Fulltextové vyhledávání ve službě Azure AI Search
Fulltextové vyhledávání je přístup při načítání informací, který odpovídá prostému textu uloženému v indexu. Například vzhledem k řetězci dotazu "hotely v San Diego na pláži", vyhledávací web vyhledá tokenizované řetězce na základě těchto termínů. Aby byly prohledávání efektivnější, řetězce dotazů procházejí lexikální analýzou: všechny termíny s nižším písmenem, odebírání slov stop jako "the" a omezení termínů na primitivní kořenové formuláře. Při hledání shodných termínů vyhledávací web načte dokumenty, řadí je v pořadí podle relevance a vrací nejlepší výsledky.
Provádění dotazů může být složité. Tento článek je určený pro vývojáře, kteří potřebují hlubší porozumění fungování fulltextového vyhledávání ve službě Azure AI Search. U textových dotazů služba Azure AI Search bezproblémově poskytuje očekávané výsledky ve většině scénářů, ale někdy se může zobrazit výsledek, který se zdá být "vypnutý". V těchto situacích vám může pomoct identifikovat konkrétní změny parametrů dotazu nebo konfigurace indexu, které vytvářejí požadovaný výsledek, ve čtyřech fázích provádění dotazů (analýza dotazů, lexikální analýza, porovnávání dokumentů, bodování).
Poznámka:
Azure AI Search používá Apache Lucene k fulltextovém vyhledávání, ale integrace Lucene není vyčerpávající. Selektivně zveřejňujeme a rozšiřujeme funkce Lucene, abychom umožnili scénáře důležité pro Azure AI Search.
Přehled architektury a diagram
Provádění dotazů má čtyři fáze:
- Analýza dotazů
- Lexikální analýza
- Načtení dokumentu
- Vyhodnocování
Fulltextový vyhledávací dotaz začíná parsováním textu dotazu za účelem extrakce hledaných termínů a operátorů. Existují dva analyzátory, abyste si mohli vybrat mezi rychlostí a složitostí. Dále je fáze analýzy, ve které jsou jednotlivé termíny dotazů někdy rozděleny a rekonstituovány do nových forem. Tento krok pomáhá přetypovat širší síť na to, co by se dalo považovat za potenciální shodu. Vyhledávací web pak prohledá index a vyhledá dokumenty s odpovídajícími termíny a skóre každé shody. Sada výsledků se pak seřadí podle skóre relevance přiřazeného jednotlivým odpovídajícím dokumentům. Ty v horní části seřazeného seznamu se vrátí do volající aplikace.
Následující diagram znázorňuje komponenty používané ke zpracování žádosti o vyhledávání.
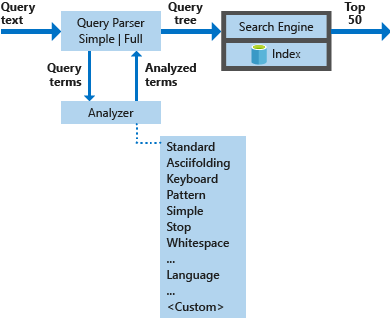
| Klíčové komponenty | Funkční popis |
|---|---|
| Analyzátory dotazů | Oddělte termíny dotazu od operátorů dotazu a vytvořte strukturu dotazu (strom dotazu), která se má odeslat do vyhledávacího webu. |
| Analyzátory | Proveďte lexikální analýzu termínů dotazů. Tento proces může zahrnovat transformaci, odebrání nebo rozšíření termínů dotazů. |
| Index | Efektivní datová struktura používaná k ukládání a uspořádání hledaných termínů extrahovaných z indexovaných dokumentů. |
| Vyhledávač | Načte a vyhodnotuje odpovídající dokumenty na základě obsahu invertovaného indexu. |
Anatomie požadavku hledání
Požadavek hledání je úplná specifikace toho, co by se mělo vrátit v sadě výsledků. V nejjednodušší podobě se jedná o prázdný dotaz bez jakýchkoli kritérií. Realističtější příklad zahrnuje parametry, několik termínů dotazu, které jsou možná vymezeny na určitá pole, s možná výrazem filtru a pravidly řazení.
Následující příklad je žádost o vyhledávání, kterou můžete odeslat do služby Azure AI Search pomocí rozhraní REST API.
POST /indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "Spacious, air-condition* +\"Ocean view\"",
"searchFields": "description, title",
"searchMode": "any",
"filter": "price ge 60 and price lt 300",
"orderby": "geo.distance(location, geography'POINT(-159.476235 22.227659)')",
"queryType": "full"
}
Pro tento požadavek vyhledávací web provede následující operace:
Najde dokumenty, ve kterých je cena alespoň 60 Kč a menší než 300 Kč.
Spustí dotaz. V tomto příkladu se vyhledávací dotaz skládá z frází a termínů:
"Spacious, air-condition* +\"Ocean view\""(uživatelé obvykle nezadávají interpunkci, ale jejich zahrnutí do příkladu nám umožňuje vysvětlit, jak ho analyzátory zpracovávají).Pro tento dotaz prohledá vyhledávací web pole popisu a názvu zadané v "searchFields" pro dokumenty, které obsahují
"Ocean view", a dále termín"spacious", nebo termíny, které začínají předponou"air-condition". Parametr "searchMode" se používá ke shodě u libovolného termínu (výchozí) nebo u všech, v případech, kdy se termín explicitně nevyžaduje (+).Objedná výslednou sadu hotelů podle blízkosti daného zeměpisného umístění a poté vrátí výsledky volající aplikaci.
Většina tohoto článku se zabývá zpracováním vyhledávacího dotazu: "Spacious, air-condition* +\"Ocean view\"". Filtrování a řazení je mimo rozsah. Další informace najdete v referenční dokumentaci k rozhraní API služby Search.
Fáze 1: Analýza dotazů
Jak je uvedeno, řetězec dotazu je prvním řádkem požadavku:
"search": "Spacious, air-condition* +\"Ocean view\"",
Analyzátor dotazů odděluje operátory (například * v + příkladu) od hledaných termínů a dekonstruuje vyhledávací dotaz do poddotazů podporovaného typu:
- dotaz na termíny pro samostatné termíny (například prostorné)
- dotaz na frázi pro citované termíny (například zobrazení oceánu)
- dotaz na předponu pro termíny následované operátorem
*předpony (například klimatizace)
Úplný seznam podporovaných typů dotazů najdete v tématu Syntaxe dotazů Lucene.
Operátory přidružené k poddotazům určují, jestli má být dotaz "musí" nebo "být" splněn, aby byl dokument považován za shodu. Například +"Ocean view" je "must" z důvodu operátoru + .
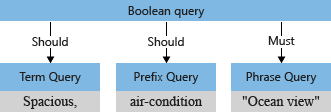
Analyzátor dotazů restrukturalizuje poddotazy do stromu dotazu (interní struktura představující dotaz), který předává do vyhledávacího webu. V první fázi analýzy dotazu vypadá strom dotazu takto.
Podporované analyzátory: Jednoduché a úplné Lucene
Azure AI Search zveřejňuje dva různé dotazovací jazyky ( simple výchozí) a full. Nastavením parametru queryType pomocí požadavku vyhledávání sdělíte analyzátoru dotazů, který dotazovací jazyk zvolíte, aby věděl, jak interpretovat operátory a syntaxi.
Jednoduchý dotazovací jazyk je intuitivní a robustní, často vhodný k interpretaci uživatelského vstupu tak, jak je bez zpracování na straně klienta. Podporuje operátory dotazů známé z webových vyhledávacích webů.
Úplný dotazovací jazyk Lucene, který získáte nastavením
queryType=full, rozšiřuje výchozí jednoduchý dotazovací jazyk přidáním podpory pro další operátory a typy dotazů, jako jsou zástupné card, fuzzy, regex a dotazy v oboru polí. Například regulární výraz odeslaný v syntaxi jednoduchého dotazu by se interpretoval jako řetězec dotazu, nikoli jako výraz. Příklad požadavku v tomto článku používá úplný dotazovací jazyk Lucene.
Dopad searchMode na analyzátor
Dalším parametrem požadavku vyhledávání, který ovlivňuje parsování, je parametr searchMode. Řídí výchozí operátor pro logické dotazy: libovolný (výchozí) nebo všechny.
Když "searchMode=any", což je výchozí, oddělovač mezery mezi prostorným a klimatizací je OR (||), takže ukázkový text dotazu odpovídá:
Spacious,||air-condition*+"Ocean view"
Explicitní operátory, například + v +"Ocean view", jsou jednoznačné v logické konstrukci dotazu (termín se musí shodovat). Méně zřejmé je, jak interpretovat zbývající termíny: prostorné a klimatizované. Měl by vyhledávač najít shody na výhled na oceán a prostorný a klimatizace? Nebo by měl najít výhled na oceán plus jeden z zbývajících termínů?
Ve výchozím nastavení ("searchMode=any") vyhledávací modul předpokládá širší interpretaci. Pole by se mělo shodovat sémantikou "nebo". Počáteční strom dotazu, který je znázorněn dříve, se dvěma operacemi "by" zobrazuje výchozí hodnotu.
Předpokládejme, že teď nastavíme "searchMode=all". V tomto případě se prostor interpretuje jako operace "and". Každý z zbývajících termínů musí být v dokumentu kvalifikovat jako shoda. Výsledný ukázkový dotaz by se interpretoval takto:
+Spacious,+air-condition*+"Ocean view"
Upravený strom dotazu pro tento dotaz by byl následující, kde odpovídající dokument je průsečíkem všech tří poddotazů:

Poznámka:
Volba "searchMode=any" u výrazu "searchMode=all" je rozhodnutí, na které nejlépe dorazí spuštěním reprezentativních dotazů. Uživatelé, kteří budou pravděpodobně zahrnovat operátory (běžné při prohledávání úložišť dokumentů), můžou najít výsledky intuitivnější, pokud "searchMode=all" informuje logické konstrukty dotazů. Další informace o vzájemném přehrání mezi "searchMode" a operátory najdete v tématu Jednoduchá syntaxe dotazu.
Fáze 2: Lexikální analýza
Lexikální analyzátory zpracovávají dotazy termínů a frází po strukturování stromu dotazů. Analyzátor přijme textové vstupy zadané analyzátorem, zpracuje text a pak odešle zpět tokenizované termíny, které se mají začlenit do stromu dotazu.
Nejběžnější formou lexikální analýzy je *lingvistická analýza, která transformuje termíny dotazů na základě pravidel specifických pro daný jazyk:
- Zmenšení termínu dotazu na kořenovou formu slova
- Odebrání jiných než podstatných slov (stopwords, například "the" nebo "and" v angličtině)
- Rozdělení složeného slova do částí součástí
- Malá písmena velkého slova
Všechny tyto operace mají tendenci mazat rozdíly mezi textovým vstupem poskytnutým uživatelem a termíny uloženými v indexu. Tyto operace přesahují zpracování textu a vyžadují podrobné znalosti samotného jazyka. Pokud chcete přidat tuto vrstvu lingvistického povědomí, Azure AI Search podporuje dlouhý seznam analyzátorů jazyka od Lucene i Microsoftu.
Poznámka:
Požadavky na analýzu můžou být v závislosti na vašem scénáři různé od minimálních po propracované. Složitost lexikální analýzy můžete řídit výběrem některého z předdefinovaných analyzátorů nebo vytvořením vlastního analyzátoru. Analyzátory jsou vymezeny na prohledávatelná pole a jsou určeny jako součást definice pole. To umožňuje měnit lexikální analýzu na základě jednotlivých polí. Není zadáno, použije se standardní analyzátor Lucene.
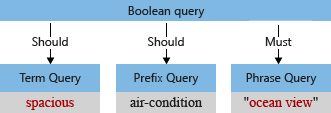
V našem příkladu má před analýzou počáteční strom dotazu termín "Prostorná" s velkými písmeny "S" a čárkou, kterou analyzátor dotazu interpretuje jako součást termínu dotazu (čárka se nepovažuje za operátor dotazovacího jazyka).
Když výchozí analyzátor zpracuje termín, bude mít malé písmeno "oceán view" (zobrazení oceánu) a "spacious" (prostorná) a odebere znak čárky. Upravený strom dotazu vypadá takto:
Testování chování analyzátoru
Chování analyzátoru je možné testovat pomocí rozhraní API pro analýzu. Zadejte text, který chcete analyzovat, abyste viděli, jaké termíny daný analyzátor generuje. Pokud například chcete zjistit, jak standardní analyzátor zpracuje text "klimatizace", můžete vydat následující požadavek:
{
"text": "air-condition",
"analyzer": "standard"
}
Standardní analyzátor rozdělí vstupní text na následující dva tokeny a označí je atributy, jako jsou počáteční a koncové posuny (používané pro zvýraznění hitu) a jejich pozici (používá se pro porovnávání frází):
{
"tokens": [
{
"token": "air",
"startOffset": 0,
"endOffset": 3,
"position": 0
},
{
"token": "condition",
"startOffset": 4,
"endOffset": 13,
"position": 1
}
]
}
Výjimky z lexikální analýzy
Lexikální analýza se vztahuje pouze na typy dotazů, které vyžadují úplné termíny – dotaz na termín nebo dotaz na frázi. Nevztahuje se na typy dotazů s neúplnými termíny – dotaz předpony, dotaz se zástupnými čísly, dotaz regex nebo přibližný dotaz. Tyto typy dotazů, včetně dotazu předpony s termínem air-condition* v našem příkladu, se přidají přímo do stromu dotazu a vynechají fázi analýzy. Jedinou transformací prováděnou s termíny dotazu těchto typů je snížení počtu.
Fáze 3: Načtení dokumentu
Načítání dokumentů odkazuje na hledání dokumentů s odpovídajícími termíny v indexu. Tato fáze je srozumitelná nejlépe prostřednictvím příkladu. Začněme indexem hotelů s následujícím jednoduchým schématem:
{
"name": "hotels",
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false },
{ "name": "title", "type": "Edm.String", "searchable": true },
{ "name": "description", "type": "Edm.String", "searchable": true }
]
}
Dále předpokládejme, že tento index obsahuje následující čtyři dokumenty:
{
"value": [
{
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"id": "2",
"title": "Beach Resort",
"description": "Located on the north shore of the island of Kauaʻi. Ocean view."
},
{
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"id": "4",
"title": "Ocean Retreat",
"description": "Quiet and secluded"
}
]
}
Jak se termíny indexují
Abyste pochopili načítání, pomůže vám to znát několik základních informací o indexování. Jednotka úložiště je invertovaný index, jeden pro každé prohledávatelné pole. Invertovaný index je seřazený seznam všech termínů ze všech dokumentů. Každý termín se mapuje na seznam dokumentů, ve kterých k nim dochází, jak je zřejmé v následujícím příkladu.
Aby se výrazy v invertovaného indexu vytvořily, vyhledávací web provádí lexikální analýzu obsahu dokumentů podobně jako při zpracování dotazů:
- Textové vstupy se předávají do analyzátoru, malého písmena, prokládání interpunkce atd. v závislosti na konfiguraci analyzátoru.
- Tokeny jsou výstupem lexikální analýzy.
- Termíny se přidají do indexu.
Je běžné, ale není nutné používat stejné analyzátory pro operace vyhledávání a indexování, aby termíny dotazů vypadaly podobně jako termíny uvnitř indexu.
Poznámka:
Azure AI Search umožňuje zadat různé analyzátory pro indexování a vyhledávání prostřednictvím dalších indexAnalyzer parametrů a searchAnalyzer parametrů polí. Pokud není zadaný, sada analyzátoru analyzer s vlastností se používá pro indexování i vyhledávání.
Invertovaný index, například dokumenty
Když se vrátíme k našemu příkladu pro pole názvu , invertovaný index vypadá takto:
| Období | Seznam dokumentů |
|---|---|
| Atman | 0 |
| pláž | 2 |
| hotel | 1, 3 |
| oceán | 4 |
| playa | 3 |
| letovisko | 3 |
| ústup | 4 |
V poli nadpisu se zobrazí pouze hotel ve dvou dokumentech: 1, 3.
Pro pole popisu je index následující:
| Období | Seznam dokumentů |
|---|---|
| vzduch | 3 |
| a | 4 |
| pláž | 0 |
| podmíněný | 3 |
| pohodlný | 3 |
| vzdálenost | 0 |
| island | 2 |
| kauați | 2 |
| umístěn | 2 |
| sever | 2 |
| oceán | 1, 2, 3 |
| z | 2 |
| on | 2 |
| tichý | 4 |
| místnosti | 1, 3 |
| odloučený | 4 |
| břeh | 2 |
| prostorný | 0 |
| prostředek | 1, 2 |
| na | 0 |
| zobrazit | 1, 2, 3 |
| chůze | 0 |
| with | 3 |
Porovnávání termínů dotazů s indexovanými termíny
Vzhledem k výše uvedeným invertovaným indexům se vraťme do ukázkového dotazu a podívejme se, jak se pro náš ukázkový dotaz najdou odpovídající dokumenty. Vzpomeňte si, že konečný strom dotazu vypadá takto:
Během provádění dotazu se jednotlivé dotazy provádějí nezávisle na prohledávatelných polích.
TermínQuery, "prostorný", odpovídá dokumentu 1 (Hotel Atman).
PředponaQuery , "klimatizace*", neodpovídá žádným dokumentům.
Jedná se o chování, které někdy zaměňuje vývojáře. I když termín klimatizace v dokumentu existuje, je rozdělený do dvou termínů ve výchozím analyzátoru. Vzpomeňte si, že dotazy předpon, které obsahují částečné termíny, nejsou analyzovány. Termíny s předponou "klimatizace" se proto vyhledá v invertované indexu a nenaleznou se.
PhraseQuery, "ocean view", vyhledá termíny "oceán" a "view" a zkontroluje blízkost termínů v původním dokumentu. Dokumenty 1, 2 a 3 odpovídají tomuto dotazu v poli popisu. Všimněte si, že dokument 4 obsahuje termín oceán v názvu, ale nepovažuje se za shodu, protože místo jednotlivých slov hledáme frázi "zobrazení oceánu".
Poznámka:
Vyhledávací dotaz se spouští nezávisle na všech prohledávatelných polích v indexu Azure AI Search, pokud neomešíte pole nastavená parametrem searchFields , jak je znázorněno v ukázkovém požadavku hledání. Vrátí se dokumenty, které odpovídají některému z vybraných polí.
V celém případě pro dotaz, které odpovídají dokumentům, jsou 1, 2, 3.
Fáze 4: Bodování
Každému dokumentu v sadě výsledků hledání se přiřadí skóre relevance. Funkce skóre relevance je lepší pořadí těch dokumentů, které nejlépe odpovídají na uživatelskou otázku vyjádřenou vyhledávacím dotazem. Skóre se vypočítá na základě statistických vlastností termínů, které odpovídají. Jádrem hodnoticího vzorce je TF/IDF (frekvence inverzního dokumentu k inverzní frekvenci). V dotazech obsahujících vzácné a běžné termíny tf/IDF podporuje výsledky obsahující vzácný termín. Například v hypotetické indexu se všemi články Wikipedie z dokumentů, které odpovídaly dotazu předsedy, jsou dokumenty odpovídající prezidentovi považovány za relevantnější než dokumenty odpovídající dokumentům v dané verzi.
Příklad bodování
Připomeňme si tři dokumenty, které odpovídají našemu ukázkovém dotazu:
search=Spacious, air-condition* +"Ocean view"
{
"value": [
{
"@search.score": 0.25610128,
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"@search.score": 0.08951007,
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"@search.score": 0.05967338,
"id": "2",
"title": "Ocean Resort",
"description": "Located on a cliff on the north shore of the island of Kauai. Ocean view."
}
]
}
Dokument 1 nejlépe odpovídal dotazu, protože termín prostorný i požadovaný pohled na oceán se vyskytuje v poli popisu. Následující dva dokumenty se shodují pouze s výhledem na oceán. Může být divu, že skóre relevance pro dokument 2 a 3 se liší, i když odpovídají dotazu stejným způsobem. Je to proto, že bodovací vzorec obsahuje více součástí než jen TF/IDF. V tomto případě byl dokument 3 přiřazen o něco vyšší skóre, protože jeho popis je kratší. Přečtěte si o praktickém bodovacím vzorci Lucene, abyste pochopili, jak může délka pole a další faktory ovlivnit skóre relevance.
Některé typy dotazů (zástupný znak, předpona, regulární výraz) vždy přispívají k celkovému skóre dokumentu konstantní skóre. To umožňuje, aby výsledky byly zahrnuty do výsledků prostřednictvím rozšíření dotazu, ale aniž by to ovlivnilo pořadí.
Příklad ukazuje, proč je to důležité. Vyhledávání se zástupnými znaky, včetně hledání předpon, jsou podle definice nejednoznačné, protože vstup je částečný řetězec s potenciálními shodami u velmi velkého počtu různorodých termínů (zvažte vstup "tour*", se shodami nalezenými na "tours", "tourettes" a "tourmaline"). Vzhledem k povaze těchto výsledků neexistuje způsob, jak rozumně odvodit, které termíny jsou cennější než jiné. Z tohoto důvodu ignorujeme četnost termínů při vyhodnocování výsledků dotazů se zástupnými čísly typů, předponou a regulárním výrazem. Ve vícedílné žádosti o hledání, která obsahuje částečné a úplné termíny, jsou výsledky z částečného vstupu začleněny s konstantním skóre, aby nedocházelo k předsudkům vůči potenciálně neočekávaným shodám.
Upřesnění relevance
Skóre relevance ve službě Azure AI Search můžete ladit dvěma způsoby:
Profily bodování propagují dokumenty v seřazeném seznamu výsledků na základě sady pravidel. V našem příkladu bychom mohli uvažovat o dokumentech, které odpovídají poli názvu, relevantnější než dokumenty, které odpovídají poli popisu. Navíc, pokud náš index měl pole ceny pro každý hotel, mohli bychom propagovat dokumenty s nižší cenou. Přečtěte si další informace o přidávání profilů bodování do indexu vyhledávání.
Zvýšení termínu (k dispozici pouze v úplné syntaxi dotazu Lucene) poskytuje operátor
^zvýšení, který lze použít na libovolnou část stromu dotazu. V našem příkladu byste místo vyhledávání na předponě klimatizace*mohli vyhledat přesnou klimatizaci nebo předponu, ale dokumenty, které se shodují s přesným termínem, jsou seřazené výš tím, že u dotazu na termín použijete zvýšení: klimatizace^2||klimatizace*. Přečtěte si další informace o zvýšení termínu v dotazu.
Bodování v distribuovaném indexu
Všechny indexy ve službě Azure AI Search se automaticky rozdělí do několika horizontálních oddílů, což nám umožňuje rychle distribuovat index mezi více uzlů během vertikálního navýšení nebo snížení kapacity služby. Když se vystaví žádost o vyhledávání, vydá se nezávisle na každém horizontálním oddílu. Výsledky z každého horizontálního oddílu se pak sloučí a seřadí podle skóre (pokud není definováno žádné jiné řazení). Je důležité vědět, že funkce bodování váhá frekvenci termínů dotazu na četnost inverzních dokumentů ve všech dokumentech v rámci horizontálního oddílu, ne napříč všemi horizontálními oddíly.
To znamená, že skóre relevance se může u stejných dokumentů lišit, pokud se nacházejí v různých horizontálních oddílech. Tyto rozdíly naštěstí obvykle zmizí, protože počet dokumentů v indexu roste kvůli rovnoměrnějšímu rozdělení termínů. Není možné předpokládat, na kterém horizontálním oddílu se umístí žádný daný dokument. Pokud se ale klíč dokumentu nezmění, vždy se přiřadí ke stejnému horizontálnímu oddílu.
Obecně platí, že skóre dokumentu není nejlepším atributem pro řazení dokumentů, pokud je důležitá stabilita objednávek. Například vzhledem k dvěma dokumentům s identickým skóre není zaručeno, že se jeden v následných spuštěních stejného dotazu zobrazí jako první. Skóre dokumentu by mělo dávat obecný pocit relevance dokumentu vzhledem k ostatním dokumentům v sadě výsledků.
Závěr
Úspěch komerčních vyhledávacích webů vyvolal očekávání pro fulltextové vyhledávání nad soukromými daty. U téměř jakéhokoli druhu vyhledávání teď očekáváme, že modul pochopí náš záměr, i když jsou termíny chybně napsané nebo neúplné. Můžeme dokonce očekávat shody na základě téměř ekvivalentních termínů nebo synonym, které jsme nikdy nezadáli.
Z technického hlediska je fulltextové vyhledávání velmi složité a vyžaduje sofistikovanou jazykovou analýzu a systematický přístup ke zpracování způsoby, které výrazy dotazů destilují, rozbalují a transformují, aby poskytovaly relevantní výsledek. Vzhledem k vnitřní složitosti existuje mnoho faktorů, které můžou ovlivnit výsledek dotazu. Z tohoto důvodu investice času na pochopení mechaniky fulltextového vyhledávání nabízí hmatatelné výhody při pokusu o práci s neočekávanými výsledky.
Tento článek prozkoumal fulltextové vyhledávání v kontextu služby Azure AI Search. Doufáme, že vám poskytne dostatečné pozadí k rozpoznání potenciálních příčin a řešení běžných problémů s dotazy.
Další kroky
Sestavte ukázkový index, vyzkoušejte různé dotazy a zkontrolujte výsledky. Pokyny najdete v tématu Sestavení a dotazování indexu na portálu.
Vyzkoušejte jinou syntaxi dotazu z ukázkové části Hledat dokumenty nebo jednoduchou syntaxi dotazu v Průzkumníku služby Search na portálu.
Pokud chcete vyladit hodnocení ve vyhledávací aplikaci, zkontrolujte profily bodování.
Naučte se používat lexikální analyzátory specifické pro jazyk.
Nakonfigurujte vlastní analyzátory pro minimální zpracování nebo specializované zpracování v konkrétních polích.