Poznámka
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tento článek vysvětluje, jak aktualizovat existující index ve službě Azure AI Search změnami schématu nebo změnami obsahu prostřednictvím přírůstkového indexování. Vysvětluje okolnosti, za kterých se vyžadují přestavby, a poskytuje doporučení pro zmírnění dopadů přestaveb na probíhající dotazy.
Během aktivního vývoje se při iterování návrhu indexů běžně odstraňují a znovu sestavují indexy. Většina vývojářů pracuje s malým reprezentativním vzorkem dat, aby přeindexování bylo rychlejší.
Pro změny schématu aplikací, které jsou již v produkčním prostředí, doporučujeme vytvořit a otestovat nový index, který běží vedle existujícího indexu. Pomocí aliasu indexu prohoďte nový index, abyste se vyvarovali změnám kódu aplikace.
Aktualizace obsahu
Přírůstkové indexování a synchronizace indexu proti změnám zdrojových dat je zásadní pro většinu vyhledávacích aplikací. Tato část vysvětluje pracovní postup pro přidání, odebrání nebo přepsání obsahu indexu vyhledávání prostřednictvím rozhraní REST API, ale sady Azure SDK poskytují ekvivalentní funkce.
Text požadavku obsahuje jeden nebo více dokumentů, které se mají indexovat. V rámci požadavku je každý dokument v indexu následující:
- Identifikovaný jedinečným klíčem rozlišující malá a velká písmena.
- Přidruženo k akci: "upload", "delete", "merge" nebo "mergeOrUpload".
- Naplněno sadou párů název/hodnota pro každé pole, které přidáváte nebo aktualizujete.
{
"value": [
{
"@search.action": "upload (default) | merge | mergeOrUpload | delete",
"key_field_name": "unique_key_of_document", (key/value pair for key field from index schema)
"field_name": field_value (name/value pairs matching index schema)
...
},
...
]
}
Nejprve použijte rozhraní API pro načítání dokumentů, například Dokumenty – Index (REST) nebo ekvivalentní rozhraní API v sadách SDK Azure. Další informace o technikách indexování naleznete v tématu Načtení dokumentů.
U velké aktualizace se doporučuje zpracování v dávkách (až 1 000 dokumentů na dávku nebo přibližně 16 MB na dávku, podle toho, co nastane dříve) a výrazně zvyšuje výkon indexování.
@search.actionNastavte parametr rozhraní API tak, aby určil vliv na existující dokumenty.Akce Účinnost odstranit Odebere celý dokument z indexu. Pokud chcete odebrat jednotlivá pole, použijte místo toho sloučení a nastavujte příslušné pole na hodnotu null. Odstraněné dokumenty a pole okamžitě nezabírají místo v indexu. Proces na pozadí provede fyzické odstranění každých několik minut. Bez ohledu na to, jestli k vrácení statistik indexu používáte Azure Portal nebo rozhraní API, můžete očekávat malé zpoždění před tím, než se odstranění projeví na webu Azure Portal a prostřednictvím rozhraní API. sloučení Aktualizuje dokument, který již existuje, a selže dokument, který se nedá najít. Sloučení nahradí existující hodnoty. Z tohoto důvodu nezapomeňte zkontrolovat pole kolekce, která obsahují více hodnot, například pole typu Collection(Edm.String). Pokud napříkladtagspole začíná hodnotou["budget"]a provedete sloučení s["economy", "pool"], konečná hodnotatagspole je["economy", "pool"].["budget", "economy", "pool"]Nebude to .
Stejné chování platí pro složité kolekce. Pokud dokument obsahuje komplexní pole kolekce s názvem Místnosti s hodnotou[{ "Type": "Budget Room", "BaseRate": 75.0 }], a provedete sloučení s hodnotou[{ "Type": "Standard Room" }, { "Type": "Budget Room", "BaseRate": 60.5 }], bude konečná hodnota pole[{ "Type": "Standard Room" }, { "Type": "Budget Room", "BaseRate": 60.5 }]Místnosti . Nepřidá nebo sloučí nové a existující hodnoty.sloučitNeboNahrát Chová se jako sloučení, jestliže dokument existuje, a jako nahrání, jestliže je dokument nový. Toto je nejběžnější akce pro přírůstkové aktualizace. nahrání Podobně jako "upsert", kde se dokument vloží, pokud je nový, a pokud existuje, aktualizuje nebo nahradí. Pokud v dokumentu chybí hodnoty, které index vyžaduje, je hodnota pole dokumentu nastavená na hodnotu null.
Dotazy se budou dál spouštět během indexování, ale pokud aktualizujete nebo odebíráte existující pole, pravděpodobně můžete očekávat smíšené výsledky a vyšší výskyt omezování.
Poznámka:
Neexistují žádné záruky řazení, pro kterou se akce v textu požadavku spouští jako první. Nedoporučuje se mít více akcí sloučení přidružených ke stejnému dokumentu v jednom textu požadavku. Pokud pro stejný dokument vyžaduje více akcí sloučení, před aktualizací dokumentu v indexu vyhledávání proveďte sloučení na straně klienta.
Odpovědi
Stavový kód 200 se vrátí pro úspěšnou odpověď, což znamená, že všechny položky byly uloženy trvale a začnou být indexovány. Indexování běží na pozadí a zpřístupní nové dokumenty (tj. dotazovatelné a prohledávatelné) několik sekund po dokončení operace indexování. Konkrétní zpoždění závisí na zatížení služby.
Úspěšné indexování označuje vlastnost stavu nastavená na hodnotu True pro všechny položky a statusCode vlastnost nastavenou na hodnotu 201 (pro nově nahrané dokumenty) nebo 200 (pro sloučené nebo odstraněné dokumenty):
{
"value": [
{
"key": "unique_key_of_new_document",
"status": true,
"errorMessage": null,
"statusCode": 201
},
{
"key": "unique_key_of_merged_document",
"status": true,
"errorMessage": null,
"statusCode": 200
},
{
"key": "unique_key_of_deleted_document",
"status": true,
"errorMessage": null,
"statusCode": 200
}
]
}
Stavový kód 207 se vrátí, pokud alespoň jedna položka nebyla úspěšně indexována. Položky, které nebyly indexovány, mají pole stavu nastaveno na false.
errorMessage Vlastnosti statusCode označují důvod chyby indexování:
{
"value": [
{
"key": "unique_key_of_document_1",
"status": false,
"errorMessage": "The search service is too busy to process this document. Please try again later.",
"statusCode": 503
},
{
"key": "unique_key_of_document_2",
"status": false,
"errorMessage": "Document not found.",
"statusCode": 404
},
{
"key": "unique_key_of_document_3",
"status": false,
"errorMessage": "Index is temporarily unavailable because it was updated with the 'allowIndexDowntime' flag set to 'true'. Please try again later.",
"statusCode": 422
}
]
}
Vlastnost errorMessage označuje důvod chyby indexování, pokud je to možné.
Následující tabulka vysvětluje různé stavové kódy jednotlivých dokumentů, které lze vrátit v odpovědi. Některé stavové kódy označují problémy se samotným požadavkem, zatímco jiné označují dočasné chybové stavy. Druhý pokus byste měli opakovat po zpoždění.
| Stavový kód | Význam | Opakovatelné | Poznámky |
|---|---|---|---|
| 200 | Dokument se úspěšně upravil nebo odstranil. | Není k dispozici | Operace odstranění jsou idempotentní. To znamená, že i když klíč dokumentu v indexu neexistuje, při pokusu o operaci odstranění s tímto klíčem vznikne stavový kód 200. |
| 201 | Dokument byl úspěšně vytvořen. | Není k dispozici | |
| 400 | V dokumentu došlo k chybě, která zabránila indexování. | Ne | Chybová zpráva v odpovědi označuje, co je v dokumentu špatně. |
| 404 | Dokument nelze sloučit, protože daný klíč v indexu neexistuje. | Ne | K této chybě dochází u nahrávání, protože vytvářejí nové dokumenty a nedochází k odstranění, protože jsou idempotentní. |
| 409 | Při pokusu o indexování dokumentu se zjistil konflikt verzí. | Ano | K tomu může dojít v případě, že se pokoušíte indexovat stejný dokument vícekrát současně. |
| 422 | Index je dočasně nedostupný, protože se v něm aktualizoval příznak allowIndexDowntime nastavený na hodnotu true. | Ano | |
| 429 | Příliš mnoho požadavků | Ano | Pokud se vám při indexování zobrazí tento kód chyby, obvykle to znamená, že máte málo úložiště. Když se blížíte limitům úložiště, může služba zadat stav, ve kterém nemůžete přidávat ani aktualizovat, dokud neodstraníte některé dokumenty. Další informace najdete v tématu Plánování a správa kapacity , pokud chcete více úložiště nebo uvolnit místo odstraněním dokumentů. |
| 503 | Vaše vyhledávací služba je dočasně nedostupná, pravděpodobně kvůli vysokému zatížení. | Ano | V takovém případě by váš kód měl před opakováním počkat, jinak riskujete prodloužení nedostupnosti služby. |
Pokud váš klientský kód často narazí na odpověď 207, je jedním z možných důvodů, proč je systém zatížený. Můžete to potvrdit tak, že zkontrolujete vlastnost statusCode pro 503. Pokud je stavOvý kód 503, doporučujeme požadavky indexování omezovat. Jestliže indexovací provoz neklesne, může systém začít odmítat všechny požadavky se stavovou chybou 503.
Stavový kód 429 označuje, že jste překročili kvótu počtu dokumentů na index. Musíte buď upgradovat na vyšší limity kapacity , nebo vytvořit nový index.
Poznámka:
Když do indexu nahrajete DateTimeOffset hodnoty s informacemi o časovém pásmu, Azure AI Search tyto hodnoty normalizuje do standardu UTC. Například 2024-01-13T14:03:00-08:00 je uložen jako 2024-01-13T22:03:00Z. Pokud potřebujete uložit informace o časovém pásmu, přidejte do indexu pro tento datový bod další sloupec.
Tipy pro přírůstkové indexování
Indexery automatizují přírůstkové indexování. Pokud můžete použít indexer a pokud zdroj dat podporuje sledování změn, můžete indexer spustit podle plánu opakování a přidat, aktualizovat nebo přepsat prohledávatelný obsah tak, aby se synchronizoval s vašimi externími daty.
Pokud provádíte volání indexu přímo prostřednictvím rozhraní push API, použijte
mergeOrUploadjako akci hledání.Datová část musí obsahovat klíče nebo identifikátory každého dokumentu, který chcete přidat, aktualizovat nebo odstranit.
Pokud index obsahuje vektorová pole a vlastnost nastavíte
storedna false, ujistěte se, že jste v částečné aktualizaci dokumentu zadali vektor, i když se hodnota nezmění. Vedlejším účinkem nastavenístoredna false je, že při operaci přeindexování jsou vektory odstraněny. Poskytnutí vektoru v datové části dokumentů zabrání tomu, aby k tomu došlo.Chcete-li aktualizovat obsah jednoduchých polí a dílčích polí ve složitých typech, uveďte pouze pole, která chcete změnit. Pokud například potřebujete aktualizovat pole popisu, datová část by se měla skládat z klíče dokumentu a upraveného popisu. Vynechání jiných polí zachová jejich stávající hodnoty.
Pokud chcete sloučit vložené změny do kolekce řetězců, zadejte celou hodnotu. Vzpomeňte si příklad
tagspole z předchozí části. Nové hodnoty přepíší staré hodnoty pro celé pole a nelze provádět spojování v obsahu pole.
Tady je příklad rozhraní REST API, který ukazuje tyto tipy:
### Get Stay-Kay City Hotel by ID
GET {{baseUrl}}/indexes/hotels-vector-quickstart/docs('1')?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
### Change the description, city, and tags for Stay-Kay City Hotel
POST {{baseUrl}}/indexes/hotels-vector-quickstart/docs/search.index?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"value": [
{
"@search.action": "mergeOrUpload",
"HotelId": "1",
"Description": "I'm overwriting the description for Stay-Kay City Hotel.",
"Tags": ["my old item", "my new item"],
"Address": {
"City": "Gotham City"
}
}
]
}
### Retrieve the same document, confirm the overwrites and retention of all other values
GET {{baseUrl}}/indexes/hotels-vector-quickstart/docs('1')?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
Aktualizace schématu indexu
Schéma indexu definuje fyzické datové struktury vytvořené ve vyhledávací službě, takže neexistuje mnoho změn schématu, které můžete provést bez nutnosti úplné opětovné sestavení.
Aktualizace bez opětovného sestavení
Následující seznam uvádí změny schématu, které lze bezproblémově zavést do existujícího indexu. Obecně platí, že seznam obsahuje nová pole a funkce používané při provádění dotazů.
- Přidat popis indexu (náhled)
- Umožňuje přidat nové pole.
- Nastavení atributu
retrievableu existujícího pole - Aktualizujte
searchAnalyzeru pole, které má existujícíindexAnalyzer - Přidání nové definice analyzátoru do indexu (které lze použít pro nová pole)
- Přidání, aktualizace nebo odstranění hodnoticího profilu
- Přidání, aktualizace nebo odstranění synonymMap
- Přidání, aktualizace nebo odstranění sémantických konfigurací
- Přidání, aktualizace nebo odstranění nastavení CORS
Pořadí operací je:
Získejte definici indexu.
Upravte schéma aktualizacemi z předchozího seznamu.
Aktualizujte schéma indexu ve vyhledávací službě.
Pokud jste přidali nové pole, aktualizujte obsah indexu tak, aby odpovídal upravenému schématu. U všech ostatních změn se stávající indexovaný obsah používá tak, jak je.
Když aktualizujete schéma indexu tak, aby zahrnovalo nové pole, stávající dokumenty v indexu mají pro toto pole hodnotu null. V další úloze indexování nahradí hodnoty z externích zdrojových dat hodnoty null přidané službou Azure AI Search.
Během aktualizací by nemělo dojít k přerušení dotazů, ale výsledky dotazů se budou lišit, jak se aktualizace projeví.
Aktualizace vyžadující opětovné sestavení
Některé úpravy vyžadují vyřazení a opětovné sestavení indexu a nahrazení aktuálního indexu novým indexem.
| Akce | Popis |
|---|---|
| Odstraňte pole | Pokud chcete fyzicky odebrat všechny stopy pole, musíte index znovu sestavit. Pokud okamžité opětovné sestavení není praktické, můžete upravit kód aplikace tak, aby přesměroval přístup mimo zastaralé pole, nebo použít vyhledávací pole a vybrat parametry dotazu, abyste zvolili, která pole se prohledávají a vrací. Definice a obsah pole fyzicky zůstanou v indexu až do dalšího opětovného sestavení, když použijete schéma, které dané pole vynechá. |
| Změna definice pole | Revize názvu pole, datového typu nebo konkrétních atributů indexu (prohledávatelné, filtrovatelné, řaditelné, facetable) vyžadují úplné opětovné sestavení. |
| Přiřazení analyzátoru k poli | Analyzátory jsou definovány v indexu, přiřazeny k polím a následně vyvolány během indexování, aby informovaly, jak se tokeny vytvářejí. Do indexu můžete kdykoli přidat novou definici analyzátoru, ale při vytváření pole můžete přiřadit pouze analyzátor. To platí pro vlastnosti analyzátoru i indexAnalyzeru. Vlastnost searchAnalyzer je výjimka (tuto vlastnost můžete přiřadit existujícímu poli). |
| Aktualizace nebo odstranění definice analyzátoru v indexu | Existující konfiguraci analyzátoru (analyzátor, tokenizátor, filtr tokenů nebo znakový filtr) v indexu nemůžete odstranit ani změnit, pokud znovu neskonstruujete celý index. |
| Přidat pole do navrhovače | Pokud pole již existuje a chcete ho přidat do konstruktoru Návrhy, znovu vytvořte index. |
| Aktualizujte svou službu nebo tarif. | Pokud potřebujete větší kapacitu, zkontrolujte, jestli můžete upgradovat službu nebo přejít na vyšší cenovou úroveň. Pokud ne, musíte vytvořit novou službu a znovu sestavit indexy od začátku. K automatizaci tohoto procesu můžete použít vzorový kód, který zálohuje index do řady souborů JSON. Pak můžete index vytvořit znovu ve vyhledávací službě, kterou zadáte. |
Pořadí operací je:
Získejte definici indexu pro případ, že ji potřebujete pro budoucí referenci, nebo ji použít jako základ pro novou verzi.
Zvažte použití řešení zálohování a obnovení k zachování kopie obsahu indexu. V jazyce C# a v Pythonu existují řešení. Doporučujeme verzi Pythonu, protože je aktuální.
Pokud máte ve vyhledávací službě kapacitu, ponechte stávající index při vytváření a testování nového indexu.
Odstraňte existující index. Dotazy, které cílí na index, se okamžitě zahodí. Mějte na paměti, že odstranění indexu je nevratné, odstraní fyzické úložiště pro kolekci polí a další struktury.
Publikuje revidovaný index, kde text požadavku obsahuje změněné nebo upravené definice polí a konfigurace.
Načtěte index s dokumenty z externího zdroje. Dokumenty se indexují pomocí definic polí a konfigurací nového schématu.
Při vytváření indexu je fyzické úložiště přiděleno pro každé pole ve schématu indexu s invertovaným indexem vytvořeným pro každé prohledávatelné pole a vektorový index vytvořený pro každé vektorové pole. Pole, která nelze prohledávat, je možné použít ve filtrech nebo výrazech, ale nemají invertované indexy a nejsou prohledávatelná jako fulltextová nebo přibližná. Při opětovném sestavení indexu se tyto invertované indexy a vektorové indexy odstraní a znovu vytvoří na základě zadaného schématu indexu.
Pokud chcete minimalizovat přerušení kódu aplikace, zvažte vytvoření aliasu pro index. Kód aplikace odkazuje na alias, ale můžete aktualizovat název indexu, na který alias odkazuje.
Přidejte popis indexu (náhled)
Počínaje verzí rozhraní REST API 2025-05-01-preview je nyní podporována ddescription. Tento čitelný text pro člověka je neocenitelný, když systém musí získat přístup k několika indexům a rozhodnout se na základě popisu. Vezměte v úvahu server MCP (Model Context Protocol), který musí vybrat správný index za běhu. Rozhodnutí může být založeno na popisu, nikoli na samotném názvu indexu.
Popis indexu je aktualizace schématu a můžete ji přidat, aniž byste museli znovu sestavit celý index.
- Délka textového řetězce je maximálně 4 000 znaků.
- Obsah musí být čitelný pro člověka v kódování Unicode. Váš případ použití by měl určit, který jazyk se má použít.
Podpora popisu indexu je k dispozici v rozhraní REST API verze Preview, na webu Azure Portal nebo v předběžném balíčku sady Azure SDK, který tuto funkci poskytuje.
Azure Portal podporuje nejnovější rozhraní API ve verzi Preview.
Přihlaste se k webu Azure Portal a vyhledejte vyhledávací službu.
V části správy vyhledávání>Indexy vyberte index.
Vyberte Upravit JSON.
Vložte
"description"a za ním popis. Hodnota musí být menší než 4 000 znaků a v unicode.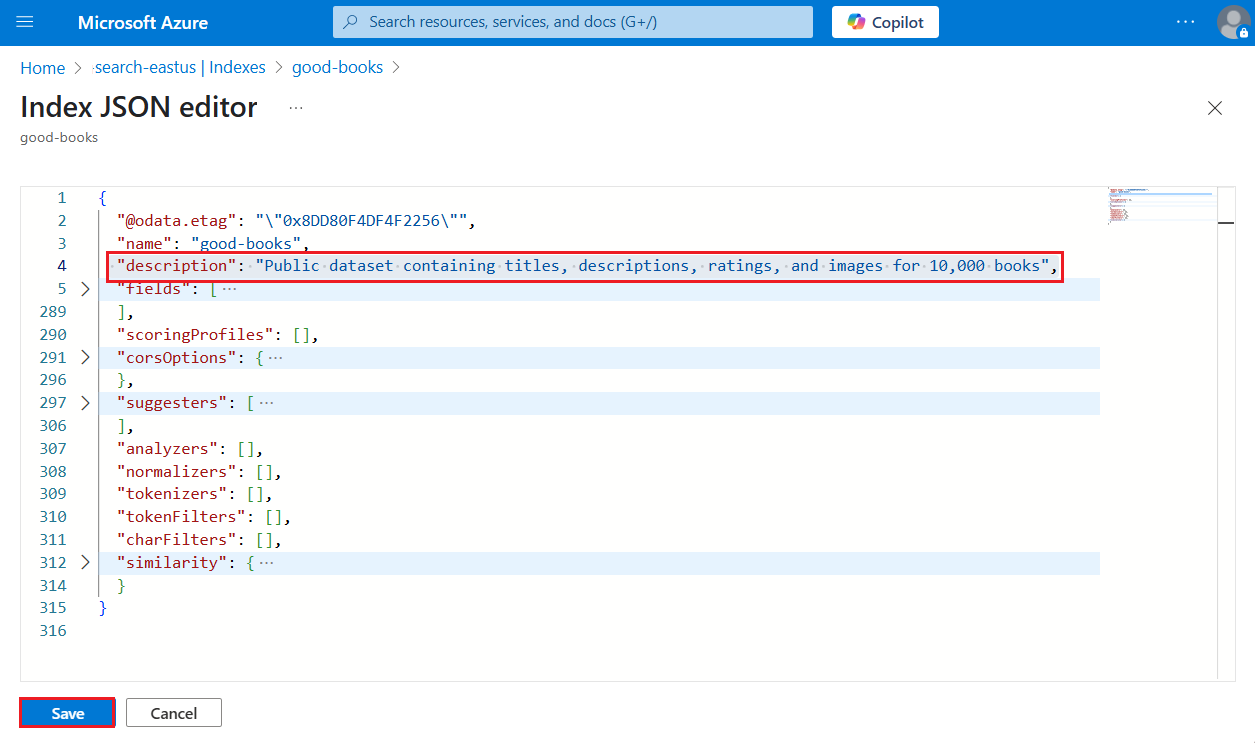
Uložte index.
Vyrovnávání zatížení
Indexování se nespustí na pozadí, ale vyhledávací služba vyrovnává všechny úlohy indexování s průběžnými dotazy. Během indexování můžete monitorovat požadavky na dotazy na webu Azure Portal, abyste zajistili, že se dotazy dokončí včas.
Pokud úlohy indexování představují nepřijatelné úrovně latence dotazů, proveďte analýzu výkonu a projděte si tyto tipy k výkonu, které vám pomůžou potenciální zmírnění rizik.
Zkontrolovat aktualizace
Jakmile se načte první dokument, můžete začít dotazovat index. Pokud znáte ID dokumentu, vrátí rozhraní REST API pro vyhledávání dokumentu konkrétní dokument. Pro širší testování byste měli počkat, až se index plně načte, a pak pomocí dotazů ověřte kontext, který očekáváte.
K vyhledání aktualizovaného obsahu můžete použít Průzkumníka služby Search nebo klienta REST.
Pokud jste pole přidali nebo přejmenovali, použijte výběr k vrácení daného pole:
"search": "*",
"select": "document-id, my-new-field, some-old-field",
"count": true
Azure Portal poskytuje velikost indexu a velikost vektorového indexu. Tyto hodnoty můžete zkontrolovat po aktualizaci indexu, ale nezapomeňte očekávat malé zpoždění, protože služba zpracovává změnu a je třeba počítat s rychlostí aktualizace portálu, což může trvat několik minut.
Odstranit sirotčí dokumenty
Azure AI Search podporuje operace na úrovni dokumentu, abyste mohli vyhledat, aktualizovat a odstranit konkrétní dokument izolovaně. Následující příklad ukazuje, jak odstranit dokument.
Odstranění dokumentu okamžitě nevybíná místo v indexu. Proces na pozadí provede fyzické odstranění každých několik minut. Bez ohledu na to, jestli k vrácení statistik indexu použijete Azure Portal nebo rozhraní API, můžete očekávat malé zpoždění před tím, než se odstranění projeví na webu Azure Portal a metrikách rozhraní API.
Určete, které pole je klíčem dokumentu. Na webu Azure Portal můžete zobrazit pole jednotlivých indexů. Klíče dokumentu jsou řetězcová pole a označují se ikonou klíče, aby se snadněji zobrazovaly.
Zkontrolujte hodnoty pole klíče dokumentu:
search=*&$select=HotelId. Jednoduchý řetězec je jednoduchý, ale pokud index používá pole s kódováním base-64 nebo pokud byly z nastavení vygeneroványparsingModevyhledávací dokumenty, můžete pracovat s hodnotami, které neznáte.Vyhledejte dokument , abyste ověřili hodnotu ID dokumentu a před odstraněním zkontrolovali jeho obsah. Zadejte klíč nebo ID dokumentu v požadavku. Následující příklady ilustrují jednoduchý řetězec pro ukázkový index Hotels a řetězec kódovaný v base-64 pro metadata_storage_path klíč indexu cog-search-demo.
GET https://[service name].search.windows.net/indexes/hotel-sample-index/docs/1111?api-version=2024-07-01GET https://[service name].search.windows.net/indexes/cog-search-demo/docs/aHR0cHM6Ly9oZWlkaWJsb2JzdG9yYWdlMi5ibG9iLmNvcmUud2luZG93cy5uZXQvY29nLXNlYXJjaC1kZW1vL2d1dGhyaWUuanBn0?api-version=2024-07-01Odstraňte dokument pomocí odstranění
@search.actiona odeberte ho z indexu vyhledávání.POST https://[service name].search.windows.net/indexes/hotels-sample-index/docs/index?api-version=2024-07-01 Content-Type: application/json api-key: [admin key] { "value": [ { "@search.action": "delete", "id": "1111" } ] }