Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Návod
Tento obsah je výňatek z eBooku, architektury mikroslužeb .NET pro kontejnerizované aplikace .NET, které jsou k dispozici na .NET Docs nebo jako zdarma ke stažení PDF, které lze číst offline.

Cílem při identifikaci hranic a velikosti modelu pro každou mikroslužbu není dosáhnout co nejpodrobnějšího možného oddělení, i když pokud je to možné, měli byste se snažit o menší mikroslužby. Místo toho by vaším cílem mělo být dosáhnout nejvýznamnějšího rozdělení, které je vedeno vašimi znalostmi oboru. Důraz není na velikost, ale na obchodní možnosti. Kromě toho, pokud je pro určitou oblast aplikace nutná jasná soudržnost na základě vysokého počtu závislostí, znamená to také potřebu jedné mikroslužby. Soudržnost je způsob, jak identifikovat, jak oddělit nebo seskupit mikroslužby. Nakonec, i když získáte více znalostí o doméně, měli byste přizpůsobit velikost mikroslužby iterativním způsobem. Hledání správné velikosti není procesem na jeden pokus.
Sam Newman, rozpoznaný propagátor mikroslužeb a autor knihy Vytváření mikroslužeb, zdůrazňuje, že byste měli navrhnout mikroslužby na základě vzoru vázaného kontextu (BC) (součást návrhu řízeného doménou), jak jsme představili dříve. Někdy se BC může skládat z několika fyzických služeb, ale ne naopak.
Doménový model s konkrétními entitami domény se vztahuje v rámci konkrétní bc nebo mikroslužby. Bc odděluje použitelnost doménového modelu a poskytuje členům vývojového týmu jasné a sdílené porozumění tomu, co musí být soudržné a co je možné vyvíjet nezávisle. To jsou stejné cíle pro mikroslužby.
Dalším nástrojem, který informuje vaši volbu návrhu, je Conwayův zákon, který uvádí, že aplikace bude odrážet sociální hranice organizace, která ji vytvořila. Někdy je ale pravý opak -the organizaci společnosti tvoří software. Možná budete muset zvrátit Conwayův zákon a vytvořit hranice tak, jak chcete, aby byla společnost uspořádána, přičemž se zaměříte na poradenství v oblasti obchodních procesů.
K identifikaci ohraničených kontextů můžete použít model DDD označovaný jako model mapování kontextu. Pomocí mapování kontextu identifikujete různé kontexty v aplikaci a jejich hranice. Pro každý malý subsystém je běžné mít jiný kontext a hranici, například. Kontextová mapa představuje způsob, jak definovat a explicitně určit hranice mezi doménami. BC je autonomní a obsahuje podrobnosti o jedné doméně -details, jako jsou entity domény, a definuje integrační kontrakty s jinými BCs. Podobá se definici mikroslužby: je autonomní, implementuje určité schopnosti domény a musí poskytovat rozhraní. To je důvod, proč mapování kontextu a vzor ohraničeného kontextu jsou vhodné přístupy k identifikaci hranic doménového modelu mikroslužeb.
Při návrhu velké aplikace uvidíte, jak je možné její doménový model fragmentovat – odborník na doménu z domény katalogu bude pojmenovat entity odlišně v katalogu a v doménách inventáře než odborník na expediční doménu, například. Nebo entita domény uživatele se může lišit v rozsahu a počtu atributů při práci s odborníkem na CRM, který chce ukládat všechny podrobnosti o zákazníkovi, než u odborníka na objednávku domény, který potřebuje jenom částečná data o zákazníkovi. Je velmi těžké zrušit nejednoznačnost všech termínů domény ve všech doménách souvisejících s velkou aplikací. Ale nejdůležitější je, že byste se neměli snažit sjednotit termíny. Místo toho přijměte rozdíly a bohatost poskytovanou každou doménou. Pokud se pokusíte mít jednotnou databázi pro celou aplikaci, pokusy o jednotný slovník budou neohrabané a nebudou znít dobře žádnému z několika odborníků v oboru. Proto vám řadiče BCS (implementované jako mikroslužby) pomůžou objasnit, kde můžete použít určité podmínky domény a kde budete muset rozdělit systém a vytvořit další řadiče domény s různými doménami.
Víte, že máte správné hranice a velikosti jednotlivých BC a doménového modelu, pokud máte několik silných vztahů mezi doménovými modely a při provádění typických operací aplikace obvykle nepotřebujete sloučit informace z více doménových modelů.
Možná nejlepší odpověď na otázku, jak velký doménový model pro každou mikroslužbu by měl být následující: měla by mít autonomní BC, co nejizolanější, která vám umožní pracovat, aniž byste museli neustále přepínat do jiných kontextů (modely jiných mikroslužeb). Na obrázku 4–10 vidíte, jak má každá z více mikroslužeb (více řadičů BC) svůj vlastní model a jak se dají definovat jejich entity v závislosti na konkrétních požadavcích pro každou z identifikovaných domén ve vaší aplikaci.
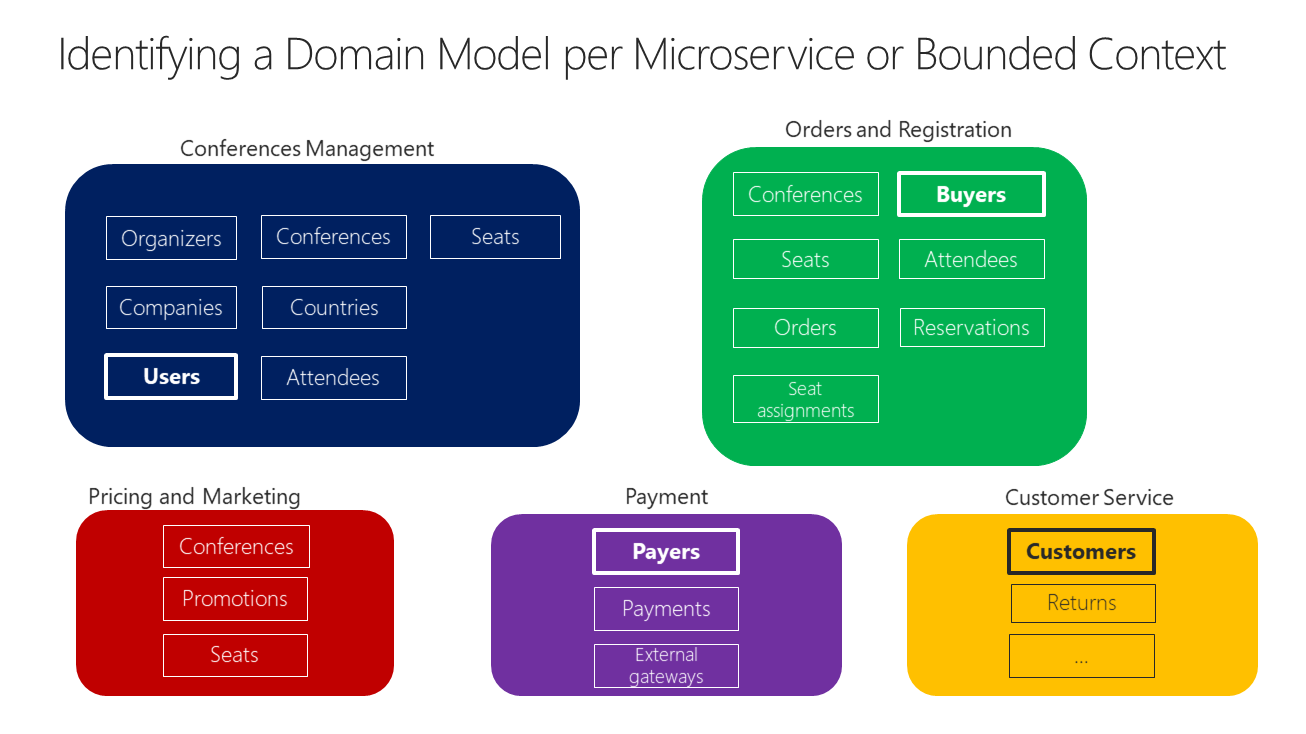
Obrázek 4–10 Identifikace entit a hranic modelu mikroslužeb
Obrázek 4–10 znázorňuje ukázkový scénář související se systémem online správy konferencí. Stejná entita se v závislosti na vázaném kontextu zobrazí jako Uživatelé, Kupující, Plátci a Zákazníci. Identifikovali jste několik BCs, které by se daly implementovat jako mikroslužby na základě odborné definice domén. Jak vidíte, existují entity, které se nacházejí pouze v jednom modelu mikroslužeb, jako jsou platby v mikroslužbě platby. Ty se budou snadno implementovat.
Můžete ale mít také entity, které mají jiný tvar, ale sdílejí stejnou identitu napříč několika doménovými modely z několika mikroslužeb. Například entita User je identifikována v mikroslužbě Správy konferencí. Stejný uživatel se stejnou identitou je ten, který se jmenuje Kupující v mikroslužbě Objednávání, nebo ten s názvem Payer v mikroslužbě Platby, a dokonce i ten, který se jmenuje Zákazník v mikroslužbě Služby zákazníkům. Je to proto, že v závislosti na všudypřítomnosti jazyka , který každý odborník na doménu používá, může mít uživatel jinou perspektivu i s různými atributy. Entita uživatele v modelu mikroslužeb s názvem Conferences Management může mít většinu svých atributů osobních dat. Stejný uživatel jako Payer v mikroslužbě Payment nebo jako Customer v mikroslužbě Customer Service nemusí mít stejný seznam atributů.
Podobný přístup je znázorněn na obrázku 4–11.
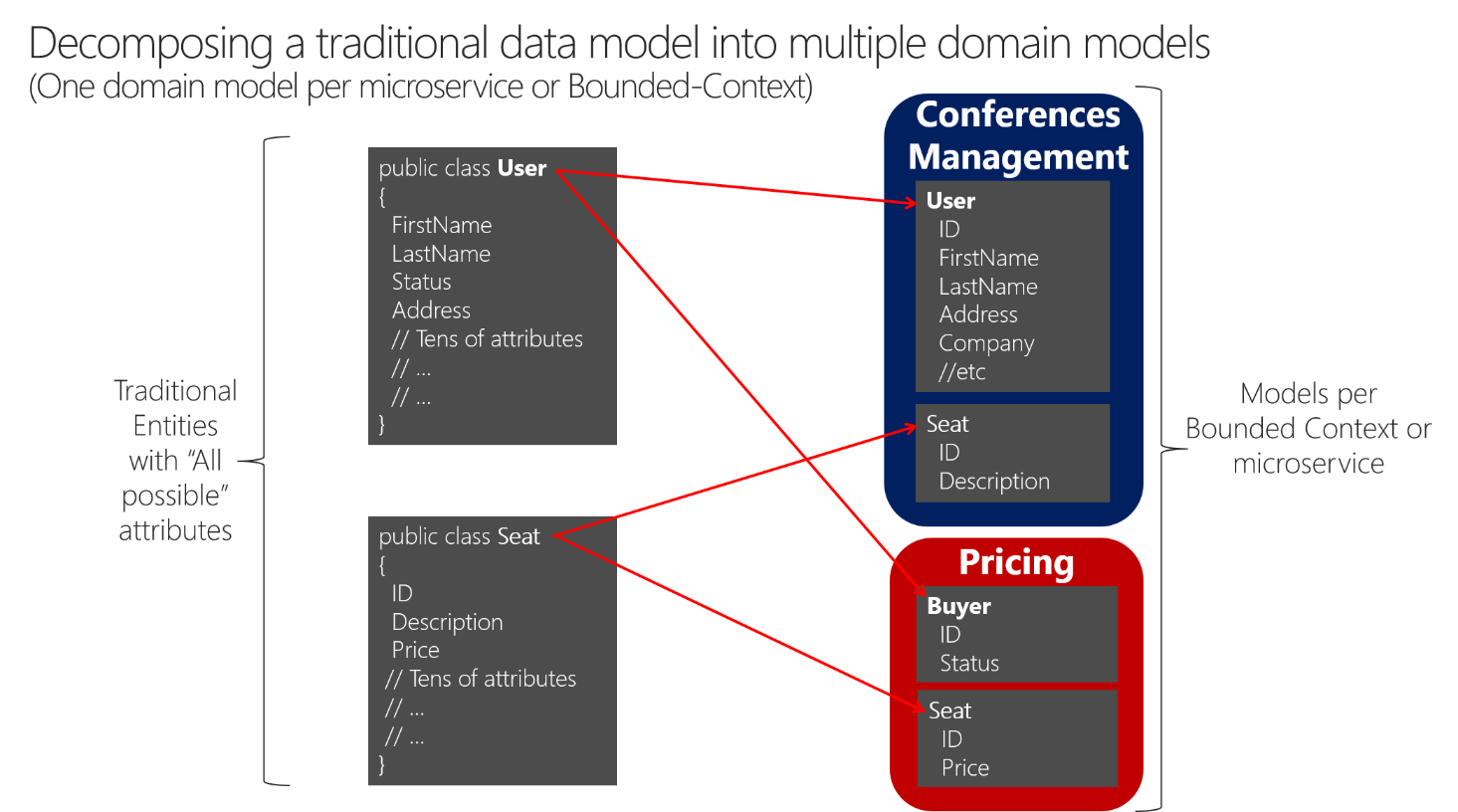
Obrázek 4–11 Rozložení tradičních datových modelů do několika doménových modelů
Při rozkladu tradičního datového modelu mezi ohraničenými kontexty můžete mít různé entity, které sdílejí stejnou identitu (kupující je také uživatel) s různými atributy v každém vázaném kontextu. Uvidíte, jak se uživatel nachází v modelu mikroslužby pro správu konferencí jako entita Uživatel a je také přítomen jako entita Kupující v mikroslužbě pro stanovení cen, s odlišnými atributy nebo detaily o uživateli, když je skutečně kupující. Každá mikroslužba nebo BC nemusí potřebovat všechna data související s entitou uživatele, jen její část v závislosti na problému, který se má vyřešit, nebo kontextu. Například v modelu mikroslužby pro účtování nepotřebujete adresu ani název uživatele, jenom ID (jako identitu) a Stav, které budou mít vliv na slevy při určování cen míst na kupujícího.
Entita Seat má stejný název, ale různé atributy v každém doménovém modelu. Společnost Seat ale sdílí identitu na základě stejného ID, jako se stane u uživatele a kupujícího.
V podstatě existuje sdílený koncept uživatele ve více službách (doménách), které sdílejí identitu daného uživatele. V každém doménovém modelu ale můžou existovat další nebo jiné podrobnosti o entitě uživatele. Proto musí existovat způsob, jak mapovat entitu uživatele z jedné domény (mikroslužby) na jinou.
Existuje několik výhod v nesdílení stejné uživatelské entity se stejným počtem atributů napříč doménami. Jednou z výhod je snížení duplicit, aby modely mikroslužeb neměly žádná data, která nepotřebují. Další výhodou je primární mikroslužba, která vlastní určitý typ dat na entitu, aby aktualizace a dotazy na tento typ dat byly řízeny pouze danou mikroslužbou.
Spolupracujte s námi na GitHubu
Zdroj tohoto obsahu najdete na GitHubu, kde můžete také vytvářet a kontrolovat problémy a žádosti o přijetí změn. Další informace najdete v našem průvodci pro přispěvatele.