Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tip
Microsoft Fabric Data Warehouse je relační sklad v podnikovém měřítku na základu datového jezera s architekturou připravenou pro budoucnost, integrovanou AI a novými funkcemi. Pokud s datovými sklady začínáte, začněte pracovat s Fabric Data Warehouse. Stávající úlohy fondu dedikované SQL můžou upgradovat na Fabric a získat tak přístup k novým funkcím napříč datovou vědou, analýzou v reálném čase a reportováním.
V tomto článku se dozvíte, jak dotazovat jeden soubor CSV pomocí bezserverového fondu SQL ve službě Azure Synapse Analytics. Soubory CSV můžou mít různé formáty:
- S řádkem záhlaví a bez řádku záhlaví
- Hodnoty oddělené čárkou a tabulátorem
- Konce řádků ve stylu Windows a Unix
- Necitované a citované hodnoty a znaky pro escapování
Všechny výše uvedené varianty budou popsány níže.
Příklad rychlého startu
OPENROWSET funkce umožňuje číst obsah souboru CSV zadáním adresy URL souboru.
Čtení souboru CSV
Nejjednodušší způsob, jak zobrazit obsah CSV souboru, je zadat adresu URL souboru pro OPENROWSET funkci, zadat csv FORMATa 2.0 PARSER_VERSION. Pokud je soubor veřejně dostupný nebo pokud má vaše identita Microsoft Entra přístup k tomuto souboru, měli byste být schopni zobrazit obsah souboru pomocí dotazu, jako je ten zobrazený v následujícím příkladu:
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2 ) as rows
Možnost firstrow slouží ke přeskočení prvního řádku v souboru CSV, který v tomto případě představuje záhlaví. Ujistěte se, že máte přístup k tomuto souboru. Pokud je soubor chráněný klíčem SAS nebo vlastní identitou, budete muset nastavit přihlašovací údaje na úrovni serveru pro přihlášení SQL.
Důležité
Pokud soubor CSV obsahuje znaky UTF-8, ujistěte se, že používáte kolaci databáze UTF-8 (například Latin1_General_100_CI_AS_SC_UTF8).
Neshoda mezi kódováním textu v souboru a kolací může způsobit neočekávané chyby převodu.
Výchozí kolaci aktuální databáze můžete snadno změnit pomocí následujícího příkazu T-SQL: alter database current collate Latin1_General_100_CI_AI_SC_UTF8
Využití zdroje dat
Předchozí příklad používá úplnou cestu k souboru. Jako alternativu můžete vytvořit externí zdroj dat s umístěním, které odkazuje na kořenovou složku úložiště:
create external data source covid
with ( location = 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases' );
Jakmile vytvoříte zdroj dat, můžete použít tento zdroj dat a relativní cestu k souboru ve OPENROWSET funkci:
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) as rows
Pokud je zdroj dat chráněný klíčem SAS nebo vlastní identitou, můžete zdroj dat nakonfigurovat s pověřením v oboru databáze.
Explicitní zadání schématu
OPENROWSET umožňuje explicitně určit, které sloupce chcete ze souboru číst pomocí WITH klauzule:
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) with (
date_rep date 1,
cases int 5,
geo_id varchar(6) 8
) as rows
Čísla za datovým typem v WITH klauzuli představují index sloupců v souboru CSV.
Důležité
Pokud soubor CSV obsahuje znaky UTF-8, ujistěte se, že explicitně zadáváte kolaci UTF-8 (například Latin1_General_100_CI_AS_SC_UTF8) pro všechny sloupce v klauzuli WITH nebo nastavte určitou kolaci UTF-8 na úrovni databáze.
Neshoda mezi kódováním textu v souboru a kolací může způsobit neočekávané chyby převodu.
Výchozí kolaci aktuální databáze můžete snadno změnit pomocí následujícího příkazu T-SQL:
alter database current collate Latin1_General_100_CI_AI_SC_UTF8 Kolaci u typů sloupců můžete snadno nastavit pomocí následující definice: geo_id varchar(6) collate Latin1_General_100_CI_AI_SC_UTF8 8
V následujících částech se dozvíte, jak dotazovat různé typy souborů CSV.
Požadavky
Prvním krokem je vytvoření databáze , ve které se tabulky vytvoří. Potom objekty inicializujete spuštěním instalačního skriptu v této databázi. Tento instalační skript vytvoří zdroje dat, přihlašovací údaje s oborem databáze a formáty externích souborů, které se používají v těchto ukázkách.
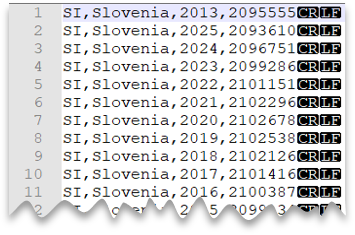
Nový řádek ve stylu Windows
Následující dotaz ukazuje, jak číst soubor CSV bez řádku záhlaví, s novým řádkem ve stylu Windows a sloupci oddělenými čárkami.
Náhled souboru:
SELECT *
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
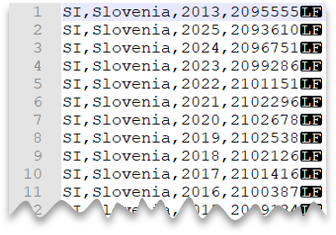
Nový řádek ve stylu Unixu
Následující dotaz ukazuje, jak číst soubor bez řádku záhlaví, s novým řádkem ve stylu Unixu a sloupci oddělenými čárkami. Všimněte si jiného umístění souboru v porovnání s jinými příklady.
Náhled souboru:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
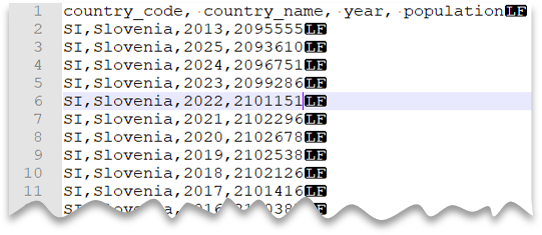
Řádek záhlaví
Následující dotaz ukazuje, jak číst soubor s řádkem záhlaví, s novým řádkem ve stylu Unixu a sloupci oddělenými čárkami. Všimněte si jiného umístění souboru v porovnání s jinými příklady.
Náhled souboru:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
HEADER_ROW = TRUE
) AS [r]
Možnost HEADER_ROW = TRUE způsobí čtení názvů sloupců z řádku záhlaví v souboru. Je to skvělé pro účely průzkumu, když nejste obeznámeni s obsahem souboru. Pro dosažení nejlepšího výkonu se podívejte do sekce Použití vhodných datových typů v rámci Osvědčených postupů. Zde si také můžete přečíst další informace o syntaxi OPENROWSET.
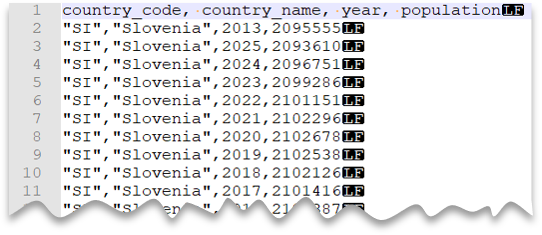
Vlastní znak pro uvozovky
Následující dotaz ukazuje, jak číst soubor s řádkem záhlaví, s novým řádkem ve stylu Unixu, sloupci oddělenými čárkou a hodnotami v uvozovkách. Všimněte si jiného umístění souboru v porovnání s jinými příklady.
Náhled souboru:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
FIELDQUOTE = '"'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
Poznámka:
Tento dotaz by vrátil stejné výsledky, pokud jste parametr FIELDQUOTE vynechali, protože výchozí hodnota pro FIELDQUOTE je dvojitá uvozovka.
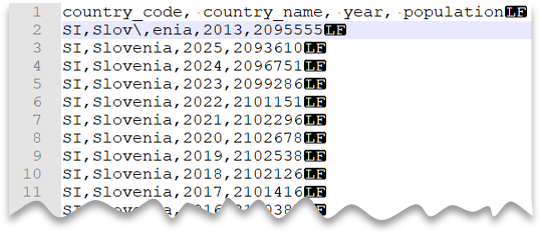
Únikové znaky
Následující dotaz ukazuje, jak číst soubor s řádkem záhlaví, s novým řádkem ve stylu Unixu, sloupci oddělenými čárkami a únikovým znakem použitým pro oddělovač polí (čárka) v hodnotách. Všimněte si jiného umístění souboru v porovnání s jinými příklady.
Náhled souboru:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
ESCAPECHAR = '\\'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
Poznámka:
Tento dotaz selže, pokud není zadán ESCAPECHAR, protože čárka ve "Slov,enia" by byla považována za oddělovač polí místo části názvu země/oblasti. Slov, enia by byla považována za dva sloupce. Proto by měl konkrétní řádek jeden sloupec více než ostatní řádky a jeden sloupec více, než jste definovali v klauzuli WITH.
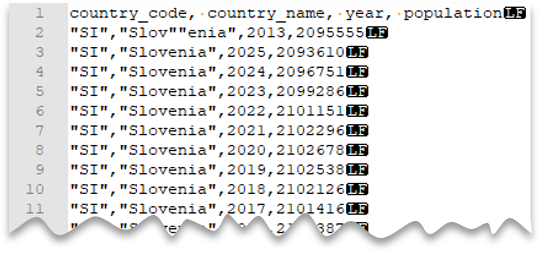
Znak při escapování uvozovek
Následující dotaz ukazuje, jak číst soubor s řádkem záhlaví, s novým řádkem ve stylu Unixu, sloupci oddělenými čárkami a řídicím znakem uvozovek v rámci hodnot. Všimněte si jiného umístění souboru v porovnání s jinými příklady.
Náhled souboru:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
Poznámka:
Znak uvozování musí být odstraněn dalším znakem uvozování. Znak uvozování se může objevit v hodnotě sloupce pouze tehdy, je-li hodnota ohraničena znaky uvozování.
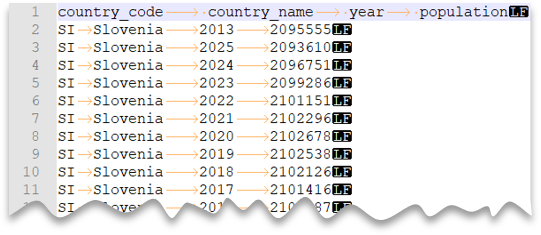
Soubor oddělený tabulátory
Následující dotaz ukazuje, jak číst soubor s řádkem záhlaví, s formátováním nového řádku ve stylu Unixu a se sloupci oddělenými tabulátory. Všimněte si jiného umístění souboru v porovnání s jinými příklady.
Náhled souboru:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-tsv/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR ='\t',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017
Vrátit podmnožinu sloupců
Zatím jste pomocí příkazu WITH zadali schéma souboru CSV a vypisovali všechny sloupce. Sloupce, které ve svém dotazu skutečně potřebujete, můžete zadat pouze pomocí pořadového čísla pro každý sloupec, který potřebujete. Vynecháte také sloupce, které vás nezajímají.
Následující dotaz vrátí počet jedinečných názvů zemí a oblastí v souboru, který určuje pouze sloupce, které jsou potřeba:
Poznámka:
Podívejte se na klauzuli WITH v dotazu níže a všimněte si, že na konci řádku je "2" (bez uvozovek), kde definujete sloupec [country_name]. Znamená to, že sloupec [country_name] je druhý sloupec v souboru. Dotaz bude ignorovat všechny sloupce v souboru s výjimkou druhého sloupce.
SELECT
COUNT(DISTINCT country_name) AS countries
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
--[country_code] VARCHAR (5),
[country_name] VARCHAR (100) 2
--[year] smallint,
--[population] bigint
) AS [r]
Dotazování přidávaných souborů
Soubory CSV, které se používají v dotazu, by se neměly měnit, když je dotaz spuštěný. V dlouhotrvajícím dotazu může fond SQL opakovat čtení, číst části souborů nebo dokonce číst soubor několikrát. Změny obsahu souboru by způsobily nesprávné výsledky. SQL pool proto dotaz selže, pokud zjistí, že během provádění dotazu se změní doba poslední úpravy libovolného souboru.
V některých scénářích můžete chtít číst soubory, které jsou neustále připojené. Abyste se vyhnuli selhání dotazů kvůli neustále přidávaným souborům, můžete povolit funkci OPENROWSET, aby ignorovala potenciálně nekonzistentní čtení pomocí nastavení ROWSET_OPTIONS.
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2,
ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}') as rows
Možnost ALLOW_INCONSISTENT_READS čtení zakáže kontrolu času úpravy souboru během životního cyklu dotazu a přečte, co je v souboru k dispozici. V doplňovatelných souborech se stávající obsah neaktualizuje a přidají se jenom nové řádky. Proto je pravděpodobnost nesprávných výsledků minimalizovaná ve srovnání s aktualizovatelnými soubory. Tato možnost vám může umožnit čtení často připojených souborů bez zpracování chyb. Ve většině scénářů fond SQL bude jenom ignorovat některé řádky, které jsou připojeny k souborům během provádění dotazu.
Související obsah
V dalších článcích se dozvíte, jak: