Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
V tomto článku se dozvíte, jak vytvořit vlastní fondy Apache Sparku v Microsoft Fabric pro analytické úlohy. Fondy Apache Spark umožňují vytvářet přizpůsobená výpočetní prostředí na základě vašich požadavků, abyste získali optimální výkon a využití prostředků.
Zadejte minimální a maximální počet uzlů pro automatické škálování. Systém přidává a odebírá uzly v reakci na změny ve výpočetních potřebách vaší úlohy, čímž je škálování efektivní a výkon se zvyšuje. Fondy Sparku upravují počet exekutorů automaticky, takže je nemusíte nastavovat ručně. Systém mění počet exekutorů podle objemu dat a potřeb výpočetních úloh, abyste se mohli soustředit na své pracovní úkoly místo ladění výkonu a správy prostředků.
Návod
Při konfiguraci fondů Sparku je velikost uzlu určena jednotkami kapacity (CU), které představují výpočetní kapacitu přiřazenou jednotlivým uzlům. Další informace o velikostech uzlů a CU najdete v části Možnosti velikosti uzlů v této příručce.
Požadavky
Pokud chcete vytvořit vlastní fond Sparku, ujistěte se, že máte přístup správce k pracovnímu prostoru. Správce kapacity povolí možnost Vlastní fondy pracovních prostorů v části Výpočty Sparku nastavení správce kapacity. Další informace naleznete v Nastavení výpočetních prostředků Spark pro kapacity Fabric.
Vytvořte vlastní fondy Spark
Vytvoření nebo správa fondu Sparku přidruženého k vašemu pracovnímu prostoru:
Přejděte do svého pracovního prostoru a vyberte Nastavení pracovního prostoru.
Výběrem možnosti Přípravy dat nebo Vědy rozbalte nabídku a pak vyberte Nastavení Sparku.
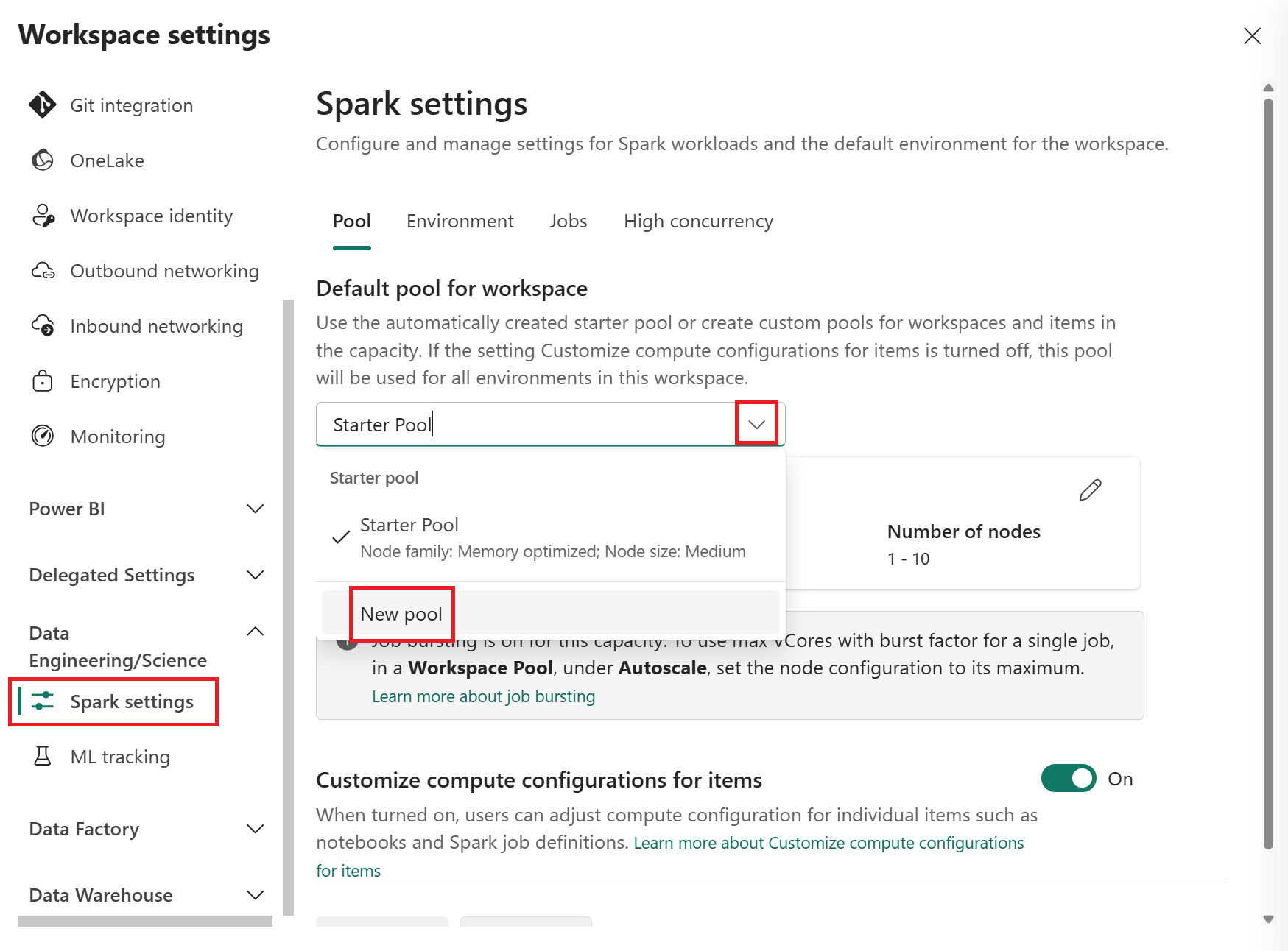
Vyberte možnost Nový fond . Na obrazovce Vytvořit fond pojmenujte Spark pool. Zvolte také řadu uzlů a v závislosti na požadavcích na výpočetní prostředky pro vaše úlohy vyberte velikost uzlu z dostupných velikostí (Small, Medium, Large, X-Large a XX-Large).
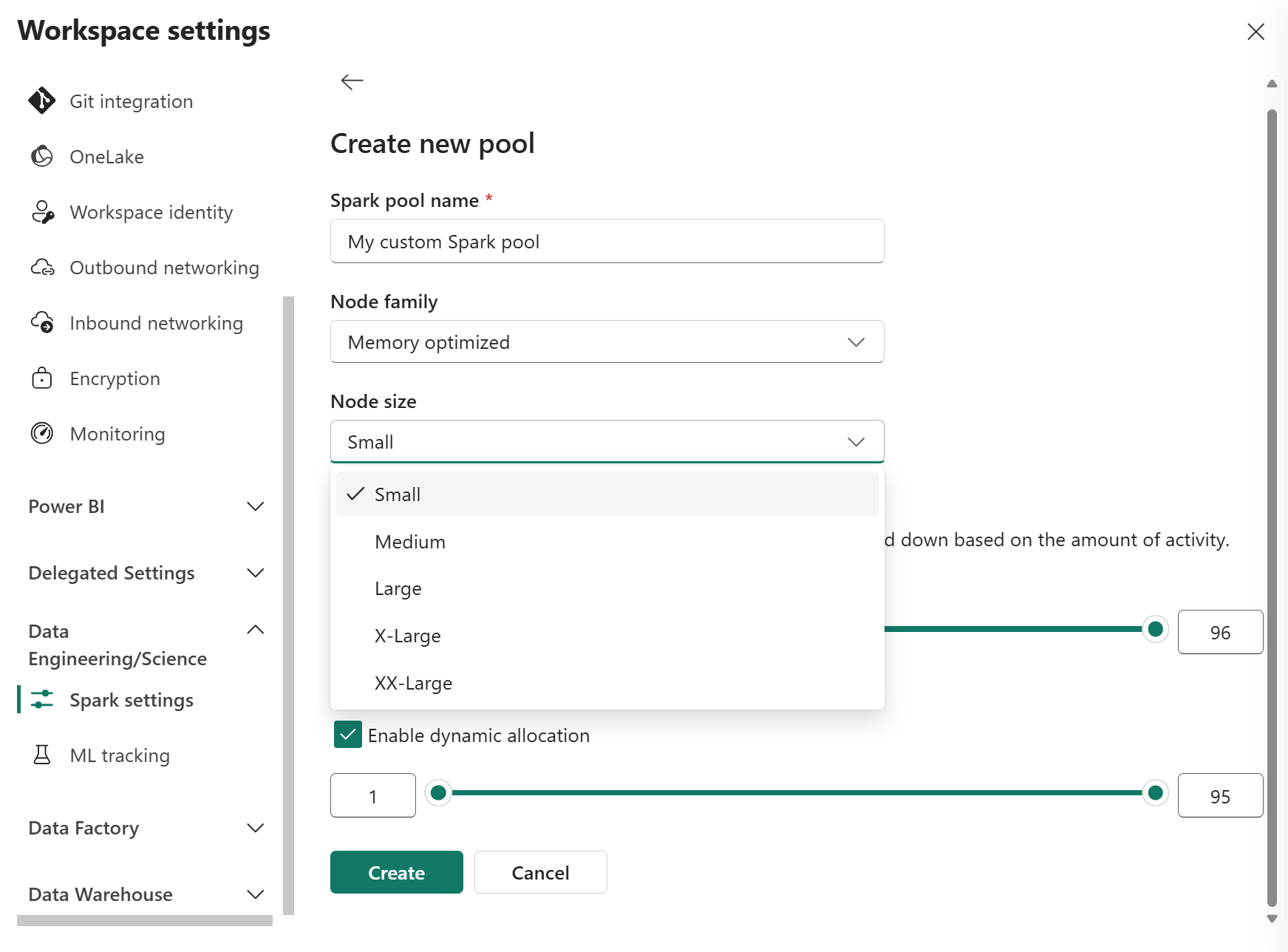
Minimální konfiguraci uzlu pro vlastní fondy můžete nastavit na 1. Vzhledem k tomu, že Fabric Spark poskytuje možnost obnovení dostupnosti pro clustery s jedním uzlem, nemusíte se obávat selhání úloh, ztráty relace při selhání nebo přeplacení výpočetních zdrojů pro menší úlohy Sparku.
Automatické škálování pro vlastní fondy Sparku můžete povolit nebo zakázat. Pokud je povolené automatické škálování, fond dynamicky získá nové uzly až do maximálního limitu uzlu určeného uživatelem a potom je po provedení úlohy vyřadí. Tato funkce zajišťuje lepší výkon úpravou prostředků na základě požadavků úlohy. Můžete upravit velikost uzlů, které se vejdou do kapacitních jednotek zakoupených jako součást SKU kapacity Fabric.
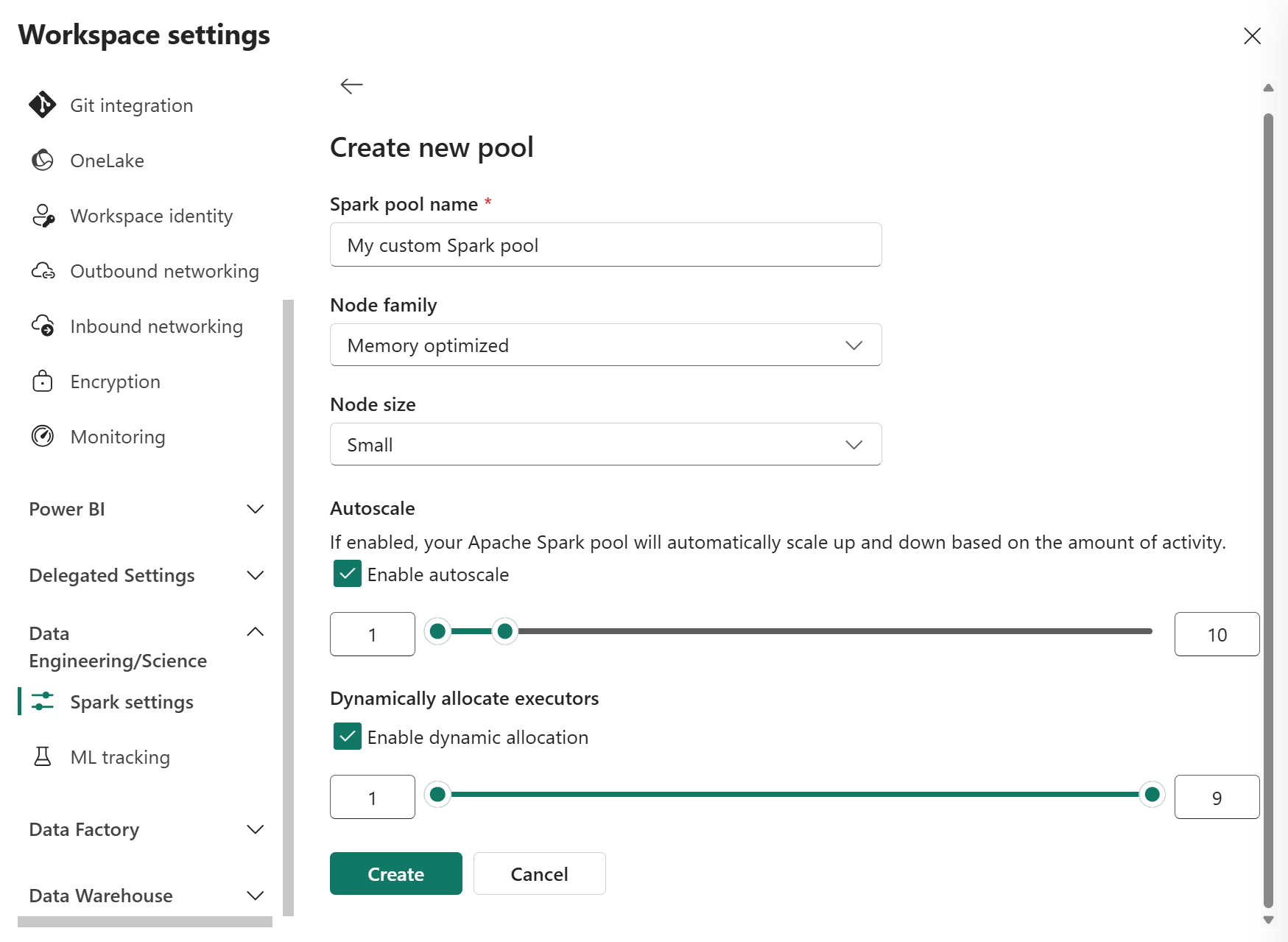
Počet exekutorů můžete upravit pomocí posuvníku. Každý exekutor je proces Sparku, který spouští úlohy a uchovává data v paměti. Zvýšení exekutorů může zlepšit paralelismus, ale také zvyšuje velikost a dobu spuštění clusteru. Můžete také povolit přidělení dynamického exekutoru pro váš fond Spark, což automaticky určuje optimální počet exekutorů v rámci maximální hranice zadané uživatelem. Tato funkce upravuje počet exekutorů na základě objemu dat, což vede ke zlepšení výkonu a využití prostředků.



Tyto vlastní fondy mají výchozí dobu automatického pozastavení 2 minuty po vypršení časového období nečinnosti. Jakmile uplyne doba automatického pozastavení, platnost relace vyprší a clustery jsou uvolněny. Účtují se vám poplatky na základě počtu uzlů a doby trvání, po kterou se používají vlastní fondy Sparku.
Poznámka:
Vlastní fondy Sparku v Microsoft Fabric aktuálně podporují maximální limit uzlu 200. Při konfiguraci automatického škálování nebo nastavení počtu ručních uzlů se ujistěte, že vaše minimální a maximální hodnoty zůstanou v rámci tohoto limitu. Překročení tohoto limitu způsobí chyby ověření během vytváření nebo aktualizace fondu.
Možnosti velikosti uzlu
Při nastavování vlastního fondu Sparku si můžete vybrat z následujících velikostí uzlů:
| Velikost uzlu | Jednotky kapacity (CU) | Paměť (GB) | Popis |
|---|---|---|---|
| Malý | 4 | 32 | Pro jednoduché úlohy vývoje a testování. |
| Středně | 8 | 64 | Pro obecné úlohy a typické operace. |
| Velké | 16 | 128 | Pro úlohy náročné na paměť nebo velké úlohy zpracování dat. |
| X-Large | 32 | 256 | Pro nejnáročnější úlohy Sparku, které potřebují významné prostředky. |
Poznámka:
Jednotka kapacity (CU) ve fondech Microsoft Fabric Spark představuje výpočetní kapacitu přiřazenou jednotlivým uzlům, nikoli skutečnou spotřebu. Jednotky kapacity se liší od virtuálních jader (Virtual Core), které se používají v prostředcích Azure založených na SQL. CU je standardním termínem pro fondy Spark ve Fabric, zatímco VCore je pro fondy SQL častější. Při určování velikosti uzlů použijte CU k určení přiřazené kapacity pro úlohy Sparku.
Související obsah
- Další informace najdete ve veřejné dokumentaci k Apache Sparku.
- Začínáme s nastavením správy pracovního prostoru Sparku v Microsoft Fabric