Popis clusteru Service Fabric pomocí Správce prostředků clusteru
Funkce Správce prostředků clusteru v Azure Service Fabric poskytuje několik mechanismů pro popis clusteru:
- Domény selhání
- Upgrade domén
- Vlastnosti uzlu
- Kapacity uzlů
Během běhu používá Správce prostředků clusteru tyto informace k zajištění vysoké dostupnosti služeb spuštěných v clusteru. Při vynucování těchto důležitých pravidel se také snaží optimalizovat spotřebu prostředků v rámci clusteru.
Domény selhání
Doména selhání je libovolná oblast koordinovaného selhání. Jeden počítač je doména selhání. Může selhat samostatně z různých důvodů, od selhání napájení až po selhání jednotky až po chybný firmware síťové karty.
Počítače připojené ke stejnému ethernetovému přepínači jsou ve stejné doméně selhání. To jsou počítače, které sdílejí jeden zdroj napájení nebo v jednom umístění.
Vzhledem k tomu, že je přirozené, že se hardwarové chyby překrývají, domény selhání jsou ze své podstaty hierarchické. V Service Fabric jsou reprezentované jako identifikátory URI.
Je důležité, aby domény selhání byly správně nastavené, protože Service Fabric tyto informace používá k bezpečnému umístění služeb. Service Fabric nechce umístit služby tak, aby ztráta domény selhání (způsobená selháním některé komponenty) způsobila, že služba přejde dolů.
Service Fabric v prostředí Azure používá informace o doméně selhání poskytované prostředím k správné konfiguraci uzlů v clusteru vaším jménem. U samostatných instancí Service Fabric se domény selhání definují v době, kdy je cluster nastavený.
Upozorňující
Je důležité, aby informace o doméně selhání poskytované Service Fabric byly přesné. Řekněme například, že uzly clusteru Service Fabric běží uvnitř 10 virtuálních počítačů běžících na 5 fyzických hostitelích. V tomto případě, i když existuje 10 virtuálních počítačů, existují pouze 5 různých domén selhání (nejvyšší úrovně). Sdílení stejného fyzického hostitele způsobí, že virtuální počítače sdílejí stejnou kořenovou doménu selhání, protože virtuální počítače mají v případě selhání fyzického hostitele koordinované selhání.
Service Fabric očekává, že doména selhání uzlu se nezmění. Jiné mechanismy zajištění vysoké dostupnosti virtuálních počítačů, jako jsou například virtuální počítače s vysokou dostupností, můžou způsobit konflikty se Service Fabric. Tyto mechanismy používají transparentní migraci virtuálních počítačů z jednoho hostitele do druhého. Nepřekonfigurují ani neoznamují spuštěný kód uvnitř virtuálního počítače. Proto se nepodporují jako prostředí pro spouštění clusterů Service Fabric.
Service Fabric by měla být jediná technologie s vysokou dostupností, která se používá. Mechanismy, jako je migrace virtuálních počítačů za provozu a sítě SAN, nejsou nezbytné. Pokud se tyto mechanismy používají ve spojení s Service Fabric, snižují dostupnost a spolehlivost aplikací. Důvodem je, že přinášejí další složitost, přidávají centralizované zdroje selhání a používají strategie spolehlivosti a dostupnosti, které jsou v konfliktu s těmi ve službě Service Fabric.
V následujícím obrázku obarvíme všechny entity, které přispívají k doménám selhání, a zobrazíme seznam všech různých domén selhání, které vedou. V tomto příkladu máme datacentra (DC), racky (R) a okna (B). Pokud každé okno obsahuje více než jeden virtuální počítač, může v hierarchii domény selhání existovat jiná vrstva.
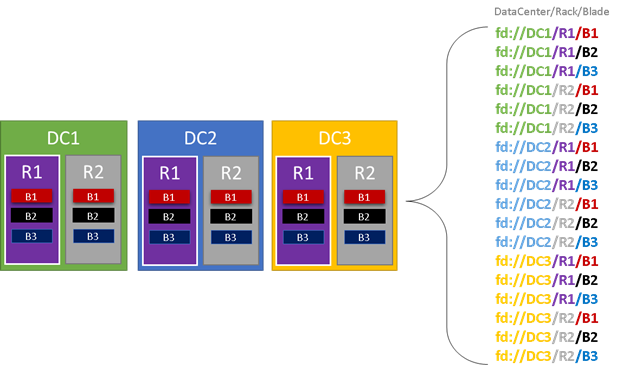
Během běhu považuje Resource Manager clusteru Service Fabric domény selhání v rozloženích clusteru a plánů. Stavové repliky nebo bezstavové instance služby se distribuují, takže jsou v samostatných doménách selhání. Distribuce služby napříč doménami selhání zajišťuje, že dostupnost služby nebude ohrožena, když doména selhání selže na jakékoli úrovni hierarchie.
Správce prostředků clusteru nezajímá, kolik vrstev je v hierarchii domény selhání. Snaží se zajistit, aby ztráta jakékoli části hierarchie neměla vliv na služby spuštěné v této hierarchii.
Nejlepší je, když je stejný počet uzlů na jednotlivých úrovních hierarchie domén selhání. Pokud je strom domén selhání v clusteru nevyvážený, je pro Cluster Resource Manager obtížnější zjistit nejlepší přidělení služeb. Nevyvážené rozložení domény selhání znamenají, že ztráta některých domén ovlivňuje dostupnost služeb více než jiných domén. V důsledku toho je Resource Manager clusteru roztrhaný mezi dvěma cíli:
- Chce používat počítače v této "těžké" doméně tím, že na ně umístí služby.
- Chce umístit služby do jiných domén, aby ztráta domény nezpůsobí problémy.
Jak nevyrovnaná doména vypadá? Následující diagram znázorňuje dvě různá rozložení clusteru. V prvním příkladu se uzly distribuují rovnoměrně napříč doménami selhání. V druhém příkladu má jedna doména selhání mnohem více uzlů než ostatní domény selhání.
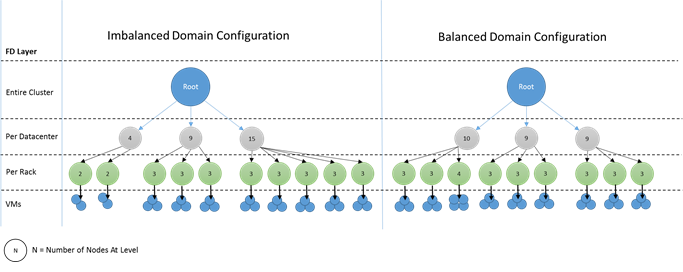
V Azure se pro vás spravuje volba, která doména selhání obsahuje uzel. V závislosti na počtu uzlů, které zřídíte, ale stále můžete skončit s doménami selhání, které mají v nich více uzlů než v jiných uzlech.
Řekněme například, že máte v clusteru pět domén selhání, ale pro typ uzlu (NodeType) zřídíte sedm uzlů. V tomto případě první dvě domény selhání skončí s více uzly. Pokud i nadále nasazujete více instancí NodeType pouze s několika instancemi, problém se zhorší. Z tohoto důvodu doporučujeme, aby počet uzlů v každém typu uzlu byl násobkem počtu domén selhání.
Upgrade domén
Domény upgradu jsou další funkcí, která pomáhá Service Fabric Cluster Resource Manageru pochopit rozložení clusteru. Upgradovací domény definují sady uzlů, které se upgradují současně. Domény upgradu pomáhají Cluster Resource Manageru pochopit a orchestrovat operace správy, jako jsou upgrady.
Upgradovací domény jsou hodně podobné doménám selhání, ale s několika klíčovými rozdíly. Za prvé, oblasti koordinovaných selhání hardwaru definují domény selhání. Domény upgradu jsou naopak definovány zásadami. Místo toho, abyste nechali prostředí diktovat číslo, se můžete rozhodnout, kolik chcete. Můžete mít tolik upgradových domén, kolik děláte v uzlech. Dalším rozdílem mezi doménami selhání a upgradovými doménami je, že upgradující domény nejsou hierarchické. Místo toho se jedná spíše o jednoduchou značku.
Následující diagram znázorňuje tři domény upgradu prokládání napříč třemi doménami selhání. Zobrazuje také jedno možné umístění pro tři různé repliky stavové služby, kde každá končí v různých doménách selhání a upgradu. Toto umístění umožňuje ztrátu domény selhání uprostřed upgradu služby a stále má jednu kopii kódu a dat.
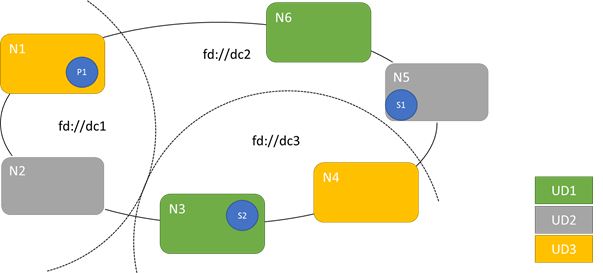
Existují výhody a nevýhody, které mají velký počet upgradovaných domén. Více upgradovaných domén znamená, že každý krok upgradu je podrobnější a ovlivňuje menší počet uzlů nebo služeb. Méně služeb se musí přesunout najednou, protože do systému zavádí méně změn. To má tendenci ke zvýšení spolehlivosti, protože méně služby je ovlivněno jakýmkoli problémem zavedeným během upgradu. Další upgradovací domény také znamenají, že k řešení dopadu upgradu potřebujete méně dostupnou vyrovnávací paměť na jiných uzlech.
Pokud máte například pět upgradovaných domén, uzly v každé z nich zpracovávají přibližně 20 procent provozu. Pokud potřebujete tuto upgradovací doménu pro upgrade snížit, zatížení obvykle musí jít někam. Vzhledem k tomu, že máte čtyři zbývající domény upgradu, musí mít každý prostor přibližně pro 25 procent celkového provozu. Větší upgradovací domény znamenají, že na uzlech v clusteru potřebujete méně vyrovnávací paměti.
Zvažte, jestli místo toho máte 10 upgradových domén. V takovém případě by každá doména upgradu zpracovávala pouze přibližně 10 procent celkového provozu. Při postupu upgradu clusteru by každá doména musela mít místo jenom pro přibližně 11 procent celkového provozu. Větší upgradování domén obecně umožňuje spouštět uzly s vyšším využitím, protože potřebujete méně rezervované kapacity. Totéž platí pro domény selhání.
Nevýhodou mnoha upgradovaných domén je, že upgrady obvykle trvá déle. Service Fabric po dokončení upgradu domény počká na krátkou dobu a provede kontroly před zahájením upgradu další domény. Tato zpoždění umožňují zjišťovat problémy zavedené upgradem před zahájením upgradu. Kompromis je přijatelný, protože zabraňuje špatným změnám v ovlivnění příliš velké části služby najednou.
Přítomnost příliš málo upgradovaných domén má mnoho negativních vedlejších účinků. Zatímco každá upgradovaná doména je mimo provoz a upgraduje se, není k dispozici velká část celkové kapacity. Pokud máte například jenom tři upgradované domény, odebíráte najednou asi třetinu celkové služby nebo kapacity clusteru. Pokud máte tolik služeb najednou, není žádoucí, protože potřebujete dostatečnou kapacitu ve zbytku clusteru pro zvládnutí úlohy. Zachování této vyrovnávací paměti znamená, že během normálního provozu jsou tyto uzly méně načtené, než by jinak. Tím se zvýší náklady na provoz vaší služby.
Celkový počet domén selhání nebo upgradu v prostředí nebo omezení jejich překrytí neexistuje žádný skutečný limit. Existují ale běžné vzory:
- Domény selhání a upgradované domény mapované 1:1
- Jedna upgradovací doména na uzel (fyzická nebo virtuální instance operačního systému)
- Model "prokládání" nebo "matice", kde domény selhání a upgradované domény tvoří matici s počítači, které obvykle běží dolů diagonály
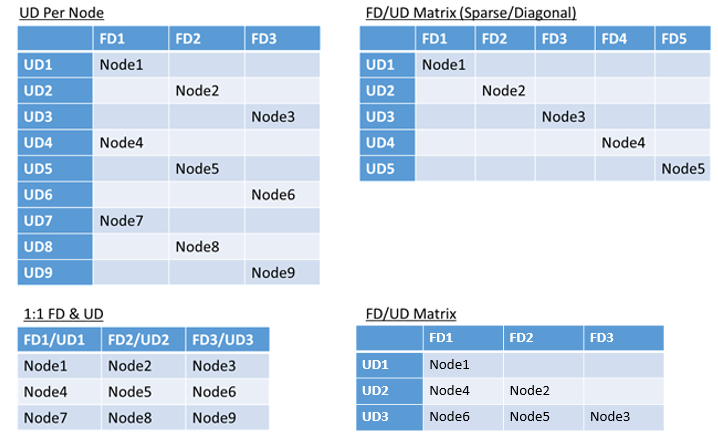
Neexistuje žádná nejlepší odpověď, pro které rozložení zvolit. Každý má výhody a nevýhody. Například model 1FD:1UD je jednoduchý k nastavení. Model jedné domény upgradu na model uzlu je nejvíce podobný tomu, k čemu se lidé používají. Během upgradů se každý uzel aktualizuje nezávisle. To se podobá tomu, jak se malé sady počítačů upgradovaly ručně v minulosti.
Nejběžnějším modelem je matice FD/UD, kde domény selhání a upgradovací domény tvoří tabulku a uzly, které začínají diagonálně. Jedná se o model, který se ve výchozím nastavení používá v clusterech Service Fabric v Azure. U clusterů s mnoha uzly všechno nakonec vypadá jako hustý maticový vzor.
Poznámka:
Clustery Service Fabric hostované v Azure nepodporují změnu výchozí strategie. Toto přizpůsobení nabízejí pouze samostatné clustery.
Omezení domény selhání a upgrade a výsledné chování
Výchozí přístup
Resource Manager clusteru ve výchozím nastavení udržuje služby vyvážené napříč doménami selhání a upgradu. Modeluje se jako omezení. Omezení domén selhání a upgradu uvádí: "Pro daný oddíl služby by nikdy neměl existovat rozdíl větší než jeden v počtu objektů služby (bezstavových instancí služby nebo replik stavových služeb) mezi všemi dvěma doménami na stejné úrovni hierarchie."
Řekněme, že toto omezení poskytuje záruku maximálního rozdílu. Omezení pro domény selhání a upgradu brání určitým přesunům nebo ujednáním, které porušují pravidlo.
Řekněme například, že máme cluster se šesti uzly, který je nakonfigurovaný s pěti doménami selhání a pěti upgradovými doménami.
| FD0 | FD1 | FD2 | FD3 | FD4 | |
|---|---|---|---|---|---|
| UD0 | N1 | ||||
| UD1 | N6 | N2 | |||
| UD2 | N3 | ||||
| UD3 | N4 | ||||
| UD4 | N5 |
Nyní řekněme, že vytvoříme službu s TargetReplicaSetSize (nebo pro bezstavovou službu, InstanceCount) hodnotu pět. Repliky přistanou na N1-N5. N6 se ve skutečnosti nikdy nepoužívá bez ohledu na to, kolik služeb, které vytvoříte. Ale proč? Pojďme se podívat na rozdíl mezi aktuálním rozložením a tím, co by se stalo, když zvolíme N6.
Tady je rozložení, které jsme získali, a celkový počet replik na selhání a doménu upgradu:
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | R1 | 0 | ||||
| UD1 | R2 | 0 | ||||
| UD2 | R3 | 0 | ||||
| UD3 | R4 | 0 | ||||
| UD4 | R5 | 0 | ||||
| FDTotal | 1 | 1 | 1 | 1 | 1 | - |
Toto rozložení je vyváženo z hlediska uzlů na doménu selhání a upgradované domény. Je také vyvážená z hlediska počtu replik na selhání a domény upgradu. Každá doména má stejný počet uzlů a stejný počet replik.
Teď se podíváme na to, co by se stalo, kdybysme místo N2 použili N6. Jak se pak repliky distribuují?
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | R1 | 0 | ||||
| UD1 | R5 | 0 | ||||
| UD2 | R2 | 0 | ||||
| UD3 | R3 | 0 | ||||
| UD4 | R4 | 0 | ||||
| FDTotal | 2 | 0 | 1 | 1 | 1 | - |
Toto rozložení porušuje definici záruky maximálního rozdílu pro omezení domény selhání. FD0 má dvě repliky, zatímco FD1 má nulu. Rozdíl mezi FD0 a FD1 je celkem dva, což je větší než maximální rozdíl jednoho. Vzhledem k tomu, že omezení je porušeno, Správce prostředků clusteru toto uspořádání neumožňuje.
Podobně pokud jsme vybrali N2 a N6 (místo N1 a N2), získáme:
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | 0 | |||||
| UD1 | R5 | R1 | 2 | |||
| UD2 | R2 | 0 | ||||
| UD3 | R3 | 0 | ||||
| UD4 | R4 | 0 | ||||
| FDTotal | 1 | 1 | 1 | 1 | 1 | - |
Toto rozložení je vyváženo z hlediska domén selhání. Teď ale porušuje omezení domény upgradu, protože UD0 má nulové repliky a UD1 má dvě. Toto rozložení je také neplatné a Správce prostředků clusteru ho nevybíral.
Tento přístup k distribuci stavových replik nebo bezstavových instancí poskytuje nejlepší možnou odolnost proti chybám. Pokud dojde k výpadku jedné domény, dojde ke ztrátě minimálního počtu replik nebo instancí.
Na druhou stranu může být tento přístup příliš striktní a neumožňuje clusteru využívat všechny prostředky. U určitých konfigurací clusteru se některé uzly nedají použít. To může způsobit, že Service Fabric neumisťuje vaše služby, což vede k upozorněním. V předchozím příkladu se některé uzly clusteru nedají použít (v příkladu N6). I když jste do tohoto clusteru přidali uzly (N7-N10), repliky a instance se umístí pouze do N1–N5 kvůli omezením na domény selhání a upgradu.
| FD0 | FD1 | FD2 | FD3 | FD4 | |
|---|---|---|---|---|---|
| UD0 | N1 | N10 | |||
| UD1 | N6 | N2 | |||
| UD2 | N7 | N3 | |||
| UD3 | N8 | N4 | |||
| UD4 | N9 | N5 |
Alternativní přístup
Resource Manager clusteru podporuje jinou verzi omezení pro domény selhání a upgradu. Umožňuje umístění a zároveň zaručuje minimální úroveň bezpečnosti. Alternativní omezení může být uvedeno takto: "U daného oddílu služby by distribuce repliky mezi domény měla zajistit, aby nedošlo ke ztrátě kvora oddílu.". Řekněme, že toto omezení poskytuje záruku bezpečného kvora.
Poznámka:
U stavové služby definujeme ztrátu kvora v situaci, kdy je většina replik oddílů ve stejnou dobu v provozu. Pokud je například TargetReplicaSetSize pět, sada tří replik představuje kvorum. Podobně platí, že pokud je TargetReplicaSetSize šest, jsou pro kvorum nezbytné čtyři repliky. V obou případech může být současně méně než dvě repliky, pokud oddíl chce pokračovat v normálním fungování.
Pro bezstavovou službu neexistuje žádná taková věc, jako je ztráta kvora. Bezstavové služby nadále fungují normálně i v případě, že většina instancí ve stejnou dobu nefunguje. Ve zbytku tohoto článku se tedy zaměříme na stavové služby.
Vraťme se k předchozímu příkladu. U verze omezení bezpečné kvora budou všechna tři rozložení platná. I když FD0 ve druhém rozložení selhalo nebo UD1 ve třetím rozložení selhalo, oddíl by stále měl kvorum. (Většina replik bude stále vzhůru.) U této verze omezení je možné používat N6 téměř vždy.
Přístup "bezpečné kvorum" poskytuje větší flexibilitu než přístup "maximální rozdíl". Důvodem je jednodušší najít distribuce replik, které jsou platné téměř v jakékoli topologii clusteru. Tento přístup ale nemůže zaručit nejlepší charakteristiky odolnosti proti chybám, protože některé chyby jsou horší než jiné.
V nejhorším případě může dojít ke ztrátě většiny replik s chybou jedné domény a jedné další repliky. Například místo tří selhání, která se vyžadují ke ztrátě kvora s pěti replikami nebo instancemi, teď můžete přijít o většinu s pouhými dvěma selháními.
Adaptivní přístup
Vzhledem k tomu, že oba přístupy mají silné a slabé stránky, zavedli jsme adaptivní přístup, který kombinuje tyto dvě strategie.
Poznámka:
Toto je výchozí chování počínaje Service Fabric verze 6.2.
Adaptivní přístup ve výchozím nastavení používá logiku "maximálního rozdílu" a přepne na logiku "kvora bezpečný" pouze v případě potřeby. Správce prostředků clusteru automaticky zjistí, jakou strategii je potřeba, a to tak, že se podíváte na konfiguraci clusteru a služeb.
Cluster Resource Manager by měl pro službu použít logiku založenou na kvoru pro obě tyto podmínky:
- TargetReplicaSetSize pro službu je rovnoměrně dělitelný podle počtu domén selhání a počtu upgradovaných domén.
- Počet uzlů je menší nebo roven počtu domén selhání vynásobeným počtem upgradovaných domén.
Mějte na paměti, že Resource Manager clusteru použije tento přístup pro bezstavové i stavové služby, i když ztráta kvora není relevantní pro bezstavové služby.
Vraťme se k předchozímu příkladu a předpokládejme, že cluster teď má osm uzlů. Cluster je stále nakonfigurovaný s pěti doménami selhání a pěti upgradovými doménami a hodnotou TargetReplicaSetSize služby hostované v daném clusteru zůstává pět.
| FD0 | FD1 | FD2 | FD3 | FD4 | |
|---|---|---|---|---|---|
| UD0 | N1 | ||||
| UD1 | N6 | N2 | |||
| UD2 | N7 | N3 | |||
| UD3 | N8 | N4 | |||
| UD4 | N5 |
Vzhledem k tomu, že jsou splněny všechny nezbytné podmínky, Použije Správce prostředků clusteru při distribuci služby logiku založenou na kvoru. To umožňuje použití N6-N8. Jedna možná distribuce služby v tomto případě může vypadat takto:
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | R1 | 0 | ||||
| UD1 | R2 | 0 | ||||
| UD2 | R3 | R4 | 2 | |||
| UD3 | 0 | |||||
| UD4 | R5 | 0 | ||||
| FDTotal | 2 | 0 | 1 | 0 | 1 | - |
Pokud je hodnota TargetReplicaSetSize vaší služby snížena na čtyři (například), Správce prostředků clusteru si všimne této změny. Bude pokračovat v používání logiky maximálního rozdílu, protože TargetReplicaSetSize už není možné vydělit počtem domén selhání a upgradovacími doménami. V důsledku toho dojde k určitým přesunům replik, které distribuují zbývající čtyři repliky na uzlech N1-N5. Tímto způsobem není porušena verze "maximálního rozdílu" domény selhání a logiky upgradu domény.
Pokud je v předchozím rozložení hodnota TargetReplicaSetSize pět a N1 se odebere z clusteru, počet upgradovaných domén se rovná čtyřech. Znovu platí, že Cluster Resource Manager začne používat logiku maximálního rozdílu, protože počet upgradovaných domén už nedělí rovnoměrně hodnotu TargetReplicaSetSize služby. V důsledku toho musí replika R1 při opětovném sestavení přistát na N4, aby nedošlo k porušení omezení chyby a domény upgradu.
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | – | – | – | – | – | N/A |
| UD1 | R2 | 0 | ||||
| UD2 | R3 | R4 | 2 | |||
| UD3 | R1 | 0 | ||||
| UD4 | R5 | 0 | ||||
| FDTotal | 1 | 1 | 1 | 1 | 1 | - |
Konfigurace domén selhání a upgradu
V nasazeních Service Fabric hostovaných v Azure se domény selhání a upgradované domény definují automaticky. Service Fabric převezme a použije informace o prostředí z Azure.
Pokud vytváříte vlastní cluster (nebo chcete spustit konkrétní topologii při vývoji), můžete zadat doménu selhání a upgradovat informace o doméně sami. V tomto příkladu definujeme místní vývojový cluster s devíti uzly, který zahrnuje tři datová centra (každý se třemi racky). Tento cluster má také tři domény upgradu, které jsou v těchto třech datových centrech odděleny. Tady je příklad konfigurace v ClusterManifest.xml:
<Infrastructure>
<!-- IsScaleMin indicates that this cluster runs on one box/one single server -->
<WindowsServer IsScaleMin="true">
<NodeList>
<Node NodeName="Node01" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType01" FaultDomain="fd:/DC01/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node02" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType02" FaultDomain="fd:/DC01/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node03" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType03" FaultDomain="fd:/DC01/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
<Node NodeName="Node04" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType04" FaultDomain="fd:/DC02/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node05" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType05" FaultDomain="fd:/DC02/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node06" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType06" FaultDomain="fd:/DC02/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
<Node NodeName="Node07" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType07" FaultDomain="fd:/DC03/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node08" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType08" FaultDomain="fd:/DC03/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node09" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType09" FaultDomain="fd:/DC03/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
</NodeList>
</WindowsServer>
</Infrastructure>
Tento příklad používá clusterConfig.json pro samostatná nasazení:
"nodes": [
{
"nodeName": "vm1",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm2",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm3",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD3"
},
{
"nodeName": "vm4",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm5",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm6",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD3"
},
{
"nodeName": "vm7",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm8",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm9",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD3"
}
],
Poznámka:
Když definujete clustery prostřednictvím Azure Resource Manageru, Azure přiřazuje domény selhání a upgraduje domény. Definice typů uzlů a škálovacích sad virtuálních počítačů v šabloně Azure Resource Manageru proto neobsahuje informace o doméně selhání ani upgradu domény.
Vlastnosti uzlu a omezení umístění
Někdy (ve většině případů) budete chtít zajistit, aby určité úlohy běžely jenom na určitých typech uzlů v clusteru. Některé úlohy můžou například vyžadovat gpu nebo disky SSD a jiné nemusí.
Skvělým příkladem cílení hardwaru na konkrétní úlohy je téměř každá n-úrovňová architektura. Některé počítače slouží jako front-end nebo strana aplikace obsluhující rozhraní API a jsou vystaveny klientům nebo internetu. Různé počítače, často s různými hardwarovými prostředky, zpracovávají práci výpočetních nebo úložných vrstev. Obvykle nejsou přímo vystaveny klientům nebo internetu.
Service Fabric očekává, že v některých případech se konkrétní úlohy budou muset spouštět na konkrétních konfiguracích hardwaru. Příklad:
- Existující n-vrstvá aplikace se "zvedla a přesunula" do prostředí Service Fabric.
- Kvůli výkonu, škálování nebo izolaci zabezpečení musí být úloha spuštěná na konkrétním hardwaru.
- Úloha by měla být izolovaná od jiných úloh z důvodů zásad nebo spotřeby prostředků.
Pro podporu těchto typů konfigurací obsahuje Service Fabric značky, které můžete použít na uzly. Tyto značky se nazývají vlastnosti uzlu. Omezení umístění jsou příkazy připojené k jednotlivým službám, které vyberete pro jednu nebo více vlastností uzlu. Omezení umístění definují, kde se mají služby spouštět. Sada omezení je rozšiřitelná. Může fungovat libovolný pár klíč/hodnota.
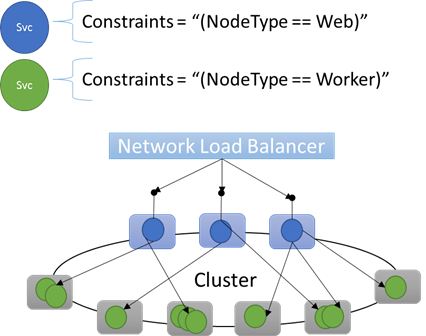
Předdefinované vlastnosti uzlu
Service Fabric definuje některé výchozí vlastnosti uzlu, které se dají použít automaticky, takže je nemusíte definovat. Výchozí vlastnosti definované v každém uzlu jsou NodeType a NodeName.
Můžete například napsat omezení umístění jako "(NodeType == NodeType03)". NodeType je běžně používaná vlastnost. Je užitečné, protože odpovídá 1:1 typu počítače. Každý typ počítače odpovídá typu úlohy v tradiční n-vrstvé aplikaci.
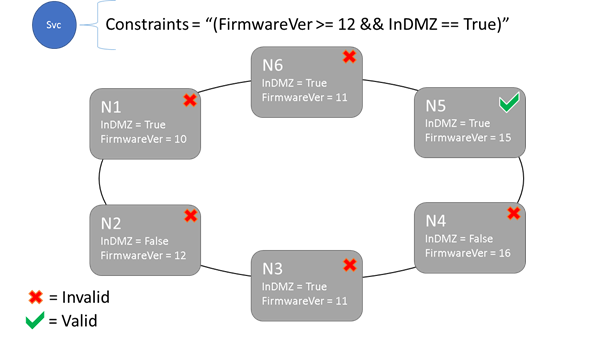
Omezení umístění a syntaxe vlastností uzlu
Hodnota zadaná ve vlastnosti uzlu může být řetězec, logická hodnota nebo podepsaná dlouhá. Příkaz ve službě se nazývá omezení umístění, protože omezuje, kde může služba běžet v clusteru. Omezení může být libovolný logický příkaz, který pracuje s vlastnostmi uzlu v clusteru. Platné selektory v těchto logických příkazech jsou:
Podmíněné kontroly vytváření konkrétních příkazů:
Příkaz Syntaxe "rovná se" "==" "není rovno" "!=" "větší než" ">" "větší než nebo rovno" ">=" "menší než" "<" "menší než nebo rovno" "<=" Logické příkazy pro seskupení a logické operace:
Příkaz Syntaxe "a" "&&" "nebo" "||" "not" "!" "group as single statement" "()"
Tady je několik příkladů základních příkazů omezení:
"Value >= 5""NodeColor != green""((OneProperty < 100) || ((AnotherProperty == false) && (OneProperty >= 100)))"
Pouze uzly, ve kterých se příkaz omezení celkového umístění vyhodnotí jako True, může mít službu umístěnou na ní. Uzly, které nemají definovanou vlastnost, neodpovídají žádnému omezení umístění, které obsahuje vlastnost.
Řekněme, že následující vlastnosti uzlu byly definovány pro typ uzlu v ClusterManifest.xml:
<NodeType Name="NodeType01">
<PlacementProperties>
<Property Name="HasSSD" Value="true"/>
<Property Name="NodeColor" Value="green"/>
<Property Name="SomeProperty" Value="5"/>
</PlacementProperties>
</NodeType>
Následující příklad ukazuje vlastnosti uzlu definované prostřednictvím ClusterConfig.json pro samostatná nasazení nebo Template.json pro clustery hostované v Azure.
Poznámka:
V šabloně Azure Resource Manageru se typ uzlu obvykle parametrizuje. Vypadalo by to spíše než "[parameters('vmNodeType1Name')]" NodeType01.
"nodeTypes": [
{
"name": "NodeType01",
"placementProperties": {
"HasSSD": "true",
"NodeColor": "green",
"SomeProperty": "5"
},
}
],
Omezení umístění služby pro službu můžete vytvořit následujícím způsobem:
FabricClient fabricClient = new FabricClient();
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
serviceDescription.PlacementConstraints = "(HasSSD == true && SomeProperty >= 4)";
// Add other required ServiceDescription fields
//...
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceType -Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton -PlacementConstraint "HasSSD == true && SomeProperty >= 4"
Pokud jsou všechny uzly NodeType01 platné, můžete také vybrat tento typ uzlu s omezením "(NodeType == NodeType01)".
Omezení umístění služby je možné dynamicky aktualizovat během běhu. Pokud potřebujete, můžete službu přesunout v clusteru, přidat a odebrat požadavky atd. Service Fabric zajišťuje, aby služba zůstala v provozu i v případě, že jsou tyto typy změn provedeny.
StatefulServiceUpdateDescription updateDescription = new StatefulServiceUpdateDescription();
updateDescription.PlacementConstraints = "NodeType == NodeType01";
await fabricClient.ServiceManager.UpdateServiceAsync(new Uri("fabric:/app/service"), updateDescription);
Update-ServiceFabricService -Stateful -ServiceName $serviceName -PlacementConstraints "NodeType == NodeType01"
Omezení umístění jsou určena pro každou pojmenovanou instanci služby. Aktualizace vždy místo (přepsání) toho, co bylo dříve zadáno.
Definice clusteru definuje vlastnosti v uzlu. Změna vlastností uzlu vyžaduje upgrade na konfiguraci clusteru. Upgrade vlastností uzlu vyžaduje, aby se každý ovlivněný uzel restartoval, aby se nahlásily nové vlastnosti. Service Fabric spravuje tyto postupné upgrady.
Popis a správa prostředků clusteru
Jednou z nejdůležitějších úloh jakéhokoli orchestrátoru je pomoct se správou spotřeby prostředků v clusteru. Správa prostředků clusteru může znamenat několik různých věcí.
Nejprve je zajištěno, že počítače nejsou přetížené. To znamená, že počítače nepoužívají více služeb, než dokážou zpracovat.
Za druhé existuje vyrovnávání a optimalizace, které jsou důležité pro efektivní spouštění služeb. Nákladově efektivní nabídky služeb nebo nabídky služeb citlivé na výkon neumožňují, aby některé uzly byly horké, zatímco jiné jsou studené. Horké uzly vedou ke kolizím prostředků a nízkému výkonu. Studené uzly představují plýtvání zdroji a zvýšené náklady.
Service Fabric představuje prostředky jako metriky. Metriky jsou všechny logické nebo fyzické prostředky, které chcete popsat službě Service Fabric. Příklady metrik jsou WorkQueueDepth nebo MemoryInMb. Informace o fyzických prostředcích, které může Service Fabric řídit na uzlech, najdete v tématu Zásady správného řízení prostředků. Informace o výchozích metrikách používaných Správcem prostředků clusteru a o tom, jak nakonfigurovat vlastní metriky, najdete v tomto článku.
Metriky se liší od omezení umístění a vlastností uzlu. Vlastnosti uzlu jsou statické popisovače samotných uzlů. Metriky popisují prostředky, které uzly mají a které služby spotřebovávají při jejich spuštění na uzlu. Vlastnost uzlu může být HasSSD a může být nastavená na true nebo false. Velikost místa dostupného na daném disku SSD a kolik spotřebovávají služby, by byla metrika jako DriveSpaceInMb.
Stejně jako u omezení umístění a vlastností uzlu Service Fabric Resource Manager nerozumí názvům metrik. Názvy metrik jsou jen řetězce. Je vhodné deklarovat jednotky jako součást názvů metrik, které vytvoříte, když mohou být nejednoznačné.
Kapacita
Pokud jste vypnuli veškeré vyrovnávání prostředků, Service Fabric Cluster Resource Manager stále zajistí, že žádný uzel nepřejde přes jeho kapacitu. Správa přetečení kapacity je možná, pokud není cluster příliš plný nebo úloha je větší než jakýkoli uzel. Kapacita je dalším omezením , které Správce prostředků clusteru používá k pochopení toho, kolik prostředků uzel má. Zbývající kapacita se také sleduje pro cluster jako celek.
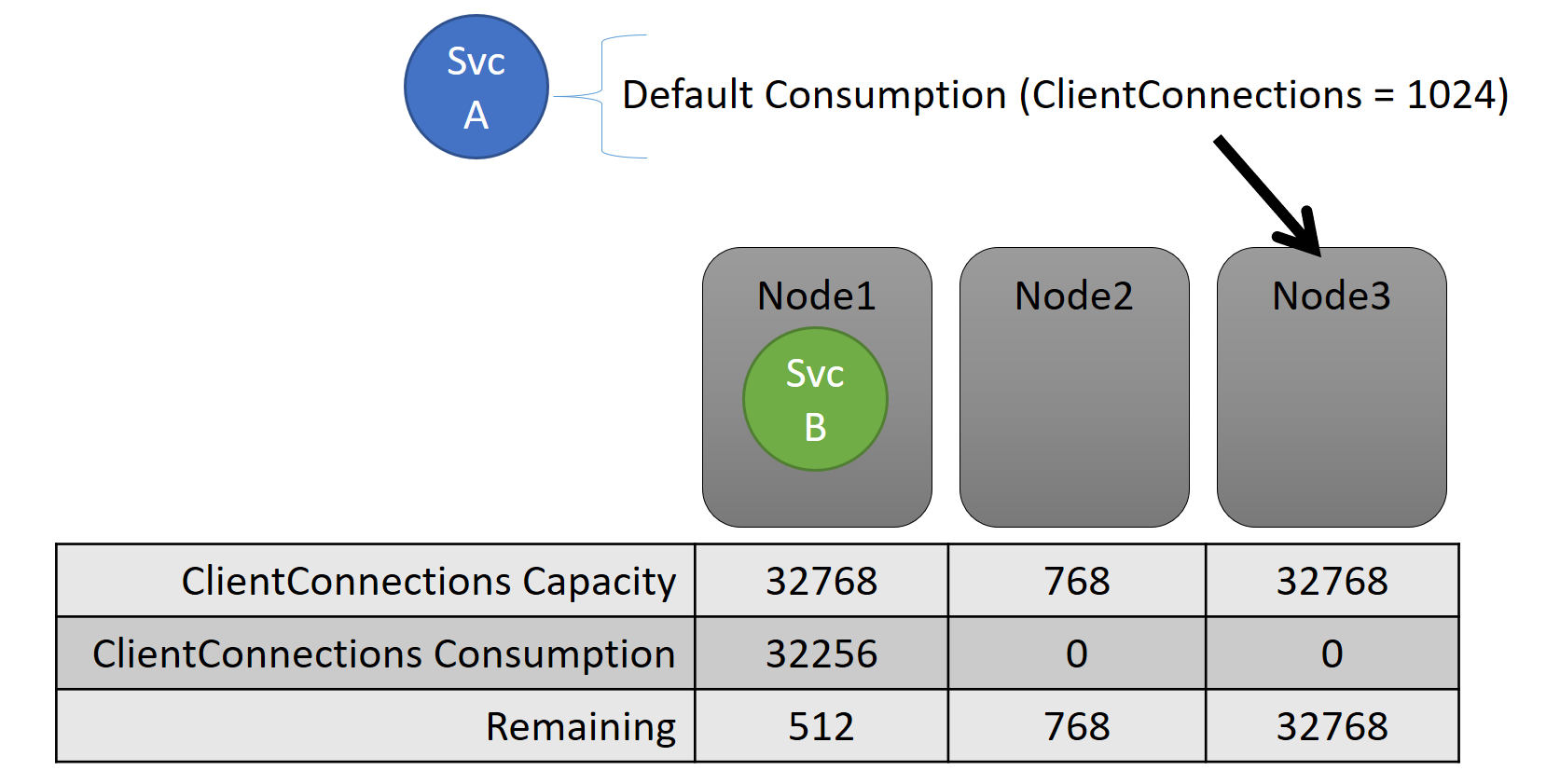
Kapacita i spotřeba na úrovni služby se vyjadřují z hlediska metrik. Metrika může být například "Client Připojení ions" (Klient Připojení ions) a uzel může mít kapacitu pro "Client Připojení ions" (Klient Připojení ions) 32 768. Jiné uzly můžou mít jiné limity. Služba spuštěná na daném uzlu může říct, že aktuálně spotřebovává 32 256 metriky "Klient Připojení ions".
Během běhu správce prostředků clusteru sleduje zbývající kapacitu v clusteru a na uzlech. Pokud chcete sledovat kapacitu, Odečte Resource Manager využití jednotlivých služeb od kapacity uzlu, ve které je služba spuštěná. Pomocí těchto informací může Správce prostředků clusteru zjistit, kam umístit nebo přesunout repliky, aby uzly nepřešly přes kapacitu.
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
ServiceLoadMetricDescription metric = new ServiceLoadMetricDescription();
metric.Name = "ClientConnections";
metric.PrimaryDefaultLoad = 1024;
metric.SecondaryDefaultLoad = 0;
metric.Weight = ServiceLoadMetricWeight.High;
serviceDescription.Metrics.Add(metric);
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("ClientConnections,High,1024,0)
Zobrazí se kapacity definované v manifestu clusteru. Tady je příklad pro ClusterManifest.xml:
<NodeType Name="NodeType03">
<Capacities>
<Capacity Name="ClientConnections" Value="65536"/>
</Capacities>
</NodeType>
Tady je příklad kapacit definovaných prostřednictvím ClusterConfig.json pro samostatná nasazení nebo Template.json pro clustery hostované v Azure:
"nodeTypes": [
{
"name": "NodeType03",
"capacities": {
"ClientConnections": "65536",
}
}
],
Zatížení služby se často dynamicky mění. Řekněme, že zatížení repliky "Client Připojení ions" se změnilo z 1 024 na 2 048. Uzel, na kterém byl spuštěný, měl kapacitu pouze 512 zbývajících pro danou metriku. Teď, když je umístění repliky nebo instance neplatné, protože na tomto uzlu není dostatek místa. Správce prostředků clusteru musí získat uzel zpět pod kapacitou. Snižuje zatížení uzlu, který je nad kapacitou, přesunutím jedné nebo více replik nebo instancí z tohoto uzlu do jiných uzlů.
Správce prostředků clusteru se snaží minimalizovat náklady na přesun replik. Další informace o nákladech na pohyb a o vyrovnávání strategií a pravidel.
Kapacita clusteru
Jak Správce prostředků clusteru Service Fabric zachová celkový cluster tak, aby byl příliš plný? S dynamickým zatížením toho není moc možné. Služby můžou mít špičku zatížení nezávisle na akcích, které Cluster Resource Manager provádí. V důsledku toho může být váš cluster s velkým množstvím místností dnes podnícený, pokud bude zítra špička.
Ovládací prvky v Cluster Resource Manageru pomáhají předcházet problémům. První věcí, kterou můžete udělat, je zabránit vytváření nových úloh, které by způsobily, že se cluster zaplní.
Řekněme, že vytváříte bezstavovou službu a má s ní spojené určité zatížení. Služba se stará o metriku DiskSpaceInMb. Služba bude využívat pět jednotek DiskSpaceInMb pro každou instanci služby. Chcete vytvořit tři instance služby. To znamená, že k vytvoření těchto instancí služby potřebujete 15 jednotek "DiskSpaceInMb" v clusteru.
Správce prostředků clusteru průběžně vypočítá kapacitu a spotřebu každé metriky, aby mohl určit zbývající kapacitu v clusteru. Pokud není dostatek místa, Správce prostředků clusteru odmítne volání pro vytvoření služby.
Vzhledem k tomu, že požadavek je jenom na 15 jednotek, můžete tento prostor přidělit mnoha různými způsoby. Na 15 různých uzlech může být například jedna zbývající jednotka kapacity nebo tři zbývající jednotky kapacity na pěti různých uzlech. Pokud Správce prostředků clusteru může změnit uspořádání, aby na třech uzlech bylo dostupných pět jednotek, umístí službu. Uspořádání clusteru je obvykle možné, pokud je cluster téměř plný nebo stávající služby nelze z nějakého důvodu konsolidovat.
Vyrovnávací paměť uzlu a kapacita overbookingu
Pokud je zadaná kapacita uzlu pro metriku, Správce prostředků clusteru nikdy neumisťuje nebo nepřesune repliky do uzlu, pokud by celkové zatížení překročilo zadanou kapacitu uzlu. To může někdy zabránit umístění nových replik nebo nahrazení neúspěšných replik, pokud je cluster téměř v plné kapacitě a replika s velkým zatížením musí být umístěna, nahrazena nebo přesunuta.
Pokud chcete zajistit větší flexibilitu, můžete zadat vyrovnávací paměť uzlu nebo kapacitu přebookování. Pokud je pro metriku zadána vyrovnávací paměť uzlu nebo kapacita overbookingu, pokusí se Správce prostředků clusteru umístit nebo přesunout repliky takovým způsobem, aby vyrovnávací paměť nebo kapacita překnižování zůstaly nepoužité, ale v případě potřeby se kapacita vyrovnávací paměti nebo overbookingu použijí v případě potřeby pro akce, které zvyšují dostupnost služby, například:
- Umístění nové repliky nebo nahrazení neúspěšných replik
- Umístění během upgradů
- Oprava porušení měkkých a pevných omezení
- Defragmentace
Kapacita vyrovnávací paměti uzlu představuje rezervovanou část kapacity nižší než zadanou kapacitu uzlu a overbookingová kapacita představuje část dodatečné kapacity nad zadanou kapacitou uzlu. V obou případech se Správce prostředků clusteru pokusí zachovat tuto kapacitu zdarma.
Pokud má například uzel zadanou kapacitu pro využití procesoru metrik 100 a procent vyrovnávací paměti uzlu pro tuto metriku je nastavená na 20 %, celkové a nepřipojené kapacity budou 100 a 80 a Během normálních okolností nebude Správce prostředků clusteru v uzlu za normálních okolností zatížit více než 80 jednotek zatížení.

Vyrovnávací paměť uzlu by se měla použít, pokud chcete rezervovat část kapacity uzlu, která se použije jenom pro akce, které zvyšují dostupnost služby uvedené výše.
Na druhou stranu platí, že pokud se použije procento překnihování uzlů a nastaví se na 20 %, celkové a nepřipojené kapacity budou 120 a 100.
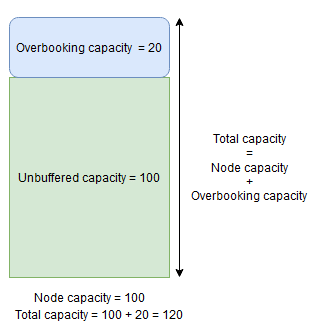
Overbooking capacity by se měl použít, když chcete Cluster Resource Manageru povolit umístit repliky do uzlu, i když by jejich celkové využití prostředků překročilo kapacitu. Dá se použít k zajištění další dostupnosti služeb na úkor výkonu. Pokud se používá overbooking, logika aplikace uživatele musí být schopná fungovat s menším počtem fyzických prostředků, než může vyžadovat.
Pokud je zadána vyrovnávací paměť uzlu nebo kapacity overbookingu, Správce prostředků clusteru nepřesune ani neumisťuje repliky, pokud by celkové zatížení cílového uzlu překročilo celkovou kapacitu (kapacita uzlu v případě vyrovnávací paměti uzlu a kapacity uzlu + kapacita overbookingu v případě překnižování).
Kapacitu overbookingu je možné zadat také tak, aby byla nekonečná. V tomto případě se Správce prostředků clusteru pokusí zachovat celkové zatížení uzlu pod zadanou kapacitou uzlu, ale může potenciálně způsobit mnohem větší zatížení uzlu, což může vést k závažnému snížení výkonu.
Metrika nemůže mít současně zadanou vyrovnávací paměť uzlu i kapacitu overbookingu.
Tady je příklad, jak zadat vyrovnávací paměť uzlu nebo kapacity overbookingu v ClusterManifest.xml:
<Section Name="NodeBufferPercentage">
<Parameter Name="SomeMetric" Value="0.15" />
</Section>
<Section Name="NodeOverbookingPercentage">
<Parameter Name="SomeOtherMetric" Value="0.2" />
<Parameter Name=”MetricWithInfiniteOverbooking” Value=”-1.0” />
</Section>
Tady je příklad, jak zadat vyrovnávací paměť uzlu nebo překlonovat kapacity prostřednictvím ClusterConfig.json pro samostatná nasazení nebo Template.json pro clustery hostované v Azure:
"fabricSettings": [
{
"name": "NodeBufferPercentage",
"parameters": [
{
"name": "SomeMetric",
"value": "0.15"
}
]
},
{
"name": "NodeOverbookingPercentage",
"parameters": [
{
"name": "SomeOtherMetric",
"value": "0.20"
},
{
"name": "MetricWithInfiniteOverbooking",
"value": "-1.0"
}
]
}
]
Další kroky
- Informace o architektuře a toku informací v rámci Resource Manageru clusteru najdete v tématu Přehled architektury Cluster Resource Manageru.
- Definování metrik defragmentace je jedním ze způsobů, jak konsolidovat zatížení uzlů místo jejich rozložení. Informace o konfiguraci defragmentace najdete v tématu Defragmentace metrik a zatížení v Service Fabric.
- Začněte od začátku a získejte úvod do Resource Manageru clusteru Service Fabric.
- Informace o správě a vyrovnávání zatížení clusteru v clusteru najdete v tématu Vyrovnávání clusteru Service Fabric.