Kurz: Vytvoření, vyhodnocení a hodnocení modelu detekce chyb počítače
Tento kurz představuje ucelený příklad pracovního postupu Synapse Datová Věda v Microsoft Fabric. Scénář používá strojové učení k systematičtějšímu přístupu k diagnostice chyb, k proaktivní identifikaci problémů a k provádění akcí před skutečným selháním počítače. Cílem je předpovědět, jestli by u počítače došlo k selhání na základě teploty procesu, rotační rychlosti atd.
Tento kurz se věnuje těmto krokům:
- Instalace vlastních knihoven
- Načtení a zpracování dat
- Vysvětlení dat prostřednictvím průzkumné analýzy dat
- Použití knihovny scikit-learn, LightGBM a MLflow k trénování modelů strojového učení a použití funkce automatickéhologování prostředků infrastruktury ke sledování experimentů
- Určení skóre natrénovaných modelů pomocí funkce Fabric
PREDICT, uložení nejlepšího modelu a načtení modelu pro předpovědi - Zobrazení výkonu načteného modelu pomocí vizualizací Power BI
Požadavky
Získejte předplatné Microsoft Fabric. Nebo si zaregistrujte bezplatnou zkušební verzi Microsoft Fabricu.
Přihlaste se k Microsoft Fabric.
Pomocí přepínače prostředí na levé straně domovské stránky přepněte na prostředí Synapse Datová Věda.

- V případě potřeby vytvořte microsoft Fabric lakehouse, jak je popsáno v tématu Vytvoření jezerahouse v Microsoft Fabric.
Sledování v poznámkovém bloku
V poznámkovém bloku můžete zvolit jednu z těchto možností:
- Otevření a spuštění integrovaného poznámkového bloku v prostředí Datová Věda
- Nahrání poznámkového bloku z GitHubu do prostředí Datová Věda
Otevření integrovaného poznámkového bloku
Tento kurz doprovází ukázkový poznámkový blok selhání počítače.
Otevření integrovaného ukázkového poznámkového bloku kurzu v prostředí Datová Věda Synapse:
Přejděte na domovskou stránku Synapse Datová Věda.
Vyberte Použít ukázku.
Vyberte odpovídající ukázku:
- Pokud je ukázka pro kurz Pythonu, na výchozí kartě Kompletní pracovní postupy (Python ).
- Pokud je ukázka kurzu jazyka R, na kartě Kompletní pracovní postupy (R).
- Pokud je ukázka pro rychlý kurz, na kartě Rychlé kurzy .
Než začnete spouštět kód, připojte k poznámkovému bloku lakehouse.
Import poznámkového bloku z GitHubu
Poznámkový blok AISample – Prediktivní údržba doprovází tento kurz.
Pokud chcete otevřít doprovodný poznámkový blok pro tento kurz, postupujte podle pokynů v části Příprava systému na kurzy datových věd a importujte poznámkový blok do pracovního prostoru.
Pokud byste raději zkopírovali a vložili kód z této stránky, můžete vytvořit nový poznámkový blok.
Než začnete spouštět kód, nezapomeňte k poznámkovému bloku připojit lakehouse.
Krok 1: Instalace vlastních knihoven
Pro vývoj modelů strojového učení nebo ad hoc analýzu dat možná budete muset rychle nainstalovat vlastní knihovnu pro relaci Apache Sparku. Máte dvě možnosti instalace knihoven.
- Pomocí funkcí vložené instalace (
%pipnebo%conda) poznámkového bloku nainstalujte knihovnu jenom v aktuálním poznámkovém bloku. - Alternativně můžete vytvořit prostředí Infrastruktury, nainstalovat knihovny z veřejných zdrojů nebo do něj nahrát vlastní knihovny a správce pracovního prostoru pak může prostředí připojit jako výchozí pro pracovní prostor. Všechny knihovny v prostředí se pak zpřístupní pro použití v poznámkových blocích a definicích úloh Sparku v pracovním prostoru. Další informace o prostředích najdete v tématu vytvoření, konfigurace a použití prostředí v Microsoft Fabric.
Pro účely tohoto kurzu nainstalujte %pip install knihovnu imblearn do poznámkového bloku.
Poznámka:
Po spuštění se jádro PySpark restartuje %pip install . Před spuštěním jiných buněk nainstalujte potřebné knihovny.
# Use pip to install imblearn
%pip install imblearn
Krok 2: Načtení dat
Datová sada simuluje protokolování parametrů výrobního stroje jako funkci času, což je běžné v průmyslových nastaveních. Skládá se z 10 000 datových bodů uložených jako řádky s funkcemi jako sloupci. Toto jsou některé z dostupných funkcí:
Jedinečný identifikátor (UID), který se pohybuje od 1 do 1 0000
ID výrobku, které se skládá z písmene L (pro nízké), M (pro střední) nebo H (pro vysoké), označující variantu kvality výrobku a sériové číslo specifické pro variantu. Nízké, střední a vysoce kvalitní varianty tvoří 60 %, 30 % a 10 % všech produktů.
Teplota vzduchu ve stupních Kelvin (K)
Teplota procesu ve stupních Kelvin
Rychlost otáčení v otáčkách za minutu (RPM)
Točivý moment v Newton-Metrech (Nm)
Opotřebení nástroje v minutách. Varianty kvality H, M a L přidávají do nástroje použitého v procesu 5, 3 a 2 minuty opotřebení nástroje.
Popisek selhání počítače, který označuje, jestli počítač selhal v konkrétním datovém bodě. Tento konkrétní datový bod může mít některý z následujících pěti nezávislých režimů selhání:
- Chyba opotřebení nástrojů (TWF): Nástroj se nahradí nebo selže v náhodně vybrané době opotřebení nástroje v rozmezí 200 až 240 minut.
- Selhání rozdělení tepla (HDF): Rozdělení tepla způsobí selhání procesu, pokud je rozdíl mezi teplotou vzduchu a teplotou procesu menší než 8,6 K a rotační rychlost nástroje je menší než 1380 RPM.
- Selhání napájení (PWF): součin momentu a rotační rychlosti (v radi/s) se rovná výkonu požadovanému pro proces. Proces selže, pokud tento výkon klesne pod 3 500 W nebo překročí 9 000 W.
- OverStrain Failure (OSF): Pokud produkt opotřebení a točivý moment nástroje překročí 11 000 min. Nm pro variantu produktu L (12 000 pro M, 13 000 pro H), proces selže kvůli přetrénování.
- Náhodná selhání (RNF): Každý proces má šanci na selhání 0,1 %, bez ohledu na parametry procesu.
Poznámka:
Pokud platí alespoň jeden z výše uvedených režimů selhání, proces selže a popisek "selhání počítače" je nastaven na hodnotu 1. Metoda strojového učení nemůže určit, který režim selhání způsobil selhání procesu.
Stažení datové sady a nahrání do jezera
Připojení do kontejneru Azure Open Datasets a načtěte datovou sadu prediktivní údržby. Tento kód stáhne veřejně dostupnou verzi datové sady a pak ji uloží do objektu Fabric Lakehouse:
Důležité
Před spuštěním poznámkového bloku přidejte do poznámkového bloku lakehouse. V opačném případě se zobrazí chyba. Informace o přidání jezera najdete v tématu Připojení lakehouses a poznámkové bloky.
# Download demo data files into the lakehouse if they don't exist
import os, requests
DATA_FOLDER = "Files/predictive_maintenance/" # Folder that contains the dataset
DATA_FILE = "predictive_maintenance.csv" # Data file name
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/MachineFaultDetection"
file_list = ["predictive_maintenance.csv"]
download_path = f"/lakehouse/default/{DATA_FOLDER}/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Po stažení datové sady do jezera ji můžete načíst jako datový rámec Sparku:
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}raw/{DATA_FILE}")
.cache()
)
df.show(5)
Tato tabulka ukazuje náhled dat:
| UDI | ID produktu | Typ | Teplota vzduchu [K] | Teplota procesu [K] | Rychlost otáčení [ot/min] | Točivý moment [Nm] | Opotřebení nástroje [min] | Cíl | Typ selhání |
|---|---|---|---|---|---|---|---|---|---|
| 0 | M14860 | M | 298.1 | 308.6 | 1551 | 42.8 | 0 | 0 | Bez selhání |
| 2 | L47181 | L | 298.2 | 308.7 | 1408 | 46.3 | 3 | 0 | Bez selhání |
| 3 | L47182 | L | 298.1 | 308.5 | 1498 | 49.4 | 5 | 0 | Bez selhání |
| 4 | L47183 | L | 298.2 | 308.6 | 1433 | 39.5 | 7 | 0 | Bez selhání |
| 5 | L47184 | L | 298.2 | 308.7 | 1408 | 40.0 | 9 | 0 | Bez selhání |
Zápis datového rámce Sparku do tabulky Delta lakehouse
Naformátujte data (například nahraďte mezery podtržítky), aby se usnadnily operace Sparku v následujících krocích:
# Replace the space in the column name with an underscore to avoid an invalid character while saving
df = df.toDF(*(c.replace(' ', '_') for c in df.columns))
table_name = "predictive_maintenance_data"
df.show(5)
Tato tabulka ukazuje náhled dat s přeformátovanými názvy sloupců:
| UDI | Product_ID | Typ | Air_temperature_[K] | Process_temperature_[K] | Rotational_speed_[rpm] | Torque_[Nm] | Tool_wear_[min] | Cíl | Failure_Type |
|---|---|---|---|---|---|---|---|---|---|
| 0 | M14860 | M | 298.1 | 308.6 | 1551 | 42.8 | 0 | 0 | Bez selhání |
| 2 | L47181 | L | 298.2 | 308.7 | 1408 | 46.3 | 3 | 0 | Bez selhání |
| 3 | L47182 | L | 298.1 | 308.5 | 1498 | 49.4 | 5 | 0 | Bez selhání |
| 4 | L47183 | L | 298.2 | 308.6 | 1433 | 39.5 | 7 | 0 | Bez selhání |
| 5 | L47184 | L | 298.2 | 308.7 | 1408 | 40.0 | 9 | 0 | Bez selhání |
# Save data with processed columns to the lakehouse
df.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Krok 3: Předběžné zpracování dat a provádění průzkumné analýzy dat
Převeďte datový rámec Sparku na datový rámec pandas a použijte oblíbené knihovny vykreslování kompatibilní s Pandas.
Tip
U velké datové sady možná budete muset načíst část této datové sady.
data = spark.read.format("delta").load("Tables/predictive_maintenance_data")
SEED = 1234
df = data.toPandas()
df.drop(['UDI', 'Product_ID'],axis=1,inplace=True)
# Rename the Target column to IsFail
df = df.rename(columns = {'Target': "IsFail"})
df.info()
Podle potřeby převeďte konkrétní sloupce datové sady na plovoucí nebo celočíselné typy a namapujte řetězce ('L', 'M', 'H') na číselné hodnoty (0, 1, 2):
# Convert temperature, rotational speed, torque, and tool wear columns to float
df['Air_temperature_[K]'] = df['Air_temperature_[K]'].astype(float)
df['Process_temperature_[K]'] = df['Process_temperature_[K]'].astype(float)
df['Rotational_speed_[rpm]'] = df['Rotational_speed_[rpm]'].astype(float)
df['Torque_[Nm]'] = df['Torque_[Nm]'].astype(float)
df['Tool_wear_[min]'] = df['Tool_wear_[min]'].astype(float)
# Convert the 'Target' column to an integer
df['IsFail'] = df['IsFail'].astype(int)
# Map 'L', 'M', 'H' to numerical values
df['Type'] = df['Type'].map({'L': 0, 'M': 1, 'H': 2})
Prozkoumání dat prostřednictvím vizualizací
# Import packages and set plotting style
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
sns.set_style('darkgrid')
# Create the correlation matrix
corr_matrix = df.corr(numeric_only=True)
# Plot a heatmap
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True)
plt.show()
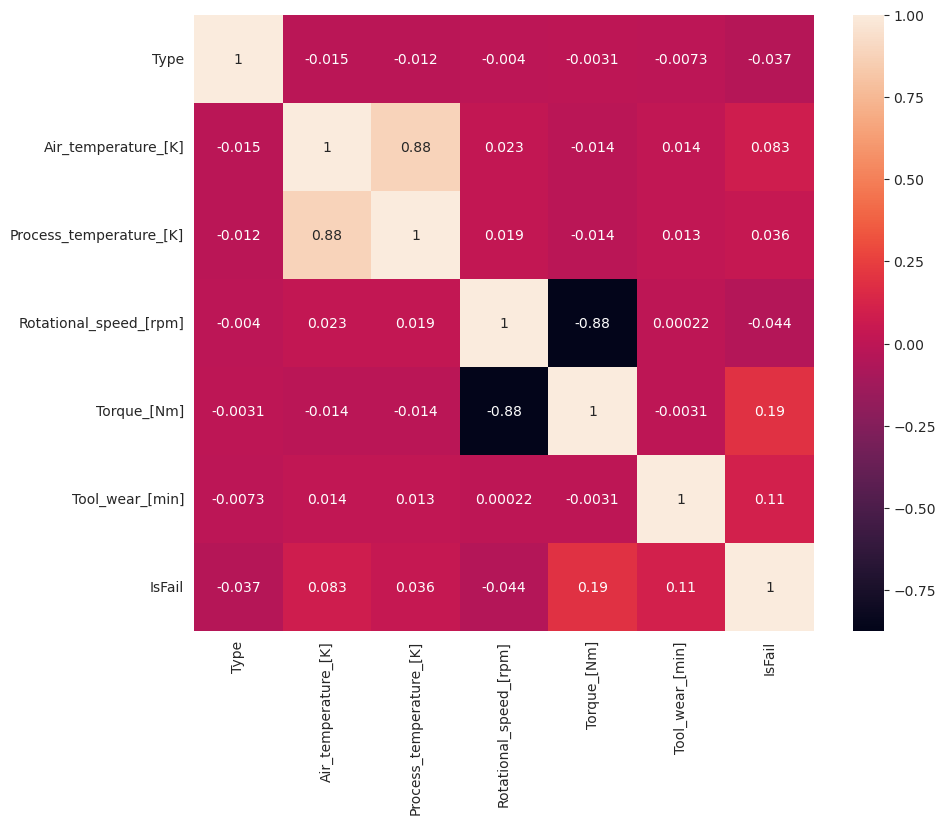
Podle očekávání koreluje selhání (IsFail) s vybranými funkcemi (sloupci). Matice korelace ukazuje, že Air_temperature, , Process_temperatureRotational_speed, Torquea Tool_wear mají nejvyšší korelaci s proměnnouIsFail.
# Plot histograms of select features
fig, axes = plt.subplots(2, 3, figsize=(18,10))
columns = ['Air_temperature_[K]', 'Process_temperature_[K]', 'Rotational_speed_[rpm]', 'Torque_[Nm]', 'Tool_wear_[min]']
data=df.copy()
for ind, item in enumerate (columns):
column = columns[ind]
df_column = data[column]
df_column.hist(ax = axes[ind%2][ind//2], bins=32).set_title(item)
fig.supylabel('count')
fig.subplots_adjust(hspace=0.2)
fig.delaxes(axes[1,2])
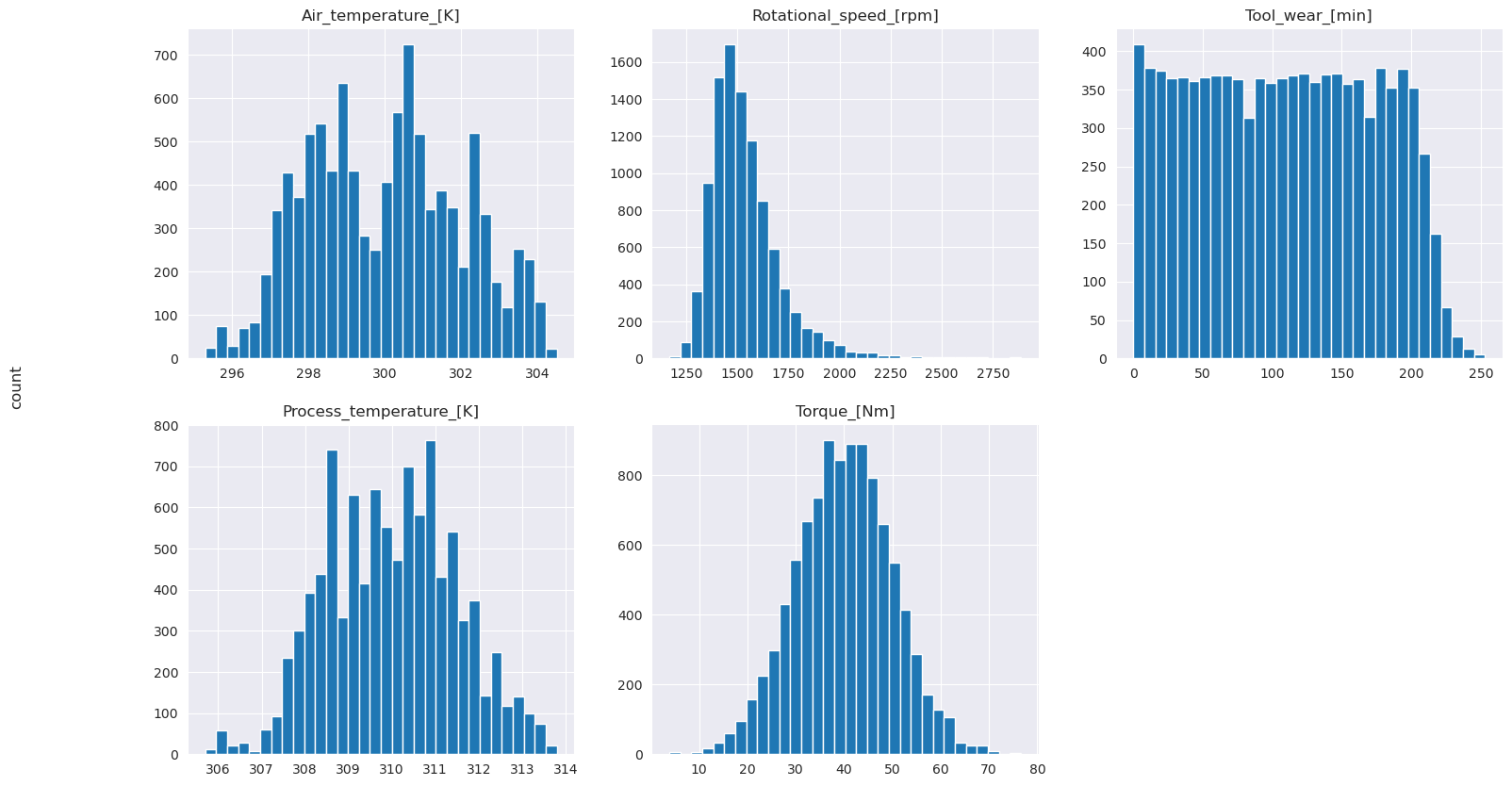
Jak vykreslované grafy ukazují, Air_temperaturenejsou řídké hodnoty , Process_temperatureRotational_speed, Torquea Tool_wear proměnné. Zdá se, že mají v prostoru funkcí dobrou kontinuitu. Tyto grafy potvrdí, že trénování modelu strojového učení na této datové sadě pravděpodobně vede ke spolehlivým výsledkům, které se dají zobecnit na novou datovou sadu.
Kontrola nevyrovnanosti tříd v cílové proměnné
Spočítejte počet vzorků pro neúspěšné a neúspěšné počítače a zkontrolujte zůstatek dat pro každou třídu (IsFail=0, IsFail=1):
# Plot the counts for no failure and each failure type
plt.figure(figsize=(12, 2))
ax = sns.countplot(x='Failure_Type', data=df)
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x()+0.4, p.get_height()+50))
plt.show()
# Plot the counts for no failure versus the sum of all failure types
plt.figure(figsize=(4, 2))
ax = sns.countplot(x='IsFail', data=df)
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x()+0.4, p.get_height()+50))
plt.show()
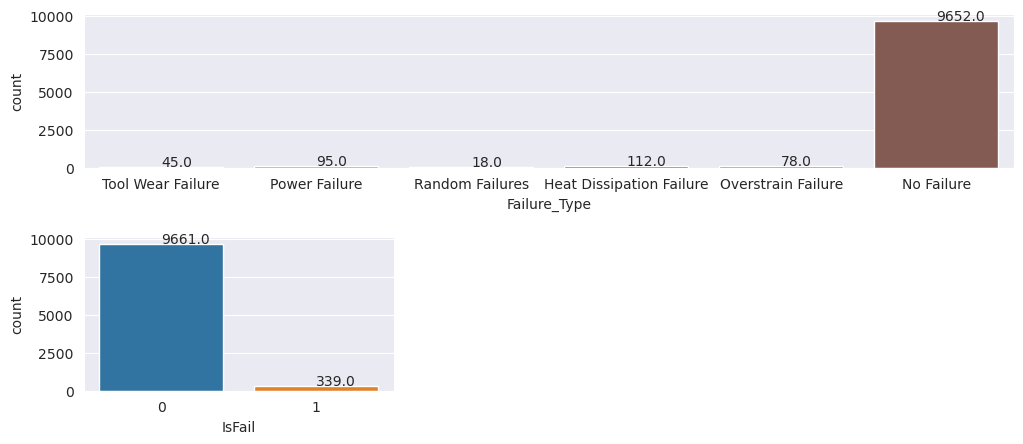
Grafy označují, že většina vzorků představuje třídu bez selhání (zobrazenou jako IsFail=0 v druhém grafu). Pomocí techniky převzorkování vytvořte vyváženější trénovací datovou sadu:
# Separate features and target
features = df[['Type', 'Air_temperature_[K]', 'Process_temperature_[K]', 'Rotational_speed_[rpm]', 'Torque_[Nm]', 'Tool_wear_[min]']]
labels = df['IsFail']
# Split the dataset into the training and testing sets
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=42)
# Ignore warnings
import warnings
warnings.filterwarnings('ignore')
# Save test data to the lakehouse for use in future sections
table_name = "predictive_maintenance_test_data"
df_test_X = spark.createDataFrame(X_test)
df_test_X.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Převzorkování tříd v trénovací datové sadě
Předchozí analýza ukázala, že datová sada je vysoce nevyvážená. Tato nerovnováha se stává problémem, protože menšinová třída má příliš málo příkladů, aby se model efektivně naučil rozhodovací hranici.
SMOTE může tento problém vyřešit. SMOTE je široce používaná technika převzorkování, která generuje syntetické příklady. Generuje příklady menšinové třídy na základě euklidiánských vzdáleností mezi datovými body. Tato metoda se liší od náhodného převzorkování, protože vytváří nové příklady, které jen duplikují menšinové třídy. Metoda se stává efektivnější technikou pro zpracování nevyvážených datových sad.
# Disable MLflow autologging because you don't want to track SMOTE fitting
import mlflow
mlflow.autolog(disable=True)
from imblearn.combine import SMOTETomek
smt = SMOTETomek(random_state=SEED)
X_train_res, y_train_res = smt.fit_resample(X_train, y_train)
# Plot the counts for both classes
plt.figure(figsize=(4, 2))
ax = sns.countplot(x='IsFail', data=pd.DataFrame({'IsFail': y_train_res.values}))
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x()+0.4, p.get_height()+50))
plt.show()
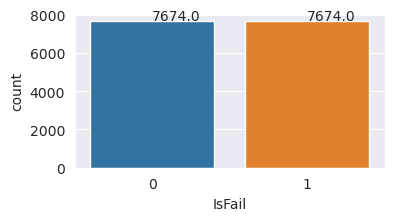
Datovou sadu jste úspěšně vyrovnali. Teď můžete přejít na trénování modelu.
Krok 4: Trénování a vyhodnocení modelů
MLflow zaregistruje modely, trénuje a porovnává různé modely a vybírá nejlepší model pro účely predikce. Pro trénování modelů můžete použít následující tři modely:
- Klasifikátor náhodné doménové struktury
- Klasifikátor logistické regrese
- Klasifikátor XGBoost
Trénovat klasifikátor náhodných doménových struktur
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from mlflow.models.signature import infer_signature
from sklearn.metrics import f1_score, accuracy_score, recall_score
mlflow.set_experiment("Machine_Failure_Classification")
mlflow.autolog(exclusive=False) # This is needed to override the preconfigured autologging behavior
with mlflow.start_run() as run:
rfc_id = run.info.run_id
print(f"run_id {rfc_id}, status: {run.info.status}")
rfc = RandomForestClassifier(max_depth=5, n_estimators=50)
rfc.fit(X_train_res, y_train_res)
signature = infer_signature(X_train_res, y_train_res)
mlflow.sklearn.log_model(
rfc,
"machine_failure_model_rf",
signature=signature,
registered_model_name="machine_failure_model_rf"
)
y_pred_train = rfc.predict(X_train)
# Calculate the classification metrics for test data
f1_train = f1_score(y_train, y_pred_train, average='weighted')
accuracy_train = accuracy_score(y_train, y_pred_train)
recall_train = recall_score(y_train, y_pred_train, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_train", f1_train)
mlflow.log_metric("accuracy_train", accuracy_train)
mlflow.log_metric("recall_train", recall_train)
# Print the run ID and the classification metrics
print("F1 score_train:", f1_train)
print("Accuracy_train:", accuracy_train)
print("Recall_train:", recall_train)
y_pred_test = rfc.predict(X_test)
# Calculate the classification metrics for test data
f1_test = f1_score(y_test, y_pred_test, average='weighted')
accuracy_test = accuracy_score(y_test, y_pred_test)
recall_test = recall_score(y_test, y_pred_test, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_test", f1_test)
mlflow.log_metric("accuracy_test", accuracy_test)
mlflow.log_metric("recall_test", recall_test)
# Print the classification metrics
print("F1 score_test:", f1_test)
print("Accuracy_test:", accuracy_test)
print("Recall_test:", recall_test)
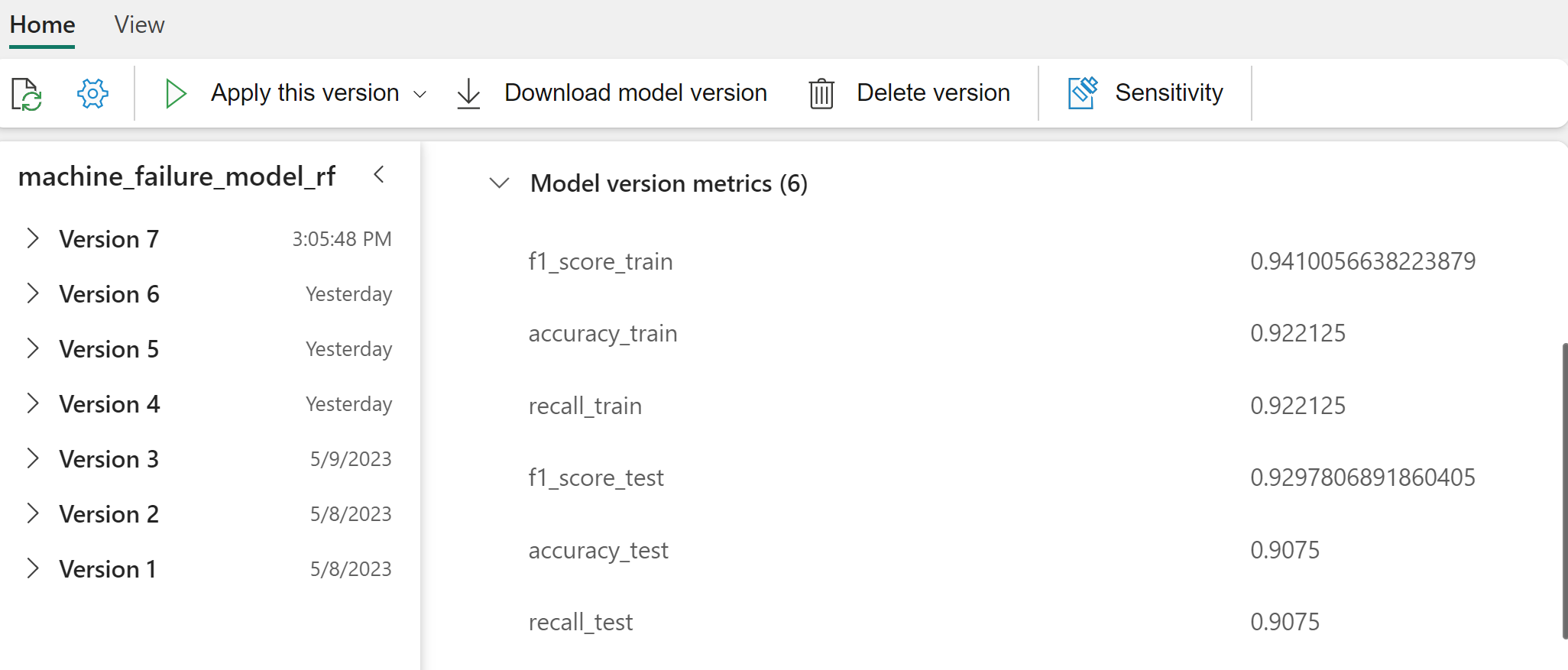
Z výstupu poskytují trénovací i testovací datové sady skóre F1, přesnost a úplnost přibližně 0,9 při použití klasifikátoru náhodné doménové struktury.
Trénování klasifikátoru logistické regrese
from sklearn.linear_model import LogisticRegression
with mlflow.start_run() as run:
lr_id = run.info.run_id
print(f"run_id {lr_id}, status: {run.info.status}")
lr = LogisticRegression(random_state=42)
lr.fit(X_train_res, y_train_res)
signature = infer_signature(X_train_res, y_train_res)
mlflow.sklearn.log_model(
lr,
"machine_failure_model_lr",
signature=signature,
registered_model_name="machine_failure_model_lr"
)
y_pred_train = lr.predict(X_train)
# Calculate the classification metrics for training data
f1_train = f1_score(y_train, y_pred_train, average='weighted')
accuracy_train = accuracy_score(y_train, y_pred_train)
recall_train = recall_score(y_train, y_pred_train, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_train", f1_train)
mlflow.log_metric("accuracy_train", accuracy_train)
mlflow.log_metric("recall_train", recall_train)
# Print the run ID and the classification metrics
print("F1 score_train:", f1_train)
print("Accuracy_train:", accuracy_train)
print("Recall_train:", recall_train)
y_pred_test = lr.predict(X_test)
# Calculate the classification metrics for test data
f1_test = f1_score(y_test, y_pred_test, average='weighted')
accuracy_test = accuracy_score(y_test, y_pred_test)
recall_test = recall_score(y_test, y_pred_test, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_test", f1_test)
mlflow.log_metric("accuracy_test", accuracy_test)
mlflow.log_metric("recall_test", recall_test)
Trénování klasifikátoru XGBoost
from xgboost import XGBClassifier
with mlflow.start_run() as run:
xgb = XGBClassifier()
xgb_id = run.info.run_id
print(f"run_id {xgb_id}, status: {run.info.status}")
xgb.fit(X_train_res.to_numpy(), y_train_res.to_numpy())
signature = infer_signature(X_train_res, y_train_res)
mlflow.xgboost.log_model(
xgb,
"machine_failure_model_xgb",
signature=signature,
registered_model_name="machine_failure_model_xgb"
)
y_pred_train = xgb.predict(X_train)
# Calculate the classification metrics for training data
f1_train = f1_score(y_train, y_pred_train, average='weighted')
accuracy_train = accuracy_score(y_train, y_pred_train)
recall_train = recall_score(y_train, y_pred_train, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_train", f1_train)
mlflow.log_metric("accuracy_train", accuracy_train)
mlflow.log_metric("recall_train", recall_train)
# Print the run ID and the classification metrics
print("F1 score_train:", f1_train)
print("Accuracy_train:", accuracy_train)
print("Recall_train:", recall_train)
y_pred_test = xgb.predict(X_test)
# Calculate the classification metrics for test data
f1_test = f1_score(y_test, y_pred_test, average='weighted')
accuracy_test = accuracy_score(y_test, y_pred_test)
recall_test = recall_score(y_test, y_pred_test, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_test", f1_test)
mlflow.log_metric("accuracy_test", accuracy_test)
mlflow.log_metric("recall_test", recall_test)
Krok 5: Výběr nejlepšího modelu a predikce výstupů
V předchozí části jste vytrénovali tři různé klasifikátory: náhodnou doménovou strukturu, logistickou regresi a XGBoost. Teď máte možnost získat přístup k výsledkům prostřednictvím kódu programu nebo použít uživatelské rozhraní.
Pro možnost cesta k uživatelskému rozhraní přejděte do svého pracovního prostoru a vyfiltrujte modely.
Výběrem jednotlivých modelů zobrazíte podrobnosti o výkonu modelu.
Tento příklad ukazuje, jak programově přistupovat k modelům prostřednictvím MLflow:
runs = {'random forest classifier': rfc_id,
'logistic regression classifier': lr_id,
'xgboost classifier': xgb_id}
# Create an empty DataFrame to hold the metrics
df_metrics = pd.DataFrame()
# Loop through the run IDs and retrieve the metrics for each run
for run_name, run_id in runs.items():
metrics = mlflow.get_run(run_id).data.metrics
metrics["run_name"] = run_name
df_metrics = df_metrics.append(metrics, ignore_index=True)
# Print the DataFrame
print(df_metrics)
I když XGBoost poskytuje nejlepší výsledky v trénovací sadě, provádí špatně na testovací datové sadě. Tento nízký výkon značí přetáčení. Klasifikátor logistické regrese provádí špatně jak u trénovacích, tak testovacích datových sad. Náhodná doménová struktura celkově představuje dobrou rovnováhu mezi výkonem trénování a zabránění přeurčením.
V další části zvolte registrovaný model náhodné doménové struktury a pomocí funkce PREDICT proveďte predikci:
from synapse.ml.predict import MLFlowTransformer
model = MLFlowTransformer(
inputCols=list(X_test.columns),
outputCol='predictions',
modelName='machine_failure_model_rf',
modelVersion=1
)
S objektem MLFlowTransformer , který jste vytvořili k načtení modelu pro odvozování, použijte rozhraní Transformer API k určení skóre modelu v testovací datové sadě:
predictions = model.transform(spark.createDataFrame(X_test))
predictions.show()
Tato tabulka ukazuje výstup:
| Typ | Air_temperature_[K] | Process_temperature_[K] | Rotational_speed_[rpm] | Torque_[Nm] | Tool_wear_[min] | Předpovědi |
|---|---|---|---|---|---|---|
| 0 | 300.6 | 309.7 | 1639.0 | 30.4 | 121.0 | 0 |
| 0 | 303.9 | 313.0 | 1551.0 | 36,8 | 140.0 | 0 |
| 1 | 299.1 | 308.6 | 1491.0 | 38.5 | 166.0 | 0 |
| 0 | 300.9 | 312.1 | 1359.0 | 51.7 | 146.0 | 0 |
| 0 | 303.7 | 312.6 | 1621.0 | 38.8 | 182.0 | 0 |
| 0 | 299.0 | 310.3 | 1868.0 | 24,0 | 221.0 | 1 |
| 2 | 297.8 | 307.5 | 1631.0 | 31.3 | 124.0 | 0 |
| 0 | 297.5 | 308.2 | 1327.0 | 56.5 | 189.0 | 0 |
| 0 | 301.3 | 310.3 | 1460.0 | 41.5 | 197.0 | 0 |
| 2 | 297.6 | 309.0 | 1413.0 | 40.2 | 51.0 | 0 |
| 1 | 300.9 | 309.4 | 1724.0 | 25.6 | 119.0 | 0 |
| 0 | 303.3 | 311.3 | 1389.0 | 53.9 | 39.0 | 0 |
| 0 | 298.4 | 307.9 | 1981.0 | 23.2 | 16.0 | 0 |
| 0 | 299.3 | 308.8 | 1636.0 | 29.9 | 201.0 | 0 |
| 1 | 298.1 | 309.2 | 1460.0 | 45,8 % | 80.0 | 0 |
| 0 | 300.0 | 309.5 | 1728.0 | 26.0 | 37.0 | 0 |
| 2 | 299.0 | 308.7 | 1940.0 | 19.9 | 98.0 | 0 |
| 0 | 302.2 | 310.8 | 1383.0 | 46.9 | 45.0 | 0 |
| 0 | 300.2 | 309.2 | 1431.0 | 51.3 | 57.0 | 0 |
| 0 | 299.6 | 310.2 | 1468.0 | 48,0 | 9.0 | 0 |
Uložte data do jezera. Data se pak zpřístupní pro pozdější použití – například řídicí panel Power BI.
# Save test data to the lakehouse for use in the next section.
table_name = "predictive_maintenance_test_with_predictions"
predictions.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Krok 6: Zobrazení business intelligence prostřednictvím vizualizací v Power BI
Zobrazte výsledky v offline formátu pomocí řídicího panelu Power BI.
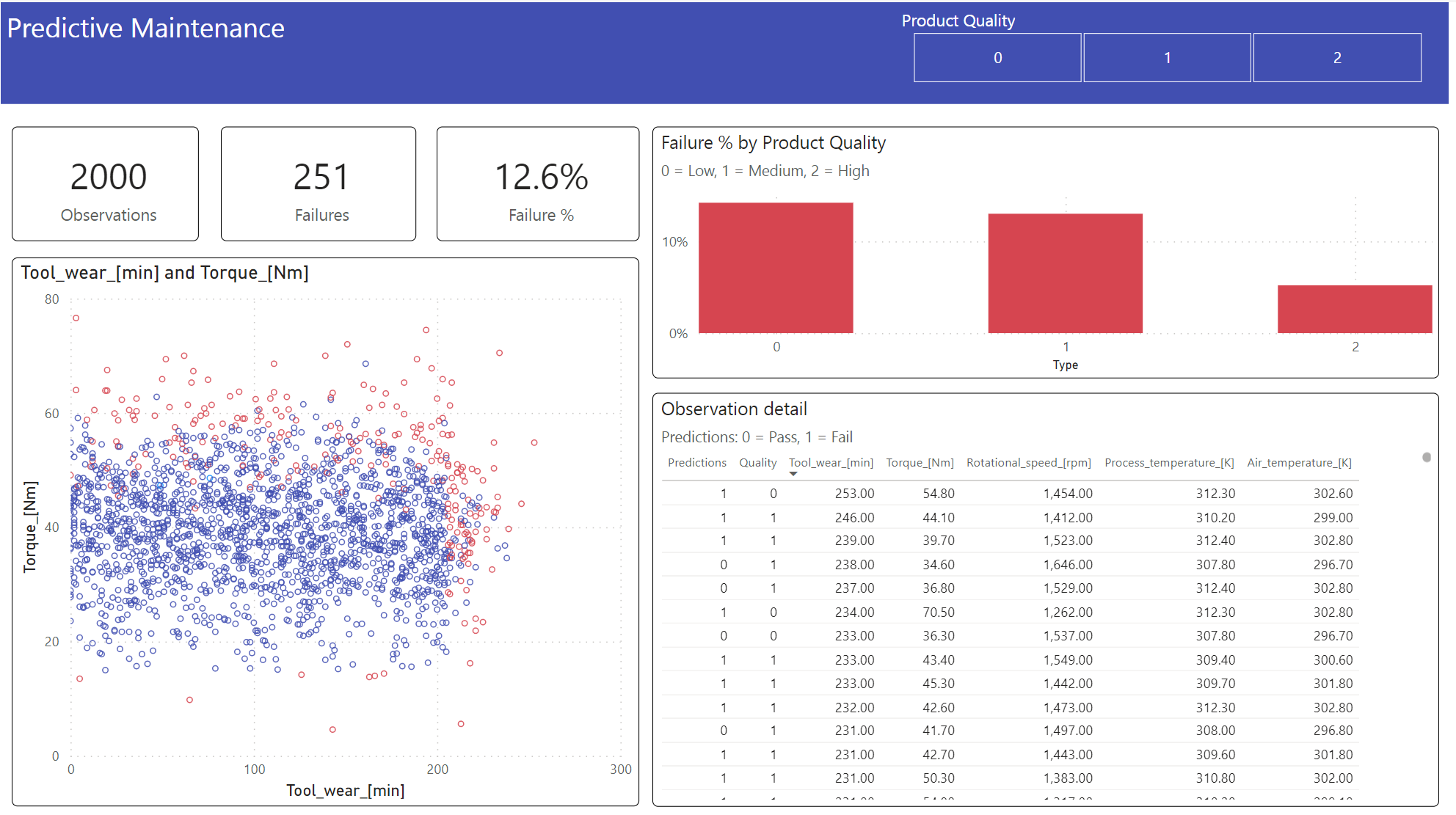
Řídicí panel ukazuje, že Tool_wear a Torque vytvoří znatelnou hranici mezi neúspěšnými a neúspěšnými případy podle očekávání z předchozí analýzy korelace v kroku 2.
Související obsah
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro