Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Důležité
Tato funkce je ve verzi Preview.
Prostředí Fabric Runtime poskytuje bezproblémovou integraci v ekosystému Microsoft Fabric a nabízí robustní prostředí pro projekty přípravy dat a datových věd využívajících Apache Spark.
Tento článek představuje prostředí Fabric Runtime 2.0 Public Preview, nejnovější modul runtime navržený pro výpočty velkých objemů dat v Microsoft Fabric. Zvýrazňuje klíčové funkce a komponenty, díky kterým je tato verze významným krokem vpřed pro škálovatelné analýzy a pokročilé úlohy.
Modul Fabric Runtime 2.0 obsahuje následující komponenty a upgrady navržené tak, aby zlepšily možnosti zpracování dat:
- Apache Spark 4.1
- Operační systém: Azure Linux 3.0 (Mariner 3.0)
- Java: 21
- Scala: 2.13
- Python: 3.13
- Delta Lake: 4.1
- R: 4.5.2
Důležité
Fabric Runtime 2.0 se aktualizoval na Spark 4.1, Delta Lake 4.1 a Python 3.13. Verze běhového prostředí Fabric zobrazená v portálu (Nastavení pracovního prostoru a možnost Runtime v prostředí Environment UX) se nezmění.
| Součást | Předchozí verze | Aktuální verze |
|---|---|---|
| Spark | 4.0 | 4.1 |
| Delta Lake | 4.0 | 4.1 |
| Python | 3.12 | 3.13 |

Zásadní změna: Aktualizace Pythonu vyžaduje, abyste znovu publikovali každé prostředí, které obsahuje knihovny. Dokud znovu nepublikujete, zobrazí se karty Veřejné knihovny a vlastní knihovny prázdné a úlohy Sparku, které cílí na ovlivněné prostředí, selžou s chybami "Nenalezena žádná modul" nebo "Třída nebyla nalezena".
Požadované akce
- Zaznamenejte nebo vyexportujte seznam knihoven z každého prostředí.
- Znovu přidejte knihovny a výběrem možnosti Publikovat je znovu sestavte ve Sparku 4.1.
Návod
Modul fabric Runtime 2.0 obsahuje podporu nativního prováděcího modulu, která může výrazně zvýšit výkon bez dalších nákladů. Nativní spouštěcí modul můžete povolit na úrovni prostředí, aby všechny úlohy a poznámkové bloky automaticky dědily vylepšené možnosti výkonu.
Povolení modulu runtime 2.0
Modul runtime 2.0 můžete povolit na úrovni pracovního prostoru nebo na úrovni položky prostředí. Pomocí nastavení pracovního prostoru použijte modul runtime 2.0 jako výchozí pro všechny úlohy Sparku ve vašem pracovním prostoru. Případně vytvořte položku prostředí s modulem Runtime 2.0, který se použije s konkrétními poznámkovými bloky nebo definicemi úloh Sparku, což přepíše výchozí nastavení pracovního prostoru.
Povolení modulu runtime 2.0 v nastavení pracovního prostoru
Nastavení modulu runtime 2.0 jako výchozího pro celý pracovní prostor:
Přejděte na stránku Nastavení pracovního prostoru v pracovním prostoru Fabric.
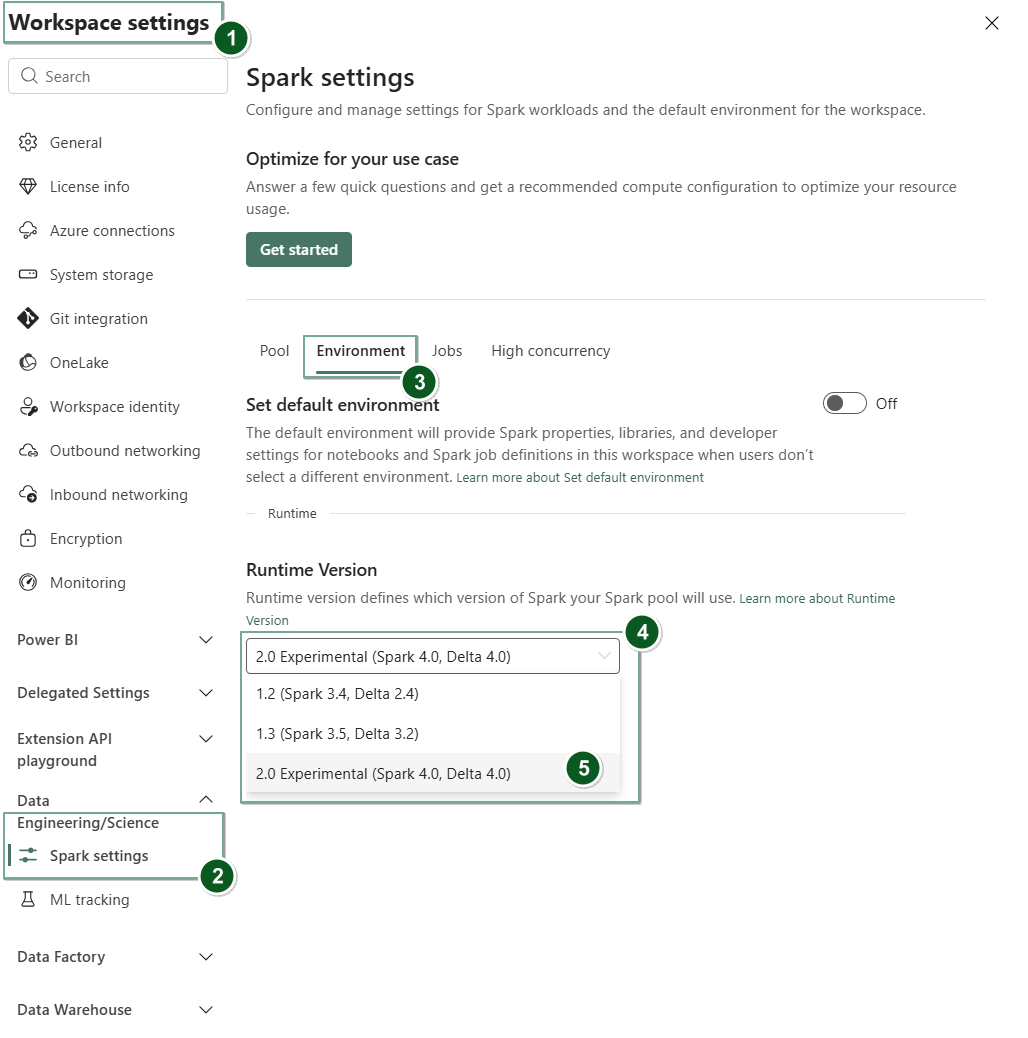
Vyberte kartu Datové inženýrství nebo věda a pak vyberte Nastavení Sparku.
Vyberte kartu Prostředí.
V rozevíracím seznamu Verze modulu runtime vyberte 2.0 Public Preview (Spark 4.1, Delta 4.1) a uložte změny.
Modul runtime 2.0 je nastavený jako výchozí modul runtime pro váš pracovní prostor.

Povolení modulu runtime 2.0 v položce prostředí
Použití modulu runtime 2.0 s konkrétními poznámkovými bloky nebo definicemi úloh Sparku:
Vytvořte novou položku prostředí nebo otevřete existující položku.
V rozevíracím seznamu Runtime vyberte 2.0 Public Preview (Spark 4.1, Delta 4.1) a uložte a publikujte provedené změny.
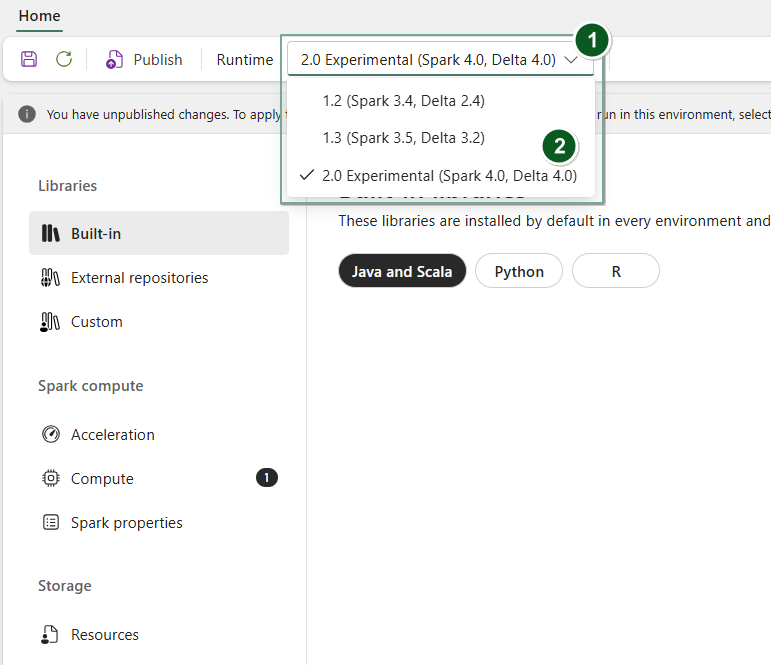
Dále můžete tuto položku prostředí použít s Poznámkovým blokem nebo definicí úlohy Spark.

Teď můžete začít experimentovat s nejnovějšími vylepšeními a funkcemi zavedenými v prostředí Fabric Runtime 2.0 (Spark 4.1 a Delta Lake 4.1).
Poznámka:
Protokol WASB pro účty Azure Storage pro obecné účely v2 (GPv2) je zastaralý. Místo toho byste měli použít nejnovější protokol ABFS pro čtení a zápis do účtů úložiště GPv2.
Veřejná ukázka
Fáze veřejné verze Preview Fabric Runtime 2.0 poskytuje přístup k novým funkcím a rozhraním API ze Sparku 4.1 i Delta Lake 4.1. Preview verze umožňuje okamžitě využít nejnovější vylepšení založené na technologii Spark a Delta a zajistit hladkou připravenost a přechod na vylepšení, jako jsou novější verze Java, Scala a Python.
Návod
Aktuální informace, podrobný seznam změn a konkrétní poznámky k verzi pro moduly runtime Fabric najdete tak, že zkontrolujete a přihlásíte se k odběru verzí a aktualizací modulů Spark Runtime.
Hlavní přednosti
Vylepšení výkonu a prováděcího modulu
Modul fabric Runtime 2.0 obsahuje nativní spouštěcí modul, který poskytuje významná vylepšení výkonu oproti opensourcovém Sparku. Modul používá vektorizované zpracování k urychlení dotazů Sparku na infrastrukturu lakehouse bez nutnosti změn kódu.
Klíčové funkce výkonu v modulu Runtime 2.0:
- Až šestkrát rychlejší: Srovnávací testy ukazují až šestkrát rychlejší výkon v porovnání s opensourcovým Sparkem v TPC-DS úlohách.
- Vektorizované zpracování CSV: Nativní prováděcí modul obsahuje vektorizovaný analyzátor CSV, který zrychluje příjem CSV a zpracování dotazů. Podpora vektorizovaného parsování JSON a strukturovaného streamování Sparku se plánuje pro budoucí aktualizace.
Pokud chcete povolit nativní výpočetní stroj, přečtěte si téma Nativní výpočetní stroj pro Fabric Data Engineering.
Apache Spark 4.1
Apache Spark 4.0 označil významný milník jako úvodní vydání v sérii 4.x, které ztělesňuje kolektivní úsilí živé opensourcové komunity. Fabric Runtime 2.0 teď běží na Apache Spark 4.1, která je založená na základech s dalšími vylepšeními.
V této verzi je Spark SQL výrazně rozšířen o výkonné nové funkce navržené tak, aby zvýšily výraznost a všestrannost pro úlohy SQL, jako je podpora datových typů VARIANT, uživatelem definované funkce SQL, proměnné relace, syntaxe kanálu a kolace řetězců. PySpark se neustále věnuje funkční šíře i celkovému vývojářskému zážitku a přináší nativní rozhraní API pro vykreslování, nové rozhraní API pro zdroje dat Pythonu, podporu uživatelsky definovaných tabulkových funkcí (UDTF) v Pythonu a sjednocenou profilaci pro uživatelem definované funkce (UDF) v PySpark spolu s mnoha dalšími vylepšeními. Strukturované streamování se vyvíjí s klíčovými doplňky, které poskytují větší kontrolu a snadné ladění, zejména zavedení rozhraní API libovolného stavu v2 pro flexibilnější správu stavu a zdroj dat o stavu pro snadnější ladění.
Úplný seznam a podrobné změny můžete zkontrolovat tady:
Poznámka:
Ve Sparku 4.x je SparkR zastaralý a v budoucí verzi může být odstraněn.
Delta Lake 4.1
Delta Lake 4.1 navazuje na milníkové vydání Delta Lake 4.0 a dále rozvíjí snahu o to, aby byl Delta Lake interoperabilní napříč formáty, snazší pro práci a výkonnější. Zahrnuje výkonné nové funkce, optimalizace výkonu a základní vylepšení pro budoucnost otevřených datových jezer.
Úplný seznam a podrobné změny zavedené v Delta Lake 3.3, 4.0 a 4.1 najdete tady:
Rozložení a optimalizace dat
Modul runtime 2.0 podporuje funkce rozložení a optimalizace dat pro tabulky Delta:
- Řazení Z: Uspořádejte data v souborech tabulky Delta podle zadaných sloupců, aby se zlepšil výkon dotazů pro filtrované dotazy.
- Liquid Clustering: Flexibilní přístup ke clusteringu, který automaticky optimalizuje rozložení dat bez ruční údržby.
- Paralelní načítání snímků Delta: Nativní prováděcí modul načte snímky tabulek Delta paralelně a zkracuje dobu spouštění dotazů u velkých tabulek.
Důležité
Specifické funkce Delta Lake 4.1 jsou experimentální a pracují jenom s prostředími Sparku, jako jsou poznámkové bloky a definice úloh Sparku. Pokud potřebujete použít stejné tabulky Delta Lake napříč několika úlohami Microsoft Fabric, nepovolujte tyto funkce. Další informace o tom, které verze protokolů a funkce jsou kompatibilní ve všech prostředích Microsoft Fabric, najdete v tématu Interoperabilita formátů tabulek Delta Lake.
Správa výpočetních prostředků v modulu runtime 2.0
Modul runtime 2.0 podporuje následující funkce správy výpočetních prostředků:
- Profily prostředků: Nakonfigurujte předdefinované přidělení prostředků pro relace Sparku tak, aby odpovídaly požadavkům úloh a kontrolovaly náklady.
- Vlastní interaktivní skupiny (Preview): Vytvořte dedikované, předem připravené skupiny Sparku, které zkracují dobu spuštění relace. Vlastní živé fondy jsou dostupné ve verzi Preview pro úlohy runtime 2.0.
Omezení a poznámky
- Specifické funkce Delta Lake 4.x jsou experimentální a pracují jenom s prostředími Sparku, jako jsou poznámkové bloky a definice úloh Sparku. Pokud potřebujete použít stejné tabulky Delta Lake napříč několika úlohami Fabric, nepovolujte tyto funkce. Další informace najdete v tématu Interoperabilita formátu tabulky Delta Lake.
- Runtime 2.0 je ve veřejné verzi. Některé funkce a rozhraní API se můžou před obecnou dostupností změnit.
- Rozšíření VS Code pro Fabric Spark podporuje modul runtime 2.0 pro vývoj definic úloh poznámkového bloku a Sparku.
Související obsah
- Runtimy Apache Spark v prostředí Fabric – přehled, verzování a podpora vícero runtime
- Průvodce migrací Spark Core
- Průvodce migrací sql, datových sad a datových rámců
- Průvodce migrací strukturovaného streamování
- Průvodce migrací MLlib (Machine Learning)
- Průvodce migrací PySpark (Python ve Sparku)
- Průvodce migrací SparkR (R ve Sparku)