Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Ve vyhledávacích řešeních můžou být řetězce se složitými vzory nebo speciálními znaky náročné na práci, protože výchozí analyzátor odstraní nebo nesprávně interpretuje smysluplné části vzoru. Výsledkem je špatné vyhledávání, kdy uživatelé nemůžou najít informace, které očekávají. Telefonní čísla jsou klasickým příkladem řetězců, které se obtížně analyzují. Přicházejí v různých formátech a obsahují speciální znaky, které výchozí analyzátor ignoruje.
S telefonními čísly jako předmětem tohoto kurzu se pomocí rozhraní REST API vyhledávací služby řeší problémy se vzorovými daty pomocí vlastního analyzátoru. Tento přístup se dá použít stejně jako u telefonních čísel nebo přizpůsobených pro pole se stejnými vlastnostmi (ve vzorech se speciálními znaky), jako jsou adresy URL, e-maily, PSČ a kalendářní data.
V tomto kurzu se naučíte:
- Pochopení problému
- Vývoj počátečního vlastního analyzátoru pro zpracování telefonních čísel
- Testování vlastního analyzátoru
- Iterace návrhu vlastního analyzátoru za účelem dalšího zlepšení výsledků
Požadavky
Účet Azure s aktivním předplatným. Vytvoření účtu zdarma
Stažení souborů
Zdrojový kód pro tento kurz je v souboru custom-analyzer.rest v úložišti GitHubu Azure-Samples/azure-search-rest-samples .
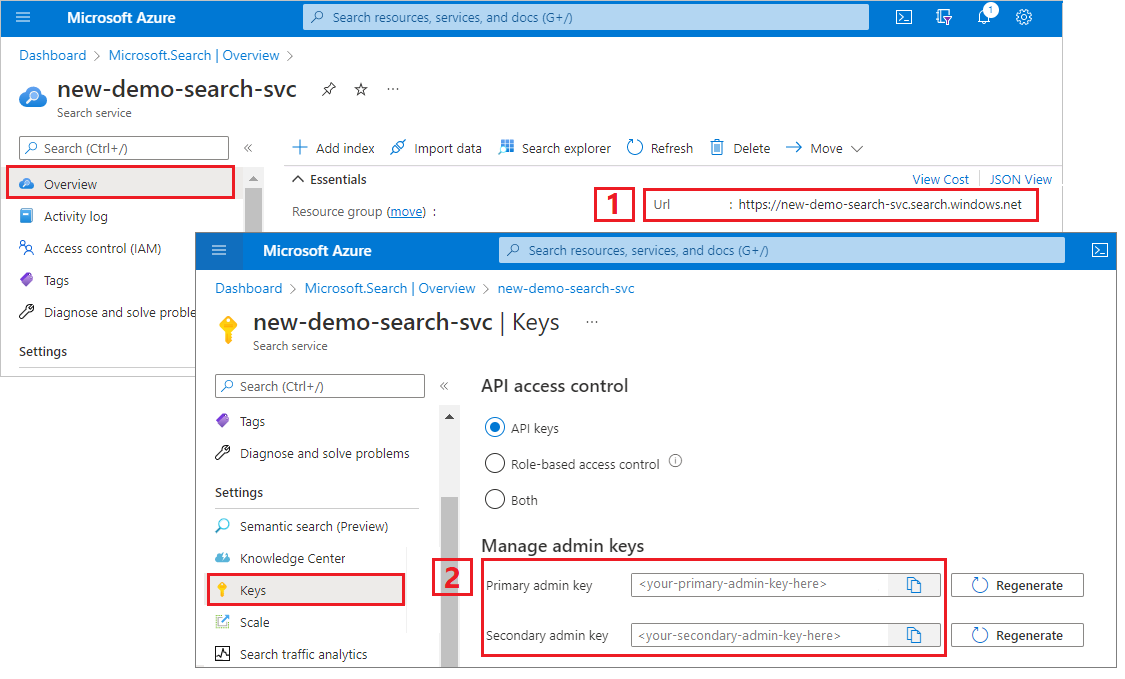
Zkopírování klíče správce a adresy URL
Volání REST v tomto kurzu vyžadují koncový bod vyhledávací služby a klíč rozhraní API pro správu. Tyto hodnoty můžete získat z webu Azure Portal.
Na webu Azure Portal přejděte do vyhledávací služby.
V levém podokně vyberte Přehled a zkopírujte koncový bod. Měl by být v tomto formátu:
https://my-service.search.windows.netV levém podokně vyberte Klíče nastavení> a zkopírujte klíč správce pro úplná práva ke službě. Existují dva zaměnitelné klíče správce, které jsou k dispozici pro zajištění kontinuity podnikových procesů v případě, že potřebujete jeden převést. Objekty můžete přidávat, upravovat nebo odstraňovat pomocí klíče u požadavků.
Vytvoření počátečního indexu
Otevřete nový textový soubor v editoru Visual Studio Code.
Nastavte proměnné na koncový bod vyhledávání a klíč rozhraní API, který jste shromáždili v předchozí části.
@baseUrl = PUT-YOUR-SEARCH-SERVICE-URL-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HEREUložte soubor s příponou
.rest.Vložte následující příklad pro vytvoření malého indexu volaný
phone-numbers-indexse dvěma poli:idaphone_number.### Create a new index POST {{baseUrl}}/indexes?api-version=2026-04-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "name": "phone-numbers-index", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "searchable": true, "filterable": false, "facetable": false, "sortable": true }, { "name": "phone_number", "type": "Edm.String", "sortable": false, "searchable": true, "filterable": false, "facetable": false } ] }Ještě jste nedefinovali analyzátor, takže je analyzátor
standard.lucenepoužíván ve výchozím nastavení.Vyberte Odeslat žádost. Měli byste mít
HTTP/1.1 201 Createdodpověď a text odpovědi by měl obsahovat reprezentaci JSON schématu indexu.Načtěte data do indexu pomocí dokumentů, které obsahují různé formáty telefonních čísel. Toto jsou vaše testovací data.
### Load documents POST {{baseUrl}}/indexes/phone-numbers-index/docs/index?api-version=2026-04-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "value": [ { "@search.action": "upload", "id": "1", "phone_number": "425-555-0100" }, { "@search.action": "upload", "id": "2", "phone_number": "(321) 555-0199" }, { "@search.action": "upload", "id": "3", "phone_number": "+1 425-555-0100" }, { "@search.action": "upload", "id": "4", "phone_number": "+1 (321) 555-0199" }, { "@search.action": "upload", "id": "5", "phone_number": "4255550100" }, { "@search.action": "upload", "id": "6", "phone_number": "13215550199" }, { "@search.action": "upload", "id": "7", "phone_number": "425 555 0100" }, { "@search.action": "upload", "id": "8", "phone_number": "321.555.0199" } ] }Zkuste dotazy podobné tomu, co uživatel může zadat. Uživatel může například hledat
(425) 555-0100v libovolném počtu formátů a stále očekává vrácení výsledků. Začněte hledáním(425) 555-0100.### Search for a phone number POST {{baseUrl}}/indexes/phone-numbers-index/docs/search?api-version=2026-04-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "search": "(425) 555-0100" }Dotaz vrátí tři ze čtyř očekávaných výsledků, ale také vrátí dva neočekávané výsledky.
{ "value": [ { "@search.score": 0.05634898, "phone_number": "+1 425-555-0100" }, { "@search.score": 0.05634898, "phone_number": "425 555 0100" }, { "@search.score": 0.05634898, "phone_number": "425-555-0100" }, { "@search.score": 0.020766128, "phone_number": "(321) 555-0199" }, { "@search.score": 0.020766128, "phone_number": "+1 (321) 555-0199" } ] }Zkuste to znovu bez formátování:
4255550100.### Search for a phone number POST {{baseUrl}}/indexes/phone-numbers-index/docs/search?api-version=2026-04-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "search": "4255550100" }Tento dotaz je ještě horší a vrací pouze jednu ze čtyř správných shod.
{ "value": [ { "@search.score": 0.6015292, "phone_number": "4255550100" } ] }
Pokud tyto výsledky zjistíte matoucí, nejste sami. V další části se dozvíte, proč se vám tyto výsledky zobrazí.
Kontrola fungování analyzátorů
Abyste porozuměli těmto výsledkům hledání, musíte pochopit, co analyzátor dělá. Odtud můžete otestovat výchozí analyzátor pomocí rozhraní API pro analýzu a poskytnout základ pro návrh analyzátoru, který lépe vyhovuje vašim potřebám.
Analyzátor je součástí fulltextového vyhledávacího webu zodpovědného za zpracování textu v řetězcích dotazů a indexovaných dokumentech. Různé analyzátory manipulují s textem různými způsoby v závislosti na scénáři. V tomto scénáři potřebujeme vytvořit analyzátor přizpůsobený telefonním číslům.
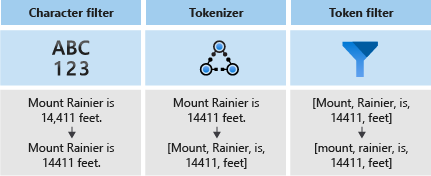
Analyzátory se skládají ze tří součástí:
- Filtry znaků, které odeberou nebo nahradí jednotlivé znaky ze vstupního textu.
- Tokenizátor, který rozdělí vstupní text na tokeny, které se stanou klíči v indexu vyhledávání.
- Filtry tokenů, které manipulují s tokeny vytvořenými tokenizátorem.
Následující diagram znázorňuje, jak tyto tři komponenty spolupracují na tokenizaci věty.
Tyto tokeny se pak ukládají do invertovaného indexu, který umožňuje rychlé fulltextové vyhledávání. Invertovaný index umožňuje fulltextové vyhledávání namapováním všech jedinečných termínů extrahovaných během lexikální analýzy na dokumenty, ve kterých k nim dochází. Příklad můžete vidět v následujícím diagramu:

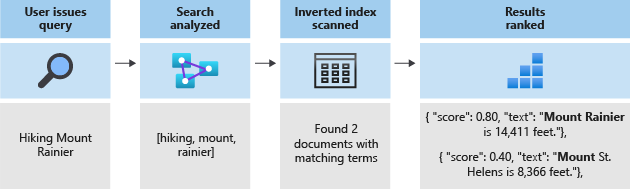
Celé hledání spočívá v hledání termínů uložených v invertovaném indexu. Když uživatel vydá dotaz:
- Dotaz se analyzuje a termíny dotazu se analyzují.
- Invertovaný index se používá ke skenování dokumentů s odpovídajícími termíny.
- Algoritmus bodování řadí načtené dokumenty.
Pokud se termíny dotazu neshodují s termíny v inverzním indexu, výsledky se nevrátí. Další informace o tom, jak fungují dotazy, najdete v tématu Fulltextové vyhledávání ve službě Azure AI Vyhledávač.
Poznámka:
Částečné dotazy termínů jsou důležitou výjimkou tohoto pravidla. Na rozdíl od běžných dotazů termínů tyto dotazy (dotaz předpony, dotaz se zástupnými čísly a dotaz regulárního výrazu) obcházejí proces lexikální analýzy. Částečné termíny jsou před porovnáváním s termíny v indexu převedeny na malá písmena. Pokud není analyzátor nakonfigurovaný tak, aby podporoval tyto typy dotazů, často dostáváte neočekávané výsledky, protože odpovídající termíny v indexu neexistují.
Testování analyzátorů pomocí rozhraní API pro analýzu
Azure AI Vyhledávač poskytuje rozhraní API pro analýzu, které umožňuje testovat analyzátory, abyste pochopili, jak zpracovávají text.
Zavolejte API pro analýzu pomocí následujícího požadavku:
### Test analyzer
POST {{baseUrl}}/indexes/phone-numbers-index/analyze?api-version=2026-04-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"text": "(425) 555-0100",
"analyzer": "standard.lucene"
}
Rozhraní API vrátí tokeny extrahované z textu pomocí analyzátoru, který jste zadali. Standardní analyzátor Lucene rozdělí telefonní číslo na tři samostatné tokeny.
{
"tokens": [
{
"token": "425",
"startOffset": 1,
"endOffset": 4,
"position": 0
},
{
"token": "555",
"startOffset": 6,
"endOffset": 9,
"position": 1
},
{
"token": "0100",
"startOffset": 10,
"endOffset": 14,
"position": 2
}
]
}
Naopak telefonní číslo 4255550100 formátované bez interpunkce je tokenizováno do jednoho tokenu.
{
"text": "4255550100",
"analyzer": "standard.lucene"
}
Odpověď:
{
"tokens": [
{
"token": "4255550100",
"startOffset": 0,
"endOffset": 10,
"position": 0
}
]
}
Mějte na paměti, že termíny dotazu i indexované dokumenty procházejí analýzou. Když se vrátíte k výsledkům hledání z předchozího kroku, můžete začít zjistit, proč se tyto výsledky vrátí.
V prvním dotazu se vrátí neočekávaná telefonní čísla, protože jeden z jejich tokenů odpovídá jednomu z hledaných termínů 555. Ve druhém dotazu se vrátí pouze jedno číslo, protože se jedná o jediný záznam, který má odpovídající 4255550100token .
Vytvoření vlastního analyzátoru
Teď, když rozumíte výsledkům, které vidíte, vytvořte vlastní analyzátor pro zlepšení logiky tokenizace.
Cílem je poskytovat intuitivní vyhledávání telefonních čísel bez ohledu na formát dotazu nebo indexovaného řetězce. Chcete-li dosáhnout tohoto výsledku, zadejte filtr znaků, tokenizátor a filtr tokenů.
Filtry znaků
Filtry znaků zpracovávají text před jeho odesláním do tokenizátoru. Běžné použití filtrů znaků filtruje elementy HTML a nahrazuje speciální znaky.
U telefonních čísel chcete odebrat prázdné znaky a speciální znaky, protože ne všechny formáty telefonních čísel obsahují stejné speciální znaky a mezery.
"charFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.MappingCharFilter",
"name": "phone_char_mapping",
"mappings": [
"-=>",
"(=>",
")=>",
"+=>",
".=>",
"\\u0020=>"
]
}
]
Filtr odebere -()+. a mezery ze vstupu.
| Vstup | Výstup |
|---|---|
(321) 555-0199 |
3215550199 |
321.555.0199 |
3215550199 |
Tokenizátory
Tokenizátory rozdělují text na tokeny a zahodí některé znaky, jako je interpunkce, po cestě. V mnoha případech je cílem tokenizace rozdělit větu na jednotlivá slova.
V tomto scénáři pomocí tokenizátoru keyword_v2klíčových slov zachyťte telefonní číslo jako jeden termín. Toto není jediný způsob, jak tento problém vyřešit, jak je vysvětleno v části Alternativní přístupy .
Tokenizátory klíčových slov vždy vypíší stejný text jako jeden termín.
| Vstup | Výstup |
|---|---|
The dog swims. |
[The dog swims.] |
3215550199 |
[3215550199] |
Filtry tokenů
Filtry tokenů upravují nebo odfiltrují tokeny vygenerované tokenizátorem. Jedním z běžných použití filtru tokenů je převod všech znaků na malá písmena pomocí filtru pro převod na malá písmena. Dalším běžným použitím je filtrování zastavovacích slov, jako the, and nebo is.
I když pro tento scénář nepotřebujete použít některý z těchto filtrů, použijte filtr tokenu nGram, který umožňuje částečné hledání telefonních čísel.
"tokenFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.NGramTokenFilterV2",
"name": "custom_ngram_filter",
"minGram": 3,
"maxGram": 20
}
]
NGramTokenFilterV2
Filtr tokenů nGram_v2 rozdělí tokeny na n-gramy o dané velikosti na základě parametrů minGram a maxGram.
U analyzátoru telefonu je minGram nastaveno na 3, protože se očekává, že uživatelé budou hledat nejkratší podřetězec.
maxGram je nastaven tak, aby se všechna telefonní čísla 20, i s příponami, vešla do jednoho n-gramu.
Nešťastným vedlejším účinkem n-gramů je, že se vracejí některé falešně pozitivní výstupy. Tento problém opravíte v pozdějším kroku vytvořením samostatného analyzátoru pro hledání, která neobsahuje filtr tokenů n-gram.
| Vstup | Výstup |
|---|---|
[12345] |
[123, 1234, 12345, 234, 2345, 345] |
[3215550199] |
[321, 3215, 32155, 321555, 3215550, 32155501, 321555019, 3215550199, 215, 2155, 21555, 215550, ... ] |
Analyzátor
Pomocí filtrů znaků, tokenizátoru a filtrů tokenů jste připraveni definovat analyzátor.
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer",
"tokenizer": "keyword_v2",
"tokenFilters": [
"custom_ngram_filter"
],
"charFilters": [
"phone_char_mapping"
]
}
]
Z rozhraní API pro analýzu jsou výstupy z vlastního analyzátoru následující:
| Vstup | Výstup |
|---|---|
12345 |
[123, 1234, 12345, 234, 2345, 345] |
(321) 555-0199 |
[321, 3215, 32155, 321555, 3215550, 32155501, 321555019, 3215550199, 215, 2155, 21555, 215550, ... ] |
Všechny tokeny ve výstupním sloupci existují v indexu. Pokud dotaz obsahuje některý z těchto termínů, vrátí se telefonní číslo.
Opětovné sestavení pomocí nového analyzátoru
Odstraňte aktuální index.
### Delete the index DELETE {{baseUrl}}/indexes/phone-numbers-index?api-version=2026-04-01 HTTP/1.1 api-key: {{apiKey}}Znovu vytvořte index pomocí nového analyzátoru. Toto schéma indexu přidává v poli telefonního čísla definici vlastního analyzátoru a přiřazení tohoto analyzátoru.
### Create a new index POST {{baseUrl}}/indexes?api-version=2026-04-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "name": "phone-numbers-index-2", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "searchable": true, "filterable": false, "facetable": false, "sortable": true }, { "name": "phone_number", "type": "Edm.String", "sortable": false, "searchable": true, "filterable": false, "facetable": false, "analyzer": "phone_analyzer" } ], "analyzers": [ { "@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer", "name": "phone_analyzer", "tokenizer": "keyword_v2", "tokenFilters": [ "custom_ngram_filter" ], "charFilters": [ "phone_char_mapping" ] } ], "charFilters": [ { "@odata.type": "#Microsoft.Azure.Search.MappingCharFilter", "name": "phone_char_mapping", "mappings": [ "-=>", "(=>", ")=>", "+=>", ".=>", "\\u0020=>" ] } ], "tokenFilters": [ { "@odata.type": "#Microsoft.Azure.Search.NGramTokenFilterV2", "name": "custom_ngram_filter", "minGram": 3, "maxGram": 20 } ] }
Testování vlastního analyzátoru
Po opětovném vytvoření indexu otestujte analyzátor pomocí následujícího požadavku:
### Test custom analyzer
POST {{baseUrl}}/indexes/phone-numbers-index-2/analyze?api-version=2026-04-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"text": "+1 (321) 555-0199",
"analyzer": "phone_analyzer"
}
Teď byste měli vidět kolekci tokenů, které jsou výsledkem telefonního čísla.
{
"tokens": [
{
"token": "132",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
{
"token": "1321",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
{
"token": "13215",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
...
...
...
]
}
Úprava vlastního analyzátoru pro zpracování falešně pozitivních výsledků
Po použití vlastního analyzátoru k vytvoření ukázkových dotazů na index byste měli vidět, že pokrytí se zlepšilo a všechna odpovídající telefonní čísla se nyní zobrazí. Filtr n-gram tokenů ale také způsobí vrácení některých falešně pozitivních výsledků. Jedná se o běžný vedlejší účinek filtru tokenů n-gram.
Pokud chcete zabránit falešně pozitivním výsledkům, vytvořte samostatný analyzátor pro dotazování. Tento analyzátor je identický s předchozím, s tím rozdílem, že vynechává custom_ngram_filter.
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer_search",
"tokenizer": "custom_tokenizer_phone",
"tokenFilters": [],
"charFilters": [
"phone_char_mapping"
]
}
V definici indexu zadejte jak indexAnalyzer, tak i searchAnalyzer.
{
"name": "phone_number",
"type": "Edm.String",
"sortable": false,
"searchable": true,
"filterable": false,
"facetable": false,
"indexAnalyzer": "phone_analyzer",
"searchAnalyzer": "phone_analyzer_search"
}
S touto změnou je vše připraveno. Tady jsou další kroky:
Odstraňte index.
Po přidání nového vlastního analyzátoru (
phone_analyzer-search) znovu vytvořte index a přiřaďte tento analyzátor vlastnostiphone-numberpolesearchAnalyzer.Znovu načtěte data.
Znovu otestujte dotazy a ověřte, že hledání funguje podle očekávání. Pokud používáte ukázkový soubor, tento krok vytvoří třetí index s názvem
phone-number-index-3.
Alternativní přístupy
Analyzátor popsaný v předchozí části je navržený tak, aby maximalizoval flexibilitu vyhledávání. To ale dělá za cenu uložení mnoha potenciálně nedůležitých termínů v indexu.
Následující příklad ukazuje alternativní analyzátor, který je efektivnější v tokenizaci, ale má nevýhody.
Při zadání 14255550100 nemůže analyzátor logicky rozdělit telefonní číslo. Například nemůže oddělit kód země , 1od směrového kódu oblasti, 425. Tato nesrovnalost vede k tomu, že se telefonní číslo nevrátí, pokud uživatel do hledání nezahrne kód země.
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer_shingles",
"tokenizer": "custom_tokenizer_phone",
"tokenFilters": [
"custom_shingle_filter"
]
}
],
"tokenizers": [
{
"@odata.type": "#Microsoft.Azure.Search.StandardTokenizerV2",
"name": "custom_tokenizer_phone",
"maxTokenLength": 4
}
],
"tokenFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.ShingleTokenFilter",
"name": "custom_shingle_filter",
"minShingleSize": 2,
"maxShingleSize": 6,
"tokenSeparator": ""
}
]
V následujícím příkladu je telefonní číslo rozdělené na bloky dat, které obvykle očekáváte, že uživatel bude hledat.
| Vstup | Výstup |
|---|---|
(321) 555-0199 |
[321, 555, 0199, 321555, 5550199, 3215550199] |
V závislosti na vašich požadavcích to může být efektivnější přístup k problému.
Shrnutí
V tomto kurzu jsme si ukázali proces sestavování a testování vlastního analyzátoru. Vytvořili jste index, indexovaná data a potom jste se na index dotazovali, abyste zjistili, jaké výsledky hledání se vrátily. Odtud jste použili rozhraní API pro analýzu k zobrazení procesu lexikální analýzy v akci.
I když analyzátor definovaný v tomto kurzu nabízí jednoduché řešení pro vyhledávání na telefonních číslech, stejný proces lze použít k vytvoření vlastního analyzátoru pro jakýkoli scénář, který sdílí podobné charakteristiky.
Vyčištění prostředků
Na konci projektu je vhodné odebrat prostředky, které už nepotřebujete, když pracujete ve vlastním předplatném. Prostředky ponechané v provozu mohou způsobit výdaje. Prostředky můžete odstraňovat jednotlivě nebo můžete odstranit skupinu prostředků, a odstranit tak celou sadu prostředků najednou.
Prostředky můžete najít a spravovat na webu Azure Portal pomocí odkazu Všechny prostředky nebo skupiny prostředků v levém navigačním podokně.
Další kroky
Teď, když víte, jak vytvořit vlastní analyzátor, podívejte se na všechny různé filtry, tokenizátory a analyzátory, které jsou k dispozici pro vytvoření bohatého vyhledávacího prostředí: