Škálování v Service Fabric
Azure Service Fabric usnadňuje vytváření škálovatelných aplikací tím, že spravuje služby, oddíly a repliky na uzlech clusteru. Spouštění mnoha úloh na stejném hardwaru umožňuje maximální využití prostředků, ale také poskytuje flexibilitu z hlediska toho, jak se rozhodnete škálovat úlohy. Toto video channel 9 popisuje, jak můžete vytvářet škálovatelné aplikace mikroslužeb:
Škálování v Service Fabric se provádí několika různými způsoby:
- Škálování vytvořením nebo odebráním bezstavových instancí služby
- Škálování vytvořením nebo odebráním nových pojmenovaných služeb
- Škálování vytvořením nebo odebráním nových pojmenovaných instancí aplikací
- Škálování pomocí dělených služeb
- Škálování přidáním a odebráním uzlů z clusteru
- Škálování pomocí metrik Resource Manageru clusteru
Škálování vytvořením nebo odebráním bezstavových instancí služby
Jeden z nejjednodušších způsobů škálování v rámci Service Fabric funguje s bezstavovými službami. Když vytvoříte bezstavovou službu, získáte šanci definovat InstanceCount. InstanceCount definuje, kolik spuštěných kopií kódu této služby se vytvoří při spuštění služby. Řekněme například, že v clusteru je 100 uzlů. Řekněme také, že se služba vytvoří s InstanceCount 10. Během běhu mohlo dojít k příliš zaneprázdnění těchto 10 spuštěných kopií kódu (nebo nebylo dost zaneprázdněno). Jedním ze způsobů, jak tuto úlohu škálovat, je změnit počet instancí. Například část monitorování nebo kódu pro správu může změnit stávající počet instancí na 50 nebo na 5 v závislosti na tom, jestli se zatížení musí škálovat na více nebo více instancí na základě zatížení.
C#:
StatelessServiceUpdateDescription updateDescription = new StatelessServiceUpdateDescription();
updateDescription.InstanceCount = 50;
await fabricClient.ServiceManager.UpdateServiceAsync(new Uri("fabric:/app/service"), updateDescription);
PowerShell:
Update-ServiceFabricService -Stateless -ServiceName $serviceName -InstanceCount 50
Použití počtu dynamických instancí
Service Fabric nabízí automatický způsob, jak změnit počet instancí, konkrétně pro bezstavové služby. To umožňuje službě dynamicky škálovat s počtem dostupných uzlů. Způsob, jak se přihlásit k tomuto chování, je nastavit počet instancí = -1. InstanceCount = -1 je instrukce pro Service Fabric, která říká "Spustit tuto bezstavovou službu na každém uzlu". Pokud se počet uzlů změní, Service Fabric automaticky změní počet instancí tak, aby odpovídal, aby se zajistilo, že služba běží na všech platných uzlech.
C#:
StatelessServiceDescription serviceDescription = new StatelessServiceDescription();
//Set other service properties necessary for creation....
serviceDescription.InstanceCount = -1;
await fc.ServiceManager.CreateServiceAsync(serviceDescription);
PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName -Stateless -PartitionSchemeSingleton -InstanceCount "-1"
Škálování vytvořením nebo odebráním nových pojmenovaných služeb
Pojmenovaná instance služby je konkrétní instance typu služby (viz životní cyklus aplikace Service Fabric) v rámci některé pojmenované instance aplikace v clusteru.
Nové pojmenované instance služby je možné vytvořit (nebo odebrat), protože služby jsou více nebo méně zaneprázdněné. To umožňuje rozšířit požadavky mezi více instancí služby, což obvykle umožňuje snížit zatížení stávajících služeb. Při vytváření služeb umístí Resource Manager clusteru Service Fabric služby do clusteru distribuovaným způsobem. Přesná rozhodnutí se řídí metrikami v clusteru a dalšími pravidly umístění. Služby lze vytvořit několika různými způsoby, ale nejběžnější jsou buď prostřednictvím akcí správy, jako je někdo volá New-ServiceFabricService, nebo voláním CreateServiceAsynckódu . CreateServiceAsync lze dokonce volat z jiných služeb spuštěných v clusteru.
Dynamické vytváření služeb se dá použít v nejrůznějších scénářích a je to běžný vzor. Představte si například stavovou službu, která představuje konkrétní pracovní postup. Volání představující práci se budou zobrazovat v této službě a tato služba provede kroky tohoto pracovního postupu a zaznamená průběh.
Jak byste tuto konkrétní službu škálovala? Služba může být v nějaké podobě více tenantů a přijímat volání a zahajovat kroky pro mnoho různých instancí stejného pracovního postupu najednou. To ale může zkompilovat kód, protože se teď musí starat o mnoho různých instancí stejného pracovního postupu, a to vše v různých fázích a od různých zákazníků. Zpracování více pracovních postupů současně také nevyřeší problém se škálováním. Důvodem je to, že v určitém okamžiku bude tato služba spotřebovávat příliš mnoho prostředků, aby se vešla na konkrétní počítač. Řada služeb, které nejsou pro tento model vytvořené na prvním místě, má potíže také kvůli určitému vlastnímu kritickému bodu nebo zpomalení v kódu. Tyto typy problémů způsobují, že služba nefunguje stejně, když počet souběžných pracovních postupů, které sleduje, se zvětší.
Řešením je vytvořit instanci této služby pro každou jinou instanci pracovního postupu, který chcete sledovat. Jedná se o skvělý vzor a funguje bezstavové nebo stavové služby. Aby tento model fungoval, je obvykle jiná služba, která funguje jako služba Správce úloh. Úkolem této služby je přijímat požadavky a směrovat tyto žádosti do jiných služeb. Správce může dynamicky vytvořit instanci služby úloh, když obdrží zprávu, a pak předat žádosti těmto službám. Když daná služba pracovního postupu dokončí svou úlohu, může služba manažera také přijímat zpětná volání. Když správce obdrží tyto zpětná volání, může odstranit instanci služby pracovního postupu nebo ji nechat, pokud se očekává více volání.
Pokročilé verze tohoto typu správce můžou dokonce vytvářet fondy služeb, které spravuje. Fond pomáhá zajistit, že když přijde nový požadavek, nemusí čekat, až se služba roztáčí. Místo toho může správce vybrat službu pracovního postupu, která není aktuálně zaneprázdněna z fondu, nebo náhodně směrovat. Udržování fondu služeb umožňuje rychlejší zpracování nových požadavků, protože je méně pravděpodobné, že požadavek musí čekat na vytvoření nové služby. Vytváření nových služeb je rychlé, ale ne bezplatné nebo okamžité. Fond pomáhá minimalizovat dobu, po kterou musí požadavek čekat před obsluhou. Tento model manažera a fondu se často zobrazí, když na době odezvy záleží nejvíce. Vytvoření fronty požadavku a vytvoření služby na pozadí a jeho následné předání je také oblíbeným vzorem správce, stejně jako vytváření a odstraňování služeb na základě sledování množství práce, která služba aktuálně čeká na vyřízení.
Škálování vytvořením nebo odebráním nových pojmenovaných instancí aplikací
Vytváření a odstraňování celých instancí aplikací je podobné vzoru vytváření a odstraňování služeb. Pro tento model existuje nějaká služba manažera, která provádí rozhodnutí na základě požadavků, které vidí, a informace, které přijímá z jiných služeb v clusteru.
Kdy byste měli vytvořit novou pojmenovanou instanci aplikace místo vytvoření nových pojmenovaných instancí služby v některé již existující aplikaci? Existuje několik případů:
- Nová instance aplikace je určená pro zákazníka, jehož kód musí běžet pod určitým nastavením identity nebo zabezpečení.
- Service Fabric umožňuje definovat různé balíčky kódu, které se spouštějí pod konkrétními identitami. Aby bylo možné spustit stejný balíček kódu v různých identitách, musí k aktivacím dojít v různých instancích aplikace. Představte si případ, kdy máte nasazené úlohy existujícího zákazníka. Můžou běžet pod konkrétní identitou, abyste mohli monitorovat a řídit jejich přístup k jiným prostředkům, jako jsou vzdálené databáze nebo jiné systémy. V takovém případě, když se nový zákazník zaregistruje, pravděpodobně nechcete aktivovat svůj kód ve stejném kontextu (procesní prostor). I když byste to mohli, znesnadňuje to, aby kód služby fungoval v kontextu konkrétní identity. Obvykle musíte mít větší zabezpečení, izolaci a kód správy identit. Místo použití různých pojmenovaných instancí služby ve stejné instanci aplikace a proto stejný prostor procesu můžete použít různé pojmenované instance aplikace Service Fabric. To usnadňuje definování různých kontextů identit.
- Nová instance aplikace slouží také jako prostředek konfigurace.
- Ve výchozím nastavení se všechny pojmenované instance služby konkrétního typu služby v instanci aplikace spustí ve stejném procesu na daném uzlu. To znamená, že i když můžete nakonfigurovat každou instanci služby jinak, je to složité. Služby musí mít nějaký token, který používají k vyhledání konfigurace v rámci konfiguračního balíčku. Obvykle se jedná jenom o název služby. Funguje to správně, ale konfiguraci páruje s názvy jednotlivých pojmenovaných instancí služby v rámci této instance aplikace. To může být matoucí a obtížné spravovat, protože konfigurace je obvykle artefakt času návrhu s konkrétními hodnotami instance aplikace. Vytváření více služeb vždy znamená více upgradů aplikací, které změní informace v konfiguračních balíčcích nebo nasadí nové, aby nové služby mohly vyhledat jejich konkrétní informace. Často je jednodušší vytvořit zcela novou pojmenovanou instanci aplikace. Potom můžete pomocí parametrů aplikace nastavit jakoukoli konfiguraci potřebnou pro služby. Tímto způsobem můžou všechny služby vytvořené v této pojmenované instanci aplikace dědit konkrétní nastavení konfigurace. Například místo toho, abyste měli jeden konfigurační soubor s nastavením a přizpůsobením pro každého zákazníka, jako jsou tajné kódy nebo limity prostředků zákazníka, byste místo toho měli pro každého zákazníka jinou instanci aplikace s těmito nastaveními přepsáním.
- Nová aplikace slouží jako hranice upgradu.
- V Service Fabric slouží různé pojmenované instance aplikací jako hranice pro upgrade. Upgrade jedné pojmenované instance aplikace nebude mít vliv na kód, který je spuštěna jiná pojmenovaná instance aplikace. Různé aplikace budou mít na stejných uzlech spuštěné různé verze stejného kódu. To může být faktor, pokud potřebujete rozhodnout o škálování, protože můžete zvolit, jestli má nový kód postupovat podle stejných upgradů jako jiná služba, nebo ne. Řekněme například, že volání přichází do služby manažera, která je zodpovědná za škálování úloh konkrétního zákazníka tím, že vytváří a odstraňuje služby dynamicky. V tomto případě je však volání pro úlohu přidruženou k novému zákazníkovi. Většina zákazníků se podobá izolaci od sebe nejen z dříve uvedených důvodů zabezpečení a konfigurace, ale vzhledem k tomu, že poskytuje větší flexibilitu z hlediska spouštění konkrétních verzí softwaru a výběru, kdy se upgradují. Můžete také vytvořit novou instanci aplikace a vytvořit službu tam jednoduše k dalšímu rozdělení množství služeb, které se dotkne každý upgrade. Samostatné instance aplikací poskytují větší členitost při upgradu aplikací a také umožňují testování A/B a nasazení Blue/Green.
- Stávající instance aplikace je plná.
- V Service Fabric je kapacita aplikace koncept, který můžete použít k řízení množství prostředků dostupných pro konkrétní instance aplikace. Můžete se například rozhodnout, že daná služba musí mít vytvořenou jinou instanci, aby bylo možné škálovat. Tato instance aplikace je však pro určitou metriku mimo kapacitu. Pokud by tomuto konkrétnímu zákazníkovi nebo úloze stále mělo být uděleno více prostředků, můžete buď zvýšit stávající kapacitu pro danou aplikaci, nebo vytvořit novou aplikaci.
Škálování na úrovni oddílu
Service Fabric podporuje dělení. Dělení služby rozdělí na několik logických a fyzických oddílů, z nichž každá funguje nezávisle. To je užitečné u stavových služeb, protože žádná sada replik musí zpracovávat všechna volání a manipulovat se všemi stavy najednou. Přehled dělení obsahuje informace o podporovaných typech schémat dělení. Repliky každého oddílu jsou rozloženy mezi uzly v clusteru, distribuují zatížení dané služby a zajišťují, že ani jedna služba jako celek nebo žádný oddíl nemá jediný bod selhání.
Vezměte v úvahu službu, která používá schéma dělení s rozsahem s nízkým klíčem 0, vysokým klíčem 99 a počtem oddílů 4. V clusteru se třemi uzly může být služba rozložená se čtyřmi replikami, které sdílejí prostředky na každém uzlu, jak je znázorněno tady:
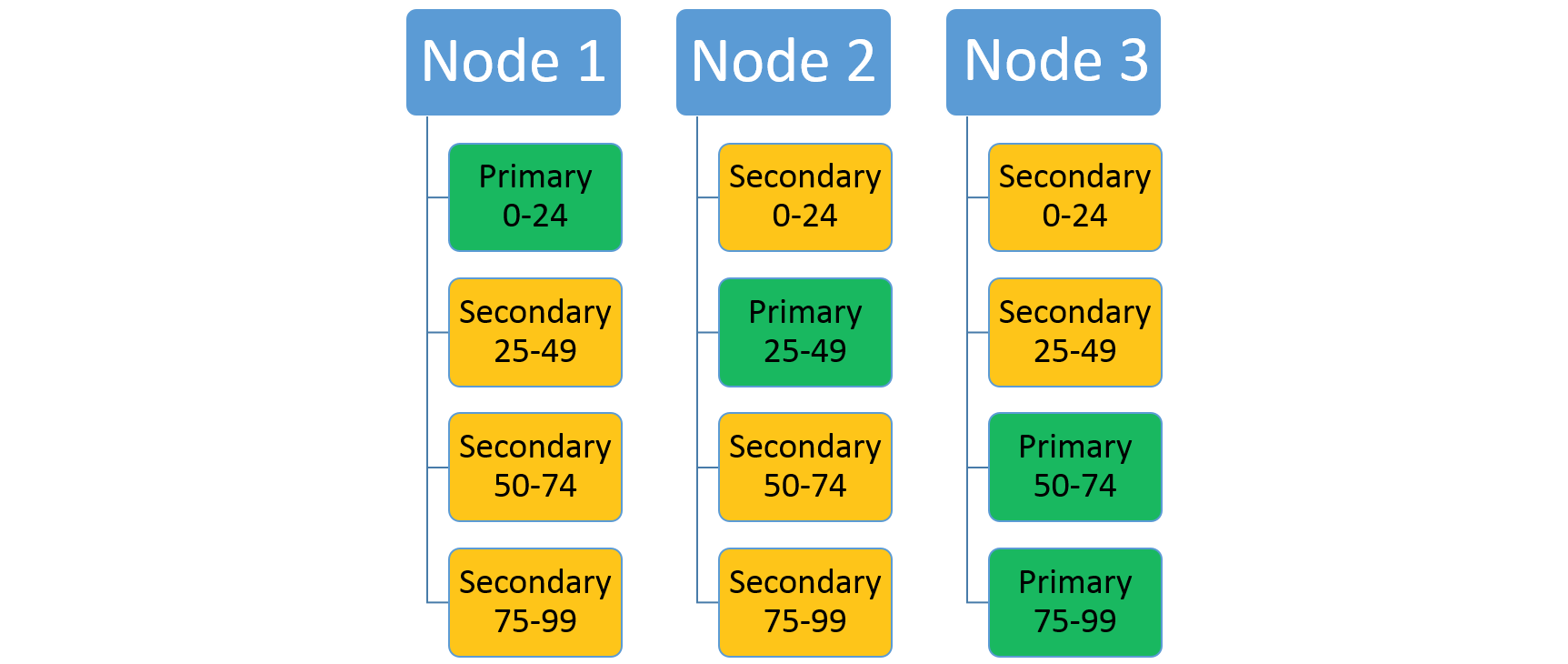
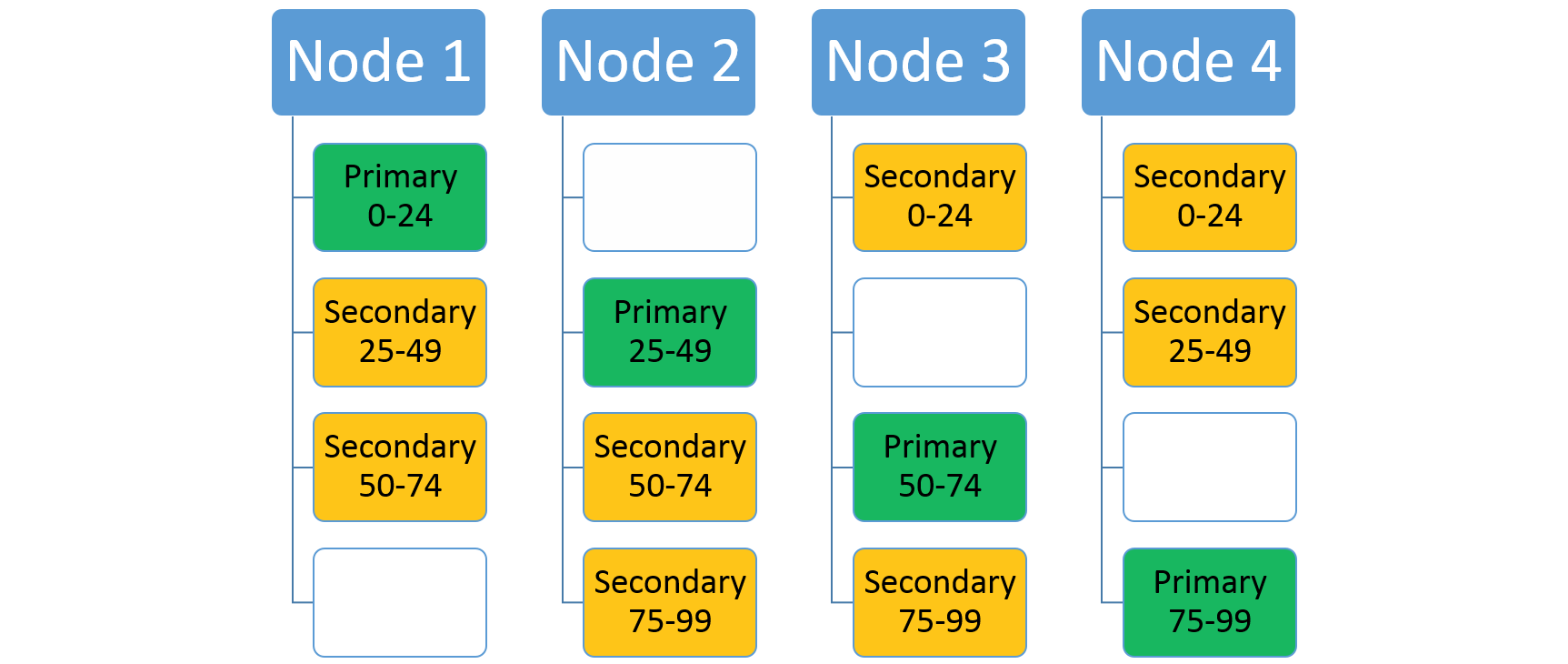
Pokud zvýšíte počet uzlů, Service Fabric tam přesune některé z existujících replik. Řekněme například, že se počet uzlů zvýší na čtyři a repliky se redistribuují. Teď má služba spuštěné tři repliky na každém uzlu, z nichž každá patří do různých oddílů. To umožňuje lepší využití prostředků, protože nový uzel není studený. Obvykle také zvyšuje výkon, protože každá služba má k dispozici více prostředků.
Škálování pomocí Resource Manageru clusteru Service Fabric a metrik
Metriky jsou způsob, jakým služby vyjadřují spotřebu prostředků do Service Fabric. Použití metrik dává Resource Manageru clusteru příležitost změnit uspořádání a optimalizovat rozložení clusteru. V clusteru může být například spousta prostředků, ale nemusí se přidělovat službám, které právě pracují. Použití metrik umožňuje Správci prostředků clusteru změnit uspořádání clusteru, aby zajistilo, že služby mají přístup k dostupným prostředkům.
Škálování přidáním a odebráním uzlů z clusteru
Další možností škálování pomocí Service Fabric je změna velikosti clusteru. Změna velikosti clusteru znamená přidání nebo odebrání uzlů pro jeden nebo více typů uzlů v clusteru. Představte si například případ, kdy jsou všechny uzly v clusteru horké. To znamená, že prostředky clusteru jsou téměř všechny spotřebované. V tomto případě je nejlepším způsobem škálování přidání dalších uzlů do clusteru. Jakmile se nové uzly připojí ke clusteru, Přesune do nich Resource Manager služby Service Fabric, což vede k menšímu celkovému zatížení stávajících uzlů. U bezstavových služeb s počtem instancí = -1 se automaticky vytvoří více instancí služby. To umožňuje, aby se některá volání přesunula z existujících uzlů na nové uzly.
Další informace najdete v tématu Škálování clusteru.
Volba platformy
Vzhledem k rozdílům v implementaci mezi operačními systémy může být zásadní součástí škálování aplikace volba Service Fabric s Windows nebo Linuxem. Jedním z potenciálních bariér je způsob provedení fázovaného protokolování. Service Fabric ve Windows používá ovladač jádra pro protokol 1 na počítač sdílený mezi replikami stavové služby. Tento protokol váží přibližně 8 GB. Linux na druhou stranu používá pro každou repliku přípravný protokol 256 MB, takže je méně ideální pro aplikace, které chtějí maximalizovat počet odlehčených replik služeb spuštěných na daném uzlu. Tyto rozdíly v dočasných požadavcích na úložiště by mohly potenciálně informovat požadovanou platformu pro nasazení clusteru Service Fabric.
Spojení všech součástí dohromady
Pojďme se podívat na všechny nápady, které jsme zde probrali, a probrat si příklad. Představte si následující službu: pokoušíte se vytvořit službu, která funguje jako adresář a drží jména a kontaktní údaje.
Máte přímo před sebou spoustu otázek týkajících se škálování: Kolik uživatelů budete mít? Kolikkontaktůch Snažíte se to všechno zjistit, když stojíte svou službu poprvé, je obtížné. Řekněme, že půjdete s jednou statickou službou s konkrétním počtem oddílů. Důsledky výběru nesprávného počtu oddílů můžou způsobit, že později budete mít problémy se škálováním. Podobně i v případě, že vyberete správný počet, možná nemáte všechny potřebné informace. Musíte se například rozhodnout o velikosti clusteru předem, a to jak z hlediska počtu uzlů, tak jejich velikostí. Obvykle je obtížné předpovědět, kolik prostředků bude služba spotřebovávat v průběhu své životnosti. Také může být obtížné předem zjistit vzor provozu, který služba skutečně vidí. Třeba lidé přidávají a odebírají kontakty jenom první věc ráno, nebo se třeba rovnoměrně distribuují v průběhu dne. V závislosti na tom možná budete muset škálovat kapacitu a dynamicky. Možná se naučíte předpovědět, kdy budete potřebovat horizontální navýšení kapacity, ale v obou případech budete pravděpodobně muset reagovat na změnu spotřeby prostředků vaší službou. To může zahrnovat změnu velikosti clusteru, aby bylo možné poskytnout více prostředků, když změna uspořádání stávajících prostředků nestačí.
Proč se ale dokonce pokusíte vybrat schéma jednoho oddílu pro všechny uživatele? Proč se omezit na jednu službu a jeden statický cluster? Skutečná situace je obvykle dynamičtější.
Při sestavování pro škálování zvažte následující dynamický vzor. Možná ho budete muset přizpůsobit své situaci:
- Místo toho, abyste se pokusili vybrat schéma dělení pro všechny uživatele předem, vytvořte "službu manažera".
- Úkolem služby manažera je podívat se na informace o zákazníce, když se zaregistrují do vaší služby. V závislosti na těchto informacích pak služba správce vytvoří instanci vaší skutečné služby úložiště kontaktů pouze pro daného zákazníka. Pokud vyžadují konkrétní konfiguraci, izolaci nebo upgrady, můžete se také rozhodnout, že pro tohoto zákazníka spustíte instanci aplikace.
Tento model dynamického vytváření má mnoho výhod:
- Nepokoušíte se odhadnout správný počet oddílů pro všechny uživatele předem nebo vytvořit jednu službu, která je nekonečně škálovatelná.
- Různí uživatelé nemusí mít stejný počet oddílů, počet replik, omezení umístění, metriky, výchozí načtení, názvy služeb, nastavení DNS nebo jakékoli jiné vlastnosti zadané na úrovni služby nebo aplikace.
- Získáte další segmentaci dat. Každý zákazník má vlastní kopii služby.
- Každou zákaznickou službu je možné nakonfigurovat jinak a udělit více nebo méně prostředků s více nebo méně oddíly nebo replikami podle potřeby na základě očekávaného škálování.
- Řekněme například, že zákazník zaplatil za úroveň Gold – mohl by získat více replik nebo vyšší počet oddílů a potenciálně prostředky vyhrazené pro své služby prostřednictvím metrik a kapacit aplikací.
- Nebo řekli, že zadali informace o počtu kontaktů, které potřebovali, bylo "Malé" – získali by jenom několik oddílů nebo by se dokonce mohli umístit do sdíleného fondu služeb s jinými zákazníky.
- Každou zákaznickou službu je možné nakonfigurovat jinak a udělit více nebo méně prostředků s více nebo méně oddíly nebo replikami podle potřeby na základě očekávaného škálování.
- Během čekání na zobrazení zákazníků neběží spousta instancí služeb ani replik.
- Pokud zákazník někdy odejde, odebráním informací z vaší služby stačí odstranit tuto službu nebo aplikaci, kterou vytvořil správce.
Další kroky
Další informace o konceptech Service Fabric najdete v následujících článcích: