Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
V tomto kurzu se dozvíte, jak pomocí modulu plug-in Azure Toolkit for IntelliJ vyvíjet aplikace Apache Spark, které jsou napsané v jazyce Scala, a pak je odeslat do bezserverového fondu Apache Sparku přímo z integrovaného vývojového prostředí (IDE) IntelliJ. Modul plug-in můžete použít několika způsoby:
- Vývoj a odeslání aplikace Scala Spark ve fondu Spark
- Získejte přístup k prostředkům fondů Sparku.
- Vyvíjejte a spouštějte aplikaci Scala Spark místně.
V tomto kurzu se naučíte:
- Použití pluginu Azure Toolkit for IntelliJ
- Vývoj aplikací Apache Spark
- Odeslání aplikace do fondů Sparku
Požadavky
Modul plug-in Azure Toolkit 3.27.0-2019.2 – Instalace z úložiště modulu plug-in IntelliJ
Modul plug-in Scala – Instalace z úložiště modulu plug-in IntelliJ
Následující předpoklad platí jenom pro uživatele Windows:
Při spouštění místní aplikace Spark Scala na počítači s Windows se může zobrazit výjimka, jak je vysvětleno ve SPARK-2356. K výjimce dochází, protože v systému Windows chybí WinUtils.exe. Pokud chcete tuto chybu vyřešit, stáhněte si spustitelný soubor WinUtils do umístění, například C:\WinUtils\bin. Potom přidejte proměnnou prostředí HADOOP_HOME a nastavte hodnotu proměnné na C:\WinUtils.
Vytvoření aplikace Spark Scala pro fond Sparku
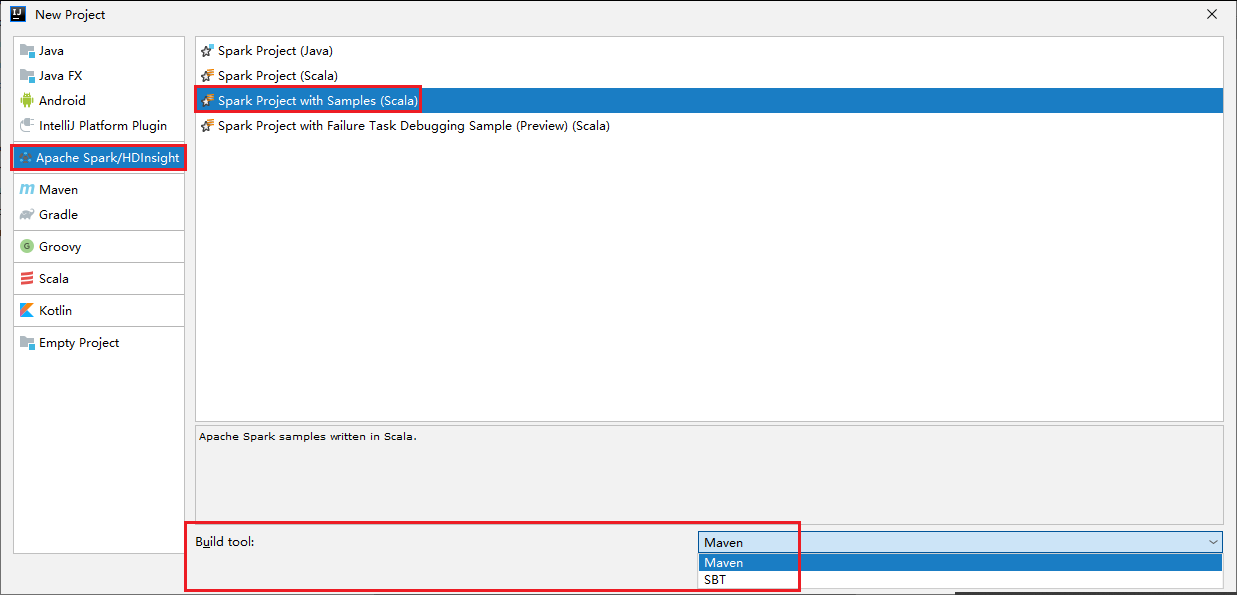
Spusťte IntelliJ IDEA a výběrem možnosti Vytvořit nový projekt otevřete okno Nový projekt.
V levém podokně vyberte Apache Spark/HDInsight .
V hlavním okně vyberte Projekt Sparku s ukázkami (Scala ).
V rozevíracím seznamu Nástrojů sestavení vyberte jeden z následujících typů:
- Podpora průvodce vytvořením projektu Maven pro Scala.
- SBT pro správu závislostí a sestavování pro projekt Scala.
Vyberte Další.
V okně Nový projekt zadejte následující informace:
Vlastnost Popis Název projektu Zadejte název. Tento návod používá myApp.Umístění projektu Zadejte požadované umístění pro uložení projektu. Project SDK Při prvním použití funkce IDEA může být prázdné. Vyberte Nový... a vyhledejte nebo vyberte složku s vaší JDK. Verze Sparku Průvodce vytvořením integruje správnou verzi sady Spark SDK a Scala SDK. Tady můžete zvolit požadovanou verzi Sparku. 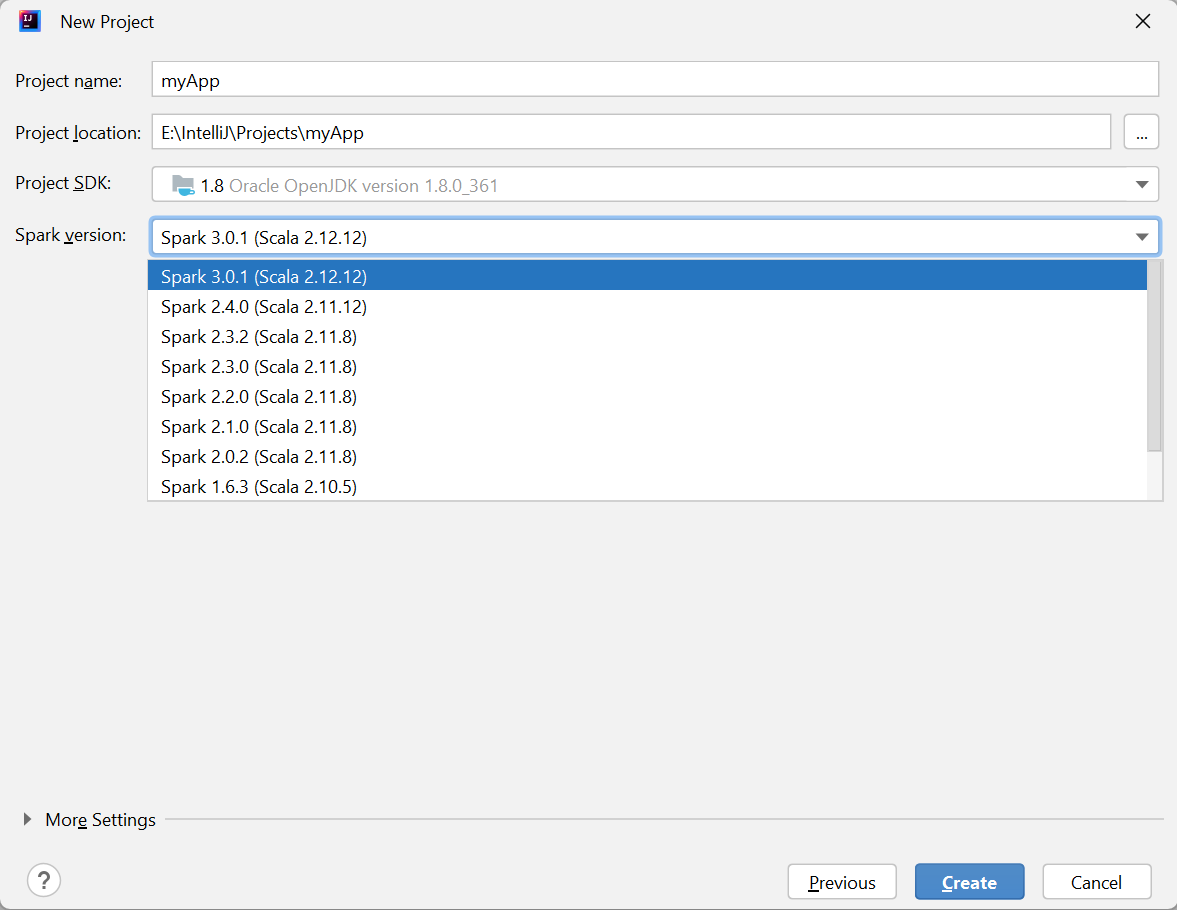
Vyberte Dokončit. Než bude projekt dostupný, může to trvat několik minut.
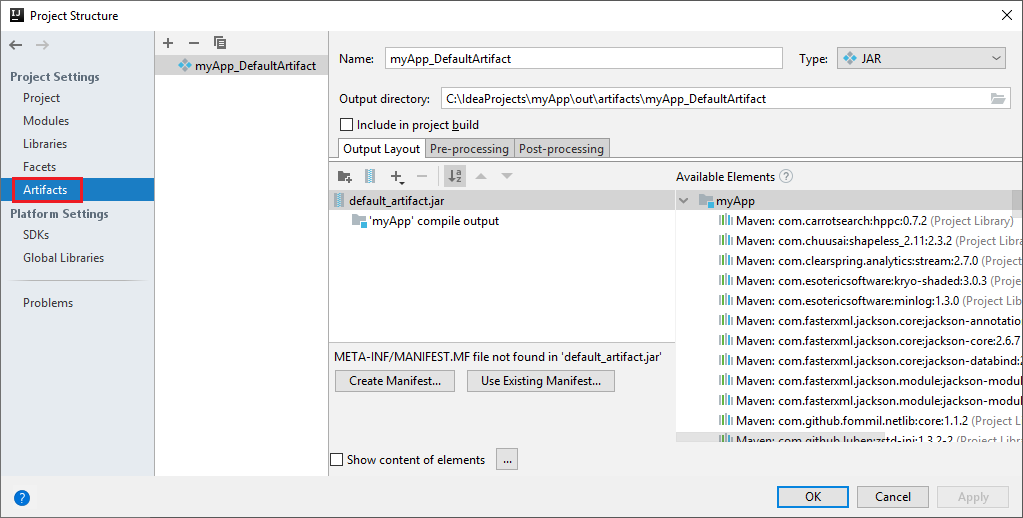
Projekt Spark automaticky vytvoří artefakt za vás. Pokud chcete zobrazit artefakt, postupujte takto:
a. V řádku nabídek přejděte na Soubor>Struktura projektu....
b. V okně Struktura projektu vyberte Artefakty.
c. Po zobrazení artefaktu vyberte Zrušit .
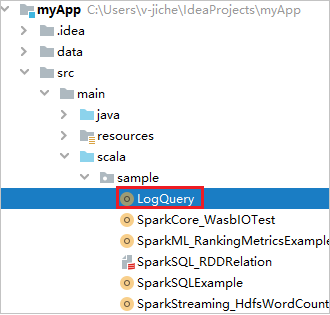
Vyhledejte LogQuery z myApp>src>main>scala>sample>LogQuery. V tomto kurzu se ke spuštění používá LogQuery .
Připojení k fondům Sparku
Přihlaste se k předplatnému Azure a připojte se k fondům Sparku.
Přihlaste se ke svému předplatnému Azure.
V panelu nabídek přejděte na Zobrazení>Nástroje pro okna>Průzkumník Azure.
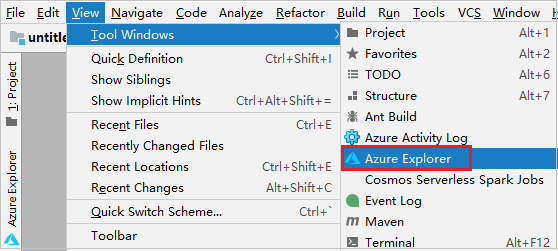
V Azure Exploreru klikněte pravým tlačítkem na uzel Azure a pak vyberte Přihlásit se.
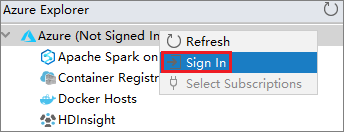
V dialogovém okně Azure Sign In (Přihlášení k Azure) zvolte Device Login (Přihlášení zařízení) a pak vyberte Sign in (Přihlásit se).
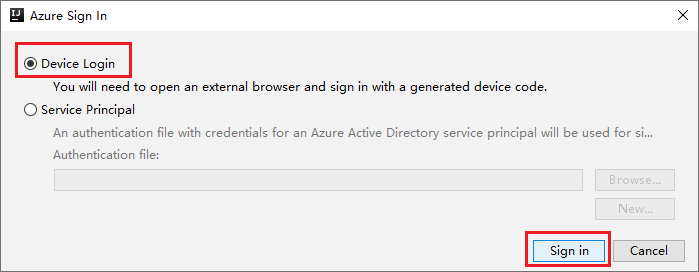
V dialogovém okně Azure Device Login (Přihlášení zařízení Azure) vyberte Copy&Open (Kopírovat&Otevřít).
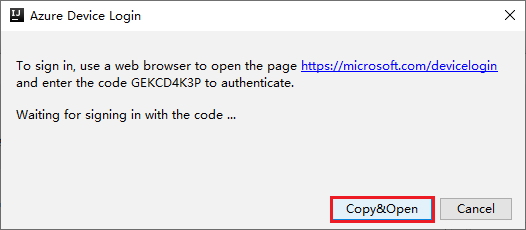
V rozhraní prohlížeče vložte kód a pak vyberte Další.
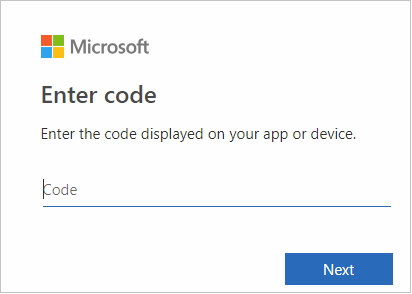
Zadejte své přihlašovací údaje Azure a zavřete prohlížeč.
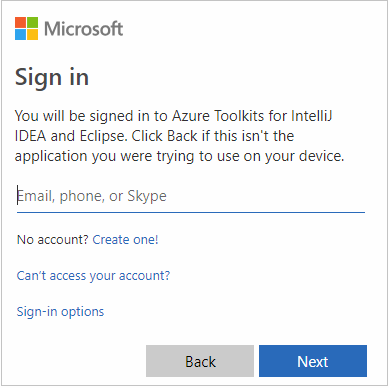
Po přihlášení se v dialogovém okně Vybrat předplatná zobrazí seznam všech předplatných Azure přidružených k přihlašovacím údajům. Vyberte své předplatné a pak vyberte Vybrat.

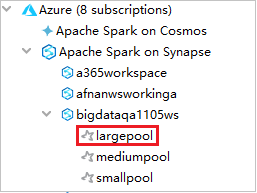
V Azure Exploreru rozbalte Apache Spark ve službě Synapse a zobrazte pracovní prostory, které jsou ve vašich předplatných.
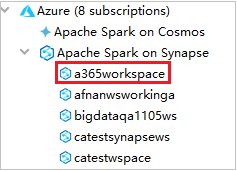
Pokud si přejete zobrazit fondy Sparku, můžete pracovní prostor dále rozšířit.
Vzdálené spuštění aplikace Spark Scala ve fondu Sparku
Po vytvoření aplikace Scala ji můžete vzdáleně spustit.
Výběrem ikony otevřete okno Spustit/Ladit konfigurace .
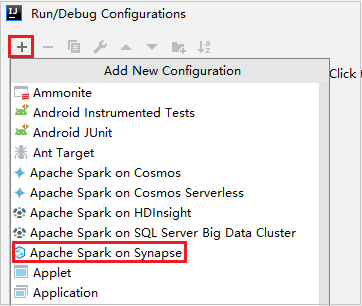
V dialogovém okně Spustit/Ladit konfigurace vyberte +a pak ve službě Synapse vyberte Apache Spark.
V okně Konfigurace spuštění/ladění zadejte následující hodnoty a pak vyberte OK:
Vlastnost Hodnota Fondy úloh Sparku Vyberte fondy Sparku, na kterých chcete aplikaci spustit. Výběr artefaktu k odeslání Ponechte výchozí nastavení. Název hlavní třídy Výchozí hodnota je hlavní třída z vybraného souboru. Třídu můžete změnit tak, že vyberete tři tečky (vodoznak) (...) a zvolíte jinou třídu. Konfigurace úloh Výchozí klíč a hodnoty můžete změnit. Další informace najdete v tématu Apache Livy REST API. Argumenty příkazového řádku V případě potřeby můžete zadat argumenty oddělené mezerou pro hlavní třídu. Odkazované soubory Jar a odkazované soubory Pokud nějaké jsou, můžete zadat cesty pro odkazované soubory JAR. Můžete také procházet soubory ve virtuálním systému souborů Azure, který aktuálně podporuje pouze cluster ADLS Gen2. Další informace: Konfigurace Apache Sparku a postup nahrání prostředků do clusteru. Úložiště pro nahrání úloh Rozbalením zobrazíte další možnosti. Typ úložiště Vyberte Použít objekt blob Azure k nahrání nebo Použít výchozí účet úložiště clusteru k nahrání z rozevíracího seznamu. Účet úložiště Zadejte svůj účet úložiště. Klíč úložiště Zadejte svůj klíč úložiště. Úložný kontejner Po zadání účtu úložiště a klíče úložiště vyberte kontejner úložiště z rozevíracího seznamu. 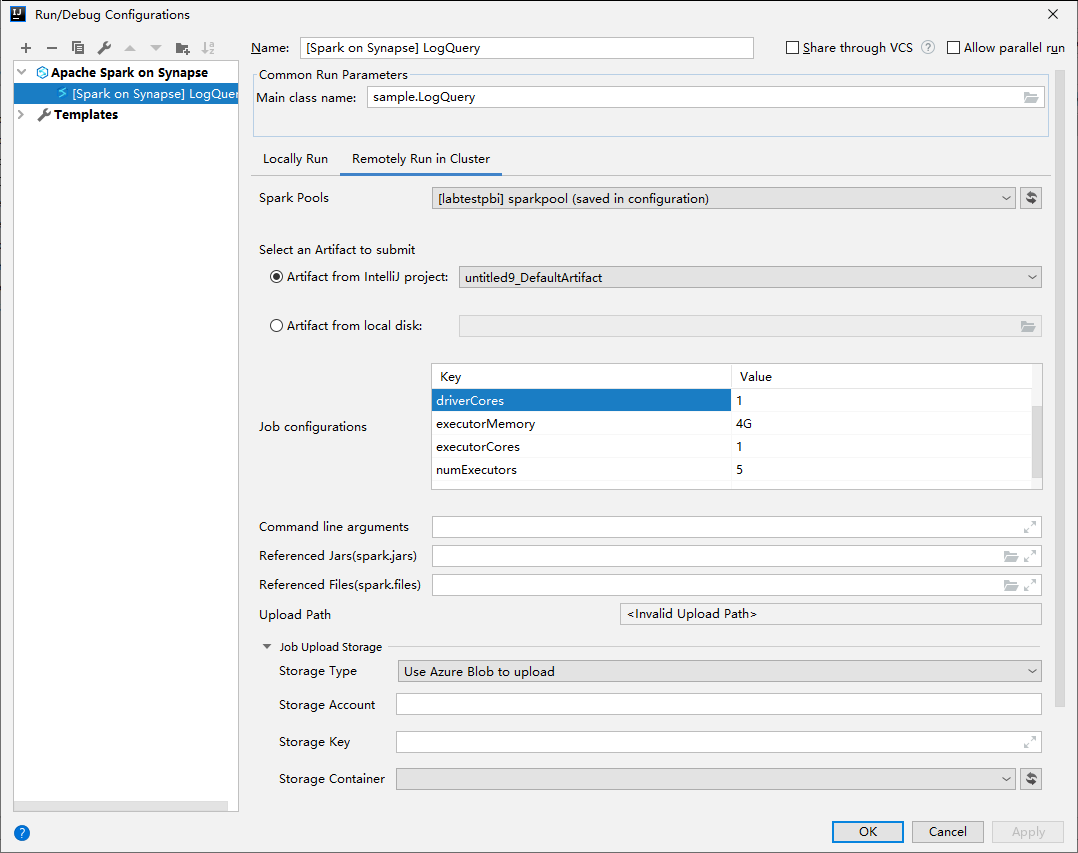
Výběrem ikony SparkJobRun odešlete projekt do vybraného fondu Sparku. Karta Vzdálená úloha Sparku v clustru zobrazuje průběh spuštění úlohy dole. Aplikaci můžete zastavit výběrem červeného tlačítka.

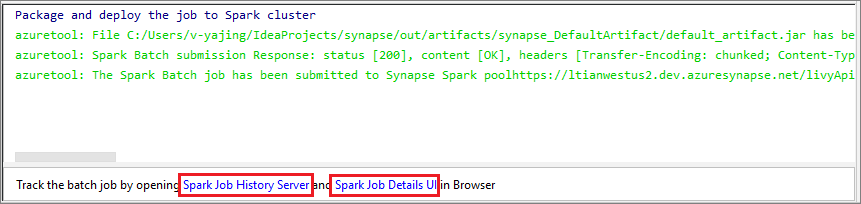
Místní spuštění/ladění aplikací Apache Spark
Můžete postupovat podle následujících pokynů pro nastavení místního spuštění a ladění úlohy Apache Spark.
Scénář 1: Místní spuštění
Otevřete dialogové okno Konfigurace spuštění/ladění a vyberte znaménko plus (+). Pak vyberte možnost Apache Spark v Synapse . Zadejte informace pro Jméno a Hlavní název třídy, aby bylo možné je uložit.
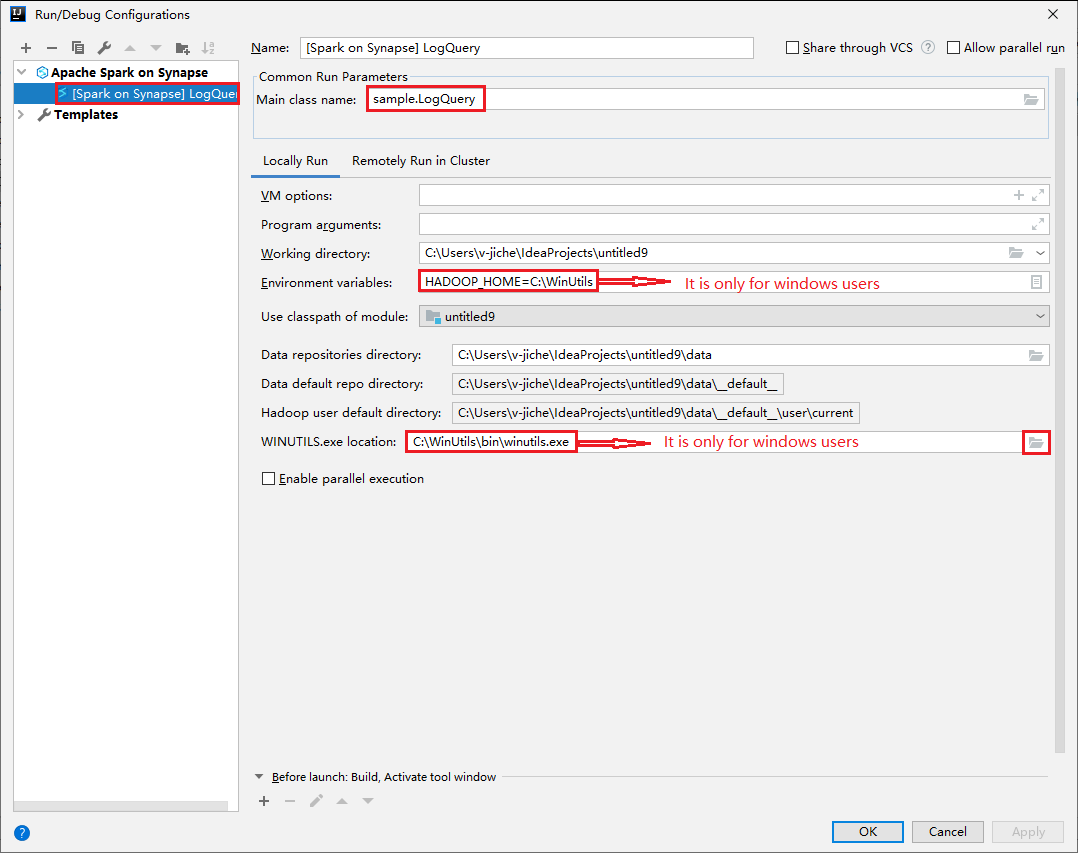
- Proměnné prostředí a umístění WinUtils.exe jsou určené jenom pro uživatele Windows.
- Proměnné prostředí: Systémová proměnná prostředí se dá automaticky rozpoznat, pokud jste ji nastavili dříve a nemusíte ji přidávat ručně.
- WinUtils.exe Umístění: Umístění WinUtils můžete určit tak, že vpravo vyberete ikonu složky.
Pak vyberte tlačítko místního přehrávání.

Po dokončení místního spuštění, pokud skript obsahuje výstup, můžete zkontrolovat výstupní soubor ze data>default.
Scénář 2: Místní ladění
Otevřete skript LogQuery a nastavte zarážky.
Pokud chcete provést místní ladění, vyberte ikonu místního ladění .

Přístup k pracovnímu prostoru Synapse a jeho správa
V Azure Exploreru můžete provádět různé operace v sadě Azure Toolkit for IntelliJ. V panelu nabídek přejděte na Zobrazení>Nástroje pro okna>Průzkumník Azure.
Otevřít pracovní prostor
V Azure Exploreru přejděte na Apache Spark ve službě Synapse a rozbalte ho.
Klikněte pravým tlačítkem na pracovní prostor a pak vyberte Spustit pracovní prostor, otevře se web.
Konzole Spark
Můžete spustit místní konzolu Sparku (Scala) nebo spustit konzolu interaktivní relace Spark Livy (Scala).
Místní konzola Sparku (Scala)
Ujistěte se, že jste splnili požadavky na WINUTILS.EXE.
Na řádku nabídek přejděte na Spustit>Upravit konfigurace....
V okně Konfigurace spuštění/ladění přejděte v levém podokně na Apache Spark na Synapse>[Spark na Synapse] myApp.
V hlavním okně vyberte záložku Místně spustit.
Zadejte následující hodnoty a pak vyberte OK:
Vlastnost Hodnota Proměnné prostředí Ujistěte se, že je správná hodnota pro HADOOP_HOME. Umístění WINUTILS.exe Ujistěte se, že je cesta správná. 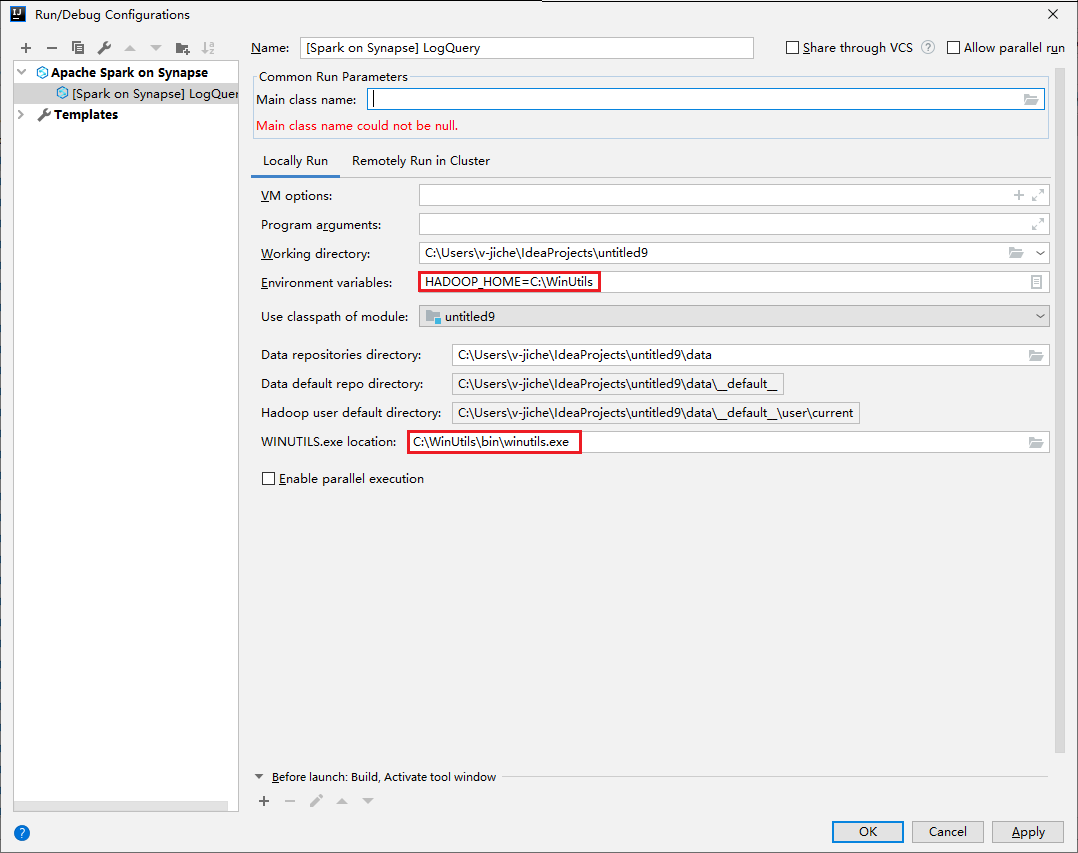
V Projectu přejděte na myApp>src>main>scala>myApp.
Ve výběru menu přejděte do Nástroje>konzola Spark>Spustit místní konzolu Spark (Scala).
Pak se můžou zobrazit dvě dialogová okna s dotazem, jestli chcete automaticky opravit závislosti. Pokud ano, vyberte Automatická oprava.
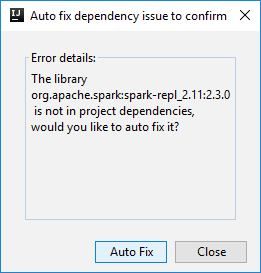
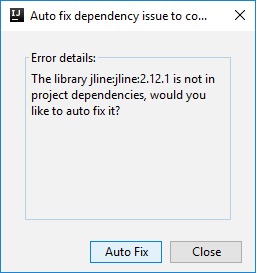
Konzola by měla vypadat podobně jako na následujícím obrázku. V okně konzoly zadejte
sc.appNamea stiskněte ctrl+Enter. Zobrazí se výsledek. Místní konzolu můžete zastavit výběrem červeného tlačítka.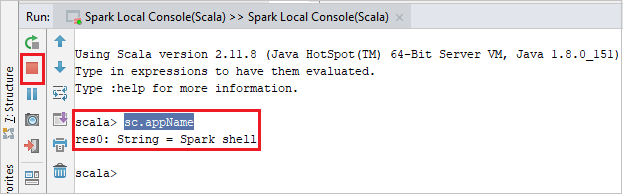
Konzola interaktivní relace Spark Livy (Scala)
Podporuje se jenom v IntelliJ 2018.2 a 2018.3.
Na řádku nabídek přejděte na Spustit>Upravit konfigurace....
V okně Konfigurace spuštění/ladění v levém podokně přejděte do Apache Spark na synapse>[Spark na synapse] myApp.
V hlavním okně vyberte kartu Vzdálené spuštění v clusteru .
Zadejte následující hodnoty a pak vyberte OK:
Vlastnost Hodnota Název hlavní třídy Vyberte název hlavní třídy. Datové fondy Sparku Vyberte fondy Sparku, na kterých chcete aplikaci spustit. 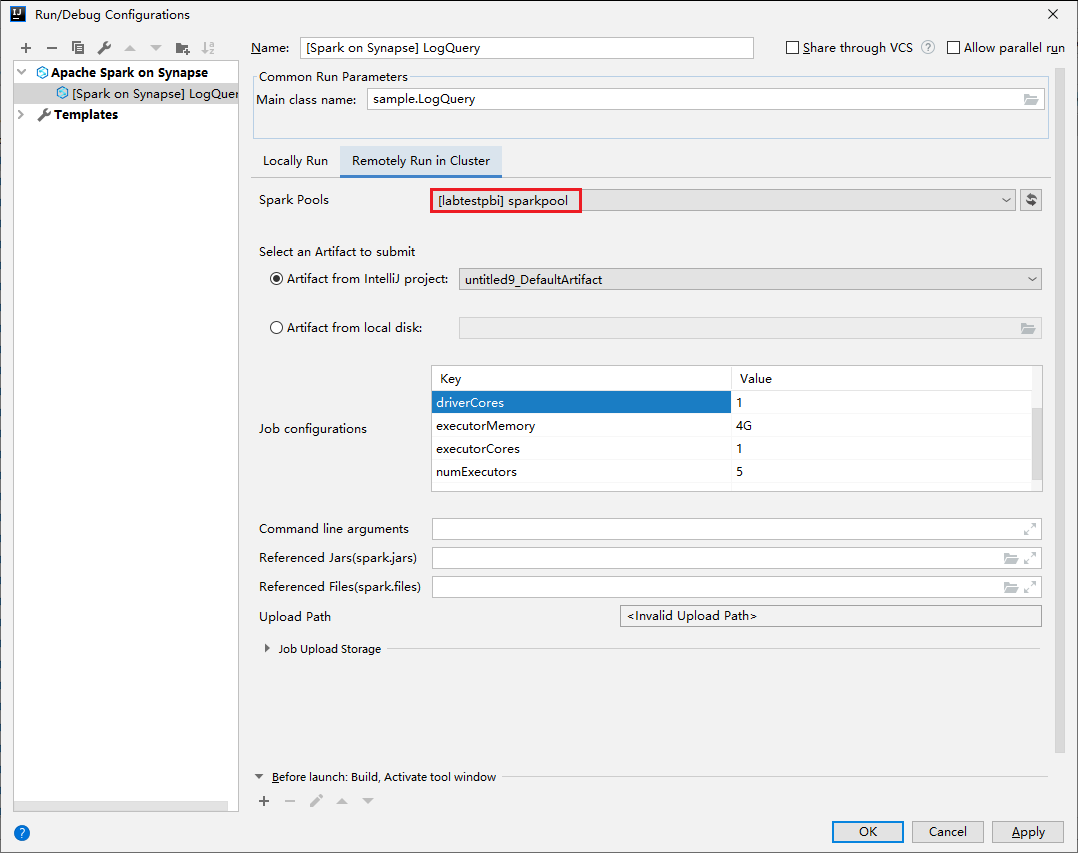
V Projectu přejděte na myApp>src>main>scala>myApp.
Na panelu nabídek přejděte na
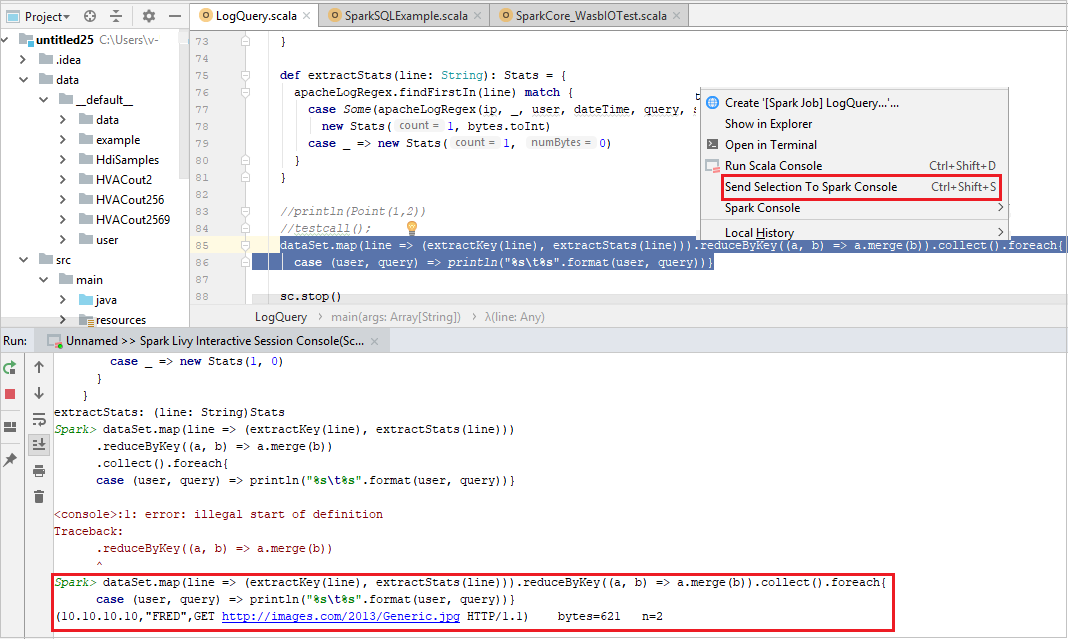
Nástroje konzola Sparku Spusťte interaktivní konzolu relace Spark Livy (Scala) . Konzola by měla vypadat podobně jako na následujícím obrázku. V okně konzoly zadejte
sc.appNamea stiskněte ctrl+Enter. Zobrazí se výsledek. Místní konzolu můžete zastavit výběrem červeného tlačítka.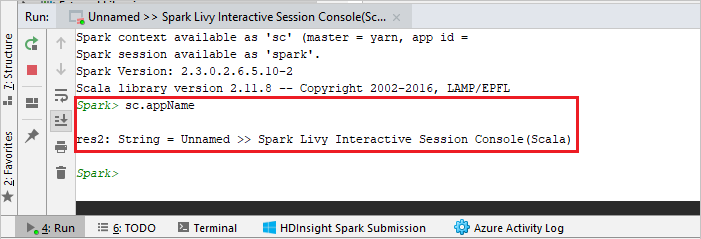
Odeslání výběru do konzoly Sparku
Výsledek skriptu můžete zobrazit odesláním kódu do místní konzoly nebo konzoly Livy Interactive Session Console(Scala). Uděláte to tak, že v souboru Scala zvýrazníte nějaký kód a pak kliknete pravým tlačítkem myši na konzolu Odeslat výběr do Sparku. Vybraný kód bude odeslán do konzole a následně proveden. Výsledek se zobrazí za kódem v konzole. Konzola zkontroluje existující chyby.