Kopírování dat z Netezza pomocí služby Azure Data Factory nebo Synapse Analytics
PLATÍ PRO:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Tento článek popisuje, jak pomocí aktivity kopírování v kanálech Azure Data Factory nebo Synapse Analytics kopírovat data z Netezza. Článek vychází z aktivity kopírování, která představuje obecný přehled aktivity kopírování.
Tip
Pokud chcete použít scénář migrace dat z Netezza do Azure, přečtěte si další informace o migraci dat z místního serveru Netezza do Azure.
Podporované funkce
Tento konektor Netezza je podporovaný pro následující funkce:
| Podporované funkce | IR |
|---|---|
| aktivita Copy (zdroj/-) | (1) (2) |
| Aktivita Lookup | (1) (2) |
(1) Prostředí Azure Integration Runtime (2) Místní prostředí Integration Runtime
Seznam úložišť dat, která aktivita kopírování podporuje jako zdroje a jímky, najdete v tématu Podporované úložiště a formáty dat.
Konektor Netezza podporuje paralelní kopírování ze zdroje. Podrobnosti najdete v části Paralelní kopie z Netezza .
Služba poskytuje integrovaný ovladač, který umožňuje připojení. Abyste mohli tento konektor používat, nemusíte ručně instalovat žádný ovladač.
Požadavky
Pokud se vaše úložiště dat nachází uvnitř místní sítě, virtuální sítě Azure nebo amazonového privátního cloudu, musíte nakonfigurovat místní prostředí Integration Runtime pro připojení k němu.
Pokud je vaše úložiště dat spravovanou cloudovou datovou službou, můžete použít Azure Integration Runtime. Pokud je přístup omezený na IP adresy schválené v pravidlech brány firewall, můžete do seznamu povolených přidat IP adresy prostředí Azure Integration Runtime.
K přístupu k místní síti bez nutnosti instalace a konfigurace místního prostředí Integration Runtime můžete také použít funkci Runtime integrace spravované virtuální sítě ve službě Azure Data Factory.
Další informace o mechanismech zabezpečení sítě a možnostech podporovaných službou Data Factory najdete v tématu Strategie přístupu k datům.
Začínáme
Kanál, který používá aktivitu kopírování, můžete vytvořit pomocí sady .NET SDK, sady Python SDK, Azure PowerShellu, rozhraní REST API nebo šablony Azure Resource Manageru. Podrobné pokyny k vytvoření kanálu s aktivitou kopírování najdete v kurzuaktivita kopírování.
Vytvoření propojené služby do Netezza pomocí uživatelského rozhraní
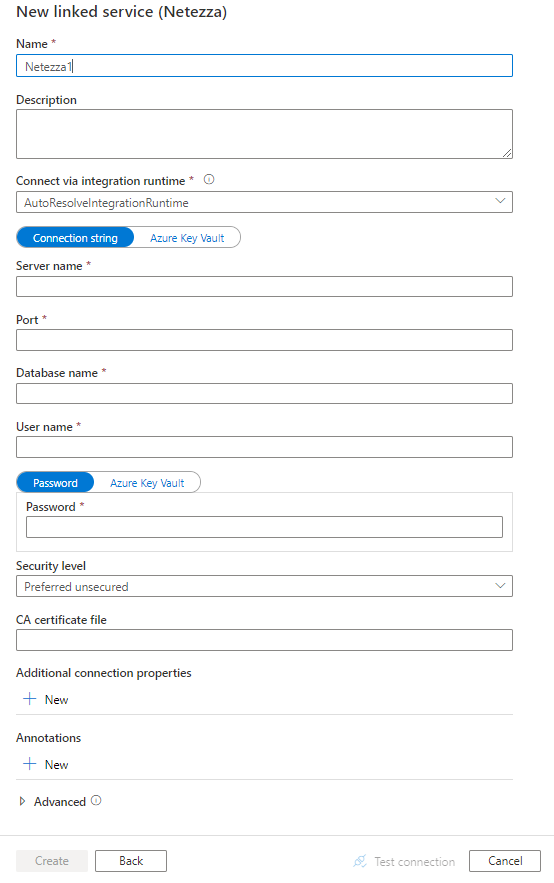
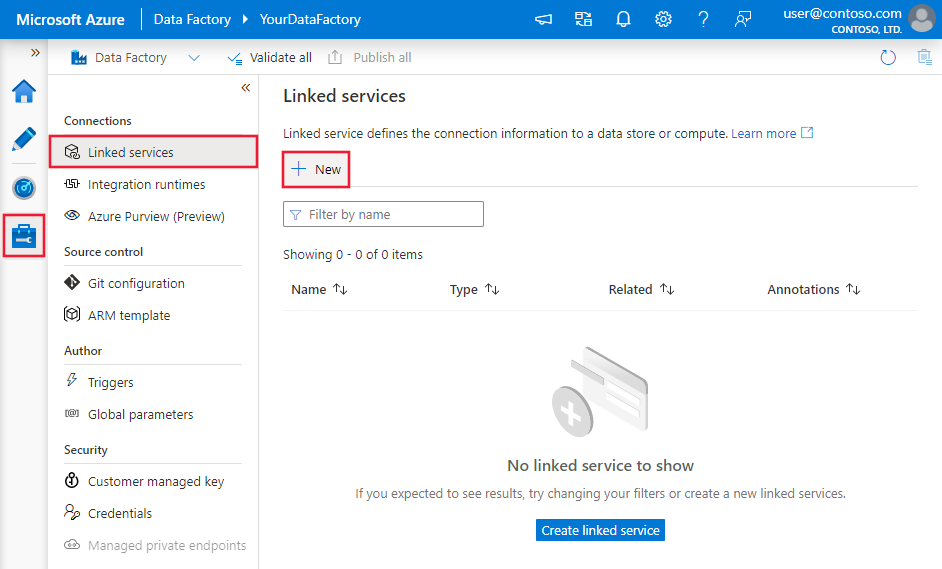
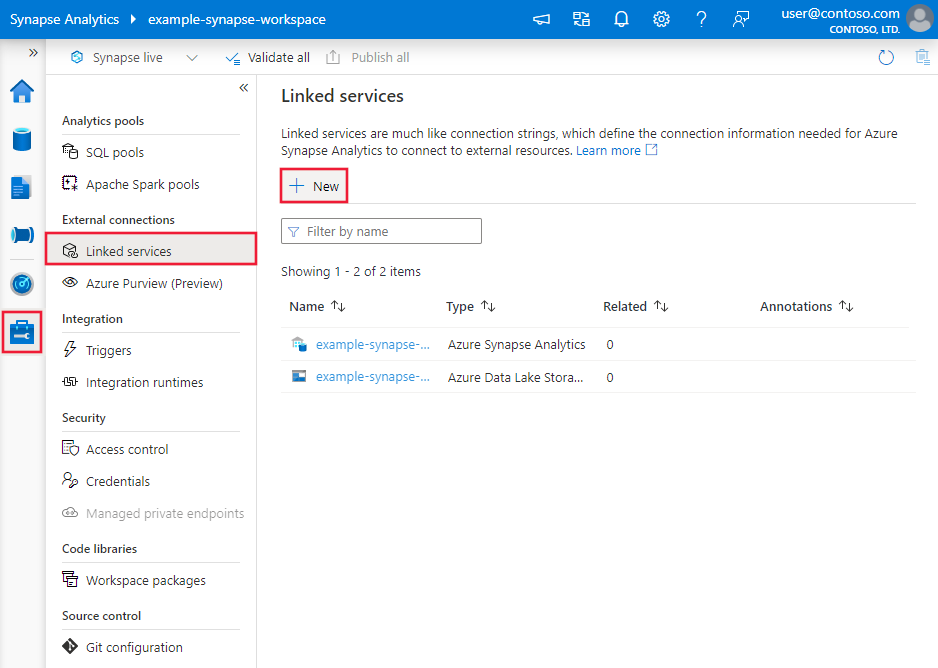
Pomocí následujícího postupu vytvořte propojenou službu s Netezza v uživatelském rozhraní webu Azure Portal.
Přejděte na kartu Správa v pracovním prostoru Azure Data Factory nebo Synapse a vyberte Propojené služby a pak klikněte na Nový:
Vyhledejte Netezza a vyberte konektor Netezza.

Nakonfigurujte podrobnosti o službě, otestujte připojení a vytvořte novou propojenou službu.
Podrobnosti konfigurace konektoru
Následující části obsahují podrobnosti o vlastnostech, které můžete použít k definování entit specifických pro konektor Netezza.
Vlastnosti propojené služby
Propojená služba Netezza podporuje následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu musí být nastavena na Netezza. | Ano |
| připojovací řetězec | Rozhraní ODBC připojovací řetězec pro připojení k Netezza. Můžete také zadat heslo do služby Azure Key Vault a vytáhnout pwd konfiguraci z připojovací řetězec. Další podrobnosti najdete v následujících ukázkách a ukládání přihlašovacích údajů ve službě Azure Key Vault . |
Ano |
| connectVia | Prostředí Integration Runtime , které se má použít pro připojení k úložišti dat. Další informace najdete v části Požadavky . Pokud není zadaný, použije se výchozí prostředí Azure Integration Runtime. | No |
Typický připojovací řetězec je Server=<server>;Port=<port>;Database=<database>;UID=<user name>;PWD=<password>. Následující tabulka popisuje další vlastnosti, které můžete nastavit:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| Úroveň zabezpečení | Úroveň zabezpečení, kterou ovladač používá pro připojení k úložišti dat. Ovladač podporuje připojení SSL s jednosměrným ověřováním pomocí PROTOKOLU SSL verze 3. Příklad: SecurityLevel=preferredSecured. Podporované hodnoty jsou:- Pouze nezabezpečený (onlyUnSecured): Ovladač nepoužívá protokol SSL. - Preferovaný nezabezpečený (preferredUnSecured) (výchozí): Pokud server nabízí volbu, ovladač nepoužívá protokol SSL. - Upřednostňované zabezpečení (preferredSecured): Pokud server nabízí volbu, ovladač používá protokol SSL. - Pouze zabezpečené (onlySecured):: Ovladač se nepřipojí, pokud není k dispozici připojení SSL. |
No |
| CaCertFile | Úplná cesta k certifikátu SSL, který používá server. Příklad: CaCertFile=<cert path>; |
Ano, pokud je povolený protokol SSL |
Příklad
{
"name": "NetezzaLinkedService",
"properties": {
"type": "Netezza",
"typeProperties": {
"connectionString": "Server=<server>;Port=<port>;Database=<database>;UID=<user name>;PWD=<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Příklad: Uložení hesla ve službě Azure Key Vault
{
"name": "NetezzaLinkedService",
"properties": {
"type": "Netezza",
"typeProperties": {
"connectionString": "Server=<server>;Port=<port>;Database=<database>;UID=<user name>;",
"pwd": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Vlastnosti datové sady
Tato část obsahuje seznam vlastností, které datová sada Netezza podporuje.
Úplný seznam oddílů a vlastností, které jsou k dispozici pro definování datových sad, najdete v tématu Datové sady.
Pokud chcete kopírovat data z Netezza, nastavte vlastnost typu datové sady na NetezzaTable. Podporují se následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu datové sady musí být nastavená na: NetezzaTable. | Ano |
| schema | Název schématu | Ne (pokud je zadán dotaz ve zdroji aktivity) |
| table | Název tabulky. | Ne (pokud je zadán dotaz ve zdroji aktivity) |
| tableName | Název tabulky se schématem Tato vlastnost je podporována pro zpětnou kompatibilitu. Používejte schema a table pro nové úlohy. |
Ne (pokud je zadán dotaz ve zdroji aktivity) |
Příklad
{
"name": "NetezzaDataset",
"properties": {
"type": "NetezzaTable",
"linkedServiceName": {
"referenceName": "<Netezza linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {}
}
}
Vlastnosti aktivity kopírování
Tato část obsahuje seznam vlastností, které zdroj Netezza podporuje.
Úplný seznam oddílů a vlastností, které jsou k dispozici pro definování aktivit, najdete v tématu Kanály.
Netezza jako zdroj
Tip
Pokud chcete efektivně načítat data z Netezza pomocí dělení dat, přečtěte si další informace z oddílu Paralelní kopírování z oddílu Netezza .
Pokud chcete kopírovat data z Netezza, nastavte typ zdroje v aktivitě kopírování na NetezzaSource. Ve zdroji aktivity kopírování jsou podporovány následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu zdroje aktivity kopírování musí být nastavena na NetezzaSource. | Ano |
| query | Ke čtení dat použijte vlastní dotaz SQL. Příklad: "SELECT * FROM MyTable" |
Ne (pokud je v datové sadě zadán název tabulky) |
| partitionOptions | Určuje možnosti dělení dat, které se používají k načtení dat z Netezza. Povolené hodnoty jsou: None (výchozí), DataSlice a DynamicRange. Pokud je povolená možnost oddílu (to znamená, že ne None), stupeň paralelismu pro souběžné načítání dat z databáze Netezza je řízen parallelCopies nastavením aktivity kopírování. |
No |
| partitionSettings | Zadejte skupinu nastavení pro dělení dat. Použít, pokud není možnost oddílu None. |
No |
| partitionColumnName | Zadejte název zdrojového sloupce v celočíselném typu , který bude použit dělením rozsahu pro paralelní kopírování. Pokud není zadaný, primární klíč tabulky se automaticky rozdetekuje a použije se jako sloupec oddílu. Použít, pokud je DynamicRangemožnost oddílu . Pokud k načtení zdrojových dat použijete dotaz, připojte se ?AdfRangePartitionColumnName do klauzule WHERE. Viz příklad paralelní kopie z oddílu Netezza . |
No |
| partitionUpperBound | Maximální hodnota sloupce oddílu pro zkopírování dat. Použít, pokud je DynamicRangemožnost oddílu . Pokud k načtení zdrojových dat použijete dotaz, připojte se ?AdfRangePartitionUpbound do klauzule WHERE. Příklad najdete v části Paralelní kopie z oddílu Netezza . |
No |
| partitionLowerBound | Minimální hodnota sloupce oddílu pro zkopírování dat. Použít, pokud je DynamicRangemožnost oddílu . Pokud k načtení zdrojových dat použijete dotaz, připojte se ?AdfRangePartitionLowbound do klauzule WHERE. Příklad najdete v části Paralelní kopie z oddílu Netezza . |
No |
Příklad:
"activities":[
{
"name": "CopyFromNetezza",
"type": "Copy",
"inputs": [
{
"referenceName": "<Netezza input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "NetezzaSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Paralelní kopírování z Netezza
Konektor Data Factory Netezza poskytuje integrované dělení dat pro paralelní kopírování dat z Netezza. Možnosti dělení dat najdete v tabulce Zdroj aktivity kopírování.

Když povolíte dělenou kopii, služba spustí paralelní dotazy na zdroj Netezza, aby načetla data podle oddílů. Paralelní stupeň se řídí parallelCopies nastavením aktivity kopírování. Pokud například nastavíte parallelCopies hodnotu čtyři, služba souběžně vygeneruje a spouští čtyři dotazy na základě zadané možnosti a nastavení oddílu a každý dotaz načte část dat z databáze Netezza.
Doporučujeme povolit paralelní kopírování s dělením dat, zejména pokud načítáte velké množství dat z databáze Netezza. Následující konfigurace jsou navržené pro různé scénáře. Při kopírování dat do souborového úložiště dat se doporučuje zapisovat do složky jako více souborů (zadat pouze název složky), v takovém případě je výkon lepší než zápis do jednoho souboru.
| Scénář | Navrhovaná nastavení |
|---|---|
| Úplné načtení z velké tabulky | Možnost oddílu: Řez dat Během provádění služba automaticky rozdělí data na základě předdefinovaných datových řezů Netezza a kopíruje data podle oddílů. |
| Načtěte velké množství dat pomocí vlastního dotazu. | Možnost oddílu: Řez dat Dotaz: SELECT * FROM <TABLENAME> WHERE mod(datasliceid, ?AdfPartitionCount) = ?AdfDataSliceCondition AND <your_additional_where_clause>.Během provádění služba nahrazuje ?AdfPartitionCount (s paralelním číslem kopírování nastavenou aktivitou kopírování) a ?AdfDataSliceCondition logikou oddílu řezu dat a odesílá se do Netezza. |
| Načtěte velké množství dat pomocí vlastního dotazu, který má celočíselnou hodnotu s rovnoměrně distribuovanou hodnotou pro dělení rozsahu. | Možnosti oddílu: Oddíl dynamického rozsahu Dotaz: SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.Sloupec oddílu: Zadejte sloupec použitý k rozdělení dat. Rozdělení na sloupec můžete provést pomocí celočíselného datového typu. Horní mez oddílu a dolní mez oddílu: Určete, jestli chcete filtrovat podle sloupce oddílu, aby se načítala data pouze mezi dolním a horním rozsahem. Během provádění služba nahradí ?AdfRangePartitionColumnNamea ?AdfRangePartitionUpboundza skutečný název sloupce a ?AdfRangePartitionLowbound rozsahy hodnot pro každý oddíl a odešle do Netezza. Pokud je například sloupec oddílu "ID" nastavený s dolní mezí jako 1 a horní mez jako 80, s paralelním kopírováním nastaveným jako 4, služba načte data o 4 oddíly. Jejich ID jsou mezi [1,20], [21, 40], [41, 60] a [61, 80], v uvedeném pořadí. |
Příklad: Dotaz s oddílem řezu dat
"source": {
"type": "NetezzaSource",
"query": "SELECT * FROM <TABLENAME> WHERE mod(datasliceid, ?AdfPartitionCount) = ?AdfDataSliceCondition AND <your_additional_where_clause>",
"partitionOption": "DataSlice"
}
Příklad: Dotaz s oddílem dynamického rozsahu
"source": {
"type": "NetezzaSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<dynamic_range_partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column>",
"partitionLowerBound": "<lower_value_of_partition_column>"
}
}
Vlastnosti aktivity vyhledávání
Podrobnosti o vlastnostech najdete v aktivitě Vyhledávání.
Související obsah
Seznam úložišť dat, která aktivita kopírování podporuje jako zdroje a jímky, najdete v tématu Podporované úložiště a formáty dat.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro