Poznámka
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tento článek vysvětluje složení výsledků hledání a tvarování fulltextových výsledků hledání tak, aby odpovídaly vašim scénářům. Výsledky hledání se vrátí v odpovědi dotazu. Tvar odpovědi je určen parametry v samotném dotazu. Mezi tyto parametry patří:
- Počet shod nalezených v indexu (
count) - Počet shod vrácených v odpovědi (ve výchozím nastavení 50, konfigurovatelný prostřednictvím
top) nebo na stránku (skipatop) - Skóre hledání pro každý výsledek, které se používá pro řazení (
@search.score) - Pole zahrnutá ve výsledcích hledání (
select) - Logika řazení (
orderby) - Zvýraznění termínů v rámci výsledku, které odpovídá celému nebo částečnému termínu v textu
- Volitelné prvky z sémantického rankeru (
answersv horní částicaptions, pro každou shodu)
Výsledky hledání můžou obsahovat pole nejvyšší úrovně, ale většina odpovědí se skládá z odpovídajících dokumentů v poli.
Klienti a rozhraní API pro definování odpovědi dotazu
Ke konfiguraci odpovědi dotazu můžete použít následující klienty:
- Průzkumník služby Search na webu Azure Portal pomocí zobrazení JSON, abyste mohli zadat libovolný podporovaný parametr
- Dokumenty – POST (ROZHRANÍ REST API)
- Metoda SearchClient.Search (Azure SDK pro .NET)
- SearchClient.Search – metoda (Azure SDK pro Python)
- SearchClient.Search – metoda (Azure for JavaScript)
- SearchClient.Search – metoda (Azure for Java)
Složení výsledků
Výsledky jsou většinou tabulkové, složené z polí všech retrievable polí, nebo jsou omezeny pouze na tato pole zadaná v parametru select . Řádky jsou odpovídající dokumenty, obvykle seřazené v pořadí podle relevance, pokud logika dotazu nebrání řazení podle relevance.
Můžete zvolit pole ve výsledcích hledání. Zatímco vyhledávací dokument může mít velký počet polí, obvykle je potřeba jenom několik, aby každý dokument reprezentoval ve výsledcích. V požadavku dotazu připojte select=<field list> , abyste určili, která retrievable pole se mají v odpovědi zobrazit.
Vyberte pole, která nabízejí kontrast a rozlišení mezi dokumenty a poskytují dostatek informací pro pozvání odpovědi clickthrough na straně uživatele. Na webu elektronického obchodování může být název produktu, popis, značka, barva, velikost, cena a hodnocení. U integrovaného indexu hotels-sample může být pole "select" v následujícím příkladu:
POST /indexes/hotels-sample-index/docs/search?api-version=2024-07-01
{
"search": "sandy beaches",
"select": "HotelId, HotelName, Description, Rating, Address/City",
"count": true
}
Tipy pro neočekávané výsledky
Někdy výstup dotazu není to, co očekáváte. Můžete například zjistit, že některé výsledky vypadají jako duplicity, nebo výsledek, který by se měl zobrazit v horní části, je ve výsledcích umístěný níže. Pokud jsou výsledky dotazů neočekávané, můžete zkusit tyto úpravy dotazů a zjistit, jestli se výsledky zlepší:
Změňte
searchMode=any(výchozí) tak, abysearchMode=allse vyžadovaly shody u všech kritérií místo jakéhokoli kritéria. To platí zejména v případě, že jsou v dotazu zahrnuté logické operátory.Experimentujte s různými lexikálními analyzátory nebo vlastními analyzátory a zjistěte, jestli změní výsledek dotazu. Výchozí analyzátor rozdělí pomlčky slov a zmenší slova na kořenové formuláře, což obvykle zlepšuje odolnost odpovědi dotazu. Pokud ale potřebujete zachovat pomlčky nebo pokud řetězce obsahují speciální znaky, možná budete muset nakonfigurovat vlastní analyzátory, abyste zajistili, že index obsahuje tokeny ve správném formátu. Další informace najdete v tématu Částečné hledání termínů a vzorů se speciálními znaky (spojovníky, zástupné znaky, regulární výrazy, vzory).
Počítání shod
Parametr count vrátí počet dokumentů v indexu, které jsou považovány za shodu dotazu. Pokud chcete vrátit počet, přidejte count=true ho do požadavku dotazu. Vyhledávací služba nevynucuje žádnou maximální hodnotu. V závislosti na dotazu a obsahu dokumentů může být počet stejně vysoký jako každý dokument v indexu.
Počet je přesný, pokud je index stabilní. Pokud systém aktivně přidává, aktualizuje nebo odstraňuje dokumenty, je počet přibližný, s výjimkou všech dokumentů, které nejsou plně indexované.
Počet nebude ovlivněn rutinní údržbou ani jinými úlohami ve vyhledávací službě. Pokud ale máte více oddílů a jednu repliku, mohli byste zaznamenat krátkodobé kolísání počtu dokumentů (několik minut), jakmile se oddíly restartují.
Návod
Pokud chcete zkontrolovat operace indexování, můžete ověřit, jestli index obsahuje očekávaný počet dokumentů, a to přidáním count=true prázdného vyhledávacího search=* dotazu. Výsledkem je úplný počet dokumentů v indexu.
Při testování syntaxe dotazu můžete rychle zjistit, count=true jestli vaše úpravy vrací větší nebo méně výsledků, což může být užitečné pro zpětnou vazbu.
Počet výsledků v odpovědi
Azure AI Search používá stránkování na straně serveru, aby zabránilo dotazům v načítání příliš velkého počtu dokumentů najednou. Parametry dotazu, které určují počet výsledků v odpovědi, jsou top a skip.
top odkazuje na počet výsledků hledání na stránce.
skip je interval topa říká vyhledávacímu webu, kolik výsledků se má přeskočit před získáním další sady.
Výchozí velikost stránky je 50, zatímco maximální velikost stránky je 1 000. Pokud zadáte hodnotu větší než 1 000 a v indexu se najde více než 1 000 výsledků, vrátí se pouze prvních 1 000 výsledků. Pokud počet shod překročí velikost stránky, odpověď obsahuje informace pro načtení další stránky výsledků. Příklad:
"@odata.nextLink": "https://contoso-search-eastus.search.windows.net/indexes/realestate-us-sample-index/docs/search?api-version=2024-07-01"
Nejvyšší shody jsou určeny skóre hledání za předpokladu, že dotaz je fulltextové vyhledávání nebo sémantické. V opačném případě jsou nejvyšší shody libovolným pořadím pro přesné shody dotazů (kde uniforma @search.score=1.0 označuje libovolné pořadí).
Nastavte top pro přepsání výchozí hodnoty 50. Pokud používáte hybridní dotaz, můžete v novějších rozhraních API ve verzi Preview zadat maxTextRecallSize pro vrácení až 10 000 dokumentů.
Chcete-li řídit stránkování všech dokumentů vrácených v sadě výsledků, použijte top a skip společně. Tento dotaz vrátí první sadu 15 shodných dokumentů a celkový počet shod.
POST https://contoso-search-eastus.search.windows.net/indexes/realestate-us-sample-index/docs/search?api-version=2024-07-01
{
"search": "condos with a view",
"count": true,
"top": 15,
"skip": 0
}
Tento dotaz vrátí druhou sadu, která přeskočí prvních 15 a získá další 15 (16 až 30):
POST https://contoso-search-eastus.search.windows.net/indexes/realestate-us-sample-index/docs/search?api-version=2024-07-01
{
"search": "condos with a view",
"count": true,
"top": 15,
"skip": 15
}
Výsledky stránkovaných dotazů nejsou zaručeny stabilní, pokud se podkladový index mění. Stránkování změní hodnotu skip každé stránky, ale každý dotaz je nezávislý a pracuje s aktuálním zobrazením dat, protože v době dotazu existuje v indexu (jinými slovy neexistuje ukládání do mezipaměti ani snímek výsledků, například ty, které se nacházejí v databázi pro obecné účely).
Následuje příklad toho, jak můžete získat duplicity. Předpokládejme index se čtyřmi dokumenty:
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
{ "id": "4", "rating": 1 }
Teď předpokládejme, že chcete, aby se výsledky vrátily 2 po druhé, seřazené podle hodnocení. Spuštěním tohoto dotazu získáte první stránku výsledků: $top=2&$skip=0&$orderby=rating desca vytvoří se následující výsledky:
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
Ve službě předpokládejme, že se do indexu přidá pátý dokument mezi voláními dotazu: { "id": "5", "rating": 4 }. Za chvíli spustíte dotaz, který načte druhou stránku: $top=2&$skip=2&$orderby=rating desca získá tyto výsledky:
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
Všimněte si, že dokument 2 se načte dvakrát. Je to proto, že nový dokument 5 má větší hodnotu pro hodnocení, takže se seřadí před dokumentem 2 a přejde na první stránku. I když toto chování může být neočekávané, je typické, jak se vyhledávací web chová.
Stránkování přes velký počet výsledků
Alternativní technikou stránkování je použití filtru řazení a rozsahu skip.
V tomto alternativním řešení se řazení a filtrování použije u pole ID dokumentu nebo jiného pole, které je jedinečné pro každý dokument. Jedinečné pole musí obsahovat filterable a sortable přisouvat v indexu vyhledávání.
Zadejte dotaz, který vrátí celou stránku seřazených výsledků.
POST /indexes/good-books/docs/search?api-version=2024-07-01 { "search": "divine secrets", "top": 50, "orderby": "id asc" }Zvolte poslední výsledek vrácený vyhledávacím dotazem. Tady je příklad výsledku s hodnotou ID.
{ "id": "50" }Tuto hodnotu ID v dotazu rozsahu použijte k načtení další stránky výsledků. Toto pole ID by mělo mít jedinečné hodnoty, jinak stránkování může obsahovat duplicitní výsledky.
POST /indexes/good-books/docs/search?api-version=2024-07-01 { "search": "divine secrets", "top": 50, "orderby": "id asc", "filter": "id ge 50" }Stránkování skončí, když dotaz vrátí nulové výsledky.
Poznámka:
Atributy filterable lze sortable povolit pouze při prvním přidání pole do indexu, nelze je povolit u existujícího pole.
Řazení výsledků
V fulltextovém vyhledávacím dotazu je možné výsledky seřadit podle:
- skóre hledání
- Skóre sémantického rerankeru
- pořadí řazení v
sortablepoli
Přidáním profilu bodování můžete také zvýšit počet nalezených shod v konkrétních polích.
Pořadí podle skóre hledání
U fulltextových vyhledávacích dotazů se výsledky automaticky řadí podle skóre hledání pomocí algoritmu BM25 vypočítaného na základě četnosti termínů, délky dokumentu a průměrné délky dokumentu.
Rozsah @search.score je buď nevázaný, nebo 0 až (ale neobsahuje) 1,00 ve starších službách.
U obou algoritmů @search.score označuje hodnota 1,00 neohodnocenou nebo nehodnocenou sadu výsledků, kde je skóre 1,0 jednotné pro všechny výsledky. Neoznačené výsledky se vyskytují, když je formulář dotazu přibližný hledání, zástupné znamény nebo dotazy regulárního výrazu nebo prázdné hledání (search=*). Pokud potřebujete uložit strukturu řazení nad neoznamovanými výsledky, zvažte orderby výraz k dosažení tohoto cíle.
Pořadí podle sémantického pořadí
Pokud používáte sémantický ranker, @search.rerankerScore určuje pořadí řazení výsledků.
Rozsah @search.rerankerScore je 1 až 4,00, kde vyšší skóre označuje silnější sémantickou shodu.
Uspořádání podle pořadí
Pokud je konzistentní řazení požadavkem aplikace, můžete definovat orderby výraz v poli. K seřazení výsledků lze použít pouze pole, která jsou indexována jako "seřazená".
Pole, která se běžně používají v orderby hodnocení, datu a umístění, se běžně používají. Filtrování podle umístění vyžaduje, aby kromě názvu pole volaly geo.distance() i výraz filtru funkci.
Číselná pole (Edm.Double, Edm.Int32, Edm.Int64) jsou seřazená v číselném pořadí (například 1, 2, 10, 11, 20).
Pole řetězců (Edm.String, Edm.ComplexType podpole) jsou seřazená v pořadí řazení ASCII nebo v závislosti na jazyce.
Číselný obsah v řetězcových polích je seřazen abecedně (1, 10, 11, 2, 20).
Velké řetězce jsou seřazené před velkými písmeny (APPLE, Apple, BANANA, Banán, jablko, banán). Před řazením můžete přiřadit normalizátor textu k předběžnému zpracování textu, aby se toto chování změnilo. Použití tokenizátoru malými písmeny u pole nemá žádný vliv na chování řazení, protože Azure AI Search seřadí na neanalyzovanou kopii pole.
Řetězce, které vedou s diakritikou, se zobrazují jako poslední (Äpfel, Öffnen, Üben)
Zvýšení relevance pomocí hodnoticího profilu
Dalším přístupem, který podporuje konzistenci pořadí, je použití vlastního bodovacího profilu. Profily bodování poskytují větší kontrolu nad pořadím položek ve výsledcích hledání a možností zvýšit počet nalezených shod nalezených v konkrétních polích. Logika dodatečného bodování může pomoct přepsat menší rozdíly mezi replikami, protože skóre hledání pro každý dokument jsou od sebe vzdálená. Pro tento přístup doporučujeme algoritmus řazení.
Zvýrazňování položek
Zvýraznění hitů odkazuje na formátování textu (například tučné nebo žluté zvýraznění) použité u odpovídajících termínů ve výsledku, což usnadňuje nalezení shody. Zvýraznění je užitečné pro delší pole obsahu, například pole popisu, kde shoda není okamžitě jasná.
Všimněte si, že zvýraznění se používá u jednotlivých termínů. Obsah celého pole neobsahuje žádné možnosti zvýraznění. Pokud chcete zvýraznit frázi, musíte v řetězci dotazu uzavřeném v uvozovkách zadat odpovídající termíny (nebo frázi). Tato technika je podrobněji popsána v této části.
Pokyny ke zvýraznění hitů jsou k dispozici v požadavku na dotaz. Dotazy, které aktivují rozšíření dotazů v modulu, jako je přibližné vyhledávání a vyhledávání se zástupnými výjimkou, mají omezenou podporu zvýraznění hitů.
Požadavky na zvýraznění
- Pole musí být nebo musí být
Edm.StringCollection(Edm.String) - Pole musí být přiřazena na adrese
searchable
Zadání zvýraznění v požadavku
Pokud chcete vrátit zvýrazněné termíny, zahrňte do požadavku dotazu parametr zvýraznění. Parametr je nastavený na čárkami oddělený seznam polí.
Ve výchozím nastavení je <em>mark up formátu , ale můžete přepsat značku pomocí highlightPreTag a highlightPostTag parametry. Váš klientský kód zpracovává odpověď (například použití tučného písma nebo žlutého pozadí).
POST /indexes/good-books/docs/search?api-version=2024-07-01
{
"search": "divine secrets",
"highlight": "title, original_title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>"
}
Ve výchozím nastavení azure AI Search vrátí až pět zvýraznění na pole. Toto číslo můžete upravit tak, že připojíte pomlčku následovanou celé číslo. Například "highlight": "description-10" vrátí až 10 zvýrazněných termínů odpovídajícího obsahu v poli popisu.
Zvýrazněné výsledky
Při přidání zvýrazňování do dotazu obsahuje @search.highlights odpověď pro každý výsledek, aby kód aplikace mohl tuto strukturu cílit. Do odpovědi se zahrnou seznam polí určených pro zvýraznění.
Při hledání klíčových slov se každý termín prohledá nezávisle. Dotaz na "boží tajemství" vrátí shody v jakémkoli dokumentu obsahujícím některý termín.
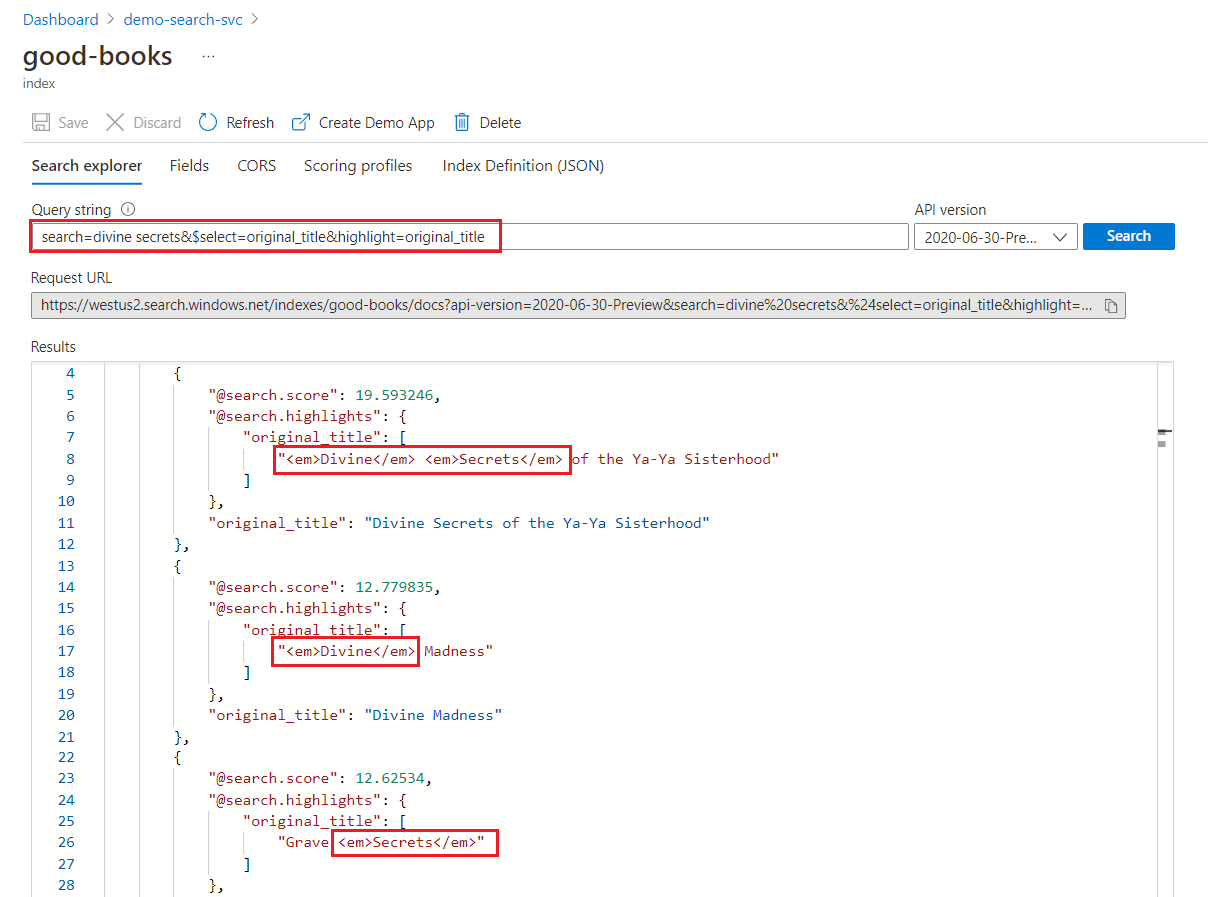
Zvýraznění hledání klíčových slov
V rámci zvýrazněného pole se formátování použije na celé termíny. Například u shody proti "Boží tajemství Ya-Ya Sesterhood", formátování se použije u každého termínu zvlášť, i když jsou po sobě jdoucí.
"@odata.count": 39,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"original_title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
],
"title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
},
{
"@search.score": 12.779835,
"@search.highlights": {
"original_title": [
"<em>Divine</em> Madness"
],
"title": [
"<em>Divine</em> Madness (Cherub, #5)"
]
},
"original_title": "Divine Madness",
"title": "Divine Madness (Cherub, #5)"
},
{
"@search.score": 12.62534,
"@search.highlights": {
"original_title": [
"Grave <em>Secrets</em>"
],
"title": [
"Grave <em>Secrets</em> (Temperance Brennan, #5)"
]
},
"original_title": "Grave Secrets",
"title": "Grave Secrets (Temperance Brennan, #5)"
}
]
Zvýraznění hledání frází
Formátování celých termínů platí i pro hledání frází, kde je více termínů uzavřeno do uvozovek. Následující příklad je stejný dotaz, s výjimkou toho, že "boží tajemství" je odesláno jako uvozovky uzavřené fráze (někteří klienti REST vyžadují, abyste uvozovky uvozovky s zpětným lomítkem \"):
POST /indexes/good-books/docs/search?api-version=2024-07-01
{
"search": "\"divine secrets\"",
"select": "title,original_title",
"highlight": "title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>",
"count": true
}
Vzhledem k tomu, že kritéria teď mají oba termíny, najde se v indexu vyhledávání jenom jedna shoda. Odpověď na předchozí dotaz vypadá takto:
{
"@odata.count": 1,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"title": [
"<b>Divine</b> <b>Secrets</b> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
}
]
}
Zvýraznění fráze ve starších službách
Search, které byly vytvořeny před 15. červencem 2020, implementují pro dotazy frází jiné zvýraznění.
V následujících příkladech předpokládejme řetězec dotazu, který obsahuje uvozovku uzavřenou frázi "super bowl". Před červencem 2020 se zvýrazní libovolný termín ve frázi:
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is <em>super</em> awesome with a <em>bowl</em> of chips"
]
Pro vyhledávací služby vytvořené po červenci 2020 se vrátí @search.highlightspouze fráze, které odpovídají dotazu na celou frázi:
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is super awesome with a bowl of chips"
]
Další kroky
Pokud chcete rychle vygenerovat vyhledávací stránku pro klienta, zvažte tyto možnosti:
Vytvoření ukázkové aplikace na webu Azure Portal vytvoří stránku HTML s panelem hledání, fasetovou navigaci a oblastí miniatur, pokud máte obrázky.
Přidání vyhledávání do aplikace ASP.NET Core (MVC) je kurz a ukázka kódu, která sestaví funkčního klienta.
Přidání vyhledávání do webových aplikací je kurz a ukázka kódu jazyka C#, která pro uživatelské prostředí používá knihovny React JavaScriptu. Aplikace se nasadí pomocí Azure Static Web Apps a implementuje stránkování.