Získání dat z úložiště Azure
V tomto článku se dozvíte, jak získat data z úložiště Azure (kontejner ADLS Gen2, kontejner objektů blob nebo jednotlivé objekty blob) do nové nebo existující tabulky.
Požadavky
- Pracovní prostor s kapacitou s podporou Microsoft Fabric
- Databáze KQL s oprávněními pro úpravy
- Účet úložiště
Source
Na dolním pásu karet databáze KQL vyberte Získat data.
V okně Načíst data je vybrána karta Zdroj .
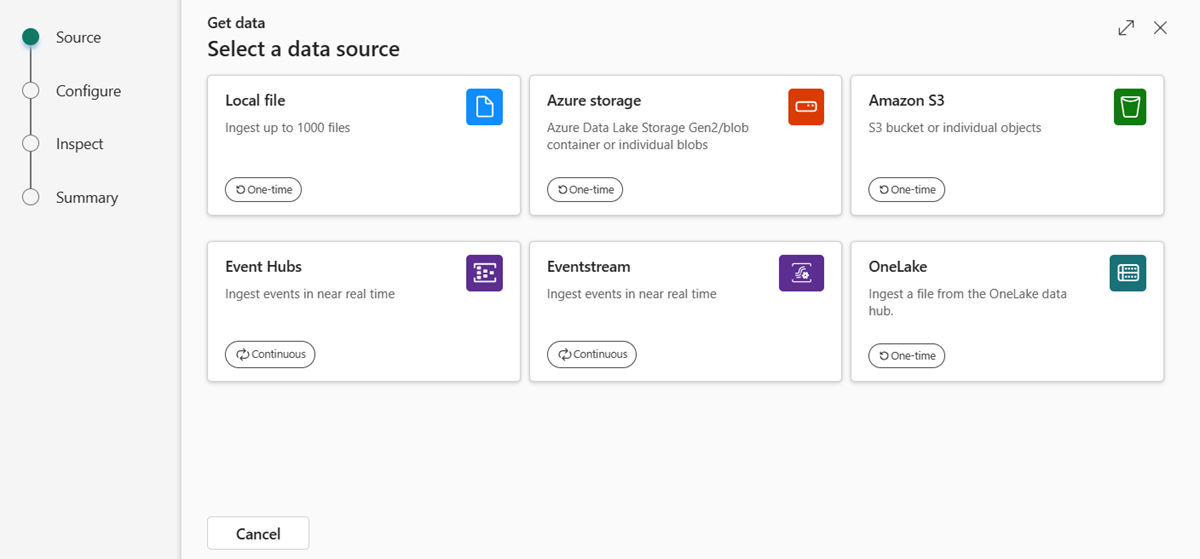
Vyberte zdroj dat z dostupného seznamu. V tomto příkladu ingestujete data z úložiště Azure.

Konfigurace
Vyberte cílovou tabulku. Pokud chcete ingestovat data do nové tabulky, vyberte + Nová tabulka a zadejte název tabulky.
Poznámka:
Názvy tabulek můžou mít maximálně 1024 znaků včetně mezer, alfanumerických znaků, pomlček a podtržítka. Speciální znaky nejsou podporované.
Pokud chcete přidat zdroj dat, vložte připojovací řetězec úložiště do pole identifikátoru URI a pak vyberte +. Následující tabulka uvádí podporované metody ověřování a oprávnění potřebná k ingestování dat z úložiště Azure.
Metoda ověřování Jednotlivé objekty blob Kontejner objektů blob Azure Data Lake Storage Gen2 Token sdíleného přístupu (SAS) Číst a Psát Čtení a seznam Čtení a seznam Přístupový klíč účtu úložiště Poznámka:
- Můžete přidat až 10 jednotlivých objektů blob nebo ingestovat až 5 000 objektů blob z jednoho kontejneru. Nemůžete ingestovat oba současně.
- Každý objekt blob může být maximálně 1 GB nekomprimovaný.
Pokud jste vložili připojovací řetězec pro kontejner objektů blob nebo Azure Data Lake Storage Gen2, můžete přidat následující volitelné filtry:
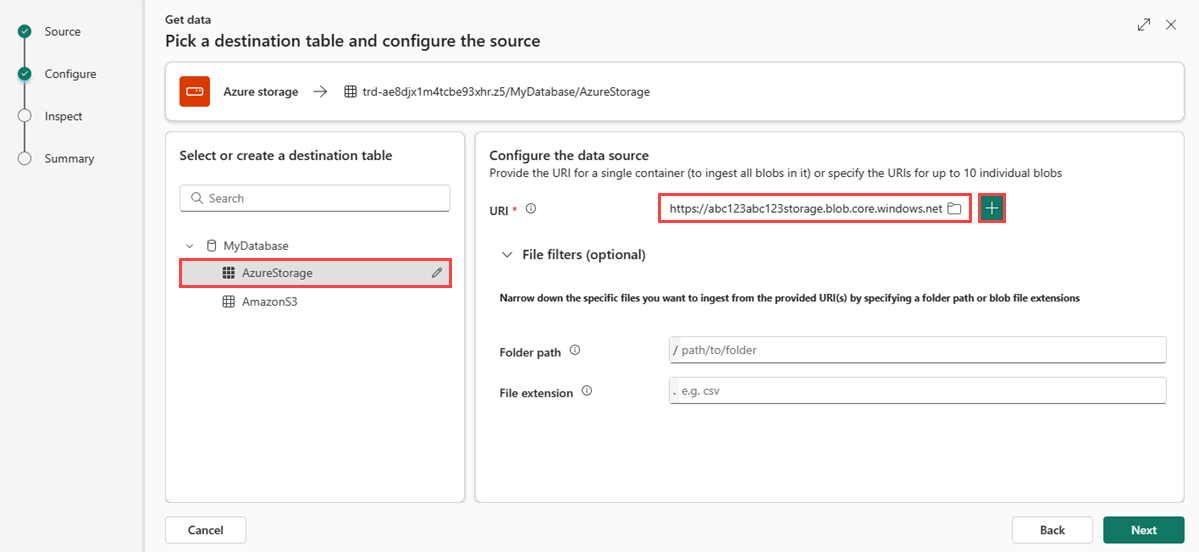
Nastavení Popis pole Filtry souborů (volitelné) Folder path Filtruje data na ingestování souborů s konkrétní cestou ke složce. Přípona souboru Filtruje data pouze na ingestování souborů s konkrétní příponou souboru.
Vyberte Další.

Inspekce
Otevře se karta Kontrola s náhledem dat.
Proces příjmu dat dokončíte výběrem možnosti Dokončit.

Nepovinná možnost:
- Výběrem prohlížeče příkazů zobrazíte a zkopírujete automatické příkazy vygenerované z vašich vstupů.
- Pomocí rozevíracího seznamu Definiční soubor schématu změňte soubor, ze kterého je schéma odvozeno.
- Změňte automaticky odvozený formát dat výběrem požadovaného formátu z rozevíracího seznamu. Další informace najdete v tématu Formáty dat podporované analýzou v reálném čase.
- Upravte sloupce.
- Prozkoumejte pokročilé možnosti na základě datového typu.
Upravit sloupce
Poznámka:
- U tabulkových formátů (CSV, TSV, PSV) nemůžete namapovat sloupec dvakrát. Pokud chcete namapovat na existující sloupec, nejprve odstraňte nový sloupec.
- Existující typ sloupce nelze změnit. Pokud se pokusíte namapovat na sloupec s jiným formátem, můžete skončit s prázdnými sloupci.
Změny, které můžete provést v tabulce, závisí na následujících parametrech:
- Typ tabulky je nový nebo existující
- Typ mapování je nový nebo existující
| Typ tabulky | Typ mapování | Dostupné úpravy |
|---|---|---|
| Nová tabulka | Nové mapování | Přejmenování sloupce, změna datového typu, změna zdroje dat, transformace mapování, přidání sloupce, odstranění sloupce |
| Existující tabulka | Nové mapování | Přidejte sloupec (u kterého pak můžete změnit datový typ, přejmenovat a aktualizovat) |
| Existující tabulka | Existující mapování | Žádná |

Mapování transformací
Některá mapování formátu dat (Parquet, JSON a Avro) podporují jednoduché transformace v čase ingestování. Pokud chcete použít transformace mapování, vytvořte nebo aktualizujte sloupec v okně Upravit sloupce .
Transformace mapování je možné provést u sloupce typu řetězec nebo datum a čas, přičemž zdroj má datový typ int nebo long. Podporované transformace mapování jsou:
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
Rozšířené možnosti založené na datovém typu
Tabulkový (CSV, TSV, PSV):
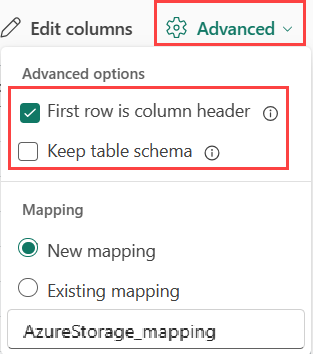
Pokud ingestujete tabulkové formáty v existující tabulce, můžete vybrat schéma tabulky Advanced>Keep. Tabulková data nemusí nutně obsahovat názvy sloupců, které se používají k mapování zdrojových dat na existující sloupce. Pokud je tato možnost zaškrtnutá, mapování se provádí podle pořadí a schéma tabulky zůstane stejné. Pokud tato možnost není zaškrtnutá, vytvoří se nové sloupce pro příchozí data bez ohledu na strukturu dat.
Pokud chcete použít první řádek jako názvy sloupců, vyberte Upřesnit>první řádek je záhlaví sloupce.
JSON:
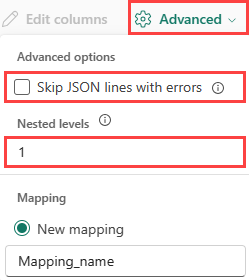
Pokud chcete určit rozdělení sloupců dat JSON, vyberte pokročilé>vnořené úrovně od 1 do 100.
Pokud vyberete rozšířené>přeskočení řádků JSON s chybami, data se ingestují ve formátu JSON. Pokud toto políčko nezaškrtnete, data se ingestují ve vícejsonovém formátu.
Souhrn
V okně přípravy dat jsou všechny tři kroky označené zelenými značkami zaškrtnutí, jakmile se příjem dat úspěšně dokončí. Můžete vybrat kartu pro dotazování, vypustit ingestované data nebo zobrazit řídicí panel souhrnu příjmu dat.

Související obsah
- Informace o správě databáze najdete v tématu Správa dat.
- Pokud chcete vytvářet, ukládat a exportovat dotazy, přečtěte si téma Dotazování dat v sadě dotazů KQL.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro