaných dotazů v klientské aplikaci. Pro počáteční zkoumání a ověření obsahu doporučujeme začít s Průzkumníkem služby Search na portálu, abyste prozkoumali strukturu dokumentů. V Průzkumníku služby Search můžete použít:
Trvalejším řešením je shromáždit vstupy dotazů a prezentovat odpověď jako výsledky hledání v klientské aplikaci. Následující kurz jazyka C# vysvětluje, jak vytvořit vyhledávací aplikaci: Přidání vyhledávání do aplikace ASP.NET Core (MVC).