Správa spotřeby a zatížení prostředků v Service Fabric s využitím metrik
Metriky jsou prostředky, o které vaše služby pečují a které poskytují uzly v clusteru. Metrika je cokoli, co chcete spravovat, abyste mohli zlepšit nebo monitorovat výkon svých služeb. Můžete například sledovat spotřebu paměti, abyste věděli, jestli je vaše služba přetížená. Dalším využitím je zjistit, jestli by se služba mohla přesunout jinam, kde je paměť méně omezená, aby se zlepšil výkon.
Příkladem metrik jsou například využití paměti, disku a procesoru. Tyto metriky jsou fyzické metriky, prostředky, které odpovídají fyzickým prostředkům na uzlu, které je potřeba spravovat. Metriky také můžou být (a obvykle jsou) logické metriky. Logické metriky jsou například "MyWorkQueueDepth" nebo "MessagesToProcess" nebo "TotalRecords". Logické metriky jsou definované aplikací a nepřímo odpovídají určité spotřebě fyzických prostředků. Logické metriky jsou běžné, protože může být obtížné měřit a vykazovat spotřebu fyzických prostředků pro jednotlivé služby. Složitost měření a generování sestav vlastních fyzických metrik je také důvodem, proč Service Fabric poskytuje některé výchozí metriky.
Výchozí metriky
Řekněme, že chcete začít psát a nasazovat službu. V tuto chvíli nevíte, jaké fyzické nebo logické prostředky využívá. To je v pořádku! Resource Manager clusteru Service Fabric používá některé výchozí metriky, pokud nejsou zadané žádné jiné metriky. Jsou to tyto:
- PrimaryCount – počet primárních replik na uzlu.
- ReplicaCount – počet celkových stavových replik na uzlu.
- Count – počet všech objektů služby (bezstavových a stavových) na uzlu.
| Metric | Bezstavové načtení instance | Stavové sekundární zatížení | Stavové primární zatížení | Hmotnost |
|---|---|---|---|---|
| PrimaryCount | 0 | 0 | 1 | Vysoká |
| ReplicaCount | 0 | 1 | 1 | Střední |
| Počet | 1 | 1 | 1 | Nízká |
U základních úloh poskytují výchozí metriky slušné rozdělení práce v clusteru. V následujícím příkladu se podíváme, co se stane, když vytvoříme dvě služby, a při vyrovnávání spoléháme na výchozí metriky. První služba je stavová služba se třemi oddíly a cílovou replikou nastavenou velikostí tři. Druhá služba je bezstavová služba s jedním oddílem a počtem instancí tří.
Získáme:
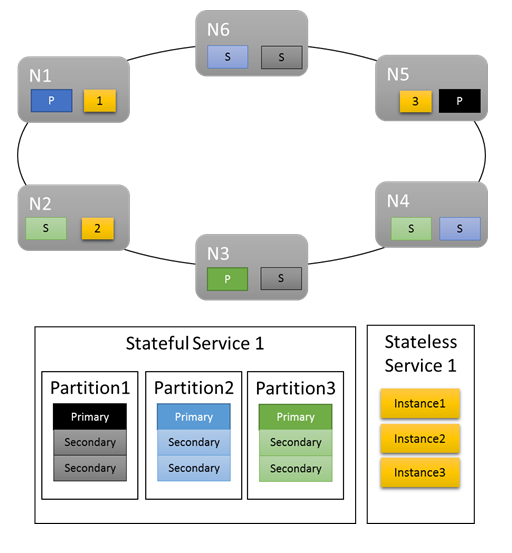
Všimněte si:
- Primární repliky stavové služby se distribuují mezi několik uzlů.
- Repliky pro stejný oddíl jsou na různých uzlech.
- Celkový počet primárek a sekundárů se distribuuje v clusteru.
- Celkový počet objektů služby, které jsou rovnoměrně přiděleny na každém uzlu
Dobré!
Výchozí metriky fungují skvěle jako začátek. Výchozí metriky vás ale budou doposud přenášet jenom vy. Příklad: Jaká je pravděpodobnost, že vámi vybrané schéma dělení způsobí dokonale rovnoměrné využití všech oddílů? Jaká je šance, že je zatížení dané služby konstantní v průběhu času nebo dokonce stejné v současné době napříč několika oddíly?
