Poznámka
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Rozšíření AI ve službě Azure AI Search odkazuje na integraci se službami Azure AI za účelem zpracování obsahu, který nelze prohledávat v nezpracované podobě. Prostřednictvím rozšiřování, analýzy a odvozování se používají k vytvoření prohledávatelného obsahu a struktury, kde nikdo dříve neexistoval.
Vzhledem k tomu, že Azure AI Search se používá pro textové a vektorové dotazy, účelem rozšiřování AI je zlepšit nástroj vašeho obsahu ve scénářích souvisejících s vyhledáváním. Surový obsah musí být text nebo obrázky (vektory nemůžete rozšířit), ale výstup z kanálu rozšiřování je možné vektorizovat a zaindexovat ve vyhledávacím indexu pomocí dovedností, jako je dovednost Rozdělení textu pro rozdělování na části a dovednost AzureOpenAIEmbedding pro kódování vektorů. Další informace o používání dovedností ve scénářích vektorů najdete v tématu Integrované bloky dat a vkládání.
Rozšiřování AI je založeno na dovednostech.
Integrované dovednosti klepněte na služby Azure AI. Na nezpracovaný obsah používají následující transformace a zpracování:
- Překlad a rozpoznávání jazyka pro vícejazyčné vyhledávání
- Rozpoznávání entit pro extrahování jmen lidí, míst a dalších entit z velkých bloků textu
- Extrakce klíčových frází pro identifikaci a výstup důležitých termínů
- Optické rozpoznávání znaků (OCR) k rozpoznávání tištěného a ručně psaného textu v binárních souborech
- Analýza obrázků popisuje obsah obrázku a vypíše popisy jako prohledávatelná textová pole.
Vlastní dovednosti spouštějí váš externí kód. Vlastní dovednosti se dají použít pro jakékoli vlastní zpracování, které chcete zahrnout do kanálu.
Rozšiřování AI je rozšíření kanálu indexeru, který se připojuje ke zdrojům dat Azure. Kanál rozšiřování má všechny součásti kanálu indexeru (indexer, zdroj dat, index) a sadu dovedností, která určuje kroky atomového rozšiřování.
Následující diagram znázorňuje průběh rozšiřování AI:
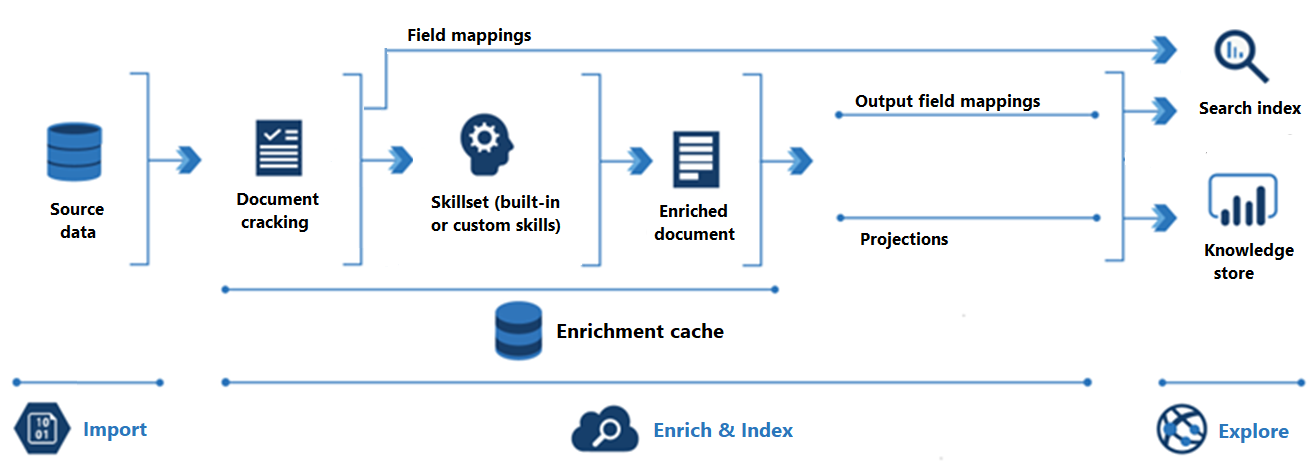
Import je prvním krokem. Indexer se tady připojí ke zdroji dat a načte obsah (dokumenty) do vyhledávací služby. Azure Blob Storage je nejběžnější prostředek používaný ve scénářích rozšiřování AI, ale jakýkoli podporovaný zdroj dat může poskytovat obsah.
Rozšíření a index pokrývá většinu kanálu rozšiřování AI:
Rozšiřování začíná, když indexer "prolomí dokumenty" a extrahuje obrázky a text. Druh zpracování, ke kterému dojde dále, závisí na vašich datech a na dovednostech, které jste přidali do sady dovedností. Pokud máte obrázky, můžete je předat dovednostem, které provádějí zpracování obrázků. Textový obsah je zařazen do fronty pro zpracování textu a přirozeného jazyka. Interně dovednosti vytvářejí "obohacený dokument" , který shromažďuje transformace při jejich výskytu.
Obohacený obsah se generuje během provádění sady dovedností a je dočasný, pokud ho neuložíte. Můžete povolit mezipaměť rozšiřování, která bude uchovávat prolomené dokumenty a výstupy dovedností pro následné opakované použití během budoucích spuštění sady dovedností.
Aby se obsah dostal do indexu vyhledávání, musí mít indexer informace o mapování pro odesílání rozšířeného obsahu do cílového pole. Mapování polí (explicitní nebo implicitní) nastavují cestu k datům ze zdrojových dat na index vyhledávání. Mapování výstupních polí nastavují cestu k datům z obohacených dokumentů na index.
Indexování je proces, při kterém se nezpracovaný a obohacený obsah ingestuje do fyzických datových struktur indexu vyhledávání (jeho souborů a složek). V tomto kroku dochází k lexikální analýze a tokenizaci.
Průzkum je posledním krokem. Výstup je vždy vyhledávací index , který můžete dotazovat z klientské aplikace. Výstupem může být úložiště znalostí skládající se z objektů blob a tabulek ve službě Azure Storage, ke kterým se přistupuje prostřednictvím nástrojů pro zkoumání dat nebo podřízených procesů. Pokud vytváříte úložiště znalostí, projekce určují cestu k datům pro obohacený obsah. Stejný obohacený obsah se může objevit jak v indexech, tak v úložištích znalostí.
Kdy použít rozšiřování AI
Rozšiřování je užitečné, pokud je nezpracovaný obsah nestrukturovaný text, obsah obrázku nebo obsah, který potřebuje rozpoznávání a překlad jazyka. Použití umělé inteligence prostřednictvím integrovaných dovedností může tento obsah odemknout pro fulltextové vyhledávání a aplikace pro datové vědy.
Můžete také vytvořit vlastní dovednosti pro zajištění externího zpracování. Opensourcový, třetí strana nebo kód první strany je možné integrovat do kanálu jako vlastní dovednost. Klasifikační modely, které identifikují určité charakteristiky různých typů dokumentů, spadají do této kategorie, ale všechny externí balíčky, které do vašeho obsahu přidávají hodnotu, je možné použít.
Případy použití pro předdefinované dovednosti
Integrované dovednosti jsou založené na rozhraních API služeb Azure AI: Azure AI Počítačové zpracování obrazu a language Service. Pokud není vstup obsahu malý, počítejte s tím, že připojíte fakturovatelný prostředek služeb Azure AI, který bude spouštět větší úlohy.
Sada dovedností sestavená pomocí předdefinovaných dovedností je vhodná pro následující scénáře aplikací:
Dovednosti zpracování obrázků zahrnují optické rozpoznávání znaků (OCR) a identifikaci vizuálních funkcí, jako je rozpoznávání obličeje, interpretace obrazu, rozpoznávání obrázků (známé osoby a orientační body) nebo atributy, jako je orientace obrázku. Tyto dovednosti vytvářejí textové reprezentace obsahu obrázků pro fulltextové vyhledávání ve službě Azure AI Search.
Strojový překlad poskytuje dovednost překladu textu, často spárovaná s rozpoznáváním jazyka pro řešení s více jazyky.
Zpracování přirozeného jazyka analyzuje bloky textu. Dovednosti v této kategorii zahrnují rozpoznávání entit, detekci mínění (včetně dolování názorů) a rozpoznávání osobních identifikovatelných informací. S těmito dovednostmi se nestrukturovaný text mapuje jako prohledávatelná a filtrovatelná pole v indexu.
Případy použití pro vlastní dovednosti
Vlastní dovednosti provádějí externí kód, který poskytnete a zabalíte do webového rozhraní vlastní dovednosti. Několik příkladů vlastních dovedností najdete v úložišti GitHubu azure-search-power-skills .
Vlastní dovednosti nejsou vždy složité. Pokud máte například existující balíček, který poskytuje porovnávání vzorů nebo model klasifikace dokumentů, můžete ho zabalit do vlastní dovednosti.
Ukládání výstupu
Ve službě Azure AI Search indexer uloží výstup, který vytvoří. Jedno spuštění indexeru může vytvořit až tři datové struktury, které obsahují rozšířené a indexované výstupy.
| Úložiště dat | Požaduje se | Umístění | Popis |
|---|---|---|---|
| prohledávatelný index | Požaduje se | Služba Search | Používá se pro fulltextové vyhledávání a další formuláře dotazu. Zadání indexu je požadavek indexeru. Obsah indexu se naplní z výstupů dovedností a všechna zdrojová pole mapovaná přímo na pole v indexu. |
| úložiště znalostí | Volitelné | Azure Storage | Používá se pro podřízené aplikace, jako je dolování znalostí nebo datové vědy. Úložiště znalostí je definováno v sadě dovedností. Její definice určuje, jestli se vaše rozšířené dokumenty promítají jako tabulky nebo objekty (soubory nebo objekty blob) ve službě Azure Storage. |
| mezipaměť rozšiřování | Volitelné | Azure Storage | Používá se k rozšiřování mezipaměti pro opakované použití v následných spuštěních sady dovedností. Mezipaměť ukládá importovaný, nezpracovaný obsah (prolomené dokumenty). Ukládá také rozšířené dokumenty vytvořené během provádění sady dovedností. Ukládání do mezipaměti je užitečné, pokud používáte analýzu obrázků nebo technologii OCR a chcete se vyhnout času a nákladům na opětovné zpracování souborů obrázků. |
Indexy a úložiště znalostí jsou plně nezávislé na sobě. Pokud je jediným cílem úložiště znalostí, musíte připojit index, který vyhovuje požadavkům indexeru, můžete index po naplnění ignorovat.
Zkoumání obsahu
Po definování a načtení indexu vyhledávání nebo úložiště znalostí můžete prozkoumat jeho data.
Dotazování indexu vyhledávání
Spusťte dotazy pro přístup k rozšířenému obsahu vygenerovaném kanálem. Index je jako jakýkoli jiný, který byste mohli vytvořit pro Azure AI Search: můžete doplnit analýzu textu vlastními analyzátory, vyvolat přibližné vyhledávací dotazy, přidat filtry nebo experimentovat s bodovacími profily za účelem vyladění relevance vyhledávání.
Použití nástrojů pro zkoumání dat ve znalostním úložišti
Úložiště znalostí ve službě Azure Storage může předpokládat následující formy: kontejner objektů blob dokumentů JSON, kontejner objektů blob objektů obrázků nebo tabulky ve službě Table Storage. K přístupu k obsahu můžete použít Průzkumník služby Storage, Power BI nebo libovolnou aplikaci, která se připojuje ke službě Azure Storage.
Kontejner objektů blob zachycuje rozšířené dokumenty v celém rozsahu, což je užitečné, pokud vytváříte informační kanál do jiných procesů.
Tabulka je užitečná, pokud potřebujete řezy obohacených dokumentů nebo pokud chcete zahrnout nebo vyloučit konkrétní části výstupu. Pro analýzu v Power BI jsou tabulky doporučeným zdrojem dat pro zkoumání a vizualizaci dat v Power BI.
Dostupnost a ceny
Rozšiřování je dostupné v oblastech, které mají služby Azure AI. Dostupnost rozšiřování můžete zkontrolovat na stránce seznamu oblastí.
Fakturace se řídí cenovým modelem Standard. Náklady na používání předdefinovaných dovedností se předávají, když je v sadě dovedností specifikovaný klíč služeb Azure AI pro více oblastí. K extrakci obrázků jsou spojené také náklady, které se měří službou Azure AI Search. Extrakce textu a nástroje ale nejsou fakturovatelné. Další informace najdete v tématu Jak se vám účtují poplatky za Azure AI Search.
Kontrolní seznam: Typický pracovní postup
Kanál rozšiřování se skládá z indexerů, které mají sady dovedností. Po indexování můžete zadat dotaz na index, abyste ověřili výsledky.
Začněte podmnožinou dat v podporovaném zdroji dat. Návrh indexeru a sady dovedností je iterativní proces. Práce probíhá rychleji s malou reprezentativní sadou dat.
Vytvořte zdroj dat, který určuje připojení k vašim datům.
Vytvořte sadu dovedností. Pokud váš projekt není malý, měli byste připojit prostředek pro více služeb Azure AI. Pokud vytváříte úložiště znalostí, definujte ho v sadě dovedností.
Vytvořte schéma indexu, které definuje index vyhledávání.
Vytvořte a spusťte indexer , aby se všechny výše uvedené komponenty spojily. Tento krok načte data, spustí sadu dovedností a načte index.
Indexer je také místo, kde zadáte mapování polí a mapování výstupních polí, která nastaví cestu k datům indexu vyhledávání.
Volitelně můžete povolit ukládání do mezipaměti rozšiřování v konfiguraci indexeru. Tento krok umožňuje později znovu použít existující rozšiřování.
Spuštěním dotazů vyhodnoťte výsledky nebo spusťte ladicí relaci a projděte si případné problémy se sadou dovedností.
Pokud chcete zopakovat některý z výše uvedených kroků, před spuštěním indexeru ho resetujte. Nebo odstraňte a znovu vytvořte objekty při každém spuštění (doporučujeme, pokud používáte úroveň Free). Pokud jste povolili ukládání indexeru do mezipaměti, přetáhne se z mezipaměti, pokud se data nezmění ve zdroji a pokud vaše úpravy kanálu nebudou zneplatnit mezipaměť.