Vytvoření úložiště vektorů
Ve službě Azure AI Search má úložiště vektorů schéma indexu, které definuje vektorová a nevectorová pole, vektorovou konfiguraci pro algoritmy, které vytvářejí vložený prostor a nastavení definic vektorových polí, které se používají v požadavcích dotazů. Rozhraní API pro vytvoření indexu vytvoří vektorové úložiště.
Při indexování vektorových dat postupujte takto:
- Definování schématu s jednou nebo více konfiguracemi vektorů, které určují algoritmy pro indexování a vyhledávání
- Přidání jednoho nebo více vektorových polí
- Načtěte předvectorizovaná data jako samostatný krok nebo použijte integrované vektorizace (Preview) pro vytváření bloků a kódování dat během indexování.
Tento článek se týká obecně dostupné verze vektorového vyhledávání bez verze Preview, která předpokládá, že kód aplikace volá externí prostředky pro blokování a kódování.
Poznámka:
Hledáte pokyny k migraci z verze 2023-07-01-Preview? Viz Upgrade rozhraní REST API.
Požadavky
Azure AI Search, v libovolné oblasti a na libovolné úrovni. Většina existujících služeb podporuje vektorové vyhledávání. U služeb vytvořených před lednem 2019 existuje malá podmnožina, která nemůže podporovat vektorové vyhledávání. Pokud se index obsahující vektorová pole nepodaří vytvořit nebo aktualizovat, jedná se o indikátor. V takovém případě se musí vytvořit nová služba.
Před existující vektorové vkládání do zdrojových dokumentů Azure AI Search negeneruje vektory v obecně dostupné verzi sad Azure SDK a rozhraní REST API. Modely vkládání Azure OpenAI doporučujeme, ale pro vektorizaci můžete použít libovolný model. Další informace naleznete v tématu Generování vkládání.
Měli byste znát omezení dimenzí modelu použitého k vytvoření vložených objektů a způsobu výpočtu podobnosti. V Azure OpenAI je délka číselného vektoru pro vkládání textu ada-002 1536. Podobnost se vypočítá pomocí
cosine. Platné hodnoty jsou 2 až 3072 dimenzí.Měli byste být obeznámeni s vytvářením indexu. Schéma musí obsahovat pole pro klíč dokumentu, další pole, která chcete prohledávat nebo filtrovat, a další konfigurace chování potřebné při indexování a dotazech.
Příprava dokumentů pro indexování
Před indexováním sestavte datovou část dokumentu, která obsahuje pole vektorových a nevectorových dat. Struktura dokumentu musí odpovídat schématu indexu.
Ujistěte se, že vaše dokumenty:
Zadejte pole nebo vlastnost metadat, která jednoznačně identifikuje každý dokument. Všechny indexy vyhledávání vyžadují klíč dokumentu. Aby bylo možné splnit požadavky na klíč dokumentu, musí mít zdrojový dokument jedno pole nebo vlastnost, které ho můžou jednoznačně identifikovat v indexu. Toto zdrojové pole musí být namapováno na pole indexu typu
Edm.Stringakey=truev indexu vyhledávání.Zadejte vektorová data (pole čísel s plovoucí desetinnou čárkou s jednoduchou přesností) ve zdrojových polích.
Vektorová pole obsahují číselná data generovaná vložením modelů, jedno vložení na pole. Pro textové dokumenty nebo rozhraní REST API pro načítání obrázků pro obrázky doporučujeme vkládat modely v Azure OpenAI, jako je vkládání textu ada-002. Podporují se pouze vektorová pole nejvyšší úrovně indexu: V současné době nejsou podporována dílčí pole vektoru.
Poskytněte ostatním polím pro odpověď dotazu alfanumerický obsah čitelný pro člověka a scénáře hybridních dotazů, které ve stejném požadavku obsahují fulltextové vyhledávání nebo sémantické řazení.
Index vyhledávání by měl obsahovat pole a obsah pro všechny scénáře dotazů, které chcete podporovat. Předpokládejme, že chcete vyhledávat nebo filtrovat názvy produktů, verze, metadata nebo adresy. V tomto případě není hledání podobnosti užitečné. Hledání klíčových slov, geografické vyhledávání nebo filtry by bylo lepší volbou. Index vyhledávání, který obsahuje komplexní kolekci vektorových a nevectorových dat, poskytuje maximální flexibilitu pro vytváření dotazů a složení odpovědí.
Krátký příklad datové části dokumentů, která obsahuje pole vektoru a nevectoru, je v části s daty vektoru načítání tohoto článku.
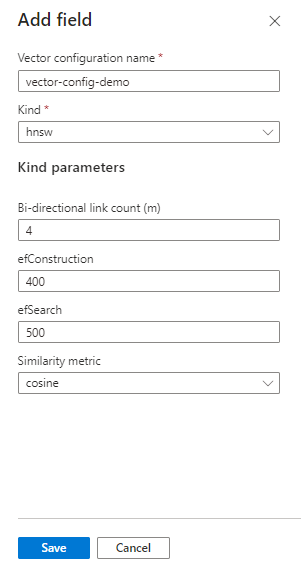
Přidání konfigurace vektorového vyhledávání
Konfigurace vektoru určuje algoritmus a parametry vektorového vyhledávání použité při indexování k vytvoření informací o nejbližším sousedu mezi vektorovými uzly:
- Hierarchický pohyblivý malý svět (HNSW)
- Vyčerpávající síť KNN
Pokud v poli zvolíte HNSW, můžete se rozhodnout pro vyčerpávající síť KNN v době dotazu. Ale druhý směr nebude fungovat: pokud zvolíte vyčerpávající, nemůžete později požádat o hledání HNSW, protože další datové struktury, které umožňují přibližné hledání neexistují.
Hledáte pokyny k migraci verzí preview na stabilní verzi? Postup najdete v tématu Upgrade rozhraní REST API .
Rozhraní REST API verze 2023-11-01 podporuje konfiguraci vektoru, která má:
vectorSearchalgoritmy aexhaustiveKnnnejbližší sousedyhnsws parametry pro indexování a bodování.vectorProfilespro více kombinací konfigurací algoritmů.
Nezapomeňte mít strategii pro vektorizaci obsahu. Stabilní verze neposkytuje vektorizátory pro integrované vkládání.
K vytvoření indexu použijte rozhraní API pro vytvoření nebo aktualizaci indexu .
vectorSearchDo indexu přidejte oddíl, který určuje vyhledávací algoritmy použité k vytvoření prostoru pro vložení."vectorSearch": { "algorithms": [ { "name": "my-hnsw-config-1", "kind": "hnsw", "hnswParameters": { "m": 4, "efConstruction": 400, "efSearch": 500, "metric": "cosine" } }, { "name": "my-hnsw-config-2", "kind": "hnsw", "hnswParameters": { "m": 8, "efConstruction": 800, "efSearch": 800, "metric": "cosine" } }, { "name": "my-eknn-config", "kind": "exhaustiveKnn", "exhaustiveKnnParameters": { "metric": "cosine" } } ], "profiles": [ { "name": "my-default-vector-profile", "algorithm": "my-hnsw-config-2" } ] }Klíčové body:
- Název konfigurace. Název musí být v rámci indexu jedinečný.
profilespřidejte vrstvu abstrakce pro zajištění širších definic. Profil je definován vvectorSearcha potom odkazuje podle názvu u každého vektorového pole."hnsw"a"exhaustiveKnn"jsou přibližné algoritmy ANN (Nearest Neighbors) sloužící k uspořádání vektorového obsahu během indexování."m"Výchozí hodnota (počet obousměrných propojení) je 4. Rozsah je 4 až 10. Nižší hodnoty by měly ve výsledcích vracet méně šumu."efConstruction"výchozí hodnota je 400. Rozsah je 100 až 1 000. Jedná se o počet nejbližších sousedů použitých při indexování."efSearch"výchozí hodnota je 500. Rozsah je 100 až 1 000. Jedná se o počet nejbližších sousedů použitých při hledání."metric"pokud používáte Azure OpenAI, měla by být kosinus, jinak použijte metriku podobnosti přidruženou k modelu vkládání, který používáte. Podporované hodnoty jsoucosine,dotProduct,euclidean.
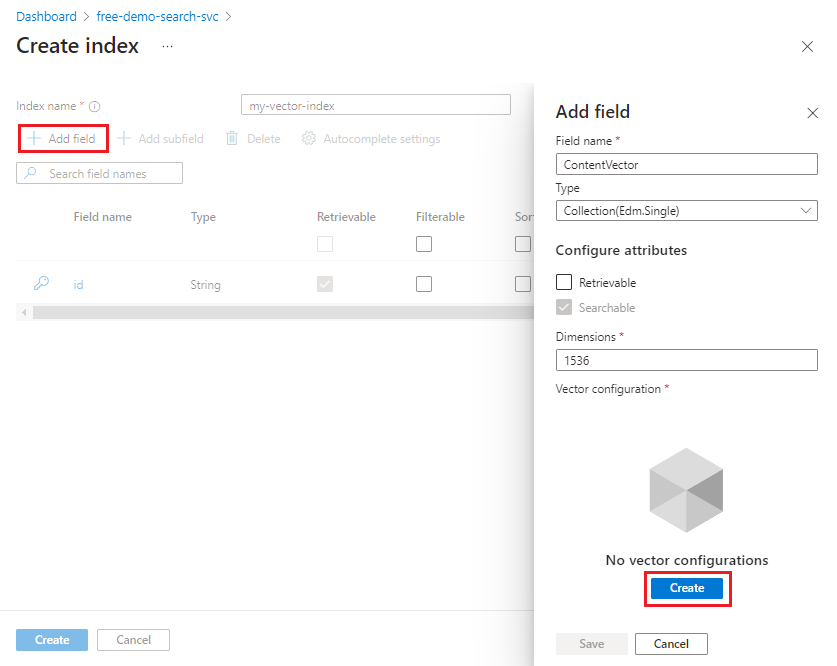
Přidání vektorového pole do kolekce polí
Kolekce polí musí obsahovat pole pro klíč dokumentu, vektorová pole a všechna další pole, která potřebujete pro scénáře hybridního vyhledávání.
Vektorová pole jsou typu Collection(Edm.Single) a hodnoty s plovoucí desetinnou čárkou s jednoduchou přesností. Pole tohoto typu má dimensions také vlastnost a určuje konfiguraci vektoru.
Tuto verzi použijte, pokud chcete jenom obecně dostupné funkce.
K vytvoření indexu použijte funkci Vytvořit nebo aktualizovat index .
Definujte vektorové pole s následujícími atributy. Pro každé pole můžete uložit jedno vygenerované vkládání. Pro každé vektorové pole:
typemusí býtCollection(Edm.Single).dimensionsje počet dimenzí vygenerovaných modelem vkládání. U text-embedding-ada-002 je to 1536.vectorSearchProfileje název profilu definovaného jinde v indexu.searchablemusí být pravdivé.retrievablemůže být true nebo false. True vrátí nezpracované vektory (1536 z nich) jako prostý text a spotřebovává úložný prostor. Pokud předáváte výsledek vektoru podřízené aplikaci, nastavte na hodnotu true.filterable,facetablesortablemusí být false.
Pokud chcete vyvolat předfiltrování nebo postfiltering v vektorovém dotazu, přidejte do kolekce filtrovatelná nevectorová pole, například "title" s
filterablenastavenou hodnotou true.Přidejte další pole, která definují látku a strukturu textového obsahu, který indexujete. Minimálně potřebujete klíč dokumentu.
Měli byste také přidat pole, která jsou užitečná v dotazu nebo v odpovědi. Následující příklad ukazuje vektorová pole pro název a obsah ("titleVector", "contentVector"), které jsou ekvivalentní vektorům. Poskytuje také pole pro ekvivalentní textový obsah ("title", "content") užitečný pro řazení, filtrování a čtení ve výsledku hledání.
Následující příklad ukazuje kolekci polí:
PUT https://my-search-service.search.windows.net/indexes/my-index?api-version=2023-11-01&allowIndexDowntime=true Content-Type: application/json api-key: {{admin-api-key}} { "name": "{{index-name}}", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "filterable": true }, { "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "sortable": true, "retrievable": true }, { "name": "titleVector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "my-default-vector-profile" }, { "name": "content", "type": "Edm.String", "searchable": true, "retrievable": true }, { "name": "contentVector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "my-default-vector-profile" } ], "vectorSearch": { "algorithms": [ { "name": "my-hnsw-config-1", "kind": "hnsw", "hnswParameters": { "m": 4, "efConstruction": 400, "efSearch": 500, "metric": "cosine" } } ], "profiles": [ { "name": "my-default-vector-profile", "algorithm": "my-hnsw-config-1" } ] } }
Načtení vektorových dat pro indexování
Obsah, který zadáte pro indexování, musí odpovídat schématu indexu a obsahovat jedinečnou řetězcovou hodnotu klíče dokumentu. Předvectorizovaná data se načtou do jednoho nebo více vektorových polí, která mohou existovat společně s jinými poli obsahujícími alfanumerický obsah.
K příjmu dat můžete použít metodologie nabízených oznámení nebo přijetí změn.
Dokumenty rejstříku (2023-11-01), Indexové dokumenty (2023-10-01-Preview) nebo Přidat, Aktualizovat nebo Odstranit dokumenty (2023-07-01-Preview) slouží k vložení dokumentů obsahujících vektorová data.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/index?api-version=2023-11-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"value": [
{
"id": "1",
"title": "Azure App Service",
"content": "Azure App Service is a fully managed platform for building, deploying, and scaling web apps. You can host web apps, mobile app backends, and RESTful APIs. It supports a variety of programming languages and frameworks, such as .NET, Java, Node.js, Python, and PHP. The service offers built-in auto-scaling and load balancing capabilities. It also provides integration with other Azure services, such as Azure DevOps, GitHub, and Bitbucket.",
"category": "Web",
"titleVector": [
-0.02250031754374504,
. . .
],
"contentVector": [
-0.024740582332015038,
. . .
],
"@search.action": "upload"
},
{
"id": "2",
"title": "Azure Functions",
"content": "Azure Functions is a serverless compute service that enables you to run code on-demand without having to manage infrastructure. It allows you to build and deploy event-driven applications that automatically scale with your workload. Functions support various languages, including C#, F#, Node.js, Python, and Java. It offers a variety of triggers and bindings to integrate with other Azure services and external services. You only pay for the compute time you consume.",
"category": "Compute",
"titleVector": [
-0.020159931853413582,
. . .
],
"contentVector": [
-0.02780858241021633,
. . .
],
"@search.action": "upload"
}
. . .
]
}
Kontrola obsahu vektoru v indexu
Pro účely ověřování můžete dotazovat index pomocí Průzkumníka služby Search na webu Azure Portal nebo volání rozhraní REST API. Protože Azure AI Search nemůže převést vektor na čitelný text, zkuste vrátit pole ze stejného dokumentu, který poskytuje důkaz shody. Pokud například vektorový dotaz cílí na pole "titleVector", můžete pro výsledky hledání vybrat "title".
Pole musí být atributem "retrievable", aby byla zahrnuta do výsledků.
K dotazování indexu můžete použít Průzkumník služby Search. Průzkumník služby Search má dvě zobrazení: zobrazení dotazu (výchozí) a zobrazení JSON.
Použití zobrazení JSON pro vektorové dotazy vložení do definice JSON vektorového dotazu, který chcete provést.
Pro rychlé potvrzení, že index obsahuje vektory, použijte výchozí zobrazení dotazu. Zobrazení dotazu je určené pro fulltextové vyhledávání. I když ho nemůžete použít pro vektorové dotazy, můžete odeslat prázdné vyhledávání (
search=*) a zkontrolovat obsah. Obsah všech polí, včetně vektorových polí, se vrátí jako prostý text.
Aktualizace úložiště vektorů
Pokud chcete aktualizovat úložiště vektorů, upravte schéma a v případě potřeby znovu načtěte dokumenty, aby se naplnila nová pole. Rozhraní API pro aktualizace schématu zahrnují rozhraní REST (Create or Update Index), CreateOrUpdateIndex v sadě Azure SDK pro .NET, create_or_update_index v sadě Azure SDK pro Python a podobné metody v jiných sadách Azure SDK.
Standardní pokyny pro aktualizaci indexu jsou popsané v rozevíracím seznamu a opětovném sestavení indexu.
Mezi klíčové body patří:
Odstranění a opětovné sestavení se často vyžaduje pro aktualizace a odstranění existujících polí.
Existující schéma však můžete aktualizovat pomocí následujících úprav bez nutnosti opětovného sestavení:
- Přidejte nová pole do kolekce polí.
- Přidejte nové konfigurace vektorů přiřazené k novým polím, ale ne existujícím polím, která již byla vektorizována.
- Změňte "retrievable" (hodnoty jsou true nebo false) u existujícího pole. Vektorová pole musí být prohledávatelná a načístelná, ale pokud chcete zakázat přístup k vektorovým polím v situacích, kdy přetažení a opětovné sestavení není možné, můžete nastavit načtení na false.
Další kroky
Jako další krok doporučujeme použít vektorová data dotazu v indexu vyhledávání.
Ukázky kódu v úložišti azure-search-vector ukazují kompletní pracovní postupy, které zahrnují definici schématu, vektorizaci, indexování a dotazy.
Existuje ukázkový kód pro Python, C# a JavaScript.