Můžete spustit jenom s výchozími metrikami. To ale obvykle znamená, že využití clusteru je nižší a nerovnoměrnější, než byste chtěli. Je to proto, že výchozí metriky nejsou adaptivní a předpokládají, že je vše ekvivalentní. Například primární, který je zaneprázdněný, a jeden, který není oba přispívají "1" do metriky PrimaryCount. V nejhorším případě může mít použití pouze výchozích metrik také za následek nadměrně naplánované uzly a způsobit problémy s výkonem. Pokud vás zajímá, jak využít cluster na maximum a vyhnout se problémům s výkonem, musíte použít vlastní metriky a dynamické generování sestav zatížení.
Vlastní metriky
Metriky se při vytváření služby konfigurují na základě jednotlivých pojmenovaných instancí.
Každá metrika má některé vlastnosti, které ji popisují: název, hmotnost a výchozí zatížení.
- Název metriky: Název metriky. Název metriky je jedinečný identifikátor metriky v rámci clusteru z pohledu Resource Manager.
Poznámka
Název vlastní metriky by neměl být žádný ze systémových názvů metrik, tj. servicefabric:/_CpuCores nebo servicefabric:/_MemoryInMB, protože může vést k nedefinovaným chováním. Počínaje Service Fabric verze 9.1 se pro existující služby s těmito vlastními názvy metrik vydává upozornění stavu, které označuje, že název metriky je nesprávný.
- Váha: Váha metriky definuje, jak důležitá je tato metrika vzhledem k ostatním metrikám pro tuto službu.
- Výchozí zatížení: Výchozí zatížení je reprezentováno odlišně v závislosti na tom, jestli je služba bezstavová nebo stavová.
- U bezstavových služeb má každá metrika jednu vlastnost s názvem DefaultLoad.
- Pro stavové služby definujete:
- PrimaryDefaultLoad: Výchozí množství této metriky, kterou tato služba využívá, když je primární.
- SecondaryDefaultLoad: Výchozí množství této metriky, kterou tato služba využívá, když je sekundární
Poznámka
Pokud definujete vlastní metriky a chcete použít také výchozí metriky, musíte výchozí metriky explicitně přidat zpět a definovat pro ně váhy a hodnoty. Je to proto, že musíte definovat vztah mezi výchozími a vlastními metrikami. Možná vás například více zajímá ConnectionCount nebo WorkQueueDepth než primární distribuce. Ve výchozím nastavení je váha metriky PrimaryCount vysoká, takže ji chcete při přidávání dalších metrik snížit na střední, abyste měli jistotu, že budou mít přednost.
Definování metrik pro vaši službu – příklad
Řekněme, že chcete následující konfiguraci:
- Vaše služba hlásí metriku s názvem ConnectionCount.
- Chcete také použít výchozí metriky.
- Provedli jste některá měření a víte, že za normálních okolností primární replika této služby zabírá 20 jednotek ConnectionCount.
- Secondaries use 5 units of "ConnectionCount"
- Víte, že "ConnectionCount" je nejdůležitější metrika z hlediska správy výkonu této konkrétní služby.
- Stále chcete, aby primární repliky byly vyvážené. Vyrovnávání primárních replik je obecně dobrý nápad bez ohledu na to, co se děje. To pomáhá zabránit tomu, aby ztráta určitého uzlu nebo domény selhání ovlivnila většinu primárních replik.
- Jinak jsou výchozí metriky v pořádku.
Tady je kód, který byste napsali k vytvoření služby s konfigurací této metriky:
Kód:
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
StatefulServiceLoadMetricDescription connectionMetric = new StatefulServiceLoadMetricDescription();
connectionMetric.Name = "ConnectionCount";
connectionMetric.PrimaryDefaultLoad = 20;
connectionMetric.SecondaryDefaultLoad = 5;
connectionMetric.Weight = ServiceLoadMetricWeight.High;
StatefulServiceLoadMetricDescription primaryCountMetric = new StatefulServiceLoadMetricDescription();
primaryCountMetric.Name = "PrimaryCount";
primaryCountMetric.PrimaryDefaultLoad = 1;
primaryCountMetric.SecondaryDefaultLoad = 0;
primaryCountMetric.Weight = ServiceLoadMetricWeight.Medium;
StatefulServiceLoadMetricDescription replicaCountMetric = new StatefulServiceLoadMetricDescription();
replicaCountMetric.Name = "ReplicaCount";
replicaCountMetric.PrimaryDefaultLoad = 1;
replicaCountMetric.SecondaryDefaultLoad = 1;
replicaCountMetric.Weight = ServiceLoadMetricWeight.Low;
StatefulServiceLoadMetricDescription totalCountMetric = new StatefulServiceLoadMetricDescription();
totalCountMetric.Name = "Count";
totalCountMetric.PrimaryDefaultLoad = 1;
totalCountMetric.SecondaryDefaultLoad = 1;
totalCountMetric.Weight = ServiceLoadMetricWeight.Low;
serviceDescription.Metrics.Add(connectionMetric);
serviceDescription.Metrics.Add(primaryCountMetric);
serviceDescription.Metrics.Add(replicaCountMetric);
serviceDescription.Metrics.Add(totalCountMetric);
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("ConnectionCount,High,20,5”,"PrimaryCount,Medium,1,0”,"ReplicaCount,Low,1,1”,"Count,Low,1,1”)
Poznámka
Výše uvedené příklady a zbytek tohoto dokumentu popisují správu metrik pro jednotlivé pojmenované služby. Pro vaše služby je také možné definovat metriky na úrovni typu služby. Toho se dosahuje jejich zadáním v manifestech služby. Definování metrik na úrovni typu se nedoporučuje z několika důvodů. Prvním důvodem je to, že názvy metrik jsou často specifické pro konkrétní prostředí. Pokud neexistuje pevná smlouva, nemůžete si být jistí, že metrika "Jádra" v jednom prostředí není "MiliCores" nebo "CoReS" v jiných prostředích. Pokud jsou metriky definované v manifestu, musíte vytvořit nové manifesty pro každé prostředí. To obvykle vede k šíření různých manifestů s pouze malými rozdíly, což může vést k potížím v řízení.
Načítání metrik se obvykle přiřazuje podle pojmenované instance služby. Řekněme například, že vytvoříte jednu instanci služby pro zákazníka A, který ji plánuje používat jen zlehka. Řekněme také, že vytvoříte další pro zákazníka, který má větší úlohu. V takovém případě byste pravděpodobně chtěli upravit výchozí zatížení těchto služeb. Pokud máte metriky a zatížení definované prostřednictvím manifestů a chcete tento scénář podporovat, vyžaduje pro každého zákazníka různé typy aplikací a služeb. Hodnoty definované při vytváření služby přepíší hodnoty definované v manifestu, takže je můžete použít k nastavení konkrétních výchozích hodnot. To ale způsobí, že hodnoty deklarované v manifestech nebudou odpovídat hodnotám, se kterými se služba skutečně spouští. To může vést k nejasnostem.
Připomínáme, že pokud chcete použít jenom výchozí metriky, nemusíte se vůbec dotýkat kolekce metrik ani při vytváření služby dělat něco zvláštního. Výchozí metriky se použijí automaticky, když nejsou definované žádné další.
Teď si projdeme každé z těchto nastavení podrobněji a promluvme si o chování, které toto nastavení ovlivňuje.
Načítání
Celý smysl definování metrik spočívá v reprezentaci určité zátěže. Zatížení udává, kolik z dané metriky spotřebuje některá instance služby nebo replika na daném uzlu. Načtení je možné nakonfigurovat téměř kdykoli. Příklad:
- Načtení je možné definovat při vytvoření služby. Tento typ konfigurace načítání se nazývá výchozí načtení.
- Informace o metrikách, včetně výchozích načtení, pro službu je možné aktualizovat po vytvoření služby. Tato aktualizace metriky se provádí aktualizací služby.
- Zatížení pro daný oddíl je možné obnovit na výchozí hodnoty pro danou službu. Tato aktualizace metriky se nazývá resetování zatížení oddílu.
- Zatížení může být hlášeno pro jednotlivé objekty služby dynamicky za běhu. Tato aktualizace metriky se nazývá načítání sestav.
- Zatížení replik nebo instancí oddílu je také možné aktualizovat hlášením hodnot zatížení prostřednictvím volání rozhraní API pro prostředky infrastruktury. Tato aktualizace metriky se nazývá generování sestav zatížení oddílu.
Všechny tyto strategie je možné používat v rámci stejné služby po celou dobu její životnosti.
Výchozí načtení
Výchozí zatížení určuje, kolik metrik spotřebuje každý objekt služby (bezstavová instance nebo stavová replika) této služby. Cluster Resource Manager používá toto číslo pro zatížení objektu služby, dokud neobdrží další informace, například sestavu dynamického zatížení. U jednodušších služeb je výchozí načtení statickou definicí. Výchozí načtení se nikdy neaktualizuje a používá se po celou dobu životnosti služby. Výchozí zatížení se skvěle hodí pro jednoduché scénáře plánování kapacity, kde jsou určité objemy prostředků vyhrazené pro různé úlohy a nemění se.
Poznámka
Další informace o správě kapacity a definování kapacit pro uzly v clusteru najdete v tomto článku.
Cluster Resource Manager umožňuje stavovým službám určit jiné výchozí zatížení pro jejich primární a sekundární. Bezstavové služby můžou zadat pouze jednu hodnotu, která se vztahuje na všechny instance. U stavových služeb se výchozí zatížení primární a sekundární repliky obvykle liší, protože repliky dělají v každé roli různé druhy práce. Například primární modely obvykle obsluhují čtení i zápisy a zpracovávají většinu výpočetní zátěže, zatímco sekundární ne. Výchozí zatížení primární repliky je obvykle vyšší než výchozí zatížení sekundárních replik. Reálná čísla by měla záviset na vašich vlastních měřeních.
Dynamické načtení
Řekněme, že službu už nějakou dobu provozujete. Při monitorování jste si všimli, že:
- Některé oddíly nebo instance dané služby spotřebovávají více prostředků než jiné.
- Některé služby mají zatížení, které se v průběhu času mění.
Existuje spousta věcí, které by mohly způsobit tyto typy kolísání zatížení. Například různé služby nebo oddíly jsou přidružené k různým zákazníkům s různými požadavky. Zatížení se také může změnit, protože množství práce, kterou služba v průběhu dne odvádí, se mění. Bez ohledu na důvod obvykle neexistuje jedno číslo, které byste mohli použít jako výchozí. To platí zejména v případě, že chcete z clusteru získat co největší využití. Jakákoli hodnota, kterou vyberete pro výchozí načtení, je někdy chybná. Nesprávná výchozí načtení způsobí, že cluster Resource Manager nad nebo pod přidělováním prostředků. V důsledku toho máte uzly, které jsou nadměrně nebo nedostatečně využívány, i když Resource Manager clusteru přesvědčen, že je cluster vyvážený. Výchozí načtení je stále dobré, protože poskytuje určité informace pro počáteční umístění, ale nejedná se o úplný scénář pro skutečné úlohy. Za účelem přesného zachycení měnících se požadavků na prostředky umožňuje Resource Manager clusteru každému objektu služby aktualizovat vlastní zatížení za běhu. To se nazývá dynamické generování sestav zatížení.
Sestavy dynamického zatížení umožňují replikám nebo instancím upravit přidělení nebo hlášené zatížení metrik v průběhu jejich životnosti. Replika služby nebo instance, které byly studené a neprovádí žádnou práci, obvykle hlásí, že používají nízké objemy dané metriky. Zaneprázdněná replika nebo instance by ohlásila, že jich využívají více.
Generování sestav zatížení na repliku nebo instanci umožňuje Resource Manager clusteru přeuspořádat jednotlivé objekty služby v clusteru. Změna uspořádání služeb pomůže zajistit, aby tyto služby získaly prostředky, které vyžadují. Zaneprázdněné služby můžou efektivně "uvolnit" prostředky z jiných replik nebo instancí, které jsou momentálně studené nebo odvádí méně práce.
V rámci Reliable Services vypadá kód pro dynamické načítání sestav takto:
Kód:
this.Partition.ReportLoad(new List<LoadMetric> { new LoadMetric("CurrentConnectionCount", 1234), new LoadMetric("metric1", 42) });
Služba může hlásit libovolnou metriku definovanou při vytváření. Pokud služba hlásí zatížení metriky, kterou není nakonfigurovaná pro použití, Service Fabric tuto sestavu ignoruje. Pokud jsou současně hlášeny další metriky, které jsou platné, jsou tyto sestavy přijaty. Kód služby může měřit a vykazovat všechny metriky, které zná, a operátory můžou určit konfiguraci metrik, která se má použít, aniž by bylo nutné měnit kód služby.
Generování sestav zatížení oddílu
Předchozí část popisuje, jak se repliky nebo instance služby samy načítají. Existuje další možnost, jak dynamicky hlásit zatížení replik nebo instancí oddílu prostřednictvím rozhraní SERVICE Fabric API. Při hlášení zatížení oddílu můžete hlásit více oddílů najednou.
Tyto sestavy se budou používat úplně stejným způsobem jako sestavy načítání, které pocházejí z replik nebo samotných instancí. Hlášené hodnoty budou platné, dokud nebudou hlášeny nové hodnoty zatížení replikou nebo instancí nebo hlášením nové hodnoty načtení pro oddíl.
S tímto rozhraním API existuje několik způsobů, jak aktualizovat zatížení v clusteru:
- Oddíl stavové služby může aktualizovat zatížení primární repliky.
- Bezstavové i stavové služby můžou aktualizovat zatížení všech svých sekundárních replik nebo instancí.
- Bezstavové i stavové služby můžou aktualizovat zatížení konkrétní repliky nebo instance v uzlu.
Je také možné kombinovat libovolnou z těchto aktualizací na oddíl současně. Kombinace aktualizací zatížení pro konkrétní oddíl by měla být určena prostřednictvím objektu PartitionMetricLoadDescription, který může obsahovat odpovídající seznam aktualizací zatížení, jak je znázorněno v následujícím příkladu. Aktualizace zatížení jsou reprezentovány prostřednictvím objektu MetricLoadDescription, který může obsahovat aktuální nebo předpokládanou hodnotu zatížení pro metriku s názvem metriky.
Poznámka
Predikované hodnoty zatížení metrik jsou v současné době funkcí Ve verzi Preview. Umožňuje hlášení a použití předpovídané hodnoty zatížení na straně Service Fabric, ale tato funkce v současné době není povolená.
Aktualizace načtení pro více oddílů je možná jedním voláním rozhraní API. V takovém případě bude výstup obsahovat odpověď na oddíl. V případě, že aktualizace oddílu není z nějakého důvodu úspěšně použita, aktualizace pro tento oddíl se přeskočí a zobrazí se odpovídající kód chyby pro cílový oddíl:
- PartitionNotFound – Zadané ID oddílu neexistuje.
- ReconfigurationPending – oddíl se v současné době překonfiguruje.
- InvalidForStatelessServices – došlo ke změně zatížení primární repliky pro oddíl patřící do bezstavové služby.
- ReplicaDoesNotExist – sekundární replika nebo instance na zadaném uzlu neexistuje.
- InvalidOperation – může k tomu dojít ve dvou případech: aktualizace zatížení oddílu, který patří do systémové aplikace, nebo aktualizace předpokládaného zatížení není povolená.
Pokud se některé z těchto chyb vrátí, můžete aktualizovat vstup pro konkrétní oddíl a zkusit aktualizaci zopakovat.
Kód:
Guid partitionId = Guid.Parse("53df3d7f-5471-403b-b736-bde6ad584f42");
string metricName0 = "CustomMetricName0";
List<MetricLoadDescription> newPrimaryReplicaLoads = new List<MetricLoadDescription>()
{
new MetricLoadDescription(metricName0, 100)
};
string nodeName0 = "NodeName0";
List<MetricLoadDescription> newSpecificSecondaryReplicaLoads = new List<MetricLoadDescription>()
{
new MetricLoadDescription(metricName0, 200)
};
OperationResult<UpdatePartitionLoadResultList> updatePartitionLoadResults =
await this.FabricClient.UpdatePartitionLoadAsync(
new UpdatePartitionLoadQueryDescription
{
PartitionMetricLoadDescriptionList = new List<PartitionMetricLoadDescription>()
{
new PartitionMetricLoadDescription(
partitionId,
newPrimaryReplicaLoads,
new List<MetricLoadDescription>(),
new List<ReplicaMetricLoadDescription>()
{
new ReplicaMetricLoadDescription(nodeName0, newSpecificSecondaryReplicaLoads)
})
}
},
this.Timeout,
cancellationToken);
V tomto příkladu provedete aktualizaci posledního ohlášeného zatížení pro oddíl 53df3d7f-5471-403b-b736-bde6ad584f42. Zatížení primární repliky pro metriku CustomMetricName0 se aktualizuje o hodnotu 100. Současně se načtení stejné metriky pro konkrétní sekundární repliku umístěné v uzlu NodeName0 aktualizuje s hodnotou 200.
Aktualizace konfigurace metrik služby
Seznam metrik přidružených ke službě a vlastnosti těchto metrik je možné dynamicky aktualizovat, když je služba aktivní. To umožňuje experimentování a flexibilitu. Mezi příklady, kdy je to užitečné, patří:
- zakázání metriky se zprávou o chybách pro konkrétní službu
- změna konfigurace váhy metrik na základě požadovaného chování
- povolení nové metriky až po nasazení a ověření kódu prostřednictvím jiných mechanismů
- změna výchozího zatížení služby na základě pozorovaného chování a spotřeby
Hlavní rozhraní API pro změnu konfigurace metrik jsou FabricClient.ServiceManagementClient.UpdateServiceAsync v jazyce C# a Update-ServiceFabricService v PowerShellu. Jakékoli informace, které zadáte pomocí těchto rozhraní API, okamžitě nahradí stávající informace o metrikách pro službu.
Kombinování výchozích hodnot zatížení a sestav dynamického zatížení
Pro stejnou službu je možné použít výchozí zatížení a dynamické načtení. Pokud služba využívá výchozí i dynamické sestavy zatížení, výchozí zatížení slouží jako odhad, dokud se dynamické sestavy nezobrazí. Výchozí zatížení je dobré, protože dává clusteru Resource Manager něco, s čím může pracovat. Výchozí zatížení umožňuje clusteru Resource Manager umístit objekty služby do dobrých umístění, když jsou vytvořeny. Pokud nejsou k dispozici žádné výchozí informace o načtení, umístění služeb je v podstatě náhodné. Když sestavy zatížení dorazí později, počáteční náhodné umístění je často chybné a cluster Resource Manager musí přesunout služby.
Podívejme se na předchozí příklad a podívejme se, co se stane, když přidáme nějaké vlastní metriky a dynamické generování sestav zatížení. V tomto příkladu použijeme jako příklad metriku MemoryInMb.
Poznámka
Paměť je jednou ze systémových metrik, které může Service Fabric řídit prostředky, a vlastní hlášení je obvykle obtížné. Ve skutečnosti neočekáváme, že budete hlásit spotřebu paměti. Paměť se zde používá jako pomůcka k získání informací o možnostech clusteru Resource Manager.
Předpokládejme, že jsme původně vytvořili stavovou službu pomocí následujícího příkazu:
PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("MemoryInMb,High,21,11”,"PrimaryCount,Medium,1,0”,"ReplicaCount,Low,1,1”,"Count,Low,1,1”)
Připomínáme, že tato syntaxe je (MetricName, MetricWeight, PrimaryDefaultLoad, SecondaryDefaultLoad).
Podívejme se, jak by mohlo vypadat jedno z možných rozložení clusteru:
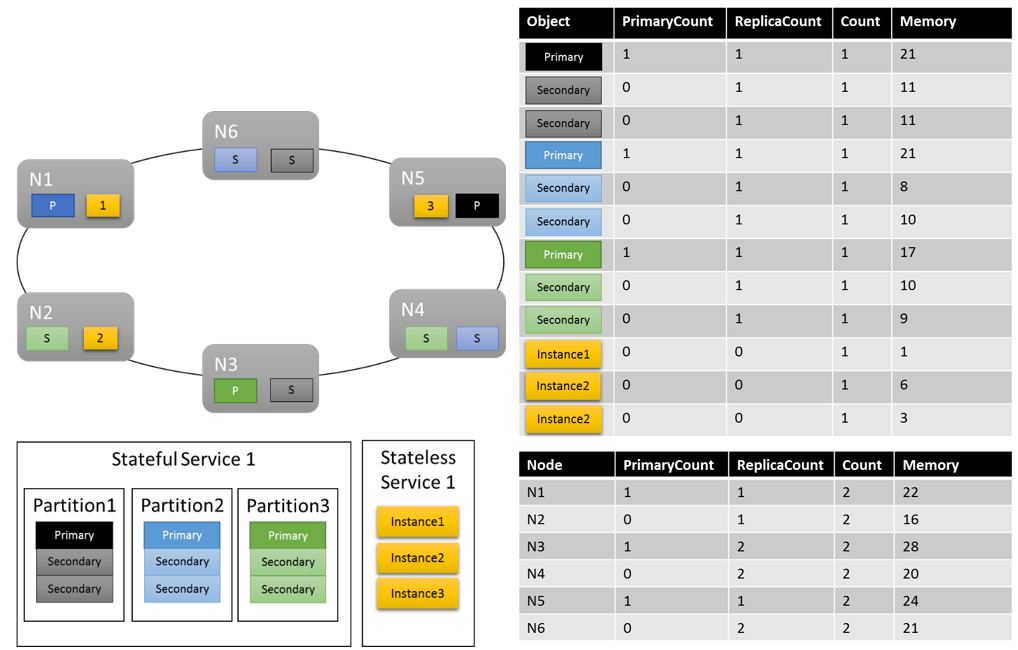
Některé věci, které stojí za zmínku:
- Sekundární repliky v rámci oddílu můžou mít každý vlastní zatížení.
- Metriky vypadají celkově vyváženě. V případě paměti je poměr mezi maximálním a minimálním zatížením 1,75 (uzel s největším zatížením je N3, nejméně N2 a 28/16 = 1,75).
Ještě je potřeba vysvětlit některé věci:
- Co určilo, jestli je poměr 1,75 přiměřený nebo ne? Jak Resource Manager clusteru zjistit, jestli je to dostatečně dobré nebo jestli je potřeba udělat víc práce?
- Kdy dojde k vyrovnávání?
- Co znamená, že paměť byla vážená "Vysoká"?
Váhy metrik
Sledování stejných metrik napříč různými službami je důležité. Toto globální zobrazení umožňuje clusterovým Resource Manager sledovat spotřebu v clusteru, vyrovnávat spotřebu mezi uzly a zajistit, aby uzly nepřekládaly kapacitu. Služby však můžou mít různá zobrazení důležitosti stejné metriky. V clusteru s mnoha metrikami a spoustou služeb také nemusí existovat dokonale vyvážená řešení pro všechny metriky. Jak by měl cluster Resource Manager tyto situace řešit?
Váhy metrik umožňují clusteru Resource Manager rozhodnout, jak cluster vyvážit, když neexistuje žádná dokonalá odpověď. Váhy metrik také umožňují clusteru Resource Manager vyrovnávat konkrétní služby odlišně. Metriky můžou mít čtyři různé úrovně hmotnosti: Nula, Nízká, Střední a Vysoká. Metrika s váhou nula nepřispívá k ničemu při zvažování, jestli jsou věci vyvážené nebo ne. Jeho zatížení ale stále přispívá ke správě kapacity. Metriky s nulovou váhou jsou stále užitečné a často se používají jako součást chování služby a monitorování výkonu. Tento článek obsahuje další informace o použití metrik pro monitorování a diagnostiku vašich služeb.
Skutečný dopad různých vah metrik v clusteru spočívá v tom, že cluster Resource Manager generuje různá řešení. Váhy metrik říkají clusteru Resource Manager, že určité metriky jsou důležitější než jiné. Pokud neexistuje žádné dokonalé řešení, clusterová Resource Manager může upřednostňovat řešení, která lépe vyrovnaly metriky s vyšší váhou. Pokud si služba myslí, že konkrétní metrika není důležitá, může její použití této metriky být nevyvážené. To umožňuje jiné službě získat rovnoměrné rozdělení určité metriky, která je pro ni důležitá.
Podívejme se na příklad některých sestav zatížení a na to, jak různé váhy metrik mají za následek různé přidělení v clusteru. V tomto příkladu vidíme, že přepnutí relativní váhy metrik způsobí, že cluster Resource Manager vytvoří různá uspořádání služeb.
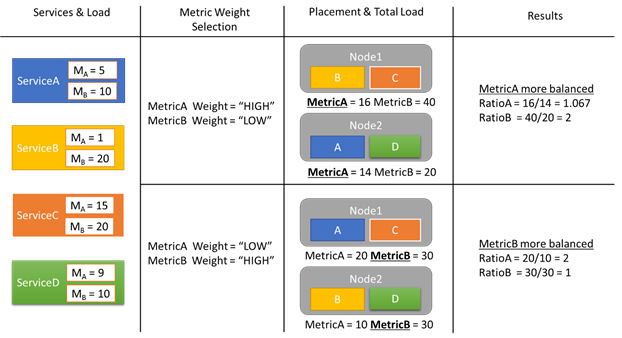
V tomto příkladu jsou čtyři různé služby, které hlásí různé hodnoty pro dvě různé metriky, MetricA a MetricB. V jednom případě všechny služby definují metriku MetricA jako nejdůležitější (Weight = High) a MetricB jako nedůležitou (Váha = Nízká). V důsledku toho vidíme, že cluster Resource Manager umístí služby tak, aby metrika MetricA byla lépe vyvážená než MetricB. "Lépe vyvážená" znamená, že metrika A má nižší směrodatnou odchylku než MetricB. Ve druhém případě obrátíme váhy metrik. V důsledku toho cluster Resource Manager prohodí služby A a B, aby přišly s přidělením, ve kterém je metrika MetricB lépe vyvážená než metrika A.
Poznámka
Váhy metrik určují, jak se má Resource Manager clusteru vyvážit, ale ne při vyrovnávání. Další informace o vyrovnávání najdete v tomto článku.
Globální váhy metrik
Řekněme, že ServiceA definuje metriku MetricA jako váhu Vysoká a ServiceB nastaví váhu pro MetricA na Nízkou nebo Nulu. Jaká je skutečná váha, která se nakonec zvykne?
Pro každou metriku je sledováno několik vah. První váha je váha definovaná pro metriku při vytváření služby. Druhá váha je globální váha, která se vypočítá automaticky. Cluster Resource Manager při vyhodnocování řešení používá obě tyto váhy. Je důležité vzít v úvahu obě váhy. To umožňuje Resource Manager clusteru vyvážit každou službu podle svých vlastních priorit a také zajistit správné přidělení clusteru jako celku.
Co by se stalo, kdyby Resource Manager clusteru nezajímá globální i místní zůstatek? Je snadné vytvořit řešení, která jsou globálně vyvážená, ale mají za následek špatnou rovnováhu prostředků pro jednotlivé služby. V následujícím příkladu se podíváme na službu nakonfigurovanou jenom s výchozími metrikami a zjistíme, co se stane, když se zvažuje pouze globální zůstatek:
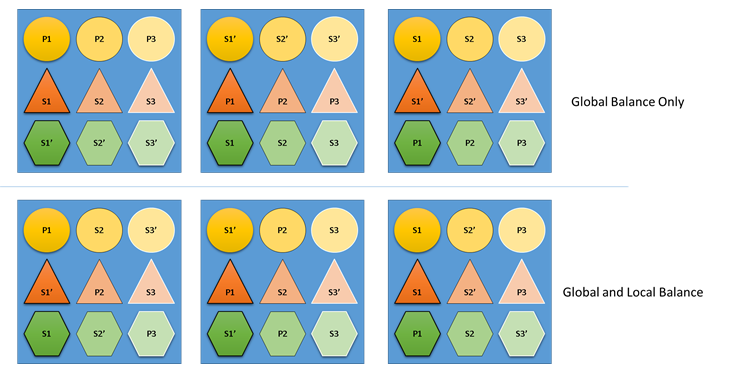
V nejvyšším příkladu založeném pouze na globální rovnováze je cluster jako celek skutečně vyvážen. Všechny uzly mají stejný počet primárek a stejný počet replik celkem. Pokud se ale podíváte na skutečný dopad tohoto přidělení, není to tak dobré: ztráta jakéhokoli uzlu má nepřiměřený dopad na konkrétní úlohu, protože bere všechny jeho primární hodnoty. Pokud například první uzel selže, ztratí se všechny tři primární položky pro tři různé oddíly služby Circle. Naopak služby Triangle a Hexagon mají své oddíly ztrátu repliky. To nezpůsobí žádné přerušení kromě nutnosti obnovit repliku mimo provoz.
V dolním příkladu Resource Manager clusteru distribuoval repliky na základě globálního zůstatku i zůstatku pro jednotlivé služby. Při výpočtu skóre řešení dává největší váhu globálnímu řešení a (konfigurovatelnou) část jednotlivým službám. Globální zůstatek metriky se vypočítá na základě průměru váhy metrik z každé služby. Každá služba je vyvážená podle vlastních definovaných vah metrik. Tím se zajistí, že služby budou vyváženy v rámci sebe podle jejich vlastních potřeb. V důsledku toho se v případě selhání prvního uzlu selhání distribuuje do všech oddílů všech služeb. Dopad na každou z nich je stejný.
Další kroky
- Další informace o konfiguraci služeb najdete v tématu Informace o konfiguraci služeb (service-fabric-cluster-resource-manager-configure-services.md)
- Definování metrik defragmentace je jedním ze způsobů, jak konsolidovat zatížení uzlů místo jeho rozložení. Informace o konfiguraci defragmentace najdete v tomto článku.
- Informace o tom, jak clusterová Resource Manager spravuje a vyrovnává zatížení v clusteru, najdete v článku o vyrovnávání zatížení.
- Začněte od začátku a získejte úvod do clusteru Service Fabric Resource Manager
- Náklady na přesun jsou jedním ze způsobů, jak signalizovat clusteru Resource Manager, že přesun některých služeb je nákladnější než jiné. Další informace o nákladech na přesun najdete v tomto článku.