Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Azure AI Vyhledávač podporuje import, analýzu a indexování dat z více zdrojů dat do jednoho konsolidovaného vyhledávacího indexu.
Tento kurz jazyka C# používá klientskou knihovnu Azure.Search.Documents v sadě Azure SDK pro .NET k indexování ukázkových dat hotelů z instance služby Azure Cosmos DB. Potom sloučíte data s podrobnostmi hotelových pokojů získanými z dokumentů Azure Blob Storage. Výsledkem je kombinovaný index vyhledávání v hotelu, který obsahuje hotelové dokumenty s místnostmi jako komplexními datovými typy.
V tomto kurzu se naučíte:
- Nahrání ukázkových dat do zdrojů dat
- Identifikace klíče dokumentu
- Definování a vytvoření indexu
- Indexování hotelových dat ze služby Azure Cosmos DB
- Sloučení dat hotelových pokojů ze služby Blob Storage
Přehled
V tomto kurzu se k vytváření a spouštění více indexerů používá Azure.Search.Documents . Nahrajete ukázková data do dvou zdrojů dat Azure a nakonfigurujete indexer, který načítá z obou zdrojů, aby se naplnil jeden index vyhledávání. Pro podporu sloučení musí mít tyto dvě sady dat společnou hodnotu. V tomto návodu je toto pole ID. Pokud je pro mapování společné pole, může indexer sloučit data z různorodých prostředků: strukturovaná data z Azure SQL, nestrukturovaná data ze služby Blob Storage nebo libovolná kombinace podporovaných zdrojů dat v Azure.
Dokončenou verzi kódu v tomto kurzu najdete v následujícím projektu:
Požadavky
- Účet Azure s aktivním předplatným. Vytvoření účtu zdarma
- Účet Azure Cosmos DB pro NoSQL.
- Účet služby Azure Storage.
- Služba Azure AI Vyhledávač.
- Visual Studio.
Poznámka:
Pro účely tohoto kurzu můžete použít bezplatnou vyhledávací službu. Úroveň Free vás omezuje na tři indexy, tři indexery a tři zdroje dat. V tomto tutoriálu se vytvoří jeden od každého. Než začnete, ujistěte se, že máte ve službě místo pro přijetí nových prostředků.
Příprava služeb
Tento kurz používá Azure AI Vyhledávač k indexování a dotazům, Azure Cosmos DB pro první sadu dat a Azure Blob Storage pro druhou datovou sadu.
Pokud je to možné, vytvořte všechny služby ve stejné oblasti a skupině prostředků pro blízkost a správu. V praxi můžou být vaše služby v libovolné oblasti.
Tato ukázka používá dvě malé sady dat popisujících sedm fiktivních hotelů. Jedna sada popisuje samotné hotely a načte se do databáze Azure Cosmos DB. Druhá sada obsahuje podrobnosti o hotelové místnosti a poskytuje se jako sedm samostatných souborů JSON, které se mají nahrát do Azure Blob Storage.
Začínáme se službou Azure Cosmos DB
Na webu Azure Portal přejděte ke svému účtu služby Azure Cosmos DB.
V levém podokně vyberte Průzkumník dat.
VyberteNovou databázi kontejneru>.
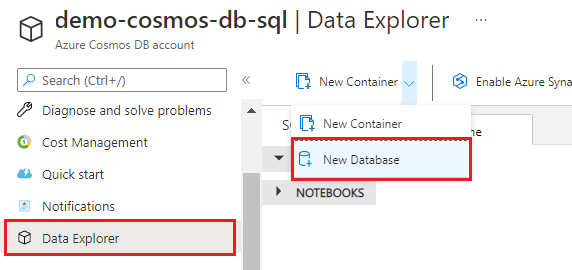
Zadejte název hotel-rooms-db . Přijměte výchozí hodnoty pro zbývající nastavení.
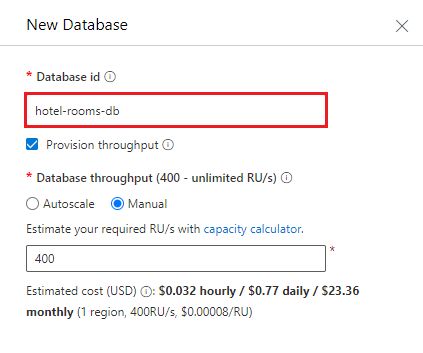
Vytvořte kontejner, který cílí na dříve vytvořenou databázi. Zadejte hotely pro název kontejneru a /HotelId pro klíč oddílu.
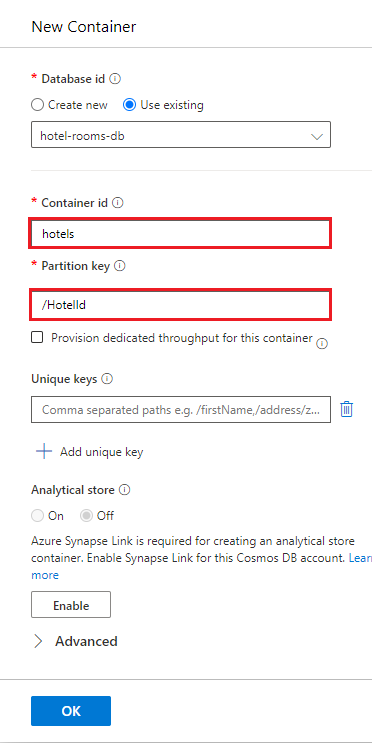
Vyberte hotely>Položky, a pak na panelu příkazů vyberte Nahrát položku.
Nahrajte soubor JSON ze
cosmosdbsložky ve složce multiple-data-sources/v11.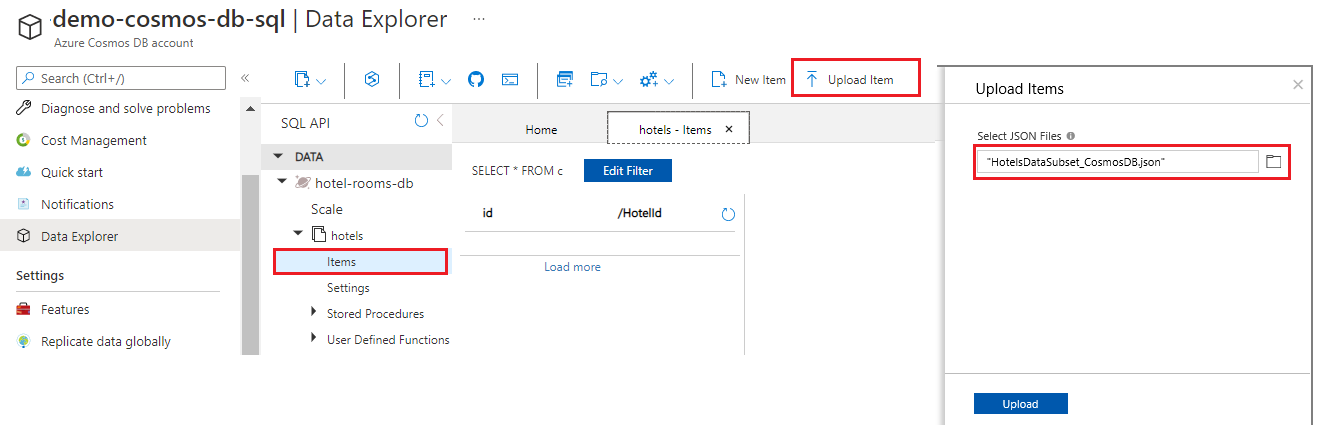
Pomocí tlačítka Aktualizovat aktualizujte zobrazení položek v kolekci hotelů. Mělo by se zobrazit sedm nových databázových dokumentů.
V levém podokně vyberte Nastavení>Klíče.
Poznamenejte si připojovací řetězec. Tuto hodnotu potřebujete pro appsettings.json v pozdějším kroku. Pokud jste nepoužíli navrhovaný název databáze hotel-rooms-db , zkopírujte také název databáze.
Azure Blob Storage
Na webu Azure Portal přejděte ke svému účtu Azure Storage.
V levém podokně vyberte úložiště dat>Kontejnery.
Vytvořte kontejner objektů blob s názvem hotel-rooms pro uložení souborů JSON ukázkových hotelových místností. Úroveň přístupu můžete nastavit na libovolnou platnou hodnotu.
Otevřete kontejner a pak na panelu příkazů vyberte Nahrát .
Nahrajte sedm souborů JSON ze
blobsložky ve více zdrojích dat/v11.
V levém podokně vyberte Zabezpečení a síťové>přístupové klíče.
Poznamenejte si název účtu a připojovací řetězec. V pozdějším kroku potřebujete obě hodnoty pro appsettings.json .
Azure AI Vyhledávač
Třetí komponentou je Azure AI Vyhledávač, kterou můžete vytvořit na webu Azure Portal nebo ve svých prostředcích Azure najít existující vyhledávací službu .
Zkopírování klíče správce a adresy URL služby Azure AI Vyhledávač
K ověření ve vyhledávací službě potřebujete adresu URL služby a přístupový klíč. Když máte platný klíč, vytvoří se vztah důvěryhodnosti na základě žádosti mezi aplikací, která žádost odešle, a službou, která ji zpracovává.
Na webu Azure Portal přejděte do vyhledávací služby.
V levém podokně vyberte Přehled.
Poznamenejte si adresu URL, která by měla vypadat takto
https://my-service.search.windows.net.V levém podokně vyberte Nastavení>Klíče.
Poznamenejte si klíč správce pro úplná práva ke službě. Existují dva zaměnitelné klíče správce, které jsou k dispozici pro zajištění kontinuity podnikových procesů v případě, že potřebujete jeden převést. K přidávání, úpravám a odstraňování objektů můžete použít jeden z klíčů v požadavcích.
Nastavení prostředí
Otevřete soubor
AzureSearchMultipleDataSources.slnz multiple-data-sources/v11 v aplikaci Visual Studio.V Průzkumníku řešení klikněte pravým tlačítkem myši na projekt a zvolte Spravovat balíčky NuGet pro řešení....
Na kartě Procházet vyhledejte a nainstalujte následující balíčky.
Azure.Search.Documents (verze 11.0 nebo novější)
Microsoft.Extensions.Configuration
Microsoft.Extensions.Configuration.Json
V Průzkumníku řešení
appsettings.jsonupravte soubor s informacemi o připojení, které jste shromáždili v předchozích krocích.{ "SearchServiceUri": "<YourSearchServiceURL>", "SearchServiceAdminApiKey": "<YourSearchServiceAdminApiKey>", "BlobStorageAccountName": "<YourBlobStorageAccountName>", "BlobStorageConnectionString": "<YourBlobStorageConnectionString>", "CosmosDBConnectionString": "<YourCosmosDBConnectionString>", "CosmosDBDatabaseName": "hotel-rooms-db" }
Mapovat klíčová pole
Sloučení obsahu vyžaduje, aby oba datové proudy cílily na stejné dokumenty v indexu vyhledávání.
Ve službě Azure AI Vyhledávač pole s klíčem jednoznačně identifikuje každý dokument. Každý index vyhledávání musí mít přesně jedno klíčové pole typu Edm.String. Toto pole klíče musí být k dispozici pro každý dokument ve zdroji dat, který je přidán do indexu. (Ve skutečnosti je to jediné povinné pole.)
Při indexování dat z více zdrojů dat se ujistěte, že každý příchozí řádek nebo dokument obsahuje společný klíč dokumentu. Díky tomu můžete sloučit data ze dvou fyzicky odlišných zdrojových dokumentů do nového vyhledávacího dokumentu v kombinovaném indexu.
Často vyžaduje určité počáteční plánování identifikace smysluplného klíče dokumentu pro váš index a zajištění, že existuje v obou zdrojích dat. V této ukázce HotelId se klíč pro každý hotel ve službě Azure Cosmos DB nachází také v datech JSON blob v Blob Storage.
Indexery azure AI Search můžou pomocí mapování polí přejmenovat a dokonce přeformátovat datová pole během procesu indexování, aby zdrojová data byla směrována na správné pole indexu. Například ve službě Azure Cosmos DB se volá HotelIdidentifikátor hotelu , ale v souborech objektů blob JSON pro hotelové pokoje se jmenuje Ididentifikátor hotelu . Program tuto nesrovnalost zpracovává mapováním Id pole z blobů na HotelId pole klíče v indexeru.
Poznámka:
Ve většině případů automaticky vygenerované klíče dokumentu, například klíče vytvořené ve výchozím nastavení některými indexery, nevytvářily vhodné klíče dokumentu pro kombinované indexy. Obecně používejte smysluplnou jedinečnou hodnotu klíče, která již ve vašich zdrojích dat existuje, nebo ji můžete snadno přidat.
Prozkoumání kódu
Jakmile jsou data a nastavení konfigurace zavedená, měl by být ukázkový program AzureSearchMultipleDataSources.sln připravený k sestavení a spuštění.
Tato jednoduchá konzolová aplikace C#/.NET provádí následující úlohy:
- Vytvoří nový index založený na datové struktuře třídy C# Hotel, která odkazuje také na třídy Address a Room.
- Vytvoří nový zdroj dat a indexer, který mapuje data Azure Cosmos DB na pole indexu. Jedná se o oba objekty ve službě Azure AI Vyhledávač.
- Spustí indexer pro načtení hotelových dat ze služby Azure Cosmos DB.
- Vytvoří druhý zdroj dat a indexer, který mapuje data objektů blob JSON na pole indexu.
- Spustí druhý indexer, který načte data hotelových místností ze služby Blob Storage.
Než program spustíte, věnujte chvíli prostudování definice kódu, definice indexu a definice indexeru. Důležitý kód je ve dvou souborech:
-
Hotel.csobsahuje schéma, které definuje index. -
Program.csobsahuje funkce, které vytvářejí index Azure AI Vyhledávač, zdroje dat a indexery a načítají kombinované výsledky do indexu.
Vytvoření indexu
Tento ukázkový program používá CreateIndexAsync k definování a vytvoření indexu Azure AI Vyhledávač. Využívá výhod Třídy FieldBuilder k vygenerování struktury indexu z třídy datového modelu jazyka C#.
Datový model je definován třídou Hotel, která obsahuje také odkazy na třídy Adresa a místnost. FieldBuilder prochází skrze mnoha definic tříd, aby vygeneroval složitou datovou strukturu pro index. Značky metadat slouží k definování atributů jednotlivých polí, jako je například to, jestli je prohledávatelné nebo řaditelné.
Program před vytvořením nového odstraní všechny existující indexy se stejným názvem, pokud chcete tento příklad spustit více než jednou.
Následující fragmenty kódu ze Hotel.cs souboru zobrazují jednotlivá pole následovaná odkazem na jinou třídu datového modelu, Místnost[], která je zase definovaná v Room.cs souboru (není zobrazena).
. . .
[SimpleField(IsFilterable = true, IsKey = true)]
public string HotelId { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true)]
public string HotelName { get; set; }
. . .
public Room[] Rooms { get; set; }
. . .
Program.cs V souboru je searchIndex definován s názvem a kolekcí polí vygenerovanou FieldBuilder.Build metodou a pak vytvořen následujícím způsobem:
private static async Task CreateIndexAsync(string indexName, SearchIndexClient indexClient)
{
// Create a new search index structure that matches the properties of the Hotel class.
// The Address and Room classes are referenced from the Hotel class. The FieldBuilder
// will enumerate these to create a complex data structure for the index.
FieldBuilder builder = new FieldBuilder();
var definition = new SearchIndex(indexName, builder.Build(typeof(Hotel)));
await indexClient.CreateIndexAsync(definition);
}
Vytvoření zdroje dat a indexeru azure Cosmos DB
Hlavní program obsahuje logiku pro vytvoření zdroje dat Azure Cosmos DB pro data hotelů.
Nejprve spojí název databáze Azure Cosmos DB s připojovacím řetězcem. Pak definuje SearchIndexerDataSourceConnection objekt.
private static async Task CreateAndRunCosmosDbIndexerAsync(string indexName, SearchIndexerClient indexerClient)
{
// Append the database name to the connection string
string cosmosConnectString =
configuration["CosmosDBConnectionString"]
+ ";Database="
+ configuration["CosmosDBDatabaseName"];
SearchIndexerDataSourceConnection cosmosDbDataSource = new SearchIndexerDataSourceConnection(
name: configuration["CosmosDBDatabaseName"],
type: SearchIndexerDataSourceType.CosmosDb,
connectionString: cosmosConnectString,
container: new SearchIndexerDataContainer("hotels"));
// The Azure Cosmos DB data source does not need to be deleted if it already exists,
// but the connection string might need to be updated if it has changed.
await indexerClient.CreateOrUpdateDataSourceConnectionAsync(cosmosDbDataSource);
Po vytvoření zdroje dat program nastaví indexer služby Azure Cosmos DB s názvem hotel-rooms-cosmos-indexer.
Program aktualizuje všechny existující indexery se stejným názvem a přepíše stávající indexer obsahem předchozího kódu. Zahrnuje také akce resetování a spuštění, pokud chcete tento příklad spustit více než jednou.
Následující příklad definuje harmonogram pro indexer, tak, aby se spouštěl jednou denně. Vlastnost harmonogramu můžete z tohoto volání odstranit, pokud nechcete, aby se indexer v budoucnu automaticky spustil znovu.
SearchIndexer cosmosDbIndexer = new SearchIndexer(
name: "hotel-rooms-cosmos-indexer",
dataSourceName: cosmosDbDataSource.Name,
targetIndexName: indexName)
{
Schedule = new IndexingSchedule(TimeSpan.FromDays(1))
};
// Indexers keep metadata about how much they have already indexed.
// If we already ran the indexer, it "remembers" and does not run again.
// To avoid this, reset the indexer if it exists.
try
{
await indexerClient.GetIndexerAsync(cosmosDbIndexer.Name);
// Reset the indexer if it exists.
await indexerClient.ResetIndexerAsync(cosmosDbIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
// If the indexer does not exist, 404 will be thrown.
}
await indexerClient.CreateOrUpdateIndexerAsync(cosmosDbIndexer);
Console.WriteLine("Running Azure Cosmos DB indexer...\n");
try
{
// Run the indexer.
await indexerClient.RunIndexerAsync(cosmosDbIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 429)
{
Console.WriteLine("Failed to run indexer: {0}", ex.Message);
}
Tento příklad obsahuje jednoduchý blok try-catch, který hlásí všechny chyby, ke kterým může dojít během provádění.
Po spuštění indexeru Azure Cosmos DB obsahuje index vyhledávání úplnou sadu ukázkových hotelových dokumentů. Pole místností pro každý hotel je však prázdné pole, protože zdroj dat Azure Cosmos DB vynechá podrobnosti o místnosti. V dalším kroku program načte a sloučí data místnosti ze služby Blob Storage.
Vytvoření zdroje dat a indexeru blob Storage
Chcete-li získat podrobnosti o místnosti, program nejprve nastaví zdroj dat Blob Storage tak, aby odkazoval na sadu samostatných JSON blob souborů.
private static async Task CreateAndRunBlobIndexerAsync(string indexName, SearchIndexerClient indexerClient)
{
SearchIndexerDataSourceConnection blobDataSource = new SearchIndexerDataSourceConnection(
name: configuration["BlobStorageAccountName"],
type: SearchIndexerDataSourceType.AzureBlob,
connectionString: configuration["BlobStorageConnectionString"],
container: new SearchIndexerDataContainer("hotel-rooms"));
// The blob data source does not need to be deleted if it already exists,
// but the connection string might need to be updated if it has changed.
await indexerClient.CreateOrUpdateDataSourceConnectionAsync(blobDataSource);
Po vytvoření zdroje dat program nastaví indexer objektů blob s názvem hotel-rooms-blob-indexer, jak je znázorněno níže.
Objekty blob JSON obsahují pole klíče s názvem Id místo HotelId. Kód používá třídu FieldMapping, aby dal vědět indexeru, že má směrovat hodnotu pole Id na klíč dokumentu HotelId v indexu.
Indexery služby Blob Storage můžou použít indexingParameters k určení režimu analýzy. V závislosti na tom, jestli objekty blob představují jeden dokument nebo více dokumentů ve stejném objektu blob, byste měli nastavit různé režimy analýzy. V tomto příkladu každý objekt blob představuje jeden dokument JSON, takže kód používá json režim analýzy. Další informace o parsování parametrů indexeru pro objekty blob JSON najdete v tématu Indexování objektů blob JSON.
Tento příklad definuje harmonogram pro indexer, aby se spouštěl jednou denně. Vlastnost harmonogramu můžete z tohoto volání odstranit, pokud nechcete, aby se indexer v budoucnu automaticky spustil znovu.
IndexingParameters parameters = new IndexingParameters();
parameters.Configuration.Add("parsingMode", "json");
SearchIndexer blobIndexer = new SearchIndexer(
name: "hotel-rooms-blob-indexer",
dataSourceName: blobDataSource.Name,
targetIndexName: indexName)
{
Parameters = parameters,
Schedule = new IndexingSchedule(TimeSpan.FromDays(1))
};
// Map the Id field in the Room documents to the HotelId key field in the index
blobIndexer.FieldMappings.Add(new FieldMapping("Id") { TargetFieldName = "HotelId" });
// Reset the indexer if it already exists
try
{
await indexerClient.GetIndexerAsync(blobIndexer.Name);
await indexerClient.ResetIndexerAsync(blobIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404) { }
await indexerClient.CreateOrUpdateIndexerAsync(blobIndexer);
try
{
// Run the indexer.
await searchService.Indexers.RunAsync(blobIndexer.Name);
}
catch (CloudException e) when (e.Response.StatusCode == (HttpStatusCode)429)
{
Console.WriteLine("Failed to run indexer: {0}", e.Response.Content);
}
Protože index je již naplněný hotelovými daty z databáze Azure Cosmos DB, indexer objektů blob aktualizuje existující dokumenty v indexu a přidá podrobnosti o místnosti.
Poznámka:
Pokud máte v obou zdrojích dat stejná pole bez klíče a data v těchto polích se neshodují, index obsahuje hodnoty podle toho, co indexer naposledy spustil. V našem příkladu oba zdroje dat obsahují HotelName pole. Pokud se data v tomto poli z nějakého důvodu liší, pro dokumenty se stejnou hodnotou HotelName klíče jsou data z naposledy indexovaného zdroje dat hodnotou uloženou v indexu.
Search
Po spuštění programu můžete prozkoumat naplněný vyhledávací index pomocí Průzkumníka služby Search na webu Azure Portal.
Na webu Azure Portal přejděte do vyhledávací služby.
V levém podokně vyberte správu vyhledávání>Indexy.
V seznamu indexů vyberte hotel-rooms-sample .
Na kartě Průzkumník služby Search zadejte dotaz na termín, například
Luxury.Ve výsledcích by se měl zobrazit aspoň jeden dokument. Tento dokument by měl obsahovat seznam objektů místnosti v poli
Rooms.
Resetování a opětovné spuštění
V počátečních experimentálních fázích vývoje je nejproktičtějším přístupem k iteraci návrhu odstranit objekty z Azure AI Vyhledávač a umožnit kódu jejich opětovné sestavení. Názvy prostředků jsou jedinečné. Když se objekt odstraní, je možné ho znovu vytvořit se stejným názvem.
Vzorový kód zkontroluje existující objekty a odstraní nebo aktualizuje, abyste mohli program spustit znovu. Pomocí webu Azure Portal můžete také odstranit indexy, indexery a zdroje dat.
Uvolnění prostředků
Když pracujete ve vlastním předplatném, je vhodné na konci projektu odebrat prostředky, které už nepotřebujete. Necháte-li běžet prostředky, může vás to stát peníze. Prostředky můžete odstraňovat jednotlivě nebo můžete odstranit skupinu prostředků, a odstranit tak celou sadu prostředků najednou.
Prostředky můžete najít a spravovat na webu Azure Portal pomocí odkazu Všechny prostředky nebo skupiny prostředků v levém podokně.
Další krok
Teď, když znáte ingestování dat z více zdrojů, se podrobněji podíváme na konfiguraci indexeru počínaje službou Azure Cosmos DB: