Direct Lake
Režim Direct Lake je sémantická funkce modelu pro analýzu velmi velkých objemů dat v Power BI. Direct Lake je založené na načítání souborů formátovaných parquet přímo z datového jezera, aniž by se musel dotazovat na koncový bod jezera nebo skladu a nemusel importovat nebo duplikovat data do modelu Power BI. Direct Lake je rychlá cesta k načtení dat z jezera přímo do modulu Power BI připraveného k analýze. Následující diagram znázorňuje porovnání klasických režimů importu a DirectQuery s režimem Direct Lake.
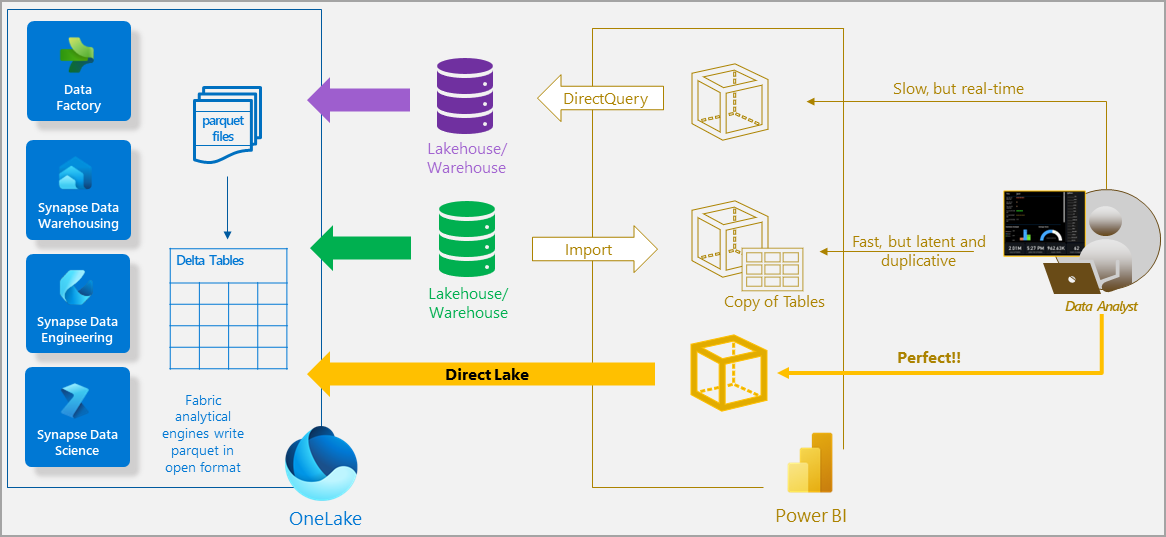
V režimu DirectQuery se modul Power BI dotazuje na data ve zdroji, což může být pomalé, ale nemusí kopírovat data, jako je režim importu. Všechny změny ve zdroji dat se okamžitě projeví ve výsledcích dotazu.
Na druhou stranu s režimem importu může být výkon lepší, protože data se ukládají do mezipaměti a optimalizují pro dotazy na sestavy DAX a MDX bez nutnosti překládat a předávat SQL nebo jiné typy dotazů do zdroje dat. Modul Power BI ale musí během aktualizace nejprve zkopírovat všechna nová data do modelu. Všechny změny ve zdroji se vyberou pouze při příští aktualizaci modelu.
Režim Direct Lake eliminuje požadavek na import načtením dat přímo z OneLake. Na rozdíl od DirectQuery neexistuje žádný překlad z jazyka DAX nebo MDX do jiných dotazovacího jazyka nebo provádění dotazů v jiných databázových systémech, který poskytuje výkon podobný režimu importu. Vzhledem k tomu, že neexistuje žádný explicitní proces importu, je možné při jejich výskytu vyzvednout všechny změny ve zdroji dat a kombinovat výhody režimů DirectQuery i importu a vyhnout se jejich nevýhodám. Režim Direct Lake může být ideální volbou pro analýzu velmi velkých modelů a modelů s častými aktualizacemi ve zdroji dat.
Direct Lake také podporuje zabezpečení na úrovni řádků Power BI a zabezpečení na úrovni objektů, aby uživatelé viděli jenom data, která mají oprávnění k zobrazení.
Požadavky
Direct Lake se podporuje jenom u skladových položek Microsoft Premium (P) a skladových položek Microsoft Fabric (F).
Důležité
Pro nové zákazníky se Direct Lake podporuje jenom u skladových položek Microsoft Fabric (F). Stávající zákazníci můžou dál používat Direct Lake se skladovými položkami Premium (P), ale doporučuje se přechod na skladovou položku kapacity Fabric. Další informace o licencích Power BI Premium najdete v oznámení o licencování.
Jezero
Před použitím Direct Lake musíte zřídit lakehouse (nebo sklad) s jednou nebo více tabulkami Delta v pracovním prostoru hostovaným v podporované kapacitě Microsoft Fabric. Jezero je povinné, protože poskytuje umístění úložiště pro soubory ve formátu parquet v OneLake.
Informace o zřízení jezera, vytvoření tabulky Delta v jezeře a vytvoření základního modelu pro jezero najdete v tématu Vytvoření jezera pro Direct Lakehouse.
Koncový bod sql Analytics a datový sklad
V rámci zřizování jezerahouse se vytvoří a aktualizuje koncový bod analýzy SQL pro dotazování SQL se všemi tabulkami přidanými do jezera. I když režim Direct Lake při načítání dat přímo z OneLake dotazuje koncový bod analýzy SQL, vyžaduje se, když se model Direct Lake musí bez problémů vrátit do režimu DirectQuery, například když zdroj dat používá specifické funkce, jako je pokročilé zabezpečení nebo zobrazení, které se nedají číst přes Direct Lake a musí využívat koncový bod SQL. Režim Direct Lake také pravidelně dotazuje koncový bod SQL na informace související se schématem a zabezpečením.
Jako alternativu ke službě Lakehouse s koncovým bodem SQL Analytics můžete také zřídit sklad a přidat tabulky pomocí příkazů SQL nebo datových kanálů. Postup zřízení samostatného datového skladu je téměř stejný jako postup pro lakehouse.
Výchozí sémantický model Power BI
Sklady a koncové body analýzy SQL také vytvářejí výchozí sémantický model Power BI v režimu Direct Lake. Tento výchozí sémantický model je možné upravit pouze v rámci skladu nebo koncového bodu SQL a má další omezení. Projděte si výchozí dokumentaci k sémantickému modelu Power BI. Tato dokumentace k Direct Lake je určená pro jiné než výchozí sémantické modely Power BI v režimu Direct Lake.
Vytvoření sémantického modelu Power BI v režimu Direct Lake
Sémantické modely Power BI v režimu Direct Lake se vytvářejí v jezeře nebo skladu.
Kliknutím na Nový sémantický model Power BI v Lakehouse vytvoříte sémantický model Power BI v režimu Direct Lake.
V koncovém bodu pro analýzu skladu nebo SQL vyberte pás karet Pro generování sestav a pak vyberte Nový sémantický model Power BI a vytvořte sémantický model Power BI v režimu Direct Lake.
Potom můžete přidat relace, míry, skupiny výpočtů, formátovací řetězce, zabezpečení na úrovni řádků atd., a přejmenovat tabulky a sloupce úpravou sémantického modelu v prohlížeči. Později upravte sémantický model pomocí místní nabídky z pracovního prostoru a otevřete datový model.
Podpora zápisu modelu s koncovým bodem XMLA
Modely Direct Lake podporují operace zápisu prostřednictvím koncového bodu XMLA pomocí nástrojů, jako je SQL Server Management Studio (19.1 a vyšší) a nejnovější verze externích nástrojů BI, jako je tabulkový editor a DAX Studio. Operace zápisu modelu prostřednictvím podpory koncového bodu XMLA:
Přizpůsobení, sloučení, skriptování, ladění a testování metadat modelu Direct Lake
Správa zdrojového kódu a verzí, kontinuální integrace a průběžné nasazování (CI/CD) s Využitím Azure DevOps a GitHubu
Úlohy automatizace, jako je aktualizace a použití změn modelů Direct Lake pomocí PowerShellu a rozhraní REST API
Tabulky Direct Lake vytvořené pomocí aplikací XMLA budou zpočátku v nezpracovaném stavu, dokud aplikace nevystaví příkaz pro aktualizaci. Nezpracované tabulky se vrátí do režimu DirectQuery. Při vytváření nového sémantického modelu nezapomeňte aktualizovat sémantický model pro zpracování tabulek.
Povolení čtení a zápisu XMLA
Před prováděním operací zápisu na modelech Direct Lake prostřednictvím koncového bodu XMLA musí být pro kapacitu povolené čtení a zápis XMLA.
U zkušebních kapacit Fabric má zkušební uživatel oprávnění správce, která jsou nezbytná k povolení čtení a zápisu XMLA.
Na portálu pro správu vyberte Nastavení kapacity.
Vyberte kartu Zkušební verze.
Vyberte kapacitu se zkušební verzí a vaším uživatelským jménem v názvu kapacity.
Rozbalte úlohy Power BI a pak v nastavení koncového bodu XMLA vyberte Čtení zápisu.
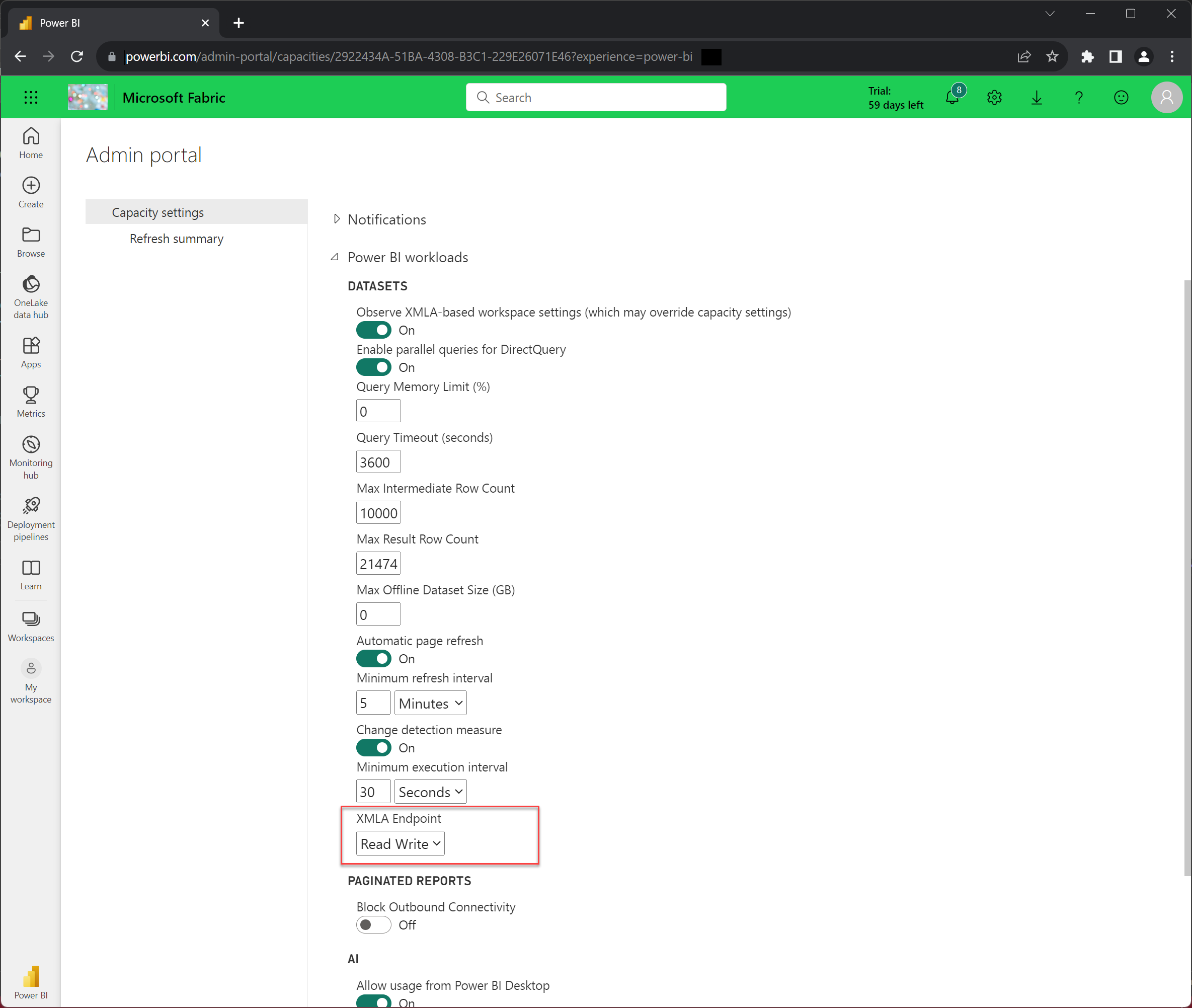
Mějte na paměti, že nastavení koncového bodu XMLA platí pro všechny pracovní prostory a modely přiřazené ke kapacitě.
Metadata modelu Direct Lake
Když se připojujete k samostatnému modelu Direct Lake prostřednictvím koncového bodu XMLA, metadata vypadají jako jakýkoli jiný model. Modely Direct Lake ale ukazují následující rozdíly:
Vlastnost
compatibilityLeveldatabázového objektu je 1604 nebo vyšší.Vlastnost
Modeoddílů Direct Lake je nastavena nadirectLake.Oddíly Direct Lake používají sdílené výrazy k definování zdrojů dat. Výraz odkazuje na koncový bod SQL lakehouse nebo skladu. Direct Lake používá koncový bod SQL ke zjišťování informací o schématu a zabezpečení, ale načítá data přímo z tabulek Delta (pokud se Direct Lake nesmí z nějakého důvodu vrátit do režimu DirectQuery).
Tady je příklad dotazu XMLA v SSMS:
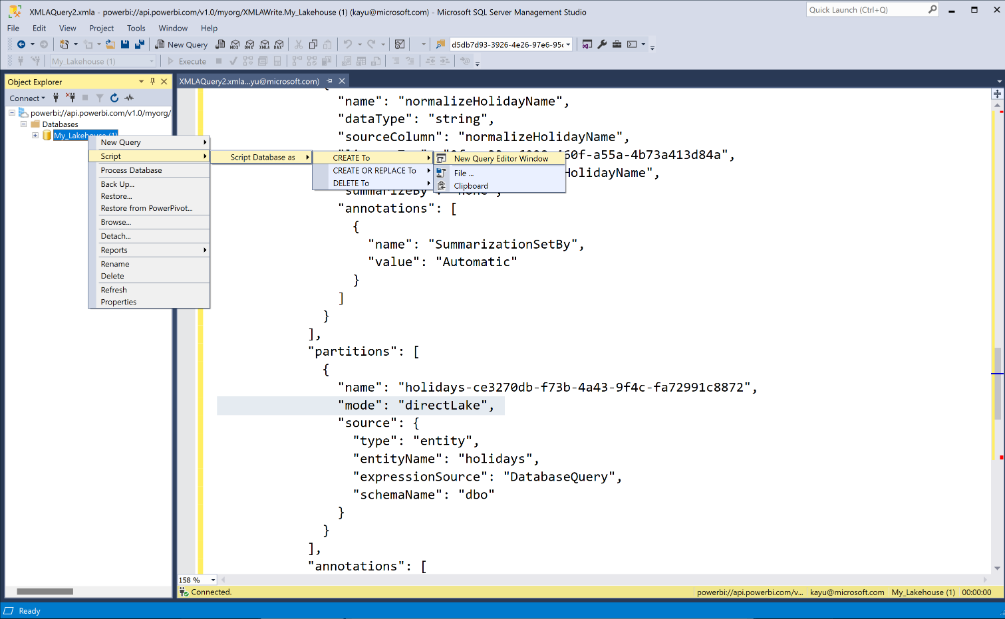
Další informace o podpoře nástrojů prostřednictvím koncového bodu XMLA najdete v tématu Sémantické připojení modelu s koncovým bodem XMLA.
Náhradní téma
Sémantické modely Power BI v režimu Direct Lake čtou tabulky Delta přímo z OneLake. Pokud ale dotaz DAX na modelu Direct Lake překročí limity pro skladovou položku nebo používá funkce, které nepodporují režim Direct Lake, jako jsou zobrazení SQL ve skladu, může se dotaz vrátit do režimu DirectQuery. V režimu DirectQuery dotazy používají SQL k načtení výsledků z koncového bodu SQL lakehouse nebo skladu, což může mít vliv na výkon dotazů. Pokud chcete zpracovávat dotazy DAX pouze v režimu Direct Lake, můžete ho zakázat do režimu DirectQuery. Pokud nepotřebujete náhradní použití DirectQuery, doporučuje se zakázat náhradní použití. Může být také užitečné při analýze zpracování dotazů pro model Direct Lake, abyste zjistili, jestli a jak často dochází k náhradním událostem. Další informace o režimu DirectQuery najdete v tématu Režimy sémantického modelu v Power BI.
Mantinely definují limity prostředků pro režim Direct Lake, za který je pro zpracování dotazů DAX nezbytné náhradní režim DirectQuery. Podrobnosti o tom, jak určit počet souborů parquet a skupin řádků pro tabulku Delta, najdete v odkazu na vlastnosti tabulky Delta.
U sémantických modelů Direct Lake představuje Maximální paměť horní limit prostředků paměti pro množství dat, ve které lze stránkovat. V důsledku toho není ochranné mantinely, protože překročení nezpůsobí náhradní použití DirectQuery; Může však mít dopad na výkon, pokud je množství dat dostatečně velké, aby mohlo způsobit stránkování dat modelu z dat OneLake a z nich.
Následující tabulka uvádí ochranné mantinely prostředků i maximální paměť:
| Skladové položky infrastruktury | Soubory Parquet na tabulku | Skupiny řádků na tabulku | Řádky na tabulku (miliony) | Maximální velikost modelu na disku / OneLake1 (GB) | Maximální paměť (GB) |
|---|---|---|---|---|---|
| F2 | 1 000 | 1 000 | 300 | 10 | 3 |
| F4 | 1 000 | 1 000 | 300 | 10 | 3 |
| F8 | 1 000 | 1 000 | 300 | 10 | 3 |
| F16 | 1 000 | 1 000 | 300 | 20 | 5 |
| F32 | 1 000 | 1 000 | 300 | 40 | 10 |
| F64/FT1/P1 | 5 000 | 5 000 | 1 500 | Bez omezení | 25 |
| F128/P2 | 5 000 | 5 000 | 3 000 | Bez omezení | 50 |
| F256/P3 | 5 000 | 5 000 | 6 000 | Bez omezení | 100 |
| F512/P4 | 10,000 | 10,000 | 12,000 | Bez omezení | 200 |
| F1024/P5 | 10,000 | 10,000 | 24,000 | Bez omezení | 400 |
| F2048 | 10,000 | 10,000 | 24,000 | Bez omezení | 400 |
1 – Pokud dojde k překročení, maximální velikost modelu na disku nebo Onelake způsobí, že se všechny dotazy na model vrátí zpět do DirectQuery, na rozdíl od ostatních mantinely, které se vyhodnocují pro každý dotaz.
V závislosti na skladové poplatku Fabric platí také další jednotka kapacity a maximální velikost paměti na jednotlivé dotazy na modely Direct Lake. Další informace najdete v tématu Kapacity a skladové položky.
Náhradní chování
Modely Direct Lake zahrnují vlastnost DirectLakeBehavior , která má tři možnosti:
Automatické – (výchozí) Určuje dotazy, které se vrátí do režimu DirectQuery , pokud data nelze efektivně načíst do paměti.
DirectLakeOnly – Určuje, že všechny dotazy používají pouze režim Direct Lake. Záložní režim DirectQuery je zakázaný. Pokud data nelze načíst do paměti, vrátí se chyba. Pomocí tohoto nastavení určete, jestli dotazy DAX nenačtou data do paměti a vynutí vrácení chyby.
DirectQueryOnly – Určuje, že všechny dotazy používají pouze režim DirectQuery. Toto nastavení použijte k otestování záložního výkonu.
Vlastnost DirectLakeBehavior lze nakonfigurovat pomocí tabulkového objektového modelu (TOM) nebo jazyka TMSL (Tabular Model Scripting Language).
Následující příklad určuje, že všechny dotazy používají pouze režim Direct Lake:
// Disable fallback to DirectQuery mode.
//
database.Model.DirectLakeBehavior = DirectLakeBehavior.DirectLakeOnly = 1;
database.Model.SaveChanges();
To lze také nastavit při úpravě sémantického modelu v prohlížeči ve vlastnostech sémantického modelu. Na kartě Model v podokně Data vyberte sémantický model.

Analýza zpracování dotazů
Pokud chcete zjistit, jestli vizuál sestavy DAX dotazuje na zdroj dat, poskytuje nejlepší výkon pomocí režimu Direct Lake nebo se vrátíte do režimu DirectQuery, můžete k analýze dotazů použít analyzátor výkonu v Power BI Desktopu, SQL Serveru Profileru nebo jiných nástrojích třetích stran. Další informace najdete v tématu Analýza zpracování dotazů pro modely Direct Lake.
Aktualizovat
Ve výchozím nastavení se změny dat ve OneLake automaticky projeví v modelu Direct Lake. Toto chování můžete změnit tak, že v nastavení modelu zakážete udržování dat Direct Lake v aktualizovaném stavu .

Pokud například potřebujete před zveřejněním nových dat uživatelům modelu povolit dokončení úloh přípravy dat, můžete je zakázat. Pokud je tato možnost zakázaná, můžete aktualizaci vyvolat ručně nebo pomocí rozhraní API aktualizace. Vyvolání aktualizace modelu Direct Lake je operace s nízkými náklady, kde model analyzuje metadata nejnovější verze tabulky Delta Lake a aktualizuje se tak, aby odkazovat na nejnovější soubory v OneLake.
Všimněte si, že Power BI může pozastavit automatické aktualizace tabulek Direct Lake, pokud během aktualizace dojde k nepřesné chybě, takže se ujistěte, že je možné úspěšně aktualizovat sémantický model. Power BI automaticky obnoví automatické aktualizace, když se následná aktualizace vyvolaná uživatelem dokončí bez chyb.
Ve výchozím nastavení je povolené jednotné přihlašování (SSO).
Modely Direct Lake ve výchozím nastavení využívají jednotné přihlašování (SSO) Microsoft Entra pro přístup ke zdrojům dat Fabric Lakehouse a Warehouse a používají identitu uživatele, který s modelem aktuálně pracuje. Konfiguraci můžete zkontrolovat v nastavení modelu Direct Lake rozbalením části Brána a cloudová připojení , jak je znázorněno na následujícím snímku obrazovky. Model Direct Lake nevyžaduje explicitní datové připojení, protože Jezerohouse nebo Warehouse je přímo přístupné a jednotné přihlašování eliminuje potřebu uložených přihlašovacích údajů připojení.
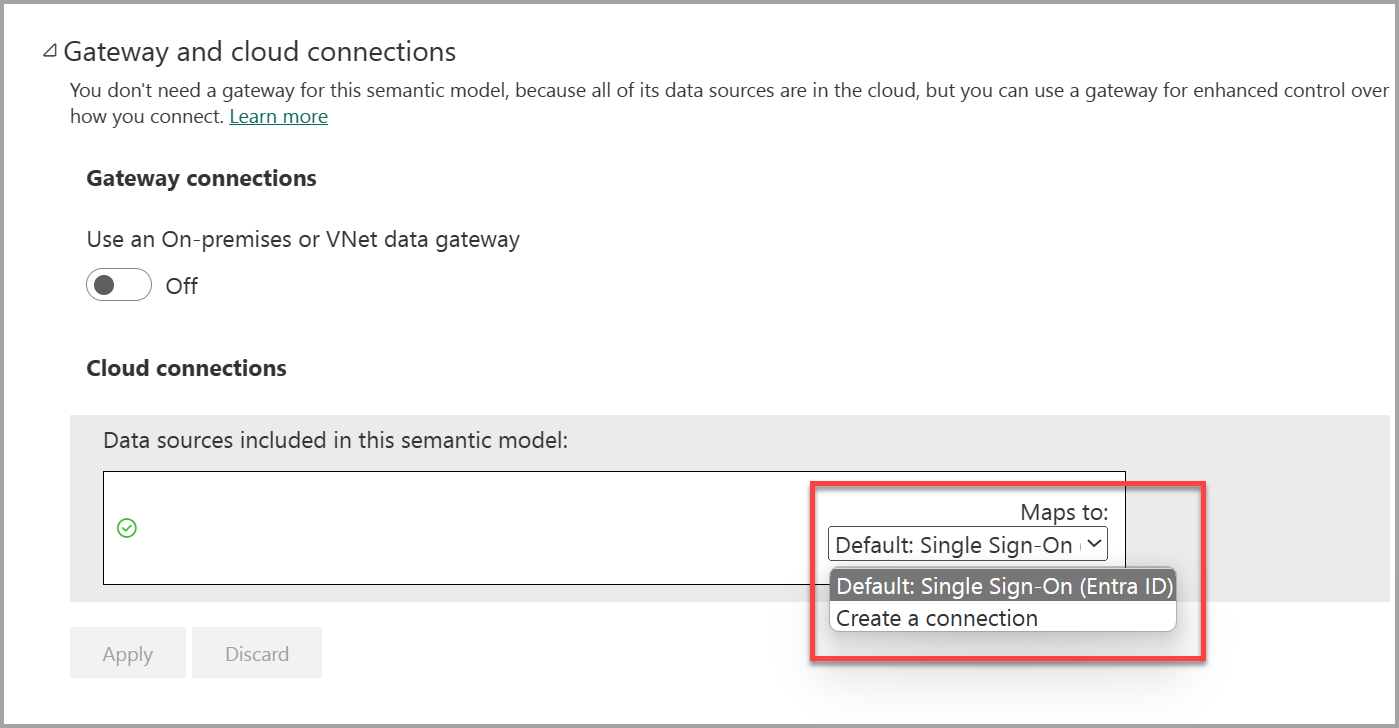
V případech, kdy chcete použít uložené přihlašovací údaje, můžete také explicitně svázat zdroj dat Lakehouse nebo Warehouse s připojením ke cloudovému připojení (SCC), a tím zakázat jednotné přihlašování pro toto připojení ke zdroji dat. Pokud chcete zdroj dat explicitně svázat, v části Brána a cloudová připojení vyberte SCC ze seznamu Mapy na: seznam. Nové připojení můžete vytvořit také tak, že vyberete Vytvořit připojení a pak podle pokynů zadáte název připojení. Dále jako metodu ověřování pro nové připojení vyberte OAuth 2.0 , zadejte požadované přihlašovací údaje a zrušte zaškrtnutí políčka Jednotné přihlašování a pak vytvořte vazbu zdroje dat Lakehouse nebo Warehouse na nové připojení SCC, které jste právě vytvořili.
Výchozí konfigurace připojení: Jednotné přihlašování (Entra ID) zjednodušuje konfiguraci modelu Direct Lake, ale pokud už máte osobní cloudové připojení (PCC) ke zdroji dat Lakehouse nebo Warehouse, model Direct Lake se automaticky sváže s odpovídajícími PCC tak, aby nastavení připojení, která jste už definovali pro zdroj dat, se okamžitě použila. Měli byste potvrdit konfiguraci připojení modelů Direct Lake, abyste zajistili, že modely přistupují ke zdrojům dat Fabric se správným nastavením.
Sémantické modely můžou používat výchozí konfiguraci připojení s jednotným přihlašováním (Entra ID) pro Fabric Lakehouses a Warehouses v režimu Direct Lake, Import a DirectQuery. Všechny ostatní zdroje dat vyžadují explicitně definovaná datová připojení.
Zabezpečení přístupu k datům ve vrstvách
Modely Direct Lake vytvořené nad lakehousem a sklady dodržují model vrstveného zabezpečení, který lakehouses a sklady podporují, provedením kontrol oprávnění prostřednictvím koncového bodu T-SQL a zjistěte, jestli identita, která se pokouší o přístup k datům, má požadovaná oprávnění pro přístup k datům. Modely Direct Lake ve výchozím nastavení používají jednotné přihlašování (SSO), takže efektivní oprávnění interaktivního uživatele určují, jestli je uživatel povolený nebo odepřený přístup k datům. Pokud je model Direct Lake nakonfigurovaný tak, aby používal pevnou identitu, efektivní oprávnění pevné identity určuje, jestli uživatelé pracující s sémantickým modelem mají přístup k datům. Koncový bod T-SQL vrátí do modelu Direct Lake povolené nebo odepřené na základě kombinace zabezpečení OneLake a oprávnění SQL.
Správce skladu může například udělit uživateli oprávnění SELECT v tabulce, aby uživatel mohl číst z této tabulky, i když uživatel nemá žádná oprávnění zabezpečení OneLake. Uživatel byl autorizovaný na úrovni jezera nebo skladu. Naopak správce skladu může uživateli odepřít přístup ke čtení tabulky. Uživatel pak nebude moct číst z této tabulky, i když má uživatel oprávnění ke čtení zabezpečení OneLake. Příkaz DENY přerušuje všechna udělená oprávnění k zabezpečení OneLake nebo SQL. V následující tabulce najdete platná oprávnění, která může uživatel udělit libovolnou kombinaci zabezpečení OneLake a oprávnění SQL.
| Oprávnění zabezpečení OneLake | Oprávnění SQL | Efektivní oprávnění |
|---|---|---|
| Povolit | Nic | Povolit |
| Nic | Povolit | Povolit |
| Povolit | Odepřít | Odepřít |
| Nic | Odepřít | Odepřít |
Známé problémy a omezení
Návrhem podporují režim Direct Lake pouze tabulky v sémantickém modelu odvozené z tabulek v Lakehouse nebo Warehouse. I když tabulky v modelu můžou být odvozeny ze zobrazení SQL v Lakehouse nebo Warehouse, dotazy používající tyto tabulky se vrátí do režimu DirectQuery.
Tabulky sémantických modelů Direct Lake lze odvozovat pouze z tabulek a zobrazení z jediného objektu Lakehouse nebo Warehouse. Jeden lakehouse může obsahovat zástupce přidané z jiných objektů Lakehouse.
Dotazy využívající zabezpečení na úrovni řádků u tabulek ve skladu (včetně koncového bodu Analýzy SQL Lakehouse) se vrátí do režimu DirectQuery.
Tabulky Direct Lake se momentálně nedají kombinovat s jinými typy tabulek, jako je Import, DirectQuery nebo Duální, ve stejném modelu. Složené modely v sémantických modelech Power BI můžou jako zdroj používat sémantické modely Power BI v režimu úložiště Direct Lake.
Relace DateTime nejsou podporovány v modelech Direct Lake. Podporují se relace kalendářních dat.
Počítané sloupce a počítané tabulky se nepodporují. Podporují se skupiny výpočtů a parametry polí.
Některé datové typy nemusí být podporované, například desetinné čárky s vysokou přesností a typy peněz.
Tabulky Direct Lake nepodporují složité typy sloupců tabulky Delta. Binární a guid sémantické typy jsou také nepodporované. Tyto datové typy je nutné převést na řetězce nebo jiné podporované datové typy.
Relace mezi tabulkami vyžadují, aby se datové typy jejich klíčových sloupců shodovaly. Sloupce primárního klíče musí obsahovat jedinečné hodnoty. Dotazy DAX selžou, pokud se zjistí duplicitní hodnoty primárního klíče.
Délka hodnot řetězcového sloupce je omezená na 32 764 znaků Unicode.
Hodnota s plovoucí desetinnou čárkou NaN (ne číslo) se v modelech Direct Lake nepodporuje.
Scénáře Power BI Embedded, které spoléhají na vložené entity, se zatím nepodporují.
Ověřování je omezené pro modely Direct Lake. Uživatelské výběry se předpokládají správně a žádné dotazy neověřují kardinalitu a výběry křížového filtru pro relace nebo pro vybraný sloupec kalendářních dat v tabulce kalendářních dat.
Karta Direct Lake v historii aktualizace obsahuje pouze chyby aktualizace související s Direct Lake. Úspěšné aktualizace jsou aktuálně vynechány.
Začínáme
Nejlepším způsobem, jak začít s řešením Direct Lake ve vaší organizaci, je vytvořit v ní tabulku Lakehouse, vytvořit v ní tabulku Delta a pak vytvořit základní sémantický model pro lakehouse v pracovním prostoru Microsoft Fabric. Další informace najdete v tématu Vytvoření jezera pro Direct Lake.
Související obsah
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro