Kurz: Vytvoření, vyhodnocení a hodnocení systému doporučení
Tento kurz představuje ucelený příklad pracovního postupu Synapse Datová Věda v Microsoft Fabric. Tento scénář sestaví model pro doporučení pro online knihy.
Tento kurz se věnuje těmto krokům:
- Nahrání dat do jezera
- Provádění průzkumné analýzy dat
- Trénování modelu a jeho protokolování pomocí MLflow
- Načtení modelu a vytváření předpovědí
K dispozici je mnoho typů algoritmů doporučení. Tento kurz používá algoritmus faktorizace matic střídavých nejmenších čtverců (ALS). ALS je algoritmus pro filtrování založený na modelu.

ALS se pokusí odhadnout matici hodnocení R jako součin dvou matic nižších pořadí, vy a V. Zde R = U * Vt. Tyto aproximace se obvykle nazývají faktorové matice.
Algoritmus ALS je iterativní. Každá iterace obsahuje jednu z konstant faktorových matic, zatímco řeší druhou metodou nejmenších čtverců. Pak obsahuje, že nově vyřešená faktorová maticová konstanta, zatímco řeší druhou faktorovou matici.

Požadavky
Získejte předplatné Microsoft Fabric. Nebo si zaregistrujte bezplatnou zkušební verzi Microsoft Fabricu.
Přihlaste se k Microsoft Fabric.
Pomocí přepínače prostředí na levé straně domovské stránky přepněte na prostředí Synapse Datová Věda.

- V případě potřeby vytvořte microsoft Fabric lakehouse, jak je popsáno v tématu Vytvoření jezerahouse v Microsoft Fabric.
Sledování v poznámkovém bloku
V poznámkovém bloku můžete zvolit jednu z těchto možností:
- Otevření a spuštění integrovaného poznámkového bloku v prostředí Datová Věda Synapse
- Nahrání poznámkového bloku z GitHubu do prostředí synapse Datová Věda
Otevření integrovaného poznámkového bloku
Tento kurz doprovází ukázkový poznámkový blok doporučení knihy.
Otevření integrovaného ukázkového poznámkového bloku kurzu v prostředí Datová Věda Synapse:
Přejděte na domovskou stránku Synapse Datová Věda.
Vyberte Použít ukázku.
Vyberte odpovídající ukázku:
- Pokud je ukázka pro kurz Pythonu, na výchozí kartě Kompletní pracovní postupy (Python ).
- Pokud je ukázka kurzu jazyka R, na kartě Kompletní pracovní postupy (R).
- Pokud je ukázka pro rychlý kurz, na kartě Rychlé kurzy .
Než začnete spouštět kód, připojte k poznámkovému bloku lakehouse.
Import poznámkového bloku z GitHubu
Poznámkový blok AIsample - Book Recommendation.ipynb doprovází tento kurz.
Pokud chcete otevřít doprovodný poznámkový blok pro tento kurz, postupujte podle pokynů v části Příprava systému na kurzy datových věd a importujte poznámkový blok do pracovního prostoru.
Pokud byste raději zkopírovali a vložili kód z této stránky, můžete vytvořit nový poznámkový blok.
Než začnete spouštět kód, nezapomeňte k poznámkovému bloku připojit lakehouse.
Krok 1: Načtení dat
Datová sada doporučení knihy v tomto scénáři se skládá ze tří samostatných datových sad:
Books.csv: Mezinárodní standardní číslo knihy (ISBN) identifikuje každou knihu s neplatnými daty, která jsou již odebrána. Datová sada obsahuje také název, autora a vydavatele. V případě knihy s více autory obsahuje soubor Books.csv jenom první autor. Adresy URL odkazují na prostředky webu Amazon pro titulní obrázky ve třech velikostech.
ISBN Název knihy Autor knihy Rok publikování Publisher Image-URL-S Obrázek URL-M Obrázek URL-l 0195153448 Klasická klasické klasicky klasického Mark P. O. Morford 2002 Oxford University Press http://images.amazon.com/images/P/0195153448.01.THUMBZZZ.jpg http://images.amazon.com/images/P/0195153448.01.MZZZZZZZ.jpg http://images.amazon.com/images/P/0195153448.01.LZZZZZZZ.jpg 0002005018 Clara Callan Richard Bruce Wright 2001 HarperFlamingo Kanada http://images.amazon.com/images/P/0002005018.01.THUMBZZZ.jpg http://images.amazon.com/images/P/0002005018.01.MZZZZZZZ.jpg http://images.amazon.com/images/P/0002005018.01.LZZZZZZZ.jpg Ratings.csv: Hodnocení pro každou knihu jsou buď explicitní (poskytovaná uživateli, v měřítku 1 až 10) nebo implicitní (pozorované bez vstupu uživatele a označené hodnotou 0).
ID uživatele ISBN Hodnocení knih 276725 034545104X 0 276726 0155061224 5 Users.csv: ID uživatelů jsou anonymizovaná a mapovaná na celá čísla. Demografické údaje – například umístění a věk – jsou k dispozici, pokud jsou k dispozici. Pokud tato data nejsou k dispozici, jsou
nulltyto hodnoty .ID uživatele Umístění Věk 0 "nyc New York usa" 2 "stockton california usa" 18.0
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Definujte tyto parametry, abyste mohli tento poznámkový blok s různými datovými sadami:
IS_CUSTOM_DATA = False # If True, the dataset has to be uploaded manually
USER_ID_COL = "User-ID" # Must not be '_user_id' for this notebook to run successfully
ITEM_ID_COL = "ISBN" # Must not be '_item_id' for this notebook to run successfully
ITEM_INFO_COL = (
"Book-Title" # Must not be '_item_info' for this notebook to run successfully
)
RATING_COL = (
"Book-Rating" # Must not be '_rating' for this notebook to run successfully
)
IS_SAMPLE = True # If True, use only <SAMPLE_ROWS> rows of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_FOLDER = "Files/book-recommendation/" # Folder that contains the datasets
ITEMS_FILE = "Books.csv" # File that contains the item information
USERS_FILE = "Users.csv" # File that contains the user information
RATINGS_FILE = "Ratings.csv" # File that contains the rating information
EXPERIMENT_NAME = "aisample-recommendation" # MLflow experiment name
Stažení a uložení dat v jezeře
Tento kód stáhne datovou sadu a uloží ji do jezera.
Důležité
Než ho spustíte, nezapomeňte do poznámkového bloku přidat jezero . V opačném případě se zobrazí chyba.
if not IS_CUSTOM_DATA:
# Download data files into a lakehouse if they don't exist
import os, requests
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/Book-Recommendation-Dataset"
file_list = ["Books.csv", "Ratings.csv", "Users.csv"]
download_path = f"/lakehouse/default/{DATA_FOLDER}/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Nastavení sledování experimentu MLflow
Tento kód použijte k nastavení sledování experimentu MLflow. Tento příklad zakáže automatické protokolování. Další informace najdete v článku o automatickémlogování v Microsoft Fabric .
# Set up MLflow for experiment tracking
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Disable MLflow autologging
Čtení dat z jezera
Po umístění správných dat do jezera načtěte tři datové sady do samostatných datových rámců Sparku v poznámkovém bloku. Cesty k souborům v tomto kódu používají parametry definované dříve.
df_items = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{ITEMS_FILE}")
.cache()
)
df_ratings = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{RATINGS_FILE}")
.cache()
)
df_users = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{USERS_FILE}")
.cache()
)
Krok 2: Provádění průzkumné analýzy dat
Zobrazení nezpracovaných dat
Prozkoumejte datové rámce pomocí display příkazu. Pomocí tohoto příkazu můžete zobrazit statistiky datového rámce vysoké úrovně a porozumět tomu, jak spolu různé sloupce datové sady souvisejí. Než prozkoumáte datové sady, použijte tento kód k importu požadovaných knihoven:
import pyspark.sql.functions as F
from pyspark.ml.feature import StringIndexer
import matplotlib.pyplot as plt
import seaborn as sns
color = sns.color_palette() # Adjusting plotting style
import pandas as pd # DataFrames
Tento kód použijte k zobrazení datového rámce, který obsahuje data knihy:
display(df_items, summary=True)
_item_id Přidejte sloupec pro pozdější použití. Hodnota _item_id musí být celé číslo pro modely doporučení. Tento kód používá StringIndexer k transformaci ITEM_ID_COL na indexy:
df_items = (
StringIndexer(inputCol=ITEM_ID_COL, outputCol="_item_id")
.setHandleInvalid("skip")
.fit(df_items)
.transform(df_items)
.withColumn("_item_id", F.col("_item_id").cast("int"))
)
Zobrazte datový rámec a zkontrolujte, jestli se _item_id hodnota monotonicky a postupně zvyšuje podle očekávání:
display(df_items.sort(F.col("_item_id").desc()))
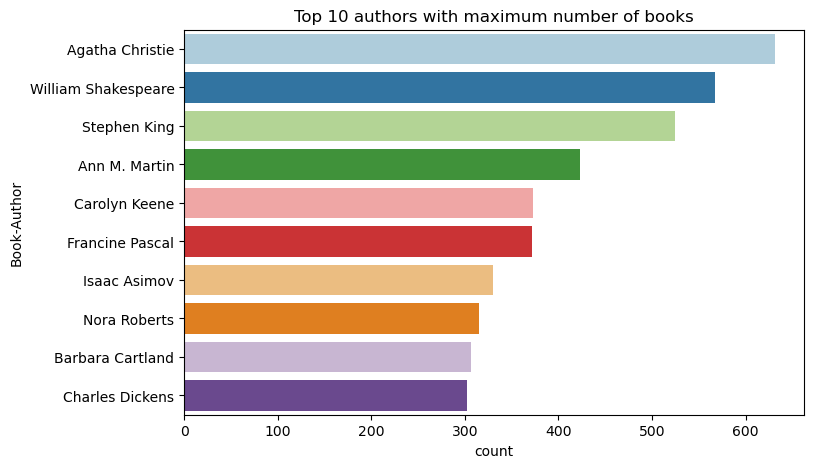
Tento kód slouží k vykreslení prvních 10 autorů podle počtu knih napsaných v sestupném pořadí. Agatha Christie je přední autorka s více než 600 knihami, následovanými Williamem Shakespearem.
df_books = df_items.toPandas() # Create a pandas DataFrame from the Spark DataFrame for visualization
plt.figure(figsize=(8,5))
sns.countplot(y="Book-Author",palette = 'Paired', data=df_books,order=df_books['Book-Author'].value_counts().index[0:10])
plt.title("Top 10 authors with maximum number of books")
Dále zobrazte datový rámec, který obsahuje uživatelská data:
display(df_users, summary=True)
Pokud řádek obsahuje chybějící User-ID hodnotu, odstraňte tento řádek. Chybějící hodnoty v přizpůsobené datové sadě nezpůsobují problémy.
df_users = df_users.dropna(subset=(USER_ID_COL))
display(df_users, summary=True)
_user_id Přidejte sloupec pro pozdější použití. U modelů _user_id doporučení musí být hodnota celé číslo. Následující ukázka kódu se používá StringIndexer k transformaci USER_ID_COL na indexy.
Datová sada knihy už obsahuje celočíselnou User-ID hodnotu. Přidáním _user_id sloupce kvůli kompatibilitě s různými datovými sadami je ale tento příklad robustnější. Pomocí tohoto kódu přidejte _user_id sloupec:
df_users = (
StringIndexer(inputCol=USER_ID_COL, outputCol="_user_id")
.setHandleInvalid("skip")
.fit(df_users)
.transform(df_users)
.withColumn("_user_id", F.col("_user_id").cast("int"))
)
display(df_users.sort(F.col("_user_id").desc()))
Pomocí tohoto kódu můžete zobrazit data hodnocení:
display(df_ratings, summary=True)
Získejte jedinečné hodnocení a uložte je pro pozdější použití v seznamu s názvem ratings:
ratings = [i[0] for i in df_ratings.select(RATING_COL).distinct().collect()]
print(ratings)
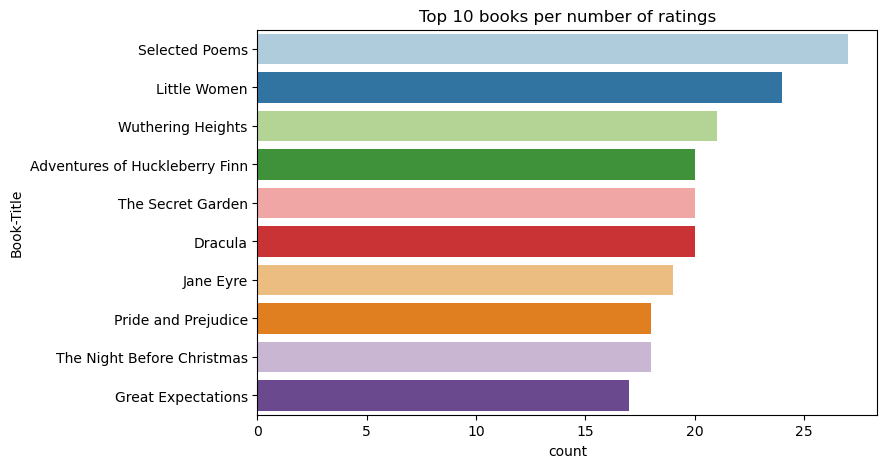
Pomocí tohoto kódu můžete zobrazit prvních 10 knih s nejvyšším hodnocením:
plt.figure(figsize=(8,5))
sns.countplot(y="Book-Title",palette = 'Paired',data= df_books, order=df_books['Book-Title'].value_counts().index[0:10])
plt.title("Top 10 books per number of ratings")
Podle hodnocení je vybraná báseň nejoblíbenější knihou. Dobrodružství Huckleberry Finn, The Secret Garden a Dracula mají stejné hodnocení.
Sloučení dat
Sloučí tři datové rámce do jednoho datového rámce pro komplexnější analýzu:
df_all = df_ratings.join(df_users, USER_ID_COL, "inner").join(
df_items, ITEM_ID_COL, "inner"
)
df_all_columns = [
c for c in df_all.columns if c not in ["_user_id", "_item_id", RATING_COL]
]
# Reorder the columns to ensure that _user_id, _item_id, and Book-Rating are the first three columns
df_all = (
df_all.select(["_user_id", "_item_id", RATING_COL] + df_all_columns)
.withColumn("id", F.monotonically_increasing_id())
.cache()
)
display(df_all)
Tento kód slouží k zobrazení počtu jedinečných uživatelů, knih a interakcí:
print(f"Total Users: {df_users.select('_user_id').distinct().count()}")
print(f"Total Items: {df_items.select('_item_id').distinct().count()}")
print(f"Total User-Item Interactions: {df_all.count()}")
Výpočty a vykreslení nejoblíbenějších položek
Tento kód použijte k výpočtu a zobrazení 10 nejoblíbenějších knih:
# Compute top popular products
df_top_items = (
df_all.groupby(["_item_id"])
.count()
.join(df_items, "_item_id", "inner")
.sort(["count"], ascending=[0])
)
# Find top <topn> popular items
topn = 10
pd_top_items = df_top_items.limit(topn).toPandas()
pd_top_items.head(10)
Tip
<topn> Použijte hodnotu pro oddíly Oblíbené nebo Nejoblíbenější zakoupené doporučení.
# Plot top <topn> items
f, ax = plt.subplots(figsize=(10, 5))
plt.xticks(rotation="vertical")
sns.barplot(y=ITEM_INFO_COL, x="count", data=pd_top_items)
ax.tick_params(axis='x', rotation=45)
plt.xlabel("Number of Ratings for the Item")
plt.show()

Příprava trénovacích a testovacích datových sad
Matice ALS vyžaduje před trénováním určitou přípravu dat. Pomocí této ukázky kódu připravte data. Kód provede tyto akce:
- Přetypování sloupce hodnocení na správný typ
- Ukázka trénovacích dat s hodnocením uživatelů
- Rozdělení dat na trénovací a testovací datové sady
if IS_SAMPLE:
# Must sort by '_user_id' before performing limit to ensure that ALS works normally
# If training and test datasets have no common _user_id, ALS will fail
df_all = df_all.sort("_user_id").limit(SAMPLE_ROWS)
# Cast the column into the correct type
df_all = df_all.withColumn(RATING_COL, F.col(RATING_COL).cast("float"))
# Using a fraction between 0 and 1 returns the approximate size of the dataset; for example, 0.8 means 80% of the dataset
# Rating = 0 means the user didn't rate the item, so it can't be used for training
# We use the 80% of the dataset with rating > 0 as the training dataset
fractions_train = {0: 0}
fractions_test = {0: 0}
for i in ratings:
if i == 0:
continue
fractions_train[i] = 0.8
fractions_test[i] = 1
# Training dataset
train = df_all.sampleBy(RATING_COL, fractions=fractions_train)
# Join with leftanti will select all rows from df_all with rating > 0 and not in the training dataset; for example, the remaining 20% of the dataset
# test dataset
test = df_all.join(train, on="id", how="leftanti").sampleBy(
RATING_COL, fractions=fractions_test
)
Sparsity odkazuje na zhuštěná data zpětné vazby, která nemohou identifikovat podobnosti v zájmu uživatelů. Pokud chcete lépe porozumět datům i aktuálnímu problému, použijte tento kód k výpočtu sparsity datové sady:
# Compute the sparsity of the dataset
def get_mat_sparsity(ratings):
# Count the total number of ratings in the dataset - used as numerator
count_nonzero = ratings.select(RATING_COL).count()
print(f"Number of rows: {count_nonzero}")
# Count the total number of distinct user_id and distinct product_id - used as denominator
total_elements = (
ratings.select("_user_id").distinct().count()
* ratings.select("_item_id").distinct().count()
)
# Calculate the sparsity by dividing the numerator by the denominator
sparsity = (1.0 - (count_nonzero * 1.0) / total_elements) * 100
print("The ratings DataFrame is ", "%.4f" % sparsity + "% sparse.")
get_mat_sparsity(df_all)
# Check the ID range
# ALS supports only values in the integer range
print(f"max user_id: {df_all.agg({'_user_id': 'max'}).collect()[0][0]}")
print(f"max user_id: {df_all.agg({'_item_id': 'max'}).collect()[0][0]}")
Krok 3: Vývoj a trénování modelu
Vytrénujte model ALS tak, aby uživatelům poskytoval přizpůsobená doporučení.
Definování modelu
Spark ML poskytuje pohodlné rozhraní API pro vytváření modelu ALS. Model ale spolehlivě nezpracuje problémy, jako jsou sparsity dat a studený start (doporučení, když jsou uživatelé nebo položky nové). Pokud chcete zlepšit výkon modelu, zkombinujte křížové ověřování a automatické ladění hyperparametrů.
Tento kód použijte k importu knihoven potřebných pro trénování a vyhodnocení modelu:
# Import Spark required libraries
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.recommendation import ALS
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator, TrainValidationSplit
# Specify the training parameters
num_epochs = 1 # Number of epochs; here we use 1 to reduce the training time
rank_size_list = [64] # The values of rank in ALS for tuning
reg_param_list = [0.01, 0.1] # The values of regParam in ALS for tuning
model_tuning_method = "TrainValidationSplit" # TrainValidationSplit or CrossValidator
# Build the recommendation model by using ALS on the training data
# We set the cold start strategy to 'drop' to ensure that we don't get NaN evaluation metrics
als = ALS(
maxIter=num_epochs,
userCol="_user_id",
itemCol="_item_id",
ratingCol=RATING_COL,
coldStartStrategy="drop",
implicitPrefs=False,
nonnegative=True,
)
Ladění hyperparametrů modelu
Následující vzorový kód vytvoří mřížku parametrů, která vám pomůže vyhledat hyperparametry. Kód také vytvoří regresní vyhodnocovač, který jako metriku vyhodnocení používá chybu RMSE (root-mean-square error):
# Construct a grid search to select the best values for the training parameters
param_grid = (
ParamGridBuilder()
.addGrid(als.rank, rank_size_list)
.addGrid(als.regParam, reg_param_list)
.build()
)
print("Number of models to be tested: ", len(param_grid))
# Define the evaluator and set the loss function to the RMSE
evaluator = RegressionEvaluator(
metricName="rmse", labelCol=RATING_COL, predictionCol="prediction"
)
Následující ukázka kódu zahájí různé metody ladění modelu na základě předkonfigurovaných parametrů. Další informace o ladění modelů najdete v tématu Ladění ML: výběr modelu a ladění hyperparametrů na webu Apache Spark.
# Build cross-validation by using CrossValidator and TrainValidationSplit
if model_tuning_method == "CrossValidator":
tuner = CrossValidator(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=evaluator,
numFolds=5,
collectSubModels=True,
)
elif model_tuning_method == "TrainValidationSplit":
tuner = TrainValidationSplit(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=evaluator,
# 80% of the training data will be used for training; 20% for validation
trainRatio=0.8,
collectSubModels=True,
)
else:
raise ValueError(f"Unknown model_tuning_method: {model_tuning_method}")
Vyhodnocení modelu
Moduly byste měli vyhodnotit na základě testovacích dat. Dobře vytrénovaný model by měl mít u datové sady vysoké metriky.
Pře fitovaný model může potřebovat zvětšení velikosti trénovacích dat nebo zmenšení některých redundantních funkcí. Architektura modelu se může muset změnit nebo její parametry můžou vyžadovat jemné ladění.
Poznámka:
Záporná hodnota metriky R-squared označuje, že trénovaný model funguje hůře než vodorovná přímka. Toto hledání naznačuje, že trénovaný model nevysvětluje data.
K definování zkušební funkce použijte tento kód:
def evaluate(model, data, verbose=0):
"""
Evaluate the model by computing rmse, mae, r2, and variance over the data.
"""
predictions = model.transform(data).withColumn(
"prediction", F.col("prediction").cast("double")
)
if verbose > 1:
# Show 10 predictions
predictions.select("_user_id", "_item_id", RATING_COL, "prediction").limit(
10
).show()
# Initialize the regression evaluator
evaluator = RegressionEvaluator(predictionCol="prediction", labelCol=RATING_COL)
_evaluator = lambda metric: evaluator.setMetricName(metric).evaluate(predictions)
rmse = _evaluator("rmse")
mae = _evaluator("mae")
r2 = _evaluator("r2")
var = _evaluator("var")
if verbose > 0:
print(f"RMSE score = {rmse}")
print(f"MAE score = {mae}")
print(f"R2 score = {r2}")
print(f"Explained variance = {var}")
return predictions, (rmse, mae, r2, var)
Sledování experimentu pomocí MLflow
Pomocí MLflow můžete sledovat všechny experimenty a protokolovat parametry, metriky a modely. K zahájení trénování a vyhodnocení modelu použijte tento kód:
from mlflow.models.signature import infer_signature
with mlflow.start_run(run_name="als"):
# Train models
models = tuner.fit(train)
best_metrics = {"RMSE": 10e6, "MAE": 10e6, "R2": 0, "Explained variance": 0}
best_index = 0
# Evaluate models
# Log models, metrics, and parameters
for idx, model in enumerate(models.subModels):
with mlflow.start_run(nested=True, run_name=f"als_{idx}") as run:
print("\nEvaluating on test data:")
print(f"subModel No. {idx + 1}")
predictions, (rmse, mae, r2, var) = evaluate(model, test, verbose=1)
signature = infer_signature(
train.select(["_user_id", "_item_id"]),
predictions.select(["_user_id", "_item_id", "prediction"]),
)
print("log model:")
mlflow.spark.log_model(
model,
f"{EXPERIMENT_NAME}-alsmodel",
signature=signature,
registered_model_name=f"{EXPERIMENT_NAME}-alsmodel",
dfs_tmpdir="Files/spark",
)
print("log metrics:")
current_metric = {
"RMSE": rmse,
"MAE": mae,
"R2": r2,
"Explained variance": var,
}
mlflow.log_metrics(current_metric)
if rmse < best_metrics["RMSE"]:
best_metrics = current_metric
best_index = idx
print("log parameters:")
mlflow.log_params(
{
"subModel_idx": idx,
"num_epochs": num_epochs,
"rank_size_list": rank_size_list,
"reg_param_list": reg_param_list,
"model_tuning_method": model_tuning_method,
"DATA_FOLDER": DATA_FOLDER,
}
)
# Log the best model and related metrics and parameters to the parent run
mlflow.spark.log_model(
models.subModels[best_index],
f"{EXPERIMENT_NAME}-alsmodel",
signature=signature,
registered_model_name=f"{EXPERIMENT_NAME}-alsmodel",
dfs_tmpdir="Files/spark",
)
mlflow.log_metrics(best_metrics)
mlflow.log_params(
{
"subModel_idx": idx,
"num_epochs": num_epochs,
"rank_size_list": rank_size_list,
"reg_param_list": reg_param_list,
"model_tuning_method": model_tuning_method,
"DATA_FOLDER": DATA_FOLDER,
}
)
Vyberte experiment s názvem aisample-recommendation z pracovního prostoru a zobrazte protokolované informace pro trénovací běh. Pokud jste změnili název experimentu, vyberte experiment s novým názvem. Protokolované informace se podobají tomuto obrázku:

Krok 4: Načtení konečného modelu pro bodování a vytváření předpovědí
Po dokončení trénování modelu a výběru nejlepšího modelu načtěte model pro bodování (někdy označovaný jako odvozování). Tento kód načte model a pomocí predikcí doporučí prvních 10 knih pro každého uživatele:
# Load the best model
# MLflow uses PipelineModel to wrap the original model, so we extract the original ALSModel from the stages
model_uri = f"models:/{EXPERIMENT_NAME}-alsmodel/1"
loaded_model = mlflow.spark.load_model(model_uri, dfs_tmpdir="Files/spark").stages[-1]
# Generate top 10 book recommendations for each user
userRecs = loaded_model.recommendForAllUsers(10)
# Represent the recommendations in an interpretable format
userRecs = (
userRecs.withColumn("rec_exp", F.explode("recommendations"))
.select("_user_id", F.col("rec_exp._item_id"), F.col("rec_exp.rating"))
.join(df_items.select(["_item_id", "Book-Title"]), on="_item_id")
)
userRecs.limit(10).show()
Výstup se podobá této tabulce:
| _item_id | _User_id | rating | Název knihy |
|---|---|---|---|
| 44865 | 7 | 7.9996786 | Lasher: Život ... |
| 786 | 7 | 6.2255826 | Klavírní muž je D... |
| 45330 | 7 | 4.980466 | Stav mysli |
| 38960 | 7 | 4.980466 | Vše, co kdy chtěl |
| 125415 | 7 | 4.505084 | Harry Potter a ... |
| 44939 | 7 | 4.3579073 | Taltos: Život ... |
| 175247 | 7 | 4.3579073 | Bonesetter je ... |
| 170183 | 7 | 4.228735 | Žijeme v jednoduchém... |
| 88503 | 7 | 4.221206 | Ostrov Blu... |
| 32894 | 7 | 3.9031885 | Zimní slunovrat |
Uložení předpovědí do jezera
Pomocí tohoto kódu napište doporučení zpět do jezera:
# Code to save userRecs into the lakehouse
userRecs.write.format("delta").mode("overwrite").save(
f"{DATA_FOLDER}/predictions/userRecs"
)
Související obsah
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro