Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Zjistěte, jak snadno rozšířit data ve vyhrazených fondech SQL pomocí prediktivních modelů strojového učení. Modely, které vaši datoví vědci vytvářejí, jsou teď snadno přístupné odborníkům na data pro prediktivní analýzu. Odborník na data ve službě Azure Synapse Analytics může jednoduše vybrat model z registru modelů služby Azure Machine Learning pro nasazení ve fondech Azure Synapse SQL a spustit předpovědi pro rozšiřování dat.
V tomto kurzu se naučíte:
- Vytrénovat prediktivní model strojového učení a zaregistrovat ho v registru modelů služby Azure Machine Learning.
- Spustit předpovědi ve vyhrazeném fondu SQL pomocí průvodce bodováním SQL.
Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet.
Požadavky
- Pracovní prostor Azure Synapse Analytics s účtem úložiště Azure Data Lake Storage Gen2 nakonfigurovaným jako výchozí úložiště. Musíte mít roli Storage Blob Data Contributor pro systém souborů Data Lake Storage Gen2, se kterým pracujete.
- Vyhrazený pool SQL v pracovním prostoru Azure Synapse Analytics Podrobnosti najdete v tématu Vytvoření vyhrazeného fondu SQL.
- Propojená služba Azure Machine Learning v pracovním prostoru Azure Synapse Analytics Podrobnosti najdete v tématu Vytvoření propojené služby Azure Machine Learning v Azure Synapse.
Přihlaste se k portálu Azure Portal.
Přihlaste se do Azure Portalu.
Trénování modelu ve službě Azure Machine Learning
Než začnete, ověřte, že vaše verze sklearnu je 0.20.3.
Před spuštěním všech buněk v poznámkovém bloku zkontrolujte, jestli je výpočetní instance spuštěná.
Přejděte do pracovního prostoru Azure Machine Learning.
Stáhnout Predict NYC Taxi Tips.ipynb.
Otevřete pracovní prostor Azure Machine Learning v nástroji Azure Machine Learning Studio.
Přejděte na poznámkové bloky>Nahrávání souborů. Pak vyberte soubor Predict NYC Taxi Tips.ipynb , který jste stáhli, a nahrajte ho.
Jakmile je poznámkový blok nahrán a otevřen, vyberte Spustit všechny buňky.
Jedna z buněk může selhat a požádat vás, abyste se ověřili v Azure. Sledujte to ve výstupech buňky a ověřte se v prohlížeči pomocí odkazu a zadáním kódu. Potom poznámkový blok znovu spusťte.
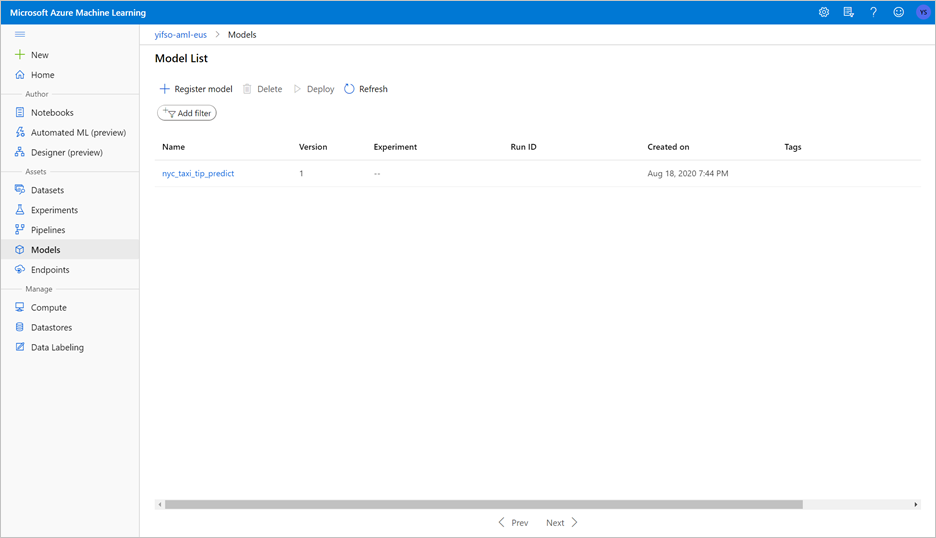
Poznámkový sešit vytrénuje model ONNX a zaregistruje jej v systému MLflow. Přejděte na Modely a zkontrolujte, jestli je nový model správně zaregistrovaný.
Spuštěním poznámkového bloku se také vyexportuje testovací data do souboru CSV. Stáhněte si soubor CSV do místního systému. Později importujete soubor CSV do vyhrazeného fondu SQL a použijete data k otestování modelu.
Soubor CSV se vytvoří ve stejné složce jako soubor poznámkového bloku. Pokud ji hned nevidíte, vyberte Aktualizovat v Průzkumníkovi souborů.
Spuštění předpovědí pomocí průvodce vyhodnocováním SQL
Otevřete pracovní prostor Azure Synapse pomocí nástroje Synapse Studio.
Přejděte na Data>Propojené>Účty úložišť. Nahrajte
test_data.csvdo výchozího účtu úložiště.
Přejděte na Vývoj>skriptů SQL. Vytvořte nový skript SQL pro načtení
test_data.csvdo vyhrazeného SQL poolu.Poznámka:
Před spuštěním souboru aktualizujte adresu URL souboru v tomto skriptu.
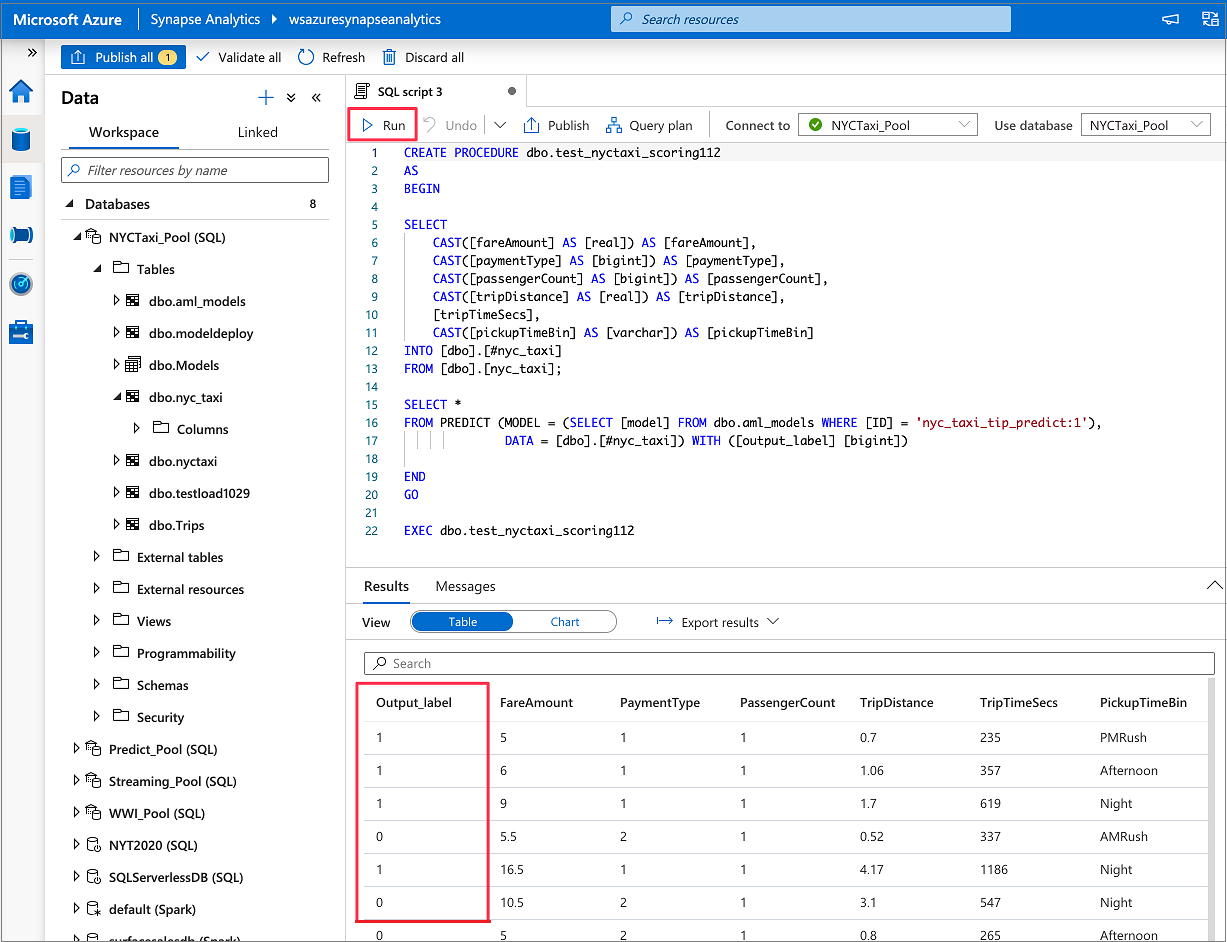
IF NOT EXISTS (SELECT * FROM sys.objects WHERE NAME = 'nyc_taxi' AND TYPE = 'U') CREATE TABLE dbo.nyc_taxi ( tipped int, fareAmount float, paymentType int, passengerCount int, tripDistance float, tripTimeSecs bigint, pickupTimeBin nvarchar(30) ) WITH ( DISTRIBUTION = ROUND_ROBIN, CLUSTERED COLUMNSTORE INDEX ) GO COPY INTO dbo.nyc_taxi (tipped 1, fareAmount 2, paymentType 3, passengerCount 4, tripDistance 5, tripTimeSecs 6, pickupTimeBin 7) FROM '<URL to linked storage account>/test_data.csv' WITH ( FILE_TYPE = 'CSV', ROWTERMINATOR='0x0A', FIELDQUOTE = '"', FIELDTERMINATOR = ',', FIRSTROW = 2 ) GO SELECT TOP 100 * FROM nyc_taxi GO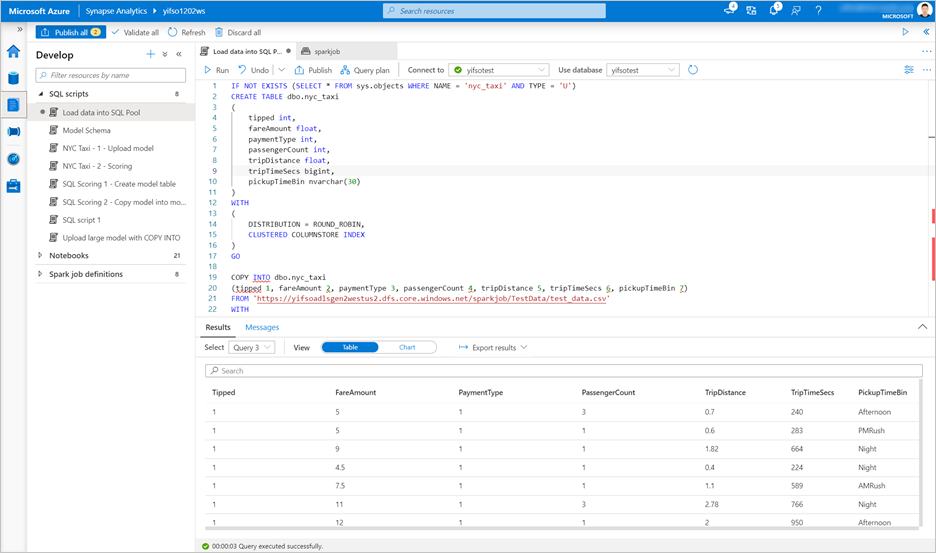
Přejděte do datového>pracovního prostoru. Otevřete průvodce hodnocením SQL tak, že kliknete pravým tlačítkem myši na vyhrazenou tabulku fondu SQL. Vyberte Strojové učení>Předpovědět pomocí modelu.
Poznámka:
Možnost strojového učení se nezobrazí, pokud nemáte vytvořenou propojenou službu pro Azure Machine Learning. (Viz požadavky na začátku tohoto kurzu.)
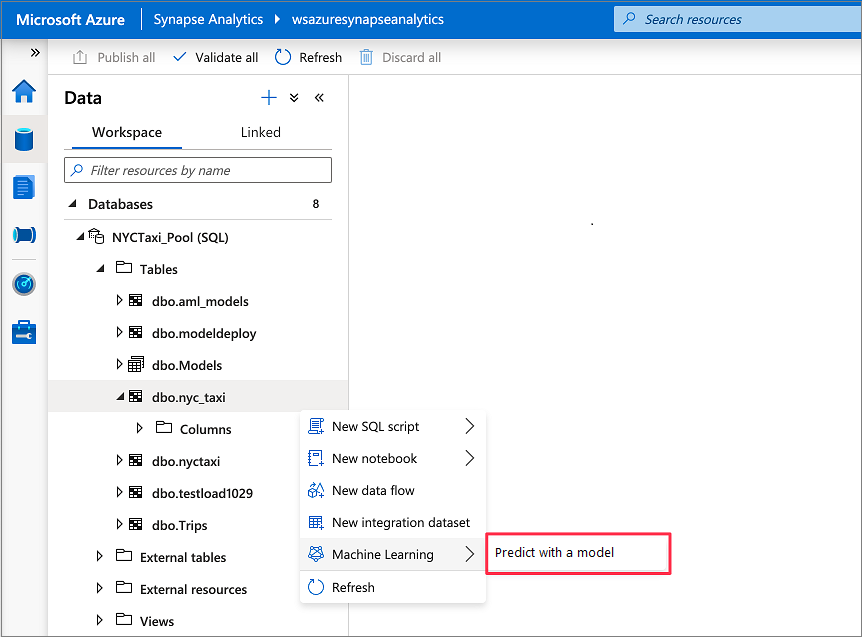
V rozevíracím seznamu vyberte propojený pracovní prostor Azure Machine Learning. Tento krok načte seznam modelů strojového učení z registru modelů zvoleného pracovního prostoru Azure Machine Learning. V současné době se podporují jenom modely ONNX, takže tento krok zobrazí jenom modely ONNX.
Vyberte model, který jste právě natrénovali, a pak vyberte Pokračovat.
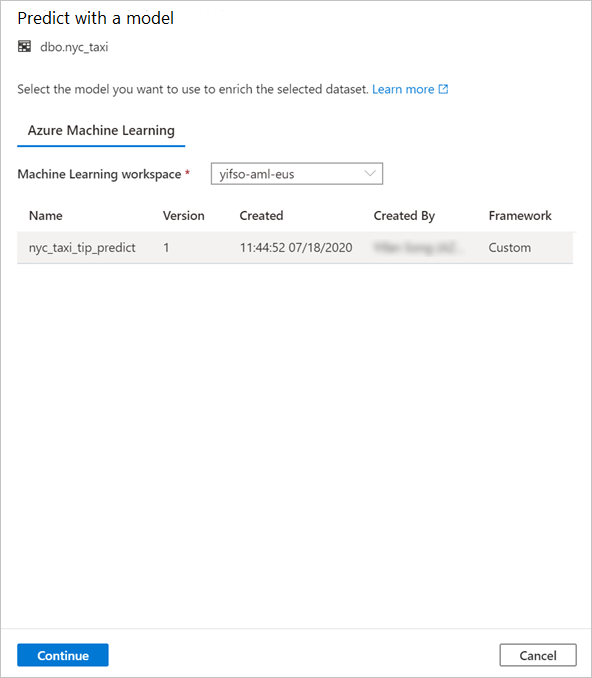
Namapujte sloupce tabulky na vstupy modelu a zadejte výstupy modelu. Pokud je model uložený ve formátu MLflow a podpis modelu se vyplní, mapování se provede automaticky pomocí logiky založené na podobnosti názvů. Rozhraní také podporuje ruční mapování.
Zvolte Pokračovat.
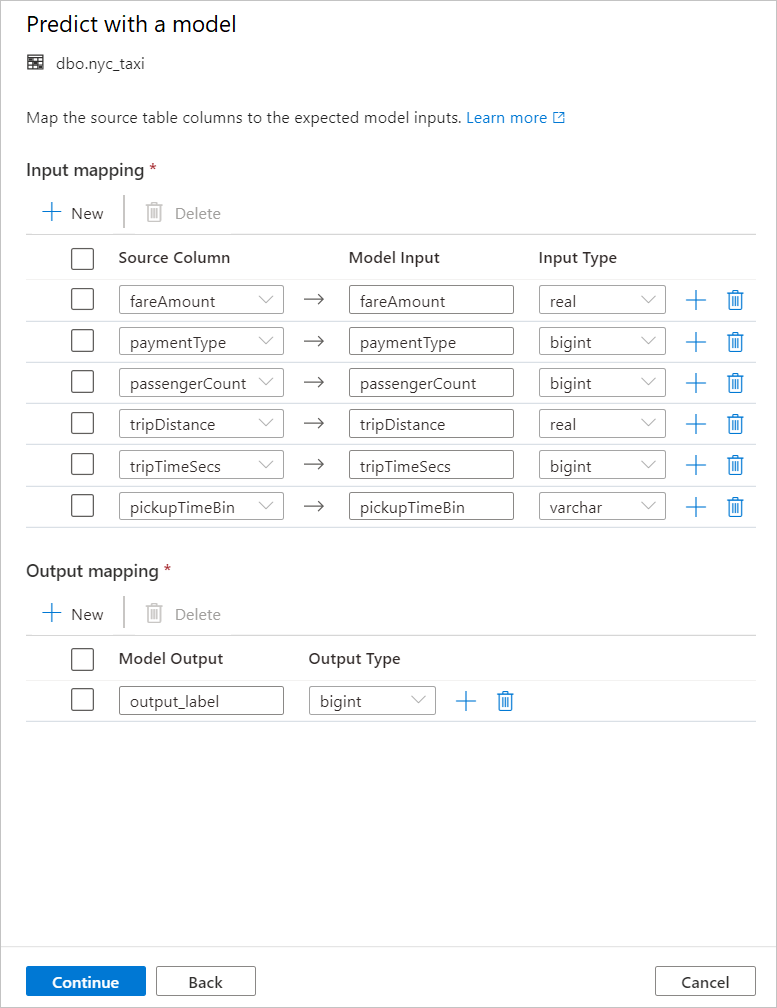
Vygenerovaný kód T-SQL je zabalen uvnitř uložené procedury. Proto potřebujete zadat název uložené procedury. Binární soubor modelu, včetně metadat (verze, popis a další informace), se fyzicky zkopíruje ze služby Azure Machine Learning do vyhrazené tabulky fondu SQL. Proto musíte určit, do které tabulky chcete model uložit.
Můžete zvolit existující tabulku nebo vytvořit novou. Až budete hotovi, vyberte Nasadit model + otevřít skript pro nasazení modelu a vygenerujte prediktivní skript T-SQL.
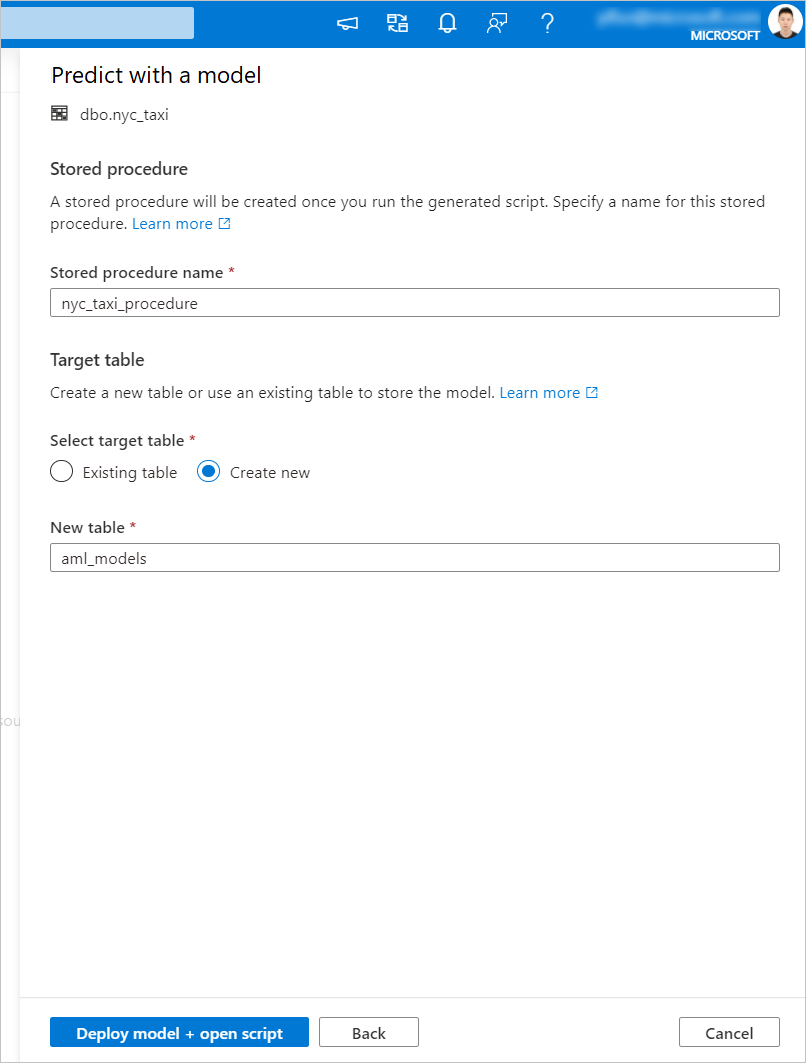
Po vygenerování skriptu vyberte Spustit a spusťte bodování a získejte předpovědi.