Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tento článek ukazuje, jak ladit aplikaci, která používá akcelerovaný masivní paralelismus C++ (C++ AMP) k využití grafických procesorů (GPU). Používá paralelní redukční program, který sečte velké množství celých čísel. Tento návod popisuje následující kroky:
- Spuštění ladicího programu GPU
- Prohlížení vláken GPU v okně vláken GPU
- Pomocí okna Paralelní zásobníky můžete současně sledovat zásobníky volání více vláken GPU.
- Použití okna Paralelní sledování ke kontrole hodnot jednoho výrazu ve více vláknech najednou.
- Označení, zmrazení, rozmrazování a seskupování vláken GPU
- Spustit všechna vlákna dlaždice na konkrétní místo v kódu.
Předpoklady
Než začnete s tímto návodem:
Poznámka:
Hlavičky C++ AMP jsou zastaralé od sady Visual Studio 2022 verze 17.0.
Zahrnutím všech hlaviček AMP se vygenerují chyby sestavení. Před zahrnutím jakýchkoli hlaviček AMP definujte _SILENCE_AMP_DEPRECATION_WARNINGS, abyste ztlumili varování.
- Přečtěte si Přehled C++ AMP.
- Ujistěte se, že se v textovém editoru zobrazují čísla řádků. Další informace naleznete v tématu Postupy: Zobrazení čísel řádků v editoru.
- Ujistěte se, že používáte alespoň Windows 8 nebo Windows Server 2012 a podporujete ladění v emulátoru softwaru.
Poznámka:
Váš počítač může v následujících pokynech zobrazovat odlišné názvy nebo umístění některých prvků uživatelského rozhraní sady Visual Studio. Edice sady Visual Studio, kterou máte, a nastavení, která používáte, určují tyto prvky. Další informace najdete v tématu Přizpůsobení integrovaného vývojového prostředí.
Vytvoření ukázkového projektu
Pokyny k vytvoření projektu se liší podle toho, jakou verzi sady Visual Studio používáte. Ujistěte se, že máte nad obsahovou tabulkou na této stránce vybranou správnou verzi dokumentace.
Vytvoření ukázkového projektu v sadě Visual Studio
Na řádku nabídek zvolte Soubor>nový>projekt a otevřete dialogové okno Vytvořit nový projekt.
V horní části dialogového okna nastavte jazyk na C++, nastavte platformu pro Windows a nastavte typ projektu na konzolu.
V filtrovaném seznamu typů projektů zvolte Konzolová aplikace a pak zvolte Další. Na další stránce zadejte
AMPMapReducedo pole Název název projektu a zadejte umístění projektu, pokud chcete jiný.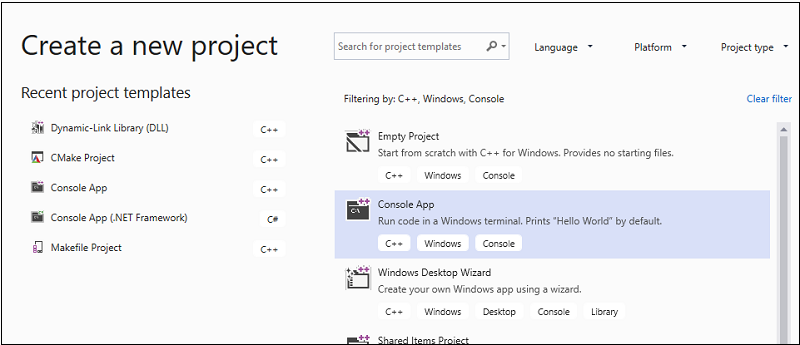
Zvolte tlačítko Vytvořit a vytvořte projekt klienta.
Další:
Otevřete AMPMapReduce.cpp a nahraďte jeho obsah následujícím kódem.
// AMPMapReduce.cpp defines the entry point for the program. // The program performs a parallel-sum reduction that computes the sum of an array of integers. #include <stdio.h> #include <tchar.h> #include <amp.h> const int BLOCK_DIM = 32; using namespace concurrency; void sum_kernel_tiled(tiled_index<BLOCK_DIM> t_idx, array<int, 1> &A, int stride_size) restrict(amp) { tile_static int localA[BLOCK_DIM]; index<1> globalIdx = t_idx.global * stride_size; index<1> localIdx = t_idx.local; localA[localIdx[0]] = A[globalIdx]; t_idx.barrier.wait(); // Aggregate all elements in one tile into the first element. for (int i = BLOCK_DIM / 2; i > 0; i /= 2) { if (localIdx[0] < i) { localA[localIdx[0]] += localA[localIdx[0] + i]; } t_idx.barrier.wait(); } if (localIdx[0] == 0) { A[globalIdx] = localA[0]; } } int size_after_padding(int n) { // The extent might have to be slightly bigger than num_stride to // be evenly divisible by BLOCK_DIM. You can do this by padding with zeros. // The calculation to do this is BLOCK_DIM * ceil(n / BLOCK_DIM) return ((n - 1) / BLOCK_DIM + 1) * BLOCK_DIM; } int reduction_sum_gpu_kernel(array<int, 1> input) { int len = input.extent[0]; //Tree-based reduction control that uses the CPU. for (int stride_size = 1; stride_size < len; stride_size *= BLOCK_DIM) { // Number of useful values in the array, given the current // stride size. int num_strides = len / stride_size; extent<1> e(size_after_padding(num_strides)); // The sum kernel that uses the GPU. parallel_for_each(extent<1>(e).tile<BLOCK_DIM>(), [&input, stride_size] (tiled_index<BLOCK_DIM> idx) restrict(amp) { sum_kernel_tiled(idx, input, stride_size); }); } array_view<int, 1> output = input.section(extent<1>(1)); return output[0]; } int cpu_sum(const std::vector<int> &arr) { int sum = 0; for (size_t i = 0; i < arr.size(); i++) { sum += arr[i]; } return sum; } std::vector<int> rand_vector(unsigned int size) { srand(2011); std::vector<int> vec(size); for (size_t i = 0; i < size; i++) { vec[i] = rand(); } return vec; } array<int, 1> vector_to_array(const std::vector<int> &vec) { array<int, 1> arr(vec.size()); copy(vec.begin(), vec.end(), arr); return arr; } int _tmain(int argc, _TCHAR* argv[]) { std::vector<int> vec = rand_vector(10000); array<int, 1> arr = vector_to_array(vec); int expected = cpu_sum(vec); int actual = reduction_sum_gpu_kernel(arr); bool passed = (expected == actual); if (!passed) { printf("Actual (GPU): %d, Expected (CPU): %d", actual, expected); } printf("sum: %s\n", passed ? "Passed!" : "Failed!"); getchar(); return 0; }Na řádku nabídek zvolte Soubor>Uložit vše.
V Průzkumník řešení otevřete kontextovou nabídku pro AMPMapReduce a pak vyberte Vlastnosti.
V dialogovém okně Stránky vlastností v části Vlastnosti konfigurace zvolte C/C++>předkompilované hlavičky.
Předkompilovaná hlavička vyberte Nepoužívat předkompilované hlavičky a pak zvolte Tlačítko OK.
Na řádku nabídek zvolte Sestavit>Sestavit řešení.
Ladění kódu procesoru
V tomto postupu použijete místní ladicí program systému Windows k ověření správnosti kódu procesoru v této aplikaci. Segment kódu CPU v této aplikaci, který je zvlášť zajímavý, je ta smyčka for ve funkci reduction_sum_gpu_kernel. Řídí paralelní redukci založenou na stromové struktuře, běžící na GPU.
Pro ladění kódu CPU
V Průzkumník řešení otevřete kontextovou nabídku pro AMPMapReduce a pak vyberte Vlastnosti.
V dialogovém okně Stránky vlastností, v oddílu Vlastnosti konfigurace, zvolte Ladění. Ověřte, že je v seznamu ladicích programů pro spuštění vybrán místní ladicí program Windows.
Vraťte se do Editoru kódu.
Nastavte body přerušení na řádcích kódu zobrazených na následujícím obrázku (přibližně řádky 67 až 70).

Zarážky procesoruNa řádku nabídek zvolte Ladění>Spustit ladění.
V okně Místní sledujte hodnotu
stride_size, dokud není dosaženo zarážky na řádku 70.Na řádku nabídek zvolte Ladění>Zastavit ladění.
Ladění kódu GPU
Tato část ukazuje, jak ladit kód GPU, což je kód obsažený ve sum_kernel_tiled funkci. Kód GPU vypočítá součet celých čísel pro každý blok paralelně.
Pro ladění kódu GPU
V Průzkumník řešení otevřete kontextovou nabídku pro AMPMapReduce a pak vyberte Vlastnosti.
V dialogovém okně Stránky vlastností, v oddílu Vlastnosti konfigurace, zvolte Ladění.
V seznamu ladicí program ke spuštění vyberte lokální ladicí program Windows.
V seznamu Typ ladicího programu ověřte, zda je vybrána možnost Auto.
Automaticky je výchozí hodnota. Ve verzích před Windows 10 je požadovaná hodnota GPU Only místo Auto.
Zvolte tlačítko OK.
Nastavte zarážku na řádku 30, jak je znázorněno na následujícím obrázku.

Bod přerušení GPUNa řádku nabídek zvolte Ladění>Spustit ladění. Zarážky v kódu procesoru na řádcích 67 a 70 se nespustí během ladění GPU, protože tyto řádky kódu běží na procesoru.
Jak používat okno vláken GPU
Pokud chcete otevřít okno Vlákna GPU, na řádku nabídek zvolte Ladit>Windows>Vlákna GPU.
Stav vláken GPU můžete zkontrolovat v okně GPU Vlákna, které se zobrazí.
Ukotvěte okno vláken GPU v dolní části sady Visual Studio. Kliknutím na tlačítko Rozbalit vlákno zobrazíte textová pole vlákna a dlaždice. Okno Vlákna GPU zobrazuje celkový počet aktivních a blokovaných vláken GPU, jak je znázorněno na následujícím obrázku.

Okno Vláken GPUPro tento výpočet se přidělí 313 dlaždic. Každá dlaždice obsahuje 32 vláken. Vzhledem k tomu, že místní ladění GPU probíhá v emulátoru softwaru, existují čtyři aktivní vlákna GPU. Čtyři vlákna spustí instrukce současně a pak se přesunou k další instrukci.
V okně Vlákna GPU jsou aktivní čtyři vlákna GPU a 28 vláken GPU je blokováno v tile_barrier::wait příkazu definovaném přibližně na řádku 21 (
t_idx.barrier.wait();). Všech 32 vláken GPU patří k první dlaždici,tile[0]. Šipka odkazuje na řádek, který obsahuje aktuální vlákno. Pokud chcete přepnout na jiné vlákno, použijte jednu z následujících metod:V řádku pro vlákno, na který se má přepnout v okně GPU Vlákna, otevřete místní nabídku a zvolte Přepnout na vlákno. Pokud řádek představuje více než jedno vlákno, přepnete na první vlákno podle souřadnic vláken.
Zadejte hodnoty dlaždice a vlákna do odpovídajících textových polí a poté zvolte tlačítko Přepnout vlákno.
V Okno Zásobník volání se zobrazí aktuální zásobník volání vlákna GPU.
Jak používat okno „Paralelní zásobníky“
Pokud chcete otevřít okno Paralelní zásobníky, na panelu nabídek zvolte Ladit>Okna>Paralelní zásobníky.
Okno Paralelní zásobníky můžete použít k souběžné kontrole zásobníkových rámců více vláken GPU.
Ukotvěte okno Paralelní zásobníky do dolní části sady Visual Studio.
Ujistěte se, že je v seznamu v levém horním rohu vybrána vlákna. Na následujícím obrázku zobrazuje okno Paralelní Zásobníky pohled zaměřený na zásobník volání vláken GPU, která jste viděli v okně Vlákna GPU.

Okno Paralelních zásobníků32 vláken přešlo z
_kernel_stubdo lambda výrazu při volání funkceparallel_for_eacha poté do funkcesum_kernel_tiled, kde dochází k paralelní redukci. 28 z 32 vláken pokročilo natile_barrier::waitpříkaz a zůstává blokováno na řádku 22, zatímco ostatní čtyři vlákna zůstávají aktivní vesum_kernel_tiledfunkci na řádku 30.Můžete zkontrolovat vlastnosti vlákna GPU. Jsou k dispozici v okně vláken GPU v rozvinutém datovém tipu okna paralelní zásobníky. Pokud je chcete zobrazit, umístěte ukazatel myši na rámeček zásobníku
sum_kernel_tiled. Následující ilustrace ukazuje DataTip.
Popis dat ve vlákně GPUDalší informace o okně Paralelní zásobníky naleznete v části Použití okna Paralelní zásobníky.
Jak používat okno Paralelní sledování
Pokud chcete otevřít okno Paralelní sledování, na řádku nabídek zvolte Ladit>Windows>Parallel Watch>Parallel Watch 1.
Okno Paralelní sledování můžete použít ke kontrole hodnot výrazu ve více vláknech.
Ukotvit okno Paralelní sledování 1 do dolní části prostředí Visual Studio V tabulce okna Paralelní kukátko je 32 řádků. Každé z nich odpovídá vláknu GPU, které se objevilo jak v okně vláken GPU, tak v okně Paralelní zásobníky. Teď můžete zadat výrazy, jejichž hodnoty chcete zkontrolovat ve všech 32 vláknech GPU.
Vyberte záhlaví sloupce Přidat sledování, zadejte
localIdxa pak zvolte klávesu Enter.Znovu vyberte záhlaví sloupce Přidat sledování, zadejte
globalIdxa pak stiskněte klávesu Enter.Znovu vyberte záhlaví sloupce Přidat sledování, zadejte
localA[localIdx[0]]a pak stiskněte klávesu Enter.Můžete řadit podle zadaného výrazu tak, že vyberete odpovídající záhlaví sloupce.
Pokud chcete sloupec seřadit, vyberte záhlaví sloupce localA[localIdx[0]]. Následující obrázek znázorňuje výsledky řazení podle localA[localIdx[0]].

Výsledky řazeníObsah v okně Paralelní kukátko můžete exportovat do Excelu tak, že vyberete tlačítko Excelu a pak zvolíte Otevřít v Excelu. Pokud máte na vývojovém počítači nainstalovaný Excel, tlačítko otevře excelový list, který obsahuje obsah.
V pravém horním rohu okna Paralelní kukátko je ovládací prvek filtru, který můžete použít k filtrování obsahu pomocí logických výrazů. Zadejte
localA[localIdx[0]] > 20000do textového pole ovládacího prvku filtru a pak zvolte klávesu Enter .Okno teď obsahuje pouze vlákna, na kterých
localA[localIdx[0]]je hodnota větší než 2 0000. Obsah je stále seřazen podlelocalA[localIdx[0]]sloupce, což je akce řazení, kterou jste zvolili dříve.
Označení vláken GPU
Konkrétní vlákna GPU můžete označit příznakem v okně Vlákna GPU, v okně Paralelní sledování nebo v okně Paralelní zásobníky. Pokud řádek v okně Vláken GPU obsahuje více než jedno vlákno, označení tohoto řádku příznakem označí všechna vlákna obsažená v řádku.
Označit vlákna GPU
Výběrem záhlaví sloupce [Vlákno] v okně Paralelní sledování 1 seřadíte podle indexu dlaždic a indexu vlákna.
Na panelu nabídek zvolte Ladění>Pokračovat, což způsobí, že čtyři vlákna, která byla aktivní, přejdou na další bariéru (definovaná na řádku 32 AMPMapReduce.cpp).
Zvolte symbol příznaku na levé straně řádku, který obsahuje čtyři vlákna, která jsou nyní aktivní.
Následující obrázek znázorňuje čtyři aktivní označená vlákna v okně GPU vláken.

Aktivní vlákna v okně Vláken GPUOkno Paralelní kukátko a popis okna Paralelní zásobníky označují vlákna s příznakem.
Pokud se chcete zaměřit na čtyři vlákna, která jste označili jako označená, můžete zobrazit pouze označená vlákna. Omezuje to, co můžete vidět v oknech vláken GPU, Paralelním sledování a Paralelních zásobnících.
Zvolte tlačítko Zobrazit pouze příznaky na libovolném okně nebo na panelu nástrojů Umístění pro ladění. Následující obrázek ukazuje tlačítko Zobrazit pouze příznakované na panelu nástrojů Umístění pro ladění.

Ukázat pouze označené tlačítkoTeď okna vláken GPU, paralelního sledování a paralelních zásobníků zobrazují jenom vlákna s příznakem.
Ukotvení a rozmrazování vláken GPU
Můžete pozastavit (ukotvit) a obnovit (rozmrazit) vlákna GPU z okna Vláken GPU nebo okna Paralelní sledování. Vlákna procesoru můžete zmrazit a obnovit stejným způsobem; informace naleznete v tématu Postupy: Použití okna vláken.
Zmrazení a rozmrazení vláken GPU
Vyberte tlačítko Zobrazit pouze označené, aby se zobrazila všechna označená vlákna.
Na řádku nabídek zvolte ladění>pokračovat.
Otevřete kontextovou nabídku aktivního řádku a poté zvolte Ukotvit.
Následující obrázek okna vláken GPU ukazuje, že jsou zablokovaná všechny čtyři vlákna.

Zamrzlá vlákna v okně Vlákna GPUPodobně okno Paralelní sledování ukazuje, že jsou zablokovaná všechna čtyři vlákna.
Na řádku nabídek zvolte Ladit>Pokračovat, aby následující čtyři vlákna GPU pokračovala kolem překážky na řádku 22 a dosáhla bodu přerušení na řádku 30. Okno GPU Vlákna ukazuje, že čtyři dříve zmrazená vlákna zůstávají zablokovaná a v aktivním stavu.
Na řádku nabídek zvolte Ladit, Pokračovat.
V okně Paralelní kukátko můžete také rozmrazit jednotlivá nebo více vláken GPU.
Seskupení vláken GPU
V místní nabídce pro jedno z vláken v okně GPU vlákna vyberte Seskupit podle, Adresa.
Vlákna v okně Vláken GPU jsou seskupené podle adresy. Adresa odpovídá pokynu k demontáži, kde se nachází každá skupina vláken. 24 vláken jsou na řádku 22, kde se spustí metoda tile_barrier::wait . 12 vláken je podle pokynu pro bariéru na řádku 32. Čtyři z těchto vláken jsou označena. Osm vláken je na bodu přerušení na řádku 30. Čtyři z těchto vláken jsou zmrazeny. Následující obrázek znázorňuje seskupené vlákna v okně Vlákna GPU.

Seskupená vlákna v okně Vláken GPUOperaci Seskupit můžete provést otevřením kontextové nabídky datové mřížky okna Parallel Watch. Vyberte Možnost Seskupit podle a pak zvolte položku nabídky, která odpovídá způsobu seskupení vláken.
Vedení všech vláken na určité místo v kódu
Spustíte všechna vlákna v dané dlaždici až k řádku, který obsahuje kurzor, pomocí příkazu Spustit aktuální dlaždici ke kurzoru.
Spustit všechna vlákna na místo označené kurzorem
V místní nabídce pro zmrazená vlákna zvolte Thaw.
V Editoru kódu umístěte kurzor na řádek 30.
V místní nabídce editoru kódu zvolte Spustit aktuální dlaždici kurzoru.
24 vláken, které byly dříve blokovány na bariéře na řádku 21, postoupily na řádek 32. Zobrazuje se v okně Vlákna GPU.
Viz také
Přehled C++ AMP
Ladění kódu GPU
Postupy: Použití okna vláken GPU
Postupy: Použití okna paralelního sledování
Analýza kódu C++ AMP pomocí Vizualizéru souběžnosti