Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Microsoft Fabric nabízí několik způsobů, jak přenést data do analytického prostředí. Bez ohledu na to, jestli potřebujete zpracovávat události streamování v reálném čase, replikovat provozní databáze, orchestrovat dávkové kanály nebo přistupovat k datům bez jejich kopírování, nabízí Fabric integrované funkce pro podporu jednotlivých scénářů.
Tento článek popisuje primární možnosti příjmu a přesunu dat ve Fabricu. Zahrnuje:
- Příjem dat v reálném čase s využitím Eventstreams a Eventhouse
- Dávková orchestrace s kanály Data Factory a úlohou kopírování
- Replikace téměř v reálném čase se zrcadlením
- Virtualizace dat pomocí klávesových zkratek OneLake
Tento přehled vám umožní pochopit, jak jednotlivé přístupy fungují, a zvolit strategii, která nejlépe vyhovuje vašim požadavkům na úlohy pro latenci, transformaci a provozní složitost.
Příjem dat v reálném čase
Streamy událostí a položky eventhouse v úloze Real-Time Intelligence podporují scénáře streamování dat. Eventstreams ingestuje a zpracovává události v reálném čase a Eventhouses tyto události ve velkém měřítku ukládá a provádí dotazy. K zachycení a směrování dat do eventhouse se obvykle používá eventstream. Každou funkci můžete také používat nezávisle na základě vašich požadavků. Následující diagram znázorňuje, jak datové sady v reálném čase proudí do Eventstream a Eventhouse v Fabricu.
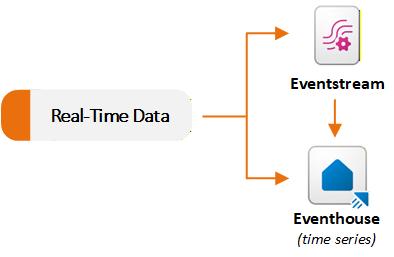
Ingestování a směrování událostí pomocí eventstreamu
Eventstream poskytuje uživatelské prostředí pro práci bez kódu, které umožňuje přijímat události do Fabric, provádět transformace dat v datovém proudu a směrovat data do několika různých cílů. Eventstream funguje jako kanál příjmu dat v reálném čase. Vytvoříte eventstream a přidáte jeden nebo více zdrojových konektorů. Prostředí Fabric podporuje mnoho streamovacích zdrojů, včetně interních událostí jako události pracovního prostoru Fabric, události souborů OneLake a události úloh v pipeline.
Po zahájení toku událostí můžete pomocí editoru přetažení použít volitelné transformace v reálném čase. Můžete například filtrovat události, agregovat údaje v časovém okně, propojit více datových proudů nebo změnit tvar polí bez psaní kódu.
Zpracovaný datový proud můžete odeslat do jednoho nebo více podporovaných cílů. Eventstreamy můžou vystavit koncové body Apache Kafka prostřednictvím vlastních zdrojů a cílů koncových bodů. Díky této funkci mohou producenti Kafka streamovat události do Fabricu a konzumenti Kafka mohou spotřebovávat události z Fabricu.
Eventstreamy neukládají data trvale. Streamují události prostřednictvím paměti a přeposílají je do nakonfigurovaných cílů. Díky tomuto návrhu jsou eventstreamy vhodné pro scénáře extrakce, transformace, načítání (ETL) v reálném čase a pro distribuci streamovaných dat do více cílů. Můžete například ingestovat telemetrii ze senzorů Internetu věcí (IoT), filtrovat a agregovat data v reálném čase, odesílat zpřesněný datový proud do eventhouse pro analýzy a směrovat události anomálií do aktivátoru pro upozorňování.
Ingestování dat přímo do eventhouse
Eventhouses může ingestovat data přímo z více zdrojů. Fabric zahrnuje integrované prostředí Získat data v rámci Eventhouse. Průvodce se připojí ke zdrojům, jako jsou místní soubory, Azure Storage, Amazon S3, Azure Event Hubs a OneLake. Data můžete načíst do databázové tabulky KQL (Kusto Query Language) v reálném čase nebo v dávkovém režimu pomocí uživatelského rozhraní Eventhouse.
Jako zdroj můžete také vybrat existující Eventstream ve Fabric. Pokud například používáte eventstream, který ingestuje data ze služby IoT Hub nebo Kafka, můžete výstup směrovat přímo do tabulky databáze KQL bez další konfigurace.
Příjem dávkových dat
Data Factory poskytuje primární prostředí pro tradiční kanály extrakce, transformace, načítání (ETL) a extrakce, načítání, transformace (ELT). Obsahuje velkou knihovnu konektorů. Fabric Data Factory poskytuje seznam nativních konektorů pro místní a cloudové úložiště dat, včetně databází, aplikací SaaS (software jako služba) a systémů založených na souborech. Tyto konektory vám pomůžou připojit se k téměř jakémukoli zdrojovému systému.
Orchestrace přesunu dat pomocí kanálů
Můžete vytvářet kanály , které tyto konektory používají ke kopírování nebo přesouvání dat do onelake nebo analytických úložišť. Tento přístup podporuje:
- Nestrukturované datové sady, jako jsou obrázky, video a zvuk
- Částečně strukturované datové sady, jako jsou JSON, CSV a XML
- Strukturované datové sady z podporovaných systémů relačních databází
V potrubí zkombinujete více komponent pro orchestraci, včetně:
- Aktivity přesunu dat, jako je kopírování dat a úloha kopírování
- Aktivity transformace dat, jako je Dataflow Gen2, Smazání dat, Fabric Notebook a skript SQL
- Aktivity toku řízení, jako jsou ForEach, Lookup, Set Variable a Webhook
Kanál můžete spustit na vyžádání, podle plánu nebo v reakci na události. Můžete například naplánovat spuštění kanálu každých dvě hodiny v pracovní dny nebo ho aktivovat při vytvoření nového souboru ve OneLake.
Zjednodušení přesunu dat pomocí úlohy kopírování
Úloha kopírování podporuje více vzorů doručení dat, včetně hromadného kopírování, přírůstkové kopie a replikace snímání změn dat (CDC). Úlohu kopírování můžete použít k přesunu dat ze zdroje do OneLake bez vytvoření kanálu a přístupu k pokročilým možnostem konfigurace. Úloha kopírování podporuje mnoho zdrojů a cílů. Nabízí větší kontrolu než synchronizace a menší provozní složitost než správa datových toků, které používají kopírovací aktivitu.
Replikace dat pomocí zrcadlení
Zrcadlení replikuje data z externích systémů do Fabric téměř v reálném čase pomocí automatizovaného nastavení. Připojujete se k externímu systému, jako je Azure SQL Database, SQL Server, Oracle, SAP nebo Snowflake. Fabric průběžně replikují data nebo metadata do OneLake. Zrcadlení podporuje tři typy:
- Zrcadlení databáze replikuje celé databáze a tabulky.
- Zrcadlení metadat synchronizuje metadata, jako jsou názvy katalogů, schémata a tabulky, a to místo fyzického přesouvání dat. Tento přístup využívá optimalizační metody, aby data zůstala ve zdrojovém systému, ale stále byla přístupná v systému Fabric.
- Otevřené zrcadlení používá otevřený formát tabulky Delta Lake. Vývojáři můžou psát změny aplikace přímo na zrcadlenou položku databáze ve OneLake pomocí veřejných rozhraní API.
Fabric naslouchá změnám zdrojového systému (prostřednictvím zachytávání dat změn nebo podobných metod) a tyto změny aplikuje téměř v reálném čase na zrcadlenou kopii. Výsledkem je živá dotazovatelná datová sada, která zůstává synchronizovaná s nízkou latencí bez složitých kanálů ETL.
Zrcadlení aktuálně podporuje různé zdroje, včetně Azure SQL Database, SQL Managed Instance, Azure Cosmos DB, Azure Database for PostgreSQL, Google BigQuery, Oracle, SAP, Snowflake a SQL Serveru. Podporuje také zdroje dat z partnerských řešení, která implementovala rozhraní OPEN Mirroring API. Zrcadlová data se ukládají ve OneLake jako aktuální tabulky Delta. Systém Fabric tyto tabulky automaticky udržuje, abyste je mohli použít k analýze v reálném čase nebo je zkombinovat s dalšími daty systému Fabric. Tato funkce podporuje scénáře hybridního transakčního a analytického zpracování, kdy provozní data nepřetržitě proudí do analytické platformy.
Zrcadlení odstraňuje potřebu manuálního sestavování kanálů přírůstkového načítání. Z pohledu nákladů na zrcadlení se výpočetní operace, které udržují zrcadlené databáze v synchronizaci, nepočítají do jednotek kapacity (CU) vaší kapacity Fabric. Zrcadlené úložiště dat v OneLake je také zdarma až do limitu terabajtů podle SKU Fabric (například F64 zahrnuje 64 TB bezplatného zrcadleného databázového úložiště).
Přístup k externím datům pomocí klávesových zkratek
Fabric poskytuje zkratky pro povolení virtualizace dat. Zástupce ve OneLake odkazuje na data uložená v externím systému, jako je Azure Data Lake Storage Gen2, Amazon S3 nebo SharePoint. Místo kopírování dat umožňují zkratky OneLake odkazovat na externí soubory jako součást sjednoceného datového jezera. Můžete dotazovat nebo připojit externí data s místními daty bez provedení počáteční migrace. Tento přístup pro příjem dat bez kopírování je užitečný v případě, že požadavky na rezidenci dat nebo duplicity brání přesunu dat. Následující diagram znázorňuje, jak klávesové zkratky připojují externí systémy úložiště k položkám Infrastruktury bez kopírování dat:
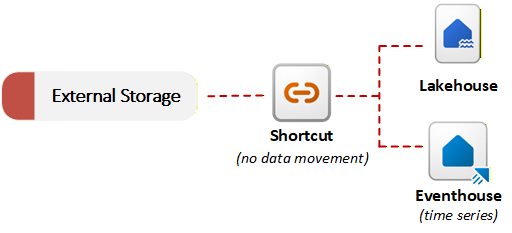
OneLake dokáže rozpoznat datový typ, na který odkazuje zástupce, a použít transformace souborů nebo AI transformace bez nutnosti zpracovatelského řetězce nebo vlastního kódu. OneLake udržuje výslednou tabulku Delta synchronizovanou se zdrojem automaticky. Můžete například převést .csv soubory na tabulky Delta nebo použít analýzu mínění založenou na umělé inteligenci na .txt soubory ve složce.
V kombinaci se zrcadlením poskytují klávesové zkratky flexibilní vzory přístupu k datům. Data můžete uchovávat na místě pomocí klávesových zkratek nebo můžete replikovat data pomocí zrcadlení. V obou případech jsou data připravena pro nástroje Fabric analytics bez složitého ETL.
Průvodce rozhodováním: Volba strategie přesunu dat
Microsoft Fabric nabízí několik možností pro přenos dat do fabric, včetně eventstreamů pro zpracování v reálném čase, zrcadlení, kanály s aktivitami kopírování, úlohou kopírování a zkratkami. Každá možnost nabízí jinou rovnováhu mezi kontrolou, automatizací a provozní složitostí.
Pokyny k výběru vhodného přístupu pro váš scénář najdete v průvodci rozhodováním Microsoft Fabric: Volba strategie přesunu dat.