Přizpůsobení výsledků v mřížce výsledků sady dotazů KQL
Pomocí mřížky výsledků v sadě dotazů KQL můžete přizpůsobit výsledky a provést další analýzu dat. Tento článek popisuje akce, které je možné provést v mřížce výsledků po spuštění dotazu.
Požadavky
- Pracovní prostor s kapacitou s podporou Microsoft Fabric
- Databáze KQL s oprávněními pro úpravy a dat
- Sada dotazů KQL
Rozbalení buňky
Rozbalení buněk je užitečné k zobrazení dlouhých řetězců nebo dynamických polí, jako je JSON.
Poklikáním na buňku otevřete rozbalené zobrazení. Toto zobrazení umožňuje číst dlouhé řetězce a poskytuje formátování JSON pro dynamická data.
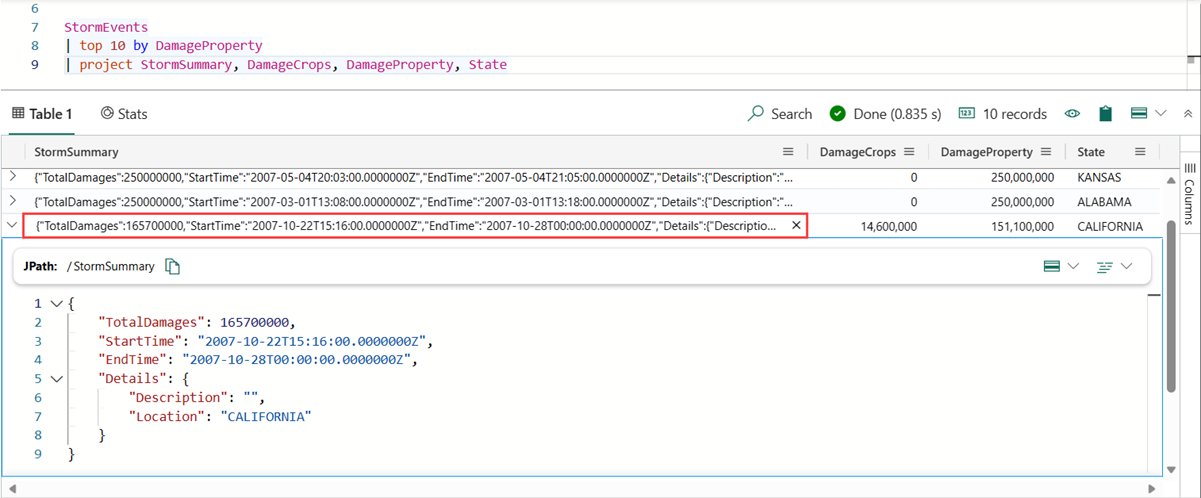
Výběrem ikony v pravém horním rohu mřížky výsledků můžete přepínat režimy podokna čtení. Zvolte pro rozbalené zobrazení následující režimy podokna čtení: vložené, pod podokno a pravé podokno.

Rozbalení řádku
Při práci s tabulkou s mnoha sloupci rozbalte celý řádek, abyste mohli snadno zobrazit přehled různých sloupců a jejich obsahu.
Klikněte na šipku > vlevo od řádku, který chcete rozbalit.
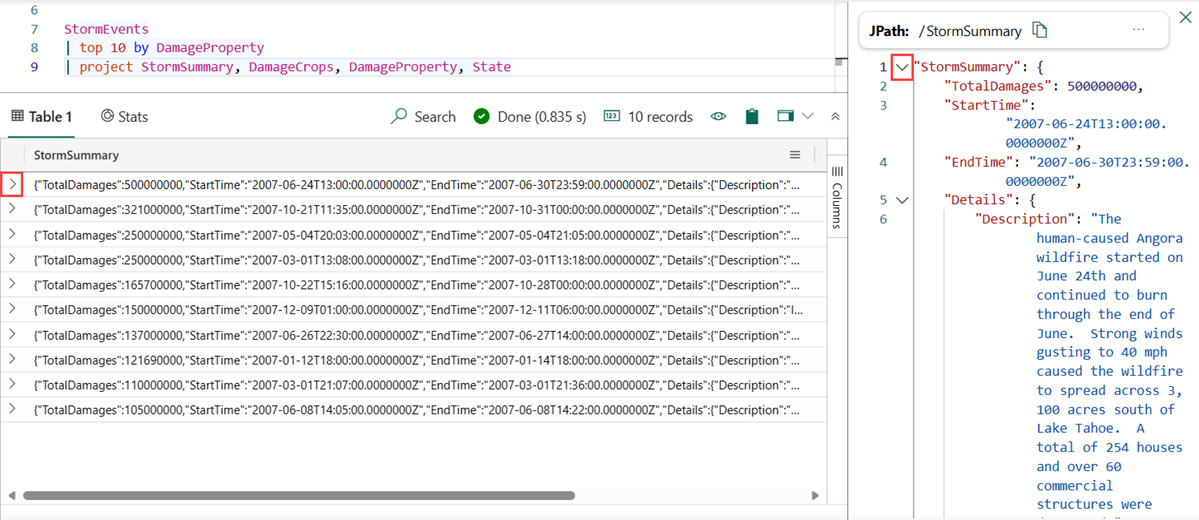
V rozbaleném řádku jsou některé sloupce rozbalené (šipka směřující dolů) a některé sloupce jsou sbalené (šipka směřující doprava). Kliknutím na tyto šipky můžete přepínat mezi těmito dvěma režimy.

Seskupení sloupců podle výsledků
Ve výsledcích můžete výsledky seskupit podle libovolného sloupce.
Spusťte tento dotaz:
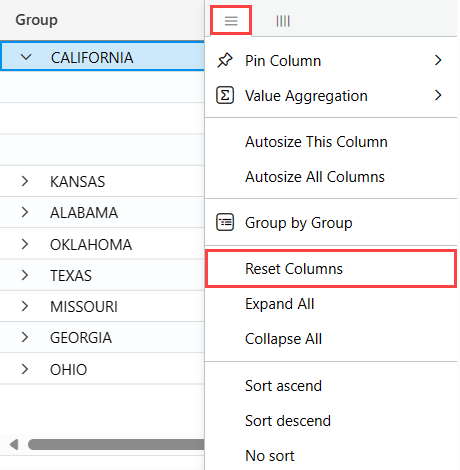
StormEvents | sort by StartTime desc | take 10Najeďte myší na sloupec Stát , vyberte nabídku a vyberte Seskupovat podle státu.
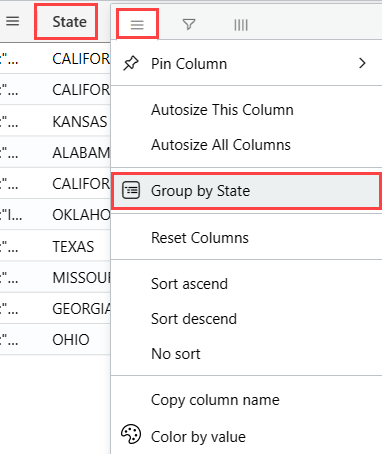
V mřížce poklikejte na Kalifornii a rozbalte záznamy pro tento stát. Tento typ seskupení může být užitečný při provádění zjišťovací analýzy.

Najeďte myší na sloupec Skupina a pak vyberte Obnovit sloupce/Oddělit podle <názvu> sloupce. Toto nastavení vrátí mřížku do původního stavu.


Skrytí prázdných sloupců
Prázdné sloupce můžete skrýt nebo zobrazit přepnutím ikony oka v nabídce mřížky výsledků.

Sloupce filtru
Výsledky sloupce můžete filtrovat pomocí jednoho nebo více operátorů.
Pokud chcete filtrovat konkrétní sloupec, vyberte nabídku pro daný sloupec.
Vyberte ikonu filtru
V tvůrci filtrů vyberte požadovaný operátor.
Zadejte výraz, podle kterého chcete sloupec filtrovat. Výsledky se filtrují při psaní.
Poznámka:
Filtr nerozlišuje malá a velká písmena.
Pokud chcete vytvořit filtr s více podmínkami, vyberte logický operátor a přidejte další podmínku.
Pokud chcete filtr odebrat, odstraňte text z první podmínky filtru.
Spuštění statistiky buněk
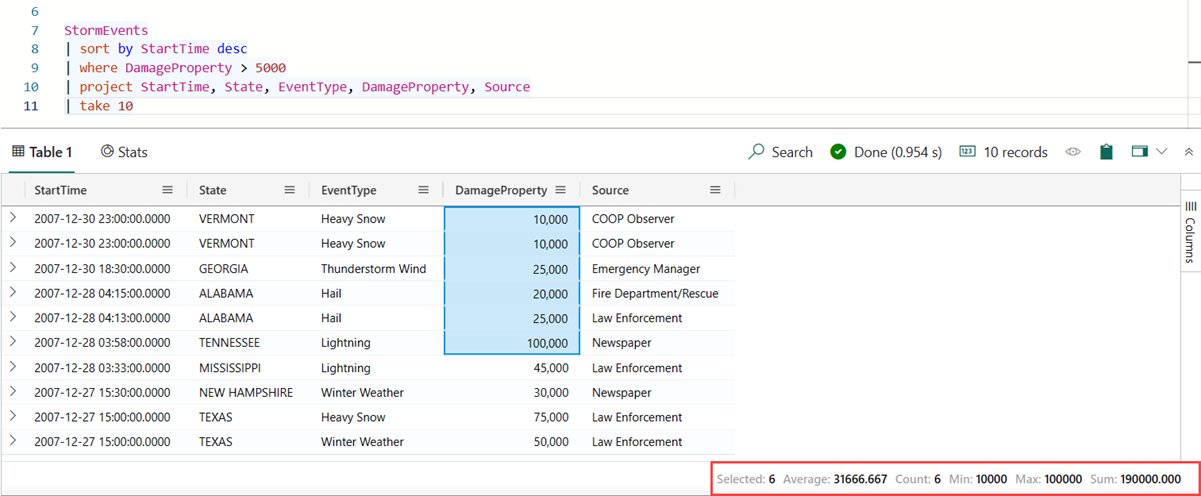
Spusťte následující dotaz.
StormEvents | sort by StartTime desc | where DamageProperty > 5000 | project StartTime, State, EventType, DamageProperty, Source | take 10V podokně výsledků vyberte několik číselných buněk. Mřížka tabulky umožňuje vybrat více řádků, sloupců a buněk a vypočítat agregace na nich. Pro číselné hodnoty jsou podporovány následující funkce: Průměr, Počet, Minimum, Maximum a Součet.

Filtrování dotazu z mřížky
Dalším snadným způsobem filtrování mřížky je přidání operátoru filtru do dotazu přímo z mřížky.
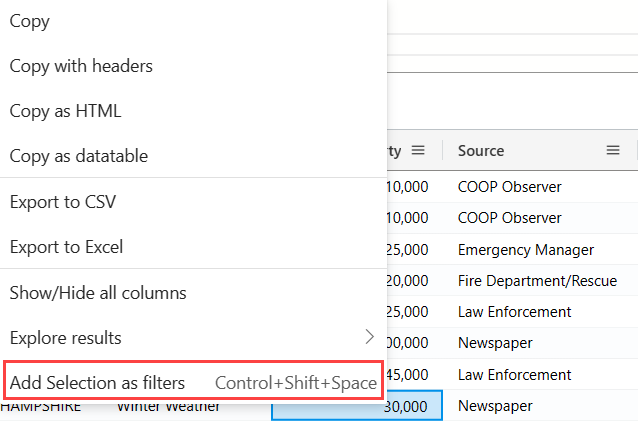
Vyberte buňku s obsahem, pro který chcete vytvořit filtr dotazu.
Kliknutím pravým tlačítkem otevřete nabídku akcí buňky. Vyberte Přidat výběr jako filtr.
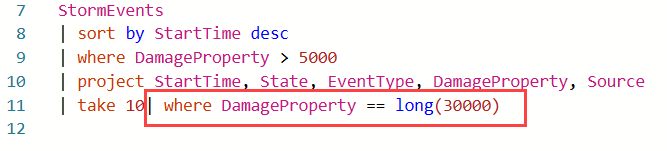
Do dotazu se přidá klauzule dotazu v editoru dotazů:
Pivot
Funkce kontingenčního režimu je podobná kontingenční tabulce Excelu, která umožňuje provádět pokročilou analýzu v samotné mřížce.
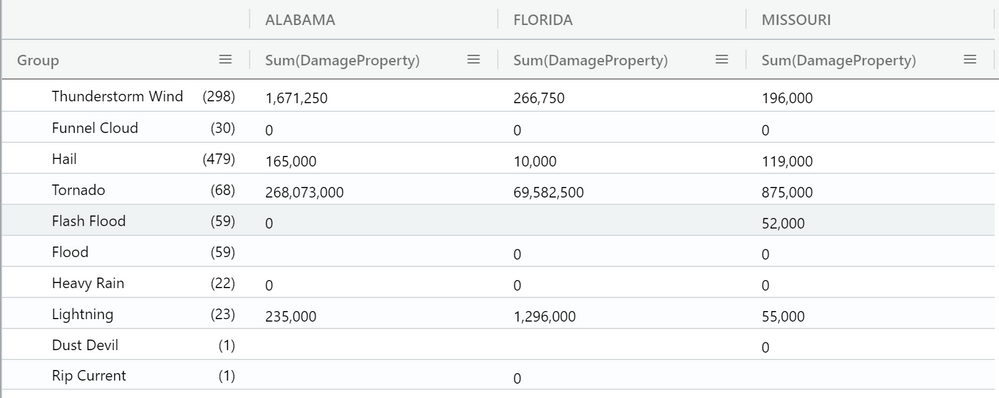
Pivoting umožňuje vzít hodnotu sloupce a převést je na sloupce. Můžete například nastavit sloupce pro Florida, Missouri, Alabama a tak dále.
Na pravé straně mřížky vyberte Sloupce a zobrazte panel nástrojů tabulky.
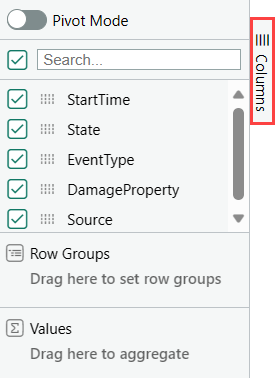
Vyberte režim kontingenční tabulky a potom přetáhněte sloupce následujícím způsobem: EventType do skupin řádků; DamageProperty to Values; and State to Column labels.
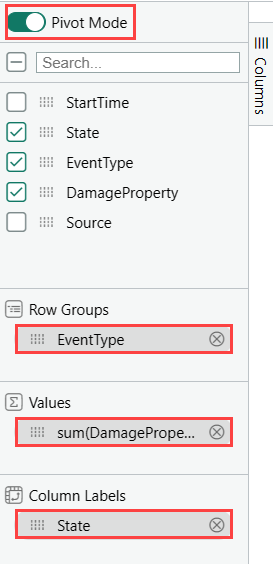
Výsledek by měl vypadat jako následující kontingenční tabulka:

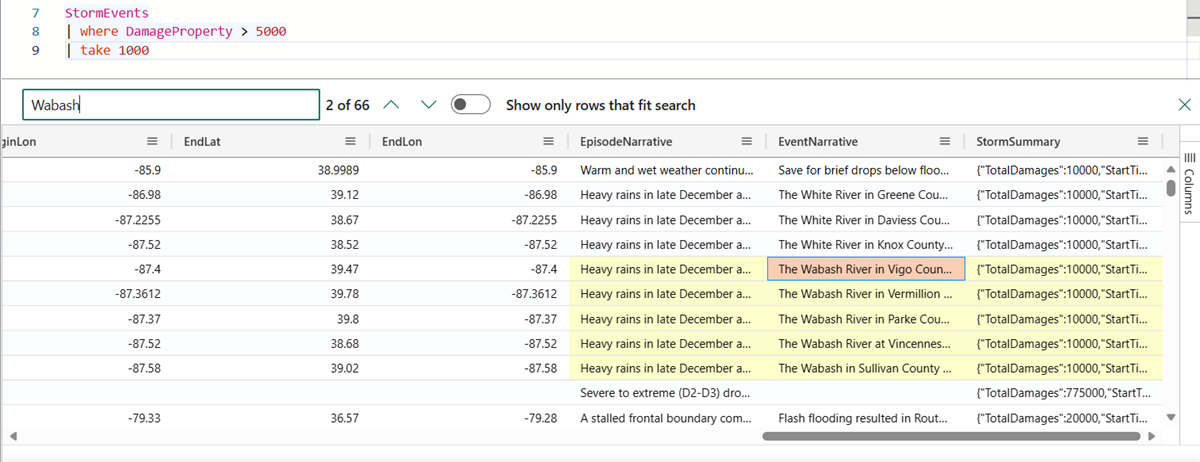
Hledání v mřížce výsledků
Můžete vyhledat konkrétní výraz v tabulce výsledků.
Spusťte tento dotaz:
StormEvents | where DamageProperty > 5000 | take 1000Vyberte tlačítko Hledat na pravé straně a zadejte "Wabash".
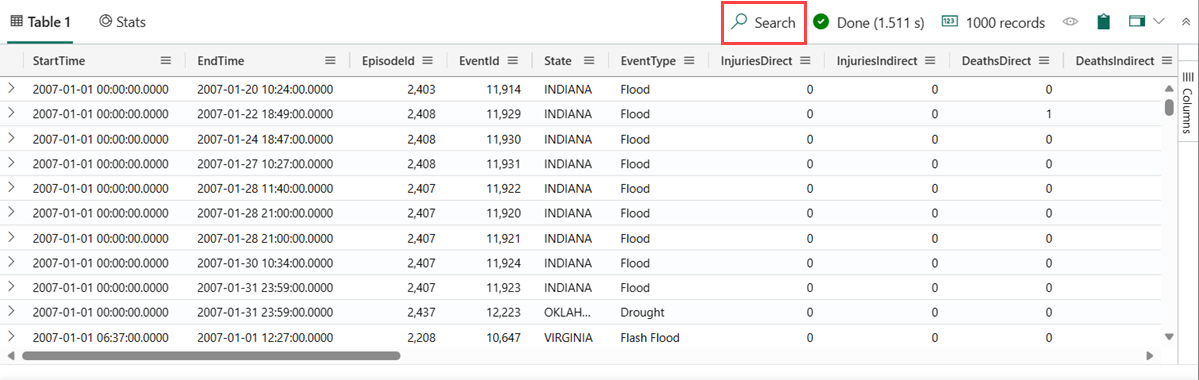
Všechny zmínky o hledaném výrazu jsou teď v tabulce zvýrazněné. Mezi nimi můžete přecházet tak , že kliknutím na Enter přejdete dopředu nebo se posunete dozadu nebo můžete použít tlačítka nahoru a dolů vedle vyhledávacího pole.


Související obsah
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro