Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tip
Microsoft Fabric Data Warehouse je relační sklad v podnikovém měřítku na základu datového jezera s architekturou připravenou pro budoucnost, integrovanou AI a novými funkcemi. Pokud s datovými sklady začínáte, začněte pracovat s Fabric Data Warehouse. Stávající úlohy fondu dedikované SQL můžou upgradovat na Fabric a získat tak přístup k novým funkcím napříč datovou vědou, analýzou v reálném čase a reportováním.
Externí tabulka odkazuje na data umístěná v Hadoopu, objektu blob služby Azure Storage nebo Azure Data Lake Storage (ADLS).
Pomocí externích tabulek můžete číst data ze souborů nebo zapisovat data do souborů ve službě Azure Storage. Pomocí Azure Synapse SQL můžete pomocí externích tabulek číst externí data pomocí vyhrazeného fondu SQL nebo bezserverového fondu SQL.
V závislosti na typu externího zdroje dat můžete použít dva typy externích tabulek:
- Externí tabulky Hadoop, které můžete použít ke čtení a exportu dat v různých datových formátech, jako jsou CSV, Parquet a ORC. Externí tabulky Hadoop jsou dostupné ve vyhrazených fondech SQL, ale nejsou dostupné v bezserverových fondech SQL.
- Nativní externí tabulky , které můžete použít ke čtení a exportu dat v různých datových formátech, jako jsou CSV a Parquet. Nativní externí tabulky jsou k dispozici v bezserverových fondech SQL a ve vyhrazených fondech SQL. Zápis a export dat pomocí CETAS a nativních externích tabulek je k dispozici pouze v bezserverovém fondu SQL, ale ne ve vyhrazených fondech SQL.
Hlavní rozdíly mezi Hadoopem a nativními externími tabulkami:
| Externí typ tabulky | Hadoop | Přirozený |
|---|---|---|
| Vyhrazený databázový fond SQL | dostupný | Pouze parkety |
| Bezserverový SQL pool | Není k dispozici | dostupný |
| Podporované formáty | Formát Oddělený/CSV, Parquet, ORC, Hive RC a RC | Bezserverový fond dotazů SQL: Oddělené/CSV, Parquet a Delta Lake Vyhrazený SQL fond: Parquet |
| Eliminace rozdělení složky | Ne | Odstranění partic je k dispozici pouze v particovaných tabulkách vytvořených ve formátech Parquet nebo CSV, které jsou synchronizované z fondů Apache Sparku. U složek s oddíly Parquet můžete vytvářet externí tabulky, ale sloupce dělení jsou nepřístupné a ignorují se, zatímco odstranění oddílu se nepoužije. Nevytvávejte externí tabulky ve složkách Delta Lake, protože nejsou podporované. Pokud potřebujete dotazovat dělená data Delta Lake, použijte dělená zobrazení Delta. |
| Odstranění souborů (pushdown predikátu) | Ne | Ano, v bezserverovém SQL fondu. Pro odsdílení řetězců je potřeba použít Latin1_General_100_BIN2_UTF8 kolaci sloupců VARCHAR , abyste povolili odsdílení. Další informace o kolacích najdete v tématu Podpora kolace databáze pro Synapse SQL ve službě Azure Synapse Analytics. |
| Vlastní formát pro umístění | Ne | Ano, použití zástupných znaků jako /year=*/month=*/day=* pro formáty Parquet nebo CSV. Cesty k vlastním složkám nejsou v Delta Lake dostupné. V bezserverovém fondu SQL můžete také pomocí rekurzivních zástupných /logs/** znaků odkazovat na soubory Parquet nebo CSV v libovolné podsložce pod odkazovanou složkou. |
| Rekurzivní prohledávání složek | Ano | Ano. V bezserverových fondech SQL je nutné zadat /** na konci cesty k umístění. V dedikovaném fondu se složky vždy rekurzivně prohledávají. |
| Ověřování úložiště | Přístupový klíč úložiště (SAK), průchod Microsoft Entra, spravovaná identita, vlastní identita aplikace Microsoft Entra | Shared Access Signature (SAS), Microsoft Entra Passthrough, Managed Identity, Vlastní aplikace Microsoft Entra identity. |
| Mapování sloupců | Řadový – sloupce v definici externí tabulky jsou mapovány na sloupce v podkladových souborech Parquet podle pozice. | Bezserverová skupina: podle názvu. Sloupce v definici externí tabulky jsou mapovány na sloupce v podkladových souborech Parquet podle odpovídajících názvů sloupců. Vyhrazený pool: pořadové párování. Sloupce v definici externí tabulky jsou mapovány na sloupce v podkladových souborech Parquet podle pozice. |
| CETAS (export/transformace) | Ano | CETAS s nativními tabulkami jako cílem funguje pouze v bezserverovém fondu SQL. Vyhrazené fondy SQL nemůžete použít k exportu dat pomocí nativních tabulek. |
Poznámka:
Nativní externí tabulky jsou doporučeným řešením ve datových fondech, kde jsou obecně dostupné. Pokud potřebujete přistupovat k externím datům, vždy používejte nativní tabulky v bezserverových nebo vyhrazených fondech. Tabulky Hadoop použijte jenom v případě, že potřebujete získat přístup k některým typům, které nejsou podporované v nativních externích tabulkách (například ORC, RC), nebo pokud nativní verze není dostupná.
Externí tabulky ve vyhrazeném SQL fondu a bezserverovém SQL fondu
Externí tabulky můžete použít k:
- Dotazování služby Azure Blob Storage a ADLS Gen2 pomocí příkazů Jazyka Transact-SQL
- Výsledky dotazů můžete ukládat do souborů ve službě Azure Blob Storage nebo Azure Data Lake Storage pomocí CETAS se Synapse SQL.
- Importujte data ze služby Azure Blob Storage a Azure Data Lake Storage a uložte je do vyhrazeného fondu SQL (pouze tabulky Hadoop ve vyhrazeném fondu).
Poznámka:
Pokud se používá s příkazem CREATE TABLE AS SELECT, výběr z externí tabulky importuje data do tabulky v rámci vyhrazenéhofondu SQL.
Pokud výkon externích tabulek Hadoop ve vyhrazených fondech nevyhovuje vašim cílům výkonu, zvažte načtení externích dat do tabulek datového skladu pomocí příkazu COPY.
Kurz načítání najdete v tématu Použití PolyBase k načtení dat ze služby Azure Blob Storage.
Externí tabulky ve fondech Synapse SQL můžete vytvořit pomocí následujících kroků:
- CREATE EXTERNAL DATA SOURCE pro odkazování na externí Azure Storage a určení přihlašovacích údajů, které by měly být použity pro přístup k úložišti.
- CREATE EXTERNAL FILE FORMAT pro popis formátu souborů CSV nebo Parquet.
- CREATE EXTERNAL TABLE nad soubory umístěné ve zdroji dat se stejným formátem souboru.
Odstranění oddělení složek
Nativní externí tabulky ve fondech Synapse můžou ignorovat soubory umístěné ve složkách, které nejsou pro dotazy relevantní. Pokud jsou vaše soubory uložené v hierarchii složek (například - /year=2020/month=03/day=16) a hodnoty pro yearmonth, a day jsou zpřístupněny jako sloupce, dotazy obsahující filtry, jako year=2020 jsou, budou číst soubory pouze z podsložek umístěných ve year=2020 složce. Soubory a složky umístěné v jiných složkách (year=2021 nebo year=2022) budou v tomto dotazu ignorovány. Tato eliminace se označuje jako eliminace oddílu.
Odstranění oddílů adresářů je k dispozici v nativních externích tabulkách, které jsou synchronizovány z poolů Synapse Spark. Pokud máte dělenou datovou sadu a chcete použít odstranění oddílů s externími tabulkami, které vytvoříte, použijte místo externích tabulek rozdělená zobrazení .
Odstranění souboru
Některé formáty dat, jako jsou Parquet a Delta, obsahují statistiky souborů pro každý sloupec (například minimální/maximální hodnoty pro každý sloupec). Dotazy, které filtrují data, nebudou číst soubory, ve kterých požadované hodnoty sloupců neexistují. Dotaz nejprve prozkoumá minimální a maximální hodnoty sloupců použitých v predikátu dotazu a vyhledá soubory, které neobsahují požadovaná data. Tyto soubory se ignorují a eliminují z plánu dotazu.
Tato technika se také označuje jako posun predikátu filtru a může zlepšit výkon vašich dotazů. Propagace filtru je k dispozici v bezserverových SQL fondech na formátech Parquet a Delta. Chcete-li použít odsdílení filtru pro typy řetězců, použijte typ VARCHAR s Latin1_General_100_BIN2_UTF8 kolací. Další informace o kolacích najdete v tématu Podpora kolace databáze pro Synapse SQL ve službě Azure Synapse Analytics.
Zabezpečení
Uživatel musí mít SELECT oprávnění k externí tabulce ke čtení dat.
Externí tabulky přistupují k podkladovému úložišti Azure pomocí přihlašovacích údajů s rozsahem databáze, které jsou definovány ve zdroji dat podle následujících pravidel:
- Zdroj dat bez přihlašovacích údajů umožňuje externím tabulkám přístup k veřejně dostupným souborům v úložišti Azure.
- Zdroj dat může mít přihlašovací údaje, které umožňují externím tabulkám přistupovat pouze k souborům v úložišti Azure pomocí tokenu SAS nebo spravované identity pracovního prostoru . Příklady najdete v článku Vývoj souborů úložiště pro řízení přístupu.
Poznámky
Aby bylo zajištěno spolehlivé provádění dotazů, musí zdrojové soubory a složky odkazované externími tabulkami zůstat po celou dobu trvání operace beze změny.
- Úprava, odstranění nebo nahrazení všech odkazovaných souborů nebo složek v době, kdy je dotaz spuštěný, může způsobit selhání nebo vést k nekonzistentním výsledkům.
- Před dotazováním externích tabulek ve vyhrazeném fondu SQL ověřte, že jsou všechna zdrojová data stabilní a během provádění se nezmění.
Příklad pro VYTVOŘENÍ EXTERNÍHO ZDROJE DAT
Následující příklad vytvoří externí zdroj dat Hadoop ve vyhrazeném fondu SQL pro ADLS Gen2 odkazující na veřejnou datovou sadu New York:
CREATE DATABASE SCOPED CREDENTIAL [ADLS_credential]
WITH IDENTITY='SHARED ACCESS SIGNATURE',
SECRET = 'sv=2022-11-02&ss=b&srt=co&sp=rl&se=2042-11-26T17:40:55Z&st=2024-11-24T09:40:55Z&spr=https&sig=DKZDuSeZhuCWP9IytWLQwu9shcI5pTJ%2Fw5Crw6fD%2BC8%3D'
GO
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH
-- Please note the abfss endpoint when your account has secure transfer enabled
( LOCATION = 'abfss://data@newyorktaxidataset.dfs.core.windows.net' ,
CREDENTIAL = ADLS_credential ,
TYPE = HADOOP
) ;
Následující příklad vytvoří externí zdroj dat pro ADLS Gen2 odkazující na veřejně dostupnou sadu dat New Yorku:
CREATE EXTERNAL DATA SOURCE YellowTaxi
WITH ( LOCATION = 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/',
TYPE = HADOOP)
Příklad příkazu CREATE EXTERNAL FILE FORMAT
Následující příklad vytvoří formát externího souboru pro soubory sčítání lidu:
CREATE EXTERNAL FILE FORMAT census_file_format
WITH
(
FORMAT_TYPE = PARQUET,
DATA_COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
Příklad CREATE EXTERNAL TABLE
Následující příklad vytvoří externí tabulku. Vrátí první řádek:
CREATE EXTERNAL TABLE census_external_table
(
decennialTime varchar(20),
stateName varchar(100),
countyName varchar(100),
population int,
race varchar(50),
sex varchar(10),
minAge int,
maxAge int
)
WITH (
LOCATION = '/parquet/',
DATA_SOURCE = population_ds,
FILE_FORMAT = census_file_format
)
GO
SELECT TOP 1 * FROM census_external_table
Vytvoření a dotazování externích tabulek ze souboru v Azure Data Lake
Pomocí možností zkoumání Datové Jezero v nástroji Synapse Studio teď můžete vytvořit a dotazovat externí tabulku pomocí fondu Synapse SQL kliknutím pravým tlačítkem myši na soubor. Gesto jedním kliknutím pro vytvoření externích tabulek z účtu úložiště ADLS Gen2 je podporováno pouze pro soubory Parquet.
Požadavky
Musíte mít přístup k pracovnímu prostoru s alespoň
Storage Blob Data Contributorrolí přístupu k účtu ADLS Gen2 nebo seznamům řízení přístupu (ACL), které umožňují dotazovat se na soubory.K vytvoření externí tabulky a dotazování externích tabulek ve fondu Synapse SQL (vyhrazeném nebo bez serveru) musíte mít alespoň oprávnění.
Na panelu Data vyberte soubor, ze kterého chcete vytvořit externí tabulku:

Otevře se dialogové okno. Vyberte vyhrazený fond SQL nebo bezserverový fond SQL, pojmenujte tabulku a vyberte otevřený skript:
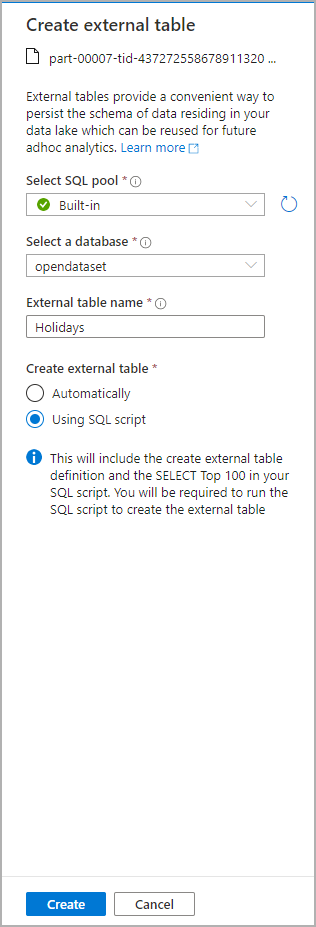
Skript SQL je automaticky vygenerován odvození schématu ze souboru:

Spusťte skript. Skript automaticky spustí SELECT TOP 100 *:

Externí tabulka je nyní vytvořena. Nyní můžete dotazovat externí tabulku přímo z podokna Data.
Související obsah
Informace o ukládání výsledků dotazů do externí tabulky ve službě Azure Storage najdete v článku CETAS. Nebo můžete začít dotazovat Apache Spark pro externí tabulky Azure Synapse.