Relevance při hledání klíčových slov (bodování BM25)
Tento článek vysvětluje algoritmus vyhodnocování relevance BM25, který se používá k výpočtu skóre hledání pro fulltextové vyhledávání. Relevance BM25 je výhradní pro fulltextové vyhledávání. Filtrování dotazů, automatického dokončování a navrhovaných dotazů, vyhledávání se zástupnými znamény nebo přibližných vyhledávacích dotazů nevyhodnotuje ani seřadí podle relevance.
Algoritmy bodování používané při fulltextové vyhledávání
Azure AI Search poskytuje následující algoritmy bodování pro fulltextové vyhledávání:
| Algoritmus | Využití | Rozsah |
|---|---|---|
BM25Similarity |
Pevný algoritmus pro všechny vyhledávací služby vytvořené po červenci 2020 Tento algoritmus můžete nakonfigurovat, ale nemůžete přepnout na starší (klasický). | Neomezeně. |
ClassicSimilarity |
Prezentovat ve starších vyhledávacích službách Můžete se přihlásit k BM25 a zvolit algoritmus na základě indexu. | 0 < 1,00 |
BM25 i Classic jsou funkce načítání podobné TF-IDF, které používají frekvenci termínů (TF) a inverzní frekvenci dokumentů (IDF) jako proměnné k výpočtu skóre relevance pro každou dvojici dotazů dokumentu, která se pak používá pro výsledky řazení. I když se koncepčně podobá klasickému modelu, BM25 je kořenem v pravděpodobnostním načítání informací, které vytváří intuitivnější shody měřené výzkumem uživatelů.
BM25 nabízí pokročilé možnosti přizpůsobení, například umožnit uživateli rozhodnout se, jak se skóre relevance škáluje s frekvencí termínů odpovídajících termínů. Další informace najdete v tématu Konfigurace algoritmu vyhodnocování.
Poznámka:
Pokud používáte vyhledávací službu vytvořenou před červencem 2020, algoritmus bodování je pravděpodobně předchozí výchozí hodnota, ClassicSimilaritykterou můžete upgradovat na základě indexu. Podrobnosti najdete v tématu Povolení bodování BM25 u starších služeb .
Následující video segment rychle předává vysvětlení obecně dostupných algoritmů řazení používaných ve službě Azure AI Search. Na celé video se můžete podívat na další pozadí.
Jak funguje hodnocení BM25
Bodování relevance odkazuje na výpočet skóre hledání (@search.score), které slouží jako indikátor relevance položky v kontextu aktuálního dotazu. Rozsah není nevázaný. Čím vyšší je ale skóre, tím relevantnější položka.
Skóre hledání se vypočítá na základě statistických vlastností vstupu řetězce a samotného dotazu. Azure AI Search najde dokumenty, které odpovídají hledanému výrazu (některé nebo všechny v závislosti na modulu searchMode), a upřednostňuje dokumenty, které obsahují mnoho instancí hledaného termínu. Skóre hledání je ještě vyšší, pokud je termín v indexu dat vzácný, ale společný v dokumentu. Základem tohoto přístupu k výpočtům relevance se označuje jako TF-IDF nebo frekvence inverzních dokumentů.
Skóre hledání je možné opakovat v celé sadě výsledků. Pokud má více přístupů stejné skóre hledání, pořadí stejných shodnocených položek není definováno a není stabilní. Spusťte dotaz znovu a může se zobrazit pozice posunu položek, zejména pokud používáte bezplatnou službu nebo fakturovatelnou službu s více replikami. Vzhledem k dvěma položkám s identickým skóre neexistuje žádná záruka, že se jedna zobrazí jako první.
Chcete-li přerušit vazby mezi opakujícími se skóre, můžete přidat klauzuli $orderby k prvnímu pořadí podle skóre a pak pořadí podle jiného seřazeného pole (například $orderby=search.score() desc,Rating desc). Další informace najdete v tématu $orderby.
K bodování se používají pouze pole označená jako searchable v indexu nebo searchFields v dotazu. Ve výsledcích hledání se vrátí pouze pole označená jako retrievablepole nebo pole zadaná v select dotazu spolu s jejich skóre hledání.
Poznámka:
A @search.score = 1 označuje nehodnocenou nebo neseřazenou sadu výsledků. Skóre je jednotné pro všechny výsledky. Nehodnocené výsledky se zobrazí, když je formulář dotazu přibližný hledání, zástupné znamény nebo dotazy regulárního výrazu nebo prázdné hledání (search=*někdy spárované s filtry, kde je filtr primárním prostředkem pro vrácení shody).
Skóre ve výsledcích textu
Pokaždé, když jsou výsledky seřazené, @search.score vlastnost obsahuje hodnotu použitou k seřazení výsledků.
Následující tabulka identifikuje vlastnost bodování vrácenou pro každou shodu, algoritmus a rozsah.
| Metoda vyhledávání | Parametr | Algoritmus bodování | Rozsah |
|---|---|---|---|
| Fulltextové vyhledávání | @search.score |
Algoritmus BM25 používající parametry zadané v indexu. | Neomezeně. |
Varianta skóre
Skóre hledání vyjadřuje obecný smysl pro relevanci a odráží sílu shody vzhledem k ostatním dokumentům ve stejné sadě výsledků. Skóre ale nejsou vždy konzistentní z jednoho dotazu na další, takže při práci s dotazy si můžete všimnout malých nesrovnalostí v tom, jak jsou hledané dokumenty seřazené. Existuje několik vysvětlení, proč k tomu může dojít.
| Příčina | Popis |
|---|---|
| Identické skóre | Pokud má více dokumentů stejné skóre, může se některý z nich objevit jako první. |
| Volatilita dat | Obsah indexu se při přidávání, úpravách nebo odstraňování dokumentů liší. Frekvence termínů se změní, protože aktualizace indexu se zpracovávají v průběhu času, což má vliv na skóre hledání odpovídajících dokumentů. |
| Více replik | U služeb používajících více replik se dotazy vydávají na každou repliku paralelně. Statistiky indexu použité k výpočtu skóre hledání se počítají na základě jednotlivých replik s výsledky sloučenými a seřazenými v odpovědi dotazu. Repliky se většinou zrcadlí, ale statistiky se můžou lišit v důsledku malých rozdílů ve stavu. Jedna replika může například odstranit dokumenty, které přispívají do statistiky, které byly sloučeny z jiných replik. Rozdíly ve statistikách jednotlivých replik jsou obvykle výraznější v menších indexech. Následující část obsahuje další informace o této podmínce. |
Efekty horizontálního dělení na výsledky dotazu
Horizontální oddíl je blok indexu. Azure AI Search rozdělí index do horizontálních oddílů, aby se proces přidávání oddílů zrychlil (přesunutím horizontálních oddílů do nových jednotek vyhledávání). Ve vyhledávací službě je správa horizontálních oddílů podrobností implementace a nekonfigurovatelná, ale znalost horizontálního dělení indexu pomáhá pochopit občasné anomálie při řazení a chování automatického dokončování:
Anomálie řazení: Skóre hledání se nejprve počítají na úrovni horizontálních oddílů a pak se agregují do jedné sady výsledků. V závislosti na vlastnostech obsahu horizontálních oddílů můžou být shody z jednoho horizontálního oddílu seřazené výš než shody v druhém. Pokud si všimnete čítačů intuitivního řazení ve výsledcích hledání, je to s největší pravděpodobností způsobeno vlivem horizontálního dělení, zejména pokud jsou indexy malé. Těmto anomáliím řazení se můžete vyhnout tím, že se rozhodnete vypočítat skóre globálně v celém indexu, ale tím dojde k penalizaci výkonu.
Automatické dokončování anomálií: Automatické dokončování dotazů, ve kterých jsou shody provedeny na prvních několika znacích částečně zadaného termínu, přijměte přibližný parametr, který odpouští malé odchylky v pravopisu. U automatického dokončování je přibližné porovnávání omezené na termíny v rámci aktuálního horizontálního oddílu. Pokud například horizontální oddíl obsahuje "Microsoft" a zadá se částečný termín "mikro", bude vyhledávací modul v tomto horizontálním oddílu odpovídat hodnotě Microsoft, ale ne v jiných horizontálních oddílech, které obsahují zbývající části indexu.
Následující diagram znázorňuje vztah mezi replikami, oddíly, horizontálními oddíly a jednotkami vyhledávání. Ukazuje příklad, jak se jeden index rozděluje do čtyř jednotek hledání ve službě se dvěma replikami a dvěma oddíly. Každý ze čtyř jednotek vyhledávání ukládá pouze polovinu horizontálních oddílů indexu. Vyhledávací jednotky v levém sloupci ukládají první polovinu horizontálních oddílů, které tvoří první oddíl, zatímco ty v pravém sloupci ukládají druhou polovinu horizontálních oddílů, které tvoří druhý oddíl. Vzhledem k tomu, že existují dvě repliky, existují dvě kopie každého horizontálního oddílu indexu. Jednotky vyhledávání v horním řádku ukládají jednu kopii, která tvoří první repliku, zatímco ty v dolním řádku ukládají další kopii, která tvoří druhou repliku.
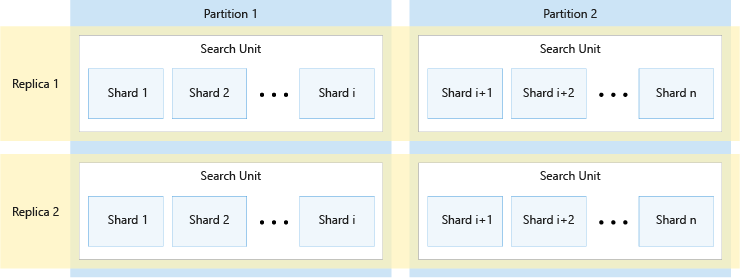
Výše uvedený diagram je pouze jedním příkladem. Je možné použít mnoho kombinací oddílů a replik, maximálně 36 celkového počtu jednotek vyhledávání.
Poznámka:
Počet replik a oddílů se rovnoměrně dělí na 12 (konkrétně 1, 2, 3, 4, 6, 12). Azure AI Search předem rozdělí každý index na 12 horizontálních oddílů, aby se mohl rozdělit do stejných částí napříč všemi oddíly. Pokud má například vaše služba tři oddíly a vytvoříte index, každý oddíl bude obsahovat čtyři horizontální oddíly indexu. Způsob horizontálního dělení indexu ve službě Azure AI Search představuje podrobnosti implementace, které se můžou v budoucích verzích změnit. I když je číslo dnes 12, neměli byste očekávat, že by toto číslo v budoucnu vždy bylo 12.
Statistiky vyhodnocování a rychlé relace
Kvůli škálovatelnosti azure AI Search distribuuje každý index horizontálně prostřednictvím procesu horizontálního dělení, což znamená, že části indexu jsou fyzicky oddělené.
Ve výchozím nastavení se skóre dokumentu počítá na základě statistických vlastností dat v rámci horizontálního oddílu. Tento přístup obecně není problémem u velkého korpusu dat a poskytuje lepší výkon než výpočet skóre na základě informací napříč všemi horizontálními oddíly. Použití této optimalizace výkonu může způsobit, že dva velmi podobné dokumenty (nebo dokonce stejné dokumenty) skončí s různými skóre relevance, pokud skončí v různých horizontálních oddílech.
Pokud dáváte přednost výpočtu skóre na základě statistických vlastností napříč všemi horizontálními oddíly, můžete to udělat tak scoringStatistics=global , že přidáte jako parametr dotazu (nebo ho přidáte "scoringStatistics": "global" jako základní parametr požadavku dotazu).
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2023-11-01
{
"search": "<query string>",
"scoringStatistics": "global"
}
Použití scoringStatistics zajistí, aby všechny horizontální oddíly ve stejné replice poskytovaly stejné výsledky. To znamená, že různé repliky se můžou mírně lišit od sebe, protože se neustále aktualizují o nejnovější změny indexu. V některých scénářích můžete chtít, aby uživatelé získali konzistentnější výsledky během "relace dotazů". V takových scénářích můžete zadat sessionId jako součást dotazů. Jedná se sessionId o jedinečný řetězec, který vytvoříte, který odkazuje na jedinečnou uživatelskou relaci.
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2023-11-01
{
"search": "<query string>",
"sessionId": "<string>"
}
Pokud se použije stejný postup, provede se pokus o dosažení stejného sessionId cíle na stejnou repliku a zvýší konzistenci výsledků, které uvidí vaši uživatelé.
Poznámka:
Opakované použití stejných sessionId hodnot může narušit vyrovnávání zatížení požadavků napříč replikami a nepříznivě ovlivnit výkon vyhledávací služby. Hodnota použitá jako sessionId nemůže začínat znakem _.
Upřesnění relevance
Ve službě Azure AI Search můžete nakonfigurovat parametry algoritmu BM25 a ladit relevanci vyhledávání a zvýšit skóre hledání pomocí těchto mechanismů:
| Přístup | Implementace | Popis |
|---|---|---|
| Konfigurace algoritmu bodování | Index vyhledávání | |
| Profily skórování | Index vyhledávání | Zadejte kritéria pro zvýšení skóre hledání shody na základě charakteristik obsahu. Můžete například chtít zvýšit počet shod na základě jejich potenciálních výnosů, zvýšit úroveň novějších položek nebo zvýšit počet položek, které byly v inventáři příliš dlouho. Bodovací profil je součástí definice indexu, která se skládá z vážených polí, funkcí a parametrů. Existující index můžete aktualizovat o změny hodnoticího profilu bez nutnosti opětovného sestavení indexu. |
| Sémantické řazení | Žádost o dotaz | Aplikuje strojové čtení na výsledky hledání a podporuje více sémanticky relevantních výsledků na začátek. |
| featuresMode – parametr | Žádost o dotaz | Tento parametr se většinou používá k rozbalení skóre, ale dá se použít v kódu, který poskytuje vlastní bodovací řešení. |
featuresMode – parametr (Preview)
Požadavky na dokumenty vyhledávání mají nový parametr featuresMode, který může poskytnout podrobnější informace o relevance na úrovni pole. Zatímco se @searchScore počítá pro celý dokument (jak je tento dokument relevantní v kontextu tohoto dotazu), prostřednictvím funkcíMode můžete získat informace o jednotlivých polích, jak je vyjádřeno @search.features ve struktuře. Struktura obsahuje všechna pole použitá v dotazu (buď konkrétní pole prostřednictvím vyhledávacích polí v dotazu, nebo všechna pole, která jsou přiřazená jako prohledávatelná v indexu). Pro každé pole získáte následující hodnoty:
- Počet jedinečných tokenů nalezených v poli
- Skóre podobnosti nebo míra toho, jak je obsah pole podobný, vzhledem k termínu dotazu
- Frekvence termínů nebo počet nalezených termínů v poli
U dotazu, který cílí na pole popis a název, může odpověď, která obsahuje @search.features , vypadat takto:
"value": [
{
"@search.score": 5.1958685,
"@search.features": {
"description": {
"uniqueTokenMatches": 1.0,
"similarityScore": 0.29541412,
"termFrequency" : 2
},
"title": {
"uniqueTokenMatches": 3.0,
"similarityScore": 1.75451557,
"termFrequency" : 6
}
}
}
]
Tyto datové body můžete využívat ve vlastních řešeních bodování nebo pomocí informací ladit problémy s relevanci vyhledáváním.
Počet seřazených výsledků v odpovědi na fulltextový dotaz
Pokud ve výchozím nastavení nepoužíváte stránkování, vrátí vyhledávací web prvních 50 nejlepších shod pro fulltextové vyhledávání. Pomocí parametru top můžete vrátit menší nebo větší počet položek (až 1 000 v jedné odpovědi). Fulltextové vyhledávání podléhá maximálnímu limitu 1 000 shod (viz limity odpovědí rozhraní API). Jakmile se najde 1 000 shod, vyhledávací web už nebude hledat víc.
Chcete-li vrátit více nebo méně výsledků, použijte parametry topstránkování , skipa next. Stránkování určuje počet výsledků na každé logické stránce a prochází celou datovou část. Další informace naleznete v tématu Jak pracovat s výsledky hledání.
Viz také
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro