Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Návod
Tento obsah je výňatek z eBooku, architekta moderních webových aplikací s ASP.NET Core a Azure, který je k dispozici na webu .NET Docs nebo jako bezplatný soubor PDF ke stažení, který si můžete přečíst offline.

"Data jsou drahocenná věc a budou trvat déle než systémy samotné."
Tim Berners-Lee
Přístup k datům je důležitou součástí téměř jakékoli softwarové aplikace. ASP.NET Core podporuje různé možnosti přístupu k datům, včetně Entity Framework Core (a Entity Framework 6) a může pracovat s libovolnou architekturou pro přístup k datům .NET. Volba architektury pro přístup k datům, která se má použít, závisí na potřebách aplikace. Abstrakce těchto voleb z projektů ApplicationCore a UI a zapouzdření podrobností implementace v infrastruktuře pomáhá vytvářet volně propojený a testovatelný software.
Entity Framework Core (pro relační databáze)
Pokud píšete novou aplikaci ASP.NET Core, která potřebuje pracovat s relačními daty, doporučuje se pro vaši aplikaci přístup k datům Entity Framework Core (EF Core). EF Core je objektově-relační mapovač (O/RM), který vývojářům .NET umožňuje zachovat objekty do a ze zdroje dat. Eliminuje potřebu většiny vývojářů kódu pro přístup k datům obvykle potřebovat psát. Stejně jako ASP.NET Core se EF Core přepsala od základů, aby podporovala modulární multiplatformní aplikace. Přidáte ho do aplikace jako balíček NuGet, nakonfigurujete ho při spuštění aplikace a vyžádáte si ho prostřednictvím injektáže závislostí, ať už ho potřebujete.
Pokud chcete použít EF Core s databází SQL Serveru, spusťte následující příkaz rozhraní příkazového řádku dotnet:
dotnet add package Microsoft.EntityFrameworkCore.SqlServer
Pokud chcete přidat podporu pro zdroj dat InMemory, pro účely testování:
dotnet add package Microsoft.EntityFrameworkCore.InMemory
DbContext
Pro práci s EF Core potřebujete podtřídu DbContext. Tato třída obsahuje vlastnosti představující kolekce entit, se kterými bude vaše aplikace pracovat. Ukázka eShopOnWeb obsahuje CatalogContext kolekce pro položky, značky a typy:
public class CatalogContext : DbContext
{
public CatalogContext(DbContextOptions<CatalogContext> options) : base(options)
{
}
public DbSet<CatalogItem> CatalogItems { get; set; }
public DbSet<CatalogBrand> CatalogBrands { get; set; }
public DbSet<CatalogType> CatalogTypes { get; set; }
}
DbContext musí mít konstruktor, který přijímá DbContextOptions a předává tento argument do základního DbContext konstruktoru. Pokud máte v aplikaci pouze jeden DbContext, můžete předat instanci DbContextOptions, ale pokud máte více než jeden, musíte použít obecný DbContextOptions<T> typ a předat typ DbContext jako obecný parametr.
Konfigurace EF Core
V aplikaci ASP.NET Core obvykle nakonfigurujete EF Core v Program.cs s jinými závislostmi vaší aplikace. EF Core používá DbContextOptionsBuilderk zjednodušení konfigurace několik užitečných metod rozšíření. Chcete-li nakonfigurovat CatalogContext tak, aby používala databázi SQL Serveru s připojovací řetězec definovanou v konfiguraci, přidejte následující kód:
builder.Services.AddDbContext<CatalogContext>(
options => options.UseSqlServer(
builder.Configuration.GetConnectionString("DefaultConnection")));
Použití databáze v paměti:
builder.Services.AddDbContext<CatalogContext>(options =>
options.UseInMemoryDatabase());
Jakmile nainstalujete EF Core, vytvoříte podřízený typ DbContext a přidáte ho do služeb aplikace, budete připraveni použít EF Core. Můžete požádat o instanci vašeho typu DbContext v libovolné službě, která ji potřebuje, a začít pracovat s trvalými entitami pomocí LINQ, jako by byly jednoduše v kolekci. EF Core dělá práci s překladem výrazů LINQ do dotazů SQL pro ukládání a načítání dat.
Dotazy EF Core se zobrazují tak, že konfigurujete protokolovací nástroj a zajistíte, že jeho úroveň je nastavená na alespoň Informace, jak je znázorněno na obrázku 8-1.
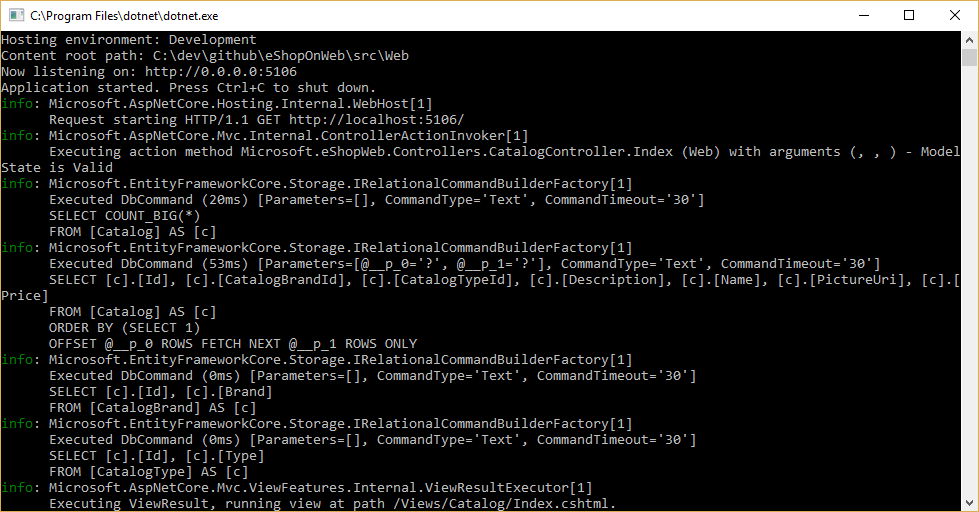
Obrázek 8-1 Protokolování dotazů EF Core do konzoly
Načítání a ukládání dat
Pokud chcete načíst data z EF Core, získáte přístup k příslušné vlastnosti a pomocí LINQ vyfiltrujete výsledek. LinQ můžete také použít k projekci a transformovat výsledek z jednoho typu na jiný. Následující příklad by načetl CatalogBrands, seřazený podle názvu, vyfiltroval jejich Enabled vlastnost a projected na SelectListItem typ:
var brandItems = await _context.CatalogBrands
.Where(b => b.Enabled)
.OrderBy(b => b.Name)
.Select(b => new SelectListItem {
Value = b.Id, Text = b.Name })
.ToListAsync();
Ve výše uvedeném příkladu je důležité přidat volání ToListAsync , aby se dotaz spustil okamžitě. V opačném případě se příkaz přiřadí IQueryable<SelectListItem> značce BrandItems, která se nespustí, dokud se nevypíše. Existují výhody a nevýhody pro vrácení IQueryable výsledků z metod. Umožňuje, aby byl dotaz EF Core dále upraven, ale může také vést k chybám, ke kterým dochází pouze za běhu, pokud se operace přidají do dotazu, který EF Core nemůže přeložit. Obecně je bezpečnější předat všechny filtry do metody, která provádí přístup k datům, a v důsledku toho vrátit zpět kolekci v paměti (například List<T>).
EF Core sleduje změny entit, které načítá z trvalosti. Pokud chcete uložit změny sledované entity, stačí volat SaveChangesAsync metodu v DbContext a ujistit se, že se jedná o stejnou instanci DbContext, která byla použita k načtení entity. Přidávání a odebírání entit se provádí přímo u příslušné vlastnosti DbSet, a to znovu s voláním pro SaveChangesAsync spuštění databázových příkazů. Následující příklad ukazuje přidání, aktualizaci a odebrání entit z trvalosti.
// create
var newBrand = new CatalogBrand() { Brand = "Acme" };
_context.Add(newBrand);
await _context.SaveChangesAsync();
// read and update
var existingBrand = _context.CatalogBrands.Find(1);
existingBrand.Brand = "Updated Brand";
await _context.SaveChangesAsync();
// read and delete (alternate Find syntax)
var brandToDelete = _context.Find<CatalogBrand>(2);
_context.CatalogBrands.Remove(brandToDelete);
await _context.SaveChangesAsync();
EF Core podporuje synchronní i asynchronní metody pro načítání a ukládání. Ve webových aplikacích se doporučuje použít vzor async/await s asynchronními metodami, aby vlákna webového serveru nebyla blokována při čekání na dokončení operací přístupu k datům.
Další informace najdete v tématu Ukládání do vyrovnávací paměti a streamování.
Načítání souvisejících dat
Když EF Core načte entity, naplní všechny vlastnosti, které jsou uložené přímo s danou entitou v databázi. Navigační vlastnosti, například seznamy souvisejících entit, nejsou naplněné a mohou mít jejich hodnotu nastavenou na hodnotu null. Tento proces zajišťuje, že EF Core nenačítá více dat, než je potřeba, což je zvlášť důležité pro webové aplikace, které musí rychle zpracovávat požadavky a vracet odpovědi efektivním způsobem. Pokud chcete zahrnout relace s entitou pomocí dychtivého načítání, zadejte vlastnost pomocí metody Include extension v dotazu, jak je znázorněno na obrázku:
// .Include requires using Microsoft.EntityFrameworkCore
var brandsWithItems = await _context.CatalogBrands
.Include(b => b.Items)
.ToListAsync();
Můžete zahrnout více relací a můžete také zahrnout dílčí relace pomocí ThenInclude. EF Core spustí jeden dotaz, který načte výslednou sadu entit. Alternativně můžete zahrnout navigační vlastnosti navigačních vlastností předáním "." -separated string to the .Include() extension method, like like so:
.Include("Items.Products")
Kromě zapouzdření logiky filtrování může specifikace určit tvar vrácených dat, včetně vlastností, které se mají naplnit. Ukázka eShopOnWeb obsahuje několik specifikací, které ukazují zapouzdření informací o dychtivých načítání v rámci specifikace. Tady se dozvíte, jak se specifikace používá jako součást dotazu:
// Includes all expression-based includes
query = specification.Includes.Aggregate(query,
(current, include) => current.Include(include));
// Include any string-based include statements
query = specification.IncludeStrings.Aggregate(query,
(current, include) => current.Include(include));
Další možností pro načítání souvisejících dat je použití explicitního načítání. Explicitní načítání umožňuje načíst další data do entity, která už byla načtena. Vzhledem k tomu, že tento přístup zahrnuje samostatný požadavek na databázi, nedoporučuje se pro webové aplikace, což by mělo minimalizovat počet odezv databáze provedených na požadavek.
Opožděné načítání je funkce, která automaticky načítá související data, protože na ni aplikace odkazuje. EF Core přidala podporu opožděných načítání ve verzi 2.1. Opožděné načítání není ve výchozím nastavení povolené a vyžaduje instalaci Microsoft.EntityFrameworkCore.Proxies. Stejně jako u explicitního načítání by se mělo u webových aplikací obvykle zakázat opožděné načítání, protože jeho použití povede k dalším databázovým dotazům provedeným v rámci jednotlivých webových požadavků. Režie způsobená opožděným načítáním bohužel často není v době vývoje nepoznaná, když je latence malá a často jsou datové sady používané pro testování malé. V produkčním prostředí ale s více uživateli, větším objemem dat a větší latencí můžou další požadavky na databázi často vést k nízkému výkonu webových aplikací, které často využívají opožděné načítání.
Vyhněte se opožděnému načítání entit ve webových aplikacích
Při zkoumání skutečných databázových dotazů, které provádí, je vhodné otestovat aplikaci. Za určitých okolností může EF Core vytvářet mnohem více dotazů nebo nákladnější dotaz, než je pro aplikaci optimální. Jeden takový problém je známý jako kartézská exploze. Tým EF Core zpřístupní metodu AsSplitQuery jako jeden z několika způsobů ladění chování modulu runtime.
Zapouzdření dat
EF Core podporuje několik funkcí, které vašemu modelu umožňují správně zapouzdřovat jeho stav. Běžným problémem v doménových modelech je, že zpřístupňují vlastnosti navigace v kolekci jako veřejně přístupné typy seznamů. Tento problém umožňuje každému spolupracovníku manipulovat s obsahem těchto typů kolekcí, což může obejít důležitá obchodní pravidla související s kolekcí, případně ponechat objekt v neplatném stavu. Řešením tohoto problému je zveřejnit přístup jen pro čtení pro související kolekce a explicitně poskytnout metody definující způsoby, kterými s nimi můžou klienti manipulovat, jako v tomto příkladu:
public class Basket : BaseEntity
{
public string BuyerId { get; set; }
private readonly List<BasketItem> _items = new List<BasketItem>();
public IReadOnlyCollection<BasketItem> Items => _items.AsReadOnly();
public void AddItem(int catalogItemId, decimal unitPrice, int quantity = 1)
{
var existingItem = Items.FirstOrDefault(i => i.CatalogItemId == catalogItemId);
if (existingItem == null)
{
_items.Add(new BasketItem()
{
CatalogItemId = catalogItemId,
Quantity = quantity,
UnitPrice = unitPrice
});
}
else existingItem.Quantity += quantity;
}
}
Tento typ entity nezpřístupňuje veřejnou List nebo ICollection vlastnost, ale místo toho zveřejňuje IReadOnlyCollection typ, který zabalí základní typ seznamu. Při použití tohoto vzoru můžete u entity Framework Core označit použití backingového pole, například takto:
private void ConfigureBasket(EntityTypeBuilder<Basket> builder)
{
var navigation = builder.Metadata.FindNavigation(nameof(Basket.Items));
navigation.SetPropertyAccessMode(PropertyAccessMode.Field);
}
Dalším způsobem, jak můžete vylepšit doménový model, je použití hodnotových objektů pro typy, které nemají identitu a které jsou pouze rozlišují jejich vlastnostmi. Použití takových typů jako vlastností entit vám může pomoct udržet logiku specifickou pro objekt hodnoty, do kterého patří, a vyhnout se duplicitní logice mezi více entitami, které používají stejný koncept. V Entity Framework Core můžete zachovat objekty hodnot ve stejné tabulce jako vlastnící entitu tak, že nakonfigurujete typ jako vlastněnou entitu, například takto:
private void ConfigureOrder(EntityTypeBuilder<Order> builder)
{
builder.OwnsOne(o => o.ShipToAddress);
}
V tomto příkladu ShipToAddress je vlastnost typu Address.
Address je objekt hodnoty s několika vlastnostmi, například Street a City. EF Core mapuje Order objekt na jeho tabulku s jedním sloupcem na Address vlastnost a předponou názvu každého sloupce názvem vlastnosti. V tomto příkladu Order by tabulka obsahovala sloupce jako ShipToAddress_Street a ShipToAddress_City. V případě potřeby je také možné ukládat vlastněné typy do samostatných tabulek.
Přečtěte si další informace o podpoře vlastněných entit v EF Core.
Odolná připojení
Externí prostředky, jako jsou databáze SQL, můžou být někdy nedostupné. V případě dočasné nedostupnosti můžou aplikace použít logiku opakování, aby se zabránilo vyvolání výjimky. Tato technika se běžně označuje jako odolnost připojení. Vlastní opakování můžete implementovat s exponenciální technikou zpětného odvrácení tím, že se pokusíte opakovat s exponenciálním zvýšením doby čekání, dokud se nedosáhne maximálního počtu opakování. Tato technika zahrnuje skutečnost, že cloudové prostředky můžou být občas nedostupné po krátkou dobu, což vede k selhání některých požadavků.
Pro Azure SQL DB už Entity Framework Core poskytuje odolnost interního připojení k databázi a logiku opakování. Pokud ale chcete mít odolná připojení EF Core, musíte pro každé připojení DbContext povolit strategii provádění entity Framework.
Například následující kód na úrovni připojení EF Core umožňuje odolná připojení SQL, která se budou opakovat, pokud se připojení nezdaří.
builder.Services.AddDbContext<OrderingContext>(options =>
{
options.UseSqlServer(builder.Configuration["ConnectionString"],
sqlServerOptionsAction: sqlOptions =>
{
sqlOptions.EnableRetryOnFailure(
maxRetryCount: 5,
maxRetryDelay: TimeSpan.FromSeconds(30),
errorNumbersToAdd: null);
}
);
});
Strategie provádění a explicitní transakce pomocí BeginTransaction a více DbContexts
Pokud se v připojeních EF Core povolí opakování, každá operace, kterou provádíte pomocí EF Core, se stane vlastní retryable operací. Každý dotaz a každé volání SaveChangesAsync se bude opakovat jako jednotka, pokud dojde k přechodnému selhání.
Pokud však váš kód inicializuje transakci pomocí BeginTransaction, definujete vlastní skupinu operací, které je třeba považovat za jednotku; vše uvnitř transakce se musí vrátit zpět, pokud dojde k selhání. Pokud se pokusíte tuto transakci spustit při použití strategie provádění EF (zásady opakování), zobrazí se výjimka podobná následující. Do ní zahrnete několik SaveChangesAsync z více dbContextů.
System.InvalidOperationException: Nakonfigurovaná strategie SqlServerRetryingExecutionStrategy provádění nepodporuje transakce iniciované uživatelem. Použijte strategii provádění vrácenou DbContext.Database.CreateExecutionStrategy() ke spuštění všech operací v transakci jako opakovatelnou jednotku.
Řešením je ručně vyvolat strategii provádění EF s delegátem představujícím vše, co je potřeba provést. Pokud dojde k přechodnému selhání, strategie provádění znovu vyvolá delegáta. Následující kód ukazuje, jak tento přístup implementovat:
// Use of an EF Core resiliency strategy when using multiple DbContexts
// within an explicit transaction
// See:
// https://learn.microsoft.com/ef/core/miscellaneous/connection-resiliency
var strategy = _catalogContext.Database.CreateExecutionStrategy();
await strategy.ExecuteAsync(async () =>
{
// Achieving atomicity between original Catalog database operation and the
// IntegrationEventLog thanks to a local transaction
using (var transaction = _catalogContext.Database.BeginTransaction())
{
_catalogContext.CatalogItems.Update(catalogItem);
await _catalogContext.SaveChangesAsync();
// Save to EventLog only if product price changed
if (raiseProductPriceChangedEvent)
{
await _integrationEventLogService.SaveEventAsync(priceChangedEvent);
transaction.Commit();
}
}
});
První DbContext je _catalogContext a druhý DbContext je uvnitř objektu _integrationEventLogService . Nakonec se akce Potvrzení provede více dbContexts a použije strategii provádění EF.
Reference – Entity Framework Core
- Dokumentace k EF Corehttps://learn.microsoft.com/ef/
- EF Core: Související datahttps://learn.microsoft.com/ef/core/querying/related-data
- Vyhněte se opožděnému načítání entit v aplikacích ASPNEThttps://ardalis.com/avoid-lazy-loading-entities-in-asp-net-applications
EF Core nebo micro-ORM?
I když je EF Core skvělou volbou pro správu trvalosti a pro většinu případů zapouzdřuje podrobnosti databáze od vývojářů aplikací, není to jediná volba. Další oblíbenou opensourcovou alternativou je Dapper, tzv. mikro-ORM. Mikro-ORM je jednoduchý, méně plnohodnotný nástroj pro mapování objektů na datové struktury. V případě Dapperu se jeho cíle návrhu zaměřují na výkon, a ne na úplné zapouzdření podkladových dotazů, které používá k načítání a aktualizaci dat. Vzhledem k tomu, že ne abstrahuje SQL od vývojáře, Dapper je "blíž k kovu", a umožňuje vývojářům psát přesné dotazy, které chtějí použít pro danou operaci přístupu k datům.
EF Core má dvě významné funkce, které jsou oddělené od Dapperu, ale také přidávají k režii na výkon. První je překlad z výrazů LINQ do SQL. Tyto překlady se ukládají do mezipaměti, ale i tak jsou režijní náklady při jejich prvním provedení. Druhým je sledování změn u entit (aby bylo možné vygenerovat efektivní aktualizační příkazy). Toto chování je možné vypnout pro konkrétní dotazy pomocí AsNoTracking rozšíření. EF Core také generuje dotazy SQL, které jsou obvykle velmi efektivní a v každém případě dokonale přijatelné z hlediska výkonu, ale pokud potřebujete přesnou kontrolu nad přesným dotazem, který se má provést, můžete předat vlastní SQL (nebo spustit uloženou proceduru) také pomocí EF Core. V tomto případě Dapper stále převýší EF Core, ale jen velmi mírně. Aktuální data srovnávacího testu výkonu pro řadu metod přístupu k datům najdete na webu Dapperu.
Pokud chcete zjistit, jak se syntaxe dapperu liší od EF Core, zvažte tyto dvě verze stejné metody pro načtení seznamu položek:
// EF Core
private readonly CatalogContext _context;
public async Task<IEnumerable<CatalogType>> GetCatalogTypes()
{
return await _context.CatalogTypes.ToListAsync();
}
// Dapper
private readonly SqlConnection _conn;
public async Task<IEnumerable<CatalogType>> GetCatalogTypesWithDapper()
{
return await _conn.QueryAsync<CatalogType>("SELECT * FROM CatalogType");
}
Pokud potřebujete pomocí Dapperu vytvářet složitější objektové grafy, musíte napsat přidružené dotazy sami (na rozdíl od přidání zahrnutí jako v EF Core). Tato funkce se podporuje prostřednictvím různých syntaxí, včetně funkce s názvem Více mapování, která umožňuje namapovat jednotlivé řádky na více mapovaných objektů. Například při zadání třídy Post s vlastností Vlastník typu Uživatel by následující SQL vrátil všechna potřebná data:
select * from #Posts p
left join #Users u on u.Id = p.OwnerId
Order by p.Id
Každý vrácený řádek obsahuje data User i Post. Vzhledem k tomu, že data uživatele by měla být připojena k datům Post prostřednictvím vlastnosti Vlastník, použije se následující funkce:
(post, user) => { post.Owner = user; return post; }
Úplný výpis kódu pro vrácení kolekce příspěvků s vlastností vlastníka naplněnými přidruženými uživatelskými daty:
var sql = @"select * from #Posts p
left join #Users u on u.Id = p.OwnerId
Order by p.Id";
var data = connection.Query<Post, User, Post>(sql,
(post, user) => { post.Owner = user; return post;});
Protože nabízí méně zapouzdření, Dapper vyžaduje, aby vývojáři věděli více o tom, jak se jejich data ukládají, jak je efektivně dotazovat, a napsat další kód, který ho načte. Když se model změní, nemusíte jednoduše vytvářet novou migraci (jinou funkci EF Core) nebo aktualizovat informace o mapování na jednom místě v dbContextu, musí se aktualizovat každý ovlivněný dotaz. Tyto dotazy nemají žádné záruky doby kompilace, takže se můžou přerušit v době běhu v reakci na změny modelu nebo databáze, což ztěžuje rychlé zjištění chyb. Ve výměně za tyto kompromisy nabízí Dapper extrémně rychlý výkon.
U většiny aplikací a většiny částí téměř všech aplikací nabízí EF Core přijatelný výkon. Výhody produktivity vývojářů proto pravděpodobně převáží nad režií na výkon. U dotazů, které můžou těžit z ukládání do mezipaměti, se skutečný dotaz může spouštět jenom malé procento času, což z důvodu relativně malých rozdílů mezi výkonem dotazů nabít.
SQL nebo NoSQL
Relační databáze, jako je SQL Server, tradičně dominují marketplace pro trvalé úložiště dat, ale nejsou jediným dostupným řešením. Databáze NoSQL, jako je MongoDB , nabízejí jiný přístup k ukládání objektů. Místo mapování objektů na tabulky a řádky je další možností serializovat celý graf objektu a uložit výsledek. Výhody tohoto přístupu, aspoň zpočátku, jsou jednoduchost a výkon. Je jednodušší uložit jeden serializovaný objekt s klíčem než rozložit objekt do mnoha tabulek s relacemi a aktualizovat řádky, které se mohly změnit od posledního načtení objektu z databáze. Podobně je načítání a deserializace jednoho objektu z úložiště založeného na klíči obvykle mnohem rychlejší a jednodušší než složité spojení nebo více databázových dotazů potřebných k úplnému vytvoření stejného objektu z relační databáze. Nedostatek zámků nebo transakcí nebo pevného schématu také činí databáze NoSQL dosažitelné škálováním napříč mnoha počítači, což podporuje velmi velké datové sady.
Na druhou stranu mají databáze NoSQL (jak se obvykle volají) své nevýhody. Relační databáze používají normalizaci k vynucení konzistence a zabránění duplikování dat. Tento přístup zmenšuje celkovou velikost databáze a zajišťuje, aby byly aktualizace sdílených dat dostupné okamžitě v celé databázi. V relační databázi může tabulka Adresa odkazovat na tabulku Země podle ID, aby v případě změny názvu země/oblasti mohly být záznamy adres přínosné z aktualizace, aniž by se musely aktualizovat. V databázi NoSQL, Adresa a její přidružená země však může být serializována jako součást mnoha uložených objektů. Aktualizace názvu země nebo oblasti by vyžadovala, aby se všechny takové objekty aktualizovaly, a ne jeden řádek. Relační databáze mohou také zajistit relační integritu vynucením pravidel, jako jsou cizí klíče. Databáze NoSQL obvykle nenabízejí taková omezení jejich dat.
Další složitost databází NoSQL se musí zabývat správou verzí. Když se vlastnosti objektu změní, nemusí být možné deserializovat z předchozích verzí, které byly uloženy. Proto musí být všechny existující objekty, které mají serializovanou (předchozí) verzi objektu, aktualizovány tak, aby odpovídaly jeho novému schématu. Tento přístup se koncepčně neliší od relační databáze, kde změny schématu někdy vyžadují aktualizace skriptů nebo aktualizace mapování. Počet položek, které je potřeba upravit, je však v přístupu NoSQL často mnohem větší, protože existuje více duplicit dat.
V databázích NoSQL je možné ukládat více verzí objektů, což obvykle nepodporuje relační databáze s pevným schématem. V tomto případě ale kód aplikace bude muset zohlednit existenci předchozích verzí objektů a přidat tak další složitost.
Databáze NoSQL obvykle nevynucují acid, což znamená, že mají výhody výkonu i škálovatelnosti oproti relačním databázím. Jsou vhodné pro extrémně velké datové sady a objekty, které nejsou vhodné pro ukládání v normalizovaných strukturách tabulek. Neexistuje žádný důvod, proč jedna aplikace nemůže využívat relační databáze i databáze NoSQL, přičemž každá z nich je nejvhodnější.
Azure Cosmos DB – databázový systém
Azure Cosmos DB je plně spravovaná databázová služba NoSQL, která nabízí cloudové úložiště dat bez schématu. Azure Cosmos DB je sestavená pro rychlý a předvídatelný výkon, vysokou dostupnost, elastické škálování a globální distribuci. Navzdory tomu, že je databáze NoSQL, můžou vývojáři u dat JSON používat bohaté a známé funkce dotazů SQL. Všechny prostředky ve službě Azure Cosmos DB se ukládají jako dokumenty JSON. Prostředky se spravují jako položky, což jsou dokumenty obsahující metadata a informační kanály, což jsou kolekce položek. Obrázek 8–2 znázorňuje vztah mezi různými prostředky Azure Cosmos DB.
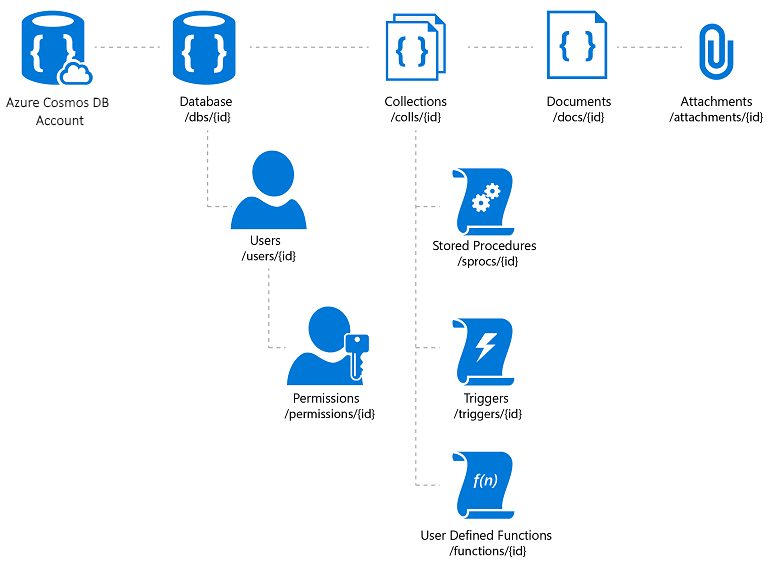
Obrázek 8–2 Organizace prostředků Azure Cosmos DB
Dotazovací jazyk Azure Cosmos DB je jednoduché, ale výkonné rozhraní pro dotazování dokumentů JSON. Tento jazyk podporuje podmnožinu gramatiky ANSI SQL a přidává těsnou integraci s javascriptovými objekty, poli, vytvářením objektů a voláním funkcí.
Reference – Azure Cosmos DB
- Úvod do služby Azure Cosmos DB https://learn.microsoft.com/azure/cosmos-db/introduction
Další možnosti trvalosti
Kromě možností relačního úložiště a úložiště NoSQL můžou aplikace ASP.NET Core používat Azure Storage k ukládání různých formátů dat a souborů v cloudové škálovatelné podobě. Azure Storage je široce škálovatelný, takže můžete začít ukládat malé objemy dat a vertikálně navýšit kapacitu a ukládat stovky nebo terabajty, pokud to vaše aplikace vyžaduje. Azure Storage podporuje čtyři druhy dat:
Blob Storage pro nestrukturované textové nebo binární úložiště, označované také jako úložiště objektů.
Table Storage pro strukturované datové sady přístupné prostřednictvím klíčů řádků.
Queue Storage pro spolehlivé zasílání zpráv založených na frontách.
File Storage pro sdílený přístup k souborům mezi virtuálními počítači Azure a místními aplikacemi.
Reference – Azure Storage
- Úvod ke službě Azure Storage https://learn.microsoft.com/azure/storage/common/storage-introduction
Ukládání do mezipaměti
Vewebových Jedním ze způsobů, jak tuto funkci dosáhnout, je omezit počet externích volání, které musí server provést k dokončení požadavku. Ukládání do mezipaměti zahrnuje ukládání kopie dat na server (nebo jiné úložiště dat, které se snadněji dotazuje než zdroj dat). Webové aplikace a zejména tradiční webové aplikace, které nejsou spa, potřebují vytvořit celé uživatelské rozhraní s každým požadavkem. Tento přístup často zahrnuje opakované provádění mnoha stejných databázových dotazů z jednoho požadavku uživatele na další. Ve většině případů se tato data mění zřídka, takže existuje malý důvod, proč je neustále požadovat z databáze. ASP.NET Core podporuje ukládání odpovědí do mezipaměti, ukládání celých stránek do mezipaměti a ukládání dat do mezipaměti, což podporuje podrobnější chování ukládání do mezipaměti.
Při implementaci ukládání do mezipaměti je důležité mít na paměti oddělení obav. Vyhněte se implementaci logiky ukládání do mezipaměti v logice přístupu k datům nebo v uživatelském rozhraní. Místo toho zapouzdřte ukládání do mezipaměti ve svých vlastních třídách a použijte konfiguraci ke správě jeho chování. Tento přístup se řídí principy otevřené/uzavřené a izolované odpovědnosti a usnadní vám správu způsobu používání ukládání do mezipaměti v aplikaci, jak roste.
ukládání odpovědí ASP.NET Core do mezipaměti
ASP.NET Core podporuje dvě úrovně ukládání odpovědí do mezipaměti. První úroveň nic na serveru neukládá do mezipaměti, ale přidává hlavičky HTTP, které dávají klientům a proxy serverům pokyn k ukládání odpovědí do mezipaměti. Tato funkce se implementuje přidáním atributu ResponseCache do jednotlivých kontrolerů nebo akcí:
[ResponseCache(Duration = 60)]
public IActionResult Contact()
{
ViewData["Message"] = "Your contact page.";
return View();
}
V předchozím příkladu se do odpovědi přidá následující hlavička s pokynem klientům, aby výsledek uložili do mezipaměti po dobu až 60 sekund.
Cache-Control: public,max-age=60
Pokud chcete do aplikace přidat ukládání do mezipaměti na straně serveru, musíte odkazovat na Microsoft.AspNetCore.ResponseCaching balíček NuGet a pak přidat middleware pro ukládání odpovědí do mezipaměti. Tento middleware se konfiguruje se službami a middlewarem během spouštění aplikace:
builder.Services.AddResponseCaching();
// other code omitted, including building the app
app.UseResponseCaching();
Middleware pro ukládání odpovědí do mezipaměti automaticky ukládá odpovědi do mezipaměti na základě sady podmínek, které můžete přizpůsobit. Ve výchozím nastavení se ukládá do mezipaměti pouze 200 odpovědí (OK) požadovaných prostřednictvím metod GET nebo HEAD. Kromě toho musí požadavky obsahovat odpověď s ovládacím prvkem Cache-Control: veřejná hlavička a nesmí obsahovat hlavičky pro autorizaci nebo set-cookie. Podívejte se na úplný seznam podmínek ukládání do mezipaměti, které používá middleware pro ukládání odpovědí do mezipaměti.
Ukládání dat do mezipaměti
Místo (nebo kromě) ukládání úplných webových odpovědí do mezipaměti můžete ukládat výsledky jednotlivých datových dotazů do mezipaměti. Pro tuto funkci můžete použít ukládání do mezipaměti paměti na webovém serveru nebo použít distribuovanou mezipaměť. V této části se dozvíte, jak implementovat ukládání do mezipaměti v paměti.
Přidejte podporu ukládání do mezipaměti (nebo distribuované) ukládání do mezipaměti pomocí následujícího kódu:
builder.Services.AddMemoryCache();
builder.Services.AddMvc();
Nezapomeňte také přidat Microsoft.Extensions.Caching.Memory balíček NuGet.
Po přidání služby si vyžádáte IMemoryCache prostřednictvím injektáže závislostí všude, kde potřebujete přístup k mezipaměti. V tomto příkladu CachedCatalogService se používá vzor návrhu proxy (nebo dekorátoru) poskytnutím alternativní implementace ICatalogService , která řídí přístup k podkladové CatalogService implementaci (nebo k němu přidává chování).
public class CachedCatalogService : ICatalogService
{
private readonly IMemoryCache _cache;
private readonly CatalogService _catalogService;
private static readonly string _brandsKey = "brands";
private static readonly string _typesKey = "types";
private static readonly TimeSpan _defaultCacheDuration = TimeSpan.FromSeconds(30);
public CachedCatalogService(
IMemoryCache cache,
CatalogService catalogService)
{
_cache = cache;
_catalogService = catalogService;
}
public async Task<IEnumerable<SelectListItem>> GetBrands()
{
return await _cache.GetOrCreateAsync(_brandsKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetBrands();
});
}
public async Task<Catalog> GetCatalogItems(int pageIndex, int itemsPage, int? brandID, int? typeId)
{
string cacheKey = $"items-{pageIndex}-{itemsPage}-{brandID}-{typeId}";
return await _cache.GetOrCreateAsync(cacheKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetCatalogItems(pageIndex, itemsPage, brandID, typeId);
});
}
public async Task<IEnumerable<SelectListItem>> GetTypes()
{
return await _cache.GetOrCreateAsync(_typesKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetTypes();
});
}
}
Pokud chcete aplikaci nakonfigurovat tak, aby používala verzi služby uloženou v mezipaměti, ale přesto službě umožnit získat instanci CatalogService, kterou potřebuje v jeho konstruktoru, přidejte do Program.cs následující řádky:
builder.Services.AddMemoryCache();
builder.Services.AddScoped<ICatalogService, CachedCatalogService>();
builder.Services.AddScoped<CatalogService>();
Při použití tohoto kódu se volání databáze pro načtení dat katalogu provede pouze jednou za minutu, a ne na každém požadavku. V závislosti na provozu na web to může mít významný vliv na počet dotazů provedených v databázi a průměrná doba načítání stránky domovské stránky, která aktuálně závisí na všech třech dotazech vystavených touto službou.
Problém, ke kterému dochází při implementaci ukládání do mezipaměti, jsou zastaralá data – to znamená, že data, která se změnila ve zdroji, ale zastaralá verze zůstává v mezipaměti. Jednoduchým způsobem, jak tento problém zmírnit, je použít dobu trvání malé mezipaměti, protože pro zaneprázdněnou aplikaci existuje omezená další výhoda pro rozšíření dat o délce, která se ukládá do mezipaměti. Představte si například stránku, která vytváří dotaz na jednoúčelovou databázi a požaduje se 10krát za sekundu. Pokud je tato stránka uložená do mezipaměti po dobu jedné minuty, výsledkem bude počet databázových dotazů provedených za minutu, aby se snížil z 600 na 1, což znamená snížení o 99,8 %. Pokud by se místo doby trvání mezipaměti provedla jedna hodina, celkové snížení by bylo 99,997 %, ale teď se výrazně zvyšuje pravděpodobnost a potenciální věk zastaralých dat.
Dalším přístupem je proaktivně odebrat položky mezipaměti při aktualizaci dat, která obsahují. Všechny jednotlivé položky lze odebrat, pokud je jeho klíč známý:
_cache.Remove(cacheKey);
Pokud vaše aplikace zpřístupňuje funkce pro aktualizaci položek, které ukládá do mezipaměti, můžete odebrat odpovídající položky mezipaměti v kódu, který provádí aktualizace. Někdy může existovat mnoho různých položek, které závisí na konkrétní sadě dat. V takovém případě může být užitečné vytvořit závislosti mezi položkami mezipaměti pomocí CancellationChangeToken. Pokud máte CancellationChangeToken, můžete vypršet více položek mezipaměti najednou zrušením tokenu.
// configure CancellationToken and add entry to cache
var cts = new CancellationTokenSource();
_cache.Set("cts", cts);
_cache.Set(cacheKey, itemToCache, new CancellationChangeToken(cts.Token));
// elsewhere, expire the cache by cancelling the token\
_cache.Get<CancellationTokenSource>("cts").Cancel();
Ukládání do mezipaměti může výrazně zlepšit výkon webových stránek, které opakovaně požadují stejné hodnoty z databáze. Před použitím ukládání do mezipaměti nezapomeňte měřit přístup k datům a výkon stránky a použít ukládání do mezipaměti jenom tam, kde vidíte potřebu zlepšení. Ukládání do mezipaměti spotřebovává prostředky paměti webového serveru a zvyšuje složitost aplikace, takže je důležité, abyste tuto techniku neoptimalizovali předčasně.
Získávání dat do BlazorWebAssembly aplikací
Pokud vytváříte aplikace, které používají Blazor Server, můžete použít Entity Framework a další technologie přímého přístupu k datům, jak jsou zatím popsány v této kapitole. Při vytváření BlazorWebAssembly aplikací, jako jsou jiné architektury SPA, ale budete potřebovat jinou strategii pro přístup k datům. Tyto aplikace obvykle přistupují k datům a komunikují se serverem prostřednictvím koncových bodů webového rozhraní API.
Pokud jsou data nebo prováděné operace citlivé, nezapomeňte si projít část věnovanou zabezpečení v předchozí kapitole a chránit vaše rozhraní API před neoprávněným přístupem.
Příklad BlazorWebAssembly aplikace najdete v referenční aplikaci eShopOnWeb v projektu BlazorAdmin. Tento projekt je hostovaný v rámci webového projektu eShopOnWeb a umožňuje uživatelům ve skupině Administrators spravovat položky v obchodě. Snímek obrazovky aplikace můžete vidět na obrázku 8–3.
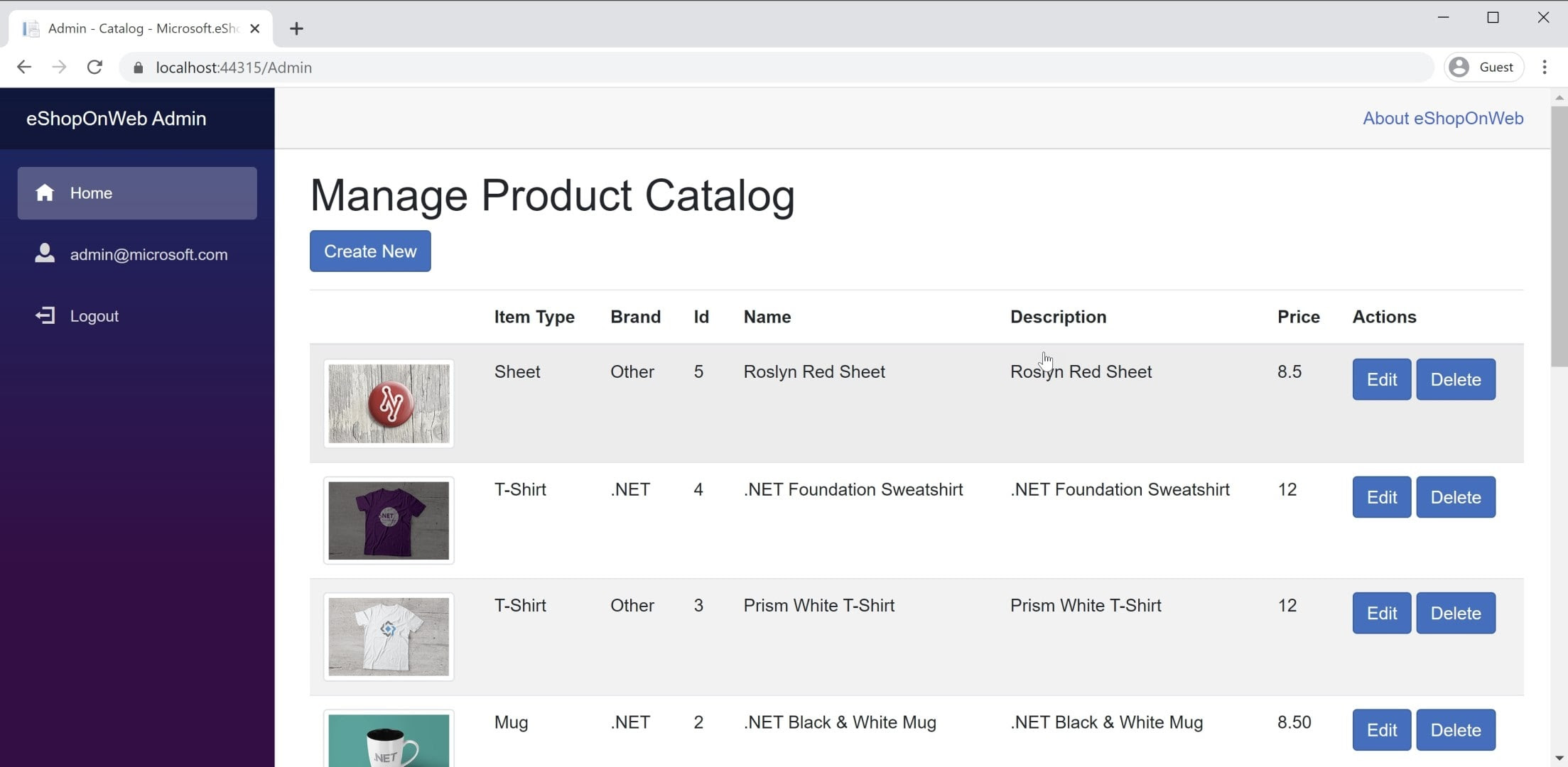
Obrázek 8-3 Snímek obrazovky správce katalogu eShopOnWeb
Při načítání dat z webových rozhraní API v aplikaci BlazorWebAssembly stačí použít instanci HttpClient stejně jako v libovolné aplikaci .NET. Základním postupem je vytvoření požadavku k odeslání (v případě potřeby, obvykle pro požadavky POST nebo PUT), čekání na samotný požadavek, ověření stavového kódu a deserializace odpovědi. Pokud budete na danou sadu rozhraní API vytvářet mnoho požadavků, je vhodné zapouzdřovat rozhraní API a centrálně nakonfigurovat HttpClient základní adresu. Pokud potřebujete některá z těchto nastavení mezi prostředími upravit, můžete změny provést na jednom místě. Do služby Program.Mainbyste měli přidat podporu pro tuto službu:
builder.Services.AddScoped(sp => new HttpClient
{
BaseAddress = new Uri(builder.HostEnvironment.BaseAddress)
});
Pokud potřebujete bezpečně přistupovat ke službám, měli byste získat přístup k zabezpečenému tokenu a nakonfigurovat ho HttpClient tak, aby předával tento token jako hlavičku ověřování s každým požadavkem:
_httpClient.DefaultRequestHeaders.Authorization =
new AuthenticationHeaderValue("Bearer", token);
Tuto aktivitu je možné provést z jakékoli komponenty, která HttpClient je do ní vložena, za předpokladu, že HttpClient nebyla přidána do služeb aplikace po Transient celou dobu života. Každý odkaz na HttpClient aplikaci odkazuje na stejnou instanci, takže se změní v jedné komponentě, která prochází celou aplikací. Dobrým místem k provedení této kontroly ověřování (následované zadáním tokenu) je sdílená komponenta, jako je hlavní navigace webu. Přečtěte si další informace o tomto přístupu v BlazorAdmin projektu v referenční aplikaci eShopOnWeb.
Jednou z výhod tradičních aktualizací javascriptových BlazorWebAssembly služeb je, že nemusíte uchovávat kopie objektů pro přenos dat synchronizované. Váš BlazorWebAssembly projekt i váš projekt webového rozhraní API můžou sdílet stejné DTO ve společném sdíleném projektu. Tento přístup eliminuje některé třecí plochy spojené s vývojem spA.
K rychlému získání dat z koncového bodu rozhraní API můžete použít integrovanou pomocnou metodu GetFromJsonAsync. Existují podobné metody pro POST, PUT atd. Následující příklad ukazuje, jak získat Položku CatalogItem z koncového bodu rozhraní API pomocí nakonfigurovaného HttpClient v BlazorWebAssembly aplikaci:
var item = await _httpClient.GetFromJsonAsync<CatalogItem>($"catalog-items/{id}");
Jakmile potřebujete data, obvykle budete sledovat změny místně. Pokud chcete aktualizovat back-endové úložiště dat, budete pro tento účel volat další webová rozhraní API.
Odkazy – Blazor data
- Volání webového rozhraní API z ASP.NET Core Blazorhttps://learn.microsoft.com/aspnet/core/blazor/call-web-api
Spolupracujte s námi na GitHubu
Zdroj tohoto obsahu najdete na GitHubu, kde můžete také vytvářet a kontrolovat problémy a žádosti o přijetí změn. Další informace najdete v našem průvodci pro přispěvatele.