Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
K vyčištění dat použijte funkční závislosti. Funkční závislost existuje, když jeden sloupec v sémantickém modelu (datová sada Power BI) závisí na jiném sloupci. Například sloupec ZIP code může určit hodnotu ve sloupci city. Funkční závislost se zobrazuje jako relace 1:N mezi hodnotami ve dvou nebo více sloupcích v objektu DataFrame. Tento kurz používá datovou sadu Synthea k zobrazení toho, jak funkční závislosti pomáhají zjišťovat problémy s kvalitou dat.
V tomto kurzu se naučíte:
- Využijte znalosti domény k vytvoření hypotéz o funkčních závislostech v sémantickém modelu.
- Seznamte se s komponentami knihovny Semantic Link Python (SemPy), které automatizují analýzu kvality dat. Mezi tyto komponenty patří:
-
FabricDataFrame– struktura podobná pandas s dalšími sémantickými informacemi. - Funkce, které automatizují vyhodnocování hypotéz o funkčních závislostech a identifikují porušení v sémantických modelech.
-
Požadavky
Získejte předplatné Microsoft Fabric. Nebo si zaregistrujte bezplatnou zkušební verzi Microsoft Fabric.
Přihlaste se k Microsoft Fabric.
Pomocí přepínače zkušeností v levém dolním rohu domovské stránky přepněte na Fabric.

- V navigačním podokně vyberte Pracovní prostory a pak vyberte svůj pracovní prostor, aby byl nastaven jako aktuální.
Postupujte podle pokynů v poznámkovém bloku
Pomocí poznámkového bloku data_cleaning_functional_dependencies_tutorial.ipynb postupujte podle tohoto kurzu.
Pokud chcete otevřít doprovodný poznámkový blok pro tento tutoriál, postupujte podle pokynů v části připravte svůj systém pro tutoriály datové vědy a importujte poznámkový blok do svého pracovního prostoru.
Pokud chcete raději zkopírovat a vložit kód z této stránky, můžete vytvořit nový poznámkový blok.
Než začnete spouštět kód, nezapomeňte k poznámkovému bloku připojit lakehouse .
Nastavení poznámkového bloku
V této části nastavíte prostředí poznámkového bloku.
Zkontrolujte verzi Sparku. Pokud používáte Spark 3.4 nebo novější v Microsoft Fabric, je sémantický odkaz ve výchozím nastavení zahrnutý, takže ho nemusíte instalovat. Pokud používáte Spark 3.3 nebo starší nebo chcete aktualizovat na nejnovější sémantický odkaz, spusťte následující příkaz.
%pip install -U semantic-linkImportujte moduly, které používáte v tomto poznámkovém bloku.
import pandas as pd import sempy.fabric as fabric from sempy.fabric import FabricDataFrame from sempy.dependencies import plot_dependency_metadataStáhněte si ukázková data. V tomto kurzu použijte datovou sadu Synthea syntetických lékařských záznamů (malá verze pro jednoduchost).
download_synthea(which='small')
Prozkoumání dat
Inicializujte
FabricDataFrameobsahem souboru providers.csv.providers = FabricDataFrame(pd.read_csv("synthea/csv/providers.csv")) providers.head()Zkontrolujte problémy s kvalitou dat u funkce SemPy
find_dependenciesvykreslením grafu automaticky rozdetekovaných funkčních závislostí.deps = providers.find_dependencies() plot_dependency_metadata(deps)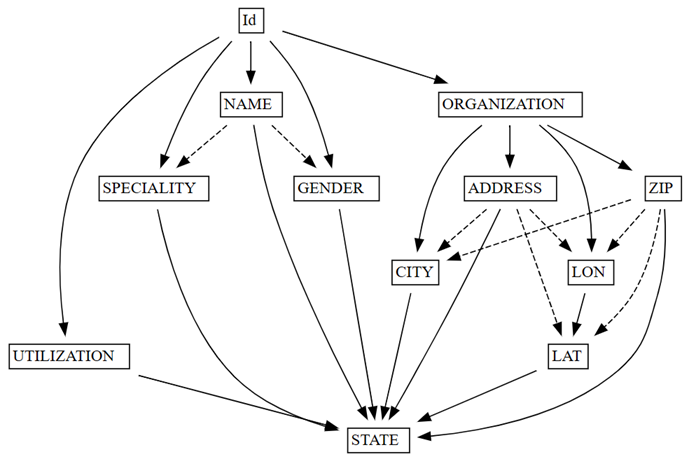
Graf ukazuje, že
IdurčujeNAMEaORGANIZATION. Tento výsledek je očekávaný, protožeIdje jedinečný.Ověřte, že
Idje jedinečný.providers.Id.is_uniqueKód vrátí
True, aby potvrdil, žeIdje jedinečný.

Hloubková analýza funkčních závislostí
Graf funkčních závislostí také ukazuje, že ORGANIZATION určuje ADDRESS a ZIPpodle očekávání. Můžete ale očekávat, že ZIP také určí CITY, ale přerušovaná šipka indikuje, že závislost je pouze přibližná a ukazuje na problém s kvalitou dat.
V grafu jsou další zvláštní vlastnosti. Například NAME neurčí GENDER, Id, SPECIALITYnebo ORGANIZATION. Každá z těchto zvláštních vlastností by mohla být za to prozkoumat.
- Podívejte se blíže na přibližný vztah mezi
ZIPaCITYtím, že použijete funkcilist_dependency_violationsz knihovny SemPy k vypsání porušení:
providers.list_dependency_violations('ZIP', 'CITY')
- Nakreslete graf pomocí
plot_dependency_violationsvizualizační funkce SemPy. Tento graf je užitečný, pokud je počet porušení malý:
providers.plot_dependency_violations('ZIP', 'CITY')
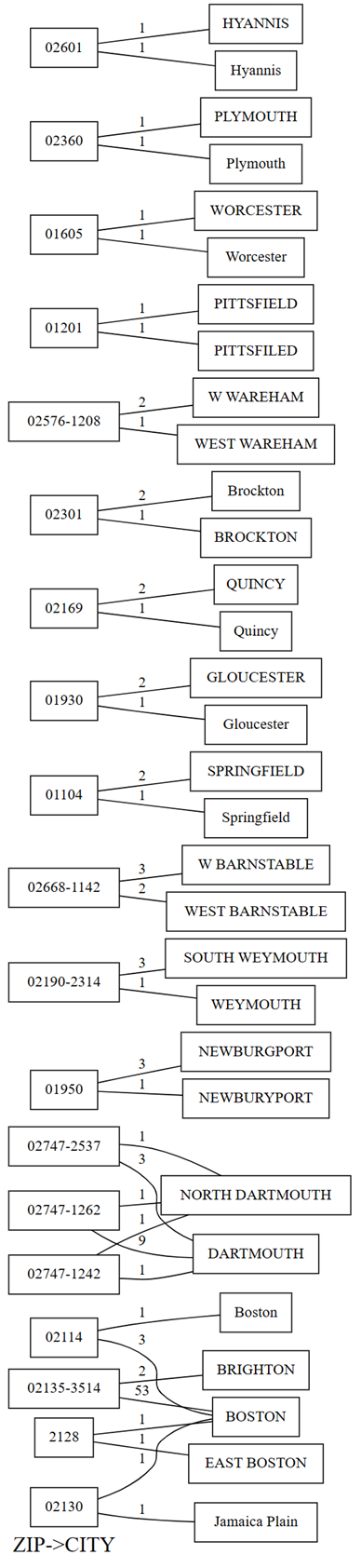
Graf porušení závislostí zobrazuje hodnoty pro ZIP levou stranu a hodnoty pro CITY pravou stranu. Hrana spojuje PSČ na levé straně grafu s městem na pravé straně, pokud je řádek obsahující tyto dvě hodnoty. Hrany jsou opatřeny poznámkami s počtem takových řádků. Například existují dva řádky se PSČ 02747-1242, jeden řádek s městem "NORTH DARTHMOUTH" a druhý s městem "DARTHMOUTH", jak je znázorněno v předchozím grafu a následujícím kódem:
- Potvrďte pozorování z grafu spuštěním následujícího kódu:
providers[providers.ZIP == '02747-1242'].CITY.value_counts()
Graf také ukazuje, že mezi řádky, které mají
CITYhodnotu "DARTHMOUTH", máZIPdevět řádků 02747-1262. Jeden řádek máZIP02747-1242. Jeden řádek máZIPčíslo 02747-2537. Pomocí následujícího kódu ověřte následující pozorování:providers[providers.CITY == 'DARTHMOUTH'].ZIP.value_counts()Existují další PSČ přidružené k "DARTMOUTH", ale tyto PSČ se nezobrazují v grafu porušení závislostí, protože neukazují na problémy s kvalitou dat. Například PSČ "02747-4302" je jedinečně spojené s "DARTMOUTH" a nezobrazuje se v grafu porušení závislostí. Potvrďte spuštěním následujícího kódu:
providers[providers.ZIP == '02747-4302'].CITY.value_counts()
Shrnutí problémů s kvalitou dat zjištěných v SemPy
Graf porušení závislostí ukazuje několik problémů s kvalitou dat v tomto sémantickém modelu:
- Některé názvy měst jsou velká písmena. Tento problém můžete vyřešit pomocí řetězcových metod.
- Některé názvy měst mají kvalifikátory (nebo předpony), například "Sever" a "Východ". Například se PSČ "2128" mapuje jednou na "EAST BOSTON" a jednou na "BOSTON". K podobnému problému dochází mezi "NORTH DARTMOUTH" a "DARTMOUTH". Odstraňte tyto kvalifikátory nebo namapujte PSČ na město s nejběžnějším výskytem.
- V některých názvech měst existují překlepy, například PITTSFIELD vs. PITTSFILED a NEWBURGPORT vs. NEWBURYPORT. V případě newBURGPORT opravte tento překlep pomocí nejběžnějšího výskytu. Pro "PITTSFIELD", který se vyskytuje pouze jednou, je automatické rozlišování nejednoznačnosti mnohem obtížnější bez externích znalostí nebo jazykového modelu.
- Někdy jsou předpony jako "West" zkráceny na jedno písmeno "W". Nahraďte "W" za "West", pokud všechny výskyty "W" stojí pro "West".
- PSČ "02130" se jednou mapuje na "BOSTON" a jednou na "Jamaica Plain". Tento problém se nedá snadno opravit. S větším množstvím dat mapujte na nejběžnější výskyt.
Vyčištění dat
Opravte velká písmena změnou hodnot na velká písmena nadpisu.
providers['CITY'] = providers.CITY.str.title()Znovu spusťte detekci porušení, abyste potvrdili, že existuje méně nejednoznačností.
providers.list_dependency_violations('ZIP', 'CITY')
Data upřesněte ručně nebo odstraňte řádky, které porušují funkční omezení mezi sloupci pomocí funkce SemPy drop_dependency_violations .
Pro každou hodnotu determinantní proměnné drop_dependency_violations vyberete nejběžnější hodnotu závislé proměnné a zahodí všechny řádky s jinými hodnotami. Tuto operaci použijte jenom v případě, že máte jistotu, že tato statistická heuristika vede ke správnému výsledku vašich dat. V opačném případě napište vlastní kód, který bude zpracovávat zjištěná porušení.
drop_dependency_violationsSpusťte funkci naZIPsloupcích aCITYsloupcích.providers_clean = providers.drop_dependency_violations('ZIP', 'CITY')Uveďte všechna porušení závislostí mezi
ZIPaCITY.providers_clean.list_dependency_violations('ZIP', 'CITY')
Kód vrátí prázdný seznam, který označuje, že neexistují žádná další porušení funkčního omezení ZIP -> CITY.
Související obsah
Další kurzy pro sémantický odkaz nebo SemPy:
- kurz : Analýza funkčních závislostí v ukázkovém sémantickém modelu
- Kurz : Extrahování a výpočet měr Power BI z poznámkového bloku Jupyter
- Kurz: Zjišťování relací v sémantickém modelu pomocí sémantického odkazu
- Kurz: Zjišťování relací v datové sadě Synthea pomocí sémantického odkazu
- Výukový program : Ověřování dat pomocí SemPy a Great Expectations (GX)