Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
V tomto rychlém startu se dozvíte, jak vytvořit bezserverový fond Apache Spark ve službě Azure Synapse pomocí webových nástrojů. Pak se naučíte připojit k fondu Apache Spark a spustit dotazy Spark SQL na soubory a tabulky. Apache Spark umožňuje rychlou analýzu dat a cluster computing s využitím zpracování v paměti. Informace o Sparku ve službě Azure Synapse najdete v tématu Přehled: Apache Spark v Azure Synapse.
Důležité
Účtování instancí Spark je rozpočítané po minutách, bez ohledu na to, jestli je používáte, nebo ne. Po dokončení použití nezapomeňte instanci Sparku vypnout nebo nastavit krátký časový limit. Další informace najdete v části Vyčištění prostředků tohoto článku.
Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet.
Požadavky
- Budete potřebovat předplatné Azure. V případě potřeby vytvořte bezplatný účet Azure.
- Pracovní prostor Synapse Analytics
- Bezserverový fond Apache Sparku
Přihlaste se k portálu Azure Portal.
Přihlaste se do Azure Portalu.
Pokud ještě nemáte předplatné Azure, vytvořte si bezplatný účet Azure před tím, než začnete.
Vytvořte poznámkový blok
Notebook je interaktivní prostředí, které podporuje různé programovací jazyky. Poznámkový blok umožňuje pracovat s daty, kombinovat kód s markdownem, textem a provádět jednoduché vizualizace.
V zobrazení webu Azure Portal pro pracovní prostor Azure Synapse, který chcete použít, vyberte Spustit Synapse Studio.
Jakmile se Synapse Studio spustí, vyberte Vývoj. Pak výběrem ikony "+" přidejte nový prostředek.
Odtud vyberte Notebook. Vytvoří se nový poznámkový blok a otevře se s automaticky vygenerovaným názvem.

V okně Vlastnosti zadejte název poznámkového bloku.
Na panelu nástrojů klikněte na Publikovat.
Pokud je ve vašem pracovním prostoru jenom jeden fond Apache Sparku, je ve výchozím nastavení automaticky vybrán. Pokud není vybrán žádný fond, použijte rozbalovací seznam k výběru správného fondu Apache Spark.
Klikněte na Přidat kód. Výchozí jazyk je
Pyspark. Použijete kombinaci Pyspark a Spark SQL, takže výchozí volba je v pořádku. Další podporované jazyky jsou Scala a .NET pro Spark.Dále vytvoříte jednoduchý objekt datového rámce Sparku pro manipulaci. V takovém případě ho vytvoříte z kódu. Existují tři řádky a tři sloupce:
new_rows = [('CA',22, 45000),("WA",35,65000) ,("WA",50,85000)] demo_df = spark.createDataFrame(new_rows, ['state', 'age', 'salary']) demo_df.show()Teď buňku spusťte pomocí jedné z následujících metod:
Stiskněte SHIFT+ENTER.
Vyberte modrou ikonu přehrávání vlevo od buňky.
Na panelu nástrojů vyberte tlačítko Spustit vše .
Pokud instance fondu Apache Spark ještě není spuštěná, spustí se automaticky. Stav instance fondu Apache Spark můžete zobrazit pod buňkou, kterou spouštíte, a také na stavovém panelu v dolní části poznámkového bloku. V závislosti na velikosti bazénu by spuštění mělo trvat 2 až 5 minut. Po dokončení spuštění kódu se pod buňkou zobrazí informace o tom, jak dlouho trvalo spuštění a provedení kódu. Ve výstupní buňce se zobrazí výstup.
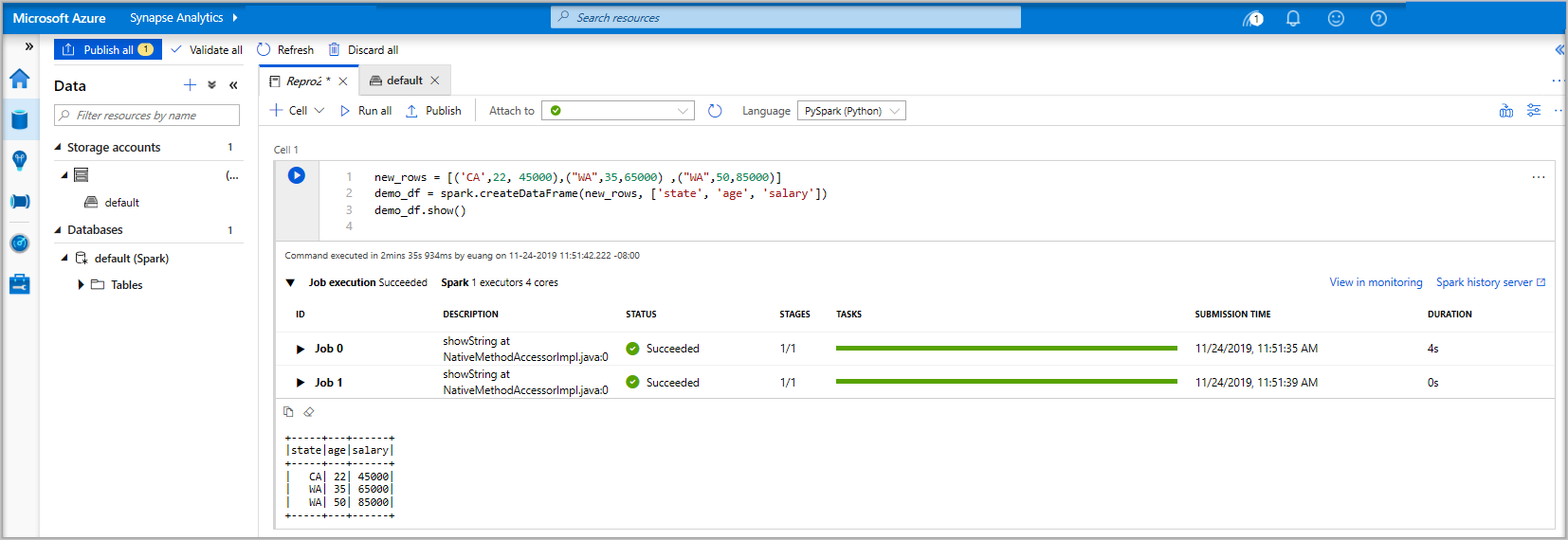
Data teď existují v datovém rámci, ze které můžete data používat mnoha různými způsoby. Pro zbytek tohoto rychlého startu ho budete potřebovat v různých formátech.
Zadejte níže uvedený kód do jiné buňky a spusťte ho, vytvoří se tabulka Sparku, CSV a soubor Parquet se všemi kopiemi dat:
demo_df.createOrReplaceTempView('demo_df') demo_df.write.csv('demo_df', mode='overwrite') demo_df.write.parquet('abfss://<<TheNameOfAStorageAccountFileSystem>>@<<TheNameOfAStorageAccount>>.dfs.core.windows.net/demodata/demo_df', mode='overwrite')Pokud používáte Průzkumníka úložiště, je možné vidět dopad dvou různých způsobů zápisu výše použitého souboru. Pokud není zadán žádný systém souborů, použije se výchozí hodnota v tomto případě
default>user>trusted-service-user>demo_df. Data se uloží do umístění zadaného souborového systému.Všimněte si, že při zápisových operacích ve formátech "csv" i "parquet" je vytvořen adresář s mnoha členěnými soubory.


Spouštění příkazů Spark SQL
Jazyk SQL (Structured Query Language) je nejběžnějším a široce používaným jazykem pro dotazování a definování dat. Spark SQL funguje jako rozšíření Apache Spark pro zpracování strukturovaných dat a používá známou syntaxi jazyka SQL.
Do prázdné buňky vložte následující kód a spusťte kód. Příkaz zobrazí seznam tabulek v poolu.
%%sql SHOW TABLESPři použití poznámkového bloku s fondem Azure Synapse Apache Spark získáte přednastavení
sqlContext, které můžete použít ke spouštění dotazů pomocí Spark SQL.%%sqlřekne poznámkovému bloku, že má použít předvolbusqlContextke spuštění dotazu. Dotaz načte prvních 10 řádků ze systémové tabulky, která je ve výchozím nastavení součástí všech fondů Azure Synapse Apache Spark.Spuštěním dalšího dotazu zobrazíte data v tabulce
demo_df.%%sql SELECT * FROM demo_dfKód vytvoří dvě výstupní buňky, jednu, která obsahuje výsledky dat druhé, která zobrazuje zobrazení úlohy.
Ve výchozím nastavení se v zobrazení výsledků zobrazuje mřížka. Pod mřížkou je ale přepínač zobrazení, který umožňuje zobrazení přepínat mezi zobrazeními mřížky a grafu.

V přepínači Zobrazení vyberte Graf.
Na pravé straně vyberte ikonu Možnosti zobrazení .
V poli Typ grafu vyberte pruhový graf.
V poli sloupce osy X vyberte "stav".
V poli sloupce osy Y vyberte "plat".
V poli Agregace vyberte možnost AVG.
Vyberte a použijte.

Je možné získat stejné prostředí pro spouštění SQL, ale nemusíte přepínat jazyky. Můžete to provést nahrazením výše uvedené buňky SQL touto buňkou PySpark, výstupní prostředí je stejné, protože se používá příkaz pro zobrazení :
display(spark.sql('SELECT * FROM demo_df'))Každá z dříve spuštěných buněk měla možnost přejít na Server Historie a Monitorování. Kliknutím na odkazy přejdete do různých částí uživatelského prostředí.
Poznámka:
Některá oficiální dokumentace k Apache Sparku závisí na používání konzoly Spark, která není k dispozici ve Službě Synapse Spark. Místo toho použijte prostředí poznámkového bloku nebo IntelliJ .
Čištění zdrojů
Azure Synapse ukládá vaše data ve službě Azure Data Lake Storage. Instanci Sparku můžete bezpečně vypnout, když se nepoužívá. Účtuje se vám za fond bez serveru Apache Spark, dokud je spuštěn, i když není používán.
Vzhledem k tomu, že poplatky za fond jsou mnohokrát vyšší než poplatky za úložiště, dává smysl nechat instance Sparku vypnout, když se nepoužívají.
Pokud chcete zajistit, aby se instance Sparku vypnula, ukončete všechny připojené relace (poznámkové bloky). Pool se vypne, když je dosaženo doby nečinnosti, která je nastavena v poolu Apache Spark. Můžete také vybrat ukončit relaci ze stavového řádku v dolní části poznámkového bloku.
Další kroky
V tomto rychlém začátku jste se naučili, jak vytvořit bezserverový cluster Apache Spark a spustit základní dotaz Spark SQL.