Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Návod
Tento obsah je výňatek z elektronické knihy Architektura cloud-native .NET aplikací pro Azure, která je k dispozici na .NET Docs nebo jako bezplatné PDF ke stažení, které si můžete přečíst offline.

Jak jsme viděli v této knize, přístup nativní pro cloud mění způsob návrhu, nasazení a správy aplikací. Mění také způsob správy a ukládání dat.
Obrázek 5–1 kontrastuje rozdíly.
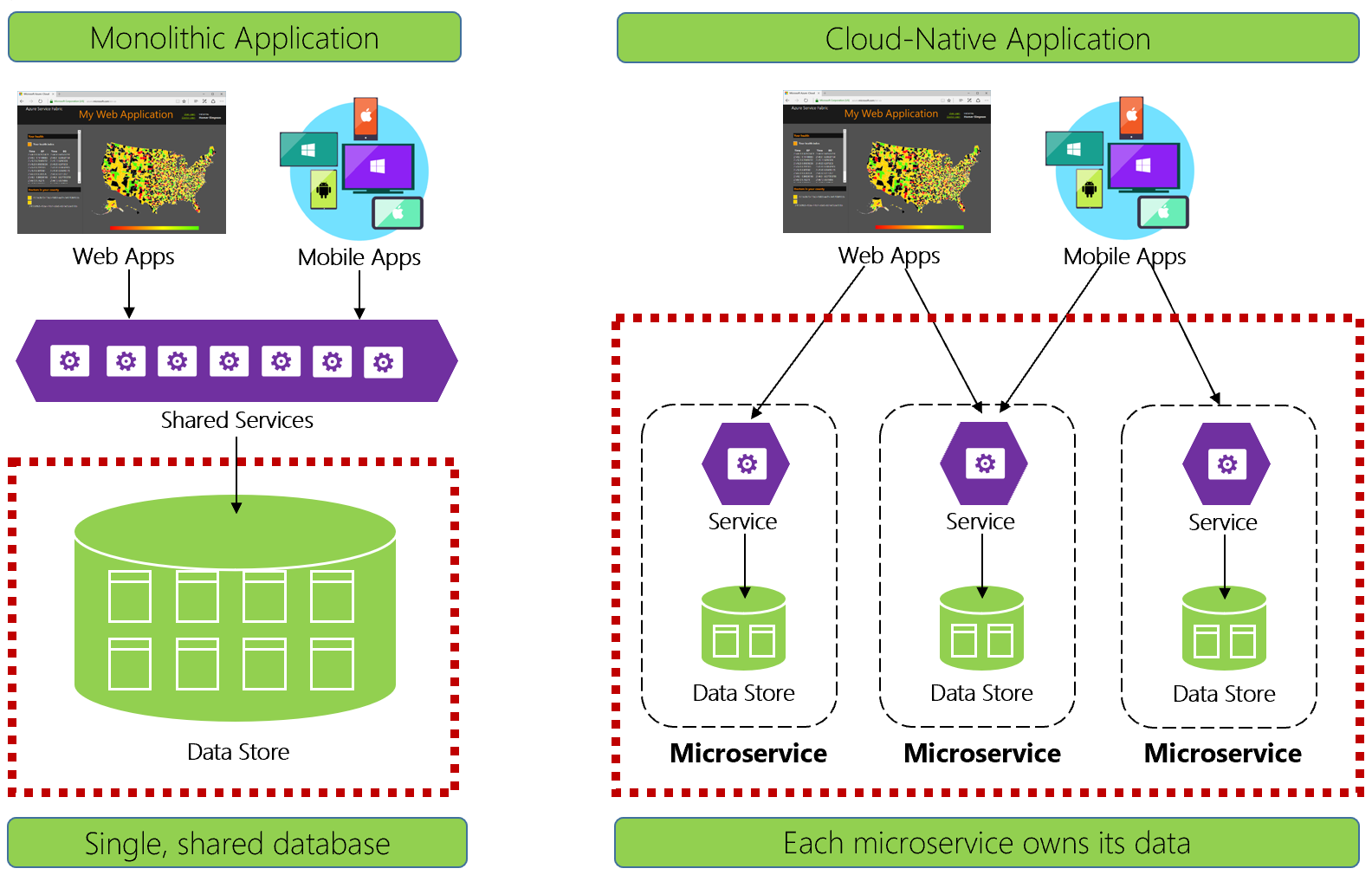
Obrázek 5–1 Správa dat v aplikacích nativních pro cloud
Zkušení vývojáři snadno rozpozná architekturu na levé straně obrázku 5-1. V této monolitické aplikaci se komponenty obchodních služeb shromáždí ve sdílené úrovni služeb a sdílejí data z jedné relační databáze.
Jednoúčelová databáze v mnoha ohledech udržuje jednoduchou správu dat. Dotazování dat napříč několika tabulkami je jednoduché. Změny v datech se aktualizují společně nebo se vrátí zpět. Transakce ACID zaručují pevnou a okamžitou konzistenci.
Při návrhu pro nativní cloud bereme jiný přístup. Na pravé straně obrázku 5-1 si všimněte, jak se obchodní funkce oddělují do malých nezávislých mikroslužeb. Každá mikroslužba zapouzdřuje konkrétní obchodní schopnosti a vlastní data. Monolitická databáze se rozloží do distribuovaného datového modelu s mnoha menšími databázemi, přičemž každá je v souladu s mikroslužbou. Když se kouř rozptýlí, objeví se návrh, který odhaluje databázi pro každou mikroslužbu.
Proč databáze pro každou mikroslužbu?
Tato databáze na mikroslužbu poskytuje mnoho výhod, zejména pro systémy, které se musí rychle vyvíjet a podporovat masivní škálování. S tímto modelem...
- Data domény jsou zapouzdřena uvnitř služby.
- Schéma dat se může vyvíjet bez přímého dopadu na jiné služby
- Každé úložiště dat může nezávisle škálovat.
- Selhání úložiště dat v jedné službě nebude mít přímý vliv na jiné služby.
Oddělení dat také umožňuje každé mikroslužbě implementovat typ úložiště dat, který je nejvhodnější pro své úlohy, potřeby úložiště a vzorce čtení a zápisu. Mezi volby patří relační úložiště dat, dokument, klíč-hodnota a dokonce i úložiště dat založená na grafech.
Obrázek 5–2 představuje princip polyglotní trvalosti v nativním cloudovém systému.
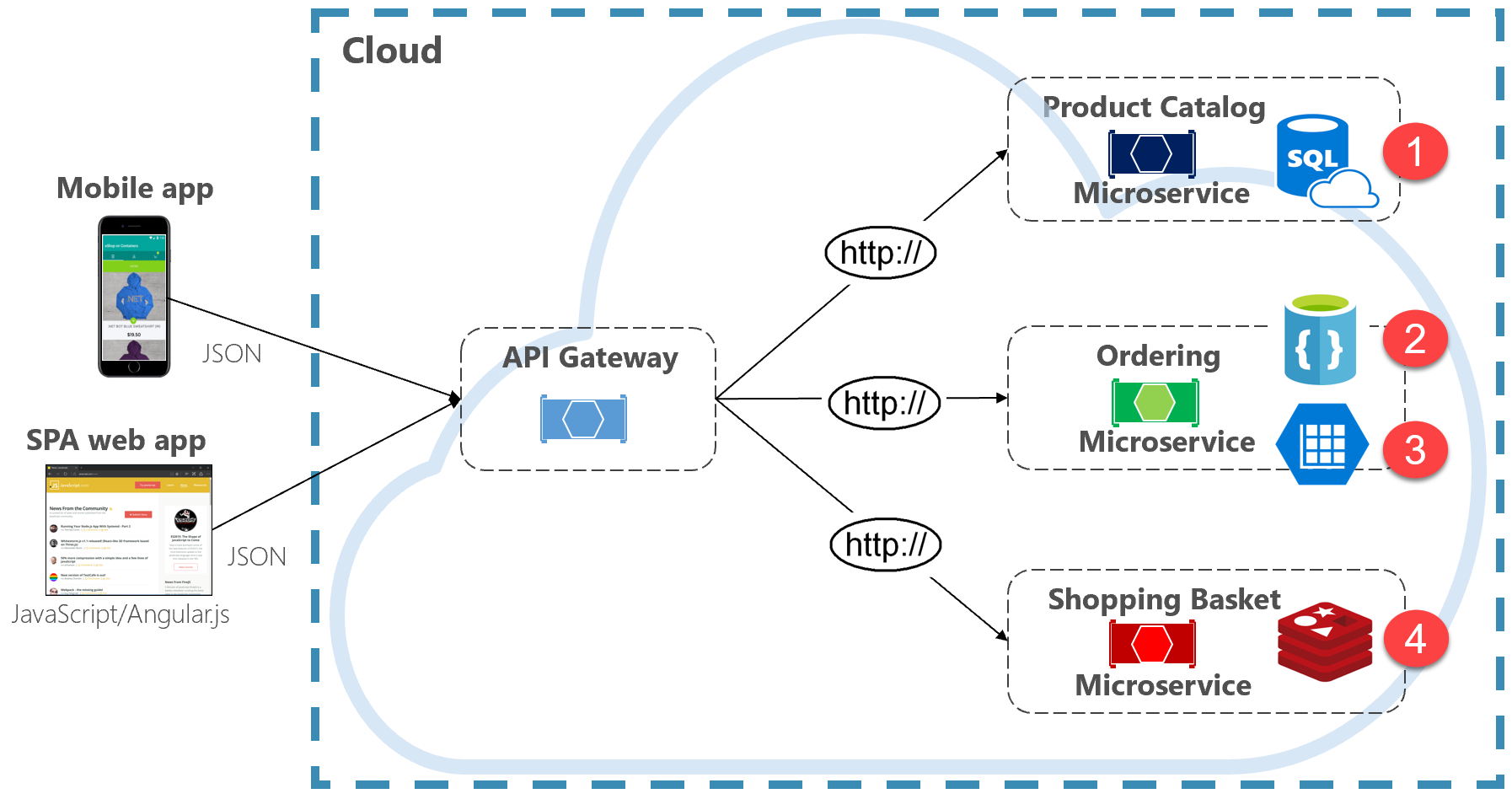
Obrázek 5–2 Trvalost polyglotních dat
Všimněte si na předchozím obrázku, jak každá mikroslužba podporuje jiný typ úložiště dat.
- Mikroslužba katalogu produktů využívá relační databázi, aby vyhovovala bohaté relační struktuře podkladových dat.
- Mikroslužba nákupního košíku využívá distribuovanou mezipaměť, která podporuje jeho jednoduché úložiště dat klíč-hodnota.
- Mikroslužba objednávání využívá databázi dokumentů NoSql pro operace zápisu spolu s vysoce denormalizovaným úložištěm klíčů a hodnot, aby vyhovovalo velkým objemům operací čtení.
I když relační databáze zůstávají relevantní pro mikroslužby se složitými daty, databáze NoSQL získaly značnou popularitu. Poskytují masivní škálování a vysokou dostupnost. Jejich povaha bez schématu umožňuje vývojářům opustit architekturu typových datových tříd a ORM, které činí změny nákladné a časově náročné. Databáze NoSQL probereme dále v této kapitole.
I když zapouzdření dat do samostatných mikroslužeb může zvýšit flexibilitu, výkon a škálovatelnost, představuje také mnoho problémů. V další části probereme tyto výzvy spolu se vzory a postupy, které jim pomůžou tyto problémy překonat.
Dotazy napříč službami
I když jsou mikroslužby nezávislé a zaměřují se na konkrétní funkční funkce, jako jsou inventarizace, expedice nebo objednávání, často vyžadují integraci s jinými mikroslužbami. Integrace často zahrnuje jednu mikroslužbu dotazující se na jiná data. Obrázek 5–3 znázorňuje scénář.
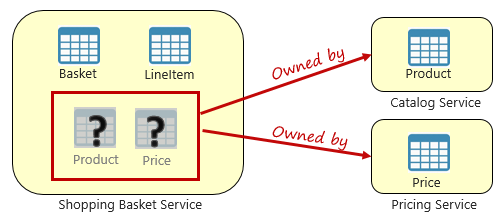
Obrázek 5–3 Dotazování napříč mikroslužbami
Na předchozím obrázku vidíme mikroslužbu nákupního košíku, která přidá položku do nákupního košíku uživatele. I když úložiště dat pro tuto mikroslužbu obsahuje data košíku a řádkové položky, neudržuje data o produktech ani cenách. Místo toho tyto datové položky vlastní katalog a cenové mikroslužby. Tento aspekt představuje problém. Jak může mikroslužba nákupního košíku přidat produkt do nákupního košíku uživatele, když v databázi nemá produkt ani cenová data?
Jednou z možností probíraných v kapitole 4 je přímé volání HTTP z nákupního košíku do katalogu a cenových mikroslužeb. V kapitole 4 jsme ale řekli, že synchronní volání HTTP spojuje dohromady mikroslužby a snižuje jejich autonomii a snižuje jejich výhody architektury.
Mohli bychom také implementovat vzor odpovědi na požadavek s samostatnými příchozími a odchozími frontami pro každou službu. Tento model je ale komplikovaný a vyžaduje technické propojení ke správné korelaci zpráv požadavků a odpovědí. I když odpojuje volání zadní mikroslužby, volající služba stále musí synchronně čekat na dokončení hovoru. Zahlcení sítě, přechodné poruchy nebo přetížená mikroslužba může vést k dlouhotrvajícím a dokonce neúspěšným operacím.
Místo toho je široce uznávaný vzor pro odebrání závislostí mezi službami materializovaný vzor zobrazení, který je znázorněn na obrázku 5-4.
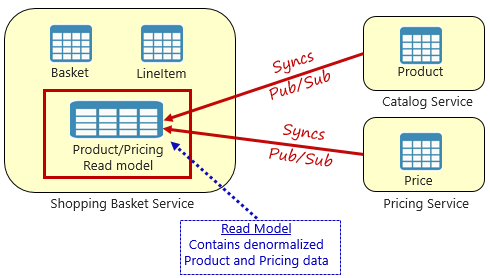
Obrázek 5–4 Model materializovaného zobrazení
Pomocí tohoto vzoru umístíte místní tabulku dat (označovanou jako model čtení) do služby nákupního košíku. Tato tabulka obsahuje denormalizovanou kopii dat potřebných z produktů a cenových mikroslužeb. Kopírování dat přímo do mikroslužby nákupního košíku eliminuje potřebu drahých volání mezi službami. Díky místním datům služby zlepšíte dobu odezvy a spolehlivost služby. Navíc díky vlastní kopii dat je služba nákupního košíku odolnější. Pokud by služba katalogu měla být nedostupná, neměla by přímý vliv na službu nákupního košíku. Nákupní košík může pokračovat v provozu s daty z vlastního obchodu.
Nevýhodou tohoto přístupu je, že teď máte v systému duplicitní data. Strategické duplikování dat v systémech nativních pro cloud je ale zavedený postup, který se nepovažuje za anti-pattern nebo chybný postup. Mějte na paměti, že jedna a pouze jedna služba může vlastnit datovou sadu a mít nad ní autoritu. Při aktualizaci systému záznamu budete muset synchronizovat modely čtení. Synchronizace se obvykle implementuje prostřednictvím asynchronního zasílání zpráv se vzorem publikování nebo odběru, jak je znázorněno na obrázku 5.4.
Distribuované transakce
Zatímco dotazování dat napříč mikroslužbami je obtížné, implementace transakce napříč několika mikroslužbami je ještě složitější. Nelze podcenit výzvu udržovat konzistenci dat napříč nezávislými zdroji dat v různých mikroslužbách. Nedostatek distribuovaných transakcí v aplikacích nativních pro cloud znamená, že distribuované transakce musíte spravovat programově. Přecházíte ze světa okamžité konzistence do světa konečné konzistence.
Obrázek 5–5 ukazuje problém.
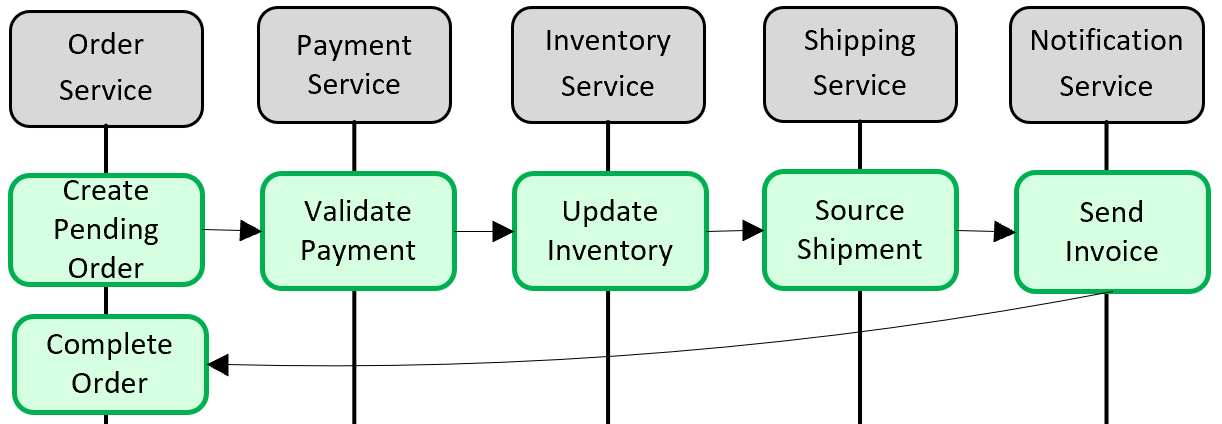
Obrázek 5–5 Implementace transakce napříč mikroslužbami
Na předchozím obrázku se pět nezávislých mikroslužeb účastní distribuované transakce, která vytvoří objednávku. Každá mikroslužba udržuje vlastní úložiště dat a implementuje místní transakci pro své úložiště. Chcete-li vytvořit objednávku, místní transakce pro každou jednotlivou mikroslužbu musí být úspěšná nebo všechny musí přerušit a vrátit operaci zpět. I když je integrovaná transakční podpora dostupná v každé z mikroslužeb, neexistuje žádná podpora distribuované transakce, která by se rozprostřela napříč všemi pěti službami, aby byla data konzistentní.
Místo toho je nutné vytvořit tuto distribuovanou transakci prostřednictvím kódu programu.
Oblíbeným vzorem pro přidání podpory distribuovaných transakcí je model Saga. Implementuje se seskupováním místních transakcí programově a postupným vyvoláním každé z nich. Pokud některá z místních transakcí selže, Saga přeruší operaci a vyvolá sadu kompenzačních transakcí. Kompenzační transakce vrátí zpět změny provedené předchozími místními transakcemi a obnovit konzistenci dat. Obrázek 5-6 ukazuje neúspěšnou transakci se vzorem Saga.
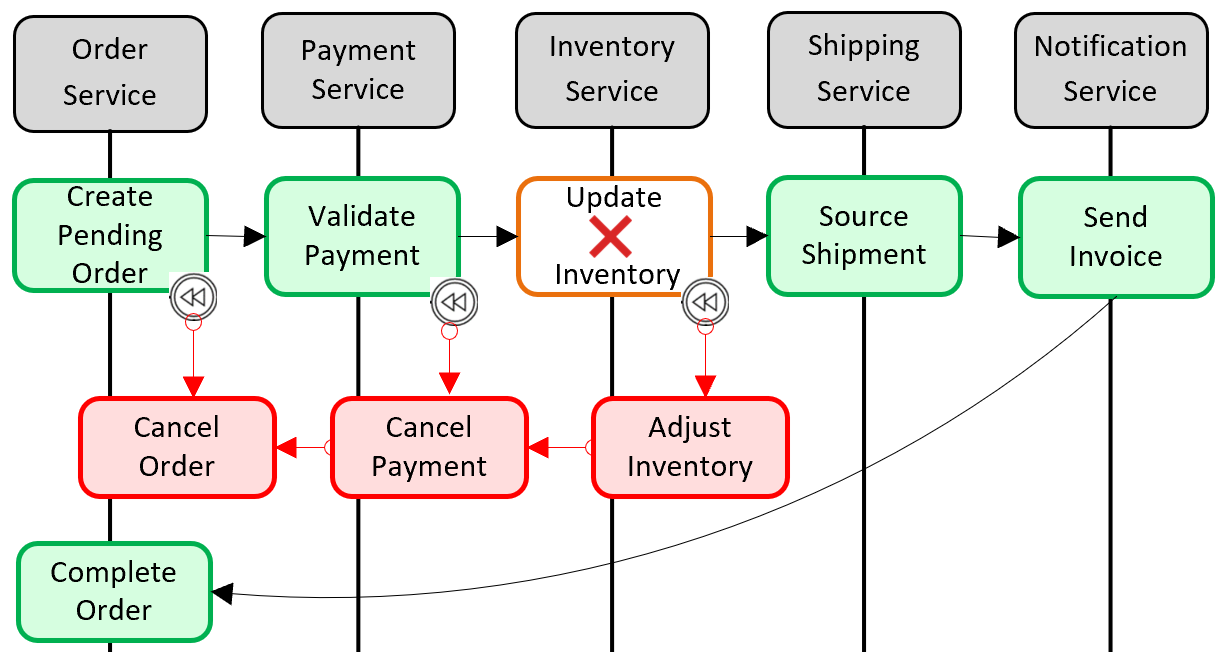
Obrázek 5–6 Vrácení transakce zpět
Na předchozím obrázku operace Update Inventory selhala v mikroslužbě inventáře. Saga vyvolá sadu kompenzačních transakcí (červeně) k úpravě počtu zásob, zrušení platby a objednávky a vrácení dat pro každou mikroslužbu zpět do konzistentního stavu.
Saga vzory jsou obvykle koordinovány jako série souvisejících událostí nebo řízeny jako sada souvisejících příkazů. V kapitole 4 jsme probrali model agregátoru služeb, který by byl základem orchestrované implementace saga. Probrali jsme také eventing spolu s tématy Azure Service Bus a Azure Event Grid, která by byla základem pro implementaci choreografované ságy.
Vysoká objemová data
Velké aplikace nativní pro cloud často podporují požadavky na data s velkým objemem. V těchto scénářích můžou tradiční techniky úložiště dat způsobit kritické body. U složitých systémů, které se nasazují ve velkém měřítku, může výkon aplikace zlepšit oddělení příkazové odpovědnosti i odpovědnosti dotazů (CQRS) a Event Sourcing.
CQRS
CQRS je model architektury, který pomáhá maximalizovat výkon, škálovatelnost a zabezpečení. Model odděluje operace, které čtou data od operací, které zapisují data.
V běžných scénářích se stejný model entity a objekt úložiště dat používají pro operace čtení i zápisu.
Scénář s velkým objemem dat ale může těžit z samostatných modelů a datových tabulek pro čtení a zápisy. Aby se zlepšil výkon, operace čtení se mohla dotazovat na vysoce denormalizované znázornění dat, aby nedocházelo k nákladným opakovaným spojením tabulek a zámkům tabulek. Operace zápisu , označovaná jako příkaz, by se aktualizovala proti plně normalizované reprezentaci dat, která by zaručila konzistenci. Pak musíte implementovat mechanismus, který zachová obě reprezentace synchronizované. Obvykle se při každé změně tabulky zápisu publikuje událost , která replikuje změnu do tabulky pro čtení.
Obrázek 5–7 ukazuje implementaci modelu CQRS.
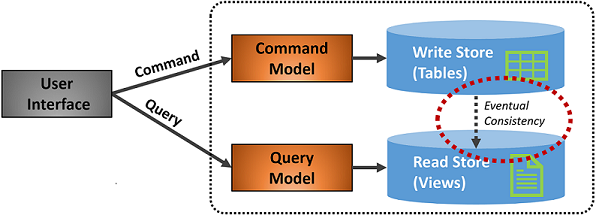
Obrázek 5–7 Implementace CQRS
Na předchozím obrázku jsou implementovány samostatné modely příkazů a dotazů. Každá operace zápisu dat se uloží do úložiště zápisu a pak se rozšíří do úložiště pro čtení. Věnujte pozornost tomu, jak proces šíření dat funguje na principu konečné konzistence. Model čtení se nakonec synchronizuje s modelem zápisu, ale v procesu může docházet k prodlevě. Konečnou konzistenci probereme v další části.
Toto oddělení umožňuje nezávislé škálování čtení a zápisů. Operace čtení používají schéma optimalizované pro dotazy, zatímco zápisy používají schéma optimalizované pro aktualizace. Dotazy při čtení se vztahují na denormalizovaná data, zatímco na model zápisu lze aplikovat komplexní firemní logiku. Můžete také nastavit přísnější zabezpečení operací zápisu, než ty, které zveřejňují čtení.
Implementace CQRS může zlepšit výkon aplikací pro služby nativní pro cloud. Výsledkem je ale složitější návrh. Tento princip použijte pečlivě a strategicky na tyto části vaší aplikace nativní pro cloud, které z ní budou těžit. Další informace o CQRS najdete v knize .NET Microservices od Microsoftu: Architektura pro kontejnerizované aplikace .NET.
Zdrojování událostí
Další přístup k optimalizaci scénářů s velkým objemem dat zahrnuje Event Sourcing.
Systém obvykle ukládá aktuální stav datové entity. Pokud uživatel změní svoje telefonní číslo, například záznam zákazníka se aktualizuje o nové číslo. Vždy známe aktuální stav datové entity, ale každá aktualizace přepíše předchozí stav.
Ve většině případů tento model funguje dobře. V systémech s velkým objemem ale může mít režie zamykání transakcí a časté operace aktualizace vliv na výkon databáze, rychlost odezvy a omezovat škálovatelnost.
Event Sourcing používá jiný přístup k zachytávání dat. Každá operace, která ovlivňuje data, se uchovává v úložišti událostí. Místo aktualizace stavu datového záznamu připojíme každou změnu k sekvenčnímu seznamu minulých událostí – podobně jako účetní registr. Úložiště událostí se stane systémem záznamu dat. Používá se k šíření různých materializovaných zobrazení v rámci ohraničeného kontextu mikroslužby. Obrázek 5.8 znázorňuje vzor.
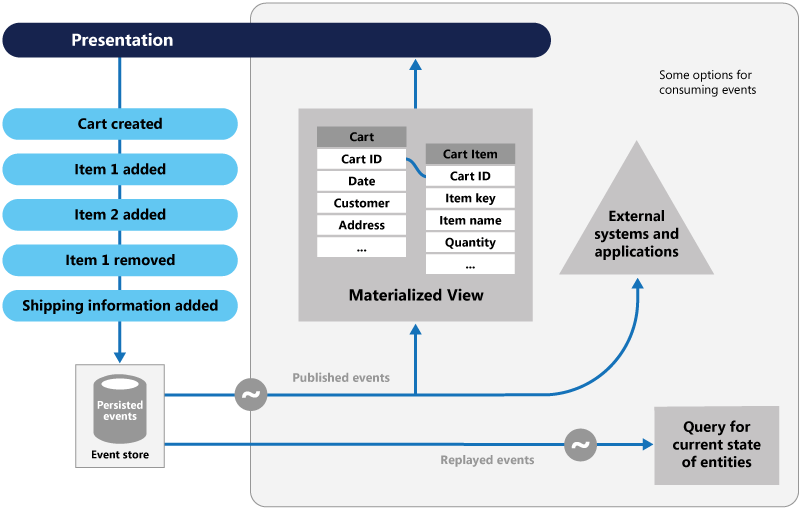
Obrázek 5–8 Event Sourcing (architektura událostí)
Na předchozím obrázku si všimněte, jak se každá položka (modře) pro nákupní košík uživatele připojí k podkladovému úložišti událostí. V přidruženém materializovaném zobrazení systém projektuje aktuální stav tak, že přehraje všechny události přidružené k jednotlivým nákupním košíkem. Toto zobrazení nebo model pro čtení se pak zobrazí zpět v uživatelském rozhraní. Události lze také integrovat s externími systémy a aplikacemi nebo dotazovat, aby bylo možné určit aktuální stav entity. Díky tomuto přístupu udržujete historii. Víte nejen o aktuálním stavu entity, ale také o tom, jak jste dosáhli tohoto stavu.
Mechanicky řečeno, event sourcing zjednodušuje model zápisu. Nejsou k dispozici žádné aktualizace ani odstranění. Připojení jednotlivých položek dat jako neměnné události minimalizuje kolize, uzamčení a konflikty souběžnosti spojené s relačními databázemi. Vytváření modelů čtení pomocí modelu materializovaného zobrazení umožňuje oddělit zobrazení od modelu zápisu a zvolit nejlepší úložiště dat pro optimalizaci potřeb uživatelského rozhraní aplikace.
U tohoto modelu zvažte úložiště dat, které přímo podporuje model Event Sourcing. Azure Cosmos DB, MongoDB, Cassandra, CouchDB a RavenDB jsou dobrými kandidáty.
Stejně jako u všech vzorů a technologií implementujte strategicky a v případě potřeby. I když event sourcing může poskytovat vyšší výkon a škálovatelnost, přichází na úkor složitosti a křivky učení.
Spolupracujte s námi na GitHubu
Zdroj tohoto obsahu najdete na GitHubu, kde můžete také vytvářet a kontrolovat problémy a žádosti o přijetí změn. Další informace najdete v našem průvodci pro přispěvatele.