Poznámka
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tento článek je druhou částí sedmidílné série, která obsahuje pokyny k migraci z Netezza do Azure Synapse Analytics. Tento článek se zaměřuje na osvědčené postupy pro ETL a migraci zatížení.
Aspekty migrace dat
Počáteční rozhodnutí o migraci dat z Netezza
Při migraci datového skladu Netezza se musíte zeptat na některé základní otázky související s daty. Například:
Měly by se migrovat nepoužívané struktury tabulek?
Jaký je nejlepší přístup k migraci, který minimalizuje riziko a dopad na uživatele?
Při migraci datových tržišť: zůstat u fyzických nebo přejít k virtuálním?
V dalších částech jsou tyto body popsány v kontextu migrace z Netezza.
Chcete migrovat nepoužívané tabulky?
Návod
Ve starších systémech není neobvyklé, že se tabulky v průběhu času stanou redundantními – ve většině případů je není potřeba migrovat.
Dává smysl migrovat pouze tabulky, které se používají v existujícím systému. Tabulky, které nejsou aktivní, je možné místo migrace archivovat, aby byla data v případě potřeby k dispozici v budoucnu. Nejlepší je použít systémová metadata a protokolové soubory místo dokumentace k určení, které tabulky se používají, protože dokumentace může být zastaralá.
Pokud je tato možnost povolená, tabulky historie dotazů Netezza obsahují informace, které můžou určit, kdy byla daná tabulka naposledy přístupná– která se pak dá použít k rozhodnutí, jestli je tabulka kandidátem na migraci.
Tady je příklad dotazu, který hledá použití konkrétní tabulky v daném časovém intervalu:
SELECT FORMAT_TABLE_ACCESS (usage),
hq.submittime
FROM "$v_hist_queries" hq
INNER JOIN "$hist_table_access_3" hta USING
(NPSID, NPSINSTANCEID, OPID, SESSIONID)
WHERE hq.dbname = 'PROD'
AND hta.schemaname = 'ADMIN'
AND hta.tablename = 'TEST_1'
AND hq.SUBMITTIME > '01-01-2015'
AND hq.SUBMITTIME <= '08-06-2015'
AND
(
instr(FORMAT_TABLE_ACCESS(usage),'ins') > 0
OR instr(FORMAT_TABLE_ACCESS(usage),'upd') > 0
OR instr(FORMAT_TABLE_ACCESS(usage),'del') > 0
)
AND status=0;
| FORMAT_TABLE_ACCESS | SUBMITTIME
----------------------+---------------------------
ins | 2015-06-16 18:32:25.728042
ins | 2015-06-16 17:46:14.337105
ins | 2015-06-16 17:47:14.430995
(3 rows)
Tento dotaz používá pomocnou funkci FORMAT_TABLE_ACCESS a číslici na konci $v_hist_table_access_3 zobrazení tak, aby odpovídala nainstalované verzi historie dotazů.
Jaký je nejlepší přístup k migraci, který minimalizuje riziko a dopad na uživatele?
Tato otázka se často objevuje, protože společnosti můžou chtít snížit dopad změn na datový model datového skladu, aby se zlepšila flexibilita. Společnosti často vidí příležitost k další modernizaci nebo transformaci dat během migrace ETL. Tento přístup přináší vyšší riziko, protože současně mění více faktorů, což ztěžuje porovnání výsledků starého systému a nových. Provádění změn datového modelu zde může mít vliv také na předřazené nebo následné úlohy ETL v jiných systémech. Z tohoto rizika je lepší po migraci datového skladu přepracovat toto škálování.
I když se datový model záměrně mění v rámci celkové migrace, je dobré stávající model migrovat tak, jak je, do Azure Synapse, místo toho, abyste ho přepracovávali na nové platformě. Tento přístup minimalizuje vliv na stávající produkční systémy a zároveň přináší výhody z výkonu a elastické škálovatelnosti platformy Azure pro jednorázové opětovné technické úlohy.
Při migraci z Netezza je často stávající datový model vhodný pro as-is migraci do Azure Synapse.
Návod
Migrujte stávající model tak, jak je na začátku, i když je v budoucnu naplánována změna datového modelu.
Migrace datových skladů: Zůstat fyzický nebo přejít na virtuální?
Návod
Virtualizace datových mart může ušetřit na prostředcích úložiště a zpracování.
In legacy Netezza data warehouse environments, it's common practice to create several data marts that are structured to provide good performance for ad hoc self-service queries and reports for a given department or business function within an organization. Datové tržiště se obvykle skládá z podmnožina datového skladu a obsahuje agregované verze dat ve formě, která uživatelům umožňuje snadno dotazovat tato data pomocí uživatelsky přívětivých nástrojů pro dotazy, jako jsou Microsoft Power BI, Tableau nebo MicroStrategy. Tento formulář je obvykle dimenzionálním datovým modelem. Jedním z použití datových mart je zveřejnění dat v použitelné podobě, i když je podkladový datový model skladu něco jiného, například trezor dat.
K implementaci robustních režimů zabezpečení dat můžete použít samostatná datová tržiště pro jednotlivé organizační jednotky v rámci organizace, a to tím, že uživatelům umožníte přístup pouze k určitým datovým martům, které jsou pro ně relevantní, a eliminují, obfuskují nebo anonymizují citlivá data.
Pokud jsou tato datová tržiště implementovaná jako fyzické tabulky, budou vyžadovat další prostředky úložiště, které je budou ukládat, a další zpracování, aby je bylo možné pravidelně sestavovat a aktualizovat. Také data v datovém skladu budou aktuální pouze do doby poslední operace aktualizace, a proto nemusí být vhodná pro vysoce nestálé informační panely.
Návod
Výkon a škálovatelnost Služby Azure Synapse umožňuje virtualizaci bez snížení výkonu.
S nástupem relativně nízkonákladových škálovatelných architektur MPP, jako je Azure Synapse, a souvisejících charakteristik výkonu takových architektur může být, že můžete poskytovat funkce datového tržiště, aniž byste museli vytvořit instanci tržiště jako sadu fyzických tabulek. Toho dosáhnete efektivní virtualizací datových mart prostřednictvím zobrazení SQL do hlavního datového skladu nebo prostřednictvím virtualizační vrstvy pomocí funkcí, jako jsou zobrazení v Azure nebo vizualizačních produktů partnerů Microsoftu. Tento přístup zjednodušuje nebo eliminuje potřebu dalšího zpracování úložiště a agregace a snižuje celkový počet databázových objektů, které se mají migrovat.
Tento přístup může přinést další potenciální výhodu. Implementací logiky agregace a spojení v rámci vrstvy virtualizace a prezentováním externích nástrojů pro vytváření sestav prostřednictvím virtualizovaného zobrazení se zpracování potřebné k vytvoření těchto zobrazení "odsune" do datového skladu, což je obecně nejlepší místo pro spouštění spojení, agregací a dalších souvisejících operací s velkými objemy dat.
Primárními faktory pro volbu implementace virtuálního datového tržiště přes fyzické datové tržiště jsou:
Větší flexibilita: Virtuální datové tržiště se snadněji mění než fyzické tabulky a přidružené procesy ETL.
Nižší celkové náklady na vlastnictví: Virtualizovaná implementace vyžaduje méně úložišť dat a kopií dat.
Odstranění úloh ETL pro migraci a zjednodušení architektury datového skladu ve virtualizovaném prostředí
Performance: although physical data marts have historically been more performant, virtualization products now implement intelligent caching techniques to mitigate.
Migrace dat z Netezza
Pochopení vašich dat
Součástí plánování migrace je podrobný přehled objemu dat, která je potřeba migrovat, protože to může mít vliv na rozhodnutí o přístupu k migraci. Pomocí systémových metadat určete fyzický prostor zabraný "nezpracovanými daty" v tabulkách, které mají být migrovány. V tomto kontextu "nezpracovaná data" znamená množství místa používaného řádky dat v tabulce, s výjimkou režijních nákladů, jako jsou indexy a komprese. To platí zejména pro největší tabulky faktů, protože tyto tabulky obvykle obsahují více než 95% dat.
Přesné číslo objemu dat, která se mají migrovat pro danou tabulku, můžete získat extrahováním reprezentativního vzorku dat (například jednoho milionu řádků) do nekomprimovaného plochého datového souboru ASCII s oddělovači. Potom pomocí velikosti tohoto souboru získáte průměrnou nezpracovanou velikost dat na řádek této tabulky. Nakonec vynásobte průměrnou velikost celkovým počtem řádků v celé tabulce, abyste získali velikost datové tabulky v surové podobě. V plánování použijte tuto nezpracovanou velikost dat.
Mapování datových typů Netezza
Návod
Vyhodnoťte dopad nepodporovaných datových typů v rámci přípravné fáze.
Většina datových typů Netezza má v Azure Synapse přímý ekvivalent. Následující tabulka uvádí tyto datové typy společně s doporučeným přístupem k jejich mapování.
| Datový typ Netezza | Datový typ Azure Synapse |
|---|---|
| BIGINT | BIGINT |
| BINARY VARYING(n) | VARBINARY(n) |
| BOOLEAN | BIT |
| BYTEINT | TINYINT |
| CHARACTER VARYING(n) | VARCHAR(n) |
| CHARACTER(n) | CHAR(n) |
| Datum | DATE(date) |
| DECIMAL(p,s) | DECIMAL(p,s) |
| DVOJITÁ PŘESNOST | FLOAT |
| FLOAT(n) | FLOAT(n) |
| INTEGER | INT |
| INTERVAL | Datové typy INTERVAL se v současné době nepodporují přímo ve službě Azure Synapse Analytics, ale dají se vypočítat pomocí dočasných funkcí, jako je DATEDIFF. |
| MONEY | MONEY |
| NATIONAL CHARACTER VARYING(n) | NVARCHAR(n) |
| NÁRODNÍ ZNAK(n) | NCHAR(n) |
| NUMERIC(p,s) | NUMERIC(p,s) |
| REAL | REAL |
| SMALLINT | SMALLINT |
| ST_GEOMETRY(n) | Azure Synapse Analytics v současné době nepodporuje prostorové datové typy, jako je například ST_GEOMETRY, ale data můžou být uložená jako VARCHAR nebo VARBINARY. |
| ČAS | ČAS |
| TIME WITH TIME ZONE | DATETIMEOFFSET |
| ČASOVÁ ZNAČKA | DATETIME |
Pomocí metadat z tabulek katalogu Netezza určete, jestli je potřeba migrovat některý z těchto datových typů, a povolit to ve vašem plánu migrace. Důležitá zobrazení metadat v Netezza pro tento typ dotazu jsou:
_V_USER: Uživatelský pohled poskytuje informace o uživatelích v systému Netezza._V_TABLE: Zobrazení tabulky obsahuje seznam tabulek vytvořených v systému výkonu Netezza._V_RELATION_COLUMN: Zobrazení katalogu systému relačních sloupců obsahuje sloupce dostupné v tabulce._V_OBJECTS: Zobrazení objektů uvádí různé objekty, jako jsou tabulky, zobrazení, funkce atd., které jsou k dispozici v Netezza.
Například tento dotaz Netezza SQL zobrazuje sloupce a typy sloupců:
SELECT
tablename,
attname AS COL_NAME,
b.FORMAT_TYPE AS COL_TYPE,
attnum AS COL_NUM
FROM _v_table a
JOIN _v_relation_column b
ON a.objid = b.objid
WHERE a.tablename = 'ATT_TEST'
AND a.schema = 'ADMIN'
ORDER BY attnum;
TABLENAME | COL_NAME | COL_TYPE | COL_NUM
----------+-------------+----------------------+--------
ATT_TEST | COL_INT | INTEGER | 1
ATT_TEST | COL_NUMERIC | NUMERIC(10,2) | 2
ATT_TEST | COL_VARCHAR | CHARACTER VARYING(5) | 3
ATT_TEST | COL_DATE | DATE | 4
(4 rows)
Dotaz lze upravit tak, aby prohledával všechny tabulky a hledal jakékoliv výskyty nepodporovaných datových typů.
Azure Data Factory se dá použít k přesunu dat ze starší verze prostředí Netezza. Další informace naleznete v tématu IBM Netezza Connector.
Dodavatelé třetích stran nabízejí nástroje a služby pro automatizaci migrace, včetně mapování datových typů, jak jsme popsali dříve. Nástroje ETL třetích stran, jako jsou Informatica nebo Talend, už se používají v prostředí Netezza, mohou implementovat všechny požadované transformace dat. V další části se seznámíte s migrací stávajících procesů ETL třetích stran.
Aspekty migrace ETL
Počáteční rozhodnutí ohledně migrace Netezza ETL
Návod
Naplánujte přístup k migraci ETL předem a podle potřeby využijte zařízení Azure.
Pro zpracování ETL/ELT mohou starší datové sklady Netezza používat vlastní skripty využívající nástroje Netezza, jako jsou nzsql a nzload, nebo nástroje ETL třetích stran, jako jsou Informatica nebo Ab Initio. Někdy datové sklady Netezza používají kombinaci přístupů ETL a ELT, které se v průběhu času vyvíjejí. Při plánování migrace do Azure Synapse je potřeba určit nejlepší způsob implementace požadovaného zpracování ETL/ELT v novém prostředí a současně minimalizovat náklady a rizika. Další informace o zpracování ETL a ELT najdete v tématu ELT vs. Přístup k návrhu ETL.
V následujících částech najdete informace o možnostech migrace a doporučení pro různé případy použití. Tento vývojový diagram shrnuje jeden přístup:
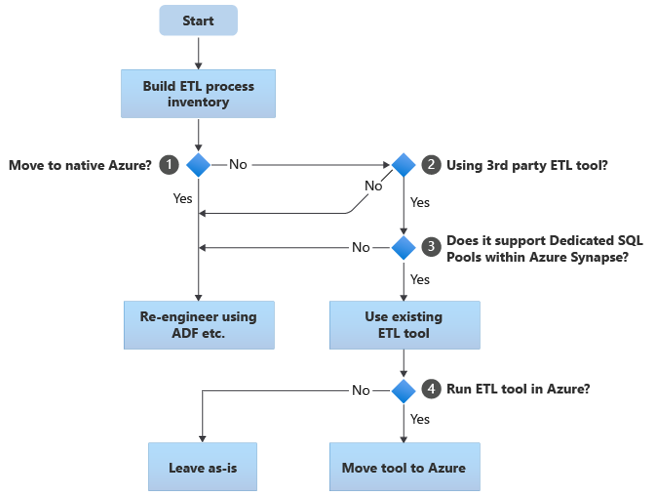
Prvním krokem je vždy sestavení inventáře procesů ETL/ELT, které je potřeba migrovat. Je možné, že podobně jako u jiných kroků, standardní integrované funkce Azure způsobí, že nebude nutné migrovat některé existující procesy. Pro účely plánování je důležité pochopit rozsah migrace, který se má provést.
V předchozím vývojovém diagramu se rozhodnutí 1 týká rozhodnutí vysoké úrovně o tom, jestli se má migrovat do zcela nativního prostředí Azure. Pokud přecházíte do zcela nativního prostředí Azure, doporučujeme přepracovat zpracování ETL pomocí kanálů a aktivit ve službě Azure Data Factory nebo Azure Synapse Pipelines. Pokud nepřesouváte do zcela nativního prostředí Azure, rozhodnutí 2 je, jestli už se používá existující nástroj ETL třetích stran.
Návod
Využijte investice do stávajících nástrojů třetích stran ke snížení nákladů a rizik.
Pokud už se používá nástroj ETL třetí strany, a to zejména v případě, že existuje velká investice do dovedností nebo několika stávajících pracovních postupů a plánů, pak rozhodnutí 3 spočívá v tom, jestli nástroj dokáže efektivně podporovat Azure Synapse jako cílové prostředí. Nástroj v ideálním případě bude obsahovat "nativní" konektory, které můžou využívat zařízení Azure, jako je PolyBase nebo COPY INTO, pro nejúčinnější načítání dat. Existuje způsob, jak volat externí proces, například PolyBase nebo COPY INTO, a předat příslušné parametry. V tomto případě využijte stávající dovednosti a pracovní postupy s Azure Synapse jako novým cílovým prostředím.
Pokud se rozhodnete zachovat existující nástroj ETL třetí strany, může být výhodné spustit tento nástroj v prostředí Azure (namísto na existujícím lokálním serveru ETL) a nechat Azure Data Factory řídit celkovou orchestraci stávajících pracovních postupů. Jednou z konkrétních výhod je to, že méně dat je potřeba stáhnout z Azure, zpracovat a nahrát zpět do Azure. Rozhodnutí 4 tedy spočívá v tom, jestli stávající nástroj necháte spuštěný as-is, nebo ho přesunete do prostředí Azure, abyste dosáhli výhod nákladů, výkonu a škálovatelnosti.
Překonstruovat existující skripty specifické pro Netezza
Pokud některé nebo všechny existující zpracování ETL/ELT skladu Netezza zpracovává vlastní skripty, které využívají nástroje specifické pro Netezza, jako je například nzsql nebo nzload, je potřeba tyto skripty překódovat pro nové prostředí Azure Synapse. Podobně platí, že pokud byly procesy ETL implementovány pomocí uložených procedur v Netezza, bude nutné je také překódovat.
Návod
Inventář úloh ETL, které se mají migrovat, by měly zahrnovat skripty a uložené procedury.
Některé prvky procesu ETL se dají snadno migrovat, například jednoduchým hromadným načtením dat do pracovní tabulky z externího souboru. Tyto části procesu je možné dokonce automatizovat, například pomocí PolyBase místo nzloadu. Další části procesu, které obsahují libovolné složité procedury SQL a/nebo uložené procedury, budou trvat delší dobu, než se překonstruují.
Jedním ze způsobů, jak otestovat kompatibilitu Netezza SQL s Azure Synapse, je zachytit některé reprezentativní příkazy SQL z historie dotazů Netezza, pak tyto dotazy předcházet prefixem EXPLAIN, a potom – za předpokladu, že existuje stejný migrovaný datový model v Azure Synapse – tyto příkazy spustit EXPLAIN v Azure Synapse. Jakékoli nekompatibilní SQL vygeneruje chybu a informace o chybě můžou určit měřítko úlohy přepočítávání.
Partneři Microsoftu nabízejí nástroje a služby pro migraci Netezza SQL a uložených procedur do Azure Synapse.
Použití nástrojů ETL třetích stran
Jak je popsáno v předchozí části, v mnoha případech se stávající starší systém datového skladu již naplní a udržuje produkty ETL třetích stran. Seznam partnerů microsoftu pro integraci dat pro Azure Synapse najdete v tématu Partneři pro integraci dat.
Načítání dat z Netezza
Možnosti dostupné při načítání dat z Netezza
Návod
Nástroje třetích stran můžou proces migrace zjednodušit a automatizovat a snížit tak riziko.
Pokud jde o migraci dat z datového skladu Netezza, existují některé základní otázky spojené s načítáním dat, které je potřeba vyřešit. Budete se muset rozhodnout, jak se budou data fyzicky přesouvat z existujícího místního prostředí Netezza do Azure Synapse v cloudu a jaké nástroje se použijí k provedení přenosu a načítání. Podívejte se na následující otázky, které jsou popsány v dalších částech.
Extrahujete data do souborů nebo je přesunete přímo přes síťové připojení?
Orchestrujete proces ze zdrojového systému nebo z cílového prostředí Azure?
Které nástroje použijete k automatizaci a správě procesu?
Přenos dat prostřednictvím souborů nebo síťového připojení?
Návod
Seznamte se s objemy dat, které se mají migrovat, a dostupnou šířku pásma sítě, protože tyto faktory ovlivňují rozhodování o přístupu k migraci.
Po vytvoření databázových tabulek, které se mají migrovat v Azure Synapse, můžete přesunout data, abyste tyto tabulky naplnili ze staršího systému Netezza a do nového prostředí. Existují dva základní přístupy:
Extrakce souboru: extrahujte data z tabulek Netezza do plochých souborů, obvykle ve formátu CSV, prostřednictvím nzsql s možností -o nebo příkazem
CREATE EXTERNAL TABLE. Externí tabulku používejte, kdykoli je to možné, protože je to nejúčinnější z hlediska propustnosti dat. Následující příklad SQL vytvoří soubor CSV prostřednictvím externí tabulky:CREATE EXTERNAL TABLE '/data/export.csv' USING (delimiter ',') AS SELECT col1, col2, expr1, expr2, col3, col1 || col2 FROM your table;Externí tabulku použijte, pokud exportujete data do připojeného systému souborů na místním hostiteli Netezza. Pokud exportujete data do vzdáleného počítače, na kterém je nainstalováno rozhraní JDBC, ODBC, nebo OLEDB, pak je pro vás možnost "remotesource odbc" definována klauzulí
USING.Tento přístup vyžaduje místo na uložení extrahovaných datových souborů. Prostor může být místní pro zdrojovou databázi Netezza (pokud je k dispozici dostatečné úložiště) nebo vzdálený ve službě Azure Blob Storage. Nejlepšího výkonu dosáhnete při místním zápisu souboru, protože se tím zabrání režijním nákladům na síť.
Pokud chcete minimalizovat požadavky na úložiště a přenos sítě, je vhodné komprimovat extrahované datové soubory pomocí nástroje, jako je gzip.
Po extrahování je možné ploché soubory přesunout do služby Azure Blob Storage (sloučit s cílovou instancí Azure Synapse), nebo je načíst přímo do Azure Synapse pomocí PolyBase nebo COPY INTO. Metoda fyzického přesunu dat z místního místního úložiště do cloudového prostředí Azure závisí na množství dat a dostupné šířce pásma sítě.
Microsoft nabízí různé možnosti přesunu velkých objemů dat, včetně AzCopy pro přesun souborů přes síť do služby Azure Storage, Azure ExpressRoute pro přesun hromadných dat přes privátní síťové připojení, a Azure Data Box pro soubory, které se přesunou do fyzického úložného zařízení, které se pak odešle do datového centra Azure pro načítání. Další informace najdete v tématu přenos dat.
Přímé extrahování a načítání napříč sítí: cílové prostředí Azure odesílá požadavek na extrakci dat( obvykle prostřednictvím příkazu SQL) do staršího systému Netezza, který extrahuje data. Výsledky se odesílají přes síť a načtou se přímo do Azure Synapse, aniž by bylo nutné přikládat data do zprostředkujících souborů. Limitující faktor v tomto scénáři je obvykle šířka pásma síťového připojení mezi databází Netezza a prostředím Azure. U velmi velkých objemů dat nemusí být tento přístup praktický.
Existuje také hybridní přístup, který používá obě metody. Můžete například použít přímý přístup k extrakci sítě pro menší tabulky dimenzí a ukázky větších tabulek faktů a rychle poskytnout testovací prostředí v Azure Synapse. U velkých objemů historických tabulek faktů můžete použít přístup k extrakci a přenosu souborů pomocí Azure Data Boxu.
Řídit z Netezza nebo Azure?
Doporučeným přístupem při přechodu na Azure Synapse je orchestrace extrakce a načítání dat z prostředí Azure pomocí azure Synapse Pipelines nebo Azure Data Factory a přidružených nástrojů, jako je PolyBase nebo COPY INTO, pro nejúčinnější načítání dat. Tento přístup využívá funkce Azure a poskytuje jednoduchou metodu pro vytváření opakovaně použitelných kanálů načítání dat.
Mezi další výhody tohoto přístupu patří snížení dopadu na systém Netezza během procesu načítání dat, protože proces správy a načítání běží v Azure, a možnost automatizovat proces pomocí kanálů načítání dat řízených metadaty.
Které nástroje je možné použít?
Úkolem transformace a přesunu dat je základní funkce všech produktů ETL. Pokud se některý z těchto produktů už používá v existujícím prostředí Netezza, může použití existujícího nástroje ETL zjednodušit migraci dat z Netezza do Azure Synapse. Tento přístup předpokládá, že nástroj ETL podporuje Azure Synapse jako cílové prostředí. Další informace o nástrojích, které podporují Azure Synapse, najdete v tématu Partneři pro integraci dat.
Pokud používáte nástroj ETL, zvažte spuštění nástroje v prostředí Azure, abyste mohli využívat výhod cloudového výkonu Azure, škálovatelnosti a nákladů a uvolnit prostředky v datovém centru Netezza. Další výhodou je snížení přesunu dat mezi cloudem a místním prostředím.
Shrnutí
Shrnutím našich doporučení pro migraci dat a přidružených procesů ETL z Netezza do Azure Synapse jsou:
Naplánujte si předem, abyste zajistili úspěšný proces migrace.
Vytvořte podrobný inventář dat a procesů, které se mají migrovat co nejdříve.
Pomocí systémových metadat a souborů protokolů získáte přesné znalosti o využití dat a procesů. Nespoléhejte na dokumentaci, protože možná není aktuální.
Seznamte se s objemy dat, které se mají migrovat, a šířku pásma sítě mezi místním datovým centrem a cloudovými prostředími Azure.
Využijte standardní integrované funkce Azure k minimalizaci úloh migrace.
Identifikujte a seznamte se s nejúčinnějšími nástroji pro extrakci a načítání dat v prostředích Netezza i Azure. V každé fázi procesu použijte příslušné nástroje.
Pomocí zařízení Azure, jako jsou Azure Synapse Pipelines nebo Azure Data Factory, můžete orchestrovat a automatizovat proces migrace a zároveň minimalizovat dopad na systém Netezza.
Další kroky
Další informace o operacích přístupu k zabezpečení najdete v dalším článku této série: Zabezpečení, přístup a operace pro migrace Netezza.