Kurz: Vytvoření, vyhodnocení a určení skóre prediktivního modelu četnosti změn
Tento kurz představuje kompletní příklad pracovního postupu datové vědy Synapse v Microsoft Fabric. Tento scénář sestaví model, který předpovídá, jestli zákazníci banky odcházejí nebo ne. Míra odchodu, neboli míra úbytku, zahrnuje rychlost, jakou zákazníci banky ukončují svou spolupráci s bankou.
Tento kurz se věnuje těmto krokům:
- Instalace vlastních knihoven
- Načtení dat
- Pochopení a zpracování dat prostřednictvím průzkumné analýzy dat a ukázat použití funkce Fabric Data Wrangler.
- Použití scikit-learn a LightGBM k trénování modelů strojového učení a sledování experimentů s funkcemi automatickéhologování MLflow a Fabric
- Vyhodnocení a uložení konečného modelu strojového učení
- Zobrazení výkonu modelu pomocí vizualizací Power BI
Požadavky
Získejte předplatné Microsoft Fabric. Nebo si zaregistrujte bezplatnou zkušební verzi Microsoft Fabric.
Přihlaste se k Microsoft Fabric.
Pomocí přepínače prostředí v levém dolním rohu domovské stránky přepněte na Fabric.

- V případě potřeby vytvořte Microsoft Fabric lakehouse, jak je popsáno v tématu Vytvoření lakehouse v Microsoft Fabric.
Sledujte s poznámkovým blokem
V poznámkovém bloku můžete zvolit jednu z těchto možností:
- Otevřete a spusťte integrovaný poznámkový blok.
- Nahrajte poznámkový blok z GitHubu.
Otevření integrovaného poznámkového bloku
Tento kurz doprovází ukázka četnosti změn poznámkového bloku zákazníka.
Pokud chcete otevřít ukázkový poznámkový blok pro tento kurz, postupujte podle pokynů v Příprava systému na kurzy datových věd.
Než začnete spouštět kód, nezapomeňte k poznámkovému bloku připojit lakehouse.
Import poznámkového bloku z GitHubu
AIsample - Bank Customer Churn.ipynb poznámkový blok doprovází tento tutoriál.
Pokud chcete otevřít doprovodný poznámkový blok pro tento kurz, postupujte podle pokynů v části Příprava systému na kurzy datových věd a naimportujte poznámkový blok do svého pracovního prostoru.
Pokud chcete raději zkopírovat a vložit kód z této stránky, můžete vytvořit nový poznámkový blok.
Než začnete spouštět kód, nezapomeňte k poznámkovému bloku připojit lakehouse.
Krok 1: Instalace vlastních knihoven
Pro vývoj modelů strojového učení nebo ad hoc analýzu dat možná budete muset rychle nainstalovat vlastní knihovnu pro relaci Apache Sparku. Máte dvě možnosti instalace knihoven.
- Pomocí funkcí vložené instalace (
%pipnebo%conda) poznámkového bloku nainstalujte knihovnu jenom v aktuálním poznámkovém bloku. - Alternativně můžete vytvořit prostředí Fabric, nainstalovat knihovny z veřejných zdrojů nebo do něj nahrát vlastní knihovny a správce pracovního prostoru pak může prostředí připojit jako výchozí pro toto pracovní prostředí. Všechny knihovny v prostředí se pak zpřístupní pro použití v poznámkových blocích a definicích úloh Sparku v pracovním prostoru. Další informace o prostředích najdete v tématu vytvoření, konfigurace a použití prostředí v Microsoft Fabric.
Pro účely tohoto kurzu použijte %pip install k instalaci knihovny imblearn do poznámkového bloku.
Poznámka
Po spuštění %pip install se jádro PySpark restartuje. Před spuštěním jiných buněk nainstalujte potřebné knihovny.
# Use pip to install libraries
%pip install imblearn
Krok 2: Načtení dat
Datová sada v churn.csv obsahuje stav odchodu 10 000 zákazníků, spolu se 14 atributy, včetně:
- Skóre kreditu
- Zeměpisné umístění (Německo, Francie, Španělsko)
- Pohlaví (muž, žena)
- Věk
- Výdrž (počet let, po které byla osoba zákazníkem v dané bance)
- Zůstatek na účtu
- Odhadovaný plat
- Počet produktů zakoupených zákazníkem prostřednictvím banky
- Stav platební karty (bez ohledu na to, jestli má zákazník platební kartu)
- Stav aktivního člena (bez ohledu na to, jestli je osoba aktivním zákazníkem banky)
Datová sada obsahuje také sloupce s číslem řádku, ID zákazníka a příjmením zákazníka. Hodnoty v těchto sloupcích by neměly ovlivnit rozhodnutí zákazníka opustit banku.
Událost uzavření bankovního účtu zákazníka definuje odchod daného zákazníka. Sloupec Exited datového souboru odkazuje na opuštění zákazníka. Vzhledem k tomu, že máme o těchto atributech málo kontextu, nepotřebujeme základní informace o datové sadě. Chceme pochopit, jak tyto atributy přispívají ke stavu Exited.
Z těchto 10 000 zákazníků opustilo banku jenom 2037 zákazníků (zhruba 20%). Kvůli poměru nevyváženosti tříd doporučujeme generovat syntetická data. Přesnost konfuzní matice nemusí mít význam pro nevyváženou klasifikaci. Přesnost můžeme změřit pomocí oblasti pod křivkou Precision-Recall (AUPRC).
- Tato tabulka ukazuje náhled na data
churn.csv.
| identifikátor zákazníka | Příjmení | Kreditní skóre | Zeměpis | Pohlaví | Věk | Funkční období | Rovnováha | NumOfProducts | HasCrCard | JeAktivníČlen | Předpokládaný plat | Odešel |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 15634602 | Hargrave | 619 | Francie | Žena | 42 | 2 | 0.00 | 1 | 1 | 1 | 101348.88 | 1 |
| 15647311 | Kopec | 608 | Španělsko | Žena | 41 | 1 | 83807.86 | 1 | 0 | 1 | 112542.58 | 0 |
Stáhněte datovou sadu a nahrajte do lakehouse
Definujte tyto parametry, abyste mohli tento poznámkový blok používat s různými datovými sadami:
IS_CUSTOM_DATA = False # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE = False # If TRUE, use only SAMPLE_ROWS of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/churn" # Folder with data files
DATA_FILE = "churn.csv" # Data file name
Tento kód stáhne veřejně dostupnou verzi datové sady a pak tuto datovou sadu uloží do objektu Fabric Lakehouse:
Důležitý
přidat lakehouse do poznámkového bloku, než ho spustíte. Pokud to neuděláte, dojde k chybě.
import os, requests
if not IS_CUSTOM_DATA:
# With an Azure Synapse Analytics blob, this can be done in one line
# Download demo data files into the lakehouse if they don't exist
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/bankcustomerchurn"
file_list = ["churn.csv"]
download_path = "/lakehouse/default/Files/churn/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Spusťte záznam času potřebného ke spuštění poznámkového bloku:
# Record the notebook running time
import time
ts = time.time()
Čtení nezpracovaných dat z platformy typu lakehouse
Tento kód čte nezpracovaná data z Files části lakehouse a přidá další sloupce pro různé části data. Vytvoření dělené tabulky delta používá tyto informace.
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
Vytvoření datového rámce pandas z datové sady
Tento kód převede datový rámec Sparku na datový rámec pandas, který usnadňuje zpracování a vizualizaci:
df = df.toPandas()
Krok 3: Provádění průzkumné analýzy dat
Zobrazení nezpracovaných dat
Prozkoumejte nezpracovaná data pomocí display, vypočítejte některé základní statistiky a zobrazte zobrazení grafu. Nejprve je nutné importovat požadované knihovny pro vizualizaci dat – například seaborn . Seaborn je knihovna vizualizací dat Pythonu a poskytuje základní rozhraní pro vytváření vizuálů na datových rámcích a polích.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
Pomocí nástroje Data Wrangler k provedení počátečního čištění dat
Spusťte aplikaci Data Wrangler přímo z poznámkového bloku a prozkoumejte a transformujte datové rámce pandas. Výběrem rozevíracího seznamu Data Wrangler na vodorovném panelu nástrojů procházejte aktivované datové rámce pandas, které jsou k dispozici pro úpravy. Vyberte datový rámec, který chcete otevřít v objektu Data Wrangler.
Poznámka
Nelze otevřít Data Wrangler, když je jádro poznámkového bloku zaneprázdněné. Provedení buňky musí být dokončeno před spuštěním služby Data Wrangler. Další informace o Data Wrangler.

Po spuštění služby Data Wrangler se vygeneruje popisný přehled datového panelu, jak je znázorněno na následujících obrázcích. Přehled obsahuje informace o dimenzi datového rámce, chybějících hodnotách atd. Pomocí nástroje Data Wrangler můžete vygenerovat skript, který vyřadí řádky s chybějícími hodnotami, duplicitní řádky a sloupce s konkrétními názvy. Potom můžete skript zkopírovat do buňky. Další buňka ukazuje zkopírovaný skript.


def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
Určení atributů
Tento kód určuje kategorické, číselné a cílové atributy:
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
Zobrazení souhrnu s pěti čísly
Zobrazení souhrnu s pěti čísly pomocí krabicových grafů
- minimální skóre
- první kvartil
- medián
- třetí kvartil
- maximální skóre
pro číselné atributy.
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
# fig.suptitle('visualize and compare the distribution and central tendency of numerical attributes', color = 'k', fontsize = 12)
fig.delaxes(axes[1,2])

Zobrazit distribuci ukončených a neukončených zákazníků
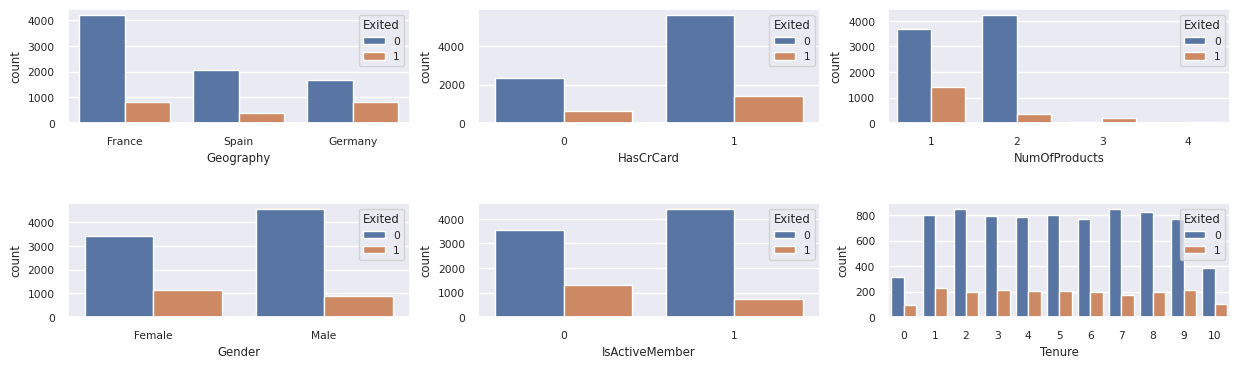
Zobrazení distribuce ukončených a neukončených zákazníků podle kategorií atributů:
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)
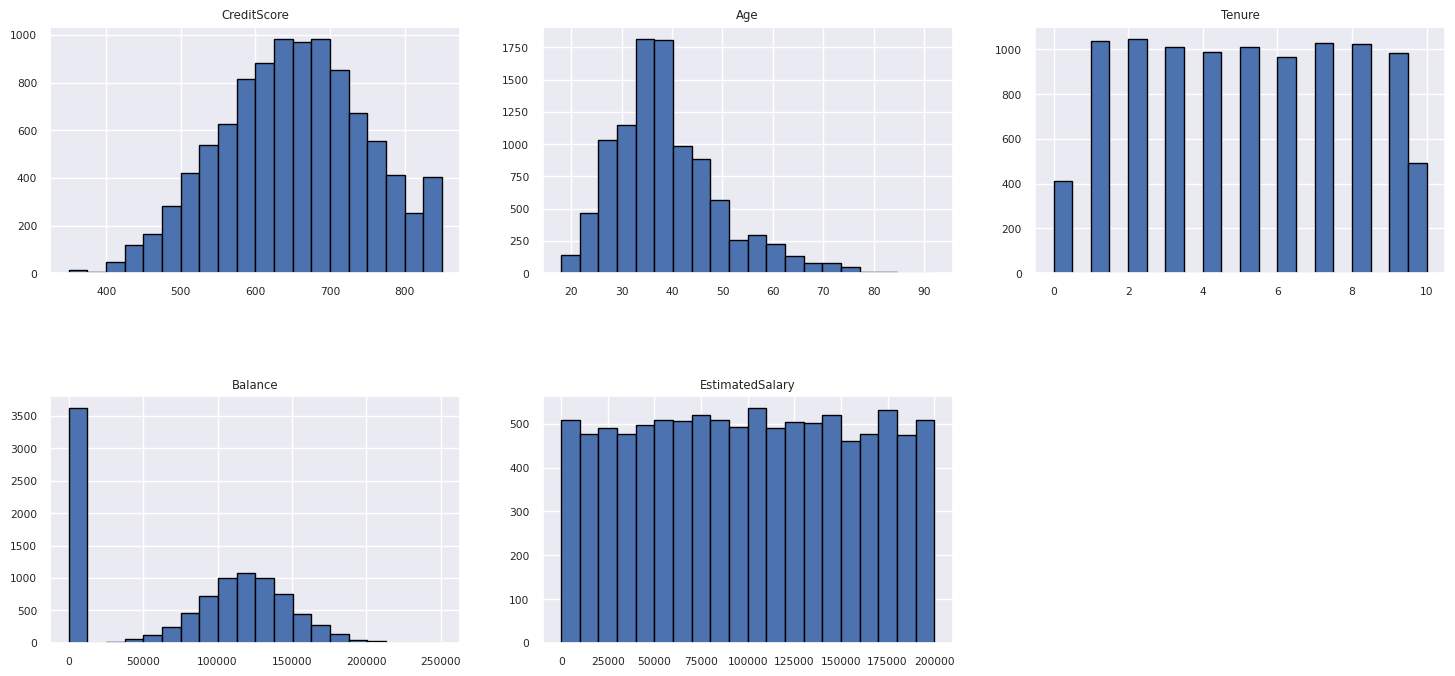
Zobrazení rozdělení číselných atributů
Histogram slouží k zobrazení četnostního rozdělení číselných atributů.
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
# fig = fig.suptitle('distribution of numerical attributes', color = 'r' ,fontsize = 14)
plt.show()
Provést inženýrství funkcí
Tato příprava funkcí generuje nové atributy na základě aktuálních atributů:
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Použijte Data Wrangler pro one-hot kódování
Pomocí stejných kroků spuštění služby Data Wrangler, jak je popsáno dříve, použijte službu Data Wrangler k provedení jednohotového kódování. Tato buňka ukazuje zkopírovaný vygenerovaný skript pro kódování 1-hot:


df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
Vytvoření tabulky delta pro vygenerování sestavy Power BI
table_name = "df_clean"
# Create a PySpark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Shrnutí pozorování z průzkumné analýzy dat
- Většina zákazníků pochází z Francie. Španělsko má nejnižší četnost změn ve srovnání s Francií a Německem.
- Většina zákazníků má platební karty.
- Někteří zákazníci jsou starší než 60 let a mají skóre kreditů nižší než 400. Nemohou však být považovány za odlehlé hodnoty.
- Velmi málo zákazníků má více než dva bankovní produkty
- Neaktivní zákazníci mají vyšší četnost změn
- Pohlaví a roky praxe mají malý vliv na rozhodnutí zákazníků uzavřít bankovní účet.
Krok 4: Provedení trénování a sledování modelu
S daty teď můžete definovat model. V tomto poznámkovém bloku použijte modely náhodného lesa a LightGBM.
Pomocí knihoven scikit-learn a LightGBM implementujte modely s několika řádky kódu. Kromě toho použijte MLflow a Fabric Autologging ke sledování experimentů.
Tento ukázkový kód načte tabulku Delta z lakehouse. Můžete použít i jiné tabulky delta, které jako zdroj používají jezero.
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
Generování experimentu pro sledování a protokolování modelů pomocí MLflow
Tato část ukazuje, jak vygenerovat experiment a určuje parametry modelu a trénování a metriky vyhodnocování. Kromě toho ukazuje, jak vytrénovat modely, protokolovat je a uložit natrénované modely pro pozdější použití.
import mlflow
# Set up the experiment name
EXPERIMENT_NAME = "sample-bank-churn-experiment" # MLflow experiment name
Automatické zachytávání automaticky zaznamenává hodnoty vstupních parametrů i výstupní metriky modelu strojového učení při trénování tohoto modelu. Tyto informace se pak zaznamenávají do vašeho pracovního prostoru, kde k nim mohou získat přístup a vizualizovat je rozhraní API MLflow nebo odpovídající experiment ve vašem pracovním prostoru.
Po dokončení se váš experiment podobá tomuto obrázku:

Všechny experimenty s příslušnými názvy se protokolují a můžete sledovat jejich parametry a metriky výkonu. Další informace o automatickémlogování najdete v tématu Automatickélogování v Microsoft Fabric.
Nastavení specifikací experimentu a automatickéhologování
mlflow.set_experiment(EXPERIMENT_NAME) # Use a date stamp to append to the experiment
mlflow.autolog(exclusive=False)
Import scikit-learn a LightGBM
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
Příprava trénovacích a testovacích datových sad
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Train/test separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
Použití SMOTE na trénovací data
Nevyvážená klasifikace má problém, protože má příliš málo příkladů menšinové třídy, aby se model efektivně naučil rozhodovací hranici. K řešení tohoto problému je technika syntetického převzorkování menšiny (SMOTE) nejrozšířenější technikou pro syntézu nových vzorků pro menšinovou třídu. Přístup k SMOTE pomocí knihovny imblearn, kterou jste nainstalovali v kroku 1.
Použití SMOTE pouze na trénovací datovou sadu. Testovací datovou sadu musíte nechat v původní nevyvážené distribuci, abyste získali platnou aproximaci výkonu modelu u původních dat. Tento experiment představuje situaci v produkčním prostředí.
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
Další informace naleznete v tématu SMOTE a Z náhodného přebírání až po SMOTE a ADASYN. Tyto prostředky hostuje web imbalanced-learn.
Trénování modelu
Pomocí náhodného lesa můžete model vytrénovat s maximální hloubkou čtyři a se čtyřmi příznaky:
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_test, y_test)
y_pred = rfc1_sm.predict(X_test)
cr_rfc1_sm = classification_report(y_test, y_pred)
cm_rfc1_sm = confusion_matrix(y_test, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
Pomocí náhodného lesa k vytrénování modelu s maximální hloubkou osmi a šesti atributy:
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_test, y_test)
y_pred = rfc2_sm.predict(X_test)
cr_rfc2_sm = classification_report(y_test, y_pred)
cm_rfc2_sm = confusion_matrix(y_test, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
Trénování modelu pomocí LightGBM:
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
cr_lgbm_sm = classification_report(y_test, y_pred)
cm_lgbm_sm = confusion_matrix(y_test, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
Zobrazení artefaktu experimentu pro sledování výkonu modelu
Spuštění experimentu se automaticky uloží do experimentálního artefaktu. Tento artefakt najdete v pracovním prostoru. Název artefaktu je založený na názvu použitém k nastavení experimentu. Všechny vytrénované modely, jejich spuštění, metriky výkonu a parametry modelu se protokolují na stránce experimentu.
Pro zobrazení vašich experimentů:
- Na levém panelu vyberte pracovní prostor.
- Vyhledejte a vyberte název experimentu, v tomto případě sample-bank-churn-experiment.
Krok 5: Vyhodnocení a uložení konečného modelu strojového učení
Otevřete uložený experiment z pracovního prostoru a vyberte a uložte nejlepší model:
# Define run_uri to fetch the model
# MLflow client: mlflow.model.url, list model
load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model")
load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model")
load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model")
Posouzení výkonu uložených modelů v testovací datové sadě
ypred_rfc1_sm = load_model_rfc1_sm.predict(X_test) # Random forest with maximum depth of 4 and 4 features
ypred_rfc2_sm = load_model_rfc2_sm.predict(X_test) # Random forest with maximum depth of 8 and 6 features
ypred_lgbm1_sm = load_model_lgbm1_sm.predict(X_test) # LightGBM
Zobrazení pravdivě/falešně pozitivních/negativních výsledků pomocí konfuzní matice
Pokud chcete vyhodnotit přesnost klasifikace, vytvořte skript, který vykreslí konfuzní matici. Pomocí nástrojů SynapseML můžete také vykreslit konfuzní matici, jak je znázorněno v ukázce detekce podvodů .
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
Vytvořte konfuzní matici pro klasifikátor náhodného lesa s maximální hloubkou čtyři a se čtyřmi příznaky.
cfm = confusion_matrix(y_test, y_pred=ypred_rfc1_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()

Vytvořte konfuzní matici pro klasifikátor náhodného lesa s maximální hloubkou osmi, se šesti příznaky:
cfm = confusion_matrix(y_test, y_pred=ypred_rfc2_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()

Vytvořte konfuzní matici pro LightGBM:
cfm = confusion_matrix(y_test, y_pred=ypred_lgbm1_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()

Uložení výsledků pro Power BI
Uložte delta rám do lakehouse, abyste mohli přemístit výsledky předpovědi modelu do vizualizace Power BI.
df_pred = X_test.copy()
df_pred['y_test'] = y_test
df_pred['ypred_rfc1_sm'] = ypred_rfc1_sm
df_pred['ypred_rfc2_sm'] =ypred_rfc2_sm
df_pred['ypred_lgbm1_sm'] = ypred_lgbm1_sm
table_name = "df_pred_results"
sparkDF=spark.createDataFrame(df_pred)
sparkDF.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Krok 6: Přístup k vizualizacm v Power BI
Přístup k uložené tabulce v Power BI:
- Vlevo vyberte OneLake.
- Vyberte jezero, které jste přidali do tohoto poznámkového bloku.
- V části Otevřít tento Lakehouse vyberte Otevřít.
- Na pásu karet vyberte Nový sémantický model. Vyberte
df_pred_results, pak vyberte a poté stiskněte Potvrdit, abyste vytvořili nový sémantický model Power BI propojený s predikcemi. - Otevřete nový sémantický model. Najdete ho v OneLake.
- Výběrem Vytvořit novou sestavu v souboru v nástrojích v horní části stránky sémantických modelů otevřete stránku pro vytváření sestav Power BI.
Následující snímek obrazovky ukazuje některé ukázkové vizualizace. Na datovém panelu se zobrazí tabulky delta a sloupce, které chcete vybrat z tabulky. Po výběru vhodné kategorie (x) a osy hodnot (y) můžete zvolit filtry a funkce – například součet nebo průměr sloupce tabulky.
Poznámka
Na tomto snímku obrazovky popisuje ilustrovaný příklad analýzu výsledků uložených předpovědí v Power BI:

V případě skutečného použití odchodu zákazníků však může uživatel potřebovat důkladnější sadu požadavků na vizualizace, které mají být vytvářeny na základě odborných znalostí a na tom, co firma a tým pro obchodní analýzy standardizovaly jako metriky.
Sestava Power BI ukazuje, že zákazníci, kteří používají více než dvě bankovní produkty, mají vyšší četnost změn. Několik zákazníků ale mělo více než dva produkty. (Zobrazení grafu v levém dolním panelu.) Banka by měla shromažďovat více dat, ale měla by také prozkoumat další funkce, které korelují s více produkty.
Zákazníci bank v Německu mají v porovnání se zákazníky ve Francii a Španělsku vyšší četnost změn. (Se podívejte na graf v pravém dolním panelu) Na základě výsledků zprávy by mohlo pomoci prošetřit faktory, které vedly k odchodu zákazníků.
Existuje více zákazníků se středními věky (mezi 25 a 45). Zákazníci ve věku mezi 45 a 60 lety mají tendenci odcházet více.
Nakonec by zákazníci s nižším skóre úvěru pravděpodobně opustili banku pro ostatní finanční instituce. Banka by měla prozkoumat způsoby, jak podpořit zákazníky s nižším skóre kreditu a zůstatky účtů, aby zůstali s bankou.
# Determine the entire runtime
print(f"Full run cost {int(time.time() - ts)} seconds.")