Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Sémantické modely Power BI můžou zahrnovat tabulky z jednoho nebo více zdrojů dat pomocí některého z podporovaných režimů úložiště tabulek. Pokud tabulky používají různé režimy úložiště, jedná se o složený sémantický model. Pro režim úložiště tabulek DirectQuery je model kompozitní, pokud tabulky DirectQuery využívají různé zdroje dat.
Pokud se například připojíte k jinému sémantickému modelu Power BI pomocí DirectQuery (který přidává tabulky v režimu úložiště DirectQuery) a máte také místní tabulky v režimu importu, stane se váš model složeným modelem, protože obsahuje tabulky s různými režimy úložiště.
Poznámka:
Import tabulek z jednoho nebo více zdrojů dat se nestanou složenými modely, dokud je nezkombinujete s tabulkami, které nejsou importované. Stejné pravidlo platí pro sémantické modely s tabulkami Direct Lake z jednoho nebo více zdrojů dat.
Poznámka:
U složených modelů se předpokládá, že režim úložiště tabulek Direct Lake je Direct Lake na OneLake. Direct Lake v režimu úložiště tabulek SQL je pouze jeden zdroj a nedá se přidat do žádného složeného modelu. Další informace o rozdílech v režimu úložiště tabulek Direct Lake najdete na aka.ms/DirectLake.
Typy složených modelů
V závislosti na kombinaci režimů úložiště tabulek v sémantickém modelu existují různé typy složených modelů. Každý typ má své vlastní aspekty funkčnosti a nástrojů.
| Typ složeného modelu | Dostupné nástroje | Poznámky |
|---|---|---|
| DirectQuery do jiného sémantického modelu Power BI s nebo bez dalších tabulek v režimu úložiště importu nebo DirectQuery | Jen Power BI Desktop | Připojte se k sémantickému modelu Power BI a po přidání tabulky v režimu importu nebo úložiště DirectQuery zvolte Provést změny tohoto modelu nebo se připojit. |
| Tabulky DirectQuery pocházející z různých zdrojů dat | Jen Power BI Desktop | Například tabulka A pochází z databáze SQL A a tabulka B pochází z databáze SQL B. |
| Import a tabulky DirectQuery ve stejném sémantickém modelu | Jen Power BI Desktop | |
| Import a tabulky Direct Lake ve stejném sémantickém modelu | Pouze webové modelování Power BI | Tabulky Import nebo Direct Lake je možné přidat v Desktopu, ale kombinovat je pouze ve webovém modelování. |
| Tabulky DirectQuery a Direct Lake ve stejném sémantickém modelu | Pouze XMLA | Zkombinujte pomocí skriptu XMLA nebo nástrojů založených na komunitě XMLA. Lze otevřít ve webovém modelování pouze pro sémantické úpravy modelu, bez možnosti aktualizace nebo změn v tabulkách. |
Vytváření složených modelů v Power BI Desktopu
V Power BI Desktopu můžete vytvářet sémantické modely s tabulkami importu nebo DirectQuery místně. Potom můžete přidat další tabulky z tlačítka Získat data na pásu karet v jiném režimu úložiště a vytvořit složený model.
Poznámka:
Pokud jsou tabulky importu i DirectQuery v sémantickém modelu a pocházejí ze stejného zdroje dat, je k dispozici duální režim úložiště. Duální režim používaný místo DirectQuery se může vyhnout omezeným relacím s tabulkami importu. Další informace najdete v režimu duálního úložiště.
Přidání tabulek DirectQuery z jiného sémantického modelu Power BI má několik různých cest vytvoření.
V prázdném souboru Power BI se nejprve připojte k sémantickému modelu Power BI. Po živém připojení máte možnost provést změny v tomto modelu. Výběrem možnosti Provedení změn v tomto modelu na pásu karet nebo v zápatí převedete živé připojení na připojení DirectQuery. Připojení DirectQuery vytvoří nový místní sémantický model s tabulkami v režimu úložiště DirectQuery. Nové tabulky můžete přidat v režimu úložiště importu nebo DirectQuery a také můžete přepsat některé vlastnosti sloupce ve zdrojovém sémantickém modelu.
Připojte se k sémantickému modelu Power BI, který již obsahuje tabulky importu nebo DirectQuery, a zvolené tabulky se přidají jako DirectQuery.
Sémantické modely vytvořené pomocí tabulek Direct Lake se v Power BI Desktopu upravují živě. Můžete přidat další tabulky Direct Lake. Pokud chcete přidat tabulky importu, otevřete sémantický model ve webovém modelování Power BI. Pokud chcete přidat tabulky DirectQuery, použijte XMLA.
V Desktopu můžete živě upravit sémantický model Direct Lake a importovat ho, ale nemůžete přidat další tabulky. Tabulky můžete přidávat jenom z webového modelování Power BI pro Direct Lake a importovat složené modely.
Vytváření složených modelů ve webovém modelování
Ve webovém modelování Power BI můžete vytvářet sémantické modely s importem nebo tabulkami Direct Lake. Nemůžete přidat tabulky DirectQuery. Pokud chcete vytvořit složený model, můžete přidat další tabulky v jiném režimu úložiště.
Použití složených modelů
Ve složených modelech se můžete připojit k různým druhům zdrojů dat, když používáte Power BI Desktop nebo služba Power BI. Tato datová připojení můžete nastavit několika způsoby:
- Importem dat do Power BI, což je nejběžnější způsob, jak získat data.
- Připojením přímo k datům v původním zdrojovém úložišti pomocí DirectQuery. Další informace o DirectQuery najdete v tématu DirectQuery v Power BI.
Při použití DirectQuery umožňují složené modely vytvořit model Power BI, například jeden soubor .pbix Power BI Desktopu, který provede jednu nebo obě následující akce:
- Kombinuje data z jednoho nebo více zdrojů DirectQuery.
- Kombinuje data ze zdrojů DirectQuery a importuje data.
Pomocí složených modelů můžete například vytvořit model, který kombinuje následující typy dat:
- Prodejní data z podnikového datového skladu
- Prodejní cílová data z databáze SQL Serveru oddělení
- Data importovaná z tabulky
Sémantický model kombinující tabulky z více než jednoho zdroje DirectQuery nebo kombinování tabulek DirectQuery, Direct Lake a import je složený sémantický model.
Relace mezi tabulkami můžete vytvářet tak, jak jste vždy měli, i když tyto tabulky pocházejí z různých zdrojů. Všechny relace, které jsou mezi zdroji, se vytvářejí s kardinalitou M:N bez ohledu na jejich skutečnou kardinalitu. Můžete je změnit na 1:N, M:1 nebo 1:1. Bez ohledu na kardinalitu, kterou nastavíte, mají relace mezi zdroji jiné chování. Funkce DAX (Data Analysis Expressions) nemůžete použít k načtení hodnot na one straně ze many strany. Můžete také vidět dopad na výkon oproti relacím M:N ve stejném zdroji.
Poznámka:
V kontextu složených modelů jsou všechny importované tabulky efektivně jediným zdrojem bez ohledu na skutečné podkladové zdroje dat.
Příklad složeného modelu
Pro příklad složeného modelu zvažte sestavu, která se připojuje k podnikovému datovému skladu v SQL Serveru pomocí DirectQuery. V tomto případě datový sklad obsahuje data Sales by Country, Quarter a Bike (Product), jak je znázorněno na následujícím obrázku:
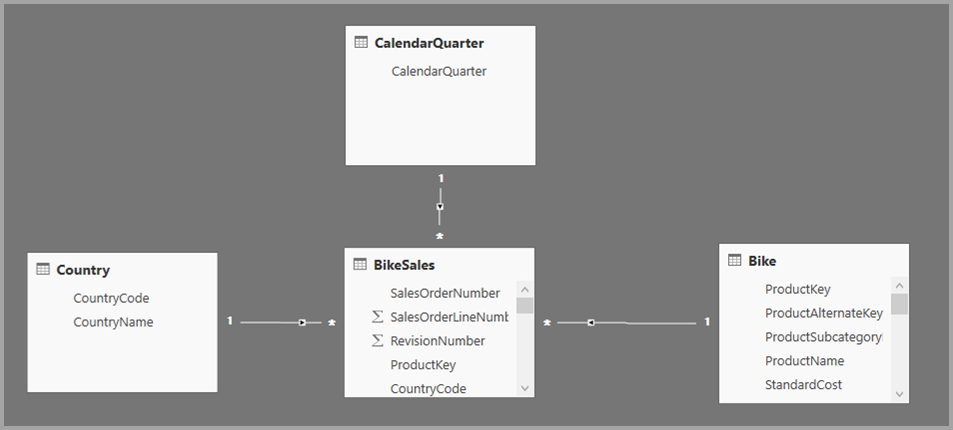
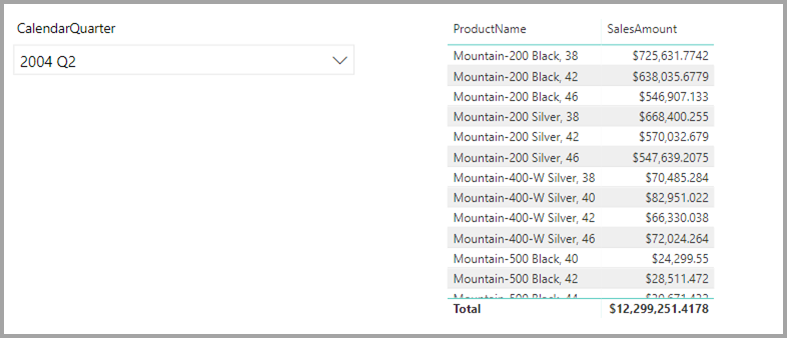
V tomto okamžiku můžete vytvářet jednoduché vizuály pomocí polí z tohoto zdroje. Následující obrázek znázorňuje celkový prodej podle ProductName pro vybrané čtvrtletí.
Ale co když máte data v excelové tabulce o produktových manažerech přiřazených jednotlivým produktům spolu s prioritou marketingu? Pokud chcete zobrazit prodejní částku podle produktového manažera, nemusí být možné tato místní data přidat do podnikového datového skladu. Nebo to může trvat měsíce v nejlepším.
Místo použití DirectQuery může být možné importovat prodejní data z datového skladu. Data o prodeji se pak dají zkombinovat s daty, která jste naimportovali z tabulky. Tento přístup je však nepřiměřený z důvodů, které vedly k používání DirectQuery na prvním místě. Mezi důvody může patřit:
- Některá kombinace pravidel zabezpečení vynucovaných v podkladovém zdroji.
- Je potřeba zobrazit nejnovější data.
- Horizontální měřítko dat.
Tady jsou složené modely. Složené modely umožňují připojit se k datovému skladu pomocí DirectQuery a pak použít Získat data pro další zdroje. V tomto příkladu nejprve vytvoříme připojení DirectQuery k podnikovému datovému skladu. Používáme Získat data, zvolte Excel a pak přejdeme do tabulky, která obsahuje naše místní data. Nakonec naimportujeme tabulku, která obsahuje názvy produktů, přiřazeného manažera prodeje a prioritu.
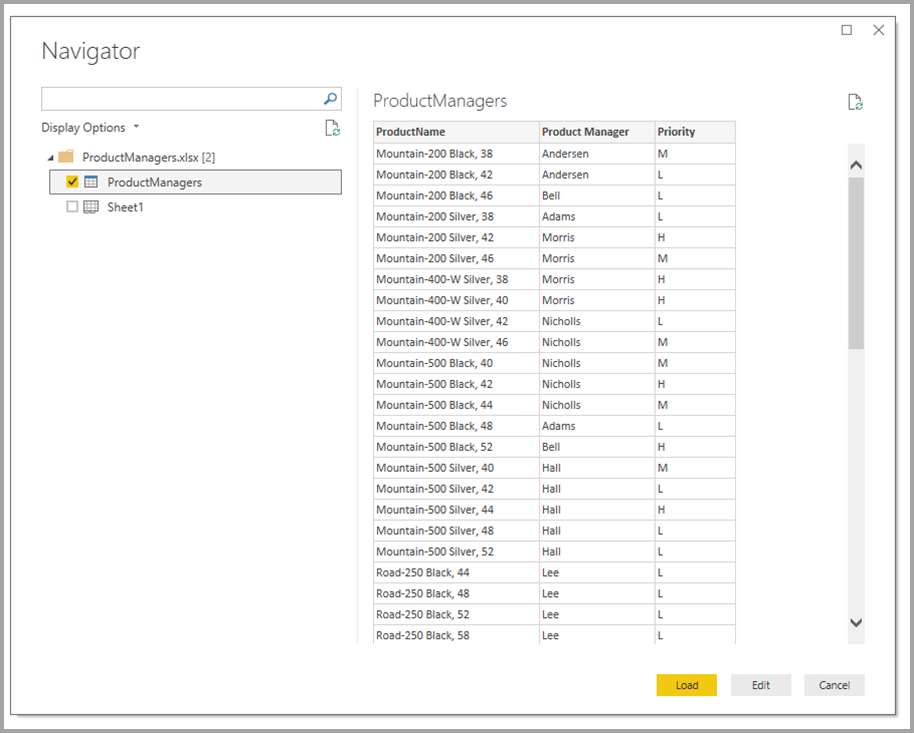
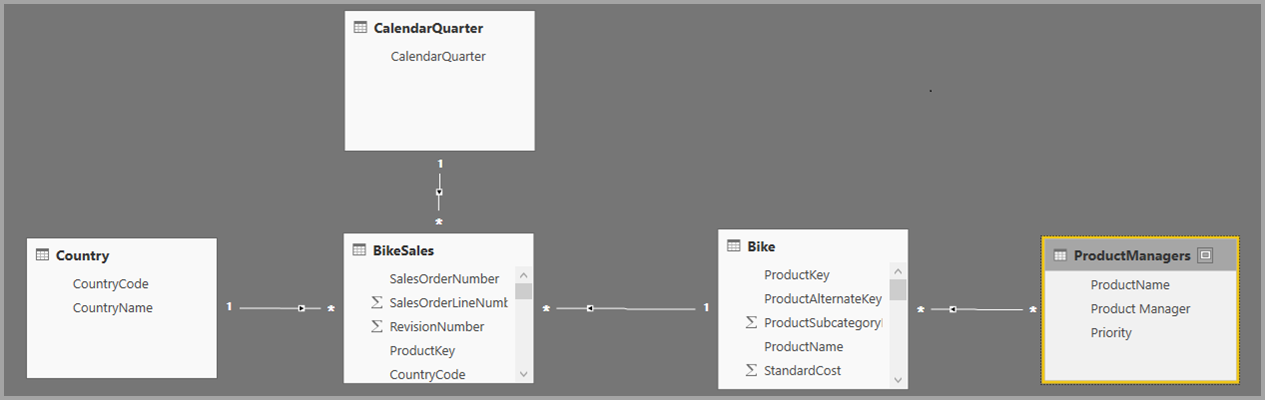
V seznamu Pole můžete vidět dvě tabulky: původní tabulku Bike z SQL Serveru a novou tabulku ProductManagers. Nová tabulka obsahuje data importovaná z Excelu.
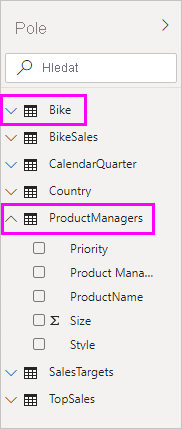
Podobně v zobrazení Relace v Power BI Desktopu teď vidíme další tabulku s názvem ProductManagers.
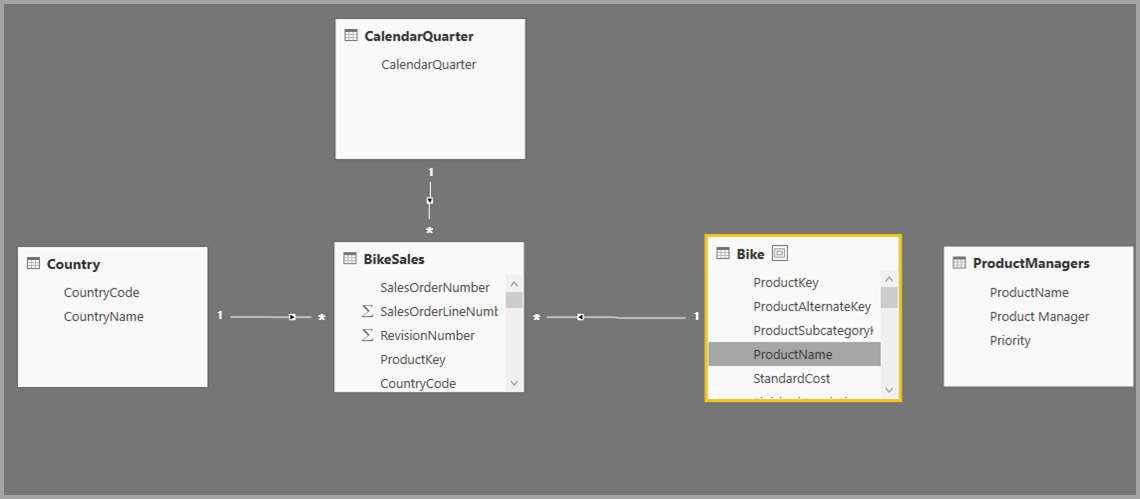
Teď musíme tyto tabulky propojit s ostatními tabulkami v modelu. Jako vždy vytvoříme relaci mezi tabulkou Bike z SQL Serveru a importovanou tabulkou ProductManagers. To znamená, že relace je mezi Bike[ProductName] a ProductManagers[ProductName]. Jak je popsáno dříve, všechny relace, které přecházejí mezi zdroji, mají výchozí kardinalitu M:N.
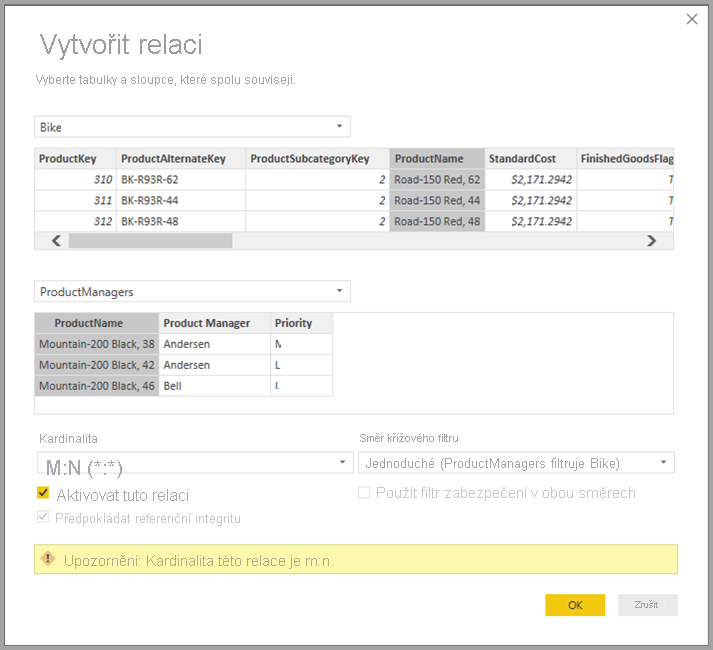
Teď, když jsme vytvořili tuto relaci, se zobrazí v zobrazení Relace v Power BI Desktopu, jak bychom očekávali.
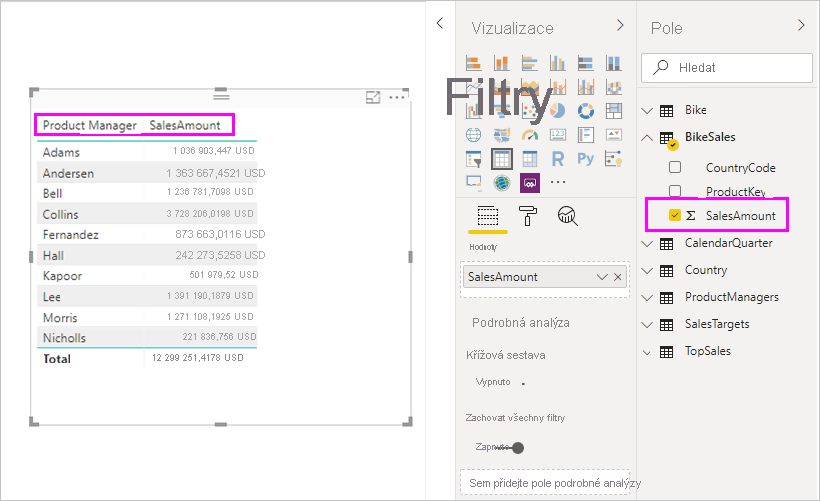
Vizuály teď můžeme vytvářet pomocí libovolného pole v seznamu Pole . Tento přístup bezproblémově kombinuje data z více zdrojů. Například celkový objem prodeje pro každého produktového manažera se zobrazí na následujícím obrázku:
Následující příklad ukazuje běžný případ tabulky dimenzí , například Product nebo Customer, která se rozšiřuje o další data importovaná z jiného někam jinam. K připojení k různým zdrojům je také možné použít DirectQuery. Abychom mohli pokračovat v našem příkladu, představte si, že prodejní cíle na zemi a období jsou uložené v samostatné databázi oddělení. Jako obvykle můžete pomocí funkce Získat data připojit k datům, jak je znázorněno na následujícím obrázku:
Stejně jako dříve můžeme vytvořit relace mezi novou tabulkou a dalšími tabulkami v modelu. Pak můžeme vytvořit vizuály, které kombinují data tabulky. Pojďme se znovu podívat na zobrazení Relace , kde jsme vytvořili nové relace:
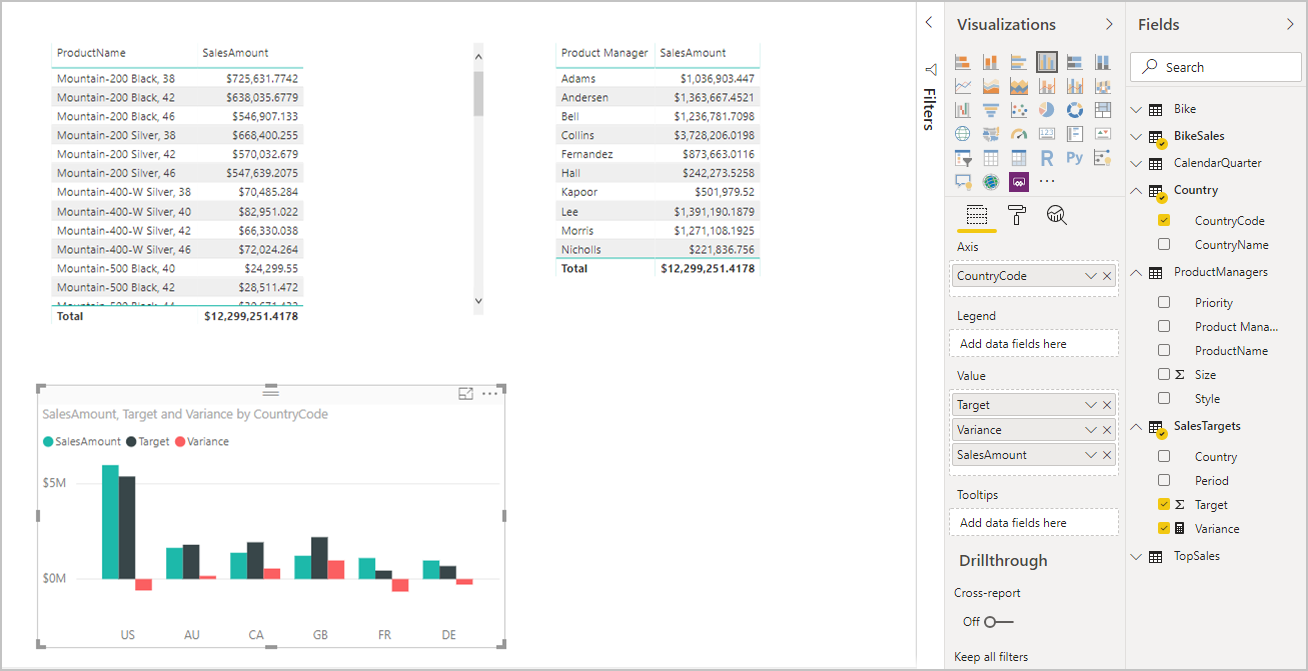
Další obrázek vychází z nových dat a relací, které jsme vytvořili. Vizuál v levém dolním rohu zobrazuje celkovou částku prodeje a cíl a výpočet odchylky ukazuje rozdíl. Data Sales Amount a Target pocházejí ze dvou různých databází SQL Serveru.
Nastavení režimu úložiště
Každá tabulka ve složeného modelu má režim úložiště, který označuje, jestli je tabulka založená na DirectQuery nebo importu. Režim úložiště můžete zobrazit a upravit v podokně Vlastnosti . Zobrazení režimu úložiště:
- V zobrazení Model vyberte tabulku.
- V podokně Vlastnosti rozbalte oddíl Upřesnit a potom rozbalte seznam Režim úložiště .
Režim úložiště můžete zobrazit také v popisu každé tabulky, když na ni najedete myší v podokně Data .
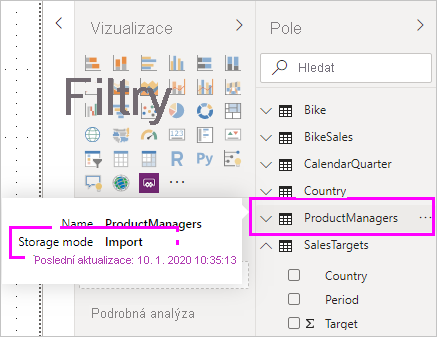
U libovolného souboru Power BI Desktopu (souboru .pbix ), který obsahuje některé tabulky z DirectQuery a některých importovaných tabulek, se na stavovém řádku zobrazí režim úložiště s názvem Smíšený. Tento termín můžete vybrat na stavovém řádku a snadno přepnout všechny tabulky k importu.
Další informace o režimu úložiště najdete v tématu Správa režimu úložiště v Power BI Desktopu.
Poznámka:
Režim smíšeného úložiště můžete použít v Power BI Desktopu a v služba Power BI.
Počítané tabulky
Počítané tabulky můžete přidat do modelu v Power BI Desktopu, který používá DirectQuery. Jazyk DAX (Data Analysis Expressions), který definuje počítanou tabulku, může odkazovat na importované tabulky nebo tabulky DirectQuery nebo na jejich kombinaci.
Počítané tabulky se vždy naimportují a při aktualizaci tabulek se aktualizují jejich data. Pokud počítaná tabulka odkazuje na tabulku DirectQuery, vizuály, které odkazují na tabulku DirectQuery, vždy zobrazují nejnovější hodnoty v podkladovém zdroji. Případně vizuály, které odkazují na počítanou tabulku, zobrazují hodnoty v době poslední aktualizace počítané tabulky.
Důležité
Počítané tabulky nejsou ve službě Power BI podporované pomocí této funkce, pokud nesplníte konkrétní požadavky. Další informace najdete v části Práce se složeným modelem založeným na sémantickém modelu v tomto článku.
Vliv na zabezpečení
Složené modely mají určité dopady na zabezpečení. Dotaz odeslaný do jednoho zdroje dat může obsahovat hodnoty dat načtené z jiného zdroje. V předchozím příkladu vizuál, který zobrazuje (Sales Amount) podle product managera , odešle dotaz SQL do relační databáze Sales. Tento dotaz SQL může obsahovat názvy produktových manažerů a jejich přidružených produktů.

Informace uložené v tabulce jsou teď zahrnuty do dotazu odeslaného do relační databáze. Pokud jsou tyto informace důvěrné, měli byste zvážit důsledky zabezpečení. Zejména zvažte následující body:
Tyto informace může zobrazit jakýkoli správce databáze, který může zobrazit trasování nebo protokoly auditu, i bez oprávnění k datům v původním zdroji. V tomto příkladu potřebuje správce oprávnění k excelovém souboru.
Nastavení šifrování pro každý zdroj. Chcete zabránit načtení informací z jednoho zdroje šifrovaným připojením a pak neúmyslně zahrnout do dotazu odeslaného do jiného zdroje nešifrovaným připojením.
Power BI Desktop zobrazí při vytváření složeného modelu zprávu s upozorněním, aby se ověřilo, že jste zvážili všechny dopady na zabezpečení.
Kromě toho, pokud autor přidá Tabulku1 z modelu A do složeného modelu (pojďme ho volat Model C pro referenci), pak uživatel, který zobrazí sestavu vytvořenou na modelu C , může dotazovat jakoukoli tabulku v modelu A , která není chráněna zabezpečením na úrovni řádků (RLS).
Z podobných důvodů buďte opatrní, když otevřete soubor Power BI Desktopu odeslaný z nedůvěryhodného zdroje. Pokud soubor obsahuje složené modely, informace, které někdo načte z jednoho zdroje, pomocí přihlašovacích údajů uživatele, který soubor otevře, se odešle do jiného zdroje dat jako součást dotazu. Informace by mohl zobrazit škodlivý autor souboru Power BI Desktopu. Při počátečním otevření souboru Power BI Desktopu, který obsahuje více zdrojů, power BI Desktop zobrazí upozornění. Upozornění se podobá upozornění zobrazenému při otevření souboru, který obsahuje nativní dotazy SQL.
Vliv na výkon
Při použití DirectQuery vždy zvažte výkon. Ujistěte se, že back-endový zdroj má dostatek prostředků pro zajištění dobrého prostředí pro uživatele. Dobrý zážitek znamená, že se vizuály aktualizují za pět sekund nebo méně. Další rady k výkonu najdete v tématu DirectQuery v Power BI.
Použití složených modelů přidává další aspekty výkonu. Jeden vizuál může odesílat dotazy do více zdrojů. Jeden dotaz často předává výsledky druhému zdroji. Tato situace může mít za následek následující formy provádění:
Dotaz zdroje, který obsahuje velký počet hodnot doslova: Například vizuál, který požaduje celkovou částku z prodeje pro soubor vybraných produktových manažerů, by nejprve potřeboval zjistit, které produkty tito produktoví manažeři spravují. K této sekvenci musí dojít před odesláním dotazu SQL, který obsahuje všechna ID produktů v
WHEREklauzuli.Zdrojový dotaz, který se dotazuje na nižší úroveň členitosti, s tím, jak se data později agregují místně: S rostoucím počtem produktů , které splňují kritéria filtru pro ProduktOvý manažer , může být neefektivní nebo neproveditelné zahrnout všechny produkty do
WHEREklauzule. Místo toho můžete dotazovat relační zdroj na nižší úrovni produktů a pak výsledky agregovat místně. Pokud kardinalita produktů překročí limit 1 milion, dotaz selže.Více zdrojových dotazů, jeden na skupinu podle hodnoty: Pokud agregace používá DistinctCount a je seskupené podle sloupce z jiného zdroje a pokud externí zdroj nepodporuje efektivní předávání mnoha hodnot literálů, které definují seskupení, je potřeba odeslat jeden dotaz SQL na skupinu podle hodnoty.
Vizuál, který žádá jedinečný počet CustomerAccountNumber z tabulky SQL Server podle produktových manažerů importovaných z tabulky, musí předat podrobnosti z tabulky produktových manažerů v dotazu odeslaném na SQL Server. U jiných zdrojů je například tato akce neproveditelná. Místo toho by se na manažera prodeje odeslal jeden dotaz SQL, a to až do určitého praktického limitu, kdy dotaz selže.
Každý z těchto případů má své vlastní důsledky na výkon a přesné podrobnosti se u každého zdroje dat liší. I když kardinalita sloupců použitých v relaci, která spojuje tyto dva zdroje, zůstává nízká (několik tisíc), nemělo by to mít vliv na výkon. S rostoucí kardinalitou věnujte větší pozornost dopadu na výsledný výkon.
Kromě toho použití relací M:N znamená, že samostatné dotazy musí být odeslány do podkladového zdroje pro každou celkovou nebo mezisoučtovou úroveň, a nikoli agregace podrobných hodnot místně. Jednoduchý vizuál tabulky se součty odesílá dva zdrojové dotazy, nikoli jeden.
Zdrojové skupiny
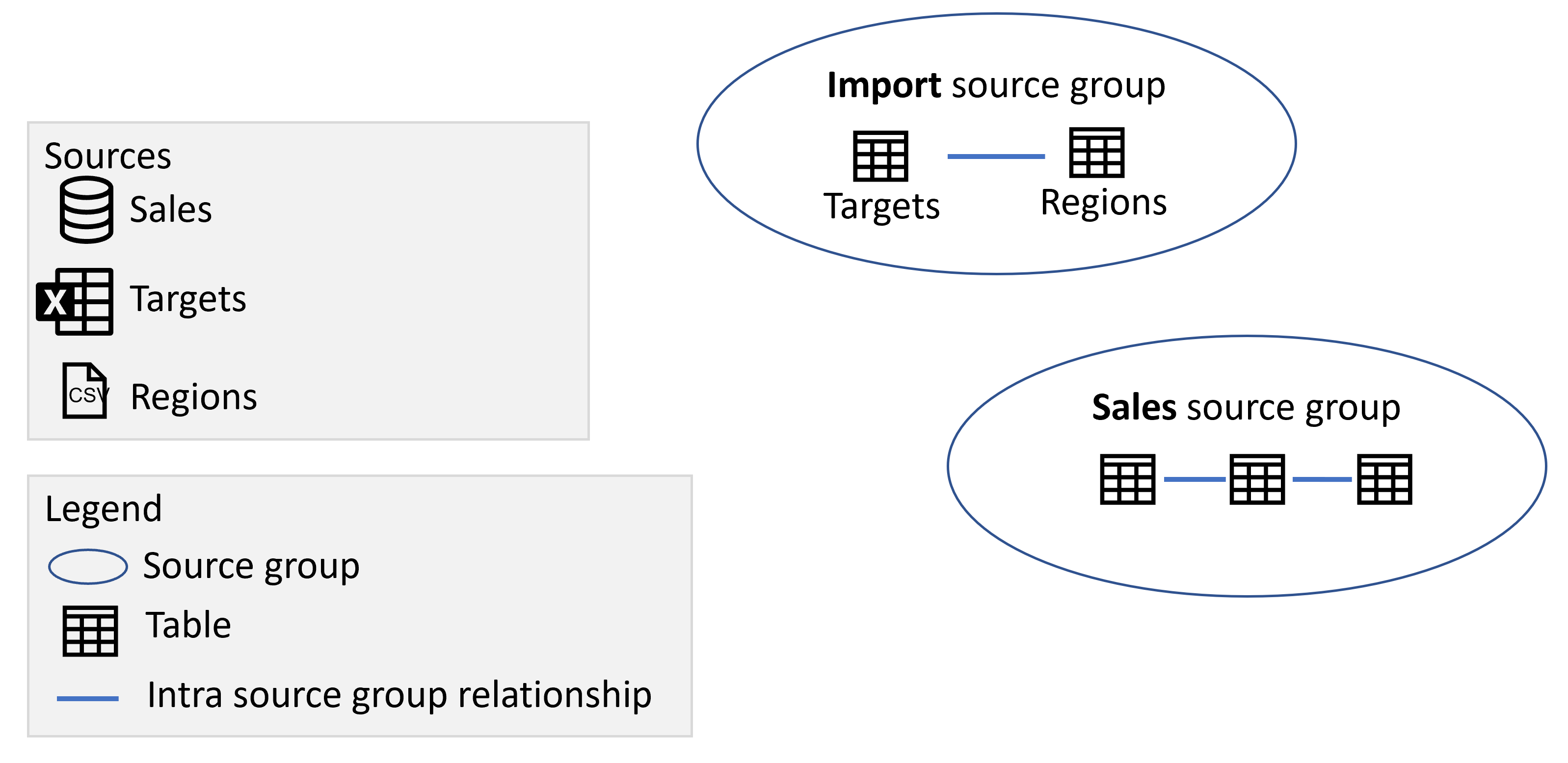
Zdrojová skupina je kolekce položek, jako jsou tabulky a relace, ze zdroje DirectQuery nebo všech zdrojů importu zahrnutých v datovém modelu. Složený model se skládá z jedné nebo více zdrojových skupin. Zvažte následující příklady:
- Složený model, který se připojuje k sémantickému modelu Power BI s názvem Prodej a rozšiřuje sémantický model přidáním míry Sales YTD , která není k dispozici v původním sémantickém modelu. Tento model se skládá z jedné zdrojové skupiny.
- Složený model, který kombinuje data importem tabulky z excelového listu s názvem Cíle a soubor CSV s názvem Oblasti a vytvoření připojení DirectQuery k sémantickému modelu Power BI s názvem Prodej. V tomto případě existují dvě zdrojové skupiny, jak je znázorněno na následujícím obrázku:
- První zdrojová skupina obsahuje tabulky z excelového listu Cíle a soubor CSV oblasti .
- Druhá zdrojová skupina obsahuje položky z sémantického modelu Sales Power BI.
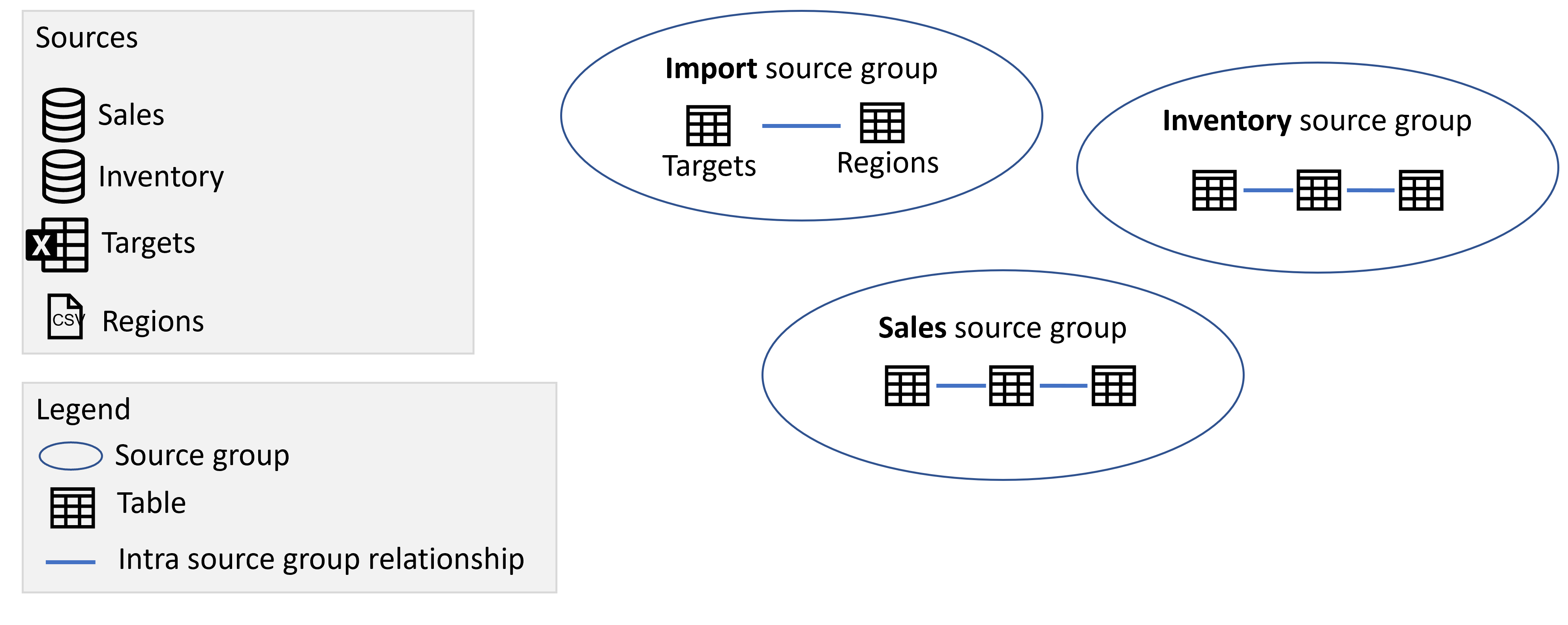
Pokud přidáte další připojení DirectQuery k jinému zdroji, jako je například připojení DirectQuery k databázi SQL Serveru s názvem Inventory, položky z tohoto zdroje se přidají jako jiná zdrojová skupina:
Poznámka:
Import dat z jiného zdroje nepřidá jinou zdrojovou skupinu, protože všechny položky ze všech importovaných zdrojů jsou v jedné zdrojové skupině. Tabulky Direct Lake a importu se také považují za stejnou zdrojovou skupinu.
Zdrojové skupiny a relace
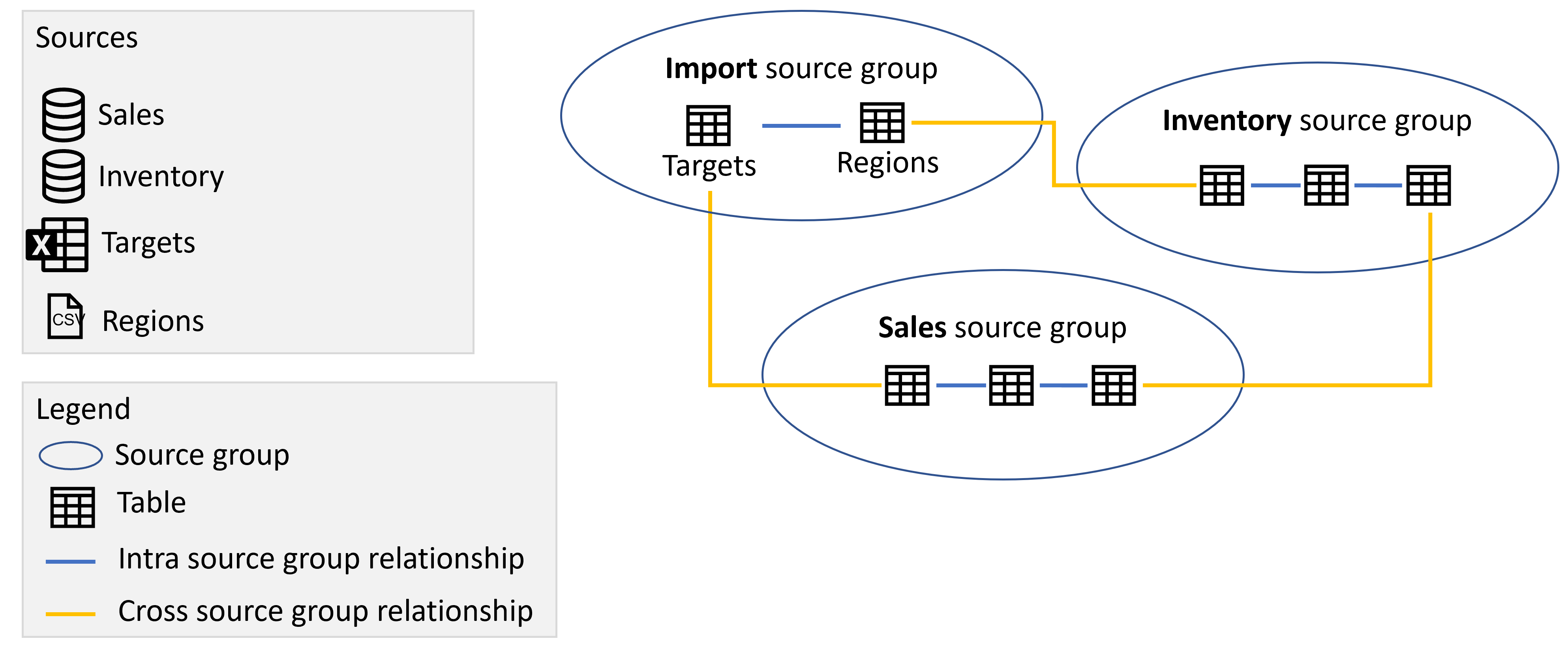
Složený model má dva typy relací:
- Vztahy uvnitř zdrojové skupiny. Tyto relace spojují položky ve zdrojové skupině. Tyto relace jsou vždy běžné, pokud nejsou M:N, v takovém případě jsou omezené.
- Vztahy mezi zdrojovými skupinami Tyto relace začínají v jedné zdrojové skupině a končí jinou zdrojovou skupinou. Tyto relace jsou vždy omezené.
Přečtěte si další informace o rozlišení mezi pravidelnými a omezenými relacemi a jejich dopadem.
Například na následujícím obrázku jsme přidali tři relace mezi zdrojovými skupinami, které vzájemně souvisejí s tabulkami mezi různými zdrojovými skupinami:
Místní a vzdálené
Jakákoli položka ve zdrojové skupině, která je zdrojovou skupinou DirectQuery , je vzdálená, pokud ji místně nedefinujete jako součást rozšíření nebo rozšiřování zdroje DirectQuery a není součástí vzdáleného zdroje, jako je míra nebo počítaná tabulka. Počítaná tabulka založená na tabulce ze zdrojové skupiny DirectQuery patří do zdrojové skupiny Import a je místní. Libovolná položka ve zdrojové skupině Import je místní. Pokud například ve složeného modelu definujete následující míru, která používá připojení DirectQuery ke zdroji inventáře, je míra místní:
[Average Inventory Count] = Average(Inventory[Inventory Count])
Skupiny výpočtů, dotazování a vyhodnocení míry
Skupiny výpočtů pomáhají snížit počet redundantních měr a seskupit společné výrazy měr. Typické případy použití zahrnují výpočty časové inteligence, kdy chcete přepnout ze skutečných hodnot na výpočty pro měsíc k dnešnímu dni, čtvrtletí k dnešnímu dni nebo rok k dnešnímu dni. Při práci s složenými modely je důležité vědět o interakci mezi skupinami výpočtů a o tom, jestli míra odkazuje jenom na položky z jedné vzdálené zdrojové skupiny. Pokud míra odkazuje pouze na položky z jedné vzdálené zdrojové skupiny a vzdálený model definuje skupinu výpočtů, která má vliv na míru, použije se skupina výpočtů, i když míru definujete ve vzdáleném modelu nebo v místním modelu. Pokud však míra neodkazuje výhradně na položky z jedné vzdálené zdrojové skupiny, ale odkazuje na položky ze vzdálené zdrojové skupiny, na které se používá vzdálená skupina výpočtů, mohou být výsledky míry stále ovlivněny vzdálenou skupinou výpočtů. Představte si následující příklad:
- Reseller Sales je míra definovaná ve vzdáleném modelu.
- Vzdálený model obsahuje skupinu výpočtů, která změní výsledek prodeje zprostředkovatelů.
- Internet Sales je míra definovaná v místním modelu.
- Total Sales je míra definovaná v místním modelu a má následující definici:
[Total Sales] = [Internet Sales] + [Reseller Sales]
V tomto scénáři není míra Internet Sales ovlivněna skupinou výpočtů definovanou ve vzdáleném modelu, protože nejsou součástí stejného modelu. Skupina výpočtů ale může změnit výsledek míry Reseller Sales , protože jsou ve stejném modelu. Tento fakt znamená, že výsledky vrácené mírou Total Sales musí být pečlivě vyhodnoceny. Představte si, že pomocí výpočetní skupiny ve vzdáleném modelu získáte výsledky od začátku roku do současného data. Výsledek vrácený reseller sales je nyní hodnotou od roku do data, zatímco výsledek vrácený internetovým prodejemje stále skutečný. Výsledek celkového prodeje je teď pravděpodobně neočekávaný, protože přidá skutečný výsledek od roku do data.
Složené modely v sémantických modelech Power BI a službě Analysis Services
Pomocí sémantických modelů Power BI a Analysis Services můžete vytvořit složený model pomocí připojení DirectQuery pro připojení k sémantickým modelům Power BI, Azure Analysis Services (AAS) a SQL Serveru 2022 Analysis Services. Složený model umožňuje kombinovat data v těchto zdrojích s jinými directquery a importovanými daty. Autoři sestav, kteří chtějí kombinovat data ze svého podnikového sémantického modelu s jinými daty, která vlastní, jako je excelová tabulka, nebo chtějí přizpůsobit nebo rozšířit metadata ze svého podnikového sémantického modelu, budou tyto funkce zvlášť užitečné.
Správa složených modelů v sémantických modelech Power BI
Pokud chcete vytvářet a používat složené modely v sémantických modelech Power BI, musí mít váš tenant povolené následující přepínače:
- Povolit koncové body XMLA a analyzovat v aplikaci Excel pomocí místních sémantických modelů Pokud tento přepínač zakážete, nemůžete vytvořit připojení DirectQuery k sémantickému modelu Power BI.
- Uživatelé můžou pracovat s sémantických modelů Power BI v Excelu pomocí živého připojení. Pokud tento přepínač zakážete, uživatelé nemůžou provádět živá připojení k sémantickým modelům Power BI, aby tlačítko Provést změny tohoto modelu nebylo dostupné.
- Povolte připojení DirectQuery k sémantickým modelům Power BI. Další informace o tomto přepínači a jeho účinku najdete v následujících odstavcích.
Pro kapacity Premium a režim Premium na uživatele by navíc mělo být povoleno nastavení "Koncový bod XMLA" a nastaveno na hodnotu "Čtení" nebo "Čtení/Zápis".
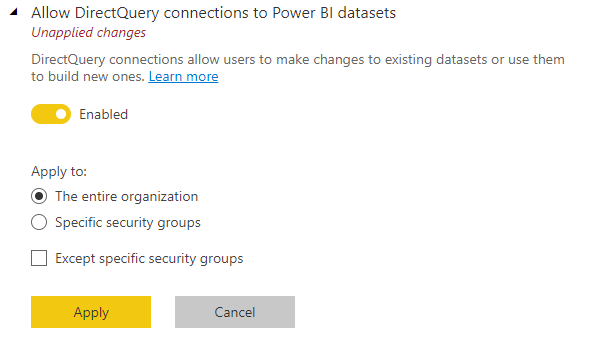
Správci tenantů můžou na portálu pro správu povolit nebo zakázat připojení DirectQuery k sémantickým modelům Power BI. I když je toto nastavení ve výchozím nastavení povolené, zakázání zabrání uživatelům v publikování nových složených modelů v sémantických modelech Power BI do služby.
Stávající sestavy, které používají složený model v sémantickém modelu Power BI, nadále fungují. Uživatelé můžou i nadále vytvářet složený model v Power BI Desktopu, ale nemůžou ho publikovat do služby. Když místo toho vytvoříte připojení DirectQuery k sémantickému modelu Power BI výběrem možnosti Provést změny v tomto modelu, zobrazí se následující zpráva s upozorněním:
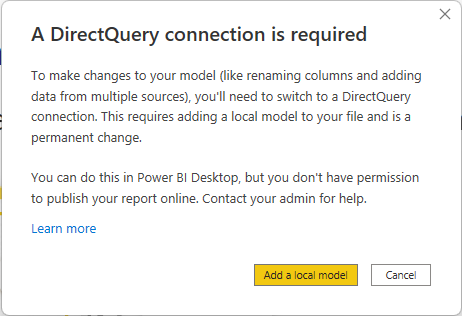
Tímto způsobem můžete stále zkoumat sémantický model v místním prostředí Power BI Desktopu a vytvořit složený model. Sestavu ale nemůžete publikovat do služby. Při publikování sestavy a modelu se zobrazí následující chybová zpráva a publikace je blokovaná:
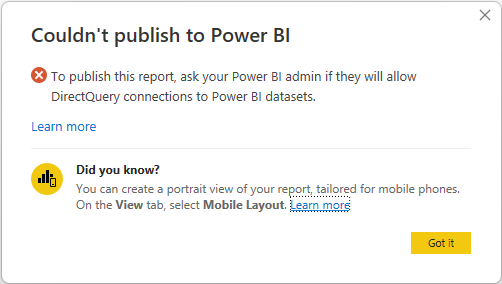
Živá připojení k sémantickým modelům Power BI nejsou ovlivněná přepínačem ani živými nebo directquery připojeními ke službě Analysis Services. Tato připojení nadále fungují bez ohledu na nastavení přepínače. Všechny publikované sestavy, které používají složený model v sémantickém modelu Power BI, budou dále fungovat, i když je přepínač po jejich publikování vypnut.
Vytvoření složeného modelu na sémantickém modelu nebo modelu
Pokud chcete vytvořit složený model na sémantickém modelu Power BI nebo modelu Analysis Services, vaše sestava potřebuje místní model. Můžete začít z živého připojení a přidat nebo upgradovat na místní model nebo začít s připojením DirectQuery nebo importovanými daty, které automaticky vytvoří místní model v sestavě.
Pokud chcete zjistit, která připojení se v modelu používají, zkontrolujte stavový řádek v pravém dolním rohu Power BI Desktopu. Pokud jste připojení jenom ke zdroji analysis Services, zobrazí se zpráva podobná následujícímu obrázku:

Pokud jste připojeni k sémantickému modelu Power BI, zobrazí se zpráva, která vám sdělí, k jakému sémantickému modelu Power BI jste připojeni.

Pokud chcete přizpůsobit metadata polí v živém připojeném sémantickém modelu, na stavovém řádku vyberte Provést změny tohoto modelu . Alternativně můžete vybrat tlačítko Provést změny tohoto modelu na pásu karet, jak je znázorněno na následujícím obrázku. V zobrazení sestavy je tlačítko Provést změny tohoto modelu na kartě Modelování. V zobrazení modelu je tlačítko na kartě Domů.

Když tlačítko vyberete, zobrazí se dialogové okno, které potvrzuje přidání místního modelu. Výběrem možnosti Přidat místní model povolíte vytváření nových sloupců nebo upravíte metadata polí ze sémantických modelů Power BI nebo analysis Services. Na následujícím obrázku je dialogové okno.
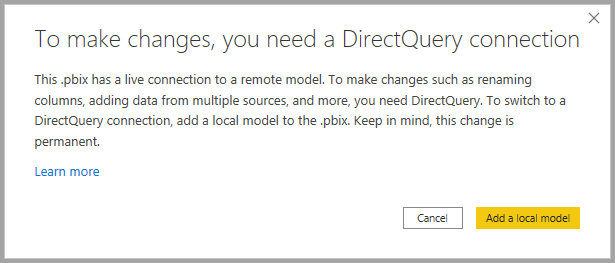
Když jste živě připojení ke zdroji Analysis Services, neexistuje žádný místní model. Pokud chcete directQuery použít pro živé připojené zdroje, jako jsou sémantické modely Power BI a Analysis Services, musíte do sestavy přidat místní model. Když publikujete sestavu s místním modelem do služby Power BI, publikuje se i sémantický model pro tento místní model.
Řetězení
Sémantické modely a sémantické modely, na kterých jsou založené, tvoří řetězec. Tento proces označovaný jako řetězení umožňuje publikovat sestavu a sémantický model založený na jiných sémantických modelech Power BI.
Představte si například, že váš kolega publikuje sémantický model Power BI s názvem Prodej a rozpočet na základě modelu Analysis Services s názvem Prodej a kombinuje ho s excelovým listem s názvem Rozpočet. Pak vytvoříte a publikujete složený sémantický model a sestavu s názvem Sales and Budget Europe pomocí sémantického modelu Sales and Budget Power BI s vlastními úpravami. Tento sémantický model je třetí v řetězci.
- Prvním řetězem je model Sales Analysis Services.
- Druhý řetězec je složený sémantický model Sales and Budget Power BI.
- Třetím řetězcem je složený sémantický model Power BI sales and Budget Europe .
Následující obrázek vizualizuje tento proces řetězení.
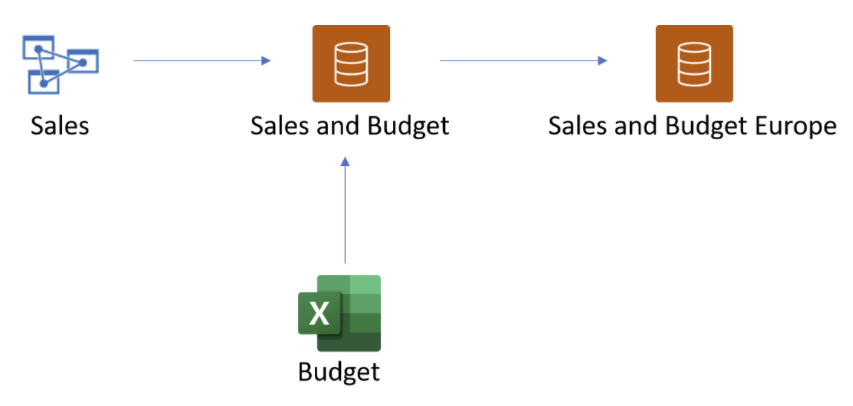
Délka řetězce na předchozím obrázku je tři, což je maximální délka. Rozšíření nad rámec délky řetězce tří se nepodporuje a vede k chybám.
Oprávnění a licencování
Uživatelé, kteří přistupují k sestavám pomocí složeného modelu, potřebují správná oprávnění pro všechny sémantické modely a modely v řetězu.
Vlastník složeného modelu potřebuje oprávnění k sestavení pro sémantické modely používané jako zdroje, aby k těmto modelům mohli přistupovat jiní uživatelé jménem vlastníka. V důsledku toho vytvoření připojení složeného modelu v Power BI Desktopu nebo vytváření sestavy v Power BI vyžaduje oprávnění k sestavení pro sémantické modely používané jako zdroje.
Uživatelé, kteří zobrazují sestavy pomocí složeného modelu, obvykle potřebují oprávnění ke čtení samotného složeného modelu a sémantických modelů používaných jako zdroje. Oprávnění k sestavení se můžou vyžadovat, pokud jsou sestavy v pracovním prostoru Pro. Tyto přepínače tenanta by měly být pro uživatele povolené.
Následující příklad znázorňuje požadovaná oprávnění:
Složený model A (vlastněný vlastníkem A)
- Zdroj dat A1: Sémantický model B.
Vlastník A musí mít oprávnění ke sestavování na sémantickém modelu B, aby uživatelé mohli sestavu zobrazit, která používá složený model A.
- Zdroj dat A1: Sémantický model B.
Složený model C (vlastněný vlastníkem C)
- Zdroj dat C1: Sémantický model D
Vlastník C musí mít oprávnění k sestavení pro sémantický model D , aby uživatelé mohli zobrazit sestavu, která používá složený model C. - Zdroj dat C2: Složený model A
Vlastník C musí mít oprávnění k sestavení pro složený model A a oprávnění ke čtení pro sémantický model B.
- Zdroj dat C1: Sémantický model D
Uživatel, který zobrazuje sestavy používající složený model A , musí mít oprávnění ke čtení pro složený model A i sémantický model B, zatímco uživatel, který zobrazuje sestavy používající složený model C , musí mít oprávnění ke čtení pro složený model C, sémantický model D, složený model A a sémantický model B.
Poznámka:
Další informace najdete v tématu Oprávnění požadovaná pro složené modely v sémantických modelech Power BI a modelech Analysis Services.
Pokud je nějaká datová sada v řetězci v pracovním prostoru Premium na uživatele, uživatel, který k ní přistupuje, potřebuje licenci Premium na uživatele. Pokud je nějaká datová sada v řetězci v pracovním prostoru Pro, uživatel, který k ní přistupuje, potřebuje licenci Pro. Pokud jsou všechny datové sady v řetězci v kapacitách Premium nebo Fabric F64 nebo větší kapacitě, může k ní uživatel přistupovat pomocí bezplatné licence.
Upozornění zabezpečení
Když použijete složené modely v sémantických modelech Power BI a funkci modelů Analysis Services , zobrazí se dialogové okno upozornění zabezpečení, které je znázorněno na následujícím obrázku.
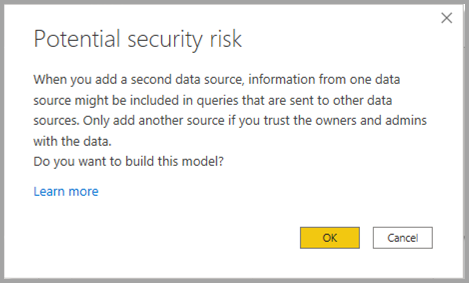
Data mohou být přenášena z jednoho zdroje dat do druhého zdroje dat. Toto upozornění zabezpečení platí pro kombinování DirectQuery a import zdrojů v datovém modelu. Další informace o tomto chování najdete v tématu Použití složených modelů v Power BI Desktopu.
Podporované scénáře
Složené modely můžete vytvářet pomocí dat z sémantických modelů Power BI nebo modelů Analysis Services, které budou obsluhovat následující scénáře:
- Připojení k datům z různých zdrojů: Import (například soubory), sémantické modely Power BI, modely Analysis Services
- Vytváření relací mezi různými zdroji dat
- Napsat míry, které používají pole z různých zdrojů dat
- Vytváření nových sloupců pro tabulky z sémantických modelů Power BI nebo modelů Analysis Services
- Vytváření vizuálů, které používají sloupce z různých zdrojů dat
- Odeberte tabulku z modelu pomocí seznamu polí, aby modely zůstaly co nejstručnější a nejefektivnější (pokud se připojíte k perspektivě, nemůžete z modelu odebrat tabulky)
- Určete, které tabulky se mají načíst, a nemusíte načítat všechny tabulky, pokud chcete jenom konkrétní podmnožinu tabulek. Viz Načtení podmnožina tabulek dále v tomto dokumentu.
- Určete, zda chcete přidat jakékoli tabulky, které později přidáte do sémantického modelu po vytvoření připojení v modelu.
Práce se složeným modelem založeným na sémantickém modelu
Při práci s DirectQuery pro sémantické modely Power BI a Analysis Services zvažte následující informace:
Pokud aktualizujete zdroje dat a dojde k chybám s konfliktními názvy polí nebo tabulek, Power BI chyby vyřeší za vás.
Nemůžete upravovat, odstraňovat ani vytvářet nové relace ve stejném sémantickém modelu Power BI nebo ve zdroji Analysis Services. Pokud máte k těmto zdrojům přístup pro úpravy, můžete změny provést přímo ve zdroji dat.
Nemůžete změnit datové typy sloupců načtených ze sémantického modelu Power BI nebo ze zdroje Analysis Services. Pokud potřebujete datový typ změnit, změňte ho ve zdroji nebo použijte počítaný sloupec.
Pokud chcete vytvářet sestavy ve službě Power BI na složeném modelu založeném na jiném sémantickém modelu, musíte nastavit všechny přihlašovací údaje.
Připojení k serveru SQL Server 2022 a novějšímu serveru Analysis Services místně nebo IAAS vyžadují místní bránu dat (režim Standard).
Všechna připojení ke vzdáleným sémantickým modelům Power BI používají jednotné přihlašování. Ověřování pomocí instančního objektu se v současné době nepodporuje.
Pravidla RLS se vztahují na zdroj, na kterém jsou definovaná, ale nevztahují se na žádné jiné sémantické modely v rámci modelu. Zabezpečení na úrovni řádků definované v sestavě se nevztahuje na vzdálené zdroje dat a zabezpečení na úrovni řádků nastavené na vzdálené zdroje dat se nevztahuje na jiné zdroje dat. Nemůžete také definovat zabezpečení na úrovni řádků v tabulce načtené ze vzdáleného zdroje a zabezpečení na úrovni řádků definované v místních tabulkách nefiltruje žádné tabulky načtené ze vzdáleného zdroje.
Klíčové ukazatele výkonu, zabezpečení na úrovni řádků a překlady se neimportují ze zdroje.
Při použití hierarchie kalendářních dat se může zobrazit neočekávané chování. Pokud chcete tento problém vyřešit, použijte místo toho sloupec kalendářních dat. Po přidání hierarchie kalendářních dat do vizuálu můžete přepnout na sloupec kalendářních dat tak, že v názvu pole vyberete šipku dolů a pak místo použití hierarchie kalendářních dat vyberete název tohoto pole:
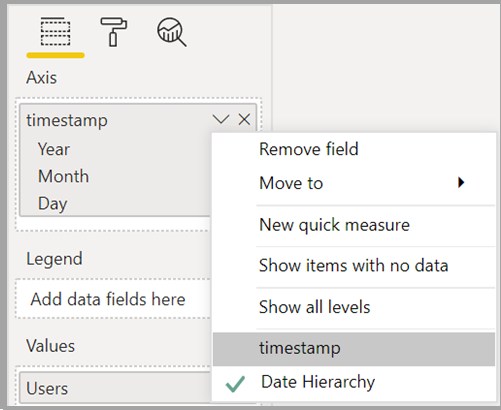
Další informace o používání sloupců kalendářních dat a hierarchií kalendářních dat najdete v tématu Použití automatického data nebo času v Power BI Desktopu.
Maximální délka řetězce modelů je tři. Rozšíření nad rámec délky řetězce tří se nepodporuje a vede k chybám.
Příznak odrazující řetězení u modelu můžete nastavit tak, aby bylo zabráněno vytvoření nebo rozšíření řetězu. Další informace najdete v tématu Správa připojení DirectQuery k publikovanému sémantickému modelu.
Power Query nezobrazuje připojení k sémantickému modelu Power BI ani k modelu Analysis Services.
Při práci s DirectQuery pro sémantické modely Power BI a Analysis Services platí následující omezení :
- Parametry pro názvy databází a serverů jsou aktuálně zakázané.
- Definování zabezpečení na úrovni řádků u tabulek ze vzdáleného zdroje se nepodporuje.
- Použití některého z následujících zdrojů jako zdroje DirectQuery se nepodporuje:
- tabulkové modely Služba Analysis Services serveru SQL (SSAS) před verzí 2022
- Multidimenzionální modely SSAS
- SAP HANA
- SAP Business Warehouse
- Sémantické modely v reálném čase
- Ukázkové sémantické modely
- Aktualizace Excelu Online
- Data importovaná ze souborů Excelu nebo CSV ve službě
- Metriky využití
- Sémantické modely uložené v pracovním prostoru
- Použití Power BI Embedded se sémantickými modely, které obsahují připojení DirectQuery k externímu modelu Analysis Services (Azure Analysis Services nebo SQL Server Analysis Services), se v současné době nepodporuje.
- Publikování sestavy na web pomocí funkce publikovat na webu se nepodporuje.
- Skupiny výpočtů ve vzdálených zdrojích nejsou podporovány s nedefinovanými výsledky dotazů.
- Počítané tabulky a počítané sloupce odkazující na tabulku DirectQuery ze zdroje dat s ověřováním jednotného přihlašování (SSO) jsou podporovány v služba Power BI s přiřazeným sdíleným cloudovým připojením nebo podrobným řízením přístupu.
- Pokud po nastavení připojení DirectQuery přejmenujete pracovní prostor, musíte aktualizovat zdroj dat v Power BI Desktopu, aby sestava nadále fungovala.
- Automatická aktualizace stránky (APR) se podporuje jenom v některých scénářích v závislosti na typu zdroje dat. Další informace najdete v tématu Automatická aktualizace stránky v Power BI.
- Převzetí sémantického modelu, který používá DirectQuery k jiným funkcím sémantických modelů , se v současné době nepodporuje.
- Stejně jako u jakéhokoli zdroje dat DirectQuery se hierarchie definované v modelu Analysis Services nebo sémantickém modelu Power BI nezobrazují při připojování k modelu nebo sémantickému modelu v režimu DirectQuery pomocí Excelu.
Při práci s DirectQuery pro sémantické modely Power BI a Analysis Services zvažte následující pokyny:
- Ve vztazích mezi různými zdrojovými skupinami používejte sloupce s nízkou kardinalitou: Při vytváření relace mezi dvěma různými zdrojovými skupinami by sloupce, které se účastní relace (označované také jako sloupce spojení), měly mít nízkou kardinalitu, ideálně 50 000 nebo méně. Tento faktor platí pro sloupce klíčů, které nejsou řetězcem; Pro sloupce s klíči řetězce se podívejte na následující aspekty.
- Vyhněte se použití velkých řetězců klíčových sloupců v relacích mezi zdrojovými skupinami: Při vytváření relace mezi zdrojovými skupinami nepoužívejte velké řetězcové sloupce jako sloupce relací, zejména pro sloupce s větší kardinalitou. Pokud jako sloupec relace musíte použít sloupce řetězců, vypočítejte očekávanou délku řetězce filtru vynásobením kardinality (C) průměrnou délkou sloupce řetězce (A). Ujistěte se, že očekávaná délka řetězce je nižší než 250 000, aby hodnota A ∗ C < 250 000.
Další informace a pokyny najdete v pokynech ke složenému modelu.
Aspekty tenanta
Všechny modely s připojením DirectQuery musíte publikovat do sémantického modelu Power BI nebo do služby Analysis Services ve stejném tenantovi. Tento požadavek je zvlášť důležitý při přístupu k sémantickému modelu Power BI nebo modelu Analysis Services pomocí identit hosta B2B, jak je znázorněno na následujícím diagramu.
Představte si následující diagram. Očíslované kroky v diagramu jsou popsány v následujících odstavcích.
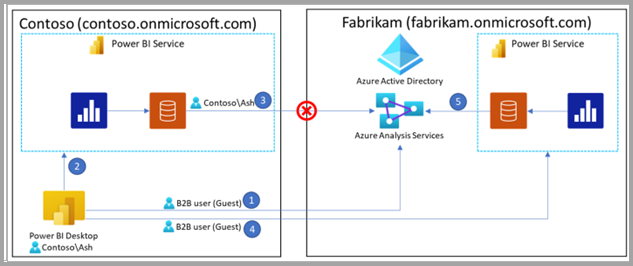
V diagramu pracuje Ash se společností Contoso a přistupuje k datům poskytovaným společností Fabrikam. V Power BI Desktopu vytvoří Ash připojení DirectQuery k modelu Analysis Services, který hostuje Fabrikam.
K ověření používá Ash identitu uživatele typu host B2B (krok 1 v diagramu).
Pokud Ash publikuje sestavu do služby Power BI Contoso (krok 2), ten sémantický model publikovaný v tenantovi Contoso se nemůže úspěšně ověřit proti modelu služby Analysis Services společnosti Fabrikam (krok 3). V důsledku toho sestava nefunguje.
V tomto scénáři, protože Fabrikam hostuje model Analysis Services, musíte také publikovat sestavu v tenantovi společnosti Fabrikam. Po úspěšném publikování v tenantovi společnosti Fabrikam (krok 4) může sémantický model úspěšně získat přístup k modelu služby Analysis Services (krok 5) a sestava funguje správně.
Práce se zabezpečením na úrovni objektů
Když složený model získá data z sémantického modelu Power BI nebo služby Analysis Services prostřednictvím DirectQuery a tento zdrojový model je zabezpečený zabezpečením na úrovni objektů, můžou si spotřebitelé složeného modelu všimnout neočekávaných výsledků. Následující část vysvětluje, jak můžou tyto výsledky nastat.
Zabezpečení na úrovni objektů (OLS) umožňuje autorům modelů skrýt objekty, které tvoří schéma modelu (to znamená tabulky, sloupce, metadata atd.) od příjemců modelu (například tvůrce sestav nebo autor složeného modelu). Při konfiguraci OLS pro objekt vytvoří autor modelu roli a pak odebere přístup k objektu pro uživatele, kteří jsou k této roli přiřazeni. Z hlediska těchto uživatelů skrytý objekt prostě neexistuje.
OLS je definována pro zdrojový model a použita pro zdrojový model. Nemůžete ho definovat pro složený model založený na zdrojovém modelu.
Když sestavíte složený model nad sémantickým modelem Power BI chráněným OLS nebo modelem Analysis Services prostřednictvím připojení DirectQuery, zkopírujete schéma modelu ze zdrojového modelu do složeného modelu. To, co kopírujete, závisí na tom, co máte povoleno zobrazit ve zdrojovém modelu podle pravidel OLS, která tam platí. Data do složeného modelu nekopírujete – v případě potřeby je vždy načtete přes DirectQuery ze zdrojového modelu. Jinými slovy, načítání dat se vždy vrátí ke zdrojovému modelu, kde platí pravidla OLS.
Vzhledem k tomu, že složený model není zabezpečený pravidly OLS, objekty, které uživatelé složeného modelu uvidí, jsou ty, které můžete vidět ve zdrojovém modelu, a ne to, k čemu by sami měli přístup. Tato situace může vést k následujícím výsledkům:
- Někdo, kdo se dívá na složený model, může vidět objekty, které jsou před nimi skryté ve zdrojovém modelu pomocí OLS.
- Naopak nemusí ve složeného modelu vidět objekt, který vidí ve zdrojovém modelu, protože tento objekt byl skrytý od autora složeného modelu pravidly OLS, která řídí přístup ke zdrojovému modelu.
Důležitým bodem je to, že i přes případ popsaný v první odrážce uživatelé složeného modelu nikdy neuvidí skutečná data, která by neměli vidět, protože data nejsou umístěná ve složeného modelu. Kvůli DirectQuery se načítá podle potřeby ze zdrojového sémantického modelu, kde OLS blokuje neoprávněný přístup.
S ohledem na toto pozadí zvažte následující scénář:
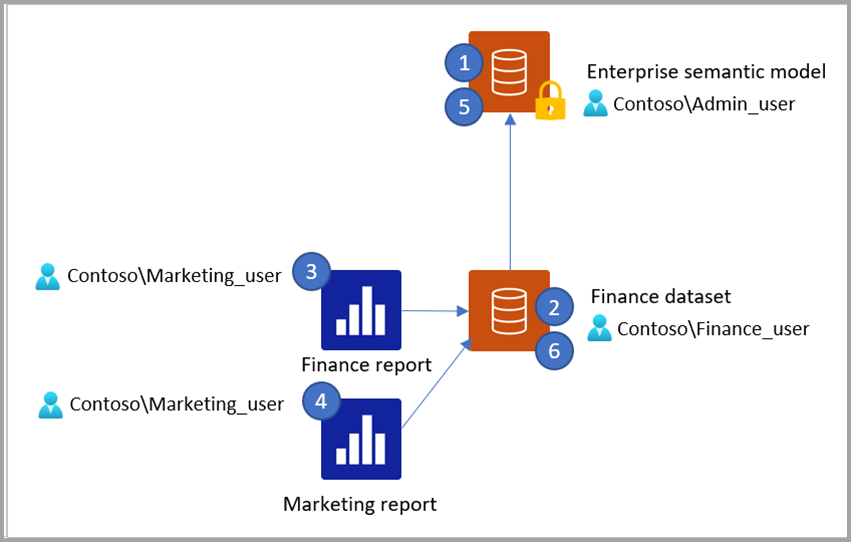
Admin_user publikuje podnikový sémantický model pomocí sémantického modelu Power BI nebo modelu Analysis Services, který má tabulku Customer a Territory. Admin_user publikuje sémantický model do služba Power BI a nastaví pravidla OLS, která mají následující účinek:
- Finanční uživatelé nevidí tabulku Customer (Zákazník)
- Uživatelé marketingu nevidí tabulku Territory
Finance_user publikuje sémantický model s názvem Finance sémantický model a sestavu s názvem Finance report, která se připojuje přes DirectQuery k podnikovému sémantickému modelu publikovanému v kroku 1. Sestava Finance obsahuje vizuál, který používá sloupec z tabulky Territory.
Marketing_user otevře sestavu Finance. Vizuál, který používá tabulku Territory, se zobrazí, ale vrátí chybu, protože při otevření sestavy se DirectQuery pokusí načíst data ze zdrojového modelu pomocí přihlašovacích údajů Marketing_user, který je zablokovaný v zobrazení tabulky Territory podle pravidel OLS nastavených v podnikovém sémantickém modelu.
Marketing_user vytvoří novou sestavu s názvem Marketing Report, která jako zdroj používá sémantický model Finance. Seznam polí zobrazuje tabulky a sloupce, ke kterým Finance_user má přístup. Proto se tabulka Territory (Oblast) zobrazuje v seznamu polí, ale tabulka Customer (Zákazník) není. Když se ale Marketing_user pokusí vytvořit vizuál, který používá sloupec z tabulky Territory, vrátí se chyba, protože v tomto okamžiku se DirectQuery pokusí načíst data ze zdrojového modelu pomocí přihlašovacích údajů Marketing_user a pravidla OLS znovu zahajují a blokují přístup. Totéž se stane, když Marketing_user vytvoří nový sémantický model a sestavu, která se připojí k sémantickému modelu Finance s připojením DirectQuery – v seznamu polí uvidí tabulku Territory, protože to je to, co Finance_user vidět, ale když se pokusí vytvořit vizuál, který tuto tabulku používá, jsou blokované pravidly OLS v podnikovém sémantickém modelu.
Teď řekněme, že Admin_user aktualizuje pravidla OLS v podnikovém sémantickém modelu, aby se finance přestaly zobrazovat v tabulce Territory.
Aktualizovaná pravidla OLS se projeví pouze v sémantickém modelu Finance při aktualizaci. Když tedy Finance_user aktualizuje sémantický model Finance, tabulka Territory se už v seznamu polí nezobrazuje a vizuál v sestavě Finance, který používá sloupec z tabulky Territory, vrátí chybu pro Finance_user, protože teď nemají povolený přístup k tabulce Territory.
Shrnutí:
- Příjemci složeného modelu uvidí výsledky pravidel OLS, která se po vytvoření modelu vztahují na autora složeného modelu. Když se tedy vytvoří nová sestava založená na složeného modelu, zobrazí se v seznamu polí tabulky, ke kterým měl autor složeného modelu přístup při vytváření modelu bez ohledu na to, k čemu má aktuální uživatel přístup ve zdrojovém modelu.
- Nemůžete definovat pravidla OLS pro samotný složený model.
- Spotřebitel složeného modelu nikdy neuvidí skutečná data, která by neměli vidět, protože příslušná pravidla OLS ve zdrojovém modelu je blokují, když se DirectQuery pokusí načíst data pomocí svých přihlašovacích údajů.
- Pokud zdrojový model aktualizuje pravidla OLS, tyto změny ovlivní jenom složený model při aktualizaci.
Načtení podmnožina tabulek z sémantického modelu Power BI nebo modelu Analysis Services
Když se připojíte k sémantickému modelu Power BI nebo modelu Analysis Services pomocí připojení DirectQuery, zvolíte, ke kterým tabulkám se chcete připojit. Po připojení k modelu můžete také automaticky přidat libovolnou tabulku, která se může přidat do sémantického modelu nebo modelu. Když se připojíte k perspektivě, váš model obsahuje všechny tabulky v sémantickém modelu a všechny tabulky, které nejsou zahrnuty do perspektivy, jsou skryté. Kromě toho se automaticky přidá jakákoli tabulka, která by se mohla přidat do perspektivy. V nabídce Nastavení se můžete po prvním nastavení připojení rozhodnout, že se automaticky připojíte k tabulkám, které se přidají do sémantického modelu.
Toto dialogové okno se nezobrazuje pro živá připojení.
Poznámka:
Toto dialogové okno se zobrazí jenom v případě, že do existujícího modelu přidáte připojení DirectQuery k sémantickému modelu Power BI nebo modelu Analysis Services. Toto dialogové okno můžete otevřít také tak, že po vytvoření změníte připojení DirectQuery k sémantickému modelu Power BI nebo modelu Analysis Services v nastavení zdroje dat.
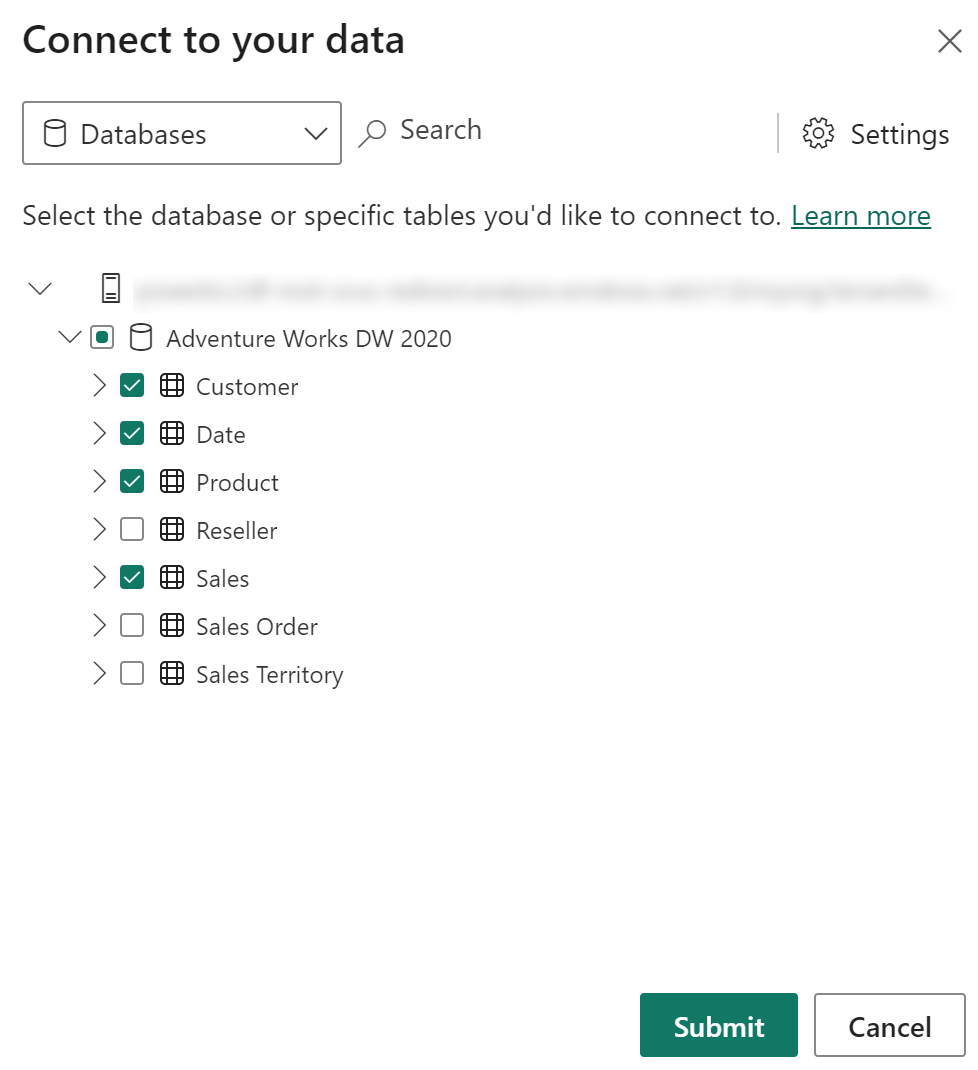
Nastavení pravidel odstranění duplicitních dat
Pravidla odstranění duplicitních dat můžete zadat tak, aby názvy měr a tabulek byly ve složeného modelu jedinečné, a to pomocí možnosti Nastavení v dialogovém okně zobrazeném dříve:
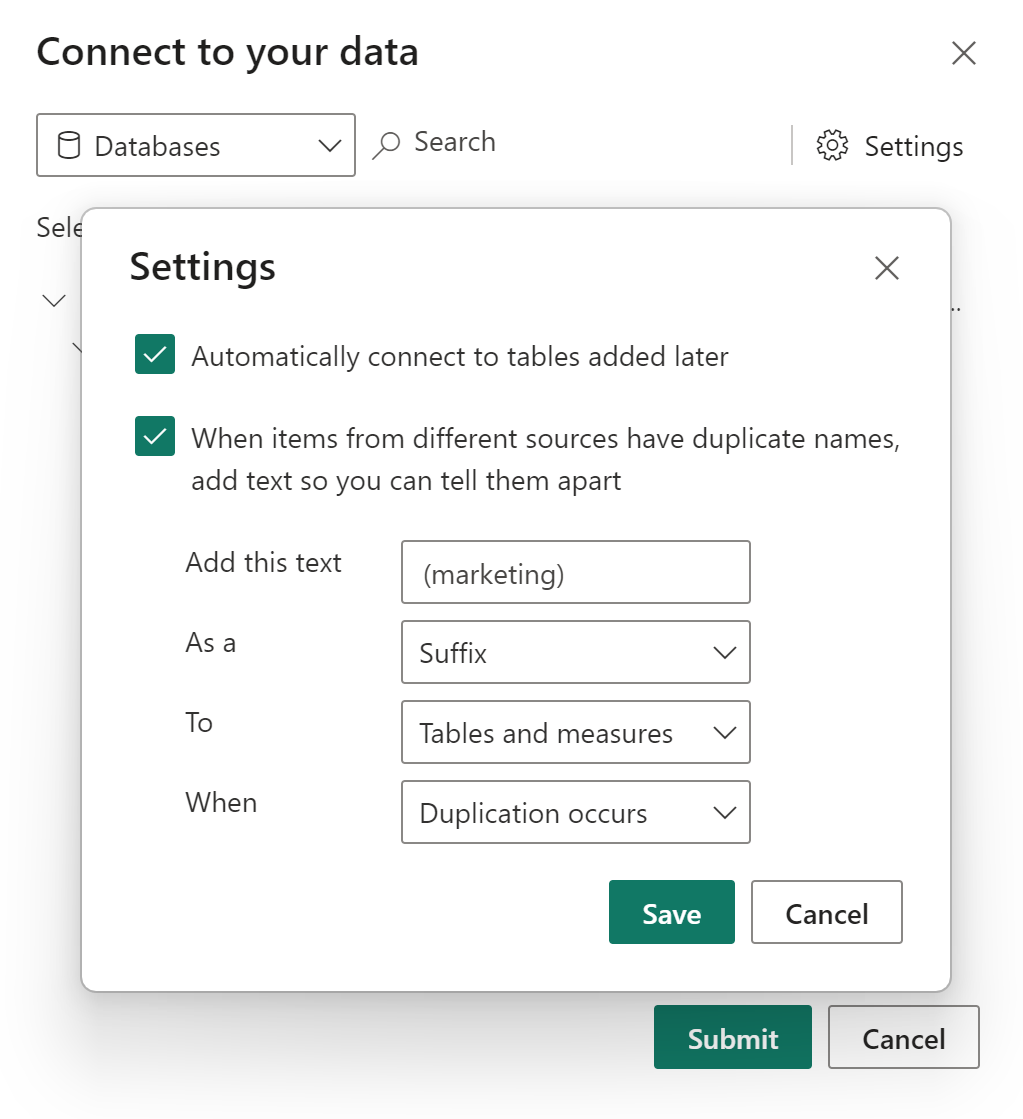
V předchozím příkladu jsme přidali příponu (marketing) do libovolné tabulky nebo názvu míry, která je v konfliktu s jiným zdrojem ve složeném modelu. Můžete provádět následující akce:
- Zadejte text, který chcete přidat k názvu konfliktních tabulek nebo měr.
- Určete, zda má být text přidán do tabulky nebo názvu míry jako předpona nebo přípona.
- Použijte pravidlo odstranění duplicitních dat u tabulek, měr nebo obojího.
- Zvolte, že se pravidlo odstranění duplicitních dat použije jenom v případě, že dojde ke konfliktu názvů nebo ho použijete po celou dobu. Výchozí hodnota je použít pravidlo pouze v případě, že dojde k duplikaci. V našem příkladu se žádná tabulka nebo míra z marketingového zdroje, které nemají v prodejním zdroji duplikát, nezmění název.
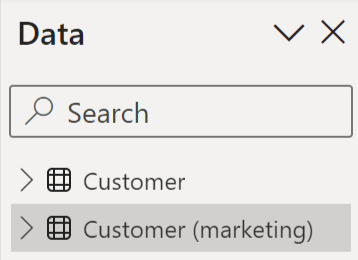
Po vytvoření připojení a nastavení pravidla odstranění duplicitních dat se v seznamu polí zobrazí zákazník i zákazník (marketing) podle pravidla odstranění duplicitních dat nastavených v našem příkladu:
Pokud nezadáte pravidlo odstranění duplicitních dat nebo vámi zadaná pravidla odstranění duplicit nevyřeší konflikt názvů, budou se dál používat standardní pravidla odstranění duplicitních dat. Standardní pravidla odstranění duplicitních dat přidávají číslo k názvu konfliktní položky. Pokud u tabulky Customer dojde ke konfliktu názvů, přejmenuje se jedna z tabulek Customer (Zákazník) na Customer 2 (Zákazník 2).
Úpravy XMLA a složené modely
Když změníte sémantický model pomocí XMLA, aktualizujte kolekce ChangedProperties a PBI_RemovedChildren pro změněný objekt tak, aby zahrnovaly všechny změněné nebo odebrané vlastnosti. Pokud tyto kolekce neaktualizujete, nástroje modelování Power BI můžou vaše změny při příští synchronizaci schématu se zdrojem dat přepsat.
Další informace o sémantických značkách rodokmenu objektů modelu najdete v tématu Značky rodokmenu pro sémantické modely Power BI.
Úvahy a omezení
Složené modely představují několik aspektů a omezení:
Připojení ve smíšeném režimu – Pokud používáte připojení ve smíšeném režimu, které obsahuje online data (například sémantický model Power BI) a místní sémantický model (například excelový sešit), musíte vytvořit mapování brány, aby se vizuály správně zobrazily.
V současné době se přírůstková aktualizace podporuje jenom u složených modelů připojujících se ke zdrojům dat SQL, Oracle a Teradata.
Ve složených modelech se nedají použít následující tabulkové zdroje Služby Live Connect:
- SAP HANA
- SAP Business Warehouse
- Služba Analysis Services serveru SQL starší než verze 2022
- Metriky využití (Můj pracovní prostor)
Použití sémantických modelů streamování ve složených modelech se nepodporuje.
Stávající omezení DirectQuery se stále vztahují při použití složených modelů. Mnohé z těchto omezení jsou teď na tabulce v závislosti na režimu úložiště tabulky. Počítaný sloupec v tabulce importu může například odkazovat na jiné tabulky, které nejsou v DirectQuery, ale počítaný sloupec v tabulce DirectQuery může stále odkazovat jenom na sloupce ve stejné tabulce. Další omezení platí pro model jako celek, pokud některé z tabulek v modelu jsou DirectQuery. Například funkce QuickInsights není v modelu dostupná, pokud některá z tabulek v něm má režim úložiště DirectQuery.
Pokud používáte zabezpečení na úrovni řádků ve složeného modelu s některými tabulkami v režimu DirectQuery, je nutné aktualizovat model, aby se použily nové aktualizace z tabulek DirectQuery. Pokud například tabulka Users v režimu DirectQuery obsahuje nové záznamy uživatelů ve zdroji, nové záznamy se zahrnou až po příští aktualizaci modelu. Služba Power BI ukládá dotaz Uživatelé do mezipaměti, aby se zlepšil výkon a nenačítá data ze zdroje do další ruční nebo plánované aktualizace.
Související obsah
Další informace o složených modelech a DirectQuery najdete v následujících článcích: