Project Flash – Monitorování dostupnosti virtuálních počítačů Azure pomocí Azure Resource Graphu
Azure Resource Graph je jedno řešení, které nabízí Flash. Flash je interní název projektu vyhrazeného pro vytvoření robustního, spolehlivého a rychlého mechanismu, který zákazníkům umožňuje monitorovat stav virtuálního počítače.
Tento článek popisuje použití Azure Resource Graphu k monitorování dostupnosti virtuálních počítačů Azure. Obecný přehled řešení Flash najdete v přehledu aplikace Flash.
Pro dokumentaci specifickou pro ostatní řešení, která flash nabízí, si vyberte z následujících článků:
- Použití témat systému Event Gridu k monitorování dostupnosti virtuálních počítačů Azure
- Monitorování dostupnosti virtuálních počítačů Azure pomocí služby Azure Monitor
- Použití služby Azure Resource Health k monitorování dostupnosti virtuálních počítačů Azure
Azure Resource Graph – HealthResources
Tato funkce je aktuálně obecně dostupná. Je užitečné provádět rozsáhlé šetření. Nabízí vysoce uživatelsky přívětivé prostředí pro načítání informací s použitím dotazovacího jazyka Kusto (KQL). Může také sloužit jako centrální centrum pro informace o prostředcích a umožňuje snadné načítání historických dat.
Kromě stavu dostupnosti virtuálních počítačů jsme publikovali poznámky k dostupnosti virtuálních počítačů do Azure Resource Graphu (ARG) pro podrobnou analýzu přiřazování selhání a výpadků spolu s povolením 14denního mechanismu sledování změn pro sledování historických změn v dostupnosti virtuálních počítačů pro rychlé ladění. S těmito novými doplňky s radostí oznamujeme obecnou dostupnost informací o dostupnosti virtuálních počítačů v datové sadě HealthResources v ARG! S touto nabídkou můžou uživatelé:
- Efektivní dotazování na nejnovější snímek dostupnosti virtuálních počítačů napříč všemi předplatnými Azure najednou a s nízkou latencí pro pravidelné a celoplošné monitorování.
- Přesné posouzení dopadu na smlouvy SLA pro celou celou řadu firem a rychlé spuštění rozhodujících opatření pro zmírnění rizik v reakci na narušení a typ podpisu selhání.
- Nastavte vlastní řídicí panely tak, aby dohlížely na komplexní stav aplikací připojením informací o dostupnosti virtuálních počítačů s metadaty prostředků, které jsou přítomné v ARG.
- Pomocí mechanismu sledování změn pro provádění podrobných šetření můžete sledovat relevantní změny dostupnosti virtuálních počítačů v průběhu 14 dnů.
Vzorové dotazy
- Ukázkové dotazy Azure Resource Graphu pro Azure Service Health – Azure Service Health | Microsoft Learn
- Informace o dostupnosti virtuálních počítačů v Azure Resource Graphu – Azure Virtual Machines | Microsoft Learn
- Seznam ukázkových dotazů Azure Resource Graphu podle tabulky – Azure Resource Graph | Microsoft Learn
Začínáme
Uživatelé se můžou dotazovat na ARG prostřednictvím PowerShellu, rozhraní REST API, Azure CLI nebo webu Azure Portal. Následující postup podrobně popisuje přístup k datům z webu Azure Portal.
Na webu Azure Portal přejděte do Průzkumníka služby Resource Graph.

Vyberte kartu Tabulka a kliknutím na tabulku HealthResources načtěte nejnovější snímek informací o dostupnosti virtuálních počítačů (stav dostupnosti a poznámky ke stavu).
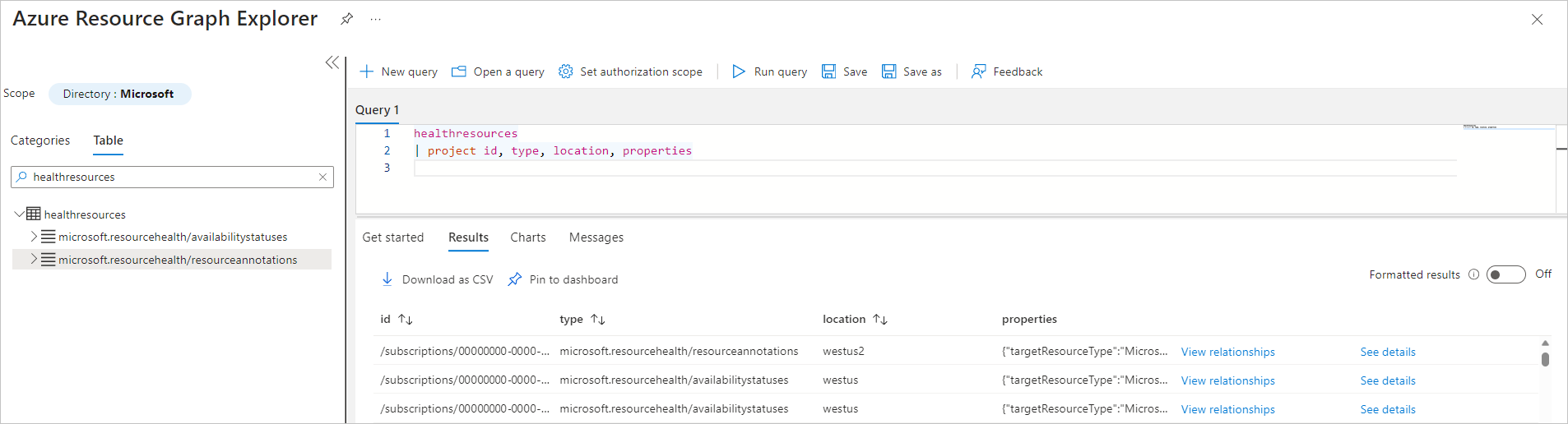


V tabulce HealthResources jsou vyplněné dva typy událostí:

- resourcehealth /availabilitystatuses
Tato událost označuje nejnovější stav dostupnosti virtuálního počítače na základě kontrol stavu provedených základní platformou Azure. Stavy dostupnosti, které aktuálně vysíláme pro virtuální počítače, jsou:
- K dispozici: Virtuální počítač je spuštěný podle očekávání.
- Nedostupné: Zjistili jsme přerušení normálního fungování virtuálního počítače, a proto se aplikace nespustí podle očekávání.
- Neznámé: Platforma nemůže přesně zjistit stav virtuálního počítače. Uživatelé se obvykle můžou v aktualizovaném stavu vrátit za několik minut.
Pokud chcete dotazovat nejnovější stav dostupnosti virtuálního počítače, projděte si pole vlastností, které obsahuje následující podrobnosti:
Vzorek
{
"targetResourceType": "Microsoft.Compute/virtualMachines",
"previousAvailabilityState": "Available",
"targetResourceId": "/subscriptions//resourceGroups//providers/Microsoft.Compute/virtualMachines/",
"occurredTime": "2022-10-11T11:13:59.9570000Z",
"availabilityState": "Unavailable"
}
Popis vlastnosti
| Vlastnost | Popis | Odpovídající kategorie stavu prostředků (RHC) |
|---|---|---|
| targetResourceType | Typ prostředku, pro který proudí data o stavu | resourceType |
| targetResourceId | ID zdroje | resourceId |
| occurredTime | Časové razítko, kdy platforma generuje nejnovější stav dostupnosti | eventTimestamp |
| previousAvailabilityState | Předchozí stav dostupnosti virtuálního počítače | previousHealthStatus |
| availabilityState | Aktuální stav dostupnosti virtuálního počítače | currentHealthStatus |
Seznam úvodních dotazů pro další zkoumání těchto dat najdete v části HealthResources v dokumentaci k ukázkovým dotazům.
- resourcehealth /resourceannotations (NOVĚ PŘIDANÉ)
Tato událost v kontextualizuje všechny změny dostupnosti virtuálního počítače tím, že podrobně popisuje nezbytné atributy selhání, které uživatelům pomůžou prozkoumat a zmírnit přerušení podle potřeby. Podívejte se na úplný seznam poznámek k dostupnosti virtuálních počítačů generovaných platformou. Tyto poznámky lze široce klasifikovat do tří kontejnerů:
- Poznámky k výpadkům: Tyto poznámky se vygenerují, když platforma zjistí, že dostupnost virtuálního počítače přejde na nedostupný. (Například při neočekávaných chybových ukončeních hostitele, restartování operací opravy).
- Informační poznámky: Tyto poznámky se vygenerují během aktivit roviny řízení bez dopadu na dostupnost virtuálních počítačů. (Například přidělení virtuálního počítače, zastavení, odstranění, spuštění). Obvykle se nevyžaduje žádná další akce zákazníka v reakci.
- Degradované poznámky: Tyto poznámky se vygenerují, když se zjistí, že je dostupnost virtuálního počítače ohrožená. (Pokud například modely predikce selhání predikují degradovanou hardwarovou komponentu, která může způsobit restartování virtuálního počítače v libovolném okamžiku). Důrazně vyzýváme uživatele, aby se do konečného termínu zadaného ve zprávě poznámky znovu nasadily, aby nedošlo k neočekávané ztrátě dat nebo výpadků. V jednom z následujících scénářů můžete obdržet upozornění ve službě Azure Virtual Machine Scale Sets Resource Health nebo v protokolu aktivit:
- Virtuální počítače ve škálovacích sadách virtuálních počítačů Azure jsou v procesu zastavení, zrušení přidělení, odstranění nebo spuštění.
- Provedli jste operace horizontálního navýšení nebo snížení kapacity ve škálovacích sadách virtuálních počítačů.
- Výstraha indikuje, že agregovaný stav platformy škálovacích sad virtuálních počítačů je v přechodném stavu Degradováno.
Pokud chcete dotazovat přidružené poznámky k dostupnosti virtuálního počítače pro prostředek( pokud existuje), projděte si pole vlastností, které obsahuje následující podrobnosti:
Vzorek
{
"targetResourceType": "Microsoft.Compute/virtualMachines", "targetResourceId": "/subscriptions//resourceGroups//providers/Microsoft.Compute/virtualMachines/",
"annotationName": "VirtualMachineHostRebootedForRepair",
"occurredTime": "2022-09-25T20:21:37.5280000Z",
"category": "Unplanned",
"summary": "We're sorry, your virtual machine isn't available because an unexpected failure on the host server. Azure has begun the auto-recovery process and is currently rebooting the host server. No further action is required from you at this time. The virtual machine will be back online after the reboot completes.",
"context": "Platform Initiated",
"reason": "Unexpected host failure"
}
Popis vlastnosti
| Vlastnost | Popis | Odpovídající RHC |
|---|---|---|
| targetResourceType | Typ prostředku, pro který proudí data o stavu | resourceType |
| targetResourceId | ID zdroje | resourceId |
| occurredTime | Časové razítko, kdy platforma vygeneruje nejnovější stav dostupnosti | eventTimestamp |
| annotationName | Název generované poznámky | eventName |
| reason | Stručný přehled dopadu dostupnosti pozorovaného zákazníkem | title |
| category | Označuje, jestli aktivita platformy, která aktivovala poznámku, byla plánovaná údržba nebo neplánovaná oprava. Toto pole se nevztahuje na události iniciované zákazníkem nebo virtuálním počítačem. Možné hodnoty: Plánované, Neplánované, Nepoužitelné, Null | category |
| kontext | Označuje, jestli aktivita, která aktivovala poznámku, byla způsobená autorizovaným uživatelem nebo procesem (iniciovaným zákazníkem), platformou Azure (iniciovanou platformou) nebo aktivitou v hostovaném operačním systému, které způsobily dopad na dostupnost (iniciovaný virtuální počítač). Možné hodnoty: Iniciované platformou, iniciované uživatelem, inicializováno virtuální počítač, nepoužitelné, Null | kontext |
| Souhrn | Prohlášení s podrobnostmi o příčině emisí poznámek spolu s nápravnými kroky, které mohou uživatelé provést | Souhrn |
Seznam úvodních dotazů pro další zkoumání těchto dat najdete v části HealthResources v dokumentaci k ukázkovým dotazům.
Pro metadata poznámek, která se nacházejí v datové sadě HealthResources, plánujeme několik vylepšení. Díky těmto rozšiřováním mají uživatelé přístup k bohatším atributům selhání, aby mohli rozhodujícím způsobem připravit odpověď na přerušení. Současně se snažíme prodloužit dobu trvání historického zpětného vyhledávání na minimálně 30 dnů, aby uživatelé mohli komplexně sledovat minulé změny dostupnosti virtuálních počítačů.
Další kroky
Další informace o nabízených řešeních najdete v příslušném článku o řešení:
- Použití témat systému Event Gridu k monitorování dostupnosti virtuálních počítačů Azure
- Monitorování dostupnosti virtuálních počítačů Azure pomocí služby Azure Monitor
- Použití služby Azure Resource Health k monitorování dostupnosti virtuálních počítačů Azure
Obecný přehled o monitorování virtuálních počítačů Azure najdete v tématu Monitorování virtuálních počítačů Azure a referenční informace k monitorování virtuálních počítačů Azure.