Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Azure Synapse Analytics nabízí různé analytické moduly, které vám pomůžou ingestovat, transformovat, modelovat, analyzovat a obsluhovat data. Fond Apache Spark nabízí opensourcové výpočetní funkce pro velké objemy dat. Po vytvoření fondu Apache Sparku v pracovním prostoru Synapse je možné načíst, modelovat, zpracovávat a obsluhovat data za účelem získání přehledů.
Tento rychlý start popisuje postup vytvoření fondu Apache Spark v pracovním prostoru Synapse pomocí nástroje Synapse Studio.
Důležité
Fakturace instancí Sparku je účtována po minutách, bez ohledu na to, zda je používáte, nebo ne. Po dokončení použití nezapomeňte instanci Sparku vypnout nebo nastavit krátký časový limit. Další informace najdete v části Vyčištění prostředků tohoto článku.
Poznámka:
Synapse Studio bude nadále podporovat konfigurační soubory založené na Terraformu nebo Bicepu.
Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet.
Požadavky
- Budete potřebovat předplatné Azure. V případě potřeby vytvořte bezplatný účet Azure.
- Budete používat pracovní prostor Synapse.
Přihlaste se k portálu Azure Portal.
Přihlaste se k portálu Azure Portal.
Přejděte do pracovního prostoru Synapse.
Přejděte do pracovního prostoru Synapse, kde se fond Apache Sparku vytvoří zadáním názvu služby (nebo názvu prostředku přímo) do panelu hledání.
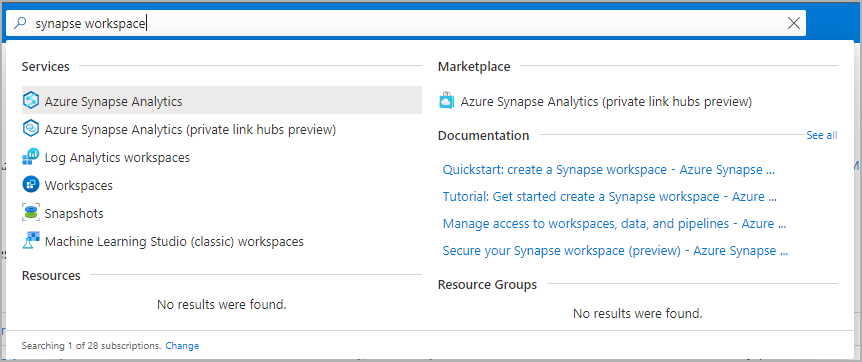
V seznamu pracovních prostorů zadejte název (nebo část názvu) pracovního prostoru, který chcete otevřít. V tomto příkladu používáme pracovní prostor s názvem contosoanalytics.
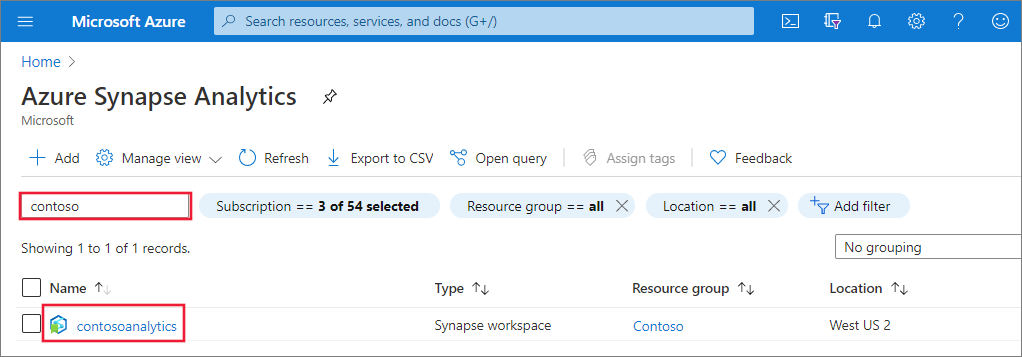


Spuštění Synapse Studio
V přehledu pracovního prostoru vyberte webovou adresu URL pracovního prostoru a otevřete Synapse Studio.

Vytvoření fondu Apache Sparku v nástroji Synapse Studio
Důležité
Modul Azure Synapse Runtime pro Apache Spark 2.4 byl deaktivován a oficiálně nepodporován od září 2023. Vzhledem k tomu , že Spark 3.1 a Spark 3.2 jsou také oznámeny ukončení podpory, doporučujeme zákazníkům migrovat na Spark 3.3.
Na domovské stránce synapse Studia přejděte do centra pro správu v levém navigačním panelu výběrem ikony Spravovat .
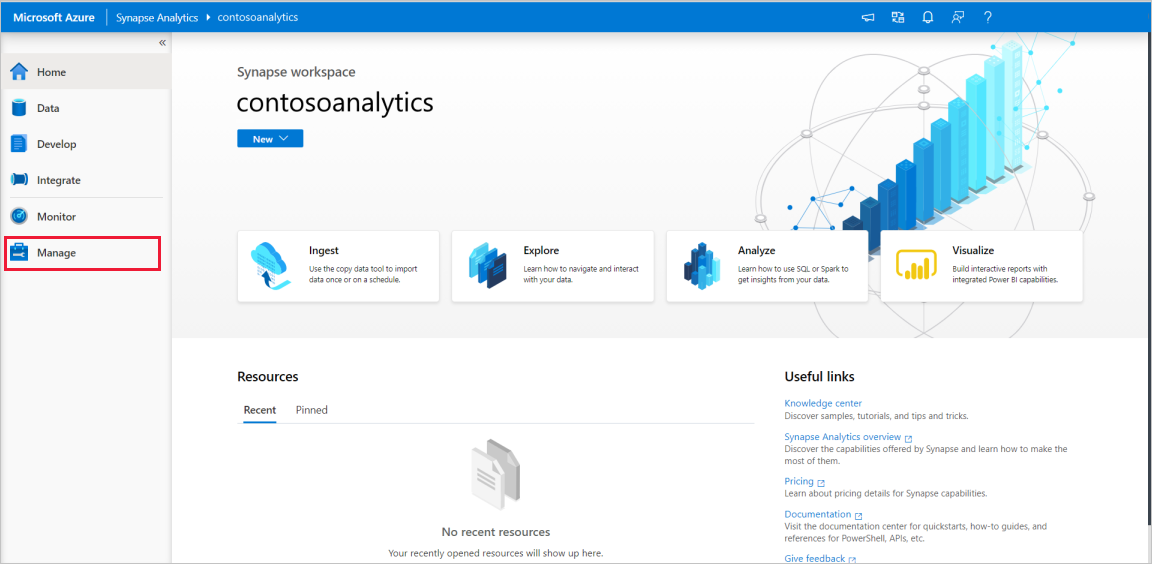
V centru pro správu přejděte do sekce Fondy Apache Spark a zobrazte aktuální seznam fondů Apache Spark, které jsou dostupné v pracovním prostoru.
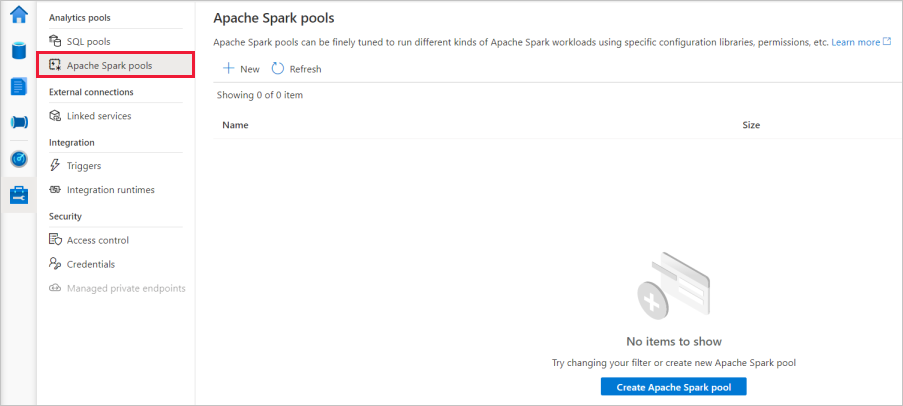
Vyberte + Nový a zobrazí se průvodce pro vytvoření nového fondu Apache Spark.
Na kartě Základy zadejte následující podrobnosti:
Nastavení Navrhovaná hodnota Popis Název fondu Apache Spark Platný název fondu, například contososparkToto je název, který bude mít fond Apache Spark. Velikost uzlu Malý (4 vCPU / 32 GB) Nastavte tuto možnost na nejmenší velikost, abyste snížili náklady na tento rychlý start. Automatické škálování Vypnuto V tomto rychlém startu nebudeme potřebovat automatické škálování. Počet uzlů 8 Použití malé velikosti k omezení nákladů v tomto rychlém startu Dynamicky přidělovat vykonavatele Vypnuto Toto nastavení se mapuje na vlastnost dynamického přidělení v konfiguraci Sparku pro přidělování exekutorů aplikací Spark. V tomto rychlém startu nebudeme potřebovat automatické škálování. 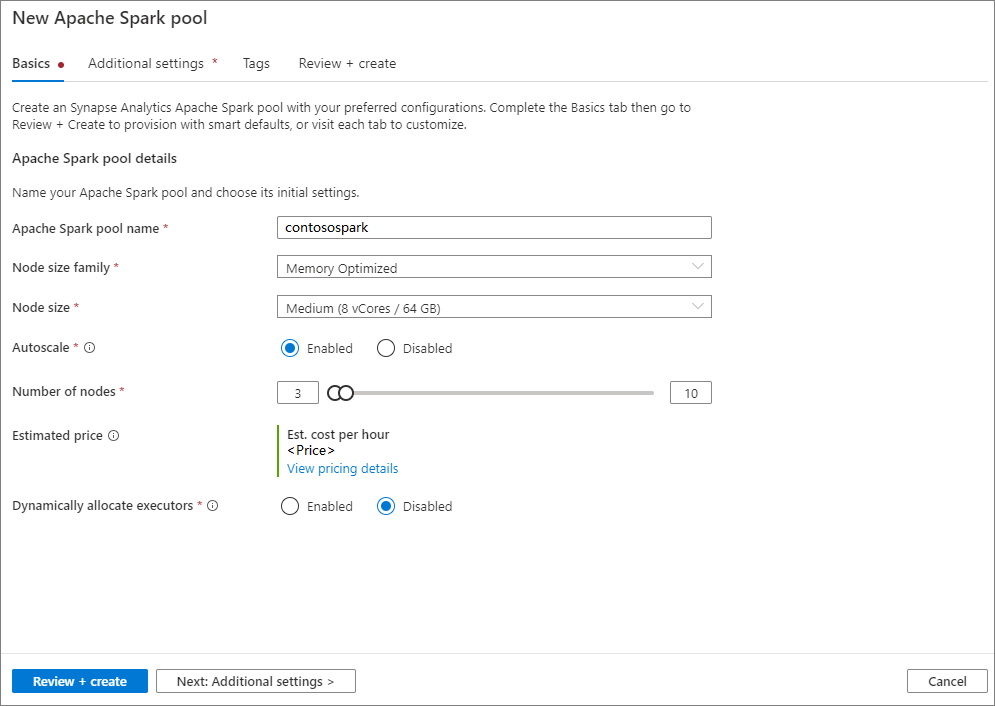
Důležité
Pro názvy, které fondy Apache Sparku můžou používat, platí určitá omezení. Názvy musí obsahovat pouze písmena nebo číslice, musí mít maximálně 15 znaků, musí začínat písmenem, nesmí obsahovat vyhrazená slova a být v pracovním prostoru jedinečná.
Na další kartě Další nastavení ponechte všechna nastavení jako výchozí.
Vyberte Značky. Zvažte použití značek Azure. Například značka "Owner" nebo "CreatedBy", která identifikuje, kdo prostředek vytvořil, a značku Prostředí, abyste zjistili, jestli se tento prostředek nachází v produkčním prostředí, vývoji atd. Další informace najdete v tématu Vývoj strategie vytváření názvů a označování prostředků Azure. Až budete připraveni, vyberte Zkontrolovat a vytvořit.
Na kartě Revize a vytvoření se ujistěte, že podrobnosti vypadají správně podle toho, co bylo dříve zadáno, a stiskněte tlačítko Vytvořit.
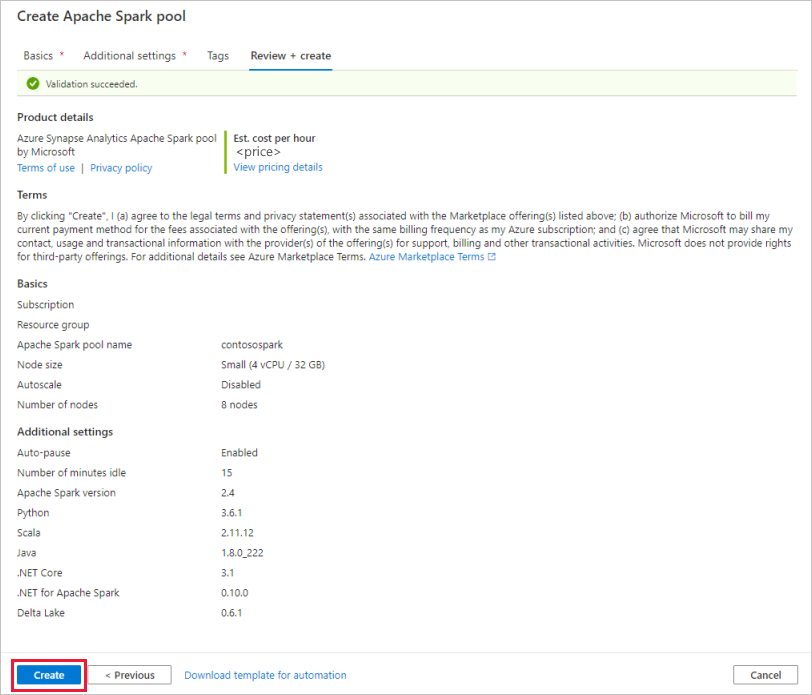
Pool Apache Spark spustí proces zřizování.
Po dokončení zřizování se nový fond Apache Spark objeví v seznamu.
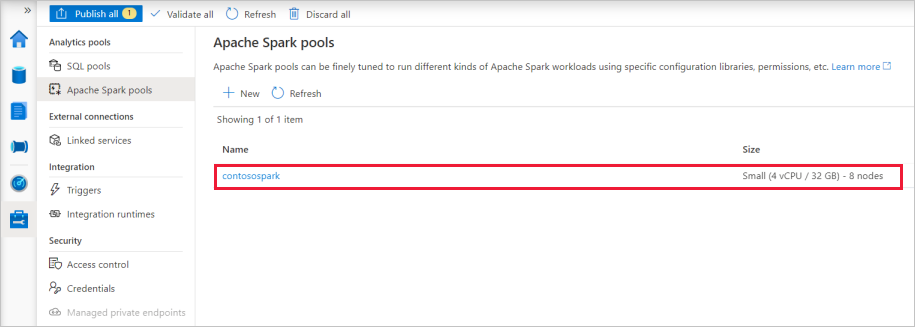





Vyčištění prostředků fondu Apache Spark pomocí nástroje Synapse Studio
Následující kroky odstraňují fond Apache Sparku z pracovního prostoru pomocí Synapse Studio.
Varování
Odstraněním Spark poolu odeberete analytickou jednotku z pracovního prostoru. Už se nebude možné připojit k fondu a všechny dotazy, kanály a poznámkové bloky, které tento fond Sparku používají, už nebudou fungovat.
Pokud chcete odstranit fond Apache Sparku, proveďte následující kroky:
Ve službě Synapse Studio přejděte k fondům Apache Spark v centru pro správu.
Výběrem ikony tří teček vedle Apache poolu, který chcete odstranit (v tomto případě contosospark), zobrazíte příkazy pro Apache Spark pool.
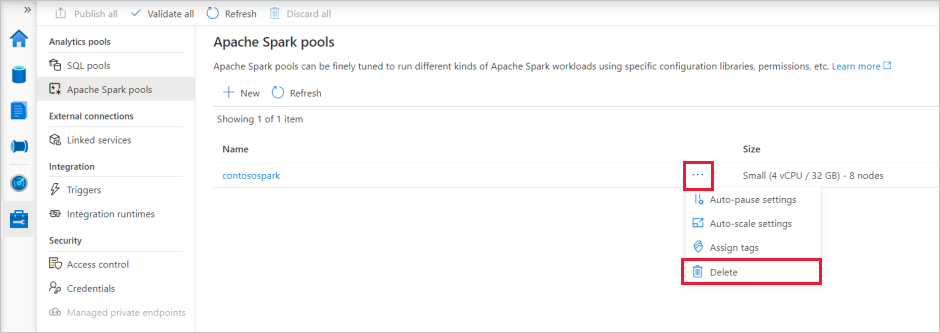
Vyberte Odstranit.
Potvrďte odstranění a stiskněte tlačítko Delete .
Po úspěšném dokončení procesu už nebude fond Apache Spark uveden mezi zdroji pracovního prostoru.
