Poznámka
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Návod
Tento obsah je výňatek z eBooku, Architekting Cloud Native .NET Applications for Azure, který je k dispozici na webu Docs pro .NET nebo jako soubor PDF zdarma ke stažení, který si můžete přečíst offline.

Relační (SQL) a nerelační (NoSQL) jsou dva typy databázových systémů běžně implementovaných v aplikacích nativních pro cloud. Vytvářejí se jinak, ukládají data odlišně a používají se jinak. V této části se podíváme na obojí. Později v této kapitole se podíváme na nově vznikající databázovou technologii s názvem NewSQL.
Relační databáze jsou po celá desetiletí rozšířenou technologií. Jsou vyspělé, prověřené a široce implementované. Konkurenční databázové produkty, nástroje a odborné znalosti. Relační databáze poskytují úložiště souvisejících tabulek dat. Tyto tabulky mají pevné schéma, ke správě dat používají SQL (jazyk SQL (Structured Query Language)) a podporují záruky ACID: atomicita, konzistence, izolace a stálost.
Databáze NoSQL odkazují na vysoce výkonná nerelační úložiště dat. Vynikají ve svých charakteristikách snadného použití, škálovatelnosti, odolnosti a dostupnosti. Místo spojování tabulek normalizovaných dat ukládá NoSQL nestrukturovaná nebo částečně strukturovaná data, často ve dvojicích klíč-hodnota nebo dokumentech JSON. Databáze NoSQL obvykle neposkytují záruky ACID nad rámec jednoho oddílu databáze. Služby s velkým objemem, které vyžadují subsekundovou dobu odezvy, upřednostňují úložiště dat NoSQL.
Dopad technologií NoSQL pro distribuované systémy nativní pro cloud není možné přetěžovat. Šíření nových datových technologií v tomto prostoru narušilo řešení, která kdysi výhradně závisela na relačních databázích.
Databáze NoSQL zahrnují několik různých modelů pro přístup k datům a jejich správu, které jsou vhodné pro konkrétní případy použití. Obrázek 5–9 představuje čtyři běžné modely.
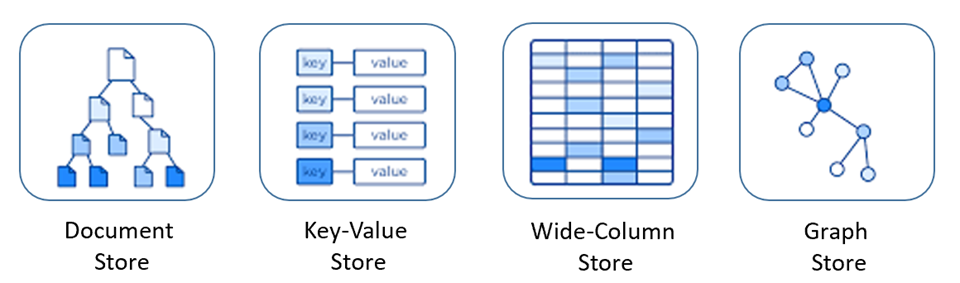
Obrázek 5–9: Datové modely pro databáze NoSQL
| Vzor | Charakteristiky |
|---|---|
| Úložiště dokumentů | Data a metadata se ukládají hierarchicky v dokumentech založených na FORMÁTU JSON uvnitř databáze. |
| Úložiště hodnot klíčů | Nejjednodušší z databází NoSQL jsou data reprezentována jako kolekce párů klíč-hodnota. |
| Široké úložiště sloupců | Související data se ukládají jako sada vnořených párů klíč/hodnota v jednom sloupci. |
| Úložiště grafu | Data jsou uložená ve struktuře grafu jako vlastnosti uzlu, hraničních zařízení a dat. |
CAP a PACELC teorémy
Jako způsob, jak porozumět rozdílům mezi těmito typy databází, zvažte CAP teorém, sadu principů použitých u distribuovaných systémů, které ukládají stav. Obrázek 5–10 znázorňuje tři vlastnosti věty CAP.
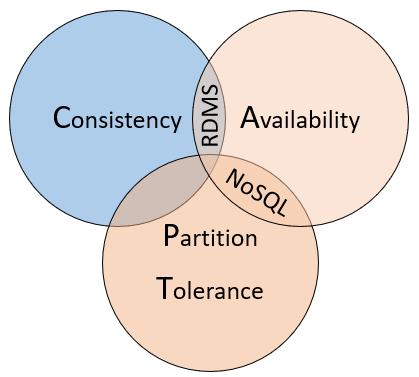
Obrázek 5–10 CAP teorém
Teorém uvádí, že distribuované datové systémy budou nabízet kompromis mezi konzistencí, dostupností a odolností mezi oddíly. A že každá databáze může zaručit pouze dvě ze tří vlastností:
Konzistence. Každý uzel v clusteru odpoví nejnovějšími daty, i když systém musí požadavek blokovat, dokud se neaktualizují všechny repliky. Pokud se dotazujete na "konzistentní systém" pro položku, která se právě aktualizuje, počkáte na tuto odpověď, dokud se všechny repliky úspěšně neaktualizují. Budete ale dostávat nejaktuálnější data. Mělo by být zřejmé, že pojem "konzistence", jak se používá v kontextu věty CAP, má technický význam, který se liší od způsobu, jakým je definována "konzistence" v kontextu záruk ACID.
Dostupnost. Každý požadavek přijatý uzlem, který selhává v systému, musí mít za následek odpověď. Jednoduše řečeno, pokud zadáte dotaz na "dostupný systém" pro položku, která se aktualizuje, získáte nejlepší možnou odpověď, kterou může služba v tuto chvíli poskytnout. Všimněte si ale, že "dostupnost" definovaná teorémem CAP se technicky liší od "vysoké dostupnosti", protože je běžně známá pro distribuované systémy.
Odolnost oddílů. Zaručuje, že systém bude fungovat i v případě, že replikovaný datový uzel selže nebo ztratí připojení k jiným replikovaným datovým uzlům.
CAP teorém vysvětluje kompromisy spojené se správou konzistence a dostupnosti během síťového oddílu; ale kompromisy s ohledem na konzistenci a výkon existují i s absencí síťového oddílu.
Poznámka:
I když zvolíte dostupnost nad konzistencí, bude dostupnost v časech síťového oddílu trpět. Dostupný systém CAP je pro některé klienty k dispozici více, ale nemusí být nutně "vysoce dostupný" pro všechny své klienty.
CAP teorém se často dále rozšiřuje na PACELC , aby vysvětlil kompromisy komplexněji. CAP teorém je obzvláště relevantní v přerušovaně propojených prostředích, jako jsou například prostředí související s internetem věcí (IoT), monitorováním životního prostředí a mobilními aplikacemi. V těchto kontextech se zařízení můžou rozdělit z důvodu náročných fyzických podmínek, jako jsou výpadky napájení nebo při vstupu do omezených prostorů, jako jsou výtahy. U distribuovaných systémů, jako jsou cloudové aplikace, je vhodnější použít větu PACELC, která je komplexnější a považuje kompromisy, jako je latence a konzistence i v případě absence síťových oddílů.
Relační databáze obvykle poskytují konzistenci a dostupnost, ale ne odolnost k oddílům. Obvykle se zřizují na jeden server a škálují se vertikálně přidáním dalších prostředků do počítače.
Mnoho systémů relačních databází podporuje integrované funkce replikace, kde je možné provádět kopie primární databáze do jiných sekundárních instancí serveru. Operace zápisu se provádějí v primární instanci a replikují se do každé sekundární instance. Při selhání může primární instance převzít služby při selhání sekundární instanci, aby poskytovala vysokou dostupnost. K distribuci operací čtení je možné použít také sekundární operace. Operace zápisu sice vždy přecházejí proti primární replice, ale operace čtení je možné směrovat na kterýkoli z sekundárních operací, aby se snížila zatížení systému.
Data je také možné horizontálně dělit napříč několika uzly, například s horizontálním dělením. Horizontální dělení ale výrazně zvyšuje provozní režii tím, že data spitting přes mnoho částí, které nemohou snadno komunikovat. Správa může být nákladná a časově náročná. Relační funkce, které zahrnují spojení tabulek, transakce a referenční integritu, vyžadují v horizontálně dělených nasazeních vysoké pokuty za výkon.
Konzistenci replikace a cíle bodu obnovení je možné ladit tak, že nakonfigurujete, jestli replikace probíhá synchronně nebo asynchronně. Pokud by repliky dat ztratily síťové připojení v "vysoce konzistentním" nebo synchronním clusteru relačních databází, nemohli byste do databáze zapisovat. Systém odmítne operaci zápisu, protože nemůže replikovat tuto změnu na jinou repliku dat. Před dokončením transakce se musí aktualizovat každá replika dat.
Databáze NoSQL obvykle podporují vysokou dostupnost a odolnost oddílů. Horizontálně horizontálně navyšují kapacitu, často napříč komoditami servery. Tento přístup poskytuje obrovskou dostupnost v rámci geografických oblastí i napříč geografickými oblastmi s nižšími náklady. Rozdělíte a replikujete data napříč těmito počítači nebo uzly a zajistíte redundanci a odolnost proti chybám. Konzistenci se obvykle ladí prostřednictvím protokolů konsensu nebo mechanismů kvora. Poskytují větší kontrolu při procházení kompromisů mezi laděním synchronní a asynchronní replikace v relačních systémech.
Pokud repliky dat ztratily připojení v databázovém clusteru NoSQL s vysokou dostupností, můžete do databáze přesto dokončit operaci zápisu. Databázový cluster by umožnil operaci zápisu a aktualizovat každou repliku dat, jakmile bude k dispozici. Databáze NoSQL, které podporují více zapisovatelných replik, můžou dále posílit vysokou dostupnost tím, že při optimalizaci cíle doby obnovení zabrání převzetí služeb při selhání.
Moderní databáze NoSQL obvykle implementují možnosti dělení jako funkce návrhu systému. Správa oddílů je často integrovaná do databáze a směrování se dosahuje pomocí tipů pro umístění – často označovaných jako klíče oddílů. Flexibilní datové modely umožňují databázím NoSQL snížit zatížení správy schémat a zlepšit dostupnost při nasazování aktualizací aplikací, které vyžadují změny datového modelu.
Vysoká dostupnost a obrovská škálovatelnost jsou pro firmu často důležitější než spojení relačních tabulek a referenční integrita. Vývojáři mohou implementovat techniky a vzory, jako jsou Sagas, CQRS a asynchronní zasílání zpráv, aby přijali konečnou konzistenci.
V současné době je třeba věnovat pozornost při zvažování omezení teorému CAP. Objevil se nový typ databáze s názvem NewSQL, který rozšiřuje relační databázový stroj tak, aby podporoval horizontální škálovatelnost i škálovatelný výkon systémů NoSQL.
Důležité informace o relačních vs. systémech NoSQL
Na základě konkrétních požadavků na data může cloudová nativní mikroslužba implementovat relační úložiště dat NoSQL nebo obojí.
| Vezměte v úvahu úložiště dat NoSQL, když: | Zvažte relační databázi v případech, kdy: |
|---|---|
| Máte úlohy s velkým objemem, které vyžadují předvídatelnou latenci ve velkém měřítku (například latence měřená v milisekundách při provádění milionů transakcí za sekundu). | Objem úloh obecně zapadá do tisíců transakcí za sekundu. |
| Vaše data jsou dynamická a často se mění. | Vaše data jsou vysoce strukturovaná a vyžadují referenční integritu. |
| Relace můžou být denormalizované datové modely. | Relace jsou vyjádřeny spojeními tabulek u normalizovaných datových modelů. |
| Načítání dat je jednoduché a vyjádřené bez spojení tabulek. | Pracujete se složitými dotazy a sestavami. |
| Data se obvykle replikují napříč zeměpisnými oblastmi a vyžadují důkladnou kontrolu nad konzistencí, dostupností a výkonem. | Data jsou obvykle centralizovaná nebo je možné replikovat oblasti asynchronně. |
| Vaše aplikace se nasadí na komoditní hardware, například s veřejnými cloudy. | Vaše aplikace se nasadí na velký vysoce výkonný hardware. |
V dalších částech prozkoumáme možnosti dostupné v cloudu Azure pro ukládání a správu dat nativních pro cloud.
Databáze jako služba
Abyste mohli začít, můžete zřídit virtuální počítač Azure a nainstalovat databázi podle výběru pro každou službu. I když byste měli plnou kontrolu nad prostředím, měli byste se stavět na mnoha integrovaných funkcích cloudové platformy. Také byste zodpovídají za správu virtuálního počítače a databáze pro každou službu. Tento přístup by mohl být rychle časově náročný a nákladný.
Aplikace nativní pro cloud místo toho upřednostňují datové služby zveřejněné jako databáze jako služba (DBaaS). Plně spravované dodavatelem cloudu poskytují tyto služby integrované zabezpečení, škálovatelnost a monitorování. Místo vlastnictví služby ji jednoduše využíváte jako backingovou službu. Poskytovatel provozuje prostředek ve velkém měřítku a nese odpovědnost za výkon a údržbu.
Dají se nakonfigurovat napříč zónami a oblastmi dostupnosti cloudu, aby dosáhly vysoké dostupnosti. Všechny podporují kapacitu za běhu a model průběžných plateb. Azure nabízí různé druhy možností spravovaných datových služeb, z nichž každá má konkrétní výhody.
Nejprve se podíváme na relační služby DBaaS dostupné v Azure. Uvidíte, že hlavní databáze SQL Serveru od Microsoftu je k dispozici spolu s několika open source možnostmi. Pak si řekneme o datových službách NoSQL v Azure.
Relační databáze Azure
Pro nativní cloudové mikroslužby, které vyžadují relační data, nabízí Azure čtyři nabídky spravovaných relačních databází jako služby (DBaaS), jak je znázorněno na obrázku 5–11.

Obrázek 5–11 Spravované relační databáze dostupné v Azure
Na předchozím obrázku si všimněte, jak každá představuje společnou infrastrukturu DBaaS, která nabízí klíčové funkce bez dalších nákladů.
Tyto funkce jsou zvlášť důležité pro organizace, které zřizují velký počet databází, ale mají omezené prostředky pro jejich správu. Databázi Azure můžete zřídit v řádu minut výběrem množství procesorových jader, paměti a základního úložiště. Databázi můžete škálovat průběžně a dynamicky upravovat prostředky bez výpadků.
Azure SQL Database
Vývojové týmy s odbornými znalostmi Microsoft SQL Serveru by měly zvážit Azure SQL Database. Jedná se o plně spravovanou relační databázi jako službu (DBaaS) založenou na databázovém stroji Microsoft SQL Serveru. Tato služba sdílí mnoho funkcí nalezených v místní verzi SQL Serveru a používá nejnovější stabilní verzi databázového stroje SQL Serveru.
Pro použití s nativní cloudovou mikroslužbou je azure SQL Database k dispozici se třemi možnostmi nasazení:
Jednoúčelová databáze představuje plně spravovanou službu SQL Database běžící na serveru Azure SQL Database v cloudu Azure. Databáze je považována za obsaženou , protože nemá žádné závislosti konfigurace na podkladovém databázovém serveru.
Spravovaná instance je plně spravovaná instance databázového stroje Microsoft SQL Serveru, která poskytuje téměř 100% kompatibilitu s místním SQL Serverem. Tato možnost podporuje větší databáze, až 35 TB a je umístěná ve službě Azure Virtual Network pro lepší izolaci.
Bezserverová úroveň Azure SQL Database je výpočetní úroveň pro jednu databázi, která se automaticky škáluje na základě poptávky po úlohách. Účtuje se pouze za množství výpočetních prostředků využitých za sekundu. Služba je vhodná pro úlohy s přerušovanými, nepředvídatelnými vzory využití, které jsou provládané s obdobími nečinnosti. Bezserverová výpočetní úroveň také automaticky pozastaví databáze během neaktivních období, aby se účtovaly jenom poplatky za úložiště. Při návratu aktivity se automaticky obnoví.
Kromě tradičního zásobníku Microsoft SQL Serveru nabízí Azure také spravované verze tří oblíbených opensourcových databází.
Opensourcové databáze v Azure
Opensourcové relační databáze se staly oblíbenou volbou pro aplikace nativní pro cloud. Mnoho podniků je upřednostňuje před komerčními databázovými produkty, zejména kvůli úsporám nákladů. Mnoho vývojových týmů si užívá flexibilitu, vývoj založený na komunitě a ekosystém nástrojů a rozšíření. Opensourcové databáze je možné nasadit napříč několika poskytovateli cloudu, což pomáhá minimalizovat obavy "uzamčení dodavatele".
Vývojáři můžou snadno hostovat libovolnou opensourcovou databázi na virtuálním počítači Azure. Tento přístup vám při poskytování úplné kontroly dává na háku pro správu, monitorování a údržbu databáze a virtuálního počítače.
Microsoft se však nadále zavazuje udržovat Azure jako "otevřenou platformu" tím, že nabízí několik oblíbených opensourcových databází jako plně spravované služby DBaaS.
Databáze Azure pro MySQL
MySQL je opensourcová relační databáze a pilíř pro aplikace založené na softwarovém zásobníku LAMP. Široce zvolená pro čtení náročných úloh, je používána mnoha velkými organizacemi, včetně Facebooku, Twitteru a YouTube. Komunitní edice je k dispozici zdarma, zatímco edice Enterprise vyžaduje nákup licence. Původně vytvořený v roce 1995 byl produkt zakoupen společností Sun Microsystems v roce 2008. Oracle získal Sun a MySQL v roce 2010.
Azure Database for MySQL je spravovaná relační databázová služba založená na opensourcovém databázovém stroji MySQL. Používá edici MySQL Community. Server Azure MySQL je bodem správy služby. Je to stejný serverový modul MySQL, který se používá pro místní nasazení. Modul může vytvořit jednu databázi na server nebo více databází na server, který sdílí prostředky. Data můžete dál spravovat pomocí stejných opensourcových nástrojů, aniž byste se museli učit nové dovednosti nebo spravovat virtuální počítače.
Databáze Azure pro MariaDB
MariaDB Server je dalším oblíbeným opensourcovým databázovým serverem. Byl vytvořen jako fork MySQL, když Oracle koupil Sun Microsystems, který vlastní MySQL. Záměrem bylo zajistit, aby MariaDB zůstala opensourcová. Vzhledem k tomu, že MariaDB je fork MySQL, definice dat a tabulek jsou kompatibilní a klientské protokoly, struktury a rozhraní API jsou úzce pletené.
MariaDB má silnou komunitu a používá ji mnoho velkých podniků. I když Oracle i nadále udržuje, vylepšuje a podporuje MySQL, nadace MariaDB spravuje MariaDB, což umožňuje veřejné příspěvky do produktu a dokumentace.
Azure Database for MariaDB je plně spravovaná relační databáze jako služba v cloudu Azure. Služba je založená na databázovém stroji MariaDB Community Edition. Dokáže zpracovávat klíčové úlohy s předvídatelným výkonem a dynamickou škálovatelností.
Azure Database for PostgreSQL (Databáze Azure pro PostgreSQL)
PostgreSQL je opensourcová relační databáze s více než 30 lety aktivního vývoje. PostgreSQL má silnou pověst pro spolehlivost a integritu dat. Je to funkce bohatá, kompatibilní s SQL a považuje se za výkonnější než MySQL – zejména pro úlohy se složitými dotazy a náročnými zápisy. Mnoho velkých podniků, včetně Společnosti Apple, Red Hat a Apple, vytvořily produkty využívající PostgreSQL.
Azure Database for PostgreSQL je plně spravovaná relační databázová služba založená na opensourcovém databázovém stroji Postgres. Tato služba podporuje řadu vývojových platforem, včetně C++, Javy, Pythonu, Node, C# a PHP. Databáze PostgreSQL můžete do ní migrovat pomocí nástroje příkazového řádku nebo služby Azure Data Migration Service.
Azure Database for PostgreSQL je k dispozici se dvěma možnostmi nasazení:
Možnost nasazení jednoúčelového serveru je centrálním bodem správy pro více databází, do kterých můžete nasadit mnoho databází. Ceny jsou strukturované na server založené na jádrech a úložišti.
Možnost Hyperscale (Citus) využívá technologii Citus Data. Umožňuje vysoký výkon horizontálním škálováním izolované databáze napříč stovkami uzlů, aby poskytoval rychlý výkon a škálování. Tato možnost umožňuje modulu přizpůsobit více dat do paměti, paralelizovat dotazy napříč stovkami uzlů a indexovat data rychleji.
Data NoSQL v Azure
Cosmos DB je plně spravovaná globálně distribuovaná databázová služba NoSQL v cloudu Azure. Byla přijata mnoha velkými společnostmi po celém světě, včetně Coca-Cola, Skype, ExxonMobil a Liberty Mutual.
Pokud vaše služby vyžadují rychlou odezvu odkudkoli na světě, vysokou dostupnost nebo elastickou škálovatelnost, je cosmos DB skvělou volbou. Obrázek 5–12 ukazuje Cosmos DB.
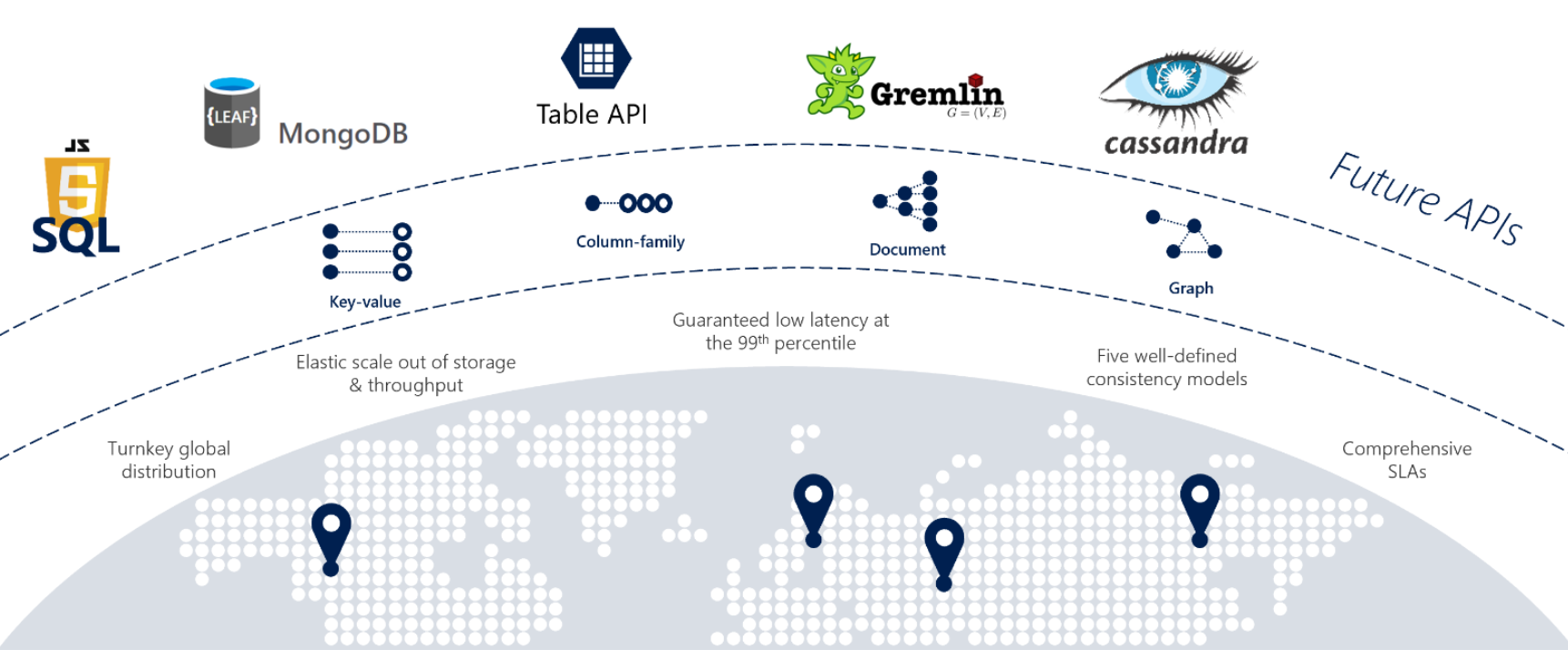
Obrázek 5–12: Přehled služby Azure Cosmos DB
Předchozí obrázek představuje řadu integrovaných funkcí nativních pro cloud dostupných ve službě Cosmos DB. V této části se na ně podíváme podrobněji.
Globální podpora
Nativní cloudové aplikace mají často globální cílovou skupinu a vyžadují globální škálování.
Databáze Cosmos můžete distribuovat napříč oblastmi nebo po celém světě, umístit data blízko uživatelů, zlepšit dobu odezvy a snížit latenci. Databázi můžete přidat nebo odebrat z oblasti bez pozastavení nebo opětovného nasazení služeb. Cosmos DB na pozadí transparentně replikuje data do každé nakonfigurované oblasti.
Cosmos DB podporuje clustering aktivní/aktivní na globální úrovni a umožňuje nakonfigurovat jakoukoli oblast databáze tak, aby podporovala zápisy i čtení.
Protokol zápisu do více oblastí je důležitou funkcí služby Cosmos DB, která umožňuje následující funkce:
Neomezená elastická škálovatelnost zápisu a čtení
99,999% dostupnost čtení a zápisu po celém světě.
Garantované čtení a zápisy obsluhované v méně než 10 milisekundách v 99. percentilu.
S rozhraními API pro multi-homing služby Cosmos DB je vaše mikroslužba automaticky informována o nejbližší oblasti Azure a odesílá do ní požadavky. Cosmos DB identifikuje nejbližší oblast bez jakýchkoli změn konfigurace. Pokud je oblast nedostupná, funkce Multi-Homing automaticky směruje požadavky do další nejbližší dostupné oblasti.
Podpora více modelů
Při replatformování monolitických aplikací na nativní cloudovou architekturu musí vývojové týmy někdy migrovat opensourcové úložiště dat NoSQL. Cosmos DB vám může pomoct zachovat investice do těchto úložišť dat NoSQL pomocí své datové platformy s více modely . Následující tabulka ukazuje podporovaná rozhraní API kompatibility NoSQL.
| Poskytovatel | Popis |
|---|---|
| NoSQL API | Rozhraní API pro NoSQL ukládá data ve formátu dokumentu. |
| Mongo DB API | Podporuje rozhraní MONGO DB API a dokumenty JSON. |
| Rozhraní Gremlin API | Podporuje rozhraní Gremlin API s uzly založenými na grafech a reprezentací hraničních dat. |
| Rozhraní Cassandra API | Podporuje rozhraní API Casandra pro reprezentaci dat v širokém sloupci. |
| Rozhraní Table API | Podporuje Azure Table Storage s vylepšeními úrovně Premium. |
| PostgreSQL API | Spravovaná služba pro spouštění PostgreSQL v libovolném měřítku |
Vývojové týmy můžou migrovat existující databáze Mongo, Gremlin nebo Cassandra do služby Cosmos DB s minimálními změnami dat nebo kódu. V případě nových aplikací můžou vývojové týmy vybírat z opensourcových možností nebo integrovaného modelu rozhraní SQL API.
Cosmos ukládá data interně do jednoduchého formátu struktury tvořeného primitivními datovými typy. Pro každý požadavek databázový stroj přeloží primitivní data do reprezentace modelu, kterou jste vybrali.
V předchozí tabulce si všimněte možnosti rozhraní Table API . Toto rozhraní API je vývoj služby Azure Table Storage. Oba sdílejí stejný základní tabulkový model, ale rozhraní Table API služby Cosmos DB přidává vylepšení úrovně Premium, která nejsou k dispozici v rozhraní API služby Azure Storage. Následující tabulka kontrastuje s funkcemi.
| Funkce | Azure Table Storage (úložiště tabulek) | Azure Cosmos DB – databázový systém |
|---|---|---|
| Latence | Rychlé | Latence jednociferného milisekundy pro čtení a zápisy kdekoli na světě |
| Propustnost | Limit 20 000 operací na tabulku | Neomezené operace na tabulku |
| Globální distribuce | Jedna oblast s volitelnou sekundární oblastí čtení | Distribuce na klíč do všech oblastí s automatickým převzetím služeb při selhání |
| Indexování | K dispozici pouze pro vlastnosti klíče oddílu a řádku | Automatické indexování všech vlastností |
| Ceny | Optimalizované pro studené úlohy (nízká propustnost: poměr úložiště) | Optimalizované pro horké úlohy (vysoká propustnost: poměr úložiště) |
Mikroslužby, které využívají službu Azure Table Storage, se můžou snadno migrovat do rozhraní Table API služby Cosmos DB. Nejsou vyžadovány žádné změny kódu.
Přizpůsobitelná konzistence
Dříve v části Relační vs. NoSQL jsme probrali téma konzistence dat. Konzistence dat odkazuje na integritu vašich dat. Cloudové nativní služby s distribuovanými daty spoléhají na replikaci a musí mít zásadní kompromis mezi konzistencí čtení, dostupností a latencí.
Většina distribuovaných databází umožňuje vývojářům vybrat si mezi dvěma modely konzistence: silnou konzistencí a konečnou konzistencí. Silná konzistence je zlatý standard programovatelnosti dat. Zaručuje, že dotaz vždy vrátí nejaktuálnější data – i když musí systém čekat na replikaci aktualizace napříč všemi kopiemi databáze. Zatímco databáze nakonfigurovaná pro konečnou konzistenci vrátí data okamžitě, i když tato data nejsou nejaktuálnější kopií. Druhá možnost umožňuje vyšší dostupnost, větší škálování a vyšší výkon.
Azure Cosmos DB nabízí pět dobře definovaných modelů konzistence znázorněných na obrázku 5–13.

Obrázek 5–13: Úrovně konzistence cosmos DB
Tyto možnosti umožňují provádět přesné volby a podrobné kompromisy pro konzistenci, dostupnost a výkon vašich dat. Úrovně jsou uvedeny v následující tabulce.
| Úroveň konzistence | Popis |
|---|---|
| Případné | Žádné záruky řazení pro čtení. Repliky se nakonec sbíhají. |
| Předpona konstanty | Čtení je stále možné, ale data se vrátí v pořadí, ve kterém se zapisují. |
| Relace | Záruky, že můžete číst všechna data zapsaná během aktuální relace. Jedná se o výchozí úroveň konzistence. |
| Omezená neaktuálnost | Čte zápisy na stopu podle zadaného intervalu. |
| Silné | Čtení zaručuje vrácení nejnovější potvrzené verze položky. Klient nikdy neuvidí nepotvrzené ani částečné čtení. |
V článku Getting Behind the 9-Ball: Cosmos DB Consistency Levels Explained, Microsoft Program Manager Jeremy Likness poskytuje vynikající vysvětlení pěti modelů.
dělení na části
Azure Cosmos DB přijímá automatické dělení na škálování databáze tak, aby splňovalo požadavky na výkon vašich nativních cloudových služeb.
Data ve službě Cosmos DB spravujete vytvořením databází, kontejnerů a položek.
Kontejnery žijí v databázi Cosmos DB a představují seskupení položek, které jsou nezávislé na schématu. Položky jsou data, která přidáte do kontejneru. Jsou reprezentované jako dokumenty, řádky, uzly nebo hrany. Všechny položky přidané do kontejneru se automaticky indexují.
Pokud chcete rozdělit kontejner, položky jsou rozdělené na různé podmnožina označované jako logické oddíly. Logické oddíly se vyplní na základě hodnoty klíče oddílu, který je přidružený ke každé položce v kontejneru. Obrázek 5–14 ukazuje dva kontejnery, z nichž každý má logický oddíl založený na hodnotě klíče oddílu.
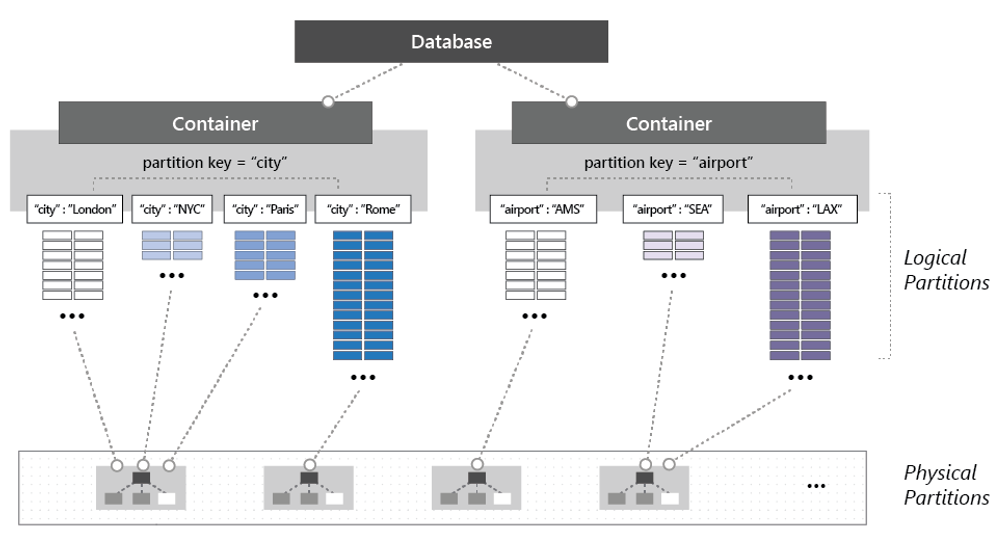
Obrázek 5–14: Mechanika dělení cosmos DB
Všimněte si na předchozím obrázku, jak každá položka obsahuje klíč oddílu "město" nebo "letiště". Klíč určuje logický oddíl položky. Položky s kódem města se přiřazují kontejneru vlevo a položky s kódem letiště na pravé straně kontejneru. Kombinace hodnoty klíče oddílu s hodnotou ID vytvoří index položky, který položku jednoznačně identifikuje.
Služba Cosmos DB interně automaticky spravuje umístění logických oddílů na fyzické oddíly , aby splňovala požadavky na škálovatelnost a výkon kontejneru. S rostoucími požadavky na propustnost aplikace a úložiště služba Azure Cosmos DB redistribuuje logické oddíly napříč větším počtem serverů. Redistribuce se spravují službou Cosmos DB a vyvolávají se bez přerušení nebo výpadku.
Databáze NewSQL
NewSQL je nově vznikající databázová technologie, která kombinuje distribuovanou škálovatelnost NoSQL se zárukami ACID relační databáze. Databáze NewSQL jsou důležité pro obchodní systémy, které musí zpracovávat velké objemy dat napříč distribuovanými prostředími s plnou podporou transakcí a dodržováním předpisů ACID. Databáze NoSQL sice může poskytovat rozsáhlou škálovatelnost, ale nezaručuje konzistenci dat. Občasné problémy z nekonzistentních dat můžou zatěžovat vývojový tým. Vývojáři musí vytvořit ochranu do kódu mikroslužby, aby mohli spravovat problémy způsobené nekonzistentními daty.
Cloud Native Computing Foundation (CNCF) obsahuje několik databázových projektů NewSQL.
| Projekt | Charakteristiky |
|---|---|
| Šváb DB | Relační databáze kompatibilní s acid, která se škáluje globálně. Přidání nového uzlu do clusteru a ŠvábDB se postará o vyvážení dat mezi instancemi a zeměpisnými oblastmi. Vytváří, spravuje a distribuuje repliky, aby se zajistila spolehlivost. Je opensourcová a volně dostupná. |
| TiDB | Opensourcová databáze, která podporuje úlohy HTAP (Hybrid Transactional Transactional and Analytical Processing). Je kompatibilní s MySQL a nabízí horizontální škálovatelnost, silnou konzistenci a vysokou dostupnost. TiDB funguje jako server MySQL. Stávající klientské knihovny MySQL můžete dál používat, aniž byste museli provádět rozsáhlé změny kódu ve vaší aplikaci. |
| YugabyteDB | Opensourcová vysoce výkonná distribuovaná databáze SQL. Podporuje nízkou latenci dotazů, odolnost proti selháním a globální distribuci dat. YugabyteDB je kompatibilní s PostgreSQL a zpracovává úlohy OLTP se škálováním na více systémů pro správu rekapitulace a internetové škálování. Produkt také podporuje NoSQL a je kompatibilní s Cassandra. |
| Virtuální weby | Virtuální weby jsou databázové řešení pro nasazení, škálování a správu velkých clusterů instancí MySQL. Může běžet v architektuře veřejného nebo privátního cloudu. Virtuální weby kombinují a rozšiřují mnoho důležitých funkcí MySQL a podporují vertikální i horizontální horizontální horizontální dělení. Weby pocházející z YouTube obsluhují veškerý provoz databáze YouTube od roku 2011. |
Opensourcové projekty na předchozím obrázku jsou k dispozici ze služby Cloud Native Computing Foundation. Tři z nabídek jsou úplné databázové produkty, které zahrnují podporu .NET. Jinými virtuálními weby je databázový clusteringový systém, který horizontálně škáluje velké clustery instancí MySQL.
Klíčovým cílem návrhu pro databáze NewSQL je nativně pracovat v Kubernetes a využívat odolnost a škálovatelnost platformy.
Databáze NewSQL jsou navržené tak, aby v dočasných cloudových prostředích, kde je možné základní virtuální počítače v okamžiku restartovat nebo přeplánovat. Databáze jsou navržené tak, aby přežily selhání uzlů bez ztráty dat ani výpadku. ŠvábDB například dokáže přežít ztrátu počítače udržováním tří konzistentních replik všech dat napříč uzly v clusteru.
Kubernetes používá konstruktor Služby, který klientovi umožňuje adresovat skupinu identických procesů databází NewSQL z jedné položky DNS. Oddělením instancí databáze od adresy služby, ke které je přidružena, můžeme škálovat bez narušení existujících instancí aplikace. Odeslání žádosti jakékoli službě v daném okamžiku vždy vrátí stejný výsledek.
V tomto scénáři jsou všechny instance databáze stejné. Neexistují žádné primární ani sekundární relace. Techniky, jako je replikace konsensu nalezená ve službě CosmosDB, umožňují libovolnému databázovému uzlu zpracovávat jakékoli požadavky. Pokud uzel, který obdrží požadavek s vyrovnáváním zatížení, má data, která potřebuje místně, okamžitě odpoví. Pokud ne, uzel se stane bránou a předá požadavek příslušným uzlům, aby získal správnou odpověď. Z pohledu klienta je každý databázový uzel stejný: Zobrazují se jako jedna logická databáze se zárukou konzistence systému s jedním počítačem, i když mají desítky nebo dokonce stovky uzlů, které pracují na pozadí.
Podrobný přehled mechaniky za databázemi NewSQL najdete v článku DASH: Čtyři vlastnosti nativních databází Kubernetes.
Migrace dat do cloudu
Jednou z časově náročnějších úloh je migrace dat z jedné datové platformy do jiné. Služba Azure Data Migration Service vám může pomoct urychlit takové úsilí. Může migrovat data z několika externích zdrojů databáze do datových platforem Azure s minimálními výpadky. Mezi cílové platformy patří následující služby:
- Azure SQL Database
- Databáze Azure pro MySQL
- Databáze Azure pro MariaDB
- Azure Database for PostgreSQL (Databáze Azure pro PostgreSQL)
- Azure Cosmos DB – databázový systém
Služba poskytuje doporučení, která vás provedou změnami potřebnými k provedení migrace, a to jak malé, tak i velké.
Spolupracujte s námi na GitHubu
Zdroj tohoto obsahu najdete na GitHubu, kde můžete také vytvářet a kontrolovat problémy a žádosti o přijetí změn. Další informace najdete v našem průvodci pro přispěvatele.