Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Návod
Tento obsah je výňatek z eBooku, architektury mikroslužeb .NET pro kontejnerizované aplikace .NET, které jsou k dispozici na .NET Docs nebo jako zdarma ke stažení PDF, které lze číst offline.

Výzva č. 1: Definování hranic jednotlivých mikroslužeb
Definování hranic mikroslužeb je pravděpodobně první výzvou, se kterými se někdo setká. Každá mikroslužba musí být součástí vaší aplikace a každá mikroslužba by měla být autonomní se všemi výhodami a výzvami, které přináší. Jak ale tyto hranice identifikujete?
Nejprve se musíte zaměřit na logické doménové modely aplikace a související data. Zkuste identifikovat oddělené ostrovy dat a různé kontexty v rámci stejné aplikace. Každý kontext může mít jiný obchodní jazyk (různé obchodní podmínky). Kontexty by se měly definovat a spravovat nezávisle. Termíny a entity, které se používají v těchto různých kontextech, můžou vypadat podobně, ale můžete zjistit, že v konkrétním kontextu se pro jiný účel používá obchodní koncept s jedním z nich a dokonce může mít jiný název. Uživatel může být například označován jako uživatel v kontextu identity nebo členství, jako zákazník v kontextu CRM, jako kupující v kontextu objednávání atd.
Způsob, jakým identifikujete hranice mezi několika kontexty aplikace s jinou doménou pro každý kontext, je přesně způsob, jak můžete identifikovat hranice jednotlivých obchodních mikroslužeb a souvisejících doménových modelů a dat. Vždy se pokusíte minimalizovat spojení mezi těmito mikroslužbami. Tato příručka podrobně popisuje tento návrh modelu identifikace a domény v části Identifikace hranic modelu domény pro každou mikroslužbu později.
Výzva č. 2: Vytvoření dotazů, které načítají data z několika mikroslužeb
Druhým problémem je, jak implementovat dotazy, které načítají data z několika mikroslužeb, a zároveň se vyhnout nadměrné komunikaci ze vzdálených klientských aplikací vůči těmto mikroslužbám. Příkladem může být jedna obrazovka z mobilní aplikace, která potřebuje zobrazit informace o uživateli vlastněné košíkem, katalogem a mikroslužbami identit uživatelů. Dalším příkladem by byla složitá sestava zahrnující mnoho tabulek umístěných v několika mikroslužbách. Správné řešení závisí na složitosti dotazů. V každém případě ale budete potřebovat způsob, jak agregovat informace, pokud chcete zlepšit efektivitu komunikace systému. Nejoblíbenější řešení jsou následující.
Brána rozhraní API. Pro jednoduchou agregaci dat z více mikroslužeb, které vlastní různé databáze, se doporučeným přístupem je agregační mikroslužba označovaná jako brána rozhraní API. Ale musíte být opatrní při implementaci tohoto modelu, protože může představovat úzké místo ve vašem systému a může porušit zásadu autonomie mikroslužeb. Pokud chcete tuto možnost zmírnit, můžete mít několik jemně odstupňovaných bran rozhraní API, které se zaměřují na vertikální "řez" nebo obchodní oblast systému. Model brány rozhraní API je podrobněji vysvětlený v části Brána rozhraní API později.
Federace GraphQL Jednou z možností, jak zvážit, jestli už vaše mikroslužby používají GraphQL, je Federace GraphQL. Federace umožňuje definovat "podgrafy" z jiných služeb a vytvořit je do agregovaného supergrafu, který funguje jako samostatné schéma.
CQRS s tabulkami dotazů a načítání dat Dalším řešením agregace dat z více mikroslužeb je model materializovaného zobrazení. V tomto přístupu předem vygenerujete (připravíte denormalizovaná data před provedením skutečných dotazů) tabulku jen pro čtení s daty vlastněnými několika mikroslužbami. Tabulka má formát vhodný pro potřeby klientské aplikace.
Představte si něco jako obrazovku mobilní aplikace. Pokud máte jednu databázi, můžete načíst data pro tuto obrazovku pomocí dotazu SQL, který provádí složité spojení zahrnující více tabulek. Pokud však máte více databází a každá databáze vlastní jinou mikroslužbu, nemůžete tyto databáze dotazovat a vytvořit připojení SQL. Složitý dotaz se stává výzvou. Tento požadavek můžete vyřešit pomocí přístupu CQRS – vytvoříte denormalizovanou tabulku v jiné databázi, která se používá jenom pro dotazy. Tabulku je možné navrhnout speciálně pro data, která potřebujete pro složitý dotaz, s relací 1:1 mezi poli potřebnými obrazovkou vaší aplikace a sloupci v tabulce dotazu. Může také sloužit pro účely reportování.
Tento přístup nejen řeší původní problém (dotazování a spojení napříč mikroslužbami), ale ve srovnání se složitým spojením výrazně zvyšuje výkon, protože už máte data, která aplikace potřebuje v tabulce dotazů. Samozřejmě použití oddělení odpovědnosti příkazů a dotazů (CQRS) s tabulkami dotazů a čtení znamená další vývojovou práci a budete muset přijmout konečnou konzistenci. Požadavky na výkon a vysokou škálovatelnost v scénářích pro spolupráci (nebo konkurenční scénáře v závislosti na pohledu) jsou místem, kde byste měli CQRS použít s více databázemi.
Studená data v centrálních databázích. U složitých sestav a dotazů, které nemusí vyžadovat data v reálném čase, je běžným přístupem exportovat "horká data" (transakční data z mikroslužeb) jako "studená data" do velkých databází, které se používají jenom pro vytváření sestav. Tento centrální databázový systém může být systémem založeným na velkých objemech dat, jako je Hadoop; datový sklad, jako je datový sklad založený na Azure SQL Data Warehouse; nebo i jednu databázi SQL, která se používá jenom pro sestavy (pokud velikost nebude problémem).
Mějte na paměti, že tato centralizovaná databáze by se používala pouze pro dotazy a sestavy, které nepotřebují data v reálném čase. Původní aktualizace a transakce, jako váš zdroj pravdy, musí být ve vašich datech mikroslužeb. Způsob synchronizace dat by byl buď pomocí komunikace řízené událostmi (popsaných v dalších částech), nebo pomocí jiných nástrojů pro import a export infrastruktury databáze. Pokud používáte komunikaci řízenou událostmi, bude tento proces integrace podobný způsobu šíření dat, jak je popsáno výše pro tabulky dotazů CQRS.
Pokud ale návrh aplikace zahrnuje neustálé agregace informací z více mikroslužeb pro složité dotazy, může to být příznakem špatného návrhu -a mikroslužby by měla být co nejvíce izolovaná od jiných mikroslužeb. (Tím se vyloučí sestavy a analýzy, které by vždy měly používat databáze centrálních dat.) Častý výskyt tohoto problému může být důvodem ke sloučení mikroslužeb. Potřebujete vyvážit autonomii vývoje a nasazování jednotlivých mikroslužeb se silnými závislostmi, soudržností a agregací dat.
Výzva č. 3: Jak dosáhnout konzistence napříč několika mikroslužbami
Jak jsme uvedli dříve, data vlastněná jednotlivými mikroslužbami jsou pro tuto mikroslužbu soukromá a dají se k němu přistupovat pouze pomocí rozhraní API mikroslužeb. Z toho důvodu je prezentována výzva, jak implementovat komplexní obchodní procesy a současně zachovat konzistenci napříč několika mikroslužbami.
Abychom tento problém analyzovali, podívejme se na příklad z referenční aplikace eShopOnContainers. Mikroslužba katalogu uchovává informace o všech produktech, včetně ceny produktu. Mikroslužba Košík spravuje dočasná data o položkách produktů, které uživatelé přidávají do svých nákupních košíků, což zahrnuje cenu položek v době, kdy byly přidány do košíku. Když se v katalogu aktualizuje cena produktu, měla by se tato cena aktualizovat také v aktivních košíkech, které obsahují stejný produkt, a systém by měl pravděpodobně upozornit uživatele, že se cena konkrétní položky změnila, protože ji přidala do košíku.
V hypotetické monolitické verzi této aplikace, když se cena změní v tabulce produktů, subsystém katalogu může jednoduše použít transakci ACID k aktualizaci aktuální ceny v tabulce Košík.
V aplikaci založené na mikroslužbách ale tabulky Product a Basket vlastní příslušné mikroslužby. Žádná mikroslužba by nikdy neměla obsahovat tabulky nebo úložiště vlastněné jinou mikroslužbou ve svých vlastních transakcích, a to ani v přímých dotazech, jak je znázorněno na obrázku 4–9.
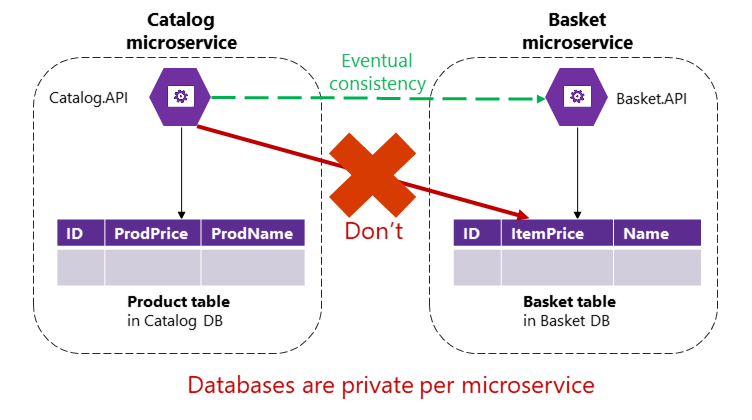
Obrázek 4–9 Mikroslužba nemá přímý přístup k tabulce v jiné mikroslužbě.
Mikroslužba katalogu by neměla aktualizovat tabulku Košík přímo, protože tabulka Košík je vlastněna mikroslužbou košíku. Pokud chcete provést aktualizaci mikroslužby košíku, měla by mikroslužba katalogu používat konečnou konzistenci pravděpodobně na základě asynchronní komunikace, jako jsou události integrace (komunikace založená na zprávách a událostech). Takto referenční aplikace eShopOnContainers provádí tento typ konzistence napříč mikroslužbami.
Jak uvádí CAP teorém, musíte si vybrat mezi dostupností a silnou konzistencí ACID. Většina scénářů založených na mikroslužbách vyžaduje dostupnost a vysokou škálovatelnost na rozdíl od silné konzistence. Kriticky důležité aplikace musí zůstat funkční a v provozu a vývojáři mohou obejít silnou konzistenci použitím technik, které pracují se slabou nebo eventuální konzistencí. Jedná se o přístup, který využívá většina architektur založených na mikroslužbách.
Transakce ve stylu ACID nebo dvoufázové potvrzení navíc nejsou jen proti principům mikroslužeb; Většina databází NoSQL (jako je Azure Cosmos DB, MongoDB atd.) nepodporuje transakce dvoufázového potvrzení, které jsou typické ve scénářích distribuovaných databází. Zachování konzistence dat napříč službami a databázemi je však nezbytné. Tato výzva souvisí také s otázkou, jak rozšířit změny napříč několika mikroslužbami, když je potřeba určitá data redundantní – například když potřebujete mít název nebo popis produktu v mikroslužbě katalogu a mikroslužbě Košíku.
Dobrým řešením tohoto problému je použít konečnou konzistenci mezi mikroslužbami vyjádřenou prostřednictvím komunikace řízené událostmi a systémem publikování a odběru. Tato témata jsou popsána v části Asynchronní komunikace řízená událostmi dále v této příručce.
Výzva č. 4: Návrh komunikace napříč hranicemi mikroslužeb
Komunikace přes hranice mikroslužeb je skutečnou výzvou. V tomto kontextu komunikace neodkazuje na protokol, který byste měli použít (HTTP a REST, AMQP, zasílání zpráv atd.). Místo toho řeší, jaký styl komunikace byste měli použít, a zejména to, jak by měly být svázané mikroslužby. V závislosti na úrovni párování se dopad tohoto selhání na váš systém výrazně liší.
V distribuovaném systému, jako je aplikace založená na mikroslužbách, s tolik artefakty, které se pohybují kolem a s distribuovanými službami napříč mnoha servery nebo hostiteli, komponenty nakonec selžou. Dojde k částečnému selhání a dokonce k větším výpadkům, takže je potřeba navrhnout mikroslužby a komunikaci mezi nimi s ohledem na běžná rizika v tomto typu distribuovaného systému.
Oblíbeným přístupem je implementace mikroslužeb založených na protokolu HTTP (REST) kvůli jejich jednoduchosti. Přístup založený na protokolu HTTP je naprosto přijatelný; problém souvisí s tím, jak ho používáte. Pokud k interakci s mikroslužbami z klientských aplikací nebo z API bran používáte požadavky a odpovědi HTTP, je to v pořádku. Pokud ale vytvoříte dlouhý řetěz synchronních volání HTTP napříč mikroslužbami, komunikace přes jejich hranice, jako by mikroslužby byly objekty v monolitické aplikaci, vaše aplikace nakonec narazí na problémy.
Představte si například, že vaše klientská aplikace volá rozhraní HTTP API pro jednotlivé mikroslužby, jako je mikroslužba Ordering. Pokud mikroslužba objednávání zase volá další mikroslužby využívající protokol HTTP ve stejném cyklu požadavků a odpovědí, vytváříte řetěz volání HTTP. Zpočátku to může znít rozumně. Při přechodu na tuto cestu je však potřeba vzít v úvahu důležité body:
Blokování a nízký výkon Vzhledem k synchronní povaze protokolu HTTP původní požadavek nedostane odpověď, dokud se nedokončí všechna interní volání HTTP. Představte si, že se počet těchto volání výrazně zvýší a současně se zablokuje jedno z průběžných volání HTTP mikroslužby. Výsledkem je dopad na výkon a celková škálovatelnost bude exponenciálně ovlivněna při nárůstu dalších požadavků HTTP.
Párování mikroslužeb pomocí protokolu HTTP. Obchodní mikroslužby by neměly být svázány s jinými obchodními mikroslužbami. V ideálním případě by neměli "vědět" o existenci jiných mikroslužeb. Pokud vaše aplikace spoléhá na párové mikroslužby jako v příkladu, bude dosažení autonomie na mikroslužbu téměř nemožné.
Selhání v jakékoli mikroslužbě. Pokud jste implementovali řetězec mikroslužeb propojených voláními HTTP, dojde k selhání některé z mikroslužeb (a nakonec k selhání) celého řetězce mikroslužeb. Systém založený na mikroslužbách by měl být navržen tak, aby fungoval i v případě částečných selhání. I když implementujete logiku klienta, která používá opakování s exponenciální zádrží nebo mechanismy jističe, čím složitější jsou řetězce volání HTTP, tím složitější je implementovat strategii selhání na základě protokolu HTTP.
Ve skutečnosti, pokud vaše interní mikroslužby komunikují vytvořením řetězů požadavků HTTP, jak je popsáno, může být argumentováno, že máte monolitickou aplikaci, ale jednu založenou na HTTP mezi procesy místo komunikačních mechanismů uvnitř procesu.
Proto pokud chcete vynutit autonomii mikroslužeb a mít lepší odolnost, měli byste minimalizovat použití řetězů komunikace požadavků a odpovědí napříč mikroslužbami. Doporučuje se použít pouze asynchronní interakci pro komunikaci mezi mikroslužbami, a to buď pomocí asynchronní komunikace založené na zprávách a událostech, nebo pomocí (asynchronního) dotazování HTTP nezávisle na původním cyklu požadavků a odpovědí HTTP.
Použití asynchronní komunikace je vysvětleno s dalšími podrobnostmi dále v této příručce v částech Asynchronní integrace mikroslužeb vynucuje autonomii mikroslužby a asynchronní komunikaci založenou na zprávách.
Dodatečné zdroje
CAP teorém
https://en.wikipedia.org/wiki/CAP_theoremKonečná konzistence
https://en.wikipedia.org/wiki/Eventual_consistencyÚvod do konzistence dat
https://learn.microsoft.com/previous-versions/msp-n-p/dn589800(v=pandp.10)Martin Fowler. CQRS (oddělení odpovědnosti příkazů a dotazů)
https://martinfowler.com/bliki/CQRS.htmlMaterializované zobrazení
https://learn.microsoft.com/azure/architecture/patterns/materialized-viewCharles Row. ACID vs. BASE: Posun pH zpracování databázové transakce
https://www.dataversity.net/acid-vs-base-the-shifting-ph-of-database-transaction-processing/Kompenzační transakce
https://learn.microsoft.com/azure/architecture/patterns/compensating-transactionUdi Dahan. Kompozice orientovaná na služby
https://udidahan.com/2014/07/30/service-oriented-composition-with-video/
Spolupracujte s námi na GitHubu
Zdroj tohoto obsahu najdete na GitHubu, kde můžete také vytvářet a kontrolovat problémy a žádosti o přijetí změn. Další informace najdete v našem průvodci pro přispěvatele